在线图正则化非负矩阵分解跨模态哈希
2023-03-10罗雪梅郑海红安亚强王笛
罗雪梅,郑海红,安亚强,王笛
西安电子科技大学 计算机科学与技术学院,西安710071
随着社交网络的发展,爆炸性增长的多媒体数据如潮水一般涌入互联网中,数据类型呈现出多模态特征,跨模态信息检索也因此吸引了大量科研工作者的研究兴趣。跨模态哈希检索的基本思想是利用不同模态的样本对信息,学习不同模态的哈希变换,将不同模态数据从原始特征空间映射到一个公共汉明空间,通过二进制编码在汉明空间中保持数据的相似性,实现快速的跨模态检索[1-5]。基于哈希的跨模态检索即通过将不同模态的原始特征在同一汉明空间映射为一定长度的二进制编码,从而节省存储空间,提升检索速度。
跨模态哈希检索算法虽然在面对海量多媒体数据时,取得了较好的检索结果。但大多数哈希检索算法采用批量学习模式,即利用当前累积的所有训练样本学习哈希函数。然而,由于数据不断增长,现有的哈希检索方法无法根据数据的变化自适应更新模型,而重新进行哈希学习势必会带来巨大的时间和计算开销。另一方面,同时利用海量数据训练哈希函数,具有较大的存储和计算需求,降低了哈希方法的适用性。
为了应对上述挑战,提出了在线跨模态哈希方法。该方法从连续到达的数据中逐步更新哈希函数,以适应数据流的变化,同时将新数据编码为紧凑的二进制代码,以有效地处理流数据。同时,由于哈希函数只根据当前数据进行更新,与基于批量学习的模式相比,在线跨模态哈希方法大大降低了计算成本和内存需求。
在线跨模态哈希(online cross-modal hashing,OCMH)[6]提出了一种无监督方法,利用矩阵分解将特征矩阵分解为共享潜码矩阵和支持在线学习的转移矩阵,然后通过共享潜码矩阵学习哈希码。然而,由于该方法是无监督模式,训练数据点的标签信息并没有被用来提高哈希函数的质量,从而降低了检索性能。动态多视图哈希(dynamic multi-view hashing,DMVH)[7]通过构造字典来表示多模态数据并支持在线哈希码生成,根据流数据的变化动态地增加哈希码的长度。然而,由于数据不断变化,其生成的哈希码通常具有较高的冗余度和较长的位长。在线潜在语义哈希(online latent semantic hashing,OLSH)[8]是一种在线监督哈希方法,其将离散标签映射到连续潜语义空间中获得哈希码,仅利用新到达的多媒体数据点对哈希函数进行有效的再训练,同时保留了旧数据点的语义相关性。然而该方法需要频繁通过标签信息矩阵来更新语义相似性矩阵,计算复杂度较高。
