基于多层交叉注意力融合网络模型的人脸图像情感分析
2023-03-15邓亚萍王新尹甜甜
邓亚萍,王新,尹甜甜
(云南民族大学数学与计算机科学学院,昆明 650500)
随着微信、微博等社交媒体的蓬勃发展,使用自拍等图片来表达想法的趋势越来越强烈,因此面部图像情感分析愈发引起了行业内外的关注。心理学家拉塞尔通过研究发现约55%的日常交流由面部表情传达,这说明面部表情在情感的表达中起着重要作用。人脸情感分析是一项复杂且具有挑战性的工作,是人机交互的重要组成,随着深度学习的发展,深度学习在人脸情感领域的研究也逐渐成为研究热点[1]。
在过往的研究中,大多是采用传统的方法对浅层信息,如颜色、轮廓等方面进行情感分析[2]。但是,传统方法易出现泛化能力差、识别率低等问题,并且在特征提取过程中容易缺少重要的表情特征[3]。近些年,研究人员基于深度学习设计了许多经典的网络结构如ResNet[4]、AlexNet[5]、GoogLeNet[6]等,使得深度学习算法再次引起了大家的关注。随着深度学习在图像处理方面的不断应用,研究者开始将其应用于人脸情感分析。张珂等[7]在保证识别率的情况下提出了一种改进的神经网络结构,简化了网络结构的同时提升了训练速度。Yang等[8]结合注意力机制和循环结构共同训练了具有双向密集型连接、逐层精炼特征的网络CliqueNet。Li等[9]利用深度残差网络来特征提取从而进行人脸情感分析。Agrawal等[10]深入研究了过滤器大小与卷积核数量等对人脸情感分析的影响,并做了全面评估。徐琳琳等[11]针对训练时间过长与表情特征提取较难等问题,提出了并行卷积神经网络的人脸情感分析方法。宋晓茹等[12]使用不同尺度的特征层嵌入注意力机制来改进的R-ResNet50网络模型,使得提取特征更具有判别性。上述研究仅考虑了图像的整体情况,而对于局部区域的情感表达研究在近年亦引起了学者们的关注。如Sun等[13]利用深度学习自动定位有效特征信息的局部区域用于视觉情感分析。Li等[14]提出了一种兼顾局部和局部-整体的全文情境感知分类模型。蔡国永等[15]针对视觉图像情感分析中忽略局部区域情感表示的问题,提出一种嵌入图像整体特征与局部对象特征的视觉情感分析方法。虽然近些年学者对图像整体与局部区域都有不同的研究,但是很少有人探索二者之间的协同作用对视觉情感特征表示的意义。
现针对大多数人脸图像情感分析方法只单方面关注图像整体或图像局部来构建视觉情感特征表示,提出一种多层交叉注意力融合网络情感分析方法。结合人脸图像整体与局部在情感表达上的协同关系,利用多层交叉注意力融合网络模型,使提取的特征更加完善全面,更有利于提高后续情感分类的准确性。
1 基于多层交叉注意力融合网络模型
1.1 图像数据预处理
在实际生活中,大规模的人脸数据集通常包含大量信息,为了最大限度地简化数据和增强模型提取特征的可靠性,同时提高网络模型的鲁棒性与泛化性,采用旋转、翻转、裁剪、缩放、扩充等手段进行预处理的同时,还使用人脸对齐的方法。人脸对齐是根据输入的人脸图像定位出面部的关键特征点,如嘴角、眼睛、鼻尖等关键部位,如图1所示,得到其关键点坐标,并根据坐标进行对齐。

图1 人脸对齐提取关键特征点图Fig.1 Face alignment extraction key feature points
如图2所示,利用K均值聚类(K-means)的方法进行人脸对齐[16],首先采用K-means对训练图像进行聚类,使欧氏距离相近的人脸图像归为一类,将训练图像分为K类;其次通过KNN(Knearest neighbors)算法根据输入图像匹配其相似的类,选取K张与输入图像相似的训练图像,建立其形状和外观模型;然后将非线性人脸模型转换为一系列的线性组合,最终实现快速拟合。

