基于多特征和LOF的用户负荷突变检测
2023-03-09曾静娄冰吕娜邓隽王冠明
曾静,娄冰,吕娜,邓隽,王冠明
(1.浙江华云信息科技有限公司,杭州 310007;2.杭州师范大学 附属未来科技城学校,杭州 311100)
0 引言
随着现代电力技术向智能化、信息化、数字化方向的高速发展,电力数据量呈指数型增长,居民用户负荷也呈高速增长态势,用户用电行为日趋复杂[1]。负荷曲线是电力系统运行规划、负荷预测和用户画像等分析预测的重要依据,因此数据质量尤为重要。为了高效地挖掘和分析数据,维持电力系统稳定运行,异常值检测和分析必不可少。其中用户负荷突变事件检测是非介入式负荷辨识技术中的核心原理之一[1],负荷突变与天气、政府政策等息息相关,通常用户用电异常、设备故障或者采集通信过程中的扰动都会对电力系统运行产生较大影响[2]。大多突变负荷在后续分析中需要进行特殊处理,因此从负荷曲线中有效地检测突变负荷数据对后续负荷特征辨识与电网稳定运行有重要意义,尤其可在用电安全检查、配电台区的优化调度管理、用户负荷画像及负荷预测方面提供应用。
从源端监测负荷数据的异常值检测方法较为成熟且效果较好。文献[3]提出了一种基于滑动窗口和多元高斯分布的变压器油色谱异常值检测方法。文献[4]提出了一种基于滑动窗口和聚类算法的变压器状态异常检测方法。文献[5]提出了一种基于灰色关联度和K-means 聚类的异常数据检测方法。源端监测负荷数据异常识别在变压器状态评估和故障诊断中有重要作用,但其对后续大量负荷数据特征研究、电能生产、调度分配和负荷预测等规律性研究益处不大。文献[6]介绍了因子分析的理论及其应用于母线负荷异常数据辨识的原理,提出了基于因子分析的母线负荷异常数据辨识方法,对母线负荷突变有较好的辨识结果。文献[7]基于采样技术对FCM 算法进行改进,利用遗传算法对聚类结果进行优化,实现了对电力异常数据的动态处理,但数据量小,算法相对复杂。文献[8]采用基于相对密度和相对距离的方式对聚类中心进行判别,利用LOF(局部离群因子)算法对负荷曲线进行聚类,从而基于聚类检测出异常数据,但该方法需要面向特定的数据集。针对用户负荷数据量大、时间强耦合、高维复杂,且不同变压器负荷特征大相径庭的特点,目前主要采用传统的概率统计或者阈值判定法对其突变异常进行检测,但传统方法存在检测准确率低、互信息量小、计算复杂、灵活性低等问题[9]。