本文提出一种新的监督在线跨模态哈希方法,称为在线图正则化非负矩阵分解跨模态哈希(online graph regularized non-negative matrix factorization crossmodal hashing,OGNMFH)。首先利用非负矩阵分解,学习不同模态数据的潜在公共因子,使不同模态数据在汉明空间中具有公共的哈希码,从而保持模态间的相似性。然后利用标签信息生成相似度矩阵,对矩阵分解的过程进行监督,保持数据的局部几何结构,从而保持模态内的相似性。如图1 所示,OGNMFH 根据当前到达的数据,增量地更新哈希函数,并生成哈希码。每次更新只需要计算当前数据块,不需要对旧数据重新计算,因此不需要存储旧数据,缓解了存储压力,提高了计算效率。

图1 OGNMFH 检索方法框图Fig.1 Flowchart of OGNMFH retrieval method
本文的主要贡献包括四方面:
(1)提出一种在线跨模态哈希方法OGNMFH。该方法利用非负矩阵分解对维度较高的不同模态数据提取语义特征,将不同模态数据映射到公共的汉明空间,并通过图正则化来保持多模态数据之间的语义相似性。
(2)利用建立缓冲区的方式增量处理输入数据,在线学习哈希函数,可以有效处理大规模数据。
(3)充分利用局部流形结构信息和数据的类别标签信息,从而学习到更有判别性的哈希码。
(4)基准数据集上的实验结果表明,本文提出的在线跨模态哈希算法可有效提升在线哈希学习的检索精度。
1 相关工作
非负矩阵分解(non-negative matrix factorization,NMF)[9]是一种经典的数据降维方法,其基本思想可以简单描述为:对于任意给定的非负矩阵X∈Rm×n,寻找非负矩阵U∈Rm×k和非负矩阵V∈Rn×k,使得X≈UVT。其中,矩阵X表示原始数据矩阵,矩阵U称为基矩阵,矩阵V称为系数矩阵或权重矩阵,k≪min(m,n)。NMF 问题可以通过最小化下式来求解基矩阵U和系数矩阵V:
其中,||·||2表示欧几里德范数。传统的NMF 在欧氏空间中进行因式分解,不能得到令人满意的解。事实上保持数据集的底层几何结构对于非线性降维是非常重要和有效的。图正则化非负矩阵分解(graphregularized non-negative matrix factorization,GNMF)[10]将几何结构融入到NMF 中,与传统的NMF 相比,其性能有显著的提高。GNMF 基于以下假设:如果两个数据xi和xj在原始数据分布中的几何结构是接近的,那么它们在新的空间中的表示应该也是接近的。上述假设表示如下:
因此,GNMF 的损失函数定义如下:
然而,由于NMF 和GNMF 都是在批处理模式下工作的,均要求数据矩阵驻留在内存中,这给计算和存储带来了巨大的压力。而数据以流式增加时,存储需求更高,计算也更复杂。在线图正则化非负矩阵分解(online graph-regularized non-negative matrix factorization,OGNMF)[11]以增量的方式处理传入的数据。首先对在线实现GNMF 算法的瞬时目标函数进行建模,建立一个缓冲区,将数据依次添加到缓冲区,当数据量达到缓冲区设定阈值时,即进行更新训练。然后,移除缓冲区中最早的一个数据,循环迭代,直到全部数据训练结束,最后推导迭代乘法更新规则来求解所提出的OGNMF 模型。
