基于平衡二叉树的数控机床数据去重备份算法
2023-03-11秦金祥
秦金祥,杨 萌
(1.西安石油大学工程训练中心,陕西 西安710065;2.西安石油大学信息中心,陕西 西安710065)
1 引言
数控机床技术进入中国市场较早,产品覆盖面较广,但由于数控系统的功能强大,假如参数或数据出现缺失,就会对机床与数控系统的运行造成不利影响,例如伺服参数缺失会导致伺服电机不能正常运行,参数数据丢失会导致数控机床不能正常工作,严重的会导致人身伤害等。这样既增加了维护人员与设计者的工作难度,也给企业的生产带来了很大的不便。对此有关学者提出了几种解决方案:其中较为典型的两种算法即:一致性哈希算法与多维备份算法。一致性哈希算法[1]通过Swift分析数据机理与代码,并加以改进,同时推出优化选取策略,在明确出节点负载的情况下根据该策略对负载节点中的数据进行备份。但该方法只能根据节点的负载情况进行备份,这就导致大量的重复记录数据也会被备份,使数据存储空间利用率下降;而多维备份算法[2]依靠三种备份策略(在线备份、离线备份、异地备份)对数据进行无差别多维备份。该方法的问题与一致性哈希算法的问题相同,在完成数据备份之后并没有删除冗余数据,导致备份完成后,冗余数据占据部分数控机床系统运行空间的问题,久而久之甚至会导致系统出现内存占满的问题。
针对上述问题,提出一种基于平衡二叉树的数控机床数据去重备份算法。
2 数控机床数据去重
2.1 基于动态权重算法的数据相似度计算
数控机床数据相似度计算方法有很多种,其中编辑距离法因具有运算简单、效果显著的优势,因此该方法最为常用。因此,本文基于编辑距离来进行动数据相似度计算。假设数控机床数据集C={r1,r2,…,rn},ri代表数据集的第i条数据,属性集P={p1,p2,…,pm},pk代表数据的第k种属性,rik代表数据ri的第k种属性值[3]。假设随机两条数据ri与rj的第k种属性值分别是rjk与rik,使D(rik,rjk)代表其编辑距离,那么数据相似度Sim(rik,rjk)就能够通过式(1)进行描述
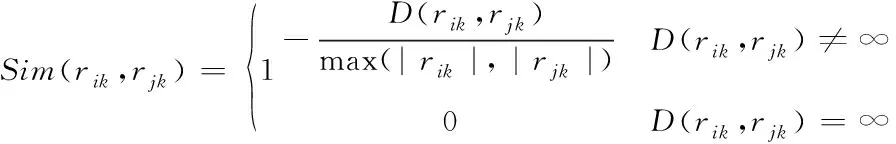
(1)
由于数据的属性对于检测重复数据的贡献不同,因此需要对不同属性按贡献大小赋予其不同权值[4]即一种较为合理且成熟的方式。拟定各属性贡献比例是c1,c2,…,cn,所有属性权值之和位1。通过Wk描述属性Pk的权重,计算公式即
wk=ck/∑ci
(2)
随机两条数据间的相似度Sim(ri,rj)能够通过式(3)进行计算
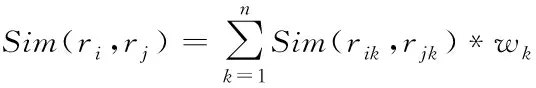
(3)
在进行数据相似度计算时,如果记录的某项属性信息丢失,那么该属性相似度Sim(rik,rjk)=0,这使得数据相似度的总值出现下滑,Sim(ri,rj)小于阈值,两条数据被视为不同。然而r1和r2仍有很大可能是相似重复数据,这种固定权重[5]运算方式因为属性的丢失,给重复数据相似度计算带来了较大的干扰,因此在上述基础上本文提出一种动态权值的就散方法。