图2 人脸对齐算法框图Fig.2 Block diagram of face alignment algorithm
为了简便计算,将其权重系数d设置为零,选择与输入图像I距离最近的K张训练图为形状和外观基础,其中欧式距离公式为
(1)
式(1)中:dist为欧式距离函数;x=(x1,x2,…xn);y=(y1,y2,…yn);xi和yi为第i个点的坐标。
最后人脸对齐方法可以简化为
(2)
式(2)中:K为选定的与测试图最相近的训练图的数量;I为测试图像;S0为平均形状;Ai(u)为形状变化;W(u;a)为平均形状S0到形状S的分段仿射变换;α和β分别为形状参数和外观参数。
1.2 特征相关性分析
面部表情通过多个面部区域同时展现,为了解面部各特征之间的联系,同时剔除部分无关特征,提取最有效的分类特征,即实现最大化类的可分性。为此引入Center Loss+Softmax Loss来实现简单而有效的特征相关性分析。该方法不仅能兼顾类内聚合与类间分离,且能在保留信息量的同时减少特征的数量。
Center Loss+Softmax Loss主要是在Softmax Loss的基础上,让每一类特征尽可能的在输出特征空间内聚集在一起,即每一类的特征在特征空间中尽可能的聚集在某一个中心点附近。在训练过程中,增加样本经过网络映射后在特征空间与类中心的距离约束,从而兼顾了类内聚合与类间分离[17]。
其中Center Loss的公式为
(3)
关于LC的梯度和cyi的更新公式为
(4)
(5)
式中:cj为类中心;cyi为第yi个类别的特征中心;δ(yi=j)为指示函数,当yi=j时返回1,否则返回0;xi为全连接层之前的特征;m为mini-batch的大小。因此式(5)就是希望一个batch中每个样本的特征离特征中心距离的平方和越小越好,也就是类内距离要越小越好。
最终将Center Loss和Softmax Loss进行加权求和,实现整体的分类任务的学习。
其中Softmax Loss的公式为
(6)
L1=LS+λLC
(7)
在加权求和的过程中通过λ来控制二者的比重,其中λ为平衡因子,m表示mini-batch包含的样本数量,n表示类别数,权重W相当于n个向量组成的矩阵,byi为偏置,在训练时,提取到人脸特征x根据标签确定属于哪一类,然后与W中的向量做内积。
1.3 多层交叉注意力网络
由于在图像的整体和局部区域学习到的情感特征并不完全相同的,因此二者对于图像的情感表达缺一不可。近年来,由于注意力机制拥有能在海量信息中筛选出重要信息并聚焦定位信息和加强局部区域的情感特征表示等特点,使其在深度学习领域被广泛应用,同时也取得了令人鼓舞的成果。但单一注意力模块无法充分捕捉不同表情中的所有微妙而复杂的变化,因此在综合考虑整体和局部协同关系后,提出了多层交叉注意力网络,即引入多头CBAM(convolutional block attention module)注意力模块。由于在特征提取的过程中,随着网络层数的增加,不同层的特征图呈现不同的特点。浅层神经网络易保留更多边缘环境信息,深层神经网络则会保留更多的情感信息。由此将融合通道和空间注意力的思想从卷积的最高层扩展到每一层,加强对空间与通道的关注,同时激活多个不重叠的注意力区域,捕获来自不同层和不同区域的关键特征,从而提升网络的特征表达能力。多层交叉注意力网络具体结构如图3~图5所示。

