基于光流计算与增强网络的颈椎CT 图像层间插值算法研究
2023-03-11吴晓红滕奇志
王 明,吴晓红,滕奇志,杨 毅,任 超*
(1.四川大学电子信息学院,成都 610065;2.四川大学华西医院骨科,成都 610041)
0 引言
人体颈椎CT 序列图像通过X 射线对人体颈椎作连续的断面扫描得到。通过观察患者的颈椎CT图像,医疗人员可以诊断出患者颈椎是否发生病变。但由于X 射线对人体组织有损伤[1],为节省拍摄时间,CT 图像的采样间隔较大,导致CT 图像的纵向点长度远大于片层内的横向点长度。因此,直接由人体颈椎CT 序列图像的横截面生成的矢状面和冠状面图像会产生明显变形(如图1 所示),与颈椎的真实情况不符。变形的矢状面和冠状面图像会对后续颈椎椎骨的终板形态分型研究带来影响。为解决此问题,一般先对人体颈椎CT 序列图像中相邻层的CT 图像进行层间插值,缩短CT 序列图像的纵向点长度,再生成矢状面和冠状面图像,其形态结构就会与颈椎真实情况相符,更有利于后续对人体颈椎模型进行分析。
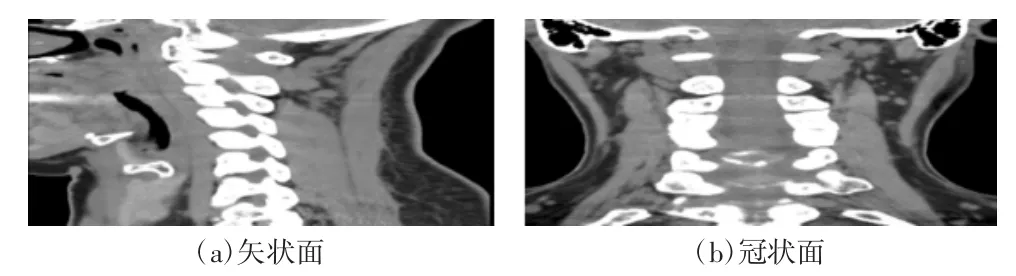
图1 原始颈椎CT 图像的矢状面和冠状面
基于配准的插值方法[2-4]在医学领域得到了广泛应用,这种插值方法先通过配准得到2 张CT 图像的形变场,由形变场进行拟合插值。张杰等[3]提出了基于曲面拟合与配准的插值算法,针对非刚性配准后的B 样条插值算法对异常点不敏感的问题,引进了薄板曲面拟合的方法,有效地去除了异常点的影响,并且更进一步利用双向形变场将2 个形变场融合后再结合样条插值与曲面拟合来得到插值图像。这种做法一定程度上提高了插值图像的精度,但是插值图像在细节的局部放大中仍然有毛刺、伪影现象。张耀等[4]利用非下采样轮廓波变换(nonsubsampled contourlet transform,NSCT)对图像进行分解,对NSCT 分解后的高频和低频子图分别采用不同插值算法生成新插值图像的高频和低频子图,再将二者逆NSCT 生成新插值图像。这种算法生成的图像仍然有模糊现象,并且由于迭代运算和非下采样技术,运算十分耗时,在速度上需要进一步优化。
基于光流信息配准后再进行插值的研究中,Ehrhardt 等[5]基于光流对序列图像插值,不仅提高了插值图像的精度还尽可能保留了目标原始结构,但是边缘轮廓依然不清晰。林毓秀等[6]先利用联合全局与局部(combined local and global,CLG)算法生成光流模型,通过此光流模型进行配准与生成插值图像,再利用序列图像的帧间非局部自相似性来解决插值后图像中的像素缺失问题,从而能够生成高质量的中间层图像。但是,当图像层间距较大时,GLG 算法生成的中间图像准确性不高。
视频插帧[7-13]和颈椎CT 图像层间插值具有一定的相似性,可以借鉴视频插帧算法完成CT 图像的层间插值任务。视频插帧算法是给定2 个连续帧生成中间帧,以形成空间和时间上一致的视频序列。文献[7]使用卷积神经网络(convolutional neural network,CNN)直接合成中间帧,由于网络没有学习相邻帧之间光学变化信息导致生成的图像十分模糊。文献[8]使用空间自适应卷积核来估计每个像素值,当卷积核变大时,运算成本很高。文献[9]先对相邻帧的光流进行估计,再对遮挡进行处理。文献[10]引入了上下文纹理特征进行帧插值,减少了插值图像的伪影现象。文献[11]综合了光流估计、深度图和上下文纹理特征对输入帧进行处理,有效增强了中间帧的质量。文献[12]提出了一种基于双边运动估计的视频插帧算法,首先使用近似双向运动网络来预测双边运动,然后利用2 个输入帧和双向运动生成中间帧,最后使用动态混合过滤器网络过滤中间帧来生成输出帧。文献[13]提出了自适应协作流网络(adaptive collaboration of flows,AdaCoF)来估计每个像素点的核权重和偏移向量以合成输出帧,其可以处理复杂的运动且能生成更真实的输出图像。
如果将视频插帧算法应用到层间插值任务上,还需要考虑CT 图像本身每一像素点的横向点长度和纵向点长度信息,不能在2 张CT 图像间任意插入图像。并且由于人体CT 图像采样间隔较大,CT 图像的变化比较剧烈,所以相邻上下层图像对中间层图像有更重要的参考性。
因此,为了解决人体颈椎CT 序列图像横向点长度和纵向点长度不匹配带来的矢状面和冠状面结构变形问题,本文基于残差密集网络和UNet 网络,针对人体颈椎CT 图像的特点制作专用数据集,通过CT图像双向光流计算与增强网络来进行人体颈椎CT图像的层间插值。
1 人体颈椎CT 图像层间插值算法
1.1 算法整体概述
CT 图像层间插值算法利用相邻的上下层图像之间的变化生成中间层图像,而视频插帧算法是在时间序列上的两帧之间根据前后帧图像之间的变化和时间信息生成中间帧,二者具有较强的相似性,因此,借鉴视频插帧算法[9],将相邻的3 张序列图像分为上层图像Iu,需要插值生成的中间层图像Im和下层图像Id。先计算Iu和Id之间的双向光流Fu→d、Fd→u,由此双向光流通过公式(1)和公式(2)计算出Im到Iu的近似光流以及Im到Id的近似光流Fˆm→d:
式中,t=0.5,表示Im到Iu以及Im到Id的光流应为Iu和Id之间光流的一半。
式中,g(·,·)根据光流和光流的一端图像进行双线性插值反向生成光流另一端图像;参数a 的值取决于两边图像对中间图像的贡献。根据光流信息,部分像素块可能在另一边图像上消失或者存在灰度变化,因此本研究引入可视图Vm←u和Vm←d表示像素块从图像Iu到Id的灰度变化。由此公式(3)可以转换为公式(4):
1.2 CT 图像双向光流计算网络
双向光流计算网络基于残差密集网络[14],利用3个残差密集块(residual dense blocks,RDB)来提取特征,网络框架如图3 所示。其由浅层特征提取部分、由3 个RDB 构成的残差密集特征提取部分和多级特征融合部分组成。在浅层特征提取部分,使用2 层卷积核为3 的卷积网络来提取初始光流特征。接着通过3 个RDB 将不同RDB 的输出融合后输入到多级特征融合网络中。RDB 既有残差网络的特点也有密集连接的卷积网络的特点,其模型结构如图4 所示。RDB 将每一级的卷积输出经过ReLU 连接起来形成一个密集的残差结构。多级特征融合部分通过1 个1×1 卷积和1 个3×3 卷积提取多级光流特征,使用残差连接,再经过3×3 卷积后输出最终的双向光流。

