基于联邦学习的电子商务企业物流服务商选择研究
2023-03-12王志惠傅德谦临沂大学信息科学与工程学院山东临沂276000
王志惠,傅德谦(临沂大学 信息科学与工程学院,山东 临沂 276000)
0 引言
随着电子商务的蓬勃发展和物流服务商的逐年增多,电商平台对于物流服务商的选择也逐渐有了更高的要求。据中华人民共和国国家邮政局统计,2021 年,全国物流服务企业在中国交付累计完成量为1 083 亿件,同比增长了29.9%;交易规模达10 332.3 亿元,同比增长了17.5%;物流服务总体满意度为76.8 分[1]。对于物流服务商的选择,电商企业的诉求体现在成本低、货物安全、易追踪、速度快、服务质量高等方面;消费者希望速度快、服务好、货物无破损。若物流服务商选择不当,容易出现服务质量差、运输费用高、运输时间长等情况,影响消费者的购物体验和后续的购买行为,进而制约电商企业的发展[2-3]。随着订单量的逐年大幅增加,这些需求表现得更为迫切。信息系统的应用与普及可以极大节约电商企业与物流企业的信息共享成本,并有助于促进其合作关系[4]。各企业应充分利用大数据技术促进企业间的信息共享,进而提升物流服务质量和效率。然而由于现代社会更加重视个人、企业数据的隐私保护问题,国内外的数据监管法律也日趋严格[5]。例如2017 年6 月,中国提出的《中华人民共和国网络安全法》针对数据收集与处理提出约束和要求;美国在2020 年1 月正式生效的《加利福尼亚州消费者隐私法》(California Consumer Privacy Act,CCPA)[6]。针对此现象,宫晓曼[7]提出了一种在云计算环境中挖掘物流历史数据寻找最优物流服务商的方法;Cao K 等[8]将线下企业、电商平台与物流服务商考虑为一个市场,基于此开发NE、Y、YT 三个理论模型,通过模型指导企业确定最优物流服务商。在实际场景中,物流数据分散存储,具有隐私性强、多源异构、可用性低等特征。因此,联邦学习(Federated Learning,FL)是保护数据隐私的同时解决数据孤岛问题的有效方式[9]。联邦学习是谷歌实验室提出来的一种用于保护数据隐私的机器学习框架[10]。客户可以在本地训练模型,在不违反数据隐私的情况下根据本地模型更新共同训练一个全局模型[11-12]。在对数据隐私要求高且存在数据孤岛问题的物流服务商选择场景中,联邦学习有着天然的适配性。