本文针对用户负荷数据量大、且需要每天监测数据异常的需求,基于以阿里云为基础的数据中台对变压器负荷进行数据挖掘,分析数据的潜在特征,提出了多特征与LOF 算法相结合的在线负荷突变异常检测方法。该方法不仅可以进行异常值检测,还可以根据阈值设定异常程度,将业务上认为突变异常的负荷曲线识别出来;结合实际情况,在中台每天定时检测并存储突变异常,以便后续进行快速统计分析和展示,从而实现突变检测的工程化应用。
1 负荷数据特征提取
1.1 负荷数据特点
用电负荷是指连接在系统上的一切用电设备所消耗的功率,负荷数据是大量、连续和有序的,一般负荷一天之内用电模式相对固定,波动较小。用电负荷也会随人口增长、季节变化以及生活水平而变化,具有以下主要特点[10]:
1)周期规律性。负荷数据是用户用电消费行为的外在表现,各类型用户的生产、生活往往呈现出一定的周期性规律。
2)时序性强。负荷数据以数据流的形式出现在采集、传输和存储各个环节,前后点相关性较大。
3)数据处理代价高昂。负荷数据一般为高精度浮点数且数值敏感性较强,用户数量大和采集频率高导致其数据量非常大,分析困难且需要大量计算资源。
4)随机性。由于电网的复杂性和用户活动的灵活多变性,突变普遍存在且难以预测。
虽然负荷具有随机性,但在一天内用电变化不会特别大,多天用电模式相对固定。如图1所示为某用户的5 天负荷曲线,用电负荷大多在10~35 kW之间变化,且变化不会特别剧烈。
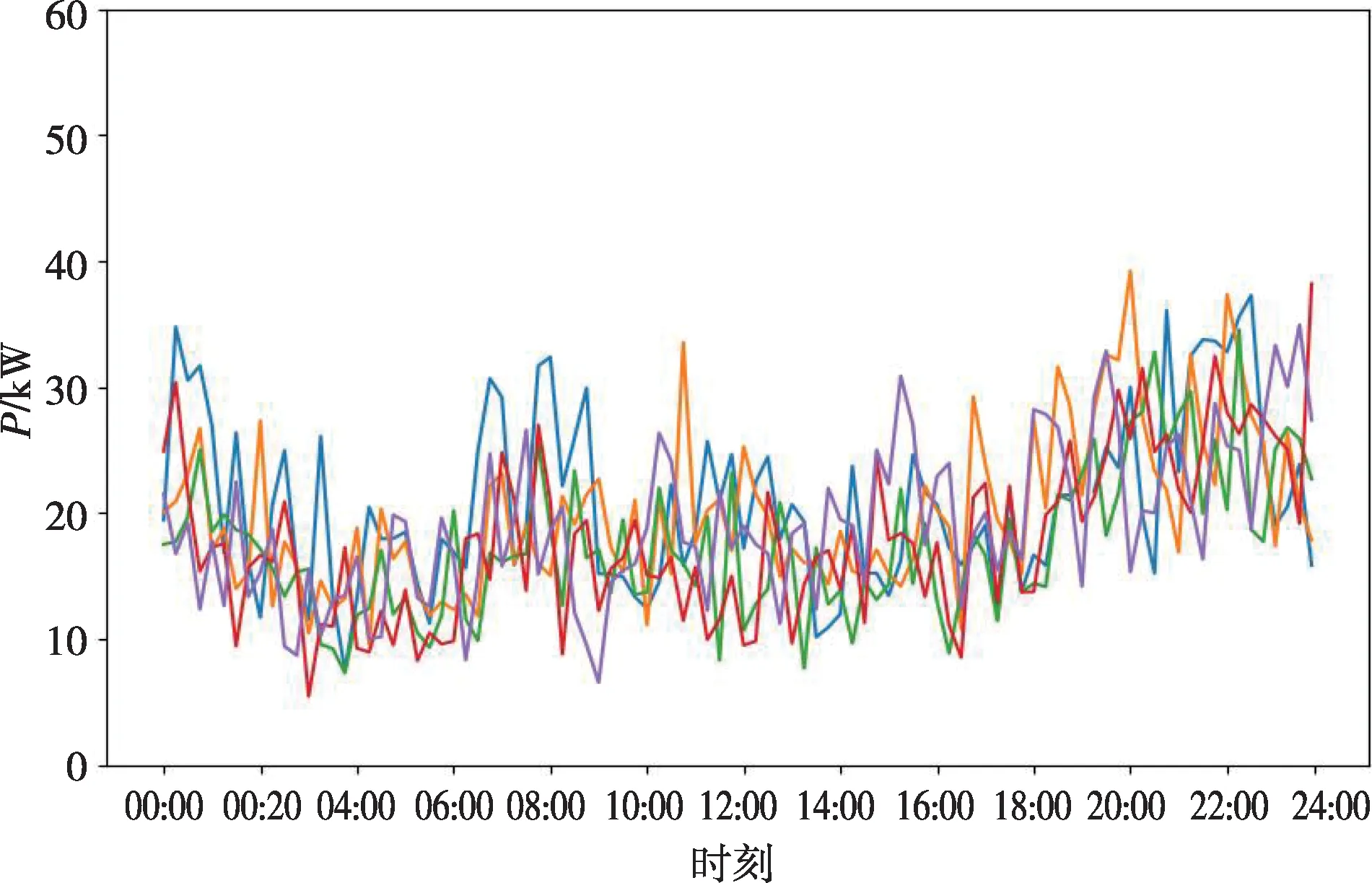
图1 某用户5天负荷曲线Fig.1 Load curves of a user in five days