图2 算法整体框图

图3 CT 图像双向光流计算网络框架图

图4 RDB 模型结构图
1.3 CT 图像双向光流增强网络
通过CT 图像双向光流计算网络得到上下层图像之间的光流后,由公式(1)和(2)可以得到中间图像到上下层图像的双向近似光流。因为此近似光流是由上下层图像之间的光流得到的,仍然需要考虑上下层图像间目标结构变化的问题,所以光流精度还需加强。本节基于UNet 设计了一个CT 图像双向光流增强网络。
Ronneberger 等[15]提出的UNet 网络是由对称的编码器和解码器组成的卷积神经网络。编码器对图像进行下采样提取特征,解码器对图像进行上采样恢复图像,编码器和解码器之间有跳层连接。在编码器中,共有4 个下采样层,每个下采样层先进行池化再经过2 个卷积层。下采样时每经过一层池化层,特征图尺寸就缩小一半,卷积核数目增加为原来的2倍。在解码器中,共有4 个上采样层,每个上采样层先对特征图进行上采样,并和编码器对应同层数据做尺度融合后再经过2 次卷积操作。上采样时先对特征图使用双线性插值拓展图像尺寸为原来的2倍,经过跳层连接后再经过2 次卷积操作。
UNet 使用卷积对空间局部特征进行提取,缺少了对全局信息的感知能力。传统的注意力机制通过独立的键值对(key-value pair)生成注意力矩阵,通过注意力矩阵对权重进行分配,从而增强关键特征对输出的影响,但是此种做法忽略了相邻键与键之间的关联信息。而CoTBlock 注意力结构[16]充分利用了输入键之间上下文信息来指导动态注意力矩阵的学习,从而提升了特征表达能力。其模块结构图如图5 所示。