综上所述,本文研究分布式环境下实现多源数据联合建模选取最优物流服务商的方法。本文主要工作如下:(1)构建物流服务商选择层次化架构,在保护数据隐私的前提下,实现联邦学习模型的应用;(2)针对物流数据差异化问题提出了一种训练数据标准化处理方法;(3)利用差分隐私算法改进Secureboost 算法,提高了模型训练效率;(4)采用生成模拟数据进行仿真实验,验证方法的安全性和可行性。
1 物流服务商选择层次化架构
为实现联合多方物流数据进行最优物流服务商的选择,本文设计了基于联邦学习的物流服务商选择层次化架构。如图1 所示,分别由数据准备层、样本数据对齐层、联邦学习训练层、模型应用层4 部分组成。
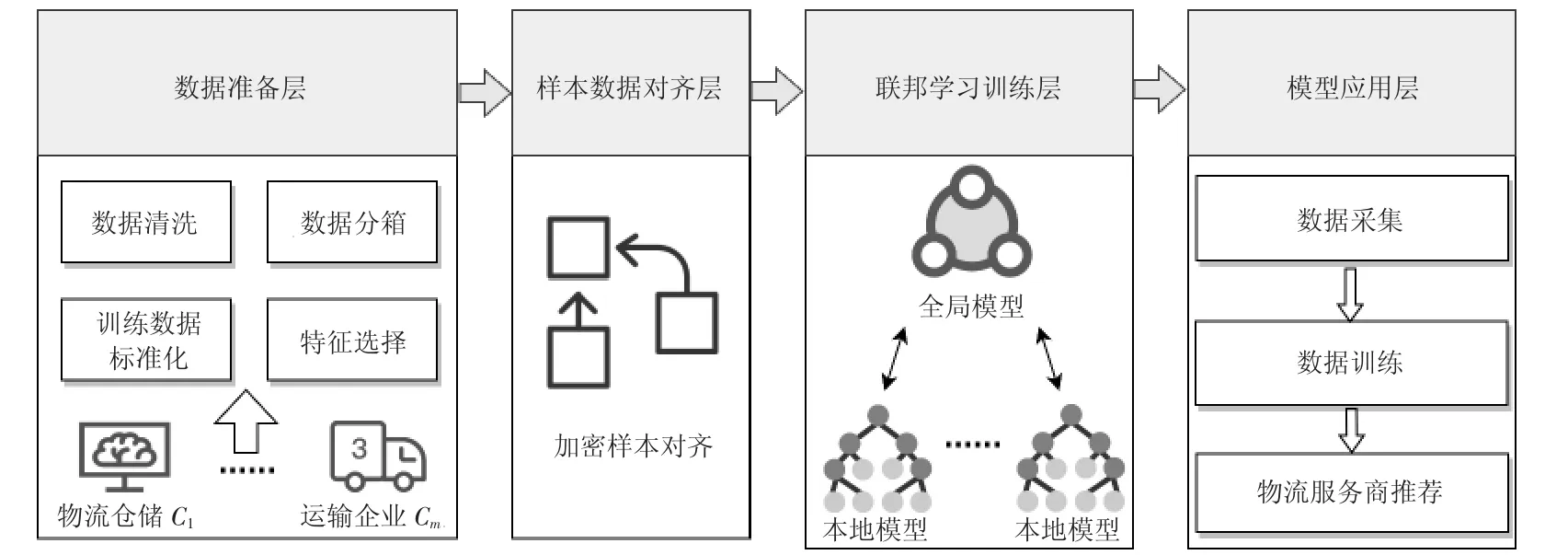
图1 物流服务商选择层次化架构
1.1 数据准备层
物流数据具有可用性低及标准化水平不高的特点,为提高物流数据质量和模型训练效率,数据准备层可以为模型提供高质量数据。因此,本文在数据准备层采用数据清洗、数据分箱、特征筛选、训练数据标准化等操作处理训练数据。本文参照相关文献,在前人研究的指标体系基础上从历史数据中筛选出具体指标数据用作样本数据。针对物流数据特征指标衡量单位和标准不同造成数据差异化大的问题,本文采用Simple Additive Weighting(SAW)方法根据参数的实际意义做训练数据标准化处理。其中,公式(1)对正向参数做标准化处理,公式(2)对反向参数做标准化处理。正向参数是指对用户来说越大越好的参数,比如破损赔付数额;反向参数则是指对用户来说越小越好的参数,比如首重与续重价格。其他参数则采用Z-score 标准化方法做训练数据标准化处理,采用把数据处理成符合标准正态分布的数据。其中是一列数据的均值,ρ是一列数据的标准差。
1.2 样本数据对齐层
物流场景中数据分布式存储,物流供应链包括电商企业、物流企业、仓储企业、运输企业等。样本数据对齐层可以在各参与方建模前使用加密技术根据ID 对齐各方样本数据,提取出共有ID 的训练样本数据。本文采用RSA 非对称加密算法和哈希机制的方案来对齐各方共有数据。
