图像边缘检测综述
2023-03-13肖扬,周军
肖 扬,周 军
辽宁工业大学 电子与信息工程学院,辽宁 锦州 121000
自然图像中检测边缘与对象边界一直都是计算机视觉中的一项基本问题,边缘检测在一些视觉领域,如图像分割、物体检测/识别、跟踪和运动分析、医学成像、3D重建等传统任务,和现代应用自动驾驶中发挥着重要作用。多年来,许多研究者致力于提高边缘检测评估标准:单图最佳阈值(optimal image scale,OIS)、全局最佳阈值(optimal dataset scale,ODS)、平均准确率(average precision,AP)。随着神经网络的快速发展,边缘检测分化为两个阵营:传统检测方法和基于深度学习的检测方法。图1显示了两种方法执行边缘检测任务的一般流程。
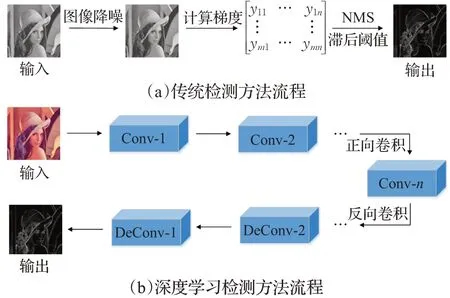
图1 两种方法的一般流程对比Fig.1 Comparison of general process of two methods
一些边缘检测[1]方法仅基于颜色、文本或其他低级特征来预测边界:(1)早期梯度算子方法,如一阶边缘检测算子Sobel算子[2]、Robert算子[3],二阶边缘检测算子Laplacian算子[4],还有工业界中常用的Canny算子[5]。(2)基于人工设计特征方法,如统计边缘[6]、概率边界(probability boundary,Pb)[7]、PMI(pointwise mutual information)[8],和结构化边缘检测算法,如SE(struc-tured forests edge detection)算法[9]等。传统的边缘检测方法提取边缘已经取得了相当大的进步,但是对噪声抑制、边缘定位和精细边缘的处理仍得不到改善。
随着近年硬件设备的更新,深度学习得到爆发式的发展,将卷积神经网络(convolutional neural network,CNN)能提取低级图像特征的优势运用在边缘检测中,使得边缘检测的效率和精度得到巨大提升,解决了传统检测方法遗留的一些问题。现如今,全监督学习是边缘检测任务的主流方法,但是该方法也存在需要使用大量数据集进行神经网络训练的弊端。值得庆幸的是,近年相继提出了一些新的数据集,如BSDS500[10]、NYUDv2[11]、PASCAL-VOC[12]。
传统方法需要手工设计梯度算子或人工设计特征送入分类器网络进行训练,复杂的数学推导和分步骤的训练方式极大限制其发展。直到Xie等[13]首次提出端到端网络架构——整体嵌套边缘检测(holistically-nested edge detection,HED),才解决了上述的问题。HED模型具有架构紧凑、性能好且效率高的优点。其缺点也显而易见,模型较为庞大,计算成本高导致GPU(graphics processing unit)占用资源过多。2021年,Su等[14]为了解决这些问题,将传统的边缘检测算子采用像素差分卷积(pixel difference convolution,PDC)的方式集成到现代CNN中,提出PidiNe(tpixel difference networks)模型。该网络使用大量可分离卷积、通道注意力和膨胀卷积,大大降低网络模型的复杂度,提高预测阶段的效率。在此期间,也出现了许多优秀的模型,如RDS(relaxed deep supervision)[15]、CED(crisp edge detector)[16]和DSCD(deep structural contour detection)[17]等,这些涉及的方法在后文中会详细介绍并分析其局限性。
目前边缘检测中有一些方法与前沿技术相结合,传统与深度学习的分类方法不足以归纳结合性质方法。由于前人的边缘检测综述没有对各类方法进行对比,仅仅将所使用方法进行罗列,读者理解边缘检测任务技术的整体趋势有一定困难。且近年来,也出现诸多新兴方法,这些方法前人的任务中也并未提及。本文以此为出发点,将多年来提出的边缘检测方法进行梳理,对其中主流以及前沿技术的方法进行介绍,分析算法的创新点和局限性。
1 边缘检测的概念
边缘检测是一个经典的计算机视觉问题,需要识别图像中的边缘以建立对象边界并分离感兴趣的目标。一张M×N的灰度图片表示为一个由二元函数组成的二维矩阵:
彩色图像中,每一个像素点又包含RGB三个通道,其强度范围都在0~255之间。把图像某一行中的所有像素绘制成三条曲线,可以得到由像素强度绘制的波形图,如图2所示。
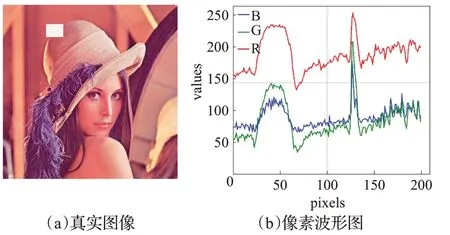
图2 数字图像与波形图Fig.2 Digital images and waveforms
图中曲线的波动幅度表示为颜色等特征的变化程度,采样区域变化剧烈(如pixels坐标130处,图2(a)中白色网格框所示)。这表明变化剧烈的波可能是包含边缘的区域,也进一步说明波和图像之间联系紧密,图像的本质就是各种色彩波的叠加。利用图像滤波器将低频过滤,保留变化剧烈的区域,即图像中的边缘。
边缘一般是指在像素强度局部剧烈变化的区域。其强度变化主要有两类:(1)阶跃变化,表示强度由暗到亮渐变的过程;(2)屋顶变化,表示由暗到亮,再由亮到暗的过程。