给定流式数据集X,t时刻OGNMF 的目标函数定义如下:
其中,Xt是t时刻缓冲区中的数据样本;Vt是系数矩阵;Ut是基矩阵;Lt是t时刻缓冲区中数据样本的图权重矩阵Wt的拉普拉斯矩阵。
2 在线图正则化非负矩阵分解哈希
本章将详细介绍所提出的在线图正则化非负矩阵分解跨模态哈希方法。在不失一般性的情况下,为了简化表示,首先关注由图像和文本组成的双模态数据的OGNMFH 方法,然后将其扩展到多模态情况。
2.1 符号和问题描述
对于在线跨模态哈希,目的是对于每一个模态都要学习相应的哈希函数,第m个模态的哈希函数表示为:
其中,Pm是映射矩阵,sign(·)是符号函数。通过哈希函数可以得到每个模态数据对应的哈希码B∈{-1,1}n×k,k为哈希编码长度。
2.2 目标函数
本文提出的在线图正则化非负矩阵分解跨模态哈希检索算法在t时刻的目标函数Ot构建如下:
2.3 在线优化
算法1第t轮在线图正则化非负矩阵分解跨模态哈希检索算法
通过在线学习哈希函数,获得了所有训练数据的哈希码,对于样本外数据,OGNMFH 方法可快速生成该样本的哈希码。假设获得一个新的查询样本xk,可通过下式计算得到它对应的哈希码bk:
其中,Pk是数据xk对应模态的哈希函数。OGNMFH方法的整个训练及查询过程如算法2 所示。
算法2在线图正则化非负矩阵分解跨模态哈希
2.4 复杂度分析
2.4.1 时间复杂度分析
OGNMFH 方法的时间复杂度主要由在线优化过程决定。每一轮在线优化共有5 个矩阵变量需要更新。由于在线更新过程使用缓冲区技术,每次通过更新缓冲区中的数据实现在线学习,因此更新每个变量的复杂度是O(s),s是缓冲区的大小。由于迭代的数量通常较小,因此,整个网络优化过程的时间复杂度近似为O(s),它的值与缓冲区的大小成线性关系。
2.4.2 空间复杂度分析
OGNMFH 通过建立缓冲区实现在线学习,每次保留中间矩阵,以便在下一轮更新。这些矩阵的大小只与哈希码长度和特征向量有关,占用的内存空间不大。在使用的所有变量中,只有数据矩阵的大小和统一表示矩阵与缓冲区大小有关。因此,一般来说,OGNMFH 的整体空间复杂度为O(s),在大规模数据检索任务中效率是非常高的。
3 实验
3.1 数据集介绍
为了验证本文所提OGNMFH 算法的有效性,在3个经典的跨模态数据集MIRFlicker[12]、NUS-WIDE[13]、MSCOCO[14]上分别进行了在线跨模态实验,并在同等实验条件下和其他方法进行了对比实验。