1.3 联邦学习训练层
在联邦学习训练层采用加密模型参数传输方式联合多方数据训练模型。本文采用安全联邦决策树模型训练出最优划分的决策树模型,构建物流服务商选择树。为保障用户隐私和数据安全,引入可信第三方(政府、可信第三方企业)利用隐私保护技术加解密并协调训练模型。
1.4 模型应用层
训练完成的模型可以通过封装接口用于电商企业的物流服务商选择应用中。模型应用层为电商企业提供模型应用接口,通过此层将符合用户选取指标要求的预测结果传到用户端,为电商企业提供最优物流服务商。
2 物流服务商选择模型与算法
2.1 模型整体架构
本文设定的选择模型整体架构如图2 所示,分别由m 个企业客户端和1 个中心服务器组成。其中,客户端由m 个物流供应链上的企业组成,各企业间具有大致相同的物流订单ID 索引。中心服务器是一个可信第三方(例如政府机构、安全数据共享机构)。为提高训练过程中的通信效率,本文对安全联邦决策树做了分析和改进,采用了差分隐私的思想加密传输聚合梯度值。在建模任务中,参与联合建模的企业方分为主动方和被动方。主动方提供的用户数据内包含标签值,其担任数据对齐的主要任务并主导服务器完成模型训练。被动方仅提供用户的样本数据,与主动方协作完成模型训练任务。完整训练流程如下。
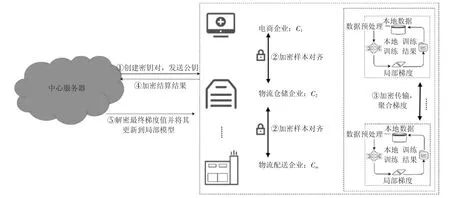
图2 模型的整体架构
步骤1:中心服务器生成密钥对,并将公钥发送至各企业。其中,公钥用于发送至各参与方加密传输梯度值,私钥用于解密接收到的密文。
步骤2:各企业以RSA 非对称加密算法和哈希机制的加密方案实现样本对齐,提取各企业共同物流订单ID 的样本数据。
步骤3:各企业使用对齐后的本地数据训练模型,以加密交换的方式计算各方本地模型的梯度与损失,实现模型的加密联合训练。
步骤4:各企业将本地模型的梯度值和损失加密发送至中心服务器。
步骤5:中心服务器将密文解密获得最终梯度信息,将梯度信息发送至各企业以更新本地模型参数。
2.2 物流服务商选择算法