假设Valk描述属性k的有效性,则存在

(4)
假如数据某一属性出现无效或丢失,那么所有属性的权重就会出现动态变化,此时必须缩减因属性丢失而出现的干扰。假设有效性属性Wk能够描述成wk=(Valk*ck)/∑(Vali*ci)。因为动态权重能够始终确保数据全部有效属性的权值和为1,进而降低了因属性不完全对数据相似度计算结果所造成的干扰。综上,基于动态权重的数据间相似度能够通过式(5)进行计算
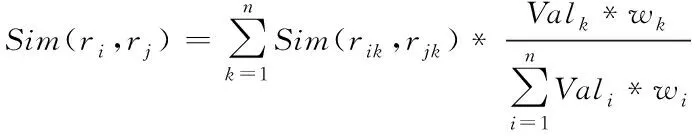
(5)
2.2 数控机床数据去重
本文首先利用专家的知识来挑选关键属性,根据结果对数据集进行互无交叉的划分,使用聚类理念,利用一种开销小的方法对数据进行粗聚类,最后在子数据集内通过两两对比精确剔除相似数据,大大节省了搜索空间,缩减计算量,提升时间效率。
2.2.1 关键属性划分
因为数控机床的数据较多,一条数据通常会由若干属性值构成,属性能够表示数据的特征,但不同属性描述数据特征时的重要性[6]是不同的,至少有一个关键属性会对相似度数据去重起到决定性的作用。本文的关键属性划分使用了一种分组的方式,需要兼顾以下三种方面:
1)关键属性值需要是可枚举、离散型的;
2)关键属性值的枚举总量较大,这样聚类组成的子数据集就会越小,有利于后续的重复数据检测;
3)关键属性值的平均字符总量需要最小化,这样聚类的运算总量就会降低。
人工挑选n种存在区分度的关键属性或属性的特定部分集为KeyList{key1,key2,key3,…},通过独一关键属性进行排列,随后依靠拟定的关键属性数值,把完整数据集划分为若干种互不相交的子数据集[7]。具体流程如下:
1)首先挑选关键属性key1,将属性取值相同的数据聚类成一类,那么能够把大数据集划分为N种相交的小数据集。
2)如果划分之后的数据集依旧较为庞大,那么挑选key2,对这些数据集进行再一次划分。
3)如机床数据集依旧不满足计算量的需求,那么迭代进行步骤2),直至数据集划分至较为合理为止。
2.2.2 Canopy算法的机床数据聚类
在此阶段通过一种用于处理大型数据的新型聚类方法—Canopy聚类,对上述的数据集进行粗聚类。其主要思想即首先将某一条数据作为中心,并将数据划分为可重叠的子集[8],随后在Canopy子集内精确清洗重复数据。这样就只需要对Canopy子集内的数据进行去重,大大缩减了传统聚类方法内对每一种数据进行对比的计算量,另外,Canopy聚类能够允许重叠的子集消除孤立点,提升了方法的容错性。图1即Canopy聚类方法的示意图。
在换分后的子数据集内随机选择一种数据A,每一种数据与A之间的距离需要小于阈值T1,并利用阈值T1将数据标记成同一Canopy子集,将与A之间的距离小于某种阈值T2的数据从数据集内剔除,其中T1≥T2。Canopy中心B、C、D、E的组成过程与A相同,利用这些过程实现机床数据聚类。

