基于融合注意力机制LSTM的网络舆情趋势预测
2023-03-11马永军
马永军,郎 威
(1. 天津科技大学人工智能学院,天津 300457;2. 天津科技大学经济与管理学院,天津 300457;3. 天津科技大学食品安全管理与战略研究中心,天津 300222)
1 引言
根据中国互联网络信息中心(CNNIC)所发布的第47次《中国互联网络发展状况统计报告》显示,截至2020年12月,我国网民规模达到9.89亿,相对于2020年3月增长8540万,互联网普及率达70.4%[1]。随着网络的不断普及,人们更加倾向使用手机这类移动终端设备上网,借助移动端的社交媒体(如:微博、微信、论坛等)进行信息共享和交流,这为舆情传播发展提供了便利的条件,但使得网络舆情传播演化变得更为复杂,更容易引起危机事件的发生。为了避免网络舆情带来的负面影响,有必要对网络舆情发展趋势进行预测,准确把握网络舆情的发展规律,有助于管理部门及时、准确、高效地引导网络舆情朝着合理、健康的方向发展,充分发挥舆情的积极作用。
2 研究现状
近年来,舆情引发的危机事件层出不穷,引起了学术界对网络舆情的极大关注。网络舆情的研究主要体现在舆情研判机制的建立与预测方法的研究,及时、准确地预测舆情的发展趋势有利于发现潜在的危机,从而尽可能地避免由舆情引发的一系列危害性事件[2]。
目前,国内学者对舆情趋势的预测研究已经取得了一定的成果,涵盖了多种方法但仍处于起步阶段,尚未形成一套完整的体系结构。使用的方法一般基于统计学[3-5]、机器学习[6-11]以及统计学与机器学习相融合的方法[12,13]。王新猛[3]提出了基于马尔科夫链的政府负面网络舆情热度趋势预测模型,并研究了网络舆情事件的规律与发展周期;徐敏捷[4]引入指数平滑法构建舆情热度趋势预测模型,以“雾霾”热议指数作为实例,验证了模型的有效性;徐旖旎[5]采用层次分析法建立舆情热度指标评价体系,对微博舆情中的元素分配相应的权重值,最后结合马尔可夫链模型实现了舆情热度趋势的预测;胡悦、王亚民[6]针对微博话题发展的复杂性和非线性特点,采用模糊神经网络的方法对微博话题的发展趋势进行预测,并利用改进的粒子群算法优化构建的模型,提高了模型预测的准确性;赵磊、王松[7]根据舆情热度的趋势变化特点,结合舆情事件的时间序列并运用BP神经网络理论,有效地预测了网络事件的舆情热度