把边缘检测的目标总结为找到具有阶跃变化或屋顶变化像素点的集合。计算某像素点及其邻域的微分找到变化剧烈的像素点,对于具有阶跃变化的像素点,其一阶微分最大或二阶微分为0则为边缘点;具有屋顶变化的像素点,其一阶微分为0或二阶微分最大则为边缘点。继而引出传统边缘检测基于梯度(一阶与二阶微分)的方法,如Sobel[2]和Canny[5]等经典算法。
2 传统方法
将基于深度学习方法出现之前的所有边缘检测方法归类为传统方法,这些方法在本质上是利用基础或手工设计的特征训练分类器检测轮廓和边缘,如纹理、颜色、梯度和一些其他图像特征。边缘检测中常见的分类器有:线性分类器[18]以及支持向量机(support vector machine,SVM)[19]等。
2.1 基于梯度算子检测方法
2.1.1 梯度算子提取特征的原理
数学中,微分表示当自变量的变化足够小时,其函数值局部的变化。图像处理结合微分的思想,通过计算x和y两个方向的偏微分,可以得到(x,y)相邻像素点在水平与垂直方向的梯度。
公式(2)表明像素点的梯度就是相邻两像素的差,计算每个像素点的梯度,可以得到所有像素组成的梯度矩阵。上文提到图像边缘处的像素变化剧烈,所以计算得到的梯度值比非边缘的梯度值大。对梯度矩阵进行NMS处理后,保留梯度矩阵中大于预先设定阈值的梯度,即为边缘。该方法需要人工设定阈值,阈值的好坏直接影响最终的结果,具有不稳定性。
2.1.2 一阶梯度算子
Robert算子[3]首次使用2个2×2的方形算子计算图像x和y方向的梯度,将对角线相邻两像素之差近似梯度幅值检测边缘,该方法设计的卷积核为后来新的算子奠定了基础。
为了弥补上述方法对水平和斜方向检测边缘不足,Prewitt算子[20]将算子个数增加至4个,分别计算水平、垂直、斜方向的梯度。Sobel算子[2]结合高斯平滑抑制噪声,对图像灰度函数求近似梯度。高斯平滑对图像处理后降低了提取边缘的精度,Kirsch算子[21]类似Sobel算子,不同的是利用8个卷积核计算像素点8个方向的梯度幅值和方向,并取最大卷积值作为该点梯度。
2.1.3 二阶梯度算子
二阶梯度识别非线性强烈变化的灰度值,对边缘的定位更精确。当输入图片发生旋转时,通常一阶算子每次计算出的结果都不同,针对这个问题,Lecun等[4]提出具有旋转不变性的Laplacian算子。
虽然该方法解决了一阶算子中如何确定阈值的问题,但是不能克服噪声的干扰,Torre等[22]将Laplacian算子与高斯低通滤波相结合提出LOG(Laplacian of Gaussian)算子。该算子通过高斯滤波和Laplace算子处理,对输出进行插值估计。依据简化计算原则,可以使用DOG(difference of Gaussian)算子[23]近似替代LOG算子。
Canny等综合考虑上述算子的优缺点,总结出算子类方法的共性:(1)好的检测效果;(2)边缘定位准确;(3)同一边缘要有低的响应次数。结合这三个要求,继而提出的Canny算法成为最常用也是当时最优秀的算子检测方法。根据上文对算子类方法分析结果,在表1中从优势、机制和局限性对这些方法进行对比分析。
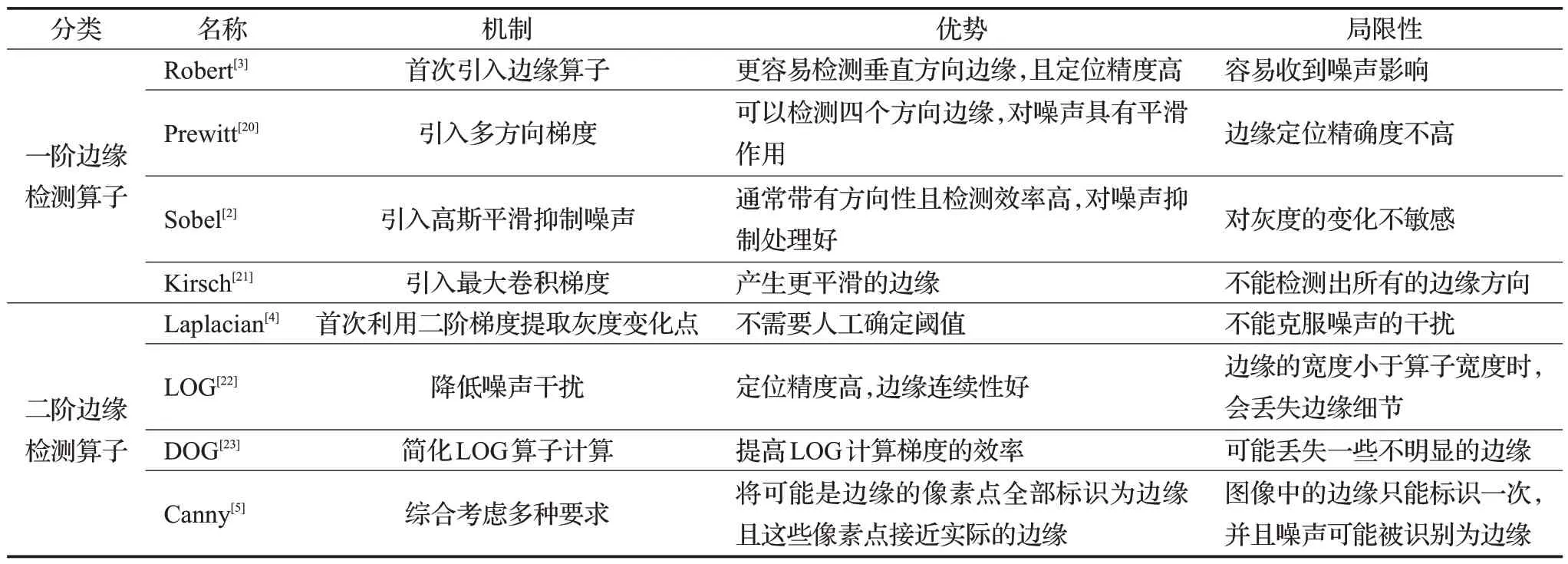
表1 算子类方法优缺点对比Table 1 Comparison of advantages and disadvantages of operator class methods
2.2 基于人工特征提取的边缘检测
2.2.1 基于局部特征
为了提高提取图像纹理、颜色的能力,继而提出人工特征提取的检测方法。通过结合像素之间的关系提取特征,并使用这些特征训练边缘分类器。
具有开创性研究的是Konishi等[6]提出使用统计和学习的方式,从预先分割的数据集(Sowerby和South Florida)中学习边缘滤波器的概率分布,并结合Chernoff信息[24]和ROC曲线(receiver operating characteristic curve)[25]评估边缘。
概率检测器Pb[7]将不连续特征与颜色和纹理梯度结合降低噪声对边缘检测的影响。Pb算法首次利用多特征梯度训练回归器。图3表示梯度波形图,图部分截取文献[7]。
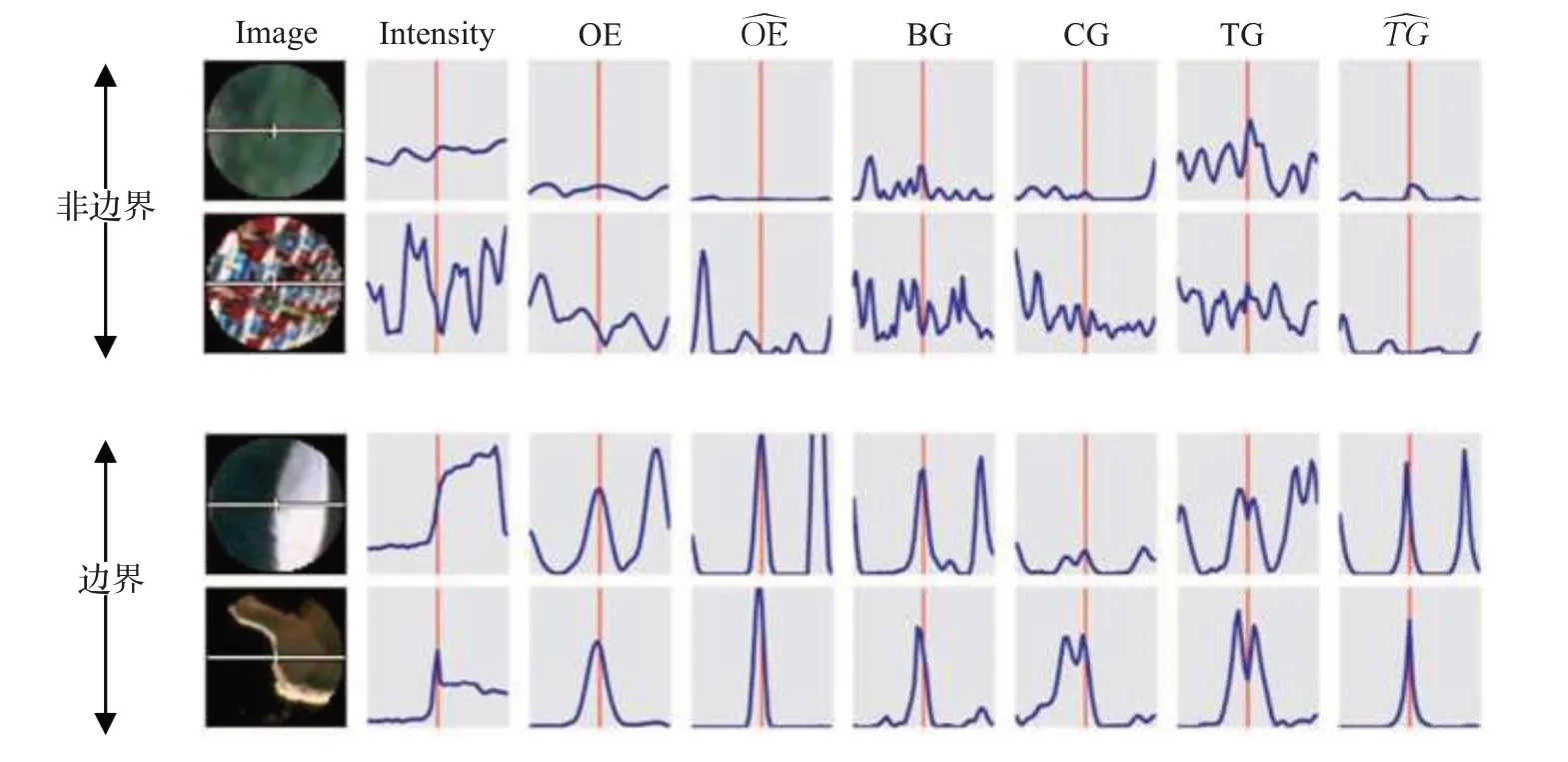
图3 边界与非边界的局部图像特征Fig.3 Boundary and non-boundary local image features
图中特征从左到右依次为:原始图像强度、定向能量OE、局部能量、亮度梯度、颜色梯度、原始纹理梯度和局部纹理梯度。
2.2.2 基于多级特征
Arbeláez等[26]将多尺度Pb算法(multiscale probability boundary,mPb)和sPb(spectral detector Pb)结合提出gPb(global Pb)算法。该算法结合亮度、颜色和纹理信号等局部信息与从图谱理论[27]获得的全局特征。实验结果表明,图谱理论获得全局信息可以减少生成边缘图的噪声和提高边缘图线条的流畅性。在此之后,他们又提出了分水岭变换(oriented watershed transform,OWT)算法[28],利用OWT构造超尺度轮廓图(ultrametric contour map,UCM)[28],最后他们将这些方法整合成著名的gPb-owt-ucm方法[10]。一个突出的贡献是,他们将BSDS300数据集[29]扩展为BSDS500[10]。实验表明,此方法在数据集BSDS500上的ODS为0.71。
