DDCAMS:NLP赋能智慧咨询业务
2023-03-11耿永建胡程忆杨志强孟龙波
孙 甜,耿永建,胡程忆,霍 明,杨志强,黄 昭,孟龙波
(卓望信息技术(北京)有限公司,北京 100060)
随着电信运营商数字化转型的推进,信息科技技术已经融入社会民生经济的各方面,各大公司也已经利用自然语言处理技术对各项业务进行赋能。比如陈庆良探讨了自然语言处理在电信客户名称匹配的应用场景,采用Albert small算法实现了客户名称的精确匹配模型,李奥等研究智能音箱在电信运营商业务中的应用,使用NLP理解用户意图等。中国移动通讯集团作为推动数字经济发展的中坚力量,承担着更大的责任和使命,致力于为企业级客户提供专业的数智化决策辅助系统。面对海量新闻中蕴含的庞大且复杂的信息,从中快速定位到所需内容,本文提出了DDCAMS,通过新闻去重模型、新闻去噪模型、新闻分类模型和新闻摘要模型4层算法自动处理和提炼关键信息,方便分析师洞察最新前沿技术,撰写分析性报告,提供智能化辅助决策支持。
本文的主要贡献可以概括为以下几个方面。
1)提出了DDCAMS系统,通过4层模型的处理,代替纯人工处理新闻的方式,实现快速有效地对海量新闻进行提取和分类,方便运营人员分析和使用,有助于分析师把握前沿技术动态,洞察行业商机。
2)在新闻去重模型当中,使用SimHASH算法,将百万量级的新闻处理时间降低到对数级别,实现了一个数量级新闻数量的下降,大幅缩短后续模型处理新闻的时间,对工程和业务来说非常友好。
3)在新闻分类和摘要模型当中,采用了预训练模型对文本进行理解,提高了结果的准确率,并使用基于mlflow框架进行模型部署,采取小批量多次迭代优化的方式,对模型实现快速迭代和更新。
1 智慧咨询业务介绍
智慧咨询项目基于网络爬虫,按日、周、月方式对网络情报人工收集行业动态新闻、政策法规、战略/业务预警和商机等信息,以日报、周报新闻聚合的方式为客户提供关于政府政策、技术发展趋势、运营商动向、重点标杆企业的发展信息和合作动态等内容。
之前业务人员的操作流程是利用爬虫从网络上下载新闻,然后人工筛选出所需新闻,并逐条阅读为文章分类,再由运营人员提取文章里的摘要内容。为替代原有纯人工筛选信息、排版的生产模式,实现自动化过滤、打标和摘要等需求,形成线上智能辅助决策产品闭环,自动生成信息洞察报告。平台由“信息获取—信息治理—数据分析—决策辅助”几大核心模块组成,AI主要负责自动处理数据量极大,使用简单逻辑无法实现的信息萃取相关功能,包括以下4类。
1)新闻去重模型(news deduplication model):重复内容自动识别。通过AI去重模型自动过滤大量重复或部分新闻语义内容重复的新闻,为内容打上完全匹配或部分匹配的重复标签。
2)新闻去噪模型(news denoise model):非新闻类内容自动过滤。获取的新闻除了包含新闻标题、新闻正文等有效信息,也常常包括导航区、超链接及图片控件广告等噪声信息。去噪模型主要用于去除和新闻内容完全无关的内容,自动将所需新闻入库。
3)新闻分类模型(news classification model):通信行业5类标签自动打标。将新闻作为原始数据输入模型,判断每一条新闻属于政策环境、技术应用、数字运营、垂直行业和公司5大类中的某几小类别。
4)新闻摘要模型(news abstract model):全文语义分析,重点段落自动摘要。通过百度快照自动摘要数据作为基础模型训练依据,完成摘要模型的学习,传入新闻生成最匹配原文标题的全文摘要内容,用以替代人工编辑提取新闻核心观点段落的工作。
2 DDCAMS整体模型图
2.1 整体流程
设计了新闻去重、新闻去噪、新闻分类和新闻摘要4层模型,依次运行在服务器上。通过爬虫系统获得大量含噪声的数据,首先通过去重模型,去掉重复新闻及语义相似度较高的新闻,减少后期模型样本量。之后新闻经过去噪模型过滤掉与主题不相符的非新闻噪声,接下来分类模型自动为每条新闻打上相应的5类标签,并且摘要模型提炼新闻的主旨内容,并返回给前端业务分析师,通过4层算法,减少人工处理新闻的数量,提高效率,整体流程如图1所示。

