基于SMOTE-GWO-SVM模型的储罐底板腐蚀声发射检测智能评价
2023-03-11薛永强刘祥彪徐海丰
李 伟,薛永强,贾 鑫,刘祥彪,徐海丰
(1.东北石油大学 机械科学与工程学院,大庆 163318; 2.中国石油天然气集团有限公司 工程和物装管理部,北京 100007)
随着经济的快速发展,我国对石油能源的需求不断增加,而常压储罐作为石油的专用储存容器,保障其长期安全稳定运行极为重要。储罐所有部位中底板是最易腐蚀但也是最难检测的部位,常规无损检测方法在不开罐的前提下无法对储罐底板进行有效检测和评价,目前声发射检测是储罐底板腐蚀状态在线检测的主要技术之一[1]。依据标准 JB/T 10764-2007 《无损检测 常压金属储罐声发射检测及评价方法》 能够对储罐的底板腐蚀情况做出评价,该标准将储罐底板腐蚀状态划分为5个等级,其中1级最好,5级最差,然而标准中某些关键参数值的确定仍需依靠经验,这给储罐底板腐蚀状况的评价带来了不确定因素,同时限制了声发射检测技术在储罐底板腐蚀检测中的推广应用。
随着机器学习技术的发展,利用机器学习算法、统计方法对数据进行分析,智能化评价储罐底板的腐蚀状态,对摆脱对传统经验的依赖具有十分重要的意义。美国声学物理公司基于其掌握的大量储罐检测数据研发了大型常压金属储罐底板声发射检测专家评估系统(TANKPAC),目前已在全世界进行了大规模应用。国内,陈荣刚[2]通过遗传算法优化贝叶斯网络实现了对储罐底板腐蚀状态的预测,并将储罐的宏观特征作为评价模型的输入特征,提高模型预测的准确率。张延兵等[3]、宋高峰等[4]、刘琪华等[5]等则利用BP神经网络及其优化算法建立了储罐底板腐蚀状态的预测模型,实现了对储罐底板腐蚀等级的预测。
储罐底板腐蚀声发射智能评价系统的建立需要大量的声发射检测数据支持,这不仅对数据的量有要求,数据的分布情况也同样会影响智能评价系统的准确性。储罐底板腐蚀检测数据库中各等级样本分布如图1所示,可见,储罐底板腐蚀状况的实际分布情况往往并不均衡,其中1级(非常微小腐蚀)和4级(存在动态腐蚀)的储罐均只有20台,而大部分储罐的声发射评价等级为2级(存在少量腐蚀)和3级(存在中等腐蚀)。缺陷样本在数据空间分布上存在差异,尤其是在底板腐蚀状态极好和极差的储罐声发射检测数据不足的情况下,往往会造成1,4,5等级的欠学习和2,3等级的过学习,从而降低底板腐蚀状态智能评价系统的准确性。

图1 储罐底板腐蚀检测数据库中各等级样本分布
针对以上问题,在结合专业人员相关经验的基础上,充分考虑了储罐的宏观特征和声发射特征,并以可能的腐蚀导向对特征进行了合理的预处理,同时提出采用过采样技术来优化样本空间,改善数据集的平衡性。过采样技术是一种广泛应用的数据增强方法,其中SMOTE算法是该领域影响力最大的过采样方法,能大幅度改善数据集的平衡性[6],最后结合灰狼算法优化的支持向量机(GWO-SVM),实现对储罐底板腐蚀声发射检测等级的智能评价。
1 SMOTE-GWO-SVM储罐底板腐蚀声发射检测等级智能评价模型
1.1 基于SMOTE算法的样本优化
与试验数据不同,储罐底板腐蚀的现场声发射检测数据非常珍贵,在246个样本数据中,2,3级占83.7%,1,4级均仅占16.3%,存在样本分布不均衡的情况,为提高后续模型的训练效果,采用SMOTE算法对少数类样本进行扩充。SMOTE算法对距离较近的少数类样本进行线性插值生成新的少数类样本,以实现数据平衡[7]。其主要计算过程为:① 对于每一个少数类样本x,计算其到该类中其余所有样本的欧氏距离并得到k近邻;② 根据数据集的不平衡比例设置采样倍率N,从少数类样本x的k近邻中随机选择若干个实例,假设选择的近邻样本为xn;③ 将随机选择的样本xn按照式(1)计算出新的样本,并加入到数据集中。
xnew=x+rand(0,1)×(xn-x)
(1)
式中:x为少数类样本;xnew为生成的新样本;rand为随机函数。
1.2 基于灰狼优化算法的支持向量机(GWO-SVM)智能评价模型
SVM(支持向量机)是一种处理分类和回归问题的监督式机器学习算法。在样本数据量不充足的情况下,与人工神经网络等其他需要大量数据训练的分类算法相比,具有更好的学习效果[8]。对于线性分类问题,其利用间隔最大化求解最优分离超平面;对于非线性分类问题,其通过核函数将原空间的数据映射到新空间,在新的空间里用线性分类学习方法学习分类模型。对于非线性可分的SVM形式可描述为[9]