Isola等[8]首次将相邻像素之间的PMI[30]引入边缘提取中提出无监督学习方法,减少特征工程处理。
2.2.3 基于图像块方法
在计算机视觉中,中级特征介于基础特征与高级特征(如对象信息)之间,提取中级特征的方法有手工设计[31-32]、监督学习[33-34]或无监督学习[35]等。为了弥补利用像素级特征提取边缘性能的不足,一些基于学习的方法提出利用图像块来提取局部边缘的中级特征。
2012年,Ren等[36]通过计算稀疏编码梯度(SCG)以此来提高轮廓检测精度。该方法在BSDS5000数据集上ODS为0.74。
Dollár等[9]提出结构化森林(SE)方法,通过将结构化标签映射到离散空间构建决策树。结果表明,SE能够以30 Hz的帧速率运行,并且在BSDS500[10]和NYUDv2[11]数据集上达到了最先进的结果。
Zhang等[37]首次提出基于结构化随机森林(SRF)的半监督学习(semi-supervised learning,SSL)学习方法。该方法通过无监督方式捕获图像块的固有特征,其优势在于仅使用少量图片标注即可获得较好的性能。
2.2.4 总结
人工特征的边缘检测发展趋势是由单一特征变化为多特征联合的过程:(1)手工设计特征方法对图像梯度作概率统计,并训练分类器;(2)后来的方法利用图谱理论获得全局特征,融合这些特征进行边缘提取;(3)最后发展为捕获图像块的中级特征,使用随机森林分类器进行边缘检测。传统方法逐渐由像素特征过渡到中级特征。
这类方法与利用梯度特征算子类方法相比已经取得非常不错的效果,优势在于人工设计多特征,提高特征利用率与分类精确率。但是仍存在一些问题:方法复杂、计算量大、无法实时检测。小型训练模型具有规模小和效率高等优点,若将特征分布移植到小型模型无疑会破坏固有结构,降低其性能;大型模型如多通道注意力机制与transformer等模型特征利用率高,能有效学习特征分布并增强特征,可移植性高。在表2中,对该类方法的优势、机制和局限性进行对比分析,并列出方法在BSDS500上的分数。
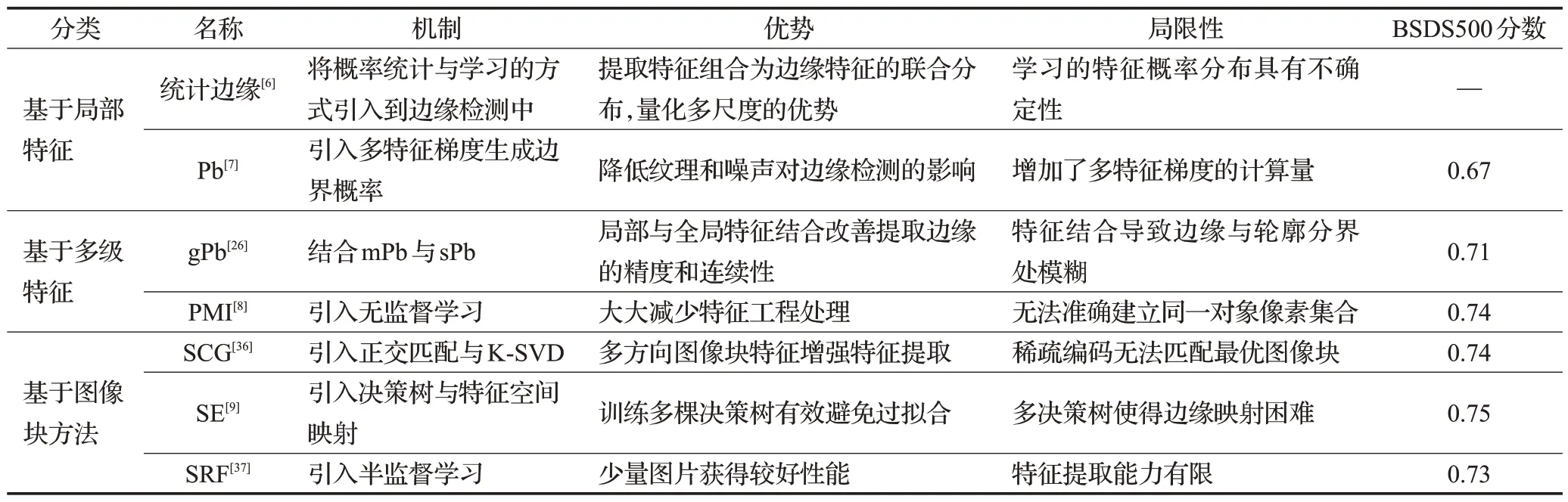
表2 人工特征提取的边缘检测方法对比Table 2 Comparison of edge detection methods with manual feature extraction
3 深度学习方法
归因于卷积神经网络对提取图像特征的优秀能力,深度学习方法在图像处理领域取得了非凡的成就。深度学习的方法是边缘检测任务发展的分水岭,解决了传统方法的诸多问题,如连续性、抗噪声能力,其方法不需要人工设计特征,所有特征均是神经网络自动提取,方法简单有效,进一步提高边缘检测的效率。为了让文章的结构层次更简洁清晰,将基于深度学习的方法分为非端到端与端到端方法,在本章最后会对两类方法进行分析对比。
3.1 非端到端方法
3.1.1 图像块算法
SE[9]是一种学习局部图像块中边缘的算法,Ganin和Lempitsky受到SE的启发,提出N4-Fields算法[38]。该算法将图像块特征与最近邻搜索(nearest neighbor search,NNS)结合,利用NNS对特征向量分类,获得相似轮廓。
Shen等[39]提出了DeepContour算法,类似于Sketch-Tokens[40],将二元分类问题(轮廓与非轮廓)转换为多类问题(图像块属于某形状类或背景类)。优点是能可视化CNN学习的边缘形状,如图4所示。缺点是类别数量未知时,该如何设定类别数量。若类别过少,CNN提取形状类减少,导致识别边缘能力下降;若类别过多,CNN提取边缘能力虽然提升,却容易将非边缘判为边缘,造成误判。实验表明,将类别数量设定为50能取得最好结果,在BSDS500上的ODS为0.757,高于同比竞争方法。

图4 部分形状类的可视化Fig.4 Visualization of shape classes
另一个贡献是提出了正共享损失的概念,即正类(形状类)之间的误差可以忽略,只计算正类与负类(背景类)的误差;定义的损失函数为:
其中:
最终损失函数表示为:
后一项仅计算误判正负类损失,当λ很小时,上式趋近于SoftMax函数;当λ很大时,区分形状效果变弱,倾向于解决二元分类问题。
3.1.2 对象特征算法
Bertasius等发现以前的大多数工作都利用纹理或低级特征来检测轮廓,然后将其用作对象检测等高级任务;为了验证高级特征检测边缘的可能性,他们利用对象相关特征训练两种对象分类神经网络模型:KNet[41]、VGG16(visual geometry group 16)[42],相继提出Deep-Edge[43]、HFL[44]算法。在两种算法中都引入多尺度增加模型提取边缘的能力,并结合图像的局部和全局信息。结果表明,DeepEdge与HFL在BSDS500上的ODS分别为0.753、0.767。与KNet相比,预训练的VGG16提取对象特征与整合特征能力更优秀,原因在于VGG16以顺序的方式结合卷积块与池化层提取特征图不同尺寸特征,有效降低图像在提取特征过程中损失。
3.1.3 方法对比
