广义最大覆盖模型的新型人类学习优化算法
2023-03-11张枫雪
张枫雪,刘 勇
(上海理工大学管理学院,上海 200093)
1 引言
广义最大覆盖模型是在传统覆盖模型基础上发展而来,当需求点在设施点的最小覆盖距离(或时间)内时,服务质量最优;当超过最小覆盖距离(或时间)时,服务质量单调递减;当超过最大覆盖距离(或时间)时,服务质量变为零。广义最大覆盖模型将服务质量引入到覆盖选址问题中,更加符合实际问题的需要。Jia等为了应对大规模突发事件,考虑距离对于服务质量的影响,建立广义最大覆盖模型来解决需求不确定性和医疗供应不足的问题[1]。Ozbaygin等考虑覆盖率,研究了时间受约束的最大覆盖销售员问题,其目的是找到一个访问某个客户子集的旅行团,从而使有限时间内覆盖的需求量最大化[2]。马云峰等基于时间满意度函数提出广义最大覆盖选址模型,考虑时间因素对企业选址的影响[3]。王文峰等基于传统的最大覆盖模型提出应急服务设施的广义覆盖选址模型,为医疗救援物资的选址提供解决方案[4]。于冬梅等建立共享不确定需求和中断情景下服务能力有限的应急设施广义覆盖选址鲁棒优化模型,有效解决需求不确定和中断风险下选址布局网络的构建问题,确定最优的选址分配方案[5]。韩珣等通过信号强度函数和概率函数,刻画联合覆盖对顾客选择的影响,建立竞争环境下的广义自提点选址模型,有利于企业通过自提点的布局获取竞争优势[6]。
广义最大覆盖模型为设施点布局规划提供了可行有效的模型,如何求解该模型一直是研究热点。该模型与传统覆盖模型一样是NP-hard问题[7]。目前,常用的算法有分支切割算法[2]、拉格朗日松弛算法[1,3],遗传算法[1,6],分布估计算法[4]和灰狼优化算法[5]等。这些算法为求解广义最大覆盖模型提供了思路,但是存在易早熟收敛和计算精度低等问题。为有效求解广义最大覆盖模型,本文提出一种新型人类学习优化算法(Novel Human Learning Optimization,NHLO),数值实验验证新算法可以显著提高模型的计算精度,为该问题的求解提供新途径。
2 广义最大覆盖模型
2.1 问题描述及假设
已知候选设施点和需求点,以及候选设施点与每个需求点之间的距离,规定了设施点和需求点的距离限制。在给定的限制条件下,使设施点尽可能多的覆盖需求点,提供更好的服务。服务的质量通过覆盖率体现,覆盖率越大表明应急资源分布越合理。该模型提出的基本假设如下:
1)设施点和需求点是离散的,有n个需求点,有m个候选设施点。
2)每个设施点提供服务的能力是足够的。
3)每个需求点只被一个设施点覆盖。
4)设施点向需求点提供的服务质量随着与需求点的距离增加而降低。
2.2 符号定义
1)I={1,2,…n}:需求点的集合。
2)J={1,2,…m}:设施候选点的集合。
3)s:待建设施点的数量,其中1≤s≤m。
4)wi:需求点i处的人口数量。
5)dij:需求点i和设施点j之间的距离。
6)L,U:分别表示最小距离值和最大距离值。
7)α:表示需求点i对距离的敏感性。
8)λij:表示模型中的需求点i被设施点j覆盖的程度,0≤λij≤1。
9)xj:0-1变量,当设施点j被选中时为1,否则为0。
10)yij:0-1变量,当需求点i被设施点j覆盖时为1,否则为0。
2.3 覆盖水平函数
引入最小距离L和最大距离U两个值,当设施点和需求点之间的距离在设定的最小距离之内,属于完全覆盖;当设施点和需求点的距离大于最小距离小于最大距离时,属于部分覆盖;当设施点和需求点的距离大于最大距离时,属于没有任何覆盖[8]。
覆盖水平函数λij[9]如下
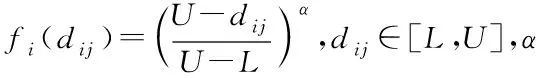
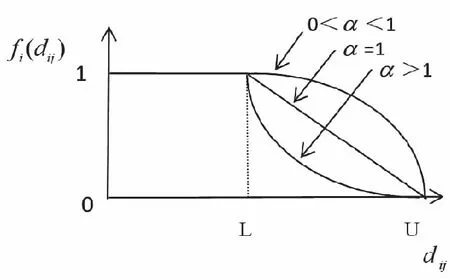
图1 覆盖水平函数曲线
2.4 数学模型

(1)
s.t.