趋势;曾子明、黄城莺[8]通过构建微博舆情热度评价指标体系,从而确定各个指标的权重,最后基于BP神经网络建立传染病舆情热度预测模型,并以MERS病毒卫生突发事件为例验证了模型的可行性;游丹丹、陈福集[9]采用改进的粒子群算法对BP神经网络进行优化,构建出一种新的网络舆情预测模型;黄亚驹、陈福集等[10]在游丹丹等人的研究基础上使用遗传算法与粒子群算法混合优化BP神经网络,提高了模型的预测效果;孙靖超、周睿等[11]考虑到传统基于统计或普通神经网络的方法对于非线性数据和多变量特征的预测效果较差,设计出一种基于循环神经网络的舆情预测模型,充分利用循环神经网络处理时序数据的强大优势,进一步提高了模型的预测精度;李彤、宋之杰[12]运用模型集成理论,对ARIMA、神经网络、支持向量机回归进行集成,构建出平均集成模型来预测微博的情感趋势;聂黎生[13]将核主成分分析(KPCK)与粒子群随机森林算法相结合,发现了舆情传播过程中的潜在驱动机制和动态规律。
综上所述,诸多学者从不同角度展开了对网络舆情发展趋势的研究,逐步拓展了网络舆情趋势预测的方法,但目前仍处于方法探索阶段,亟待进一步的研究。网络舆情的相关数据具有一定的时序相关性,采用统计学或者传统的机器学习方法很难挖掘出时序数据在时间维度上的关联性,同时,网络舆情受到众多因素的影响,每种因素对舆情发展趋势的影响程度不同,一些研究利用层次分析对相关因素分配权重,但这种方法定性成分居多,不易令人信服。因此,为了充分挖掘网络舆情相关数据中的信息,提升模型的预测速度和准确度,本文提出了一种将注意力机制与长短期记忆(Long Short-Term Memory,LSTM)模型相融合的网络舆情趋势预测方法,采用擅长处理时间序列数据的LSTM模型,引入注意力机制,有效分配网络舆情各个影响因素的权重,更快地拟合舆情的发展趋势,使得模型预测的速度和精度得到提高,同时也让模型具有一定的可解释性。
3 舆情热度指标体系的构建
3.1 热度指标体系
通过建立舆情热度指标体系,可以定量化描述舆情热度,从而分析预测舆情的发展趋势。在舆情的变化发展过程中,众多因素对舆情有着不同程度的影响,本文按照准确性、整体性和可行性的原则,同时参考前人的研究[14,15],构建出相应的指标体系,如图1所示。