与手工设计特征相比,N4-Fields利用CNN提取特征的精度更高,但利用最近邻搜索分类边缘大大降低了分类准确率;DeepContour将CNN模型提取的特征进行分类,与N4-Fields方法不同的是利用CNN处理每个图像块对其进行分类处理,分类准确率明显高于最近邻搜索。如何确定类别数量是该方法的关键因素。
DeepEdge与HFL方法的优势是利用对象与纹理特征结合预测。实验结果表明利用对象特征进行边界检测产生的感知信息边界优于同时期边界检测方法。该方法局限在于需要预先使用传统检测器获得对象信息。
非端到端方法由局部特征逐步发展为对象与纹理特征融合检测。优势是可以对提取到的特征可视化。分步执行使得模型整体分工明确且简单易懂;分步执行特征提取与分类的局限,给训练模型带来极大的不便,解决的方法是增加两者的耦合,缩短人工处理步骤,提高训练效率,可能是未来研究方向之一。
3.2 端到端方法
3.2.1 多尺度算法
最初CNN模型只能接受相同大小输入,特征图感受野固定。而多尺度算法能使模型获得不同大小的感受野,捕获不同尺度特征。最高层提取图像基础特征,随着特征图分辨率降低,特征图往往提取对象特征。各级特征的融合使得模型获得更丰富特征,能有效提高模型识别任务的精度。获得多尺度特征的方法有:(1)改变下采样步长;(2)池化层;(3)膨胀卷积等。
2015年,具有开创性方法的是Xie和Tu[13]首次提出端到端的神经网络模型HED。该模型结合多尺度学习丰富的层次特征,以图像到图像的方式训练和预测。根据其特点,后5年内出现了许多基于端到端和多尺度融合思想的网络模型,在这里对HED网络和损失函数进行介绍。HED架构,如图5所示。
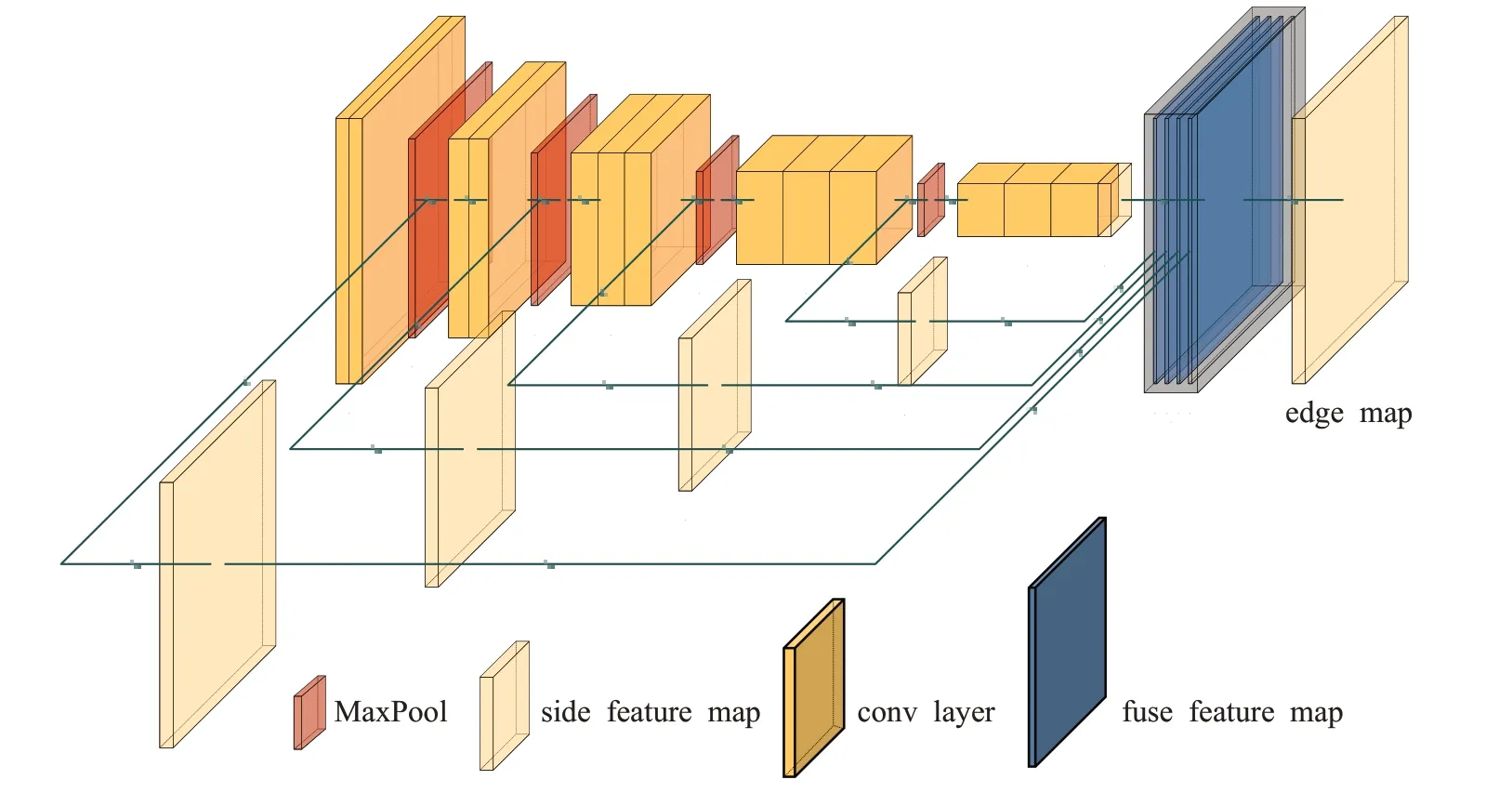
图5 HED网络结构图Fig.5 HED network structure diagram
HED使用VGG16作为主干提取图像特征,在每个卷积块经过池化(pooling layer)之前将结果执行上采样(upsampling)操作,将特征图的大小恢复成原始图像大小。其次介绍该算法的损失函数。整体的损失函数由两部分构成,第一部分为五个侧面损失;第二部分为融合损失。
作者发现在一幅图片中,90%的真实标注是非边缘,需要对交叉熵损失函数做特殊处理。引入类别平衡权重β自动平衡正/负类别损失。此方法确保数据平衡,减少对神经网络收敛的影响。侧输出层损失表示为:
其中,和w(m)分别表示第m个侧输出层的样本平衡交叉熵损失和权重。
为了直接利用融合输出预测,需定义融合损失,公式(6)表示计算人工标注Y与模型预测的损失。
最终损失函数表示为:
HED作为首个整体网络,多尺度和特征融合方法为其性能带来巨大提升,端到端模式也极大简化模型的训练和预测。局限性在于模型由上至下逐步提取特征,单向过程中,会造成特征损失,且上采样并未融合下采样特征,特征损失进一步扩大。由上至下、由下至上混合架构作为当前分割领域主流研究模型,在HED骨干模型上增加金字塔特征融合或由下至上传播路径,具有移植到语义分割领域的可行性。
Maninis等[45]利用图像多尺度信息,结合像素分类与轮廓方向,提出COB(convolutional oriented boundaries)算法。该算法网络模型主干使用最先进的50层ResNet(residual network)模型[46],模型利用细尺度响应基础特征,粗尺度提取对象轮廓并减少噪声。他们将真实标注的轮廓全部拟合为神经网络产生的K个方向边缘,与DeepContour一样,K值的好坏直接影响模型的性能。在BSDS500上的ODS为0.793。COB模型同时具有ResNet网络提取基础特征与识别边缘方向特征的优秀能力。但是模型提取细尺度和粗尺度两种特征图需要额外进行多次计算,大大增加了训练和预测时间。且方向边缘特征也需要额外的存储空间,虽然使用稀疏边界降低空间复杂度,但是数据在CPU与GPU之间的来回切换也会增加系统读写负担。K值设定与提取方向特征上的局限性导致COB无法轻易移植到别的领域中。
条件随机场(conditional random field,CRF)[47]是一种传统的分组模型,使用轮廓分段和条件随机场获得不同的连续性和频率。Xu等将注意力机制[48]与CRF结合成注意门控条件随机场(attention-gated CRFs,AG-CRF)[49],重新融合从CNN网络中提取多尺度特征图。实验表明AMH-Net(attention-guided multi-scale hierarchical DeepNet)算法中引入注意力机制是有效的,在BSDS500上的ODS为0.798。
边缘检测中用于监督学习的数据集通常需要2人以上标注,最终标注存在差异,对训练造成影响。Liu等[50]首先对标注进行处理:若没有任何标注该像素为边缘,将此像素点设置为0;全部标注该像素为边缘,则设置为1;否则对该像素点标注取平均值yi。像素边缘概率高于η为正样本,概率为0视为负样本,其余像素不计算损失。定义像素损失为:
公式(8)中,P(Xi;W)为模型对像素Xi的预测值,W表示模型参数;α、β表示类别平衡权重。
他们利用对象多尺度和多级信息,构成RCF(richer convolutional features)模型。在测试过程中引入图像金字塔增强,利用双线性插值还原特征图。实验结果表明,结合多尺度增强,RCF在BSDS500数据集上获得ODS为0.81。与HED算法[13]相比,RCF利用卷积层更丰富的特征训练;仅考虑多数标注标记为正样本的边缘像素,简化神经网络的训练难度,但也可能造成丢失关键边缘的问题。
