高速公路上无人驾驶汽车目标检测算法的研究
2023-03-11屈乐乐
葛 雯,马 乐,屈乐乐
(沈阳航空航天大学电子信息工程学院,辽宁 沈阳 110136)
1 引言
道路交通事故发生频率不断增加使人们逐渐正视交通安全问题,如不采取有效措施来提高交通安全质量,人身安全将会受到巨大的威胁。近年来,由于深度学习技术取得了突破性进展,计算机视觉及工业自动化技术也得到了显著提升。尤其在智能汽车领域,无人驾驶更是得到广泛的关注。在无人驾驶的系统中,目标检测能够为无人驾驶车辆提供安全保障,是重要的关键技术。随着科学技术的发展,深度学习逐渐成为目标检测领域最有效的方法之一,随之而来的卷积神经网络也成为了具有代表性的神经网络之一。卷积神经网络具有较强的自主学习、并行处理和容错能力,其代表算法有:R-CNN[1]、Fast R-CNN[2]、Faster R-CNN[3]、SSD[4]、YOLO[5]等。本文将SSD模型进行了改进,对高速公路环境下无人驾驶中的图像数据进行学习训练及目标检测,并通过仿真实验验证了该模型的检测效果,能够满足对大量图片数据进行准确、高效的目标检测需求,为无人驾驶汽车目标检测技术提供参考价值。
2 SSD目标检测算法
截至目前,SSD是最有效的主流目标检测框架之一,它将目的框的输出空间离散成一组具有不同形状和尺寸的默认框。SSD继承YOLO的回归思想,能够一次性完成目标的定位及分类,还继承了Faster R-CNN的Anchor机制。采用回归思想能够将复杂的神经网络计算化为简单的回归问题,从而提高算法的运行速度及实时性;采用Anchor机制能够达到在不同尺寸的特征图上产生不同预测的效果,从而提高检测的精度。与此同时,SSD采用基于特征金字塔(Pyramidal Feature Hierachy)的检测方法,即能够达到在不同感受野的特征图上预估目标,从而取得良好的检测结果。相比于Faster R-CNN,SSD更具有实时性,而相比YOLO,其mAP也得到了显著的提升,其在VOC2007数据集上的性能对比如表1所示。
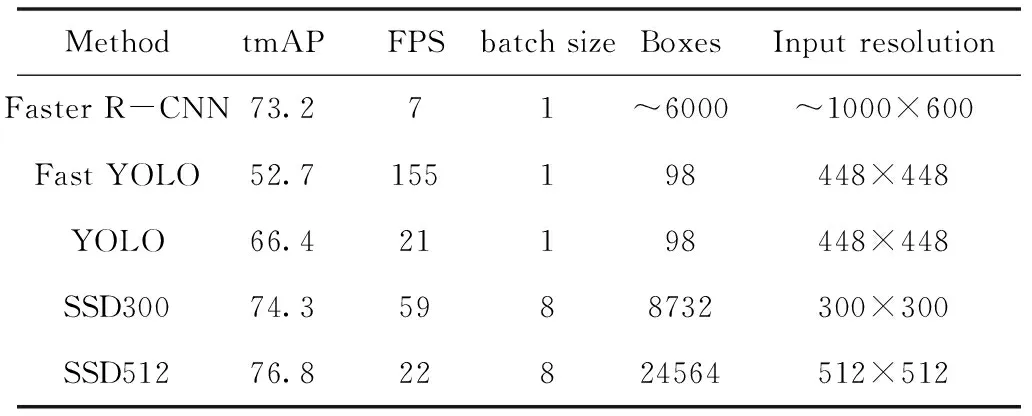
表1 Faster R-CNN、SSD、YOLO性能对比
2.1 SSD网络结构