构建的指标体系具有两个一级指标和四个二级指标,其中舆情话题传播广度是指该舆情事件的辐射范围,转发量越大辐射范围越广,本文认为转发量是传播广度的主要影响指标,因此将转发量设为该一级指标下的二级指标;舆情话题传播深度则是指舆情事件中网民的参与程度,越多的人参与,那么可以认为该舆情事件的传播深度越大,某个舆情事件的网民参与程度主要受到该事件的点赞量、评论量和访问时长的影响,因此,本文把这三个指标作为该一级指标下的二级指标。
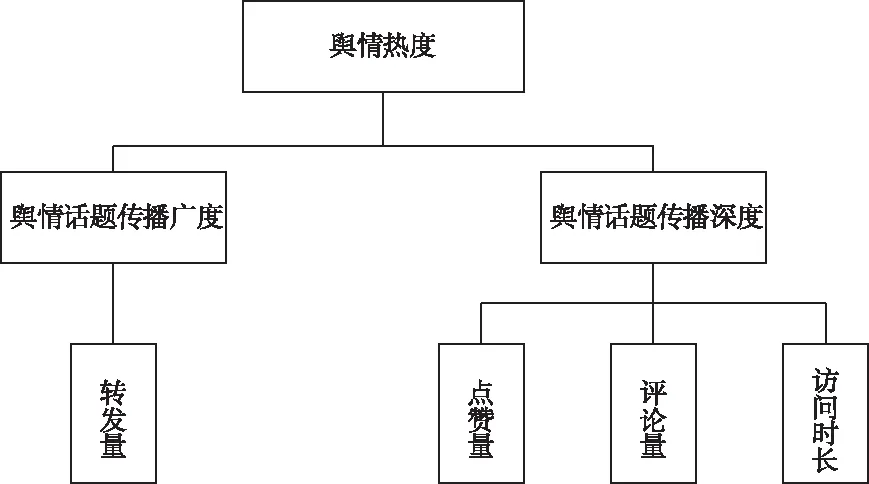
图1 舆情热度指标体系
3.2 预测的思路和方法
网络舆情热度趋势的预测是对舆情未来发展状态的一种直观反应,从而实现对舆情及时的引导和控制。预测是一项复杂、系统的工作,包括数据选取、预测方法、预测效果等。对于舆情趋势预测来说,还存在以下两个问题:
1) 动态预测问题。考虑到大数据环境,舆情数据存在产生较快、传播周期较短等情况,因此需要利用之前大量舆情数据进行预先训练,再将训练好的模型用于想要预测的舆情事件中。同时还需要对所预测的舆情事件的信息进行不断收集,以滚动的方式放入模型进行训练,从而使得模型可以及时预测突发情况;
2) 预测起点选取问题。预测研究中严格选取预测起点,可以降低初值对预测精度的影响。舆情事件一般可以分为突发性舆情事件和非突发性舆情事件。突发性舆情事件是指在某一个时间点突然出现之前没有的舆情事件,而网民经常性、持续性讨论的舆情事件就属于非突发性事件,本文称之为常态性舆情事件。对于这两种舆情事件的预测起点问题,关于突发性的舆情事件,预测起点选取事件产生的时间点;关于常态性的舆情事件,则按照由少到多的原则,预测起点选取数值较低的时间点。
4 模型的构建
4.1 长短期记忆网络模型
循环神经网络RNN对于时间序列的预测已经被证明是有效的[16],但面对大量而复杂的样本数据时,RNN容易产生梯度消失和梯度爆炸的问题。为了解决这一问题,Hochreiter等人[17]提出了长短期记忆LSTM模型,并由Graves进行了改进[18]。LSTM模型通过引入“cell state”的概念,利用“门限”的结构对信息进行控制,有效地解决了梯度消失和梯度爆炸的问题,在长时间依赖性的问题中得到广泛的应用[19]。LSTM是时序卷积神经网络的一种,每一个LSTM单元内部一般包含三个门控结构:遗忘门、输入门和输出门,单元内部结构如图2所示。通过这些门控结构,可以挖掘时间序列中相对较长间隔和延时等的时序变化规律[20]。