语义分割和边缘检测两者关系密切,为了满足在边缘检测中获得语义类别信息的需求,Ma等首次提出一种边缘检测融合语义分割的模型,MSCN(multi-scale spatial context-based network)[51]。该端到端模型利用低级、中级和高级特征提取边缘、对象和分割信息。MSCN的提出,也进一步说明语义分割与边沿检测任务的可迁移性,两者中的方法互相迁移度高。
2021年,Xuan等[52]将RNN模型中LSTM模块移植到基于RCF的边缘检测中,提出FCL-Net(fine-scale corrective learning)。该模型利用BSDN中的SEM特征提取模块,并结合LSTM对多个特征进行融合,提高小目标识别率,是一种增强多尺度模型。实验结果表明,在BSDS500上的ODS为0.826。
为了弥补多尺度算法提取特征的不足,一些方法[53-61]也对侧面特征提取块进行创新。虽然多尺度算法提取特征能力较差,但是单向网络使得模型的流程更清晰,模型训练更快,在未来仍是热门研究方向之一。图6表示两种多尺度特征模型。
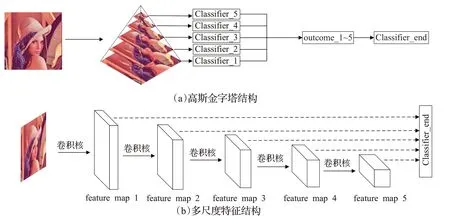
图6 多尺度分类器Fig.6 Multi-scale classifier
3.2.2 算子-卷积融合算法
Liu等[15]利用松弛深度监督(RDS)训练神经网络。这些松弛标签被看作是难以辨别的假正边界(即,标注中为非边缘,但算子检测器判别为边缘)。
其中,C(k)表示Canny算法对侧输出层的第k层执行检测操作得到的输出;G表示人工标注的真值;D(k)表示侧输出层的第k层的假正边界。
公式(9)表示Canny算子[5]误判为正类的像素集合。和经典算法HED[13]一样,RDS也需要计算侧边以及融合损失。实验结果表明,该算法取得了当时最优的性能。松弛标签的好坏完全取决于传统算子对边缘的提取能力,仍需要人工设定阈值,是该算法中的不稳定因素。
2021年,Su等[14]采用新颖的像素差分卷积(PDC),将传统边缘检测算子与现代CNN模型集成,并提出PidiNe(tpixel difference networks)算法。
PidiNet模型使用可分离深度卷积结构进行快速预测和训练。PidiNet结合PDC和简化的网络架构让模型变得非常紧凑,仅有710 000参数,支持实时预测。实验结果表明,该算法在BSDS500数据集上最优可取得215 FPS,并且达到HED相同ODS水平0.788。PidiNet中使用的分离式深度卷积结构可以降低模型参数规模,其思想可以移植到大型耦合度高的模型中。
3.2.3 双向连接算法
在此之前的所有深度学习方法虽然取得可观的ODS分数,但是输出的边缘都很模糊。首次获得突破的是2017年Wang等[16]提出的CED算法。他们总结前人的工作后发现可能是以下两点原因:(1)线性分类器在相邻像素产生类似响应;(2)上采样技术不能胜任生成精细边缘的任务。
CED使用自上而下的反向细化方法,采用亚像素卷积(sub-pixel convolutional,SPC)[62]生成清晰的边缘。该算法结合精细语义分割模型[63]和SPC,由前项传播产生高维低分辨率特征图;反向细化路径将逆向特征图与下采样输出融合,实验结果表明,CED在BSDS500数据集上取得ODS为0.80,达到人类相同水平。该方法在一定程度上弥补了使用上采样带来的不利影响,大大减少下采样不可逆的特征损失;反向路径中大量的边缘提取与特征融合无疑让模型更难训练。
He等[64]提出双向级联网络(BDCN)结构,通过计算双向特征图损失实现双向连接,根本上仍是单向模型。引入尺度增强模块(scale enhancement module,SEM),利用扩张卷积来生成多尺度特征。实验结果表明,结合图像多尺度融合,该算法在BSDS500数据集上取得最优ODS为0.828。BDCN的分层计算损失的设计让网络能学习到对应尺度的特征,且SEM避免图像金字塔的重复边缘检测。多损失的设计让其训练时,数据使用后不会立马释放空间,需要进行多次读写操作,大大降低GPU的利用率。
Deng等[65]考虑到基于深度卷积神经网络(deep convolutional neural network,DCNN)的边缘检测方法预测的边缘图边缘厚且需要执行后处理才能获得清晰边界,他们采用自下而上/自上而下的架构来处理任务,LPCB(learning to predict crisp boundaries)算法实验结果表明,在BSDS500数据集上获得ODS为0.815。
HED算法已经表明,使用预训练分类网络的特征来捕获所需的图像边界并抑制不存在的边缘是有益的。Kelm等[66]结合ResNet[46]和语义分割方法(RefineNet[67])提出RCN(refine contour net)算法。RCN引入三种不同的卷积块:(1)多分辨率融合(multi-resolution fusion,MRF)。(2)残差卷积单元(residual convolution unit,RCU)。(3)链式残差池(chained residual pooling,CRP)。实验结果表明,在BSDS500数据集上获得ODS为0.823。图7表示三种卷积增强块。其功能分别为:调整和修改MRF的输入、融合上采样与特征图、获得更丰富的上下文信息。
