基于改进YOLOv5的安全帽检测算法
2023-03-11翁小林李嘉伟
梁 循,翁小林,李嘉伟,刘 倩
(1.重庆市建设工程施工安全管理总站,重庆 400010;2.重庆邮电大学 通信与信息工程学院,重庆 400065;3.移动通信技术教育部重点实验室,重庆 400065;4.移动通信技术重庆市重点实验室,重庆 400065)
安全帽作为劳动者最基本的个人防护装备,对保护劳动者的生命安全具有重要意义。但是,由于缺乏安全观念,一些工人经常不戴安全帽上班。通过图像和视频进行安全帽的检测已经成为生产安全监测的重要手段[1],特别是在建筑工地这具有一定危险性的作业场所。在传统的头盔佩戴检测方法中,大多数检测工作是基于人工设置的特征,但在实际应用中由于光源或角度问题使得目标与背景的区别不是很明显,特征提取工作极为烦琐。随着深度学习技术的发展,特别是卷积神经网络[2]的出现,该模型的图像特征提取能力得到了很大的提高。另外,支持向量机等分类器[3]可以对提取的图像特征进行分类和预测,有效地降低了特征选择的难度。
目前,目标检测的主流算法是R-CNN[4]系列和YOLO[5]系列。但R-CNN系列算法是两阶段检测算法,将耗费大量时间,即使是更快的R-CNN算法。YOLO系列算法已经开发到YOLOv5[6],已经是一级检测算法,可以一步完成R-CNN系列算法检测过程,检测速度能够满足实时性要求。
针对安全帽检测的研究已经引起了众多学者的关注。Wen等[7]提出了一种基于改进Hough变换的圆弧/弧检测方法,并将其应用于ATM监控系统中的安全帽检测。Rubaiyat等[6]结合颜色特征提取技术和循环Hough变换特征提取技术,对建筑工人头盔使用情况进行检测。Kang等[8]采用了ViBe背景建模算法,利用实时人体分类框架对变电站内的行人进行准确、快速的定位。然而,基于传统目标检测的方法只能应用于特定的场景,准确率不高。随着目标检测技术的发展,Wu等[9]对YOLOv3算法进行了改进,有效地解决了头盔着色、部分遮挡、多目标和图像分辨率低等问题。
而对于YOLOv5,在Tesla P100上可以实现140 fps的快速检测,对输入的图像进行反向训练。因此,本文使用YOLOv5作为检测器来检测工人是否戴头盔。首先,对建筑工地采集的7 581张图片进行了标注。其次,使用最先进的目标检测算法来检测工人是否正确佩戴头盔。最后,对不同深度和宽度的YOLOv5(s,m,l)模型进行训练和评估,并进行结果分析比较。
本文的其余部分主要内容阐述如下。在第一节中,介绍YOLOv5的网络架构。在第二节中,详细介绍基于改进的YOLOv5的安全帽检测算法。在第三节中给出实验的结果和分析。在第四节中对本文进行的工作进行总结。
1 YOLOv5网络架构
YOLOv5的网络结构包括4个部分,即输入(Input)、主干网络(Backbone)、颈部(Neck)和预测(Prediction),如图1所示(其中,concat表示合并)。
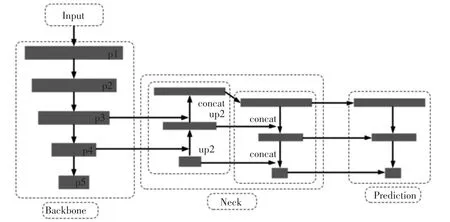
图1 YOLOv5的网络结构
输入部分包括镶嵌数据增强和自适应锚帧计算。使用随机缩放、随机剪切和随机排列的图像拼接完成数据增强。该方法对头盔、人的头部等小目标具有良好的检测效果。而YOLOv5在训练代码中嵌入了自适应锚帧。在每次训练过程中,其将自适应地计算出不同训练集中的最佳锚帧值。
主干网络部分包括焦点结构和CSPNet(Cross Stage Partial Network,跨阶段局部网络)结构。焦点结构是YOLOv5的一个独特的结构,其作用是切片。一个三维张量[4,4,3],经过分割后,可以成为一个特征映射[2,2,12]。该CSPNet结构位于Backbone部分,由卷积层和Resnet(Residual Network残差网络)的一些剩余结构组成,通过这种方式加深网络的层次。
颈部部分包括FPN(Feature Pyramid Networks,特征金字塔网络)和PAN(Path Aggregation Network,路径聚合网络)。FPN的功能是从上到下传达显著的语义特征,而PAN的功能是从下到上传达显著的定位特征。FPN和PAN的结合进一步提高了特征提取的能力,如图2所示(其中,UpSampling表示升采样,DownSampling表示降采样,图中数字单位均为像素)。
预测部分包括GIoU(Generalized Intersection over Union,广义并集上的交集)损失和加权非最大值抑制。其功能是克服IoU(Intersection over Union,并集上的交集)不能直接优化不重叠部分的问题,并在后期处理过程中保留最优框架,同时抑制这些冗余目标检测。
2 基于改进的YOLOv5的安全帽检测算法
实验部分设计的安全帽佩戴检测方法流程如图3所示。首先,YOLOv5的内置目标检测权重将用于定位人员,其次,人员的头部区域将被过滤出来,通过YOLOv5网络预先训练的头部和安全帽的权重来确定头部位置,然后,这些头盔将由YOLOv5目标检测网络识别。最后,根据数据集的特征确定安全帽是否佩戴。

