基于知识蒸馏和超分辨率的车道检测算法仿真
2023-03-11舒畅
张 琰,舒畅,王 晶
(1.武昌工学院 信息工程学院,湖北 武汉 430065;2.法国贡比涅技术大学(UTC),皮卡第大区瓦兹省 贡比涅 60200)
1 引言
随着智能汽车概念的提出,以及辅助驾驶和无人驾驶等级的追求,车道线检测成为智能驾驶范畴内的重点技术[1]。依靠车道线检测,可以实现无人驾驶、偏离预警、自主泊车等智能功能。针对不同的功能,车道线检测的精准度等指标有着不同的要求,为了满足最严苛的条件要求,即复杂环境的无人驾驶,必须提出更为有效的车道线检测算法[2]。以往的算法往往普适性较差[3,4],需要做大量的测试来验证不同场景下的实际情况,即便如此,也无法保证实际的使用场景安全。
文献[5]对车道图像映射至HSL坐标,利用S通道与Gooch的融合来获取车道线特征。由于该方法是基于灰度图的,对于灰度相近的图像区域没有采取网络学习进行训练区分。文献[6]先找出图像中的ROI部分,采取灰度和平滑滤波处理,再根据OTSU分割出车道线,并结合Hough变换实现车道线准确识别。该算法注重不同光照情况下的适用性,缺乏对拥堵等车道情况的考虑。文献[7]引入Retinex对车道图像做RGB增强,通过灰度化与OTSU完成车道线区域的分割,最后利用边缘检测与Hough提取出车道线。该算法主要针对弱光环境下的车道线检测,对于其它场景,存在一定的局限性。文献[8]根据R、G通道与车道线颜色的关系,对RGB采取阈值限定,用于约束图像的灰度与二值。该算法在光照差异和拥堵等情况下都能获得较好的适用性,但是会由于高亮出现漏检状况。
针对现有研究存在的问题,提出了基于知识蒸馏和超分辨率的快速车道线检测算法。超分辨率是指把已有的细节不清晰的LR图像变换成细节清晰的HR图像,本文利用退化模型对不同场景不同设备的图像退化进行处理,滤除掉其中的噪声,并结合重构完成图像的超分辨率处理。对于不同场景下的车道线检测,利用知识蒸馏与网络学习的结合,完成车道空间与边缘的构建,通过Teacher与Student间的知识迁移,快速实现车道线特征提取。
2 基于先验知识的车道分割
在进行车道线检测的时候,利用网络学习需要解决车道分割所面临的特殊性。首先,车道存在空间特性,车道虽然静止不动,但是其上运动着不同类型的车辆,甚至是人或其它事物,而且随着车道方向的改变,车道的空间特性也将随之改变,给车道线的检测带来困难。其次,在不同道路情况下,车道线和车道边缘并不明显。网络学习是一个根据神经网络,通过卷积与池化操作对样本采取的训练过程。由于样本训练是从无至有的,为了加速训练的收敛速度和收敛精度,在网络学习中,对空间和边缘采取先验知识分割。
通常来说,用于检测车道线的车载摄像头位置相对固定,而车道又可视为静止,于是摄像头拍摄到的车道图像具有一定的空间特征。即图像上方一般为天空,车道位于图像中下方,两侧为车道边缘及物体。以往的学习网络在引进先验知识时,通常只关注图像局部关系,这就导致很难对整个空间关系进行准确划分,从而出现模型或者先验知识出现不匹配的情况。于是这里利用像素信息作为先验依据,来引导网络学习。根据车道图像的横纵坐标,将位置索引描述为(x,y)。对应的像素索引可以通过像素位置特征来描述。假定车道图像的高与宽依次是h、w,则特征图大小是(h,w,2),包含2个通道,依次用于记录行、列索引。
车道边缘由于物体复杂,且很多车道边缘线并不清晰,可能是非铺装路面。此外,对于转弯场景,车道的边缘还会被赋予方向。于是,这里对车道图像的边缘采取八向梯度处理计算。不同方向的卷积核分别表示如下