图2中,xt为第t个输入样本序列,ct-1为t-1时刻的单元状态,ht-1为t-1时刻的隐层状态。利用xt,ct-1、ht-1结合三个门函数可以对其它值进行求解,具体的门函数以及其它数值的计算公式如下:

图2 LSTM单元内部结构图
遗忘门函数ft
ft=σ(Wf⊗[ht-1,xt]+bf)
(1)
输入门函数
it=σ(Wf⊗[ht-1,xt]+bi)
(2)

(3)
单元状态ct
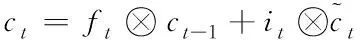
(4)
输出门函数ot
ot=σ(Wo⊗[ht-1,xt]+bo)
(5)
单元隐层输出ht
ht=ot⊗tanh(ct)
(6)
式(1)-(6)为LSTM前向计算的所有公式,其中⊗代表按元素乘;Wf、(Wi、Wc)、Wo分别为遗忘门、输入门、输出门的权重矩阵;bf、(bi、bc)、bo分别为遗忘门、输入门、输出门的偏置项,[ht-1,xt]表示把两个向量拼接成一个向量;σ,tanh为激活函数,σ定义为sigmoid函数,σ与其导数σ′的关系为

(7)
σ′(x)=y(y-1)
(8)
tanh与其导数tanh′的关系为

(9)
tanh′(x)=1-y2
(10)
4.2 融合注意力机制的LSTM模型
注意力模型(Attention Model)最初被应用于机器翻译的研究[21],现在已经成为神经网络领域中的一个重要的概念。从命名方式看,注意力模型是受到人类注意力机制的启发而得到的,绝大部分的注意力模型应用于Encoder-Decoder框架中,但是注意力机制本身可以作为一种不依赖于特定框架的通用思想——选出对结果影响较大的因素分配更多的注意力,对结果较小的因素分配较少的注意力[16]。此外,由于神经网络缺乏可解释性,利用注意力机制可以在一定程度上解释神经网络模型内部的工作[22]。
考虑到样本数据较少的问题,为了充分学习样本中的信息,并且防止模型出现过拟合现象,本文在LSTM模型中引入注意力机制的思想,实现对模型中各权重值的合理分配。其中具体操作是:将LSTM的输出与目标值进行联系,采用LSTM层的输出序列与目标序列之间的相关系数作为注意力系数的分配参考指标。本文选取Pearson相关系数作为输入序列的各个特征分配合理的注意力系数。其中注意力系数ak的计算公式如下