(2)
s.t.yi(wxi+b)≥1-ξi,i=1,2,1,…,N
(3)

(4)

(5)
式中:w为权值;b为误差;C为惩罚因子;ξi为松弛变量;N为训练样本数;s.t.为约束条件;xi,xj为样本;yi为类别号;K(xi,xj)为核函数;αi为拉格朗日乘子;sgn为判别函数;f(x)为分类决策函数;σ2为核函数参数;g为内部参数,g=1/(2σ2)。
惩罚因子C和核函数内部参数g共同决定了SVM模型的精度,依靠经验确定SVM的参数难以使模型达到最大准确率,因此对SVM的参数C和g进行优化,确定最优值十分重要。
在众多支持向量机的优化方法中,灰狼优化算法(GWO)与其他传统方法相比具有在复杂空间的全局搜索能力,GWO算法是受狼群捕猎行为启发而提出的群体优化算法,优化过程分为以下3个部分[10]。
(1) 包围猎物。狼群在狩猎过程中需要确定猎物位置并包围猎物,用数学方程描述为
D=|SXP(t)-X(t)|
(6)
X(t+1)=XP(t)-AD
(7)
A=2ar1-a
(8)
a=2-2t/T
(9)
S=2r2
(10)
式中:D为灰狼与猎物之间的距离;XP(t)为当前最优解即猎物位置;X(t)表示灰狼当前位置;X(t+1)为迭代至t+1次时灰狼的位置;A和S为系数;r1和r2为在 [0,1] 区间内的随机数;a为收敛因子,随着迭代次数增加从2线性递减到0;T为最大迭代数。
(2) 狩猎过程。在狩猎时,狼群的位置不断变化,此过程在α狼、β狼、δ狼的引导下,计算ω狼群与前3个狼的距离并不断更新位置,接近猎物,此过程的数学描述为

(11)

(12)
Xt+1=(X1+X2+X3)/3
(13)
式中:Dα,Dβ,Dδ分别为α,β,δ狼与其他狼之间的距离;Xα,Xβ,Xδ分别为α,β,δ狼的当前位置;S1,S2,S3,A1,A2,A3为系数;X1,X2,X3为普通灰狼向α,β,δ狼移动的步长;Xt+1为迭代至t+1次时猎物的位置。
(3) 攻击猎物。在最后阶段,狼群攻击追捕猎物即完成寻优过程,获取最优解。在收敛因子a从2线性递减到0的过程中,当|A|≤1时狼群集中攻击,捕获猎物位置进行局部搜索,当|A|≥1时狼群发散,远离猎物进行全局搜索。
1.3 SMOTE-GWO-SVM模型构建
首先利用SMOTE算法处理扩充数据集,实现样本数据的平衡,利用SVM算法进行训练,并采用GWO算法优化SVM算法中的参数,从而得出使储罐底板腐蚀等级评价精度最高的最佳参数,优化评价结果。SMOTE-GWO-SVM模型的流程图如图2所示。