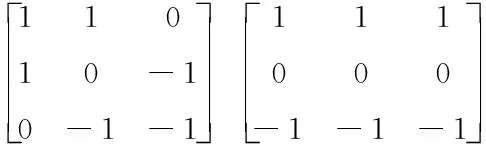

(1)
如果将车道线检测视为车道图像分割问题,那么在采用超分辨率处理后,可以通过像素进行分类。由于只需要判断车道或非车道两种情况,因此可以引入损失函数来判断分类结果。将所有像素作为样本,一幅车道图像在输入网络时的样本数量记为N。当像素i为车道线时,对应的标签li=1,否则li=0。此外,假设像素i被判断成车道线的概率是pi,那么Sigmoid损失函数可以表示为
(2)
由于式(2)对于全部样本的处理是无差别的,而车道线具有空间特性,这就导致在像素分类时缺乏约束。因此这里结合空间信息对Sigmoid进行优化。如果训练集中包含的样本数量为M,那么通过对坐标(xi,yi)处的像素计数,可以得到处于车道上的像素量nxi,yi。进而能够确定坐标(xi,yi)处像素先验概率为pi,0=nxi,yi/M。将所有位置都统计完成之后,便形成一个概率图,表示为C={pi,0|ii}。在大部分情况下,车道图像的划分都比较相似,因此,先验概率具有普适性。利用概率图C来估计像素是否为车道线,将任意像素分为两种情况分析。引入估计阈值H,当像素位于车道线上时,即有pi>H,此时先验损失函数为
Si,0=eαpi,0(H-pi)log(pi)
(3)
其中,α为常量系数。当像素不位于车道线上时,先验损失函数描述如下
Si,0=eα(1-pi,0)(pi-H)log(1-pi)
(4)
综合上述两种情况,得出最终交叉熵损失函数如下
(1-yi)eα(1-pi,0)(pi-H)log(1-pi)]
(5)
3 超分辨率与知识蒸馏网络设计
知识蒸馏是在模型压缩基础上提出的[9],它的引入能够把原来规模很大的网络学习迁移至规模很小的网络内。此过程不仅没有损失原来网络的性能,还能够显著减少网络参数[10]。在蒸馏网络中,拥有知识的一方是Teacher,学习知识的一方是Student。本文将网络分为两个过程与两个模型。两个过程依次代表训练和测试;两个模型依次代表退化和重构。在样本训练时,输入的I0先经过退化处理,得到的I0L再进行重构处理,继而得到超分辨率图像[11]。在进行测试时,I0利用训练完成的重构模块内得到I0R。
3.1 退化模型
在使用光学拍照时,都会由于抖动而形成SR退化。即便是在同样设备和同样场景下,一次得到的图像退化核都是不一样的。而且根据研究结果,退化核对图像分割的干扰超过先验知识。因此准确得到退化核至关重要。退化模型设计为两级,第一级负责把I0转化为I0L;第二级负责确定图像分布情况。在第一级中,采取五隐藏Conv设计,为了保证退化核内部功能,卷积核尺寸分别是7×7、5×5、3×3、1×1、1×1。在第二级中,采取六层设计,卷积核尺寸分别是7×7、1×1、1×1、1×1、1×1、1×1、1×1。归一处理与损失函数计算均部署在该级。对于任意像素的输入图像,经过第二级处理后得到相应的Heatmap。Heatmap中的位置即代表输入块,像素即代表块间的学习概率。退化目标函数表示如下
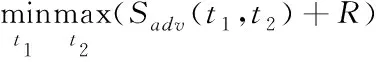
(6)
其中,Sadv(·)表示损失;t1表示第一级;t2表示第二级;R表示退化核正则。退化过程中,应该符合如下正则条件
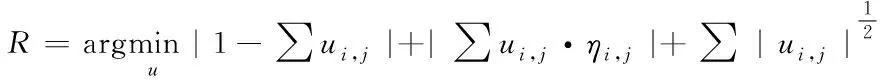
(7)
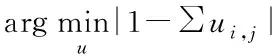
3.2 重构模型
重构的主要任务是实现知识蒸馏。但在这之前,需要对退化输入图像进行放大处理,放大处理后的图像标记为IE,通过单次卷积得到IE的粗略特征
f0=Cmonolayer(IE)
(8)
Cmonolayer表示单层卷积。基于粗略特征f0,通过多次卷积迭代计算,得到精确特征
fn=Cn(fn-1)
(9)
Cn表示第n层卷积计算;fn-1表示第n-1层卷积后得到的特征。将该图像输入Teacher网络,原始图像输入Student网络。为了能够满足图像的映射关系,需要构造Teacher与Student间的关系,进而完成知识迁移。知识蒸馏架构设计如图1所示。其中,Teacher与Student依次包含nt与ns个残差组(nt>ns)。这些残差组各自又具有若干通道,可以增加特征信息的搜索,增强学习精度。
Student想要尽可能完整地得到Teacher知识,需要Student在特征处理的过程中,最大程度的接近Teacher亲和矩阵。为此,这里以特征构建三维张量T∈Re×c×s×h。e、c、s依次表示对象、通道、空间三个维度。亲和矩阵是用来描述各种维度间特征联系程度的,对应的蒸馏损失描述如下
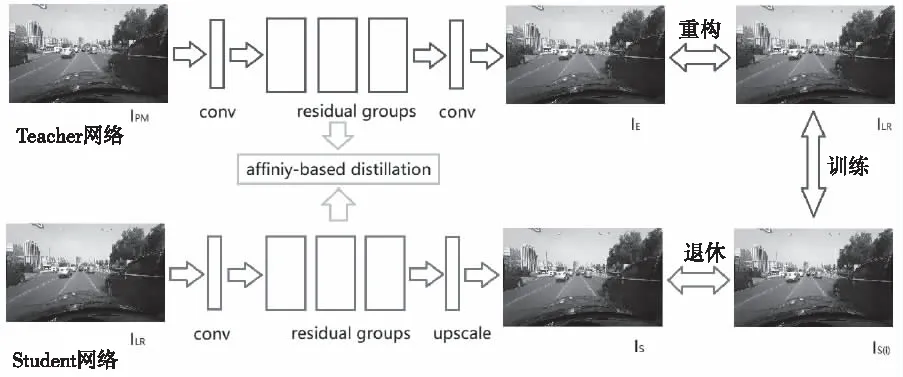
图1 知识蒸馏框架
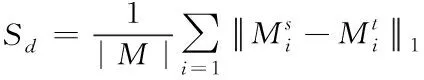
(10)