对各企业数据集X={x1,x2,…,xn}使用K 个回归树进行决策树模型的训练。为防止模型出现过拟合,引入正则项来控制模型的复杂度。则设定最优决策树算法目标函数为损失函数与正则项之和,以最小化损失为模型训练目标。当目标函数训练到第t 轮时,前t-1 轮的模型结果和复杂度都已确定,则第t 轮的预测值可以表示为。可得第t 轮模型目标函数为:
此时由主动方计算出gi和hi,使用差分隐私的思想加密传输梯度信息到每个参与任务训练的被动方。本文设定目标函数的正则项函数为其中:O 表示复杂度参数、Ln表示树的叶子节点数、Lw表示叶子节点的权重值、w 表示惩罚度参数。将正则项函数带入目标函数为:
其中:O、Lw、gi、hi都为已知数,wj是未知数,Ij表示可落在相同叶子节点j 的样本空间。算法以此过程迭代出每棵决策树,完成决策树构建后,按照一元二次函数求最优解的过程,采用公式(6)计算叶子节点j 的最优权重w:
将最优权重wj代回目标函数可得:
决策树的划分优略是由划分增益Gain 得到的,单节点分裂过程计算公式如公式(8)所示:
设定样本空间I 每次划分为两个不相交的左右节点的样本空间IL和IR,即当前节点的样本空间表示为I=IL+IR。则构建最优决策树需要最大化节点分裂前后间的差值,可得最优划分为:
其中采用差分隐私的加密方式实现企业间模型梯度信息的加密与传输。主动方计算出gi和hi,将原梯度值与随机浮点数的乘积传输到被动方。最后解密时只需除以加密时的随机浮点数即可。同态加密方式密文为256 字节,加密过程和传输过程需要消耗大量的资源成本。相比同态加密,差分隐私采用的浮点数仅占8 字节,其计算和通信的效率有较大提升。
3 实验与分析
本文采用个人生成的模拟物流数据进行仿真实验,各物流供应链企业数据集指标详细信息如表1 所示:
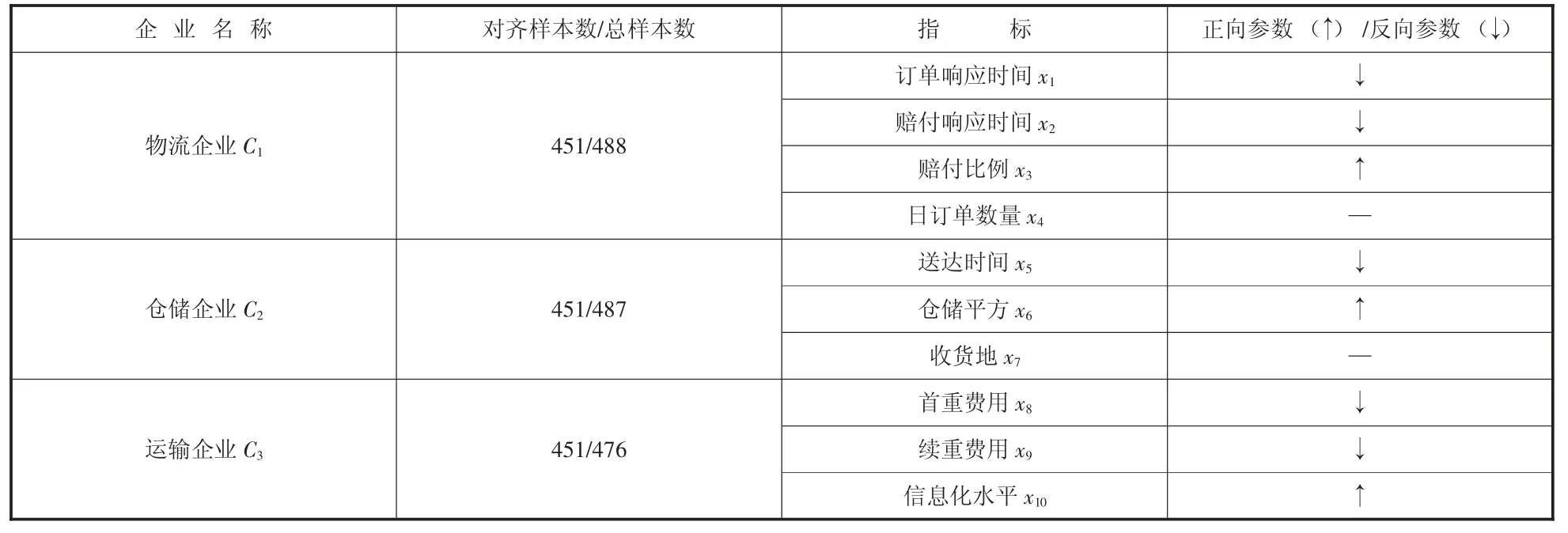
表1 物流供应链企业数据集指标
现假设某电商平台与多家物流企业具有合作关系,并且每家物流企业又与不同仓储企业和运输企业具有合作关系。各企业数据存储在本地且指标众多,为实现最优物流服务商选择模型的构建,筛选出各企业的关键指标。在对齐样本中随机抽选每个物流企业的各一条数据,如表2 所示:

表2 物流服务商历史数据
根据训练数据标准化处理的设定对历史数据进行标准化。标准化后的数据如表3 所示:

表3 标准化后的物流服务商历史数据
本文仿真实验设置由三个分布式数据源,分别是物流企业C1、仓储企业C2、运输企业C3,数据集详细情况如表1 所示。实验环境配置如下:系统使用CentOS 7.6.1810;CPU 为2 个4 核Intel(R)Core(TM)i5-9300HF CPU@2.40GHz;32G 内存;Python 版本3.8。实验参数设置学习率为0.1,树最大深度为10,最大桶数量为50,正则项系数为0.1。实验以AUC 值和KS 值作为模型评价指标,分别在训练集和验证集上做性能测试。实验以模型损失值和训练时间验证模型训练效率,采用差分隐私算法和同态加密算法对标准化处理后的数据进行模型训练。对每次实验分别进行5 次独立的重复实验取平均实验结果,仿真实验结果如图3 至图6 所示。
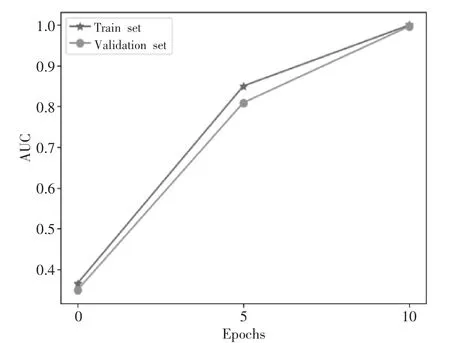
图3 模型AUC
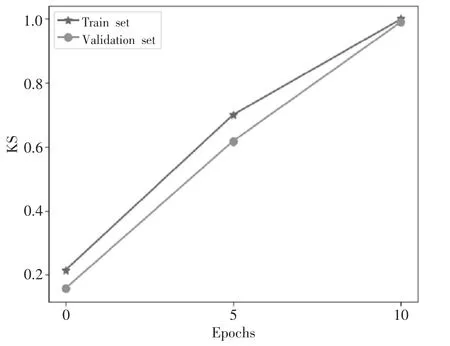
图4 模型KS
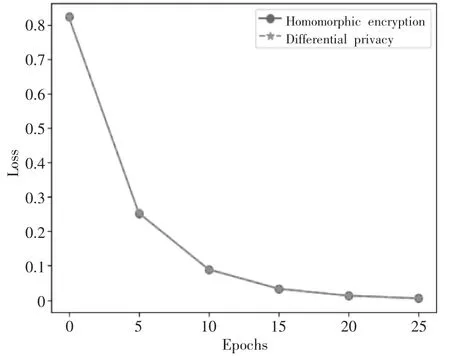
图5 模型损失
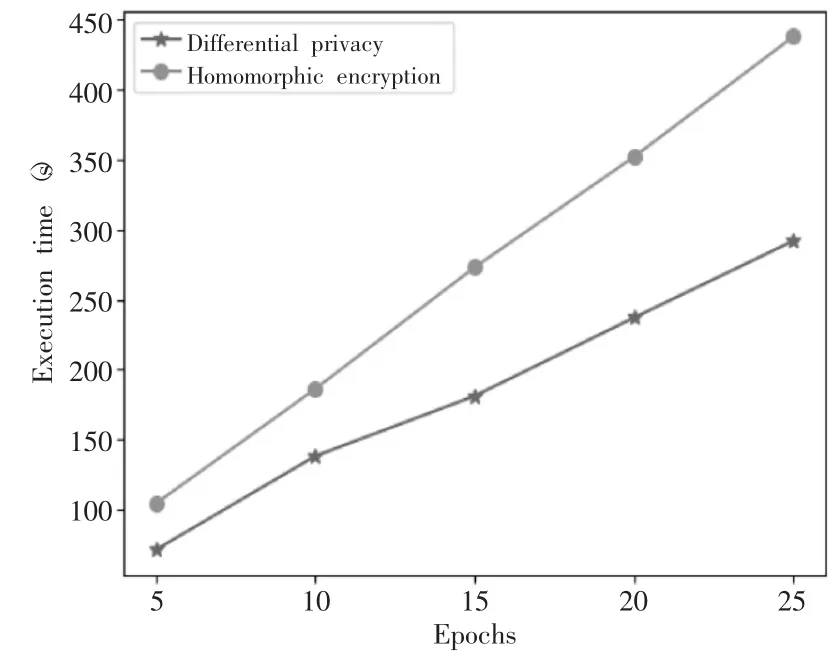
图6 模型训练时间
从实验结果可以看出,模型在迭代了10 轮次时,在数据集上的AUC 值和KS 值接近1,表明模型准确率较高,且具有较强的风险区分能力。同时,模型在经过25 轮迭代后,该算法总耗时292s,同态加密算法总体花费438s,模型训练效率可以提升50%左右。实验结果表明了该方法可以在保护数据隐私的前提下快速提供科学决策。
4 总结
在电商活动中,科学地选择合适的物流服务商具有重要意义。本文针对分布式环境中如何通过历史物流数据科学选取最优物流服务商的问题展开研究。本文构建了一种物流服务商选择层次化架构,该架构通过多环节实现模型应用,为解决数据差异化问题提出了一种训练数据标准化方法,同时引入差分隐私算法改进训练模型,提高了模型的训练效率。最后,通过模拟数据进行仿真实验,验证了该方法的安全性和可行性。在未来工作中考虑完善指标选择体系,为最优物流服务商的选择提供更科学的决策方案。
