多核数字信号处理器并行矩阵转置算法优化*
2023-03-09裴向东王庆林廖林玉李荣春梅松竹庞征斌
裴向东,王庆林,2,廖林玉,2,李荣春,2,梅松竹,2,刘 杰,2,庞征斌
(1. 国防科技大学 计算机学院, 湖南 长沙 410073; 2. 国防科技大学 并行与分布处理国防科技重点实验室, 湖南 长沙 410073)
矩阵转置是矩阵运算中最常见的一种操作,广泛应用于科学和工程领域[1-2],如信号处理、科学计算和深度学习[3-5]。作为重要的基础算子[6-7],矩阵转置的效率高低对应用的性能会产生直接的影响。特别是矩阵转置操作属于访存受限型运算,对访存密集型应用的影响将更大[8-9]。
面对各领域对高性能矩阵转置操作的需求,国内外学者对矩阵转置优化已经进行了大量的研究工作。远远等提出适应对称多处理器系统的两维均衡细粒度交织矩阵转置算法[10],通过提升矩阵在存储器上的读写效率来降低矩阵转置开销。Zekri 等提出了面向Intel 处理器的矩阵转置优化算法[11],通过采用向量扩展指令AVX来加速矩阵转置运算。王琦等提出了面向Intel KNL融合处理器的并行矩阵转置优化[12]。Springer等提出了面向张量转置的编译器TTC[13],以离线方式自动产生高性能的C++转置实现。TTC效率虽高,但不能直接应用在运行时才能确定张量大小与转置需求的场景中,因此Springer等随后又提出了支持在线自动调优的张量转置库HPTT[14],集成了自动调优、显式向量化和多线程并行等优化技术,在多种中央处理器(central processing unit,CPU)硬件架构上均展现了优异的性能,是当前面向CPU架构的流行张量转置开源库。肖汉等采用OpenCL编程模型实现了面向图形处理器(graphic processing unit,GPU)的并行矩阵转置算法优化,相比CUDA实现,具有更好的可移植性[15]。Hynninen等面向NVIDIA GPU构建了张量转置函数库cuTT[16]。Vedurada等为GPU提出张量转置库TTLG[17],构建了性能预测模型来选择不同转置内核以及分块大小。高捷针对“神威”国产超算平台优化了张量转置库 SWTT[18]。
由于能源效率和功耗的限制,高性能计算的异构计算领域引入了低功耗嵌入式架构,如数字信号处理器[19](digital signal processor,DSP)。与CPU和GPU相比,DSP通常采用基于超长指令字(very long instruction word,VLIW)和顺序执行的向量核,集成了直接存储器存取(direct memory access,DMA)引擎用于数据访问[20-21],从而已有的针对CPU和GPU的并行矩阵转置实现并不能直接适用于多核DSP架构。
FT-M7032是国防科技大学自主研发的一款异构多核DSP[19],主频为1.8 GHz时双精度浮点峰值性能高达5.53 Tflops/s,在信号处理、科学计算和深度学习等领域有巨大潜力[22],对高性能矩阵转置实现提出了强烈需求。本文面向FT-M7032芯片的体系结构特征,研究高性能矩阵转置并行实现特性,提出了一种适配不同数据位宽(8 B、4 B以及2 B)矩阵的并行矩阵转置算法ftmMT,基于DSP核中向量Load/Store单元支持的取模存储功能构建了向量化矩阵转置核心,通过矩阵分块、隐式乒乓以及多核并行的设计实现片上向量化转置与片外访存的重叠以及对片外存储带宽的高效利用。实验结果显示,ftmMT获得了高达75.95%的DDR有效带宽利用率;与主流矩阵转置开源算法库HPTT相比,ftmMT实现了高达8.99倍的性能加速。因此,本文工作对于推动FT-M7032在各领域的应用具有重要的意义。
1 矩阵转置定义与FT-M7032结构简介
本文的研究范围仅限于二维矩阵,故令输入矩阵为A[M][N],转置输出矩阵为B=AT,其中M和N表示矩阵的行数和列数。矩阵转置的具体计算如式(1)所示:
B(m,n)=A(n,m)
(1)
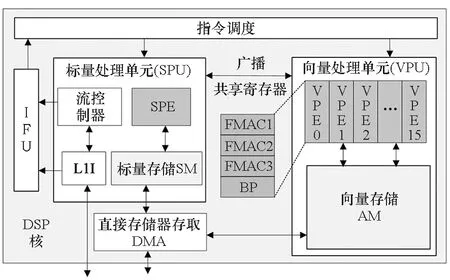
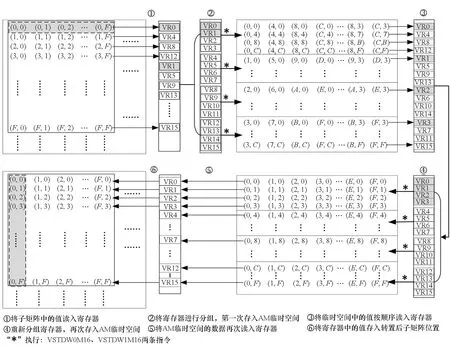
其中,0≤m FT-M7032是由一个多核CPU和4个GPDSP簇构成,其体系结构如图1所示。多核CPU是一个简化版本的FT-2000plus处理器[4-5],由16个兼容ARMv8架构的CPU核构成,主要负责进程管理和通信,上面运行操作系统。4个GPDSP簇负责提供最主要的计算性能,每个GPDSP簇由8个DSP核与全局共享内存(global shared memory,GSM)通过片上互联网络连接而成。GSM大小为6 MB, 由单簇内的8个DSP核共享,可以作为数据或指令的片上存储空间使用。同时,CPU与GPDSP共享内存空间。每个GPDSP簇所能访问的DDR理论带宽为42.62 GB/s。每个GPDSP簇中的DSP核基于VLIW架构实现,包含指令调度单元(instruction fetch unit,IFU)、标量处理单元(scalar processing unit, SPU)、向量处理单元(vector processing unit,VPU)和DMA引擎等部分,FT-M7032中DSP核的微体系结构如图2所示。 图1 FT-M7032体系结构Fig.1 Architecture of FT-M7032 图2 FT-M7032中DSP核的微体系结构Fig.2 Micro-architecture of DSP cores in FT-M7032 SPU用于指令流控制和标量计算,主要由标量处理部件(scalar processing elements, SPE)和64 KB标量存储(scalar memory, SM)空间组成,每周期最多能够处理5条标量指令。VPU主要由768 KB的向量存储(vector memory,AM)空间和16个向量处理部件(vector processing elements,VPEs)构成,为每个DSP核提供最主要的计算能力。每个VPE包含64个寄存器、3个浮点乘累加(floating point multiply accumulator, FMAC)和1个位操作(bit processing, BP)单元,一次可以处理1个8 B数据(如FP64、Int64)、2个4 B数据(如FP32、Int32),或4个2 B数据(如FP16、Int16)。16个VPE以单指令多数据(single instruction multiple data,SIMD)方式运行,因而8 B数据类型的 SIMD 宽度为 16。AM 空间可以通过VPU中的两个向量Load/Store单元在每个周期向寄存器提供多达 512 B的数据,从而AM与向量寄存器之间的访问带宽高达921.6 GB/s。 由于功耗的限制,VPU的多个VPEs之间不支持混洗功能,同时DMA部件也不支持矩阵转置功能。尽管如此,VPU的Load/Store单元支持取模存储VSTDW0M16/VSTDW1M16指令,如图3所示。执行完该指令后,可以将4个向量寄存器中的数据按地址模16的方式存储在AM空间中,即实现4×16矩阵的转置。 图3 VPU中模16的存储功能Fig.3 Store based on Module 16 in VPU 在FT-M7032上实现矩阵转置主要有四种方法:一是基于FT-M7032 上多核CPU的实现,二是基于DSP 纯DMA操作的实现,三是基于DSP SPU的实现,四是基于DSP VPU的实现。 基于FT-M7032上多核CPU的实现方法是直接调用已有面向CPU的开源矩阵转置库,如HPTT[14]等。