图3 交叉注意力网络结构图Fig.3 Structure of cross-attention network

图4 通道注意力网络结构图Fig.4 Structure of channel attention network
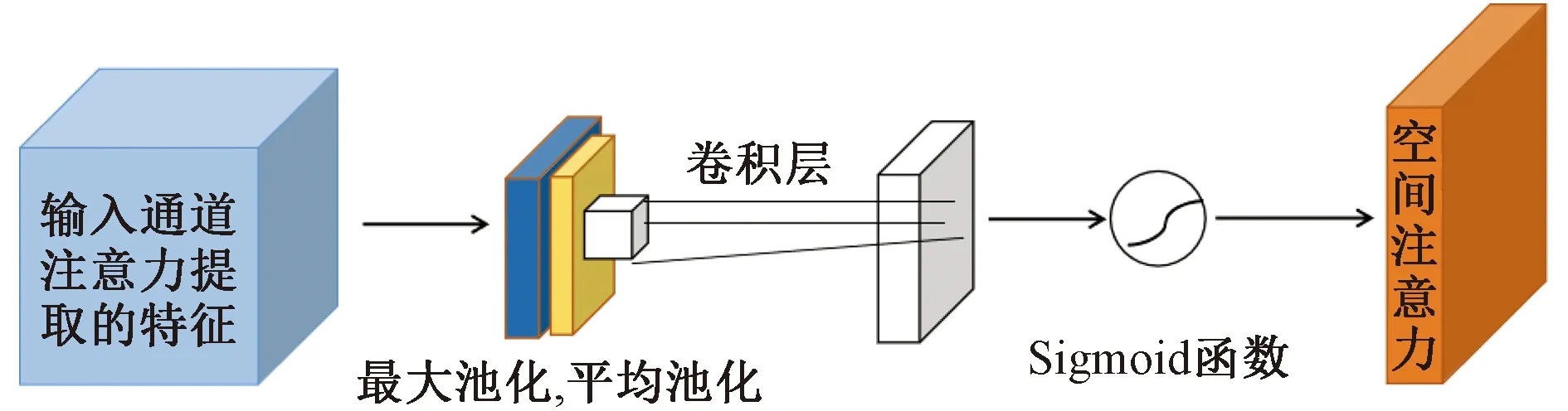
图5 空间注意力网络结构图Fig.5 Structure of spatial attention network
通道注意力聚焦在“什么”是有意义的输入图像,而空间注意力聚焦在“哪里”具有重要情感特征,是对通道注意力的补充。从空间的角度来看,通道注意力是全局的,而空间注意力是局部的,因此交叉注意力网络是通道注意力和空间注意力模型的组合[18]。在多层交叉注意力网络中,通道注意力模块先接收来自预处理的图像作为输入特征,利用最大池化与平均池化同时对输入特征维度进行压缩,再通过由多层感知器组成的共享网络,合并形成通道注意力图;然后空间注意力模块接收来自通道注意力模块的输入特征,依次利用最大池化与平均池化进行空间特征提取,获得空间注意力特征;经过交叉注意力网络后,新特征图结合了通道和空间维度上的注意力权重,提升了各特征在通道和空间上的相关性,更有利于提取人脸的有效特征。最后将通道注意力图与空间注意图放入后续的注意力融合网络模块中进行融合。
1.4 注意力融合网络
虽然多层交叉注意力网络生成的注意力图能够捕捉各种区域的特征,但仍然是无序的。为解决这个问题,提出了注意力融合网络。首先通过log-softmax函数缩放注意力图来强调最感兴趣和最重要的区域;其次提出了一种分区损失来指导多层次交叉注意力聚焦在不同的关键区域,避免重叠注意力,造成计算量的消耗;然后通过引入改进的Focal损失函数解决数据集存在类别样本不平衡问题;最后统一将其进行归一化,最终形成了注意力的融合[19-20]。
为了缩放注意力图,因此需要定义一个缩放函数。假设x属于k×c的向量空间,即x∈Rk×c,xi为注意力图的第i个向量,那么缩放函数为
(8)
为了将注意力图之间的差异最大化,考虑将交叉注意力作为自适应调整的损失值下降速度的参数,因此将分区损失定义为
(9)
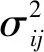
针对数据集类别样本不平衡这个问题,引入改进的 Focal 损失函数进行加权,有助于提升情感分类模型的训练效率,其具体计算公式[21]为
L3=-α(1-p)γlnp
(10)
式(10)中:聚焦参数γ为一个大于0的超参数,最优值通过实验获得,其作用是通过(1-p)γ项来调节置信样本在总损失中的权重,p为相应概率值。平衡参数α同样是一个超参数,由网格搜索方法得到最优值,其作用是控制正负样本在总损失的权重,平衡不同类别样本的数量。
为了将各损失函数进行统一融合,设计了权值融合策略为
L=λ1L1+λ2L2+λ3L3
互联网是经济发展的重要助推力,也是企业财务信息化建设的技术支撑性力量,互联网背景下的企业财务管理特点包括如下三点:
(11)
式(11)中:L1为特征相关性分析中的损失函数;L2为分区损失函数;L3为Focal损失函数;λ1、λ2和λ3为L1、L2和L3的平衡因子,系数越大,代表权重越大。
1.5 多层交叉注意力融合网络算法
多层交叉注意力融合网络包括:输入层、人脸图像预处理层、特征相关性分析层、多层交叉注意力网络层、注意力融合层、线性层、正则化层和输出层。算法步骤如下:
步骤1获取数据集,将数据集中的人脸图像X输入,其中Xi表示这张图像的第i个特征。即
X=[X1,X2,…,Xn]
(12)
步骤2将输入层的图像进行预处理,提取关键特征,用向量T表示为
T=[T1,T2,…,Tn]
(13)
步骤3将预处理后得到的特征向量T作为输入矩阵,在多层交叉注意力融合网络中进行训练,经过特征相关性分析层、多层交叉注意力网络层、注意力融合层后,得到图像向量表示为F。
步骤4利用线性层对特征进行处理,再通过正则化层稳定网络。
步骤5输出人脸图像X对应的多标签情感分类预测准确率(accuracy)和ROC(receiver operating characteristic curve)曲线。
多层交叉注意力融合网络算法框图如图6所示。
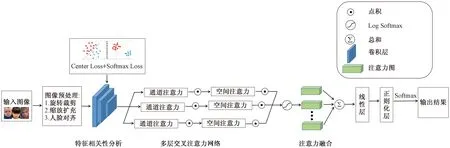
图6 多层交叉注意力网络算法框图Fig.6 Block diagram of multi-layer cross-attention network algorithm
多层交叉注意力融合网络首先采用旋转、翻转、裁剪、缩放、扩充和K-means人脸对齐等手段进行预处理,不仅最大限度地简化数据,同时增强模型提取特征的可靠性。其次利用Center Loss+Softmax Loss进行特征相关性分析,兼顾了类内聚合与类间分离,且在保留信息量的同时减少了特征的数量。再次将通道注意力与空间注意力交替组成交叉注意力网络,从卷积的最高层扩展到每一层,加强对空间与通道的关注,提升整体与局部特征的表达能力。然后通过注意力融合网络对各种注意力进行有序融合,避免因注意力重叠导致的计算量的消耗的同时,将注意力定位在最感兴趣和最重要部位。最后将融合后的结果通过线性化层与正则化层,加快网络的训练和收敛的速度,最终利用Softmax分类器输出分类结果。
2 实验结果与分析
2.1 实验环境与数据集
本文的实验平台与环境配置如表1所示。