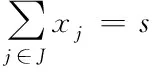
(2)
yij≤xj∀j=J∀i∈I
(3)
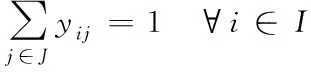
(4)
xj={0,1} ∀j∈J
(5)
yij={0,1} ∀i∈I∀j=J
(6)
其中,式(1)表示考虑覆盖水平的需求量最大;式(2)表示需要建设的应急设施点为s个;式(3)只有当候选设施点j被选中时,需求点i才能被候选设施点j覆盖;式(4)每个需求点i都被一个且只被一个设施点j覆盖;式(5)和(6)分别表示xj和yij是属于0或者1的决策变量。
3 广义最大覆盖模型的新型人类学习优化算法
人类学习优化算法是Wang等人在2014年提出,通过模仿人类的学习行为来进行优化搜索。人类学习优化算法包括以下几个部分[10]:
1)初始化
人类学习优化算法个体采用二进制编码,具体方法如式(7)所示
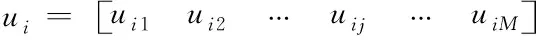
(7)
1≤i≤N,1≤j≤M
其中,ui表示第i个个体,且uij∈{0,1};N表示群体规模;M表示解的维数。
2)随机学习算子
初始阶段,由于人没有知识和经验,会随机获取各种知识。基于此,算法设计了随机学习算子,如式(8) 所示
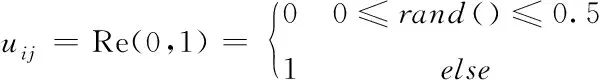
(8)
其中,rand()是介于0到1之间的随机数。
3)个体学习算子
当人们有了一定的知识和经验后,个体会将随机学习过程中获得的知识和经验运用到自身实践中。根据自己的经验学习解决问题,不断的总结和更新自身的个体学习知识库IKD,建立个人知识数据库来储存个人最好的学习经验。在算法中,设计个体学习算子,如式(9)和(10)所示
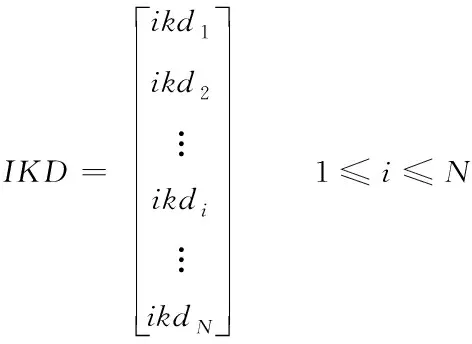
(9)
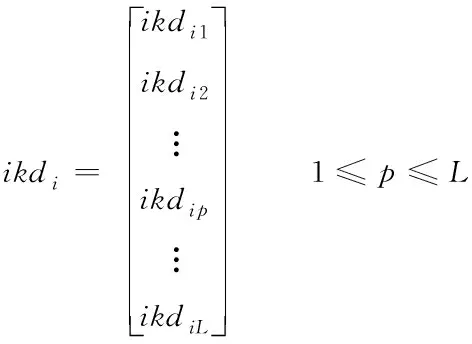
(10)
其中,ikdi表示第i个人的个体学习知识库IKD;ikdip代表第i个人的第p个为最佳解;L表示ikdi的规模。
当进行个体学习时,它会根据ikdi中的知识生成新的解决方案,其操作方式如式(11)所示