MIRFlickr数据集由来 自Flickr 网站的25 000 个图像-文本数据对组成。每个数据对都与24 个语义标签中的一个或多个关联。选择一个包含20 015 个数据对的子集,这些数据对与出现频率最高的20 个标签对应。每个图像表示为一个由VGG19 提取的4 096 维非负深度特征。通过对由VGG19 提取的4 096 维文本特征进行PCA(principal component analysis)处理,然后进行非负处理,将每个文本表示为一个1 387 维非负特征,每个标签表示为一个24 维只包含0 和1 的向量。随机选择2 000 个图像文字对作为查询集,剩下的数据对作为训练集,为了支持在线学习,训练集被分割为9个数据块,前8个数据块包含2 000个数据对,最后一个数据块包含15个数据对。
NUS-WIDE 数据集由来自Flickr 网站的269 648对图像-文本数据组成。每个数据对都与81 个语义标签中的一个或多个相关联。选择一个包含186 577个数据对的子集,这些数据对与出现频率最高的10个标签对应[15]。每个图像表示为一个由500 维SIFT(scale-invariant feature transform)特征所构成的词包特征,每个文本表示为一个1 000 维的词包特征,每个标签表示为一个10 维只包含0 和1 的向量。随机选择2 000 个图像文字对作为查询集,剩下的数据对作为训练集。为了支持在线学习,训练集被分割为37 个数据块,前36 个数据块包含5 000 个数据对,最后一个数据块包含4 577 个数据对。
MSCOCO 数据集由来自Flickr 网站的122 218对标记为图像-文本的数据对组成。每个数据对都与80 个语义标签中的一个或多个相关联。通过对VGG Net 的Caffe 实现提取的4 096 维图像深度特征进行非负处理,将每幅图像表示为一个4 096 维非负特征。通过对VGG Net 的Caffe 实现提取的4 096 维文本深度特征进行PCA 处理,然后进行非负处理,将每个文本表示为一个128 维非负特征,每个标签表示为一个80 维只包含0 和1 的向量。随机选择2 000 个图像文字对作为查询集,剩下的数据对作为训练集。为了支持在线学习,训练集被分割为25 个数据块,前24 个数据块包含5 000 个数据对,最后一个数据块包含218 个数据对。
3.2 参数设置
本文所提出的在线图正则化非负矩阵分解跨模态哈希检索方法(OGNMFH)共有5 个参数:图像模态权重系数λ1、文本模态权重系数λ2、图正则化参数α、表示平衡项参数μ以及正则化项参数γ。在本文实验中设定λ1=0.5,λ2=0.5,α=0.001,μ=0.001,γ=1。另外迭代阈值设置为0.01。
3.3 实验结果与分析
在本文实验中,进行两种类型的跨模态检索任务:图像查询和文本查询。为了证明本文所提的OGNMFH 方法在流数据点上的有效性,设置了在线进行的实验,数据点以流的方式到达。通过分割训练数据模拟流数据,整个在线检索阶段包括若干轮,在每一轮,一个新的数据块被添加到数据库,并评估检索性能。