表1 实验平台与环境Table 1 Experimental platform and environment
为了评估本文多层交叉注意力融合网络模型情感分析的效果,采用网络上公开的数据集RAF-DB对模型的有效性与优越性进行验证,数据来源于http://www.whdeng.cn/raf/model1.html。此数据集是一个大规模的面部表情数据库,发布于2017年,包含总共29 672 张图片,其中7个基本表情和12个复合表情,而且每张图还提供了年龄范围和性别标注。基于众包注释,每张图像都由大约40个注释者独立标记。实验过程中将人脸图像数据集按照5∶1的比例划分为训练集和验证集,其中标签分为惊喜、害怕、厌恶、开心、伤心、生气和中立等7个大类。数据集中部分图像如图7所示。

图7 数据集示例图像图Fig.7 sample image of the dataset
2.2 实验参数设置
多层交叉注意力融合网络模型采用ResNet-18作为主干网络,其中模型的主要参数包括学习率、Batch_size、epoch、Num attention heads、激活函数、优化器等,在控制其他参数相互保持固定的情况下,依次改变各参数的数值,以得到模型的最优参数。最终多层交叉注意力融合网络模型具体参数设置如表2所示。

表2 多层交叉注意力融合网络模型参数设置Table 2 Parameter Settings of multi-layer cross-attention fusion network model
2.3 实验效果评估与分析
2.3.1 实验效果评估
使用混淆矩阵统计分类结果,如表3所示。其中TP表示预测为正例的正例样本数量,FN表示预测为负例的正例样本数量,FP表示预测为正例的负例样本数量,TN表示预测为负例的负例样本数量。