uij=ikdipj
(11)
其中,ikdipj代表第i个人的第p个为最佳解第j个分量。
4)社会学习算子
人类除了通过自身学习获得直接经验外,还可以向其他人学习获得间接经验,从而对知识库进行补充更新,为了模拟这种学习策略,建立社会学习知识库SKD。在算法中,设计社会学习算子,如式(12)所示
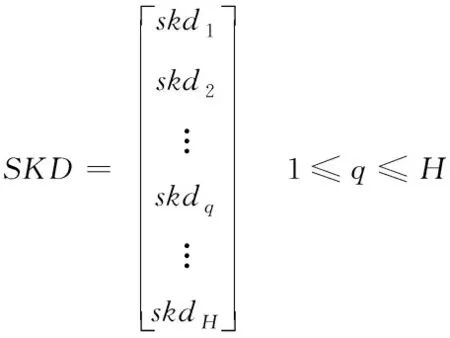
(12)
其中,skdq表示SKD中的第q个解。
基于SKD中的知识,可以按照式(13)进行社会学习,从而在搜索过程中产生更好的解决方案。
uij=skdqj
(13)
其中skdqj表示SKD中的第q个解第j个分量。
综上所述,人类学习优化算法使用随机学习算子、个体学习算子和社会学习算子,在IKD和SKD中存储的知识基础上产生新的解决方案并寻找最优解。这三种学习算子的选择策略如式(14)所示
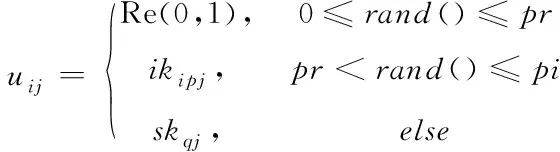
(14)
其中,pr是选择随机学习的概率,(pi-pr)和(1-pi)的值分别表示选择个体学习和社会学习的概率。
5)更新
当所有个体求出解后,需要根据适应度函数计算每个个体的适应度,从而更新IKD和SKD。对于IKD的更新,当新生成的解的适应度优于IKD中的最差解的适应度或者IKD中的解个数没有达到预先定义的值时,新生成的解储存在IKD中。SKD的更新也如IKD一样,如果当前一代的最优解优于SKD中最差的解,或者SKD中当前解的个数小于预先定义的个数,则将当前代的最优解保存在SKD中。
有三种不同方式的学习策略,分别是随机学习、个体学习和社会学习,经过这三种方式的学习会不断的更新个体学习知识库和社会学习知识库。学习系统结构图如图2所示。
不同于模拟简单生物行为的蚁群优化算法、微粒群优化算法和蜂群优化算法等,人类学习优化算法是模拟人类学习行为,为复杂问题的求解提供了新方法。人类学习算法在求解经典组合优化问题——背包问题时,表现出良好的优化性能。但是近期的研究[11-13]表明,和其它智能优化算法一样,基本人类学习优化算法存在的计算精度低和早熟收敛等问题。
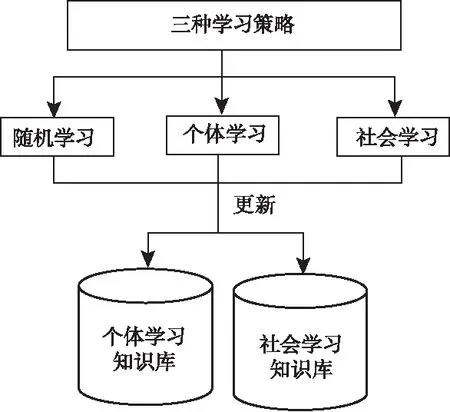
