智能全景视觉传感网络视频多目标跟踪仿真
2023-03-11高智勇乔姝函
高智勇,乔姝函
(山东农业大学信息科学与工程学院,山东 泰安 271018)
1 引言
随着互联网的普及和智能时代的到来,视觉传达技术得到了飞速发展,逐渐占据了视频图像处理领域的主导地位,并被广泛应用在影视传媒和视频动画等方面[1]。后继帧视频图像是网络视频活动影像的重要组成部分,对后继帧网络视频图像进行多目标跟踪是视频制作中的重要环节。因此,如何利用视觉传感技术,对网络视频进行多目标跟踪成为了该领域的重点研究问题。网络视频中包括多种目标元素,利用视觉传感技术对网络视频的运动目标元素的状态进行跟踪,并对其状态进行估计[2]。但是当网络视频图像的多目标元素信息较为复杂时,传统的视觉传感技术获取的网络视频目标元素较为单一,得到的样本量较少无法实现对其状态的估计,还会受到周遭复杂环境的影响,很难保证采集的多目标元素样本信息的准确度,直接影响网络视频多目标跟踪结果的精度[3]。因此对网络视频多目标跟踪进行仿真,有效提高对网络视频多目标元素跟踪的精度,这对该领域的发展具有深远的现实意义。
陈国军等人[4]提出了一种基于深度学习的水下机器人多目标跟踪方法。首先利用水下机器人采集水下环境视频中的图像信息,根据卷积神经网络的结构层次,处理了采集的图像信息,对图像的深度信息进行精细计算,仿真结果显示,该方法可以更准确地获得水下机器人采集的图像信息,提高了多目标跟踪的精度,但是跟踪效果较差。张明月等人[5]提出了一种基于线性分析和卷积神经网络结合的网络视频多目标跟踪算法。在卷积神经网络的基础上,对已经采集的图像样本进行优化改进,利用利用线性网络对网络视频跟踪获取的目标进行特征表达,采用深度学习方法对其进行迭代计算,实现对不同跟踪区域的样本数据之间的去冗处理,在与传统的方法对比表明,改进的算法可以有效提高网络视频多目标跟踪的准确度。
基于以上研究背景,本文设计一种网络视频多目标跟踪方法,从而提高网络视频多目标跟踪的性能和效果。
2 网络视频多目标跟踪方法设计
2.1 获取网络视频图像多目标区域
假设,在时刻t内,网络视频图像(x,y)的像素值为I(x,y,t),那么在t+1时刻,像素值为I(x,y,t+1),利用式(1)给出,时刻t与时刻t+1之间网络视频图像的像素值差值
ΔI(x,y)={I(x,y,t+1)-I(x,y,t)}
(1)
对上述的式(1)进行归一化处理,获得网络视频图像的权值T,利用映射原理[6],获得网络视频图像多目标可能存在的区域为
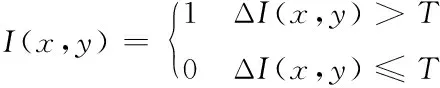
(2)
利用智能算法对网络视频图像目标的运动信息进行迭代处理[7],得到网络视频图像的像素点(x,y)在时刻t的属性信息为I(x,y,t),此时,利用下式给出网络视频图像的差分方程
uIx+vIy+It=0
(3)
上式中,网络视频图像的属性信息I(x,y,t)在x、y、t方向上的微分分别为Ix、Iy、It,u和v表示微分系数。
利用卷积神经网络[8],获取网络视频的多目标跟踪信息
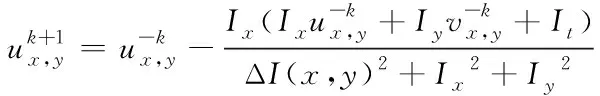
(4)
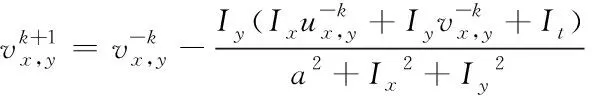
(5)
通过上述式(4)和(5),实现对网络视频图像多目标跟踪信息的分割
Energyd(Ii,Cj)=((u)2+(v)2)1/2
(6)
结合形态学分析法,有效降低聚类分析区域的非跟踪目标数量,消除非必要跟踪区域[9],得到有效识别的网络视频图像多目标区域
j=min{j/d(Ii,Cj)}≤θ1
(7)
式中,θ1表示网络视频图像中两个像素点之间的最大距离,Ii表示网络视频中的非零像素,Cj表示网络视频中的零像素。
根据以上过程,获取网络视频图像多目标区域。
2.2 采集网络视频多目标特征
智能全景视觉传感技术被越来越广泛地应用在获取网络视频中的目标信息上,虽然目前的智能全景视觉传感技术可以实现对网络视频多目标信息的分析和处理,但是还没有实现网络视频图像的自主目标跟踪。基于全景视觉传感技术,采集网络视频的多目标特征,对网络视频图像多目标特征选择的过程如下式
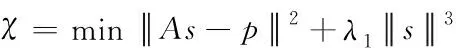
(8)
式中,A∈K×(m+n)表示多帧网络视频图像的转换图像。根据深度学习,构造其校验字典。m和n分别代表网络视频图像的采集样本个数,网络视频图像的特征信息用K表示,s为网络视频图像的特征向量,a代表加权系数,λ1为网络视频图像的属性信息。p∈m+n代表网络视频图像中每个原子的属性信息,则得到网络视频图像的投影矩阵表达式为
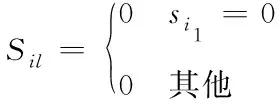
(9)
上式(9)中,si1表示网络视频图像特征向量s内的第i1个特征因子,利用深度学习字典完成对网络视频目标特征的采集[10],网络视频图像降维后,得到的字典A′和多目标特征状态x′的关系表达式如下
A′=SA,x′=Sx
(10)
根据上述的式(10)可以得到K维网络视频图像的目标特征识别结果,通过对网络视频图像目标特征的估计,得到估计值为O1:t={o1,o2,…,ot},用来表示当前网络视频图像中多目标特征的状态,利用下式(11)完成对多网络视频多目标状态xt的核验