图1 DDCAMS整体流程框架图
爬虫系统每天抓取的新闻数据大约有30万条,通过该系统中的去重模型和去噪模型,可以过滤98.5%对业务无明显意义的新闻信息,并通过分类模型,摘要模型完成信息的分类与萃取,极大地提高了工作效率。通过该系统,在人工不变的情况下,处理新闻量增加了30倍,处理时间减少了40%。
2.2 模型部署
新闻去噪、分类和摘要模型采用mlflow框架来管理不同版本的模型,通过定义标准的工程脚手架进行模型的快速训练和保存,然后通过track服务提供模型的实验记录、模型的注册、版本管理和上线发布,最后通过HTTP协议暴露接口,完成模型的部署和应用。提供标准API接口给后端、测试等相关人员,完成全流程的开发,后期模型也可以根据新数据和业务效果不断进行重新训练并更新。
去重模型采用fastAPI来创建用于获取预测结果的REST服务,在代码当中声明请求参数和请求体等变量,使用uvicorn ASGI服务器,由swagger UI自动生成交互式的用户界面API文档。
3 新闻去重模型
3.1 实验设计
新闻萃取项目首先经过的是新闻去重模型,目的就是将大量重复相似的新闻过滤掉,本质上属于文本间相似度的计算。文本相似度的计算,可以使用向量空间模型(VSM),即先对文本分词提取特征,根据特征建立文本向量,把文本之间相似度的计算转化为特征向量距离的计算,如欧式距离、余弦夹角等,对于小量数据处理是可以的,但是面对日增爬取很多的海量新闻来说,这样做的复杂度会很高,所以项目的难点在于如何将海量新闻计算的时间复杂度由O(n2)下降到O(n),这对实际生产非常重要。
3.2 实验原理
SimHash算法是GoogleMoses Charikear于2007年发表的论文中提出的,专门用来解决亿万级别的网页去重任务,其主要思想是降维,将高维的特征向量映射成低维的特征向量,再通过比较2个特征向量的汉明距离来确定文章之间的相似性,可以实现近线性的近似搜索方案。
SimHash算法总共分为5个流程:①分词。对待处理文档进行中文分词,得到有效特征和权重;②hash。对获取的词进行普通哈希操作,计算hash值,得到一个长度为n位的二进制;③加权。在获取的hash值基础上,根据对应的weight值进行加权;④合并。将上述得到的各个向量加权结果进行求和,变成一个序列串,对一个文档得到一个列表;⑤降维。对于得到的n-bit签名的累加结果的每个值进行判断,大于0则置为1,否则置为0,从而得到该文本的SimHash值。
经过SimHash映射以后,得到每个文本内容对应的SimHash签名,利用海明距离来进行2篇新闻相似度的衡量,根据抽屉原理,即在海明距离为3的情况,如果2个文档相似,那么其必有一个块的数据是相等的原理,来判断2个文本的相似性,进行更高效率的存储,提高去重效率。
3.3 实验结果及分析
SimHash算法的召回率为82%,可以有效过滤掉新闻当中约9成以上重复和近似的新闻,算法的复杂度为O(1),推理时间是24 ms,实现了近线性的近似搜索方案,作为新闻萃取的第一层处理,极大地提高了项目的整体效率。去重模型可以在很多场景当中直接使用,具有较高的实际应用价值。
4 新闻去噪模型
4.1 实验设计及流程
经过新闻去重模型后的数据会进入到新闻去噪模型,过滤掉诸如新闻报道时间、导航区、超链接、版权信息及图片控件广告等噪声信息。使用TF-IDF算法实现新闻文本的向量化,然后使用SVM算法对文本数据进行分类,判断是否为所需新闻,主要包括jieba分词、TF-IDF文本表征和SVM文本分类3个环节。
4.2 模型原理