图2 学习系统结构图
为有效求解广义最大覆盖问题,基于人类学习行为特点,本文设计一种新型人类学习优化算法。在学习的早期阶段,由于自身知识和经验不足,随机性学习的可能性比较大。但是随着学习的深入,向自我和他人学习的能力越来越强。而根据式(14),随机学习算子、个体学习算子和社会学习算子的选择策略根据概率进行设置,不符合人们学习过程的特点。因此,对式(14)进行调整,重新设计这三种学习算子的选择策略。随着学习过程的不断深入,随机学习的概率逐渐下降[13],个体学习和社会学习的概率增加。随机学习的概率不再是常数,而是随迭代次数递减,具体公式如式(15)

(15)
当个体选择向自我学习还是他人学习时,也不再根据概率确定,而是根据个体能力确定。当个体对应的函数值大于平均值时,说明个体学习效果较好,继续保持个体学习;当个体对应函数值小于等于平均值时,说明个体学习效果不佳,需要向其他人学习。
本文提出的自适应学习策略如式(16)所示

(16)
其中fi(t)表示第t次迭代时第i个个体的函数值,favg(t)表示第t次迭代时所有个体函数值的平均值。
在求解时,等式约束(2)采用罚函数进行处理。此外,选址决策变量xj和算法中的寻优个体ui相对应。例如,备选设施点有5个,寻优个体ui维数设为5。如果第一个分量取0,表示不选第一个候选点;如果第二个分量等于1,表示选第二个候选点,以此类推。在确定好选址决策变量xj后,根据覆盖水平函数将最近的候选设施点分配给需求点,从而确定分配变量yij。
综上所述,求解广义最大覆盖模型的新型人类学习优化算法的伪代码如下:
输入:种群的规模N,维数M,随机学习的概率pr。
输出:种群最优解。
1)根据N和M初始化种群
2)计算每个个体适应度
3)个体学习知识库IKD和社会学习知识库SKD初始化
4)计算随机学习的概率pr(t)
5)通过执行式(16)的学习算子生成新的解
6)if 0≤rand()≤pr(t)
7)通过随机学习算子生成新的解
8)elseif rand()>pr(t) and fi(t)>favg(t)
9)通过个体学习算子生成新的解
10)elseif rand()>pr(t) and fi(t)≤favg(t)