表3 分类结果的混淆矩阵Table 3 Confusion matrix of classification results
在图像情感分析任务中,每个样本可以有一个或多个标签,一般情况下,每个标签对应两个类别。在综合考虑各种因素后,采用准确率与ROC曲线为模型分类效果的评价指标。
准确率(accuracy,Acc)的计算公式为
(14)
真正类率(TPR)的计算公式为
(15)
假正类率(FPR)和计算公式为
(16)
准确率是预测正确的结果占总样本的百分比,能反映模型总体的预测准确程度。ROC曲线是一种直观用于评价模型分类能力的曲线,其纵轴代表真正类率(ture positive rate,TPR),即分类器预测的正类中实际正例占所有正例的比例;横轴代表假正类率(false positive rate,FPR),即分类器预测的正类中实际负例占所有负例的比例。
2.3.2 实验结果分析
实验的训练集与验证集必不可少。训练集是模型拟合的数据样本,在训练过程中对训练误差进行梯度下降和学习。验证集是模型训练过程中单独留出的样本集,用于调整模型的超参数与评估模型。实验中将数据集的29 672张图片按5∶1的比例随机划分成训练集和验证集,在上述实验环境下,统计多层交叉注意力融合网络在训练集和验证集上的表现效果,最终训练集和验证集的准确率如表4所示。
从表4知多层次交叉注意力融合网络在训练集和验证集中准确率均达到88.5%以上,验证了本文方法的有效性。然而,由于训练集类别样本不均衡,故在验证集上的表现不如训练集,因此解决样本不均衡影响分类效果的问题仍需进一步优化。

表4 多层交叉注意力融合网络模型实验结果Table 4 Experimental results of multi-layer cross-attention fusion network model
ROC曲线能直观评价模型分类能力,ROC曲线越是靠近左上角,即ROC曲线越靠拢(0,1)点,越偏离45°对角线,则模型的灵敏度越高,误判率越低,该模型的性能越好,实验的ROC曲线如图8所示。
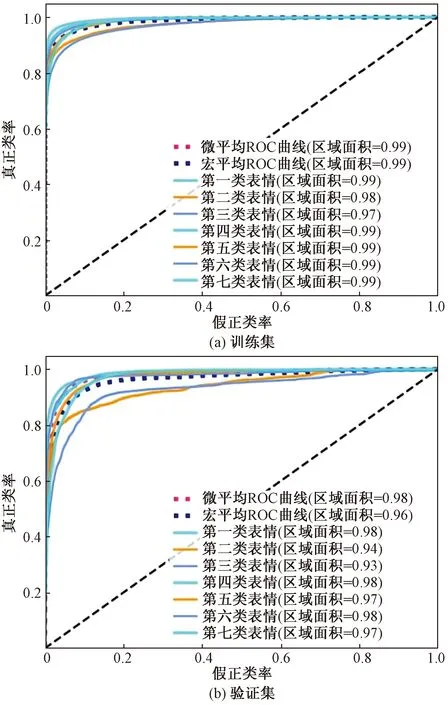
图8 实验的ROC曲线图Fig.8 ROC curve of the experiment
从图8中可以明显看出每一条曲线均非常靠近左上角(0,1)点且偏离45°对角线,表明该模型灵敏度很高,且对数据集中的七种情绪分类较为准确,再次验证该模型方法的有效性。
2.4 消融实验与对比实验
2.4.1 消融实验
为了明确各个网络模块对最终分类性能的影响,利用RAF-DB数据集在原先的实验环境与实验参数下进行消融实验,测试惊喜、害怕、厌恶、开心、伤心、生气和中立等7种情绪的最优准确率。
多层交叉注意力融合网络模型主要由图像预处理模块、特征相关性分析模块、多层交叉注意力网络模块、注意力融合模块组成,由于图像预处理对本文模型是必要的,因此保留预处理模块,然后分别删除其余模块进行消融实验,实验结果如表5所示。