而存在负荷突变的曲线变化速度快、间隔短,往往带有暂升、骤降等突变特性。突变负荷可大致分为毛刺型突变负荷和连续型突变负荷两类[11]:毛刺型突变通常表现为相邻时刻负荷数据突然增大或者突然减小,如图2所示。连续型突变通常表现为负荷转移,多是线路由于局部故障或者存在故障风险时承担其他线路负荷,使负荷在电网中重新分配,如图3所示。
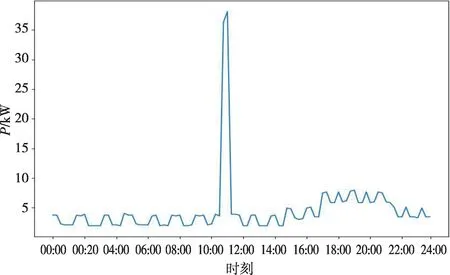
图2 毛刺型突变负荷Fig.2 Burr-type load change
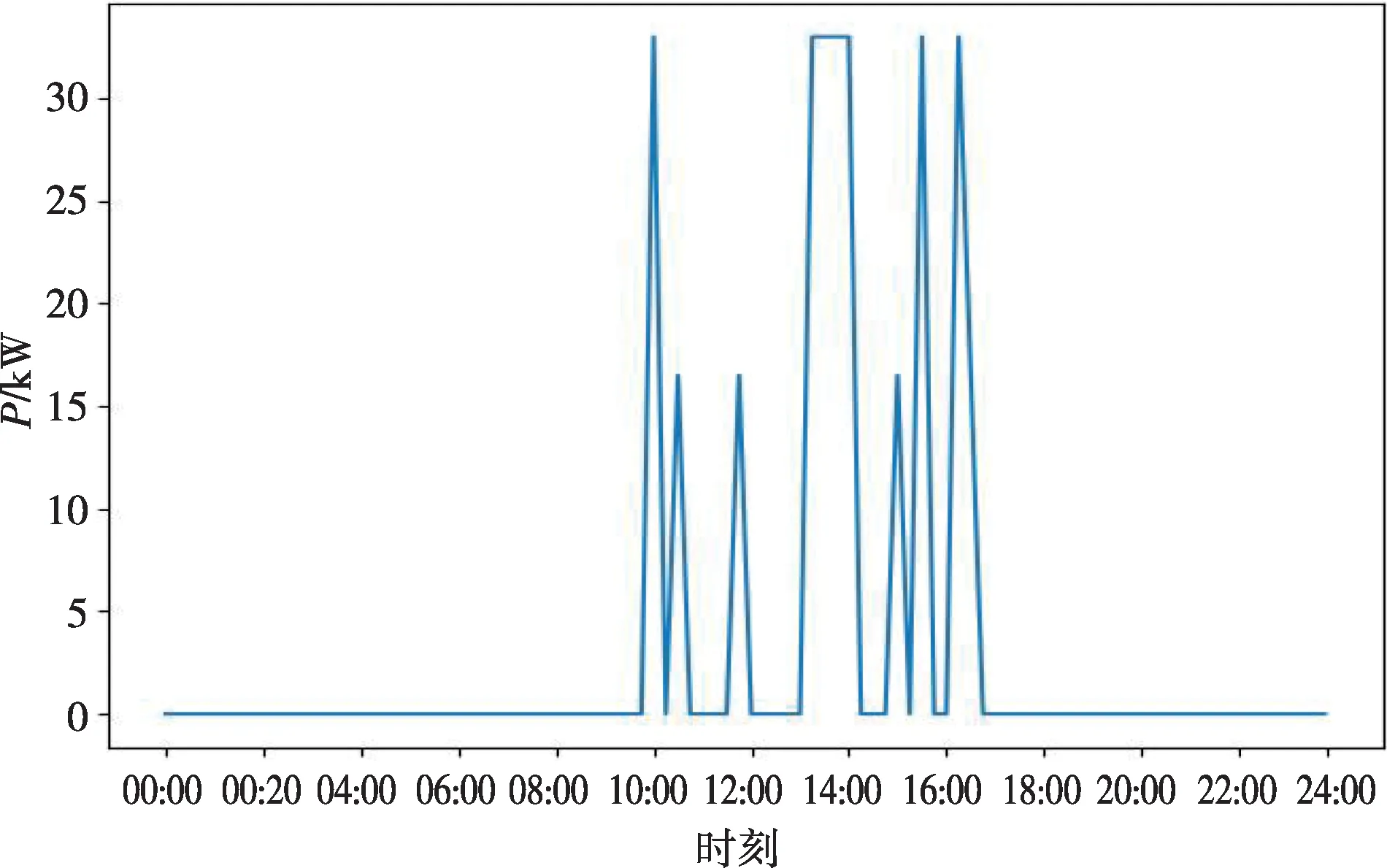
图3 连续型突变负荷Fig.3 Continuous load change
1.2 特征分析与提取
负荷突变判断需要考虑受多方面因素的影响而产生的非规律性波动。每天选取用户96 点负荷作为特征输入维度过大,且单纯的负荷量测数据对于突变这种行为特征表述不够准确。为了降低数据维度并实现对海量用户负荷数据的有效分析,需要进行数据挖掘并提取关键特征。负荷曲线是电力系统中负荷数值随时间变化的曲线,与信号有类似的规律,受信号分析方法启发,主要提取变压器负荷曲线数据统计特征和波形特征。统计特征包括平均负荷和标准差,波形特征[12]包括峭度、离散系数、波形因子和脉冲因子。
平均负荷即对当天96 点负荷取平均值,这是表示变压器一天用电负荷最直观、简明的统计特征。
标准差σ主要用于统计每天96 点负荷曲线数据的差异程度;方差是各个数据与其算术平均数和离差平方和的平均数;标准差为方差的算术平方根。计算公式如式(1)所示,n为负荷曲线采集点数量;Xi为任一采集点负荷;Xˉ为负荷曲线数据平均值。
峭度Ck表示波形的平缓程度,用于描述数据的分布。正态分布的峭度等于3;峭度小于3时分布曲线会较“平”;大于3时分布曲线较“陡”。计算公式如式(2)所示:
离散Cd系数用于比较不同样本数据的离散程度。离散系数大,说明数据存在抖起抖落的现象;离散系数小,说明数据比较均衡。计算公式如式(3)所示,xmean为负荷曲线数据平均值:
波形因子Cs是数据均方根与平均值的比值[13]。在电子领域其物理含义为直流电流相对于等功率的交流电流的比值,其值大于等于1,在这里表征负荷数据相对于平均值的波动程度:
脉冲因子Cif是信号峰值与整流平均值(绝对值的平均值)的比值[14],代表峰值在波形中的极端程度:
本文主要采用人工提取特征,因此特征中可能会存在冗余信息,这些特征不仅不会增加异常检测的有用信息,相反可能会降低检测性能。因此,需要对其进行降维,提取对突变数据检测有效的特征。
2 基于多特征和LOF 算法的用户负荷突变异常检测
由于电力数据量极大,并且突变数据并未有适用的方式进行识别和标注,均为无标签数据,因此用无监督算法对突变数据进行检测最为合适。基于对负荷曲线提取的特征,采用PCA(主成分分析)方法进行降维,并使用LOF 对所有用户负荷数据进行聚类,对突变异常数据进行检测。
2.1 PCA基本原理
PCA 是一种数学降维方法。将提取到的负荷数据多维特征进行降维的主要目的在于:简化运算、去除数据噪音、发现隐形相关变量。PCA 算法能够减少数据集的维数,同时保持数据集贡献率最大特征并找到隐变量,可简单高效地对特征进行处理。PCA 基本原理是利用正交变换将一系列可能线性相关的变量转换为一组线性不相关的新变量,也称为主成分,从而利用新变量在更小的维度下展示数据的特征[15]。基本步骤如下:
1)将特征数据按列组成N行M列矩阵X。
2)将X的每一行进行零均值化,即减去每一行的均值。
3)求出X的协方差矩阵C。
4)求出协方差矩阵C的特征值及对应的特征向量,C的特征值就是Y的每维元素的方差,也是D的对角线元素,从大到小沿对角线排列构成D。
5)将特征向量按对应特征值大小从上到下按行排列成矩阵,根据实际业务场景,取贡献率为99%的前R行组成矩阵P。
6)Y=PX即为降到R维后的目标矩阵。
2.2 LOF算法基本原理
LOF 算法是一种基于密度的无监督高精度离群点异常检测算法,其主要思想是:针对给定的数据集,对其中的任意一个数据点,如果在其局部邻域内的点都很密集,认为此数据点为正常数据点;而离群点则是距离正常数据点最近邻的点都比较远的数据点,通常由阈值界定距离的远近[16]。