11)通过社会学习算子生成新的解
12)end if
13)计算新的个体的适应度,更新IKD和SKD
14)end for
学习过程流程图如图3所示。
在图3中,用算法是否达到最大迭代次数来表示学习目标是否完成。
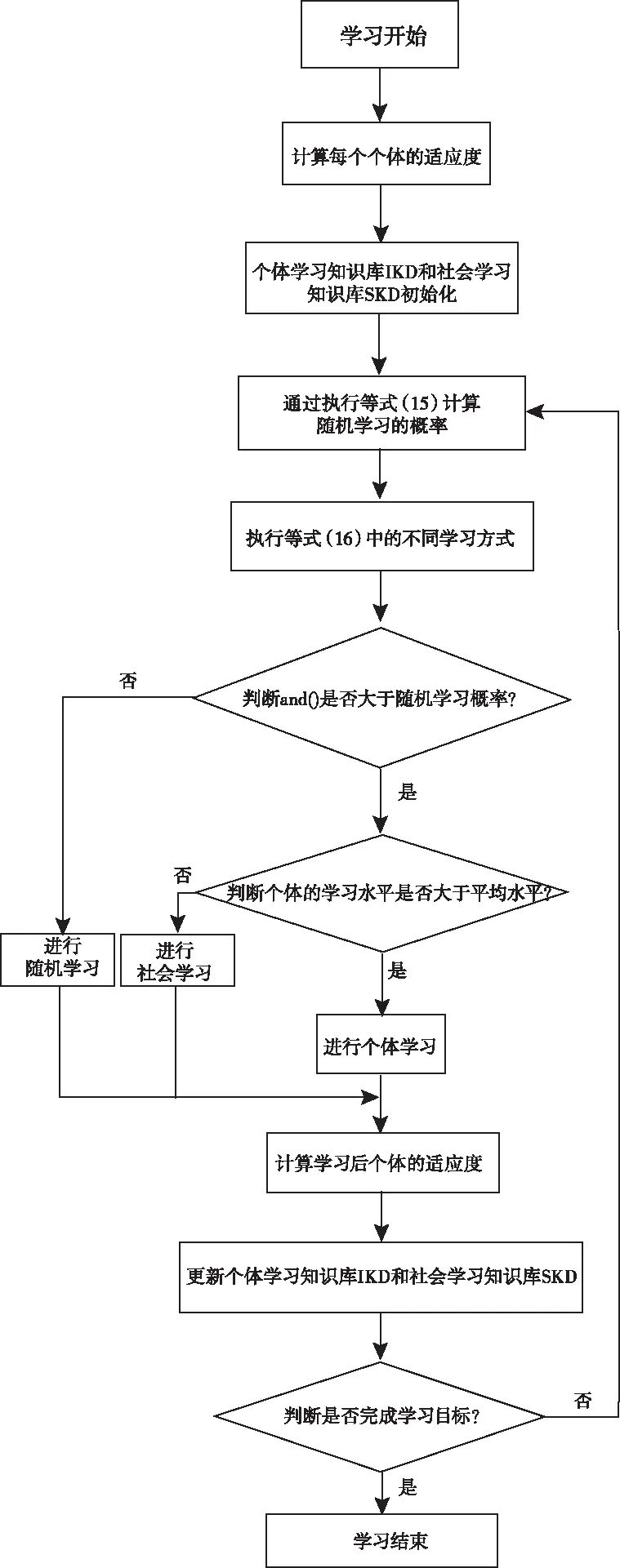
图3 学习过程流程图
4 数值实验
采用三组实验,测试新型人类学习优化算法的性能,并将其和遗传算法(Genetic Algorithm,GA)[14]、微粒群优化算法(Particle Swarm Optimization,PSO)[15]、最有价值球员算法(Most Valuable Player Algorithm,MVPA)[16]和人类学习优化算法(Human Learning Optimization,HLO)[11]的计算结果进行比较。
在第一组实验中,需求点规模为50个,备选设施点规模为30,考虑新建设施点数量分别为2个和3个两种情况;在第二组实验中,需求点规模为100个,备选设施点规模为50,考虑新建设施点数量分别为3个和4个两种情况。第一组实验中候选设施点和需求点的位置在[1,50]内均匀分布,第二组实验中候选设施点和需求点的位置在[1,100]内均匀分布,两组实验的人口数量均在[1,100]内随机生成。广义最大覆盖模型中的参数α=0.5。新型人类学习优化算法的参数设置如下: 群体规模为20;随机学习概率的最大值为0.9,最小值为0.1。遗传算法、微粒群优化算法、最有价值的运动员算法和人类学习优化算法的参数根据对应文献进行设置。为了公平起见,这些算法设置相同的函数评价次数,分别为1200次和1500次。实验环境为intel(R)core(TM)i5-8265U cpu@ 3.4Ghz处理器,内存为8G,采用matlabR2016编程实现算法。实验结果如表1和2所示。

表1 50个需求点和30个备选设施点的算法结果比较
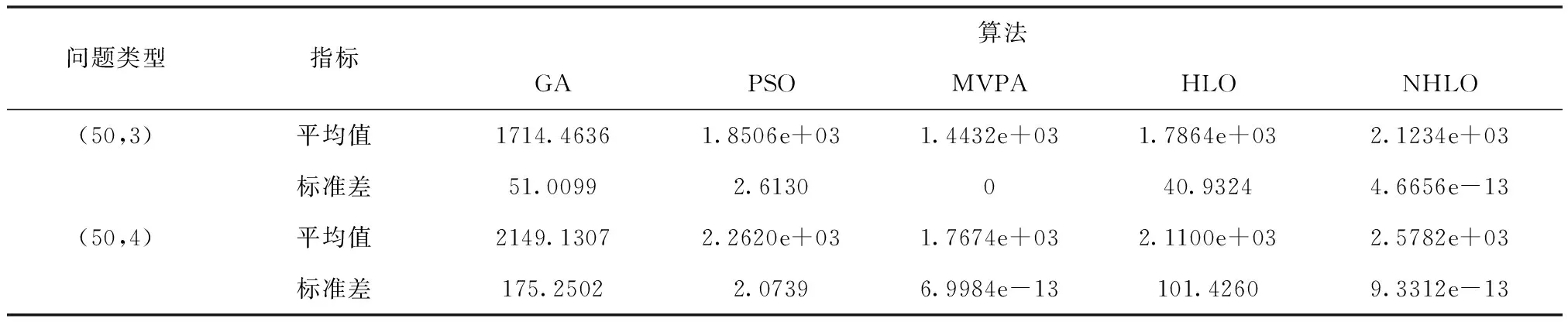
表2 100个需求点和50个备选设施点的算法结果比较