然而,由上一节内容可知,FT-M7032的主要计算能力是由GPDSP簇提供,虽然多核CPU与GPDSP簇共享存储空间,但GPDSP簇与多核CPU之间进行交互时需要将多核CPU中Cache的内容进行作废或者写回DDR中,当多次交互时,交互开销较大。 基于DSP 纯DMA操作的实现方法是通过将DMA操作的块大小设置为矩阵中单个数据的大小来实现转置。然而,FT-M7032中DMA操作最小粒度为8 B,这意味着该方法只适合于单个数据为8 B的类型,如FP64、Int64等。同时,DMA的块大小直接影响DMA的访存效率,这意味着使用该方法不能充分发挥FT-M7032的访存带宽。 基于DSP SPU的实现方法是先将数据加载到SPU的SM空间,然后基于标量操作来实现矩阵转置运算。在FT-M7032的SPU中,SM仅为64 KB,使得在转置实现过程中需要频繁调用DMA,DMA操作的启动开销较大。与此同时,SPU仅有一个标量Load/Store单元,每周期仅能向寄存器提供16 B的数据,使得基于SPU的片上转置核心在实现过程中性能受限。 基于DSP VPU的实现方法则是将数据加载到VPU的AM空间,然后基于向量操作来实现矩阵转置运算。在FT-M7032的VPU中,AM空间大小为768 KB,VPU的两个Load/Store单元每周期可以提供512 B的数据。相比前面两种基于DSP 的实现方法,可一定程度上有效克服片上存储带宽受限、频繁调用DMA以及访存效率较低等问题。 综上所述,基于DSP VPU的方法是面向FT-M7032的高性能矩阵转置实现的必然选择。但是VPU的多个VPE之间不支持混洗功能,使得基于DSP VPU的转置实现成为一个难题。本文将通过充分利用VPU中Load/Store单元支持的取模存储功能来解决这一问题。考虑到基于纯DMA操作和SPU的两种实现在理论上性能就远低于本文基于VPU的实现,故本文在后续实验部分仅与基于多核CPU的实现进行性能比较。 本节先对本文提出的面向飞腾异构多核DSP的并行矩阵转置算法ftmMT进行整体介绍,然后对该算法的具体思路及实现过程做详细描述。 如第2节所分析,基于DSP VPU的转置实现是面向FT-M7032的高性能矩阵转置实现的必然选择。基于此,本文提出了并行矩阵向量化转置算法ftmMT,如算法1所示。ftmMT算法充分结合了FT-M7032的体系结构特征和矩阵转置的计算访存特点,主要由三个步骤构成。 算法1 并行矩阵转置算法ftmMTAlg.1 Parallel matrix transpose algorithm (ftmMT) 步骤1:将CPU Cache中的内容写回DDR中(Step 1)。 步骤2:调用DSP端函数__MTrn()执行矩阵转置运算(Step 2)。 步骤3:作废CPU Cache中的内容,完成矩阵转置运算(Step 3)。 DSP端函数__MTrn()负责在一个GPDSP簇上完成矩阵的转置操作,其基本思想是将A矩阵划分为Mb×Nb大小的子矩阵,依次加载到DSP的AM空间并扩展成Ma×Na大小(第12行),调用trnKernel()函数完成Ma×Na子矩阵的转置运算(第13行),然后从AM空间读取Nb×Mb子矩阵存储回B矩阵中(第14行)。trnKernel()函数负责将AM空间中Ma×Na的矩阵进一步划分成ha×wa大小的子矩阵,然后依次调用向量化矩阵转置核心Vtkernel()基于VPU完成ha×wa子矩阵的转置。 对于DSP端的应用,可以直接调用DSP端函数__MTrn(),避免了CPU与DSP之间的反复交互开销。 总的来说,本文提出的并行矩阵转置算法ftmMT具有以下三个特点: 1)不依赖任何CPU开源转置函数库,也不依赖其他DSP矩阵转置函数库; 2)基于AM空间实现,增加了DMA每次传输的数据量,从而减少了DMA操作的总次数,大幅降低了DMA启动开销; 3)基于DSP VPU单元实现,能够有效利用VPU单元的Load/Store带宽。 