图1 Canopy示意图
2.2.3 机床数据去重实现
由于机床数据源不同,数据侧重不同,属性可能存在不完整的问题,为了降低属性丢失对去重结果所带来的影响,本文依靠动态权重算法对机床的重复记录数据进行剔除。对于上述检测出的相似数据,本文提供三种方式来处理相似重复数据:①挑选其一保留,清除其它重复数据;②合并,将所有重复数据看作完整数据的一部分,将其合并成一条更完整的新数据;③通过相似度计算结果评定取舍,并能够根据具体状况的需求挑选不同策略。
3 基于平衡二叉树的数据备份
3.1 数据备份
在开启备份任务后,需要将在本地客户端采集到的数据传输到远端服务器中,在获得数据之后,服务器会把同数据出现响应的数据块调出,并输送到日志卷内,并对与数据块存在关联的数据进行处理,获得元数据记录,随后在镜像卷的响应位置添加数据变化信息。在备份过程中需要对产生的元数据记录进行处理,其流程如下所示:
1)组建元数据记录基础架构,其格式即:
meta-process

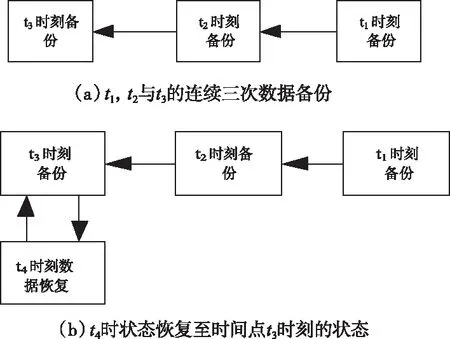
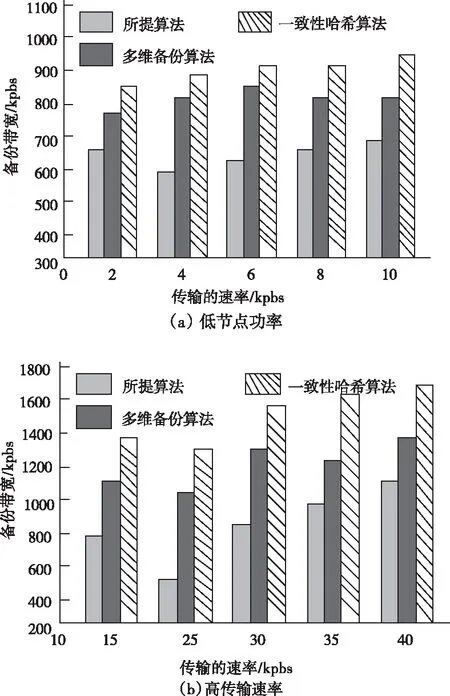
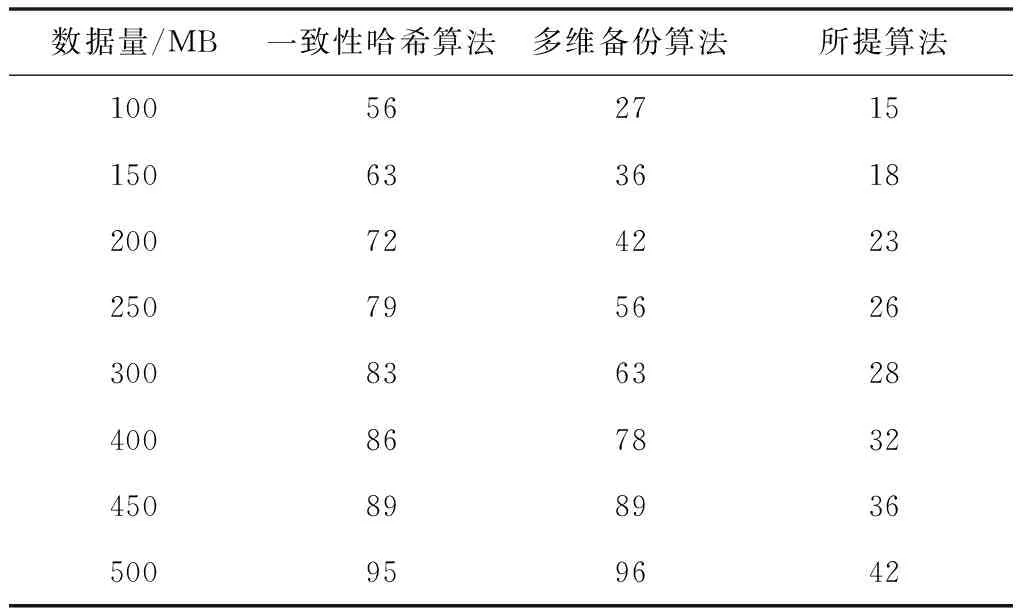
其中,NurnOfBlock代表本地数据快的总数,并利用所有数据块构成一种平衡二叉树tree[i](0 2)非分流程,在得到客户端发送的数据块信息时,需要评定日志卷还有多少容量,如果出现满载现象,就把元数据结构归类至元数据文件mftx内,其中tx为构建元数据架构所消耗的时间,在位图记录归档即元数据位图文件bftx归档后,随后转至步骤1)。归档完成后,并没有出现满载,那么进行以下处理:将数据传输至日志卷内,同时生成元数据记录,随后处理元数据记录,结果为cdp-metar-reecord(ti,2,4097*7,3),代表这在ti时间点以第2种数据块当做原始坐标后而出现的变化,存储在日志卷的原始偏移坐标4096*7,总共出现了两处变化,解析后即ti时间点数据块2和数据块3出现了变化,其储存在日志卷的偏移分别为4096*7和4096*8,经过上述方法进行解析后,依靠时间点作为平衡基础,分别引入到图2元数据记录的基础结构tree[2]和tree[3]所在的平衡二叉树中,同时把位图文件里的第二与第三坐标位拟定成1,最后在镜像卷里传入相应坐标的变化数据块,并继续运作步骤2),一直迭代,直至数据备份完成。 本文利用数据冗余挖掘模型剔除数据备份过程中所产生的冗余数据。 首先设定五种表示该模型的关键变量: 假设St为在t时刻进行数据备份所处理的数据集,St1∩St2代表在t1时刻与t2时刻所备份的数据集之间的重复数据。St1∪St2代表在t1时刻与t2时刻所需要备份的数据。