从表1和2中可以看出,相比于其它四种算法,新型人类学习优化算法平均值较高,具有较高的计算精度。此外,本文算法的标准差较小,表明该算法更稳定。在新算法中,随机学习概率逐步降低,算法由全局勘探向局部搜索转变。与此同时,算法根据个体自身寻优能力,选择个体学习算子或者社会学习算子对含有高质量解的区域进行精细化搜索。随着优化过程的进行,算法不断向最优解不断逼近。
第三组实验采用文献[17]中算例:某地有12个社区,7个候选设施点,规定最小距离为5km,最大距离为10km,7个候选设施点到12个社区的距离(km)和12个社区的人口数量(千人)如表3所示。利用新型人类学习优化算法给出具体的广义最大覆盖模型分配方案。

表3 候选设施点到社区的距离(km)和各社区的人口数量
在实验中,分别考虑从7个候选设施点建3个和4个设施点两种情况。除最大函数评价次数变为500,新型人类学习优化算法其它参数设置保持不变。此外,还采用传统覆盖选址模型求解上述问题。实验结果如表4和表5所示。

表4 建3个设施点时两种模型的覆盖情况

表5 建4个设施点时两种模型的覆盖情况
从表4和5中可以看出,当建3个设施点时,传统覆盖选址模型的平均覆盖率为0.7651,完全覆盖的社区有第7个,部分覆盖的社区有第3个,没有任何覆盖的社区有2个。而广义最大覆盖选址模型的平均覆盖率为0.9824,完全覆盖的社区有10个,部分覆盖的社区有2个,不存在没有任何覆盖的社区。当建4个设施点时,传统覆盖选址模型的平均覆盖率为0.6969,完全覆盖的社区有第4个,部分覆盖的社区有第6个,没有任何覆盖的社区有2个。而广义最大覆盖选址模型的平均覆盖率为0.9912,完全覆盖的社区有11个,部分覆盖的社区有1个,不存在没有任何覆盖的社区。
通过上述结果可以发现,广义最大覆盖模型不仅可以给出选址方案,而且可以考虑所有需求点的覆盖水平,通过覆盖水平提高整体服务质量,为设施选址提供了一种有效模型。
5 结论
为有效求解广义最大覆盖模型,在基本人类学习优化算法的基础上,设计自适应学习策略,提出一种新型人类学习优化算法。将所提出算法和遗传算法、微粒群优化算法、最有价值球员算法以及人类学习优化算法进行比较。实验结果表明新算法的优化搜索能力更强,能显著提高问题的计算精度,为求解广义最大覆盖模型提供了一种有效方法。将新算法用于多目标覆盖选址问题是下一步的研究方向。