1)jieba分词。首先进行数据清洗,去掉重复数据,然后使用正则表达式去除换行符和标点符号等操作,接下来进行停用词的处理,删除类似“我们,的,了,吗”这类停用词,但是保留数字和网页标签等超链接符号,然后使用jieba默认模式对所有新闻文本进行分词处理,用1个空格分隔每个单词,对所有的数据集都进行分词的操作。
2)TF-IDF文本表征。TF-IDF可以根据特征词在文中出现次数和在整个语料中出现文档频率数计算该词在整个语料中的重要程度,过滤掉常见却不重要的词,尽可能多的保留影响程度高特征词,TF-IDF值越大则表示该特征词对这个文本的重要程度越高。
计算公式如下,TF-IDF表示词频TF和倒文本词频IDF的乘积,TF中ni,j为特征词ti在训练文本Dj中出现的次数,分母是文本Dj中所有特征词的个数,IDF中|D|是语料文本总数,|Dt|表示文本所包含特征词ti的数据
3)SVM文本分类。支持向量机SVM是一种二分类模型,是定义在特征空间上间隔最大的线性分类器,学习策略就是间隔最大化,学习算法就是求解凸二次规划的最优化算法,通过使用核技巧成为实质上的非线性分类器。
在实验的过程中,采用高斯RBF核函数,其是一种局部性强的核函数,主要用于线性不可分的情形,可以将1个样本映射到1个更高维的空间,采用KFold五折自动训练,利用metrics计算precision、recall、f1_score 3类评价指标结果。
4.3 实验结果
对69 670条新闻数据进行训练,首先进行数据清洗和分词的处理,划分训练集、测试集和验证集,然后对此语料库用sklearn完成向量化与TF-IDF特征值计算,之后利用SVM模型进行文本分类训练,通过降低阈值增加召回率,经过100轮训练后模型达到了最优效果,离线评估去噪模型f1值为0.817 659,上线使用之后可以有效将噪声新闻过滤出来。
5 新闻分类模型
5.1 多标签分类模型
新闻分类算法框架使用Albert+TextCNN。Albert是为了得到新闻文本特征向量,TextCNN是为了更好地提取文本中的特征,最后接全连接层得到分类的标签结果,整体框架如图2所示。
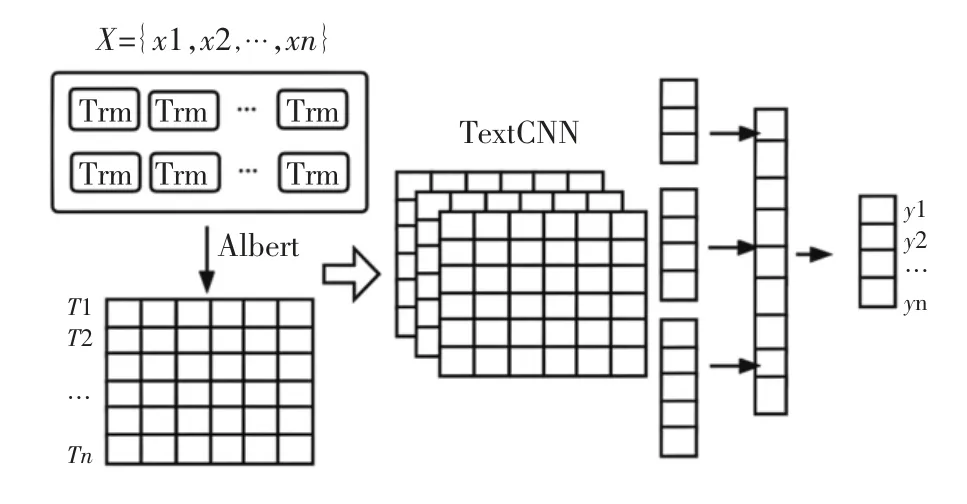
图2 新闻多标签分类模型
Albert通过向量参数化的因式分解、跨层参数共享、句间连贯性损失采用SOP及dropout 4个手段来减小模型的大小,在生产环境进行部署时无论是存储还是训练模型都很节省资源。新闻文本通过Albert模型得到1个3维向量之后,下游任务使用这个向量做多标签文本分类的任务。
TextCNN模块的核心思想是抓取新闻文本的局部特征,主要是通过不同的卷积核尺寸来提取文本的Ngram信息,因为中文会有一些5、6、7词的专业名称或短语,所以选择了更丰富的卷积核,然后进行最大池化来提取最关键信息,类似attention机制,拼接之后通过全连接层对特征进行组合,然后通过多分类的损失函数来训练模型。
最后通过全连接层,利用了TextCNN的输出作为其输入,将TextCNN的输出投射到新闻分类的标签上,有点像特征与标签之间的桥梁,得到标签的概率输出分布,获得每条新闻对应的多标签类别。
此处使用多个二分类任务,如果输出结果不属于任何一个类,则认为是噪声数据,这与第2步的去噪模型是互补的。如果输出的类别超过10个,则仅取前10个概率最大的类别。
5.2 数据集介绍
数据集来自卓望公司从各大网站上的新闻数据,一共有40 000多条,由业务运营人员对数据类别打标。数据集分为公司、政策环境、垂直行业、技术应用和数字化运营5个大类,173个小类,每1条新闻属于5个大类中的某几个特定的小类。采用one-hot进行编码,类别对应的数据标签为1,否则为0。将文本转换成向量后,随机选取其中30 000条用作训练集,6 000条验证集,4 000条测试集,数据集样本见表1。

表1 通信行业5个类别数据样例
5.3 模型训练及实验结果