图5 CoTBlock 模块结构图
对于给定的H×W×C 的二维特征图X,其键矩阵定义为K=X,查询矩阵定义为Q=X,值矩阵定义为V=XWv,其中Wv是利用1×1 卷积实现的嵌入矩阵。通过k×k 组卷积对输入特征X 进行编码,得到输入特征X 的静态局部关联性权重K1,其反映了局部键之间的静态上下文信息。将K1和X 进行拼接后通过2 个连续的1×1 卷积得到动态的多头注意力矩阵A:
式中,Wθ和Wδ是分别利用2 个1×1 卷积实现的嵌入矩阵。注意力矩阵A 具有查询特征和上下文键特征,将其与V 相乘后得到特征图K2:
式中,特征图K2代表输入之间的动态交互特征,其反映了局部键之间的动态上下文信息。将静态上下文K1和动态上下文K2通过注意力机制融合得到输出。经过CoTBlock 层,根据静态上下文信息指导注意力矩阵的生成,再通过注意力矩阵增强关键特征的权重可以有效提取光流特征。
CT 图像双向光流增强网络在UNet 架构基础上改造了编码阶段的结构,如图6 所示。首先,分别使用7×7 卷积层和5×5 卷积层增加感受野。其次,每级特征图经过池化层进行下采样后,先通过1 个卷积层,再通过CoTBlock 层得到下一级特征图,其中每经过一次操作都需要额外再通过1 个Leakly ReLU层。CoTBlock层充分利用了输入键之间上下文信息来指导动态注意力矩阵的学习,从而提升了特征表达能力。最后,在编码阶段的末尾额外增加了一次下采样操作,该下采样操作只对特征图进行下采样而不增加通道数。

图6 CT 图像双向光流增强网络框架图
1.4 损失函数
对于图像层间插值任务,可以利用损失函数计算生成的中间层图像与真实图像之间的差异。本文首先用图像损失函数lr来计算目标图像Im与预测图像之间的误差:
同时,引入高维特征损失函数lp来度量目标图像与预测图像高维度特征图之间的误差:
式中,φ 是ImageNet 预训练的VGG16[17]模型中conv4_3 输出的特征。
另外,利用光流损失函数lw来计算光流误差,由于没有真实光流对照值,由计算出的光流通过g(·,·)反向生成图像与原始图像对照来近似替代光流误差:
本研究还添加平滑损失函数ls用来使光流预测结果更加平滑:
式中,代表哈密顿算子。
最后,结合公式(7)、(8)、(9),本研究CT 图像光流计算与增强网络的损失函数l 的计算公式为
式中,λr、λw、λp和λs分别为每部分损失函数的权重,由于每部分损失函数计算得到的结果相差较大,为了调节每部分反向传播的能力,将公式中λr、λw、λp和λs的值分别设置为204、102、0.005 和1。
2 实验方法和结果
2.1 数据集的制作
为了使CT 图像双向光流计算与增强网络学习到相邻颈椎CT 图像光流变化的细节特征,本文构建了针对人体颈椎CT 图像层间插值的数据集。为了研究人体颈椎椎间盘形态,四川大学电子信息学院图像信息研究所实验室与四川大学华西医院合作,选取了32 名患者的人体颈椎CT 序列图像来制作数据集。这32 名患者的颈椎CT 序列图像形态结构良好且图像的横向点长度为0.23~0.26 mm,纵向点长度为0.625 mm。在每位患者的人体颈椎CT 序列图像中,大约含有200余张CT 图像,其中每相邻的3 张图像分为一小组,每位患者的CT 图像大约能分成200 小组。每小组中,上层图像和下层图像作为输入,中间图像作为层间插值后的验证图像供神经网络训练,每张图像大小均为512×512 像素。从32 名患者的人体颈椎CT 序列图像中选择25 名患者,即共5 226 组图像作为训练集;选择2 名患者,共422 组图像作为验证集;选择5 名患者,共1 061 组图像作为测试集。在训练时,正常的训练顺序是第一张、第三张作为输入,但为了扩充数据避免过拟合,且相邻图像的输入顺序并不影响插值结果,本文随机采取第一张、第三张和第三张、第一张2 种方式加载图像来扩充数据集。
2.2 实验设置
本实验中,实验计算机的系统为Ubuntu20.04系统,CPU 为Intel®CoreTMi7-9700,内存为32 GiB,图形处理器(graphics processing unit,GPU)为NVIDIA RTX2080Ti。
本研究使用Pytorch 框架实现算法,在人体颈椎CT 图像插值数据集上训练网络,网络学习速率设为1×10-4,batchsize 设置为2,使用Adam 方法来优化网络模型参数,训练65 个Epoch 后网络收敛。
2.3 实验结果与分析
为了验证本文网络模型的有效性,将本文算法与基于配准的线性插值算法、Penny 插值算法[2]、基于曲面拟合的双向配准层间插值(using surface fitting with bi-directional registration,USFBR)算法[3]、SuperSlomo(超级慢动作)帧间插值算法[9]和双边运动估计(bilateral motion with bilateral cost,BMBC)帧间插值算法[12]进行比较,并采用平均峰值信噪比(peak signal-tonoise ratio,PSNR)和平均结构相似性(structural similarity,SSIM)来比较生成图像的质量与原始图像的相似性。实验测试了5 组共1 061 张人体颈椎CT 图像的插值效果,结果见表1、2。同时,以病例47 为例,列出了同一病例不同算法生成的中间层的局部放大图像,如图7 所示。