Bt代表在t时刻进行数据备份时所需要传输的数据。Rt代表t时刻完成数据恢复操作所需要传输的数据。 为了使数据冗余挖掘模型的描述更为精确,经过连续三次的数据备份处理案例为例,详细的描述其在数据冗余剔除之后的数据备份过程。图2即经过有向图的方法表示了该数据集在时间点t1,t2和t3的三次连续数据备份与在t4时间点的数据恢复过程。 图2(a)内在t1,t2与t3(t1 图2 连续的数据备份与恢复有向图 (6) 图2表示的即连续三次数据备份之后在t4时刻进行的一次数据恢复处理的全过程,就是把数据集在t4时刻的状态恢复到t3时刻的状态。t4时刻的数据备份恢复处理需要把t3时刻所备份的整个数据集进行恢复与传输,就是Rt4=St3。但是t4时刻数据集和t3时刻数据集内存在很多没有修改的数据。通过消除这些冗余数据,t4时刻所需要传输与恢复的数据量表示为 Rt4=St3-St3∩St4 (7) 不过,其前提需在t4时刻进行数据恢复与传输过程中St3∩St4的数据不能出现变化,反之式(7)会不成立。并且,如果t4时刻产生的数据灾难使得在t4时刻所备份的数据集不能被访问,那么St3∩St4=∅,Rt4等于St3。 为了证明本文所设计的基于平衡二叉树的数控机床数据去重备份算法的实用性,需要进行一次实验。实验在Matlab2018的环境下进行,实验的数控机床内存是4G,CPU是IntelCore,实验参数通过表1进行描述。 表1 实验参数 在数控机床数据传输的速率不断提升的条件下,所提算法、一致性哈希算法与多维备份算法的备份带宽对比结果如图3所示。 通过图3能够看出,随着节点传输速率的逐渐提升,所提算法的数控机床数据备份带宽明显高于一致性哈希算法与多维备份算法,这是因为该方法先对机床数据进行去重,这就能够剔除掉较多的重复数据记录,降低机床数据库中由于重复数据传输量的提升而引起的带宽瓶颈效应。 图3 不同速率下数控机床数据备份带宽对比 在上述基础上,比较三种算法存储不同量的数据时在机床系统中的空间占用率,结果如表2所示。 表2 空间占用率对比(%) 分析表2可知,与一致性哈希算法与多维备份算法相比,本文算法的空间占用率最低,可以进一步提升系统运行速度,实现系统性能的大幅度提升。 为了提高数控机床系统的空间利用率,提出一种基于平衡二叉树的数控机床数据去重备份算法,通过相似度计算完成对重复记录数据的剔除,并使用平衡二叉树算法备份机床数据。虽然该算法在数据备份与去重上取得了较好的效果,但随着本文研究的不断推进,依旧发现了一些弊端,即本文算法的备份只能针对单一机床数据进行处理,而数据机床通常会有数台,这就导致算法的可应用性受限,因此下一步需要在本文算法的基础上构建系统,并将系统安装至数控机床中,实现多台机床数据的同步备份与去重。3.2 数据冗余挖掘与二次去重
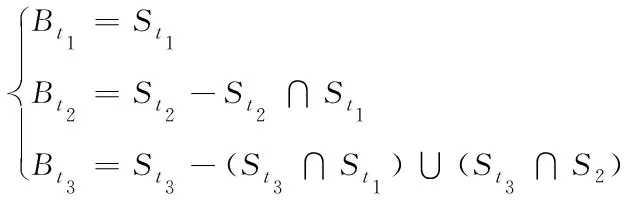
4 实验证明

5 结束语