Vtkernel()是DSP上基于VPU来实现矩阵转置的关键核心函数。为充分利用FT-M7032的向量部件来提高矩阵转置的性能,以单个数据大小为8 B、ha和wa均为16为例,本文提出了如图4所示的Vtkernel()的实现过程,一共分为6个步骤。 图4 基于DSP VPU的向量化矩阵转置核心流程Fig.4 Flow chart of vectorized matrix transpose kernel based on VPU of DSP 步骤1:基于VPU的向量Load功能将16×16大小子矩阵中的16行分别读入16个对应的向量寄存器中。比如,第0~3行,分别读入向量寄存器VR0/4/8/12中;第4~7行,分别读入向量寄存器VR1/5/9/13中等。 步骤2:对向量寄存器进行分组,将向量寄存器分为VR0~VR3、VR4~VR7、VR8~VR11和VR12~VR15四组,然后将分组后的寄存器组分别调用模16存储指令VSTDW0M16/VSTDW1M16,第一次将数据存入AM临时空间,分别完成4行的转置。比如,基于VR0~VR3,调用模16存储指令VSTDW0M16/VSTDW1M16完成了原16×16子矩阵中第0、4、8、12行组成的新子矩阵的转置。 步骤3:基于VPU的向量Load功能将步骤2产生的AM临时空间中16×16大小临时矩阵重新读入16个对应的向量寄存器中,读入规则与步骤1完全一致。 步骤4:再次将向量寄存器进行分组,并再次基于模16存储指令VSTDW0M16/VSTDW1M16将数据存入AM临时空间,分组规则与调用模16存储指令的规则与步骤2完全一致,从而完成了原16×16大小子矩阵的转置,转置结果存储在AM临时空间。 步骤5:从AM临时空间中读入转置后的临时矩阵到向量寄存器中。 步骤6:将向量寄存器中保存的转置后子矩阵存入Ma×Na矩阵中对应位置,完成ha×wa大小子矩阵的转置。 对于单个数据大小分别为4 B和2 B的矩阵来说,处理流程大致相似,只需在步骤1与步骤2之间加入数据打包过程,即:根据最后的转置需求,将原始子矩阵中相邻两行的2个 4 B数据和相邻四行的4个2 B数据分别合并为1个8 B数据,分别产生新的2行和4行8 B数据存储于向量寄存器中。最后,基于所产生的新寄存器数据执行步骤2~6,构建转置后的矩阵。以单个数据大小为4 B为例,设置ha和wa为32,每两行数据分别进行高低位打包操作形成新的32行数据,如图5所示。随后将新32行数据以行号为基准进行奇偶分组,即奇数编号16行与偶数编号16行,随后分别执行步骤2~6,即可完成32×32大小4 B矩阵的转置。对于单个数据大小为2 B的矩阵转置,设置ha和wa为64,然后分别进行打包和转置。 图5 VPU中高低位数据打包功能Fig.5 Packing of data in VPU 本文算法在设计中主要涉及ha×wa、Mb×Nb两组分块参数的选择与评估。 在矩阵转置过程中,ha×wa表示Vtkernel一次处理的子矩阵大小,其主要涉及两个方面因素的影响:一是对于特定元素大小,向量化转置核心功能实现中所要求的最小矩阵大小。如第3.2节所示,对于8 B、4 B以及2 B的矩阵转置来说,ha×wa最小要求为16×16、32×32以及64×64。二是为充分利用VPU中两个向量Load/Store单元的处理能力,需要同时执行多个最小矩阵的转置,尽可能填充满流水线,实现VPU的最大化利用。在本文实现中,对于8 B、4 B以及2 B的矩阵转置,Vtkernel分别一次完成4个、1个以及1个最小矩阵的转置,从而ha×wa分别取为32×32、32×32以及64×64。 Mb×Nb的选择涉及四个方面因素的影响:一是Mb和Nb应该尽可能分别是ha和wa的整数倍。二是受到AM可用空间大小的约束,即存储Aam[Ma][Na]、Bam[Na][Ma]和Vtkernel实现中临时空间大小Tempam之和不能超过AM可用空间的大小。