图2、图3 和图4 是本文提出的在线图正则化非负矩阵分解跨模态哈希(OGNMFH)方法和在线潜在语义哈希(OLSH)、在线跨模态哈希(OCMH)、动态多视图哈希(DMVH)三种对比方法在数据集MIRFlickr、NUS-WIDE 和MSCOCO上的mAP曲线图。本次实验比较了4 个不同哈希码长度下的mAP值,分别是16 bit、32 bit、64 bit 和128 bit。实验结果表明,使用流式数据在线更新哈希模型,本文所提出的OGNMFH 方法的检索性能比其他对比方法更好,证明了语义信息可以提高检索性能,本文所提方法是有效的。

图2 MIRFlickr 数据集上不同哈希码长度的mAP 曲线Fig.2 mAP curve under different sizes of hash on MIRFlickr dataset

图3 NUS-WIDE 数据集上不同哈希码长度的mAP 曲线Fig.3 mAP curve under different sizes of hash on NUS-WIDE dataset
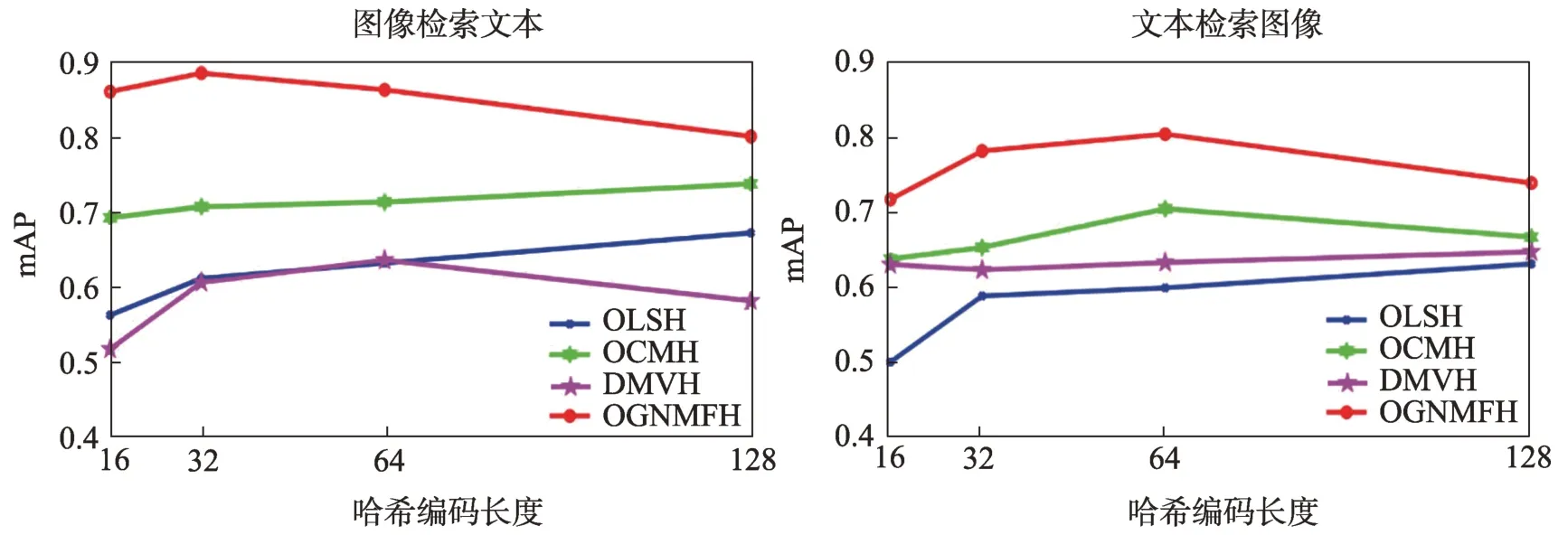
图4 MSCOCO 数据集上不同哈希码长度的mAP 曲线Fig.4 mAP curve under different sizes of hash on MSCOCO dataset
图5、图6 和图7 显示了所有方法在3 个数据集上哈希码长度为32 bit 的mAP 值随轮数的变化曲线。可以看出,每种方法的mAP 值一般都随着可用训练数据点的增加而增加。这反映出随着轮数的增加,在线哈希方法可以根据数据的变化自适应更新模型。本文所提出的OGNMFH 方法在每一轮的所有数据集上的性能都有显著的提高,总体呈现波动上升的趋势,说明其性能较好。
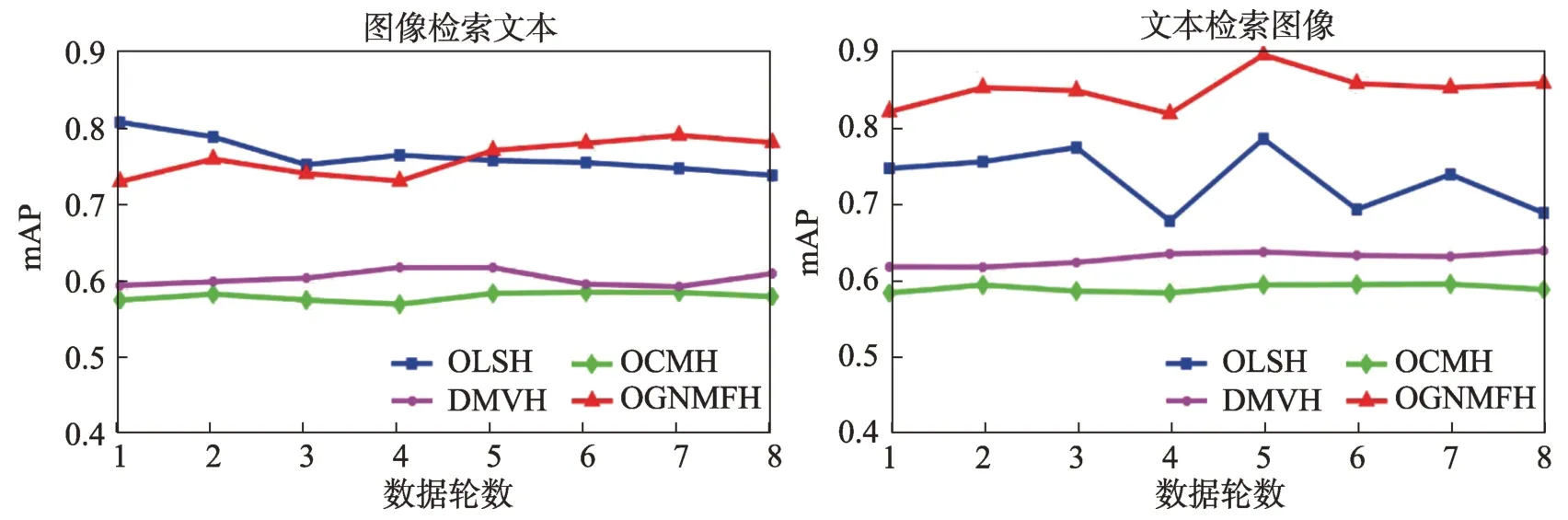
图5 MIRFlickr数据集上随数据轮数增长mAP 曲线Fig.5 mAP curve with increasing of data rounds on MIRFlickr dataset

图6 NUS-WIDE 数据集上随数据轮数增长mAP 曲线Fig.6 mAP curve with increasing of data rounds on NUS-WIDE dataset

图7 MSCOCO 数据集上随数据轮数增长mAP 曲线Fig.7 mAP curve with increasing of data rounds on MSCOCO dataset
3.4 训练时间分析
图8显示了每种方法在NUS-WIDE数据集上,哈希码长度设为32 bit,随数据集增加后训练时间变化曲线。从图中可以看出,在所有在线哈希方法中,OGNMFH比OCMH 略慢,但检索效果更好。而相较于DMVH 和OLSH,OGNMFH 的计算复杂度相对更低,训练速度要快很多。因此,OGNMFH 有较好的训练效率。