新闻分类模型的训练环境基于Linux Ubuntu 16.04,硬件环境为Intel(R)Xeon(R)Gold 5118 CPU@2.30 GHz(12-Core),8*NVIDIA Tesla V100(16 GB),64 GB内存,利用Pytorch1.7.1进行神经网络的搭建,软件环境为Python3.6。预训练模型采用albert_small_zh_google,textcnn的num_filters设置为128,卷积核token数设置为2、3、4、5、6、7,embedding_size为384,最大句子长度为512,训练过程中的学习率是5×10-5,批次大小为64,模型训练到50轮时效果最好,结果见表2。

表2 通信行业新闻5个类别f1值
公司和政策环境类别结果较好,f1值达到90%多,分析是因为文本当中有明显的类似“公司名”等关键词特征,而且数据量较多,所以分类准确率较高。垂直行业和技术应用的特征和数量少一些,效果稍差。数字化运营个别类只有几条数据,特征不明显,所以准确率不高,后期可以进行不均衡数据集处理,或采用数据增强的方式等来提高分类准确率。
6 新闻摘要模型
6.1 摘要模型介绍
业务方收集的新闻,一方面利用多分类模型为其打标,另一方面经过摘要模型生成摘要,方便分析师预览新闻内容。因新闻文章较长,seq2seq对长本文编码能力有限,所以采用抽取式的方式构建摘要模型,判断文章中哪些句子可以作为关键句,形成摘要。
先通过规则将原始的生成式语料转化为序列标注式语料,即在新闻原文中找到若干条子句,使得其链接起来与摘要尽可能相似,属于摘要的句子打标为1,否则为0。句子使用“BERT+平均池化”来生成句向量,并固定不变,标注模型主体方面则用DGCNN模型构建,最后经过dense层进行分类判断是否为摘要关键句,整体框架如图3所示。
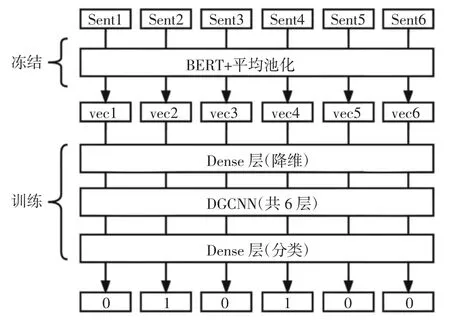
图3 新闻摘要模型图
实验模型在tensorflow1.15、python3.6环境下进行训练,采用BERT模型默认参数,词嵌入维度为128,隐藏单元为256,batch_size大小为64,采用Adam优化器优化模型,在训练抽取模型的时候,为了尽量做到“抽全”来构建摘要模型,以0.2为阈值做EarlyStop,使用交叉验证,以词为单位的加权Rouge作为评价指标。
6.2 数据集及实验结果
采集百度新闻的快照和原文作为监督式自动摘要模型任务的基础训练数据,一共有18 468条数据,以“摘要|||原文”的数据对出现,关于训练数据摘要和原文的一些统计信息见表3。

表3 新闻摘要数据统计
对以上数据进行模型训练,rouge值为12.86,新闻抽取的结果大部分集中在第1段,平均摘要句子长度为128个字左右,分析是因为训练数据的摘要基本就在原文正文的第1段,所以模型学到了位置信息及句长信息。因为数据量比较少,所以采取了回译的数据增强操作,将数据扩充了1倍,效果有些许提升,作为初代版本,基本可以满足需求,减轻运营工作人员的工作量,随着后续平台的使用和数据量的积累,再对模型做进一步的精细优化,提升摘要效果。
7 结束语
本文主要介绍了面向智慧咨询项目的自然语言处理技术在新闻萃取项目中的实践及应用,通过研究新闻去重、新闻去噪、新闻分类和新闻摘要生成等技术,实现了自动筛选信息、提取关键内容的生产技术,加快了信息处理的效率,替代了纯人工的操作方式,为分析师洞察前沿技术提供了智能化决策支持,打造了面向外部客户和内部技术人员、运营人员的AI业务变革应用案例,赋能各项智能化服务。
不过当前模型也存在不少问题,一是数量规模较小,样本量不足,覆盖范围不够,影响了模型的泛化能力,二是标注的样本质量不高,影响模型精度的进一步提升。但是随着运营人员的持续使用,有标注的数据会越来越多,有利于后续做有监督的模型训练,通过mlflow框架不断进行小批量模型迭代更新,提高准确率,提升运营人员的使用体验。