图2 SMOTE-GWO-SVM模型流程图
2 储罐底板腐蚀状态声发射智能评价模型的应用
2.1 数据预处理
储罐声发射检测数据均来源于课题组所依托的国家认证声发射检测实验室近年来进行现场储罐声发射检测所建立的数据库。每条数据有两类特征(宏观特征和声发射特征),共20个特征参数,具体如表1所示。
表1中数据类型复杂,部分宏观特征并不是数值型数据,考虑到不同条件底板腐蚀的情况不同,因此并没有直接采用one-hot编码,而是以可能的腐蚀状况为导向对储罐字符型宏观特征进行预处理,预处理结果如图3所示(腐蚀速率为归一化数值,无量纲)。处理分析如下所述。

表1 储罐宏观特征和声发射特征数据

图3 储罐宏观特征腐蚀导向预处理结果
(1) 储存介质。储罐内的各储存介质对储罐的腐蚀程度不同,重质储罐的腐蚀程度比轻质储罐的腐蚀程度更严重[11]。
(2) 运行温度。对于绝大多数化学反应,反应速率会随温度升高而加快[12]。
(3) 外观腐蚀情况。外观腐蚀情况包括罐壁、罐底边缘板及焊缝腐蚀情况,防腐漆脱落情况等,外观情况较差则储罐腐蚀更严重[13]。
(4) 基础完好情况。储罐基础无防渗层、表面有粘土、底部渗水、沉降等都会加重储罐的腐蚀[14]。
(5) 保温结构。保温层多为疏松多孔结构,易吸水,且保温层下的水分冷凝难以蒸发,与杂质形成电解质溶液更易造成储罐腐蚀[15]。
(6) 材料类别。建造常压储罐所用材料多为低碳钢和合金钢,低碳钢S和P的含量较高,而合金钢添加了Mn,Cr,Ni等耐腐蚀元素,其耐蚀性比低碳钢耐蚀性更好[16]。
(7) 储罐结构。浮顶储罐浮盘支柱与储罐底板接触部位的涂层易受到破坏无法再次涂刷,且浮顶储罐支柱易对底板造成冲击,更易造成储罐底板腐蚀[17]。
预处理后的数据宏观特征和声发射特征之间的量级相差较大,如果不进行无量纲化处理会对后续计算造成较大影响,因此对数据进行了归一化处理,公式为
y=(x-xmin)/(xmax-xmin)
(14)
式中:x为样本值;xmax,xmin分别为样本的最大值和最小值;y为归一化后的值,范围在01之间且无量纲。
储罐宏观特征和声发射预处理后的数据如表2所示(表中宏观特征均已数据化)。

表2 储罐外观和声发射数据预处理后的数据
2.2 智能评价模型应用
为提高模型的训练效果,使用SMOTE算法进行少数类样本扩容,将每个等级各20个原数据集样本作为测试集,其余样本和扩充样本作为训练集,同时,采用GWO优化算法对SVM算法的惩罚因子C和和核数参数g进行优化,以获得最佳模型,经试验,最终寻参结果为C=3.97,g=1.79,图4为SVM参数寻优过程示意。

图4 SVM参数寻优过程示意
为验证SMOTE-GWO-SVM模型用于储罐底板腐蚀等级评价的有效性,将未进行SMOTE处理和SMOTE处理后数据的分类结果进行对照,其中未经过SMOTE处理的数据中1级、4级各10个,2级、3级各20个原数据集样本作为测试集,其余作为训练集。同时与BP神经网络和随机森林(RF)算法进行分类准确性对比,结果如表3所示,各个模型的混淆矩阵如图5所示。