对于8 B、4 B以及2 B的Vtkernel实现,Tempam分别为8 KB、4 KB以及8 KB。三是DMA访问DDR内存的性能受连续访问的块大小与调用次数的影响较大。从DDR读取矩阵A的子矩阵A(m,n)[Mb][Nb]过程中,连续访问DDR的块大小为Nb个数据;将转置后的子矩阵Bam[Nb][Mb]存入DDR中B的过程中,块大小为Mb个数据。因此,在前两个因素的约束下,Mb与Nb的取值理论上应尽可能接近,从而才能在转置实现过程中同时保证DDR读和写的性能。四是根据参数的实时调整,当输入矩阵A的宽度N小于Nb或高度M小于Mb时,将分别动态降低Nb或Mb的大小。同时,在AM可用空间约束下,随之增大Mb或Nb的大小。 为充分发挥多核DSP的并行性能,本文算法设计中将实现面向多个DSP核的线程级并行,具体为将矩阵A划分为多个Mb×Nb子矩阵,然后调用多个DSP核并行完成多个Mb×Nb子矩阵的转置,直到完成矩阵A中所有Mb×Nb子矩阵的转置。在算法实现上,即在M和N两个维度进行多核并行,如算法1中第6行和第9行所示。 乒乓算法是用来实现计算与数据传输重叠的经典方法,分为显式乒乓与隐式乒乓两种。显式乒乓是在单个DSP核内实现计算与数据传输重叠,需要将单个DSP核内如AM等片上空间平均划分为两部分,一部分用于数据传输(DMA操作),一部分用于计算(trnKernel函数)。隐式乒乓算法是在多个DSP核之间实现计算与数据传输的重叠,即一个DSP核的计算与另一个DSP核的数据传输重叠。在FT-M7032单簇8个DSP核并行计算时,隐式乒乓算法是一种天然存在的重叠形态,不需进行特殊设计。两种算法相比各有优缺点,如隐式乒乓算法中总存在DSP计算核在等待数据的传输,而显式乒乓算法虽然可以让单个DSP核不间断地进行计算,但每次DMA传输的数据量降为隐式算法的一半,总数据传输开销变大。鉴于矩阵转置属于访存密集型操作,访存性能或数据传输性能才是决定性能的关键。因此,ftmMT采用隐式乒乓算法来实现trnKernel函数与DMA数据传输操作的重叠,通过最大化降低数据传输开销来实现总时间开销成本的最小化。 在本节中,将全面评测本文所提算法ftmMT的性能。首先,测试转置矩阵位于片上AM空间时矩阵转置实现的性能,即trnKernel实现的性能。其次,测试不同Mb×Nb大小对于ftmMT性能的影响。最后,测试ftmMT在不同矩阵大小下的算法性能,并与运行在FT-M7032 多核CPU上的开源算法HPTT进行性能比较。 在本节中将用两个指标来衡量矩阵转置的性能,一个是完成矩阵转置的时间T,另一个是转置带宽F,其计算如式(2)所示。 (2) 其中,QSizeof(a)表示矩阵A或B中一个数据的字节数。本文算法主要支持8 B、4 B以及2 B大小数据的矩阵,在后续讨论中对应实现分别标记为ftmMT-64/trnKernel-64、ftmMT-32/trnKernel-32以及ftmMT-16/trnKernel-16。考虑到这些实现所处理的基本块大小ha×wa不尽相同,实验中采用了不同的输入矩阵规模来进行对应实现的测试。 当Ma×Na取不同大小时,处理不同数据大小的trnKernel的性能如图6~8所示。对于所有测试的子矩阵来说,时间开销均低于10 μs。随着Ma×Na大小的增加,转置带宽呈逐渐增加的趋势。对于8 B矩阵,当Ma×Na为192×224,获得了最高145.45 GB/s的矩阵转置带宽,如图6所示;对于 4 B矩阵,当分块大小为256×352时,最高矩阵转置带宽为98.12 GB/s,如图7所示;对于2 B矩阵,当分块大小为384×448时,最高矩阵转置带宽为102.77 GB/s,如图8所示。 