SSD以检测速度快、准确率高等优点进入大众的视野,是一种单次检测的深度神经网络。它在YOLO的基础上进行了改进,将特征提取从整个特征图缩小到局部。SSD网络结构包括基本网络、辅助卷积层和预测卷积层,并以VGG16(visual geometry group)作为基本的网络模型,之后在VGG16中加入不同的卷积层,从而得到不同尺度的特征图,用于目标检测。VGG16作为基本模型,首先在ILSVRCCLS-LOC数据集上对模型进行预训练,然后利用DeepLab-LargeFOV将两个完全连通的层(fc6和fc7)替换为普通的3×3和1×1卷积层(conv6和conv7)。在此基础上,再增加几个新的卷积层。其中,在检测初始特征图时需要利用conv4_3卷积层,随后从新增加的卷积层中提取部分卷积层用于检测其它特征图,最终产生1*1的输出。SSD300网络结构图如图1所示。

图1 SSD网络结构图
2.2 默认框(default boxs)尺寸的确定
SSD采用了Faster R-CNN中anchor的机制,能够把每一个特征图转化成不同尺寸、不同长宽比的默认框,预测框会以这些默认框为基准进行目标的预测,从而降低样本训练难度。默认框是在某一个特征图上每一点处选取的长宽比不同的选框,以特征图上的每一个点的中心为中心,能够产生一系列同心的默认框。多数情况下,每个特征图将首先设置一些不同大小和不同纵横比的默认框。默认框的设置包括两个方面:尺度和纵横比。在每个特征图中设置的默认框的数量是不同的。每个特征图的默认框的大小遵循线性增加的原则,即默认框的大小随着特征图尺寸的减小而线性增加,其计算公式如式(1)所示
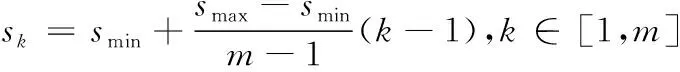
(1)
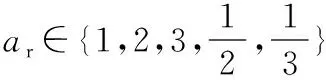

(2)
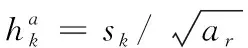
(3)
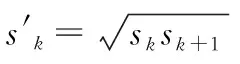
2.3 传统 SSD模型存在的问题
1) 分类网络输入的唯一来源是不同层的特征图,这样可能会导致同一个物体被不同尺寸的框同时检测出来,从而使检测结果不准确;
2) 模型中正样本与负样本极其不均衡,使模型训练困难,模型的准确度略低;