(11)
式中,p(xt∣xt-1)表示网络视频图像中两个相邻运动目标之间的关系,p(xt-1∣O1:t-1)表示在t-1时刻下网络视频目标特征状态xt的核验概率,p(ot∣xt)表示的是关联函数,代表网络视频采集样本图像信息与目标特征之间的关联关系。利用高斯分布,构建网络视频的多目标运动模型[11],表达式如下
p(xt∣xi-1)=N(xt,xt-1,ψ)
(12)
其中,N(·)表示高斯分布,ψ表示协方差矩阵,xt-1表示网络视频多目标在第j个候选状态下的特征函数表达如下
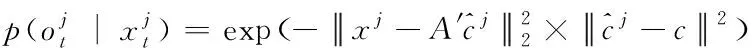
(13)
2.3 设计网络视频多目标跟踪算法


(14)

对上述公式进行归一化处理[13],得到
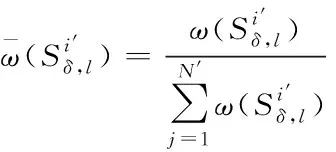
(15)
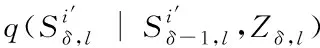

(16)
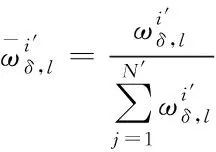
(17)
通过上述的计算,得到网络视频多目标跟踪信息的最优预测值,通过网络视频中每个目标的跟踪信息,获得整个网络视频多目标跟踪信息,将得到的粒子波最优值与上述得到的网络视频多目标跟踪信息进行关联修正[15],实现对网络视频多目标轨迹的跟踪,计算公式如下
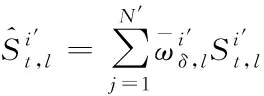
(18)
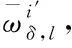
综上所述,将传感网络视频多目标特征作为状态向量,计算并归一化处理状态向量的权值,通过智能全景视觉传感网络中每个视频对应的图像,检测出多目标元素,对状态向量权值和目标位置关联,设计了网络视频多目标跟踪算法,实现了网络视频的多目标跟踪。
3 仿真设计与结果分析
3.1 样本选取
为了验证文中多目标跟踪方法在实际应用中的性能和效果,选取网络视频不同帧的属性信息作为实验样本,如表1所示。
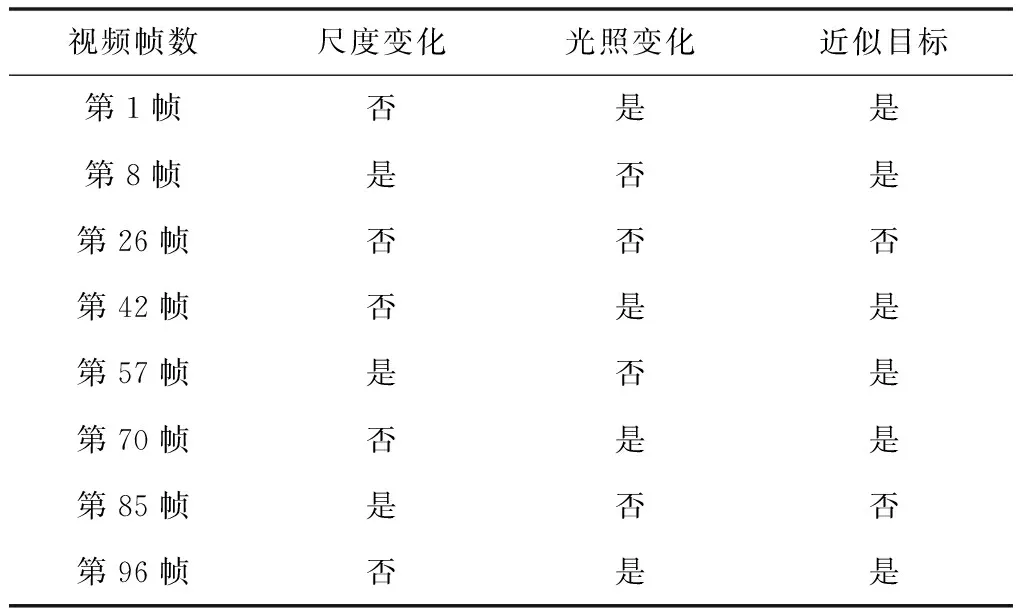
表1 实验样本的属性信息
3.2 设置实验指标
在智能全景视觉传感网络中,视频多目标跟踪实验分两个阶段进行,先利用成功率和正确率指标衡量网络视频多目标跟踪的性能,计算公式为
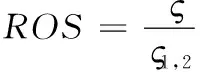
(19)