表1 不同算法PSNR 结果 单位:dB

表2 不同算法SSIM 结果

图7 同一病例不同算法生成的中间层图像对比
由表1、2 结果可知,本文算法的PSNR 和SSIM均优于其他算法。观察图7 可以看出,基于配准的线性插值算法生成的图像不仅会出现信息的明显缺失,而且图像存在明显的毛刺和重影现象;Penny 插值算法相较于基于配准的线性插值算法生成的图像结构上更符合原始图像,但仍存在模糊、重影现象;USFBR 算法相较于Penny 插值算法生成的图像质量有了进一步提升,但边缘轮廓依然不清晰;Super Slomo 算法生成的图像基本消除了伪影、毛刺问题,但是边缘结构仍与原始图像有差异;BMBC 算法生成的图像和原始图像较接近,但是图像质量还有待提高;本文算法生成的图像不仅消除了毛刺和伪影问题,并且边缘轮廓与原始图像也更为相似,同时减少了模糊现象。综上,本文算法确实提升了插值图像的质量,并且优于其他算法。
将不同算法所需的参数量、不同算法生成图像的运行时间进行对比,结果见表3。由于深度学习算法可以使用显卡加速,其生成图像的速度快于传统算法。本文算法在降低参数量与运行时间的同时能够得到最佳的插值图像。

表3 不同算法参数量和运行时间对比
由图8 可知,经过插值后的CT 序列图像水平面生成的矢状面和冠状面不仅符合颈椎组织结构的变化,也更贴近人体颈椎的真实情况。

图8 经过层间插值的颈椎CT 图像的矢状面和冠状面
2.4 消融实验
本文算法是通过搭建网络模型实现的,为验证本文提出的CT 图像双向光流计算网络中的残差密集网络和CT 图像双向光流增强网络中的CoTBlock模块对颈椎CT 图像层间插值任务的有效性,进行消融实验比较上述模块对结果的影响。其中,在第一阶段与第二阶段均使用UNet 网络作为Baseline,上采样均使用双线性插值。实验结果见表4、5,可以看出本文提出的模型在PSNR 和SSIM 方面均取得了最佳效果,残差密集网络和CoTBlock 模块均能有效提升插值图像的精度。残差密集网络可以较为精确地提取图像之间双向光流的特征,而CoTBlock 模块利用了注意力机制和相邻键之间的上下文信息加强了光流精度。

表4 不同网络模型的PSNR 结果 单位:dB
3 结语
为解决人体颈椎CT 图像层间插值问题,本文构建了人体颈椎CT 序列层间插值数据集,并使用此数据集训练了一个两阶段的深度学习网络。网络的第一阶段计算输入2 张图像的双向光流场,第二阶段提高近似光流场精度,并最终生成插值图像。在第一阶段中使用了CT 图像双向光流计算网络,该网络使用RDB 计算2 张图像之间的双向光流。第二阶段使用了CT 图像双向光流增强网络,该网络使用CoTBlock 模块改进了UNet 网络,CoTBlock 模块利用自注意力机制和键与键之间的上下文信息加强了光流精度并生成最终的中间层图像。实验表明,本文算法可以生成较高质量的中间层图像。而且本文算法消耗的时间均在训练网络模型上,训练完成后,本文算法在生成中间层图像的速度上有更好的表现。脊柱外科专家观察了经过插值后的颈椎CT 序列图像,认为其矢状面和冠状面形态更符合真实的人体颈椎结构形态,可将插值后的颈椎CT 序列图像用于颈椎终板形态结构的研究和分析。但是当相邻图像差异过大时,本文算法只能尽可能模拟层间图像的变化,精度还有待提高。后续可以考虑用人体颈椎的矢状面和冠状面信息来修缮插值图像,提升插值图像的质量。另外,本文网络模型是一个两阶段的网络,网络参数量相对较大,可以进一步研究,减少网络参数量。

表5 不同网络模型的SSIM 结果