图8 NUS-WIDE数据集上所有方法训练时间Fig.8 Training time of all methods on NUS-WIDE dataset
3.5 参数敏感性分析
本节详细分析了在MIRFlickr数据集上OGNMFH方法各个参数的敏感性,其中哈希码长度设置为32 bit。通过每次固定其余参数,在一定范围内变化其中一个参数来对各个参数进行分析。
图9 显示了OGNMFH 方法的mAP 值随λ1和λ2变化的曲线。从图中可以发现,控制两个模态非负矩阵分解项的权重系数λ1和λ2,参数变化对模型最终的性能影响较小,因此通过经验将其设置为λ1=λ2=0.5。
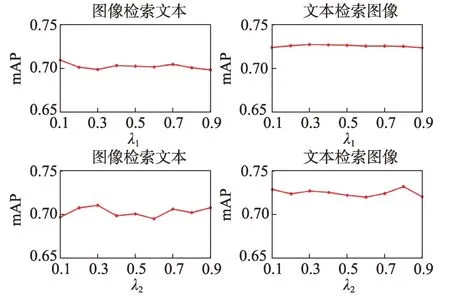
图9 参数λ1 和参数λ2 敏感性测试mAP 曲线Fig.9 mAP curve of parameter sensitivity test about λ1 and λ2
图10 显示了图正则化参数α敏感性测试mAP曲线。从图中可以看出,当α在[10-5,10-3]内时,本文方法的mAP 值较高,性能较好,因此在本文方法训练时设置α=10-3。
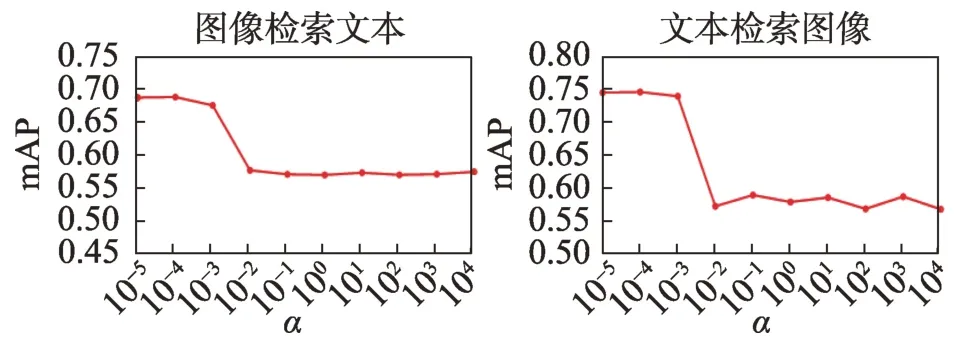
图10 参数α 敏感性测试mAP 曲线Fig.10 mAP curve of parameter sensitivity test about α
图11 显示了平衡项参数μ敏感性测试mAP 曲线。从图中可以看出,当μ小于等于10-1时,OGNMFH方法的mAP 值较高,性能较好,因此在OGNMFH 方法训练时设置μ=10-3。

图11 参数μ 敏感性测试mAP 曲线Fig.11 mAP curve of parameter sensitivity test about μ
图12 显示了正则化参数γ敏感性测试mAP 曲线。从图中可以看出,当γ的值大于10-1时,本文方法可以达到稳定的性能,在本文方法训练时设置γ=100。
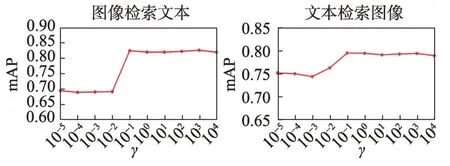
图12 参数γ 敏感性测试mAP 曲线Fig.12 mAP curve of parameter sensitivity test about γ
4 结束语
本文提出了一种新的有监督在线跨模态哈希检索算法,称为在线图正则化非负矩阵分解跨模态哈希。它增量地更新哈希函数,并通过新到达的数据生成哈希代码。通过一次处理一个数据块,可以节省大量的计算和存储空间。该算法首先通过非负矩阵分解学习跨模态数据公共语义;然后利用标签信息建立相似度矩阵,对非负矩阵分解过程进行监督,使在原始数据空间中相似的样本学习到的哈希码也相似,不相似的样本学习到的哈希码不相似,保持哈希码模态内和模态间相似度;最后松弛离散约束,在线优化目标函数,学习到质量更高的哈希码,从而提高检索性能。在三个经典数据集上的大量实验表明,该方法优于几种现有的先进方法。