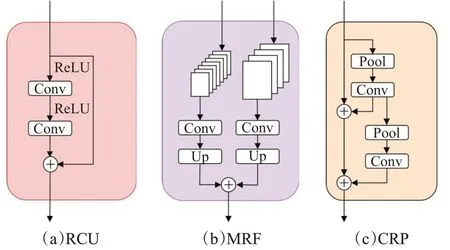
图7 细化过程操作块Fig.7 Block diagrams of refinement path operations
Soria等[68]认为边缘检测中应该考虑边缘的完整性,但是以前的工作忽略了图像的薄弱边缘。他们基于HED[13]和Xception模型[69],提出DexiNe(tdense extreme inception network)算法。在他们提出的数据集(BIPED)中,仔细标注了可能存在的边缘。使用该数据集训练可以生成人眼看到的不明显薄弱边缘。模型引入上采样(upsampling)块使得各输出层能产生精细边缘。
多尺度算法与相比双向连接算法中,前者采用由上至下融合多尺度方法,该方法的卷积块都存在侧面特征提取块;没有额外增加反向融合特征,因此多尺度算法的训练和预测效率要明显高于双向级联算法。DexiNet的密集设计结构使得模型提取精细边缘的能力比其他双向连接算法更强,虽然在BSDS500上ODS仅为0.729,但是在BIPED中ODS为0.859,远高于人类水平0.8。双向连接算法由于增加由下至上反向融合特征模块,模型能提取更丰富特征。但同时模型参数量几乎增加一倍,不易训练模型。BDPN(bi-directional pyramid network)[70]引入一种反向金字塔特征融合结构,一定程度上减少了模型所需参数量。也包括一些方法[71-72]引入更复杂的特征融合模块,舍弃效率而追求更高的ODS分数。虽然双向模型预测效率较低,但是精度更高,未来轻量级双向模型也可能是热点研究方向之一。
3.2.4 编码器-解码器算法
Deng等[17]提出新型卷积编码器-解码器网络(DSCD)。该网络逐步与低级特征融合;其次提出新型损失函数,解决生成边缘定位和清晰度问题。
利用公式(10)可以计算两个映射的相似度,其中μx、μy和σx、σy分别是预测边缘图x和真实标注边缘图y的平均值和标准方差。DSCD采用密集连接网络(DenseNet[73])来增强分层特征之间的连接;实验结果表明,结合多数集训练后,在BSDS500数据集上获得ODS为0.822,明显高于人类水平0.8。
编码器-解码器方法最早被应用于语义分割领域,U-Net[74]是其经典算法之一。DSCD优势在于提出新衡量相似度损失函数,模型仅需计算最终输出与真值的损失,一定程度上减少工程训练时间。
因为编-解码器模型存在跳跃连接层,不会因为上采样而导致特征损失,但是进行下采样时,特征可能会因为多卷积而丢失。REDN(recursive encoder-decoder network)[75]通过对下采样增加密集连接层从而降低下采样特征损失,但模型存在难以收敛的问题。编-解码器的固定设计结构也极大限制其移植可能性。
3.2.5 新兴方法
近年的边缘检测任务大多为多尺度模型,以单向特征传递为主,通过加强特征融合达到增强模型提取能力。除了多尺度与双向连接模型以外,近年也出现一些新兴方法,但所取得的评分标准与端到端模型相比仍有较大差距,还需进一步研究。
(1)低复杂度模型。将模型移植到移动或微型设备须同时考虑处理效率以及处理性能。LDC(lightweight dense CNN)[76]通过对低通道卷积之间引入密集连接增强特征利用。缺点是提取对象高级特征能力明显弱于多尺度模型。LRDNN(low-complexity residual deep neural network)[77]使用Fire模块代替常规卷积,实验结果表明,该模块充分提取特征,能提高对特征的利用率。虽然无法大规模降低参数量,但其性能与原模型基本保持不变。模型大小、效率以及系统资源调用仍需进一步优化。
(2)仿生模型。脉冲神经网络(pulse-coupled neural network,PCNN)[78]是一种基于猫视觉原理构建的简化神经网络模型,其特点是接收像素强度作为刺激并产生时间序列输出,符合人类视觉神经系统机制,该项技术研究较少,PCNN在图像处理领域仍处于发展阶段。BFCN(bio-inspired feature cascade network)[79]为了解决模型特征提取能力弱、边缘信息提取不足的问题,将视网膜的信息传递机制与边缘检测相结合,是一种利用仿生模型对特征提取增强的方法。实验结果表明,该方法能有效提高多尺度模型中单向特征提取能力,在BSDS500中ODS为0.822。
(3)对抗模型。ContourGAN[80]基于GAN(generative adversarial network)[81]的方法,利用编码器-解码器模型,用生成器提取图像轮廓,鉴别器区分真实标注和提取的图像轮廓。Art2Contour[82]也基于GAN方法,引入多重回归损失的组合,学习显著性高轮廓。GAN模型目前在图像生成、图像修复等领域占据主流地位。边缘检测任务中仅有少量使用GAN模型的方法,但其性能与多尺度以及双向模型有较大差距,仍需进一步研究。