(20)
其中,ROS为成功率指标,ς表示视频图像特征的正确匹配数,ς1,2表示相邻两个视频图像的正确匹配数,QZ表示跟踪正确率指标,PS表示正确跟踪的网络视频图像帧数,ZS表示跟踪到的网络视频图像总帧数。
接着利用网络视频图像的跟踪速度指标衡量网络视频多目标跟踪的效果,计算公式为
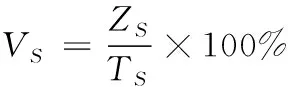
(21)
其中,VS表示跟踪速度指标,TS表示跟踪时间。
3.3 结果与分析
仿真过程中,引入基于深度学习的多目标跟踪方法和基于卷积神经网络的多目标跟踪方法作对比,测试了三种跟踪方法的性能和效果,结果如下。
三种方法的多目标跟踪成功率测试结果如图1所示。
从图1的结果可以看出,在多目标跟踪成功率方面,文中跟踪方法明显高于其它两种跟踪方法,测试得到的跟踪成功率在85%以上,而其它两种方法测试得到的成功率指标最高只有70%和80%,说明文中方法在多目标跟踪成功率方面具有更好的性能。
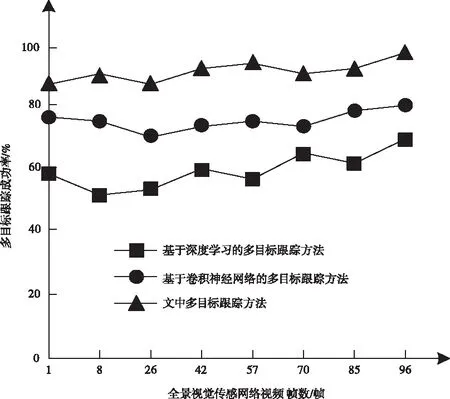
图1 多目标跟踪成功率测试结果
三种方法的多目标跟踪正确率测试结果如图2所示。
从图2的结果可以看出,在多目标跟踪正确率方面,文中方法的多目标跟踪正确率都超过了90%,最大跟踪成功率达到了99.5%,然而基于深度学习的多目标跟踪方法得到的结果在50%~63%之间,采用基于卷积神经网络的多目标跟踪方法时,多目标跟踪的最大成功率为85%,说明文中跟踪方法在多目标跟踪正确率方面同样具有更好的性能。
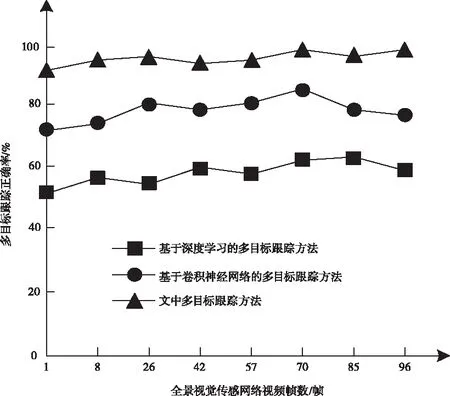
图2 多目标跟踪正确率测试结果
三种方法的多目标跟踪速度测试结果如图3所示。
从图3的结果可以看出,文中方法在多目标跟踪速度方面表现出良好的跟踪效果,在实验初期,多目标跟踪速度在40个/s左右,随后增加到45个/s以上,而其它两种多目标跟踪方法得到的跟踪速度比较低,都在40个/s以下,因此说明文中方法在多目标跟踪速度方面具有较好的跟踪效果。
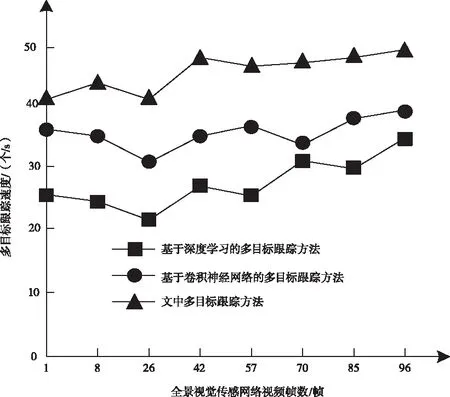
图3 多目标跟踪速度测试结果
4 结束语
本文提出了智能全景视觉传感网络视频多目标跟踪方法,经测试发现,该跟踪方法不仅具有更高的跟踪性能,跟踪效果也得到了进一步提升。但是本文的研究还存在很多不足,在今后的研究中,希望可以在本文的基础上,缩短多目标跟踪时间,从而提高跟踪效率。