图5 各预测模型的混淆矩阵
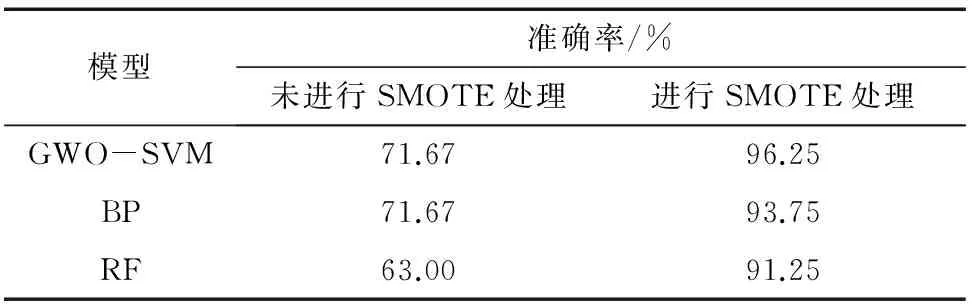
表3 各模型准确率对比
由分析结果可知,在进行SMOTE处理之前,储罐底板腐蚀1级和4级的样本数量较少,模型得不到充分训练,导致这两类数据的分类准确率极低。对数据集进行SMOTE处理后,针对不平衡小样本数据的分类准确率有较明显提升,准确率从71.67%提升至96.25%。
从模型准确率的角度分析,SOMTE-GWO-SVM模型的准确率最高,从模型安全性的角度分析SOMTE-GWO-SVM模型将低腐蚀等级预测为高腐蚀等级,虽然可能会提高后续储罐的维护成本,但是更好地满足了石化行业对安全性的高要求,因此采用SOMTE-GWO-SVM模型对储罐底板腐蚀等级进行预测,可满足企业安全生产和维护要求。
2.3 智能评价结果分析
储罐典型声发射特征参数分布如图6所示(IQR为四分位距),可见,储罐腐蚀情况越严重,声发射参数中的定位事件密度、撞击平均值、能量标准差和振铃计数标准差就越大,这与储罐声发射检测评价标准一致。标准将评定区域内每小时出现的定位数和每个通道每小时出现的撞击数作为储罐底板腐蚀等级的评价依据。从图6也可以看出,不同腐蚀等级的声发射数据存在一定程度的重合区域,对于某一腐蚀等级,储罐个体数据之间可能存在差异,而智能评价模型对多维度数据(声发射特征和宏观特征)进行学习和训练,避免了某个维度数据偏差给整体评价带来影响。

图6 储罐典型声发射特征参数分布
储罐样本不同特征的分布如图7所示,图中储罐的腐蚀等级与储罐的使用年限、运行温度、外观腐蚀情况和储罐基础沉降情况呈正相关。不难理解,储罐服役年限越长,储罐底板累积腐蚀产物越多,服役状态越差,而温度越高,存储介质越容易与底板材料发生化学反应。外观腐蚀情况和储罐沉降则体现了企业对储罐的日常维护和维修情况,若外观疏于维护,罐内底板的腐蚀状态也不会太好。此外,储罐腐蚀状态与储罐体积呈负相关,即储罐体积越大,底板腐蚀状态越好。数据研究发现,大型储罐建造年限都比较短,同时由于建造费用高,企业对大型储罐的维护投入也较高,所以储罐容积越大,储罐底板越不容易腐蚀。

图7 储罐样本不同特征分布
3 结语
(1) 将储罐宏观信息和声发射数据相结合,并以可能的腐蚀状况导向对储罐宏观信息进行预处理,提高了数据的合理性。
(2) SMOTE-GWO-SVM智能评价模型能够通过扩充少数类数据集样本,实现各类样本空间的平衡,相对未采用SMOTE算法的智能评价模型,准确率从71.67%提升至96.25%。
(3) 智能评价结果表明,储罐腐蚀与声发射参数中的定位事件密度、撞击平均值、能量标准差和振铃计数标准差呈正相关,与外观参数中的储罐使用年限、运行温度和外观腐蚀情况呈现正相关。
(4) 利用同时考虑声发射特征和宏观特征的智能评价模型对多维度数据进行分析,实现了对储罐底板腐蚀状态评价分级,避免了某个维度数据偏差给整体评价带来影响。