图6 trnKernel-64实现的性能Fig.6 Performance of trnKernel-64 implementation 图7 trnKernel-32实现的性能Fig.7 Performance of trnKernel-32 implementation 图8 trnKernel-16实现的性能Fig.8 Performance of trnKernel-16 implementation 如第3.3节分析所知,分块矩阵Mb×Nb受多个因素约束,同时也对最终矩阵转置性能有较大的影响。为评估不同分块大小的性能,本小节测试了ftmMT实现在Mb×Nb不同大小下的性能,实验结果分别如图9~11所示。其中,横坐标表示不同的分块大小,从左到右,Mb逐渐增大,Nb逐渐减小,即分块子矩阵从矮瘦矩阵逐渐演变为高瘦矩阵,但Mb和Nb的乘积尽可能接近ftmMT实现中AM空间所允许的最大值。本节测试中,输入矩阵A的大小M×N为固定值,对于ftmMT-64和ftmMT-32,输入矩阵A均为16 384×16 384的方形矩阵;对于ftmMT-16,输入矩阵A的大小为32 768×32 768。 图9 输入矩阵A为16 384×16 384的矩阵,不同分块大小下ftmMT-64实现的性能Fig.9 Performance of ftmMT-64 under different block sizes when the input matrix A is 16 384×16 384 matrix 图10 输入矩阵A为16 384×16 384的矩阵,不同分块大小下ftmMT-32实现的性能Fig.10 Performance of ftmMT-32 under different block sizes when the input matrix A is 16 384×16 384 matrix 图11 输入矩阵A为32 768×32 768的矩阵,不同分块大小下ftmMT-16实现的性能Fig.11 Performance of ftmMT-16 under different block sizes when the input matrix A is 32 768×32 768 matrix 对于ftmMT-64,如图9所示,当输入矩阵A为16 384×16 384的矩阵,分块大小为192×224时,矩阵转置性能最佳,其中耗时为152.56 ms,转置带宽达到了26.22 GB/s,对应的DDR有效带宽利用率为61.61%。 对于ftmMT-32,如图10所示,当输入矩阵A为16 384×16 384的矩阵,分块大小为256×352时,矩阵转置性能最佳,其中耗时为72.78 ms,转置带宽达到了27.48 GB/s,相应的DDR有效带宽利用率为65.17%。 对于ftmMT-16,如图11所示,当输入矩阵A为32 768×32 768的矩阵,分块大小为448×384和576×320时,矩阵转置性能最佳,其中耗时为155.34 ms,转置带宽达到了25.75 GB/s,相应的DDR有效带宽利用率为60.41%。 通过本小节的评估,从图9~11呈现的实验结果可以看出,对于不同分块大小Mb×Nb,ftmMT-64、 ftmMT-32和ftmMT-16所实现的性能均呈现中间高、两边低的特点,与第3.3小节的分析设计相符。 本小节对ftmMT处理不同大小矩阵的性能进行评估,并与运行在FT-M7032中多核CPU上的开源高性能张量转置库HPTT进行性能比较。本小节采用第4.2节中获得最佳性能的Mb×Nb大小作为ftmMT实现中的分块大小。同时,由于HPTT仅支持8 B和4 B大小数据矩阵的转置,因此也仅进行相关实现的比较。在HPTT测试中,线程数设置为16,即使用FT-M7032中所有的CPU核来进行并行矩阵转置运算。 对于ftmMT-64,测试结果如表1所示。与HPTT相比,在输入矩阵小于1 024×1 024规模时,ftmMT-64的性能较低。