(11)
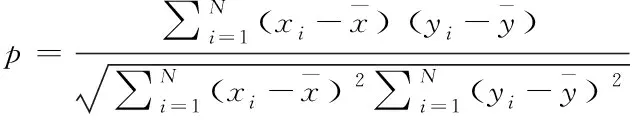
(12)
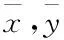
在3.1小节中介绍了LSTM前向计算,其中包含了8种参数(Wf、Wi、Wc、Wo、bf、bi、bc、bo),而LSTM的反向计算则利用真实值与预测值之间的偏离程度对这8中参数进行不断地修正,其中反向计算的步骤如下:
1) 计算每个神经元的损失函数;
本文使用均方根误差RMSE作为模型的损失函数,如下式
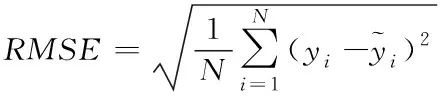
(13)
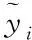
2) 根据相应误差项,更新LSTM中的权重矩阵和偏置项。
引入注意力机制的LSTM预测模型结构如图3所示。图中X代表输入样本序列,Y代表输出变量的实际值序列,a代表注意力系数,Nt代表分配注意力系数后的LSTM输入样本序列,Mt代表LSTM输出的预测值序列。
融合注意力机制的LSTM算法流程图如图4所示,具体步骤如下:
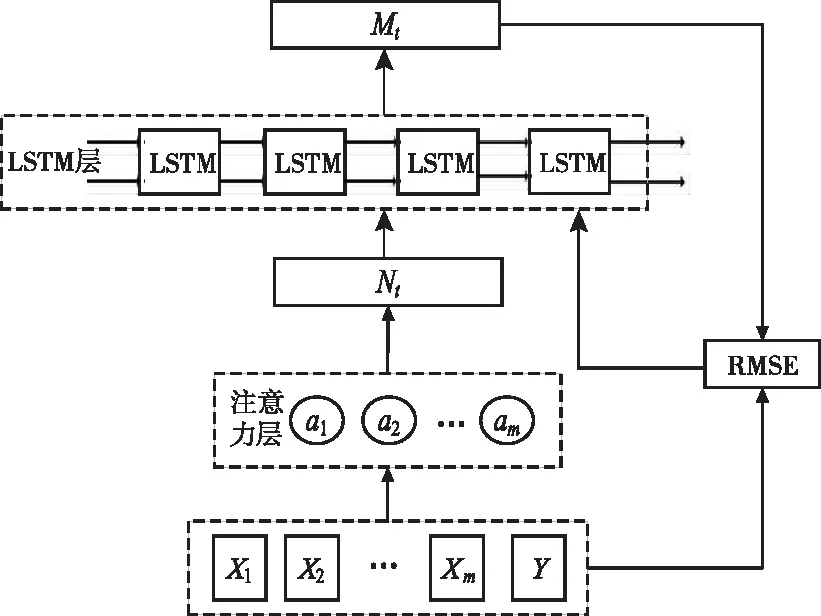
图3 引入注意力机制的LSTM预测模型结构图
1) 先通过网络爬虫爬取相关数据,并对得到的数据进行筛选、整合、归一化等预处理,构建出输入样本序列。其中归一化采用min-max标准化函数;
2) 构建注意力层。根据式(9)计算每个特征的注意力系数,再通过softmax函数对注意力系数进行归一化,然后将归一化的注意力系数分配给输入样本序列的每一个特征;
3) 确定LSTM模型的网络结构。初始化模型的相应参数值,并将具有注意力系数的输入样本序列放入LSTM模型中进行训练;
4) 计算每个神经元的输出值,同时,判断是否达到指定的迭代次数,如果是则直接跳至步骤6),否则进行步骤5);
5) 计算每个神经元的RMSE。判断RMSE是否小于门限值,是则进行步骤6),否则根据RMSE与学习率更新权重,并跳至步骤4);
6) 输出各个神经元的预测值并进行反归一化。