图3 安全帽佩戴检测流程
3 实验结果与分析
实验的数据集来自SHWD所提供的安全头盔佩戴和人头探测的数据集。该数据集包括7 581张图片,其中9 044人佩戴安全帽,111 514人没有佩戴安全帽,相关规定佩戴安全帽的对象为正向(positive),没有佩戴安全膜的对象为负向(negative),利用LabelImg工具对图像进行手动标记。实验的运行环境是Python3.8.13,并且使用Pytorch1.8.1深度学习框架对网络进行训练、验证和测试。权重文件是YOLOv5s.pt,训练在NVIDIA RTX A4000 GPU上进行。
为了客观评价该算法在安全帽佩戴检测中的性能,需要计算平均精度指标(mean Average Precision,mAP)[10]。mAP指标能客观地反映算法的整体性能,计算公式可以表示为
式中:AP是PR曲线下的面积值,可以用定积分进行计算
通过实验,得到了不同YOLOv5模型的mAP数据,见表1。经过100次的训练之后,尽管YOLOv5 m的准确度相比于YOLOv5 s有所下降,但mAP0.5的值只减少了0.1%,并不明显。随着参数量的增加,YOLOv5 l的准确度相比于YOLOv5 s上升了1%,但mAP0.5的值只上升了0.2%。

表1 不同YOLOv5模型的mAP数据
选取马路、工厂车间和工地现场3个场景进行测试,并给出原始图片和测试结果图片进行比较。具体情况如图4所示(其中,helmet表示识别到的佩戴正确安全帽)。

图4 不同场景的测试结果
从检测结果可以看出,该算法更全面地提取了图像的总体特征。即使目标环境不同,或者图像中的目标是否处于运动状态,该算法也能够准确地检测出目标。对每个网格生成的边界框进行迭代和加权非最大值抑制滤波,得到与检测对象最一致的检测框架。特别是在工地现场场景中,在一定的遮挡条件下,该算法仍然能够准确地识别工人是否佩戴安全帽。
4 结论
本文详细介绍了基于YOLOv5的安全头盔检测方法,包括YOLOv5网络结构、损失函数和具体检测流程。此外,采用不同参数的YOLOv5模型(s,m,l)进行了实验研究。实验结果表明基于改进的YOLOv5的头盔检测方法在测试效果方面具有优异的结果。