3) 由于SSD模型使用了conv4_3低级特征卷积层来检测较小的目标,缺少高级层的语义特征,存在特征提取不完整的问题,导致对小尺寸的物体检测效果不佳;
4) SSD网络中default boxs的基础大小和形状不能直接通过学习获取,必须要手工设置。每一个特征卷积层所使用的默认框的尺寸和形状都是不同的,在后期的调试带来了极大的难度,尤其依赖工程师的经验。
3 改进SSD模型的设计与优化
针对传统SSD算法以VGG16或VGG19作为基础网络,通过不同层的特征来对目标进行检测,使其对尺寸的变化有较好的鲁棒性,但在计算过程中参数较多、计算量较大,容易出现误检、漏检等问题。本文引入DenseNet网络模型,加强层与层之间的特征传播,减少参数量的同时也减少了计算量,该网络模型能够有效地缓解梯度消失的问题,使图像特征向更深层次传播。除此之外还结合了空洞卷积(Dilated-Convolution)改进DenseNet网络模型,构成D-DenseNet网络模型,以此代替传统SSD算法中的VGG16,从而提高模型的检测速度和准确度。
3.1 DenseNet模型分析
DenseNet模型在ResNet模型基础上做出创新,是近两年新兴的模型结构,由于连接方式的改变,使其相比于ResNet在各大数据集上都取得了更好的效果。DenseNet不通过增加网络层数、扩宽网络结构来提高网络的性能,它通过特征重用和旁路设置,提高了特征的传播效率和利用效率,减少了网络的参数量,又在一定程度上缓解梯度消失的问题,是一种前馈方式的密集连接型网络。
假设输入图片为X0,经过一个M层的神经网络,其中第i层的非线性变化记为Hi(*),Hi(*)是各种函数的累加,如:ReLU、BN或Conv等。如果第i层的特征输出表示为Xi,则DenseNet的非线性变换方程如式(4)所示:
Xi=Hi([X0,X1,…,Xi-1])
(4)
例如在DenseNet-121中,第i层的非线性变化采用BN、ReLU激活函数及Conv(3×3)卷积的相结合的连接方式,在加强网络各层之间的信息交换的同时,还提高了网络的训练效率,其网络参数如表2所示。

表2 DenseNet-121网络参数