(4)Transformer。该模型于2017年提出,其本质是编-解码模型,在内部引入大量的自注意力机制,获得局部与全局特征,在自然语言处理中取代循环神经网络,成为主流模型。2022年,Pu等[83]首次将Transformer引入到边缘检测中提出ENTER模型,在BSDS500取得最高ODS为0.848,远高于各类检测方法。他们在第一阶段利用编-解码器提取全局特征;在第二阶段利用局部细化获得精细边缘。归因于Transformer的自注意力机制,在视觉领域已经取得了广泛的应用,并能在各个领域取得更高性能提升。在未来的研究中,基于Transformer自注意力机制的边缘检测模型是热门研究方向之一。
3.2.6 方法对比
将深度学习方法在边缘检测中取得优秀性能的原因归结为五点:(1)多尺度;(2)多层特征融合;(3)上采样;(4)精心设计的损失函数;(5)使用大量数据集训练。
DCNN在图像特征提取中极具优势,与传统边缘检测方法相比,基于深度学习方法不仅可以提取基础特征,还包括对象特征,在图像中表现为纹理、颜色以及对象轮廓等。非端到端模型是边缘检测任务引入深度学习的开端,提高特征检测的同时,也存在特征利用率不足与步骤繁琐的问题。端到端模型以图像到图像的模式训练,图像特征均是由模型自训练提取,避免人为因素对模型训练产生影响。
深度学习作为目前边缘检测的主流方法,取得优秀性能的同时,也伴随一些新的问题:(1)神经网络结构越发复杂;(2)训练成本更高,时间更长;(3)更依赖数据集的数量和质量;(4)神经网络的不可解释性。图8表示模型使用方法对比。
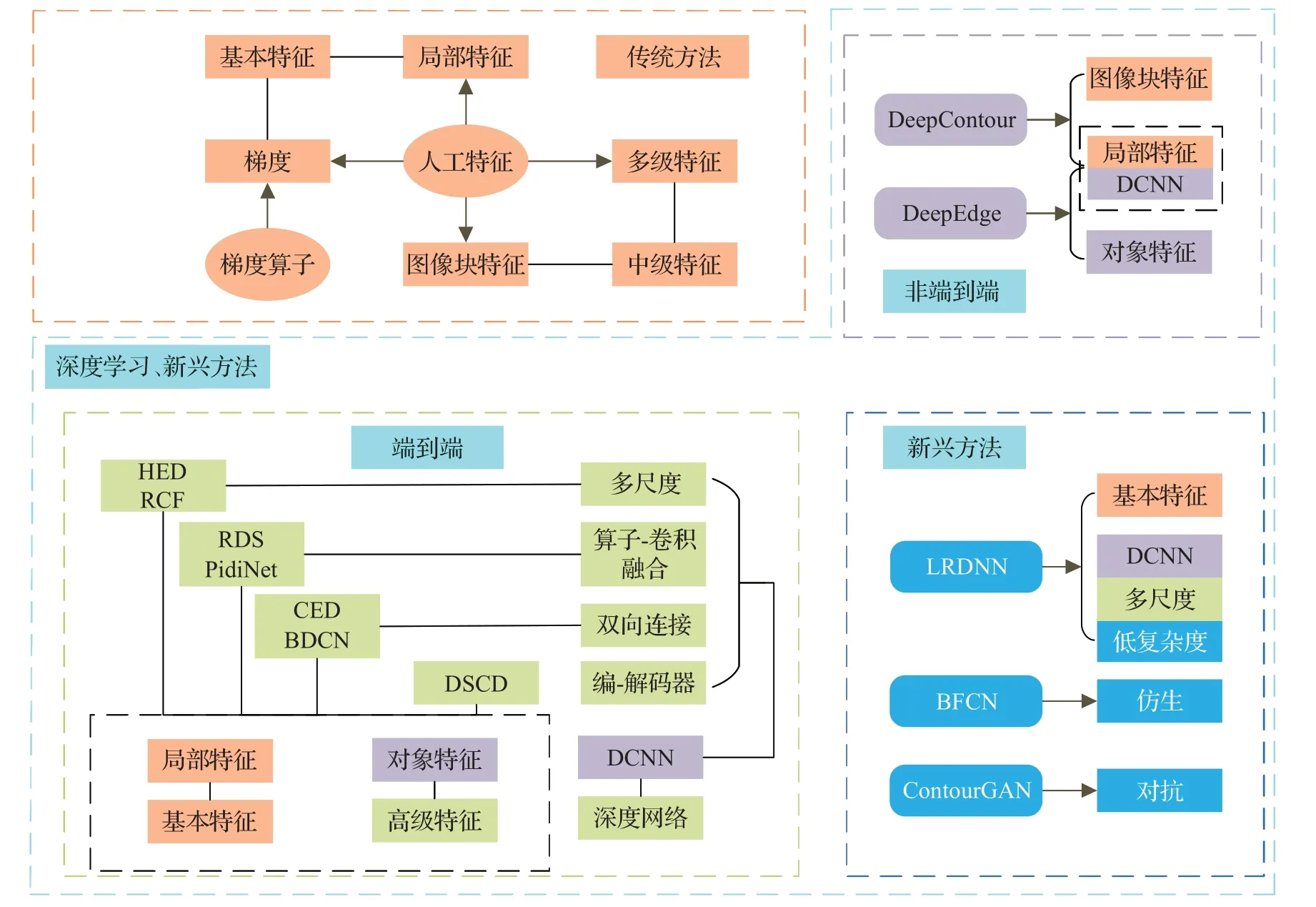
图8 模型所使用方法的联系与区别Fig.8 Connection and difference of methods used in model
在表3中,对深度学习方法的优势、机制和局限性进行分析,并列出在BSDS500上的ODS。
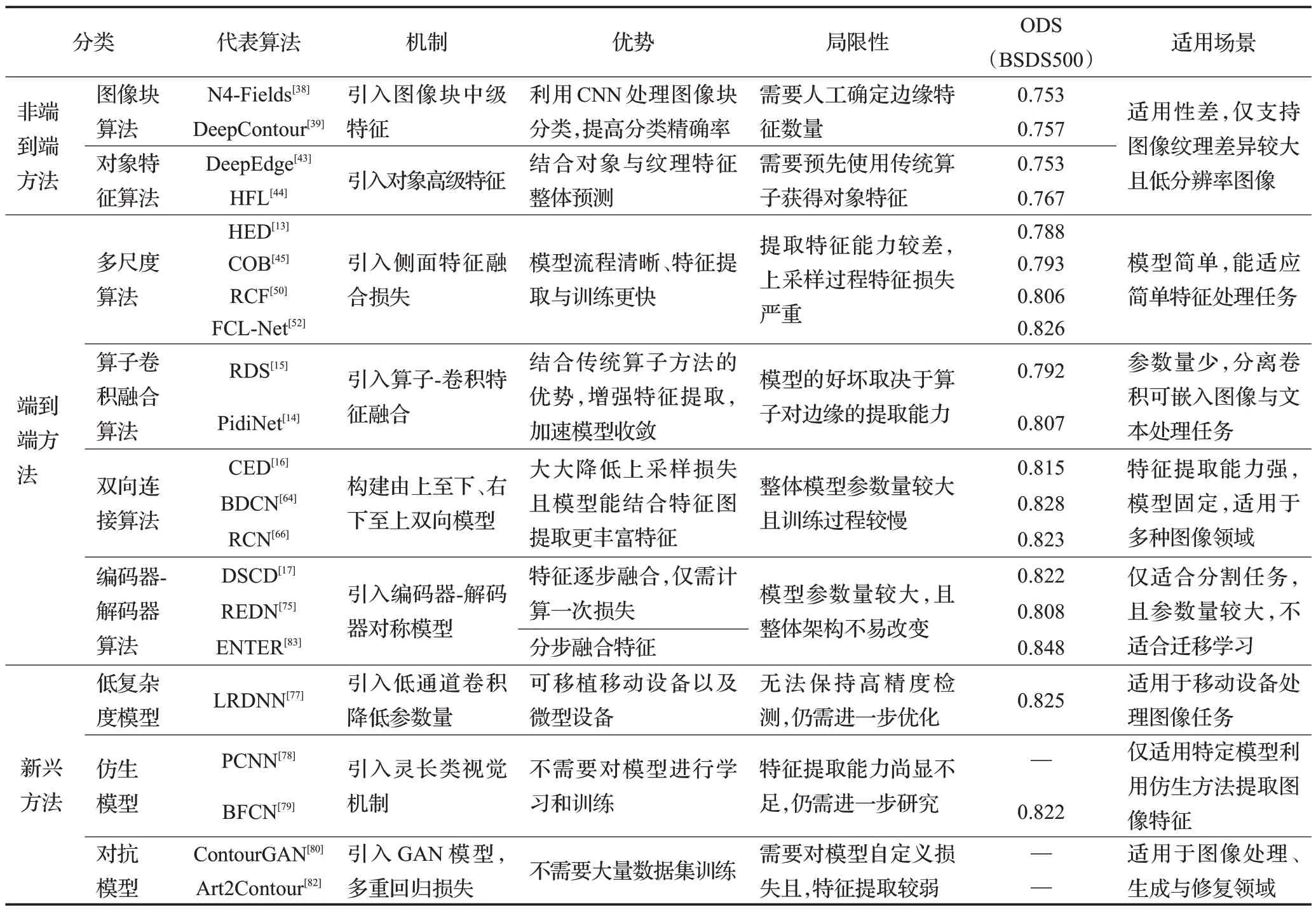
表3 深度学习的边缘检测方法对比Table 3 Comparison of edge detection methods for deep learning
在表4中,为了更直观评估其算法性能,列出一些方法在NYUDv2数据集[11]上的ODS以及模型的参数数量,最后一列表示在BSDS500数据集上的FPS。从表中可以看出,ENTER模型取得对比方法最优ODS,满足工业领域中对边缘精度较高的需求;LRDNN模型取得最优FPS,满足在移动端或边缘计算中对小体量模型的需求。

表4 深度学习方法性能定量对比Table 4 Quantitative comparison of performance of deep learning methods
4 数据集和评估标准
4.1 数据集
数据集一般分为图像和真实标注两部分,通常有2个及以上标注者对图像进行标注。真实标注为二值图像,即图像中的每一个像素都只有两种可能,通常由黑(0)白(255)来表示。边缘检测的结果通常是经过sigmoid函数处理后输出每个像素点为边缘的概率。
数据集分为人工标注和机器生成两种,人工标注的优点是精度高,缺点是耗费人力、时间等资源,大多数据集都是采用这种方式,如BSDS500[10]与PASCAL[84]等。机器生成的数据集一般是指在网络训练过程中输出的结果,对结果处理后,重新输入网络训练。此方式具有不稳定因素,优点提高数据集利用率。在RDS[15]中就采用Canny算子对模型输出进行采样,再将采样结果输入网络中增强训练。
有监督学习任务中,数据集在其中扮演着重要角色。通常,监督学习需要使用数据集训练神经网络使其趋向于收敛。边缘检测任务数据集具有两个重要作用:(1)训练神经网络模型;(2)评估网络模型生成边缘图。边缘检测数据集大多为中小型数据集,是因为复杂的标注流程耗费大量人力和物力,限制数据集发展。在BSDS500中,训练使用图片仅有200张,为了降低数据集数量给模型训练带来的不利影响,在训练过程中可以使用数据增强(旋转、镜像和剪切等)扩大数据集规模,还能有效避免模型过拟合。表5列举出边缘检测常用数据集。
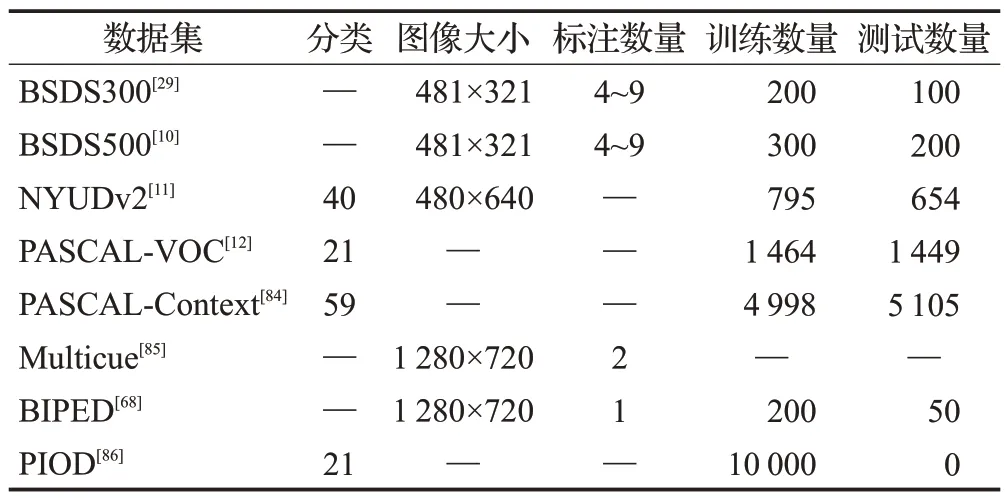
表5 边缘检测数据集Table 5 Edge detection dataset
BSDS300[29]与BSDS500[10]:Martin等使用300张规格为481×321的图像进行边缘标注。每张图片都至少有4人标注,超过第5人标注时,就会出现图片标注不全的问题。300张图片中,使用200张图片用作训练,100张用作测试。Arbeláez等在BSDS300数据集的基础上,将测试数据扩大至200张,新增100张图片用作验证数据集。
NYUDv2[11]:该数据集由1 449张室内场景图片组成,原始数据包括894个类别,用于训练语义分割任务时,可将其转化为40个类别。其中795张图片用于训练,654张图片进行测试。
PASCAL-VOC[12]:数据集包含20个对象类别,每张图像都有分割注释、边界注释以及对象注释。共2 913张图片,1 464张用于训练,1 449张用于验证。
PASCAL-Context[84]:包含10 103张图像,共459个标注类别,常用类别仅为59类。其中4 998用于训练集,5 105用于测试集。使用该数据集训练时,可以利用数据增强扩大数据规模。