最后,按照2.1小节的指标,本文选取50个舆情事件,例如“地沟油”、“毒胶囊”、“非洲猪瘟”等,按照2.2小节,选择出每个舆情事件的预测起点,并取该事件100天的舆情数据(共5000条数据),输入序列为舆情事件的评论量、点赞量、转发量、访问时长,目标序列按照该舆情事件的百度指数为参考,使用此数据集对所构建的模型进行训练和优化。
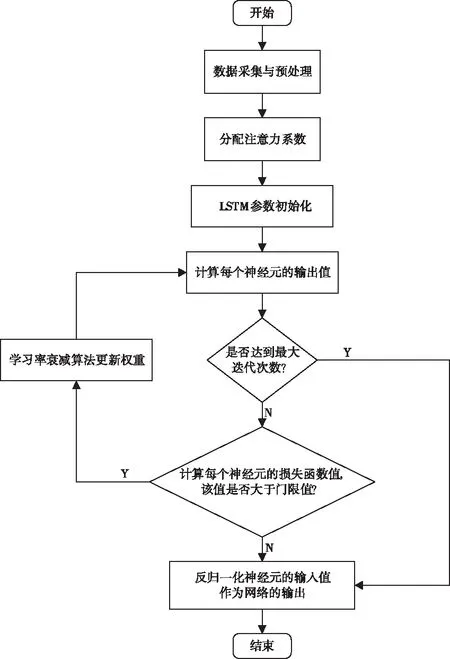
图4 融合注意力机制的LSTM模型算法流程
5 实验及结果分析
5.1 数据的选取与处理
为了验证本文构建的融合注意力机制LSTM模型对舆情趋势预测的效果,选取2019年“亚硝酸盐中毒”舆情事件为研究对象。相关数据通过编写网络爬虫代码对微博中的信息进行爬取,最终选取该舆情事件波动较为明显的时间段,即2019年4月10日至7月18日(共100天)。利用前4天的时间序列数据预测第5天的数据,采用滚动的方法,5天为一周期,数据共分为96组,取前86组作为训练组,后10组作为测试组,训练组和测试组有4天的数据重合。该时间段的百度指数如图5所示。为了消除数据的量纲对结果的影响,对所有的数据在输入模型之前进行min-max归一化,最后对模型的输出预测值进行反归一化。

图5 亚硝酸盐中毒事件的百度指数
5.2 模型的参数设置
由于在LSTM模型中引入Attention机制,模型结构复杂度有所提高,在训练过程中可能产生过拟合的现象。因此,本文加入Dropout技术防止模型过拟合。经过大量的反复试验,在Dropout为0.2、迭代次数epoch为1500的时候,本文构建的模型可以取得良好的预测效果。此外,由于采用前4天的数据对第5天的情况进行预测,因此输入维数设置为4,输出维数设置为1,对于激活函数的选择,本文选取relu、sigmoid、tanh作为模型的激活函数,输入序列每一个特征用12维的向量表示。所构建模型的主要参数取值如表1所示。

表1 融合注意力机制的LSTM模型主要参数
5.3 实验及结果分析
本文的实验在Windows10系统下进行,编程语言为Python3.7,开发工具为PyCharm2019,使用的深度学习框架为TensorFlow2.2.0。根据以上两个小节的内容,将新的舆情数据放入之前训练好的模型中进行训练,最后对舆情发展趋势进行预测,预测结果与真实值对照结果如图6所示。
通过图6可以初步判断,所构建的模型对于网络舆情趋势的预测具有一定的有效性且预测效果良好。