DenseNet网络共分为两个组成部分:Dense_Block和Transition Layer,每个Dense_Block中特征图的尺寸都相同,再对特征图进行拼接。Transition Layer设置在相邻两个Dense_Block之间,负责进行下采样。过渡层包含多种函数的累加、1×1的卷积层及2×2的平均池化层,在网络中,过渡层会把输入到该层的特征图数量减少到原来的一半,从而在一定程度上减少计算量。
3.2 改进SSD网络模型
本文用改进的D-DenseNet-121代替传统SSD模型中用于图像特征提取的映射卷积层,不仅能够提高对目标的识别精度,还能极大程度的提高模型的运算速度。DenseNet-121首层为3×3的卷积层,之后输入的图像数据再经过4个Dense_Block,依次为6层、12层、24层、16层,每两个Dense_Block之间采用非线性变换BN+ReLU6+Conv(3×3)的组合。
为了提高卷积层对小目标的检测精度,引入反向残差结构来减少学习过程中非线性变换在低维度中的特征信息损失。为了避免池化操作中特征信息丢失,本文将采用空洞卷积来替代卷积层中的下采样操作,并将激活函数ReLU更换为精度更高的ReLU6,ReLU6激活函数数学形式如式(5)所示
ReLU6=min(6,max(0,x))
(5)
多尺度信息在目标检测中起到至关重要的作用,在空洞卷积中,可以设置不同的参数来扩大感受野,从而获得更多多尺度信息,这样能够精准定位目标,保证检测精度。图2显示了卷积核尺寸为3×3,扩展率为2的空洞卷积操作,其感受野的大小为
F2=(22/2+2-1)×(22/2+2-1)=7×7
在模型训练过程中,BN算法可以加快模型训练的收敛速度,使训练过程更加稳定,防止梯度爆炸和梯度消失的情况发生,还能起到正则化的作用。
在DenseNet之后,有四个卷积层,包含了1×1和3×3的卷积层。选取最后两层Dense_Block和4个卷积层进行目标框的选择。优化后的网络模型简单,能够充分利用特征信息,提高小目标的检测精度,优化后的网络模型如图3所示。
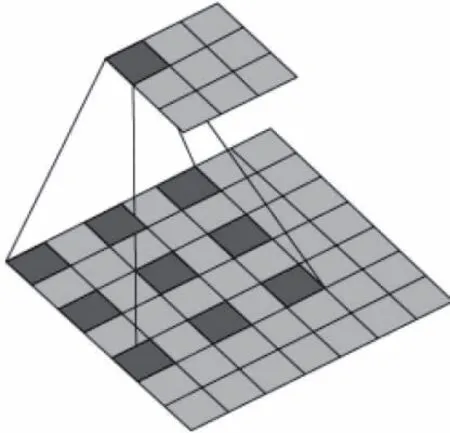
图2 空洞卷积操作
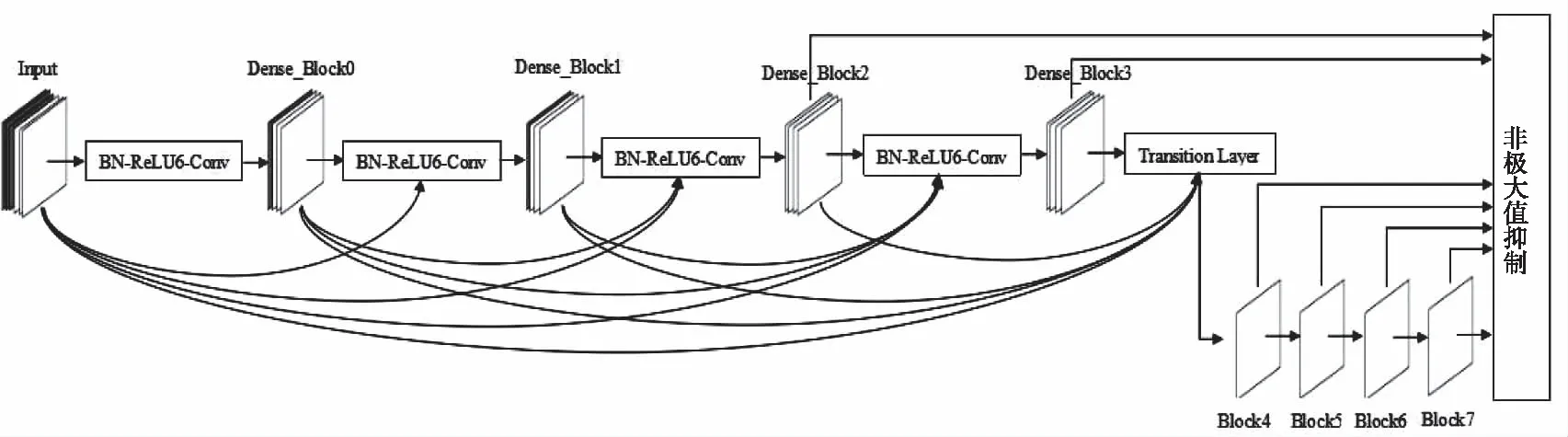
图3 优化后的网络模型
3.3 损失函数
损失函数可以用来衡量前期估计的值与实验中真实值的误差,在所有算法中损失函数即为最终需要优化的目标函数。