Multicue[85]:和其他数据集不同的是,该数据集是由相机构建的短双目视频序列组成的视频数据集。双目视频序列是指,两个不同位置摄像机同时拍摄同一场景获得的图像序列,在序列中包括灰度、纹理、颜色等信息。数据集中每帧分辨率为1 280×720像素。
BIPED[68]:包含250张1 280×720像素的图片,200张用于训练,50张用于测试。在该论文中,作者表明,此数据集的标注结果经过多次交叉检查,筛选并纠正其中错误的标注边缘。
PIOD[86]:Wang等将PASCAL VOC数据集构建为大规模实例遮挡边界数据集,使用10 000张图片用于训练,使用BSDS500测试数据集用于测试。
4.2 评估标准
最初的边缘检测结果评测都是仅凭主观意识。随着技术的发展,出现一些的新的评估指标:(1)精确率(Precision),表示生成的边界像素是真实边界像素的概率;(2)召回率(Recall),测得真实边界像素占所有真实边界像素的概率;(3)F1-Score(F1值),综合Precision与Recall的结果,输出1表示模型结果最好,0表示模型结果最差;(4)平均精度(average precision),计算方式为P-R曲线下方的面积,范围在0~1,值越大,则模型越好。精确率和召回率定义为:
其中,TP表示被模型预测为正类的正样本;FP表示被模型预测为正类的负样本;FN表示被模型预测为负类的正样本。F1值定义为:
常用的F1值有两种:(1)全局最优规模(ODS),整体数据达到最优时,F1值的平均值即为ODS;(2)图像最佳规模(OIS),数据每张图片最优时,F1值的平均值即为OIS。
训练完模型后,将测试得到的图片进行最终评估,会获得该模型测试结果的ODS、OIS、AP以及生成的P-R曲线图。图9表示模型在BSDS500数据集上的性能。从中可以发现,近年深度学习模型的优势更加明显,未来的研究方向明显更偏向于深度学习方法。图中某些方法实现不同,可能与原方法结果存在误差。
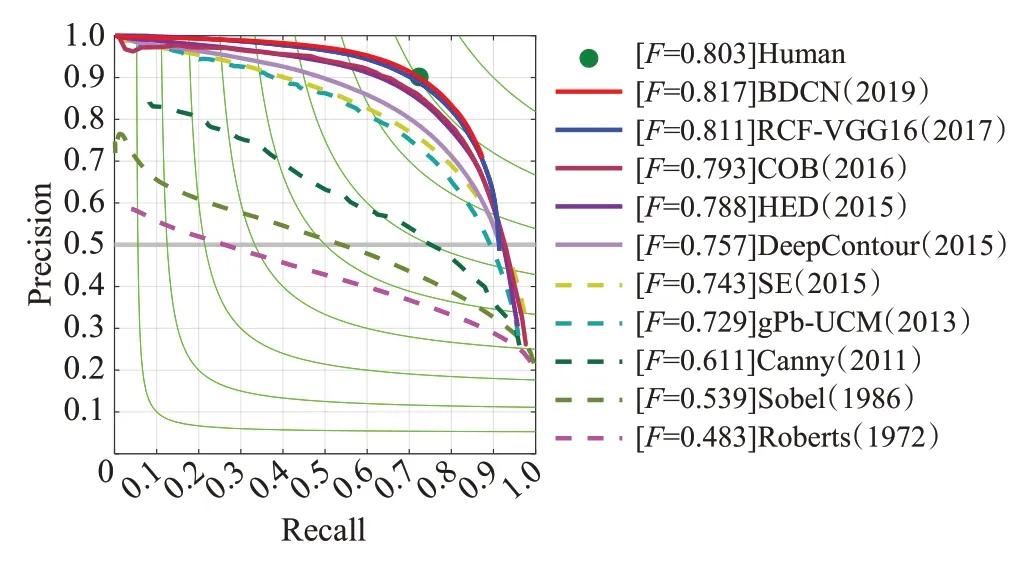
图9 PR曲线Fig.9 Precision-Recall curve
5 总结与展望
边缘检测经过40多年的发展,诞生了许多有代表性的方法,如Canny算子[5]、HED[13]网络架构等。尤其是近年提出的一些方法,如BDCN[64]在BSDS500数据集中取得ODS分数0.828,远超人类视觉水平ODS分数0.8;PiDiNet[14]不仅达到人类视觉水平,还拥有150 FPS,支持实时预测。本文分析模型在BSDS500数据集取得ODS分数,深度学习模型凭借优秀的特征提取和融合特征能力往往能取得比传统方法更优秀的性能,未来的发展中,深度学习仍然会占据边缘检测任务主流地位。
本文对历年出现的大多数方法进行分类、介绍和总结,并且对一些经典算法进行研究,分析这些方法的优缺点和局限性。对目前仍存在的一些问题进行分析并提出一些有前景的方向,相信本文提出的建议能够对以后边缘检测的发展起到促进作用。
(1)弱监督、无监督学习。虽然目前深度学习中全监督学习占据主流地位,但是弱监督、无监督学习方法也是研究的热门方向。目前已经有一些方法[81-82]用于边缘检测,这是值得肯定的。弱监督、无监督能大大减轻人工标注的压力,从而降低研究成本。这些方法的研究非常有意义,值得付出更多的精力去探索。
(2)多线索、上下文语义信息、反向传播和多特征融合。上下文语义信息在语义分割任务中得到广泛的使用,提高了语义分割的各项性能指标;在图像的亮度、颜色、梯度、纹理和对象特征中包含大量的边缘信息,提取更全面的基础特征能提高边缘的检测精度;反向传播是边缘检测技术必不可少的一环,可以通过设计更好的上采样方法,不仅能减少生成边缘的损失,还可以提升最终边缘图的清晰度;特征融合已经被证明在边缘检测任务中是有利的,结合多尺度、图像金字塔结构获得更多特征并融合特征增强网络提取边缘的能力。使用Transformer[87]提取全局与局部上下文信息和特征融合技术未来仍然是热门方法,如ENTER[83]。
(3)图谱理论与图神经网络。传统的边缘检测方法引入图谱理论[27]将图信号变换的变换为拉普拉斯矩阵,获得全局特征,减少噪声的影响并且提高了提取边缘的流畅性。在图神经网络[88]中对拉普拉斯矩阵进行特征分解得到对应的特征值,特征值的大小表示图信号的频率。传统边缘检测中,利用算子检测邻近像素差异,表示为梯度变化。图神经网络节点表示该节点受周围邻居节点的影响,结合信号域变换构建滤波器可以实现图卷积操作。认为图神经网络结合多种方式应用到边缘检测中:①利用图卷积网络代替传统算子提取梯度特征;②利用节点信息表示相邻像素的相似性,引入图注意力网络赋予重要节点更大权重。
(4)语义分割和对象特征。图像分割的任务是将图像划分成若干个互不相交的小区域的过程,边缘检测的任务是将亮度变化明显的像素点识别为边缘。这些不相交的边缘在图像中表示不同对象的分界线,其像素差异变化明显,两者关系密切。一些方法通过预先训练图像分割训练集初始化参数,获得一些轮廓特征,提高模型收敛速度和提取边缘性能。也有一些方法通过使用对象分类模型,获得对象特征提高检测边缘能力。将语义分割与目标检测模型结合应用到边缘检测任务中,仍是值得研究的方向之一。