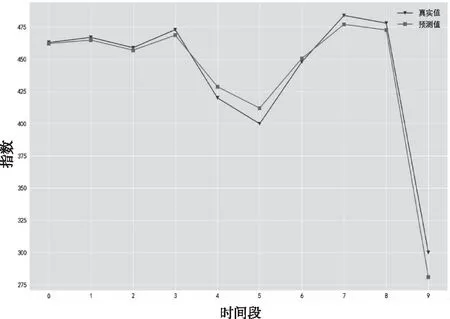
图6 融合注意力机制的LSTM预测效果图(epoch=1500)
为了对比模型的性能,本文将构建的模型与传统BP模型、传统LSTM模型进行对比,绘制出这三种模型的预测效果,如图7所示。最后分别计算这三种模型的平均相对误差MRE进行对比,误差结果对照表如表2所示。
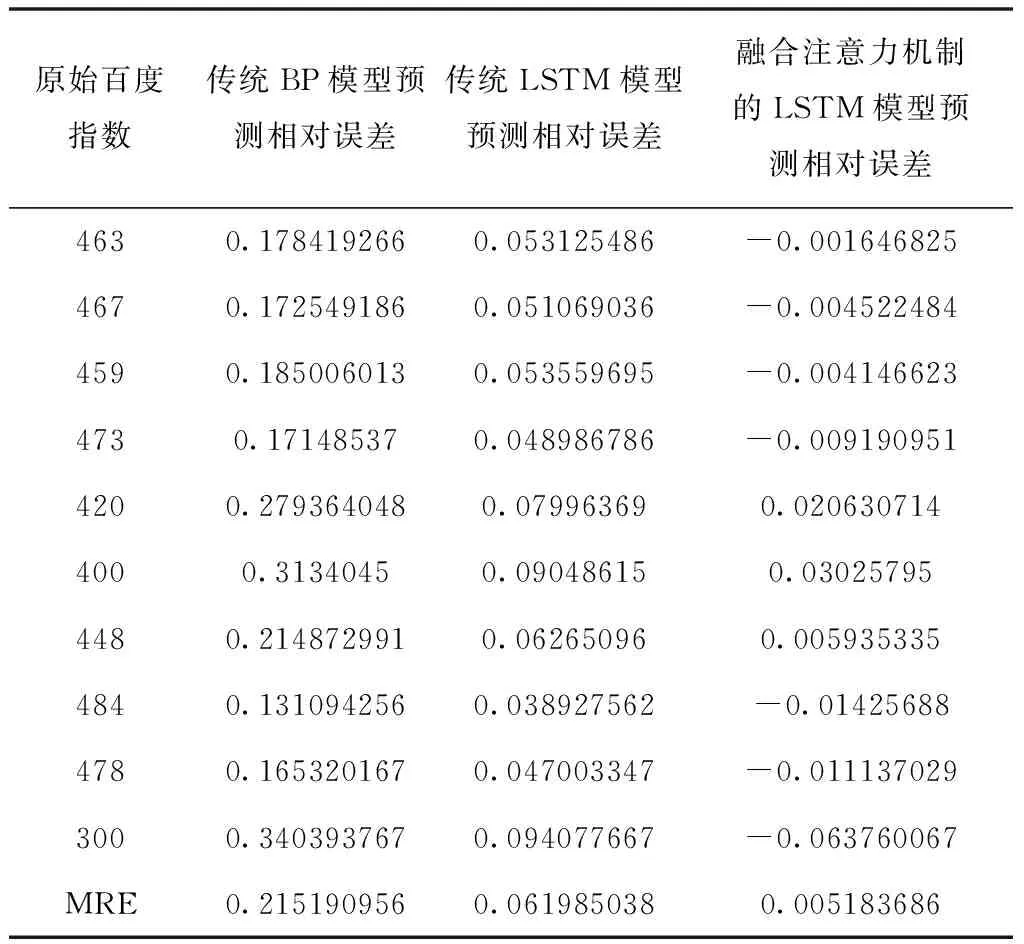
表2 三种模型的平均相对误差表
通过图7以及表2可以看出,传统BP模型的预测曲线波动最大且预测效果最差,本文构建的融合注意力机制的LSTM模型相对于传统BP模型和传统LSTM模型,在预测精度上有一定的提高,同时预测的曲线波动较小、相对稳定。
最后,为了进一步对比这三种模型,本文将迭代次数epoch设置为2500,观察三种模型的预测效果,并绘制相应的预测结果图,如图8所示。
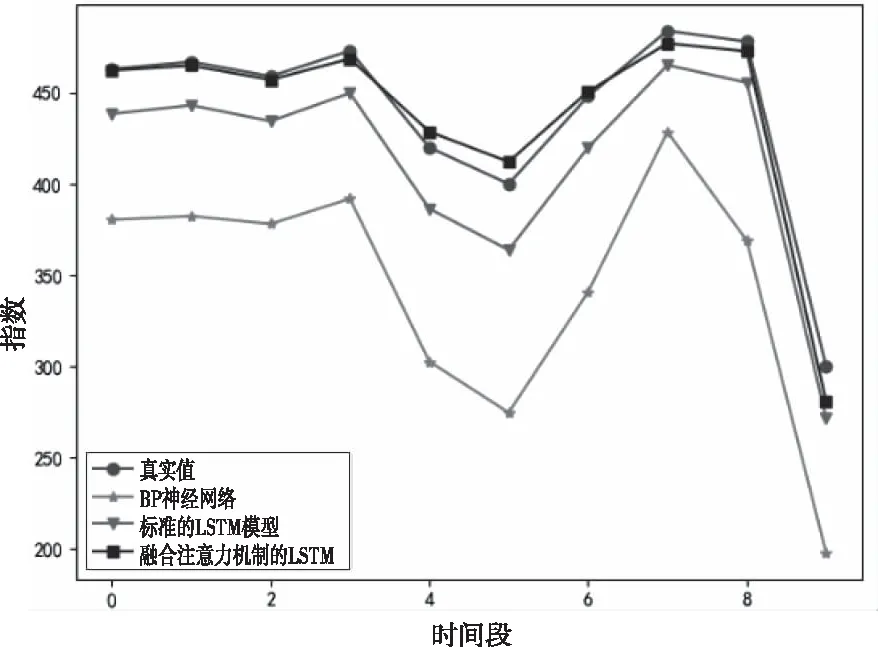
图7 三种模型的预测效果(epoch=1500)
通过图7和8相互对比可以看出,随着迭代次数的不断增加,传统BP模型与传统LSTM模型的预测精度在不断地提高,而融合注意力机制的LSTM模型在迭代次数epoch=1500的时候已经达到了很好的预测效果,之后融合注意力机制LSTM模型的预测效果降低,造成的原因可能是模型在训练过程中出现过拟合。
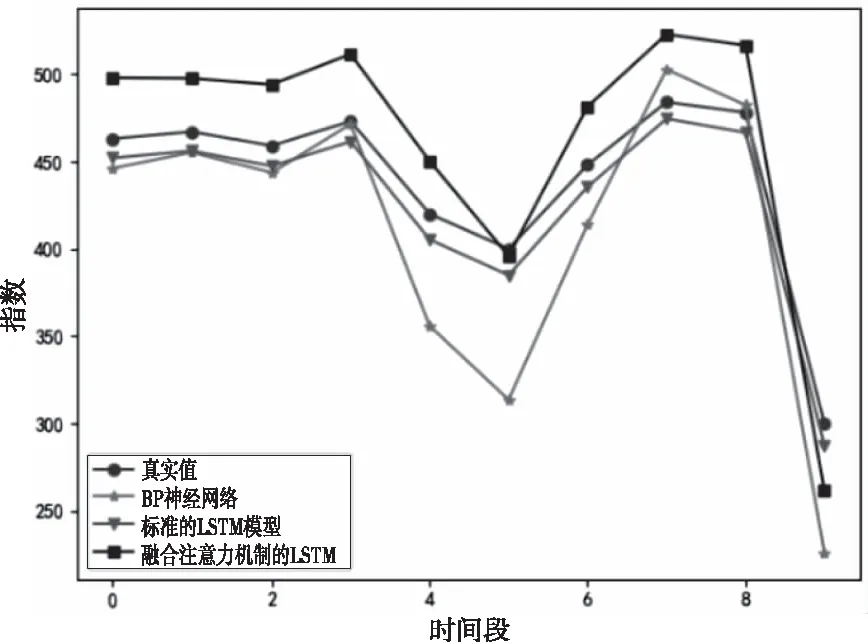
图8 三种模型的预测效果(epoch=2500)
上述实验结果表明,融合注意力机制的LSTM模型在预测舆情发展趋势上具有一定的有效性和准确性。在预测精度方面,构建的模型相对于传统BP模型与传统LSTM模型有所提高;在预测速度方面,经过比对发现,本文构建的模型可以更快地达到更好的精度,进而实现对舆情趋势的有效预测。
6 结束语
本文在网络舆情大数据背景下,构建相关指标体系,提出了融合注意力机制的LSTM模型,通过分析网络舆情特征数据与预测值之间的关系,对各个特征事先合理分配注意力系数,使得模型更快、更好地实现舆情趋势的预测,同时也使得模型具有一定的可解释性。最后将所构建的模型与传统BP模型和传统LSTM模型进行对比,验证了融合注意力机制的LSTM模型具有较好的预测效果,为网络舆情趋势预测提供了一种有效的方法。