在SSD算法中,损失函数由两部分组成,分别为定位损失和置信度损失,如式(6)所示
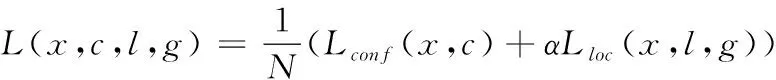
(6)
其中,N为筛选过后默认边界框的数量;c是经过处理后的定位置信度;l为预测框的位置预测值;g就是真实框的位置值;α为可自己设置的权重系数,通常将其设置为1;x为匹配系数,x∈(0,1)。当x=0时表示预测框与Ground Truth不匹配;当x=1时表示预测框与Ground Truth完全匹配。Lconf(x,c)为置信损失函数;Lloc(x,l,g)为定位损失函数。
定位损失函数Lloc(x,l,g)是预测框与真实物体框参数之间SmoothL1损失,其计算公式如式(7)所示
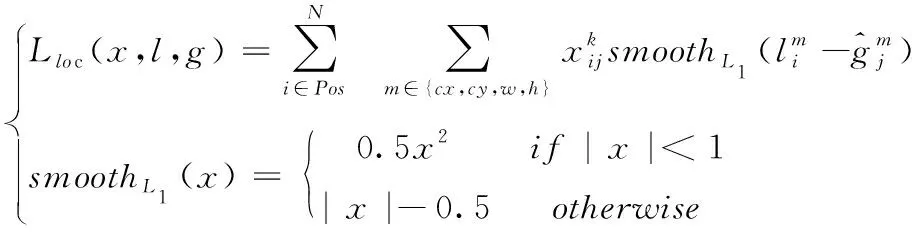
(7)
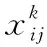
通常采用Softmax loss函数对置信损失Lconf(x,c)进行计算,如式(8)所示
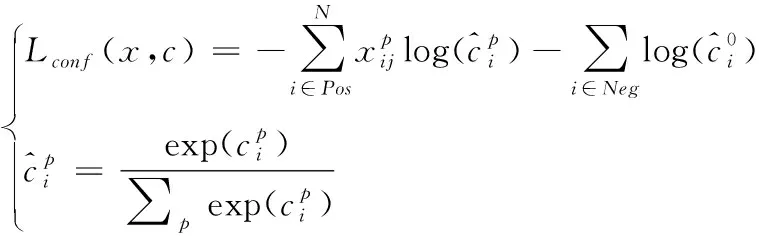
(8)
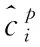
目标损失函数对正负样本比例进行了相关控制,不但能够提高算法优化的速度,还能提高训练结果的稳定性。
4 实验与结果分析
4.1 实验平台
本次实验的仿真环境为:计算机Win10操作系统,CPU型号为Intel(R) Core(TM) i5-9400F。在以上硬件的基础上搭建Pytorch机器学习平台,采用Python3.8编程语言对相关模型进行训练和测试,从而实现适用于无人驾驶汽车的目标检测算法。
4.2 数据样本结构及模型训练
数据集是通过采集高速公路上道路情况的截图,标注了高速公路上行驶的过程中包含汽车、人、动物等7类标签的样本图片,并且结合了目标检测中常用的V0C2012数据集中含有相同标签的样本图片,共包含1150张图片。为了减少训练中的过拟合现象,提高数据集的质量,本文在此基础上进行数据样本扩展,具体实现方式如表3所示。
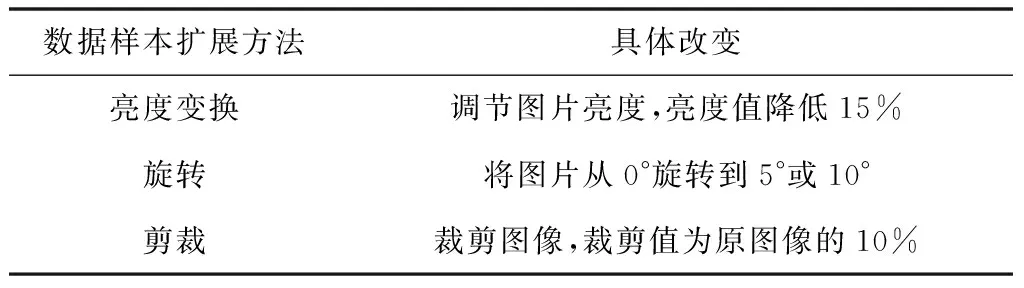
表3 数据样本扩展方法