主要原因是ftmMT-64的时间开销里包含了刷Cache的开销(算法1中Step 1和Step 3的开销),该部分开销是相对固定的,属于ftmMT的固有开销,与输入的矩阵大小无关。当输入的矩阵规模较小时,刷Cache的开销在总时间开销中所占比例较大,从而使得ftmMT算法的性能低于HPTT。当输入的矩阵规模变大时,DSP端函数__MTrn()的时间开销增加,刷Cache开销所占比例也逐渐变小。当输入矩阵大于等于1 024×1 024时,ftmMT-64的性能均优于HPTT。当输入矩阵规模为4 096×4 096时,ftmMT-64的耗时仅为HPTT的15.14%,计算速度为HPTT的6.61倍。在ftmMT-64的测试中,转置带宽最高为30.98 GB/s,与DDR的理论带宽42.62 GB/s相比,对应DDR有效带宽利用率达到了72.69%。除了刷Cache开销包含在ftmMT总开销内的原因外,影响ftmMT的DDR有效带宽利用率的另一个重要因素是DDR本身的实测带宽与理论值存在差距。 表1 不同矩阵大小下ftmMT-64与HPTT的性能Tab.1 Performance of ftmMT-64 and HPTT implementations under different matrix sizes 对于ftmMT-32,测试结果如表2所示。当输入矩阵规模为8 192×8 192时,转置带宽达到了32.37 GB/s,相应的DDR带宽利用率为75.95%。与HPTT相比,当输入矩阵小于等于1 024×1 024时,ftmMT-32的性能较低,与ftmMT-64情况一样,也是因为刷Cache开销占总执行时间的比率较大。当输入矩阵大于1 024×1 024时,ftmMT-32的性能也是均高于HPTT。当输入矩阵规模为8 192×8 192时,ftmMT-32的耗时仅为HPTT的11.13%,转置带宽加速比高达8.99。 表2 不同矩阵大小下ftmMT-32与HPTT的性能Tab.2 Performance of ftmMT-32 and HPTT implementations under different matrix sizes 对于ftmMT-16,测试结果如表3所示。当输入矩阵规模为16 384×16 384时,ftmMT-32的转置带宽达到了31.78 GB/s,DDR的有效带宽利用率为74.57%。 表3 不同矩阵大小下ftmMT-16的性能Tab.3 Performance of ftmMT-16 implementation under different matrix sizes 从上述实验结果可知,ftmMT-64、 ftmMT-32和ftmMT-16均能有效发挥DDR存储器的性能,且ftmMT-64与ftmMT-32相对运行在多核CPU上的HPTT实现了较高的性能提升。 本文针对飞腾异构多核DSP的体系结构特征与矩阵转置操作的特点,基于DSP VPU的实现方法,提出了一种适配不同数据位宽(8 B、4 B以及2 B)矩阵的并行矩阵转置算法ftmMT。ftmMT基于矩阵分块实现了多个DSP核的并行处理,通过隐式乒乓设计实现了片上向量化转置与片外访存的重叠,有效克服片外存储带宽受限、频繁调用DMA以及访存效率较低等问题。通过开展相关实验,证明了ftmMT能够显著加快多核DSP上的矩阵转置操作,DDR的带宽利用率最高达到75.95%;与HPTT相比,可获得高达8.99倍的性能加速。该项研究对于推动国产化多核DSP在科学计算和深度学习领域的应用具有重要的意义。

2 面向FT-M7032的矩阵转置实现分析
3 并行矩阵转置算法与优化
3.1 ftmMT算法整体设计

3.2 向量化矩阵转置核心

3.3 分块设计
3.4 多核并行与乒乓设计
4 性能评估
4.1 trnKernel的性能评估



4.2 不同分块大小下ftmMT的性能评估



4.3 不同大小矩阵下ftmMT的性能评估



5 结论