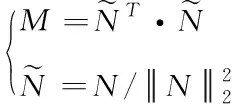
(11)
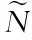
为了有效增强知识蒸馏网络的学习效果,采用Teacher监督,对Student模型退化结果与输入图像做对比;采用数据监督,对Teacher模型结果与输入图像做对比。最终实现对Student模型的监督,损失函数描述为:

(12)
其中,λ1、λ2、λ3、λ4代表监督权重;IT(i)代表Teacher模型图像结果;IS(i)代表Student模型图像结果;ILR(i)代表原始输入的粗糙图像。通过(12)式,Student模型能够更好的获取Teacher模型知识。
4 仿真与结果分析
4.1 仿真环境
仿真过程采用Culane数据集对所提算法进行验证。Culane由多辆道路采集车完成,包含55个小时道路视频,总计133235帧。Culane规模庞大,场景复杂,基本涵盖了当前所有的道路情况,图2列举了Culane的8种场景实例。
基于Python与OpenCV实现本文算法,从Culane中随机选择各个场景的300幅图像用于测试。通过不同场景下的实验结果,验证所提方法的鲁棒性。引入F1-Measure指标对车道线检测性能采取量化分析,其计算公式表示为

图2 Culane场景实例
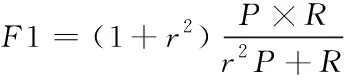
(13)
系数r一般设定成1;P为准确率,根据真正例对真假正例和的比值计算得到;R为召回率,根据真正例对真正例与假负例和的比值计算得到。
4.2 结果分析
针对不同场景的车道线识别结果如图3所示。从图中结果可以看出,无论是拥堵或者夜间,所提算法都能准确检测到当前车道线,几乎不存在漏缺和重复情况。即使是不连续,或者无明显车道的情况,也能够进行合理有效的像素级处理。
为了验证所提方法的性能优势,采用文献[6]、文献[7]和文献[8]方法的作为比较,得到各算法的F1-Measure结果。图4描述了四种算法的平均F1-Measure指标,表1描述了四种算法对于不同场景下的车道线检测F1-Measure指标。根据图4可明显得出,本文算法对于车道线检测的准确性更高,蒸馏网络的错误学习能力更好,有效改善学习效率和精度。根据表1数据比较得出,无论是何种场景下,本文算法都具有良好的通用性,及时在很恶劣的情况下,也能够利用蒸馏网络获得较好的推理能力,从而提高车道线检测的效果。

图3 车道线检测结果
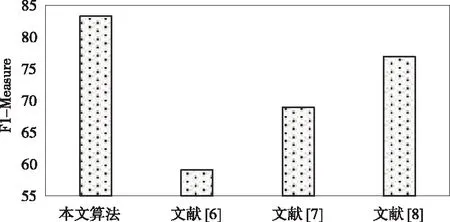
图4 不同算法的F1-Measure对比

表1 不同场景下的F1-Measure对比
5 结束语
针对车道线和车道边缘不明显的情况,在网络学习中,对空间和边缘采取先验知识分割,结合空间信息对Sigmoid损失函数进行优化。采取知识蒸馏完成网络学习迁移,减少网络参数,利用退化和重构实现车道图像的超分辨率特征处理和学习,最终根据网络学习识别出车道线。基于Culane数据集对算法性能进行仿真分析,通过不同场景的车道线识别结果,证明了所设计的知识蒸馏网络具有良好的学习能力,能够利用先验知识推测出尽可能接近真实情况的特征。结合不同算法的量化对比,进一步证明所提算法在车道线检测方面的准确性和鲁棒性。