通过表3的方法对数据集进行扩展,扩展后的数据集为2500张,扩展数据集由2000个训练集和500个测试集组成。然后使用Labellmg软件对数据集进行标记和注释。
在训练过程中,该算法进行了40000次迭代,初始化学习率base_lr=0.001,批尺寸batch_size=8,权重衰减因子设为0.0005,在一定程度上预防训练过程中出现过拟合现象。在数据集训练的过程中,损失值随着迭代次数的增加而收敛。最后,经过35000次迭代,训练模型的损失值趋于稳定。
4.3 结果分析
利用训练好的网络模型对数据集进行检测实验。从检测结果中看出,改进后的SSD网络模型平均准确率均值达到83.82%,检测速度为42fps。在同一数据集上,对本文提出的改进后的SSD网络模型与其它网络模型、原始SSD网络模型进行测试及对比试验。实验结果如表4、表5所示。
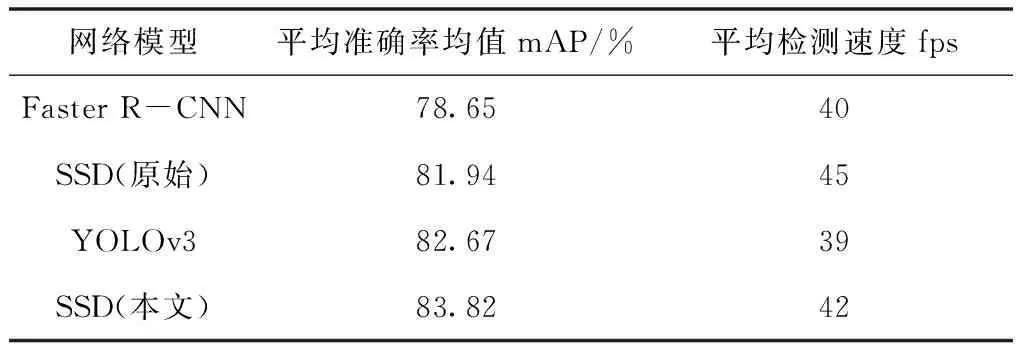
表4 不同网络模型实验结果
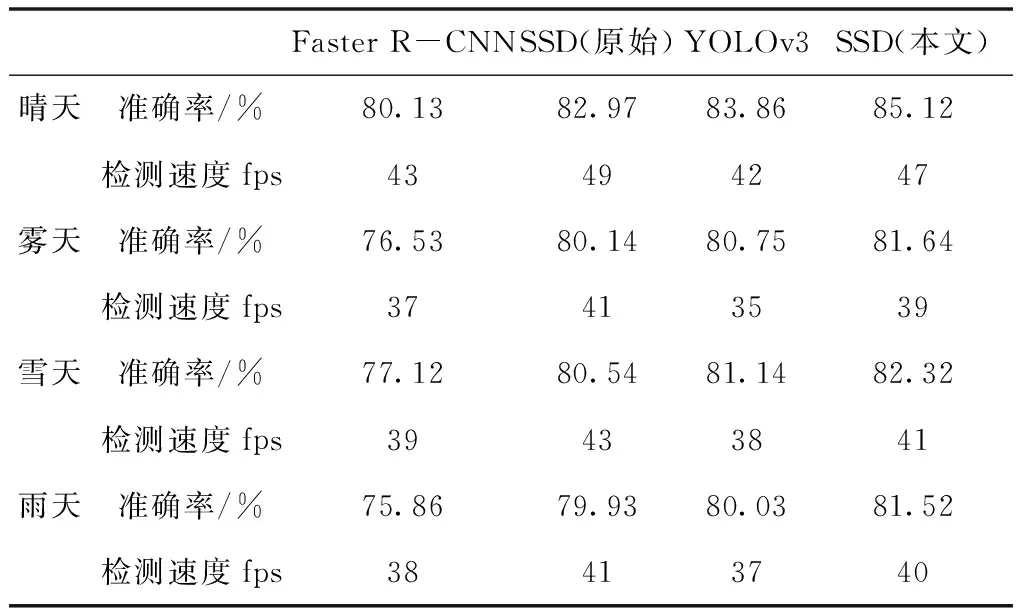
表5 不同网络模型在不同天气、场景下实验结果
由表4可知,本文改进的SSD模型的mAP为83.82%,Faster R-CNN模型的mAP为78.65%,YOLOv3模型的mAP为82.67%,原始的SSD模型的mAP为81.94%,结果表明改进后的SSD网络模型准确率更高,从检测速度分析,本文的检测速度虽然比原始SSD模型检测速度慢,但能够达到应用要求。因此,改进的SSD模型在无人驾驶中对目标的检测性能更好,四种网络模型在不同天气、场景检测效果如图4所示。

图4 不同网络模型结果对比
5 结论
为了更好的保证无人驾驶系统的安全问题,本文结合传统的SSD算法与DenseNet模型的优势,引入D-DenseNet网络模型,提高了网络的深度。前置网络采用DenseNet代替传统SSD网络中VGG16进行特征提取,使各层的网络信息得到充分的利用,有益于网络的训练。辅助层网络利用空洞卷积替换下采样操作从而避免信息的丢失,同时还能提高对体积较小物体检测的准确性,进一步提高了系统的检测速度和准确度。实验表明,本文改进后的算法相较于其它算法具有一定的优越性,能够运用于无人驾驶中的目标检测技术中。在接下来的研究中,将增加更多复杂场景的数据集,完善数据集的多样性,进一步提高算法的鲁棒性。