表5 RAF-DB数据集消融实验结果Table 5 Ablation experiment results of RAF-DB data set
从表5中可以看出,当删除其中任何一个模块时,与完整网络相比,最优准确率均有一定程度的下降。当没有特征相关性分析模块,准确率下降了1.31%;没有注意力融合模块,准确率下降了0.39%;尤其是没有多层次交叉注意力模块的情况下,准确率下降了2.12%,下降比例最大。实验结果表明每个模块对最终输出结果上都有一定的促进作用,同时也确立了多层次交叉注意力模块在整个网络模型中的核心地位。
2.4.2 对比实验
为了评估模型的性能,本文列举了当下先进的5种研究情感分析模型与之进行对比。
Separate-Loss[22]:为了提高学习特征的判别能力,基于主干网络ResNet-18,使用随机梯度下降算法进行训练,提出了一种新的基本与复合面部表情识别的单独损失,利用Separate-Loss与Softmax Loss共同优化卷积神经网络模型,最终的特征具有类内紧密性与类间分离性的优点。
DDA-Loss[23]:考虑到最大化嵌入空间中的类内相似性和类间分离,基于随机梯度下降算法训练的主干网络ResNet-18,提出了一种新的判别分布不可知损失(discriminant distribution-agnostic loss,DDA)来优化极端类别不平衡场景的嵌入空间,任何卷积神经网络模型都可以使用 DDA 损失进行训练,以在嵌入空间中产生分离良好的深度特征簇。
DACL[24]:由于显著的类内变化和类间相似性,所以提出了一种深度注意力中心损失(deep attentive center loss,DACL)方法来自适应地选择重要特征元素的子集以增强辨别力,该方法采用ResNet-18作为主干网络,由注意力网络和稀疏中心损失组成的模块化DACL方法使用标准随机梯度下降算法进行训练,能迅速应用于任何最先进网络和深度度量学习方法。
IF-GAN[25]:由身份相关的面部属性(例如年龄、种族和性别)引起的高主体间差异问题,提出了一种新的无身份条件生成对抗网络(identity-free conditional generative adversarial network,IF-GAN)。该方法在ResNet-101主干网络上加入自注意力机制提取关键特征,是一个端到端的网络,能通过直接移动身份信息为无身份(facial expression recognition,FER)生成人脸图像。
EfficientFace[26]:考虑到大多数情绪以基本情绪的组合、混合或复合形式出现,引入了一种简单但有效的标签分布学习(label distribution learning,LDL)方法作为一种新颖的训练策略。该方法采用了由Conv1、Stage2、Stage3、Stage4和Conv5组成的最先进的轻量级ShuffleNet-V2作为主干网络,并设计了局部特征提取器和通道空间调制器,增强了模型鲁棒性,并显著提升了性能。
为了进行公平的比较,统一使用相同的数据集,都没有进行人工标注。最终对比结果如表6所示。
从表6给出的本文方法与另外5种情感分析方法的比较结果中,可以看出这些方法准确率都为85%~88%,而本文方法取得了最好的效果,其准确率达到了88.53%,比Separate-Loss方法提升了2.15%,比DDA-Loss方法提升了1.63%,比DACL方法提升了0.75%,比IF-GAN方法提升了0.2%,比EfficientFace模型提升了0.17%,验证了本文提出方法的优越性。

表6 各种网络模型方法性能对比Table 6 Performance comparison of various network model methods
3 结论
综合考虑图像整体和局部的关系,提出了一种多层交叉注意力融合网络模型分析方法,该方法主要由图像预处理模块、特征相关性分析模块、多层交叉注意力网络模块、注意力融合模块等组成。首先将图像预处理,然后利用特征相关性分析模块同时兼顾类内聚合与类间分离,从而实现了最大化类的可分性,再将多头的通道-空间注意力机制嵌入到每一层网络中,最后将提取的注意力图进行融合,从而使得提取的特征更加有效全面,最终在RAF-DB数据集上验证了本文提出的方法的有效性与优越性。在下一步的工作中,考虑针对样本不均衡问题设计出更合理的特征提取网络,通过深度学习的方法更精确地挖掘动态视觉图像中的整体和局部全方面的情感特征,以进一步提高视觉情感分析的效果。