LOF 算法的核心是将特征分布异常离群的点“挑出来”,由于负荷曲线数据异常值只占很少一部分,因此相比非监督聚类算法,采用LOF 算法把异常分布相似的点集“聚出来”会更有针对性,同时比传统的统计方法考虑更多互信息,且灵活性高。当未知类型的异常数据因为各种原因而分布比较零散、且距离正常数据集合较远时,LOF算法具有很好的表现性能,而负荷曲线在提取特征降维后已有了基本的区分,非常适合采用LOF算法进行异常值检测。
对于一个给定的点p,LOF 算法的基本过程[17]如下。
1)对象p的k距离。对象p的k距离指对象p与它第k近邻数据点o的距离,用dk(p)表示:
满足条件:集合中至少存在k个数据点o′∈D,使得d(p,o′)≤d(p,o);集合中至多存在k-1个数据点o′∈D,使得d(p,o′)<d(p,o)。
Nk(p)是p的第k距离及以内的所有点,包括第k距离,因此p的第k邻域点的个数|Nk(p)|满足|Nk(p)|≤k。
2)对象p到对象o的第k可达距离。可用reach_distk表示,该距离至少是o的第k距离,或是o、p间的真实距离:
reach_distk(p,o)=max{dk(p),d(p,o)} (7)
3)对象p的局部可达密度。使用局部可达密度表征样本点p的密度,用lrdk(p)表示:
4)对象p的LOF。离群因子标识了一个数据点的离群程度,用LOFk(p)表示:
LOFk(p)表示对象p的邻域点Nk(p)的局部可达密度之比的平均数,对象p的LOF 意义在于其值越接近1,说明点p与其邻域点的密度相差较小,属于同一类簇;如果比值大于1,说明点p的密度小于其邻域点的密度,p有可能是异常点。
检测异常值需要计算每一个样本的LOF 并设置阈值,通过阈值与离群因子的比较来判断样本点是否为异常值。
2.3 基于多特征和LOF 算法的用户负荷突变异常检测步骤
用户分为专变用户和公变用户。本文以营销系统某市所有专变和公变负荷数据为实验数据,为了更加精确地判定负荷,每15 min 更新1 次,一天共选取96 个负荷量测值数据。主要检测步骤如下:
1)将T-1 的数据按量测点进行分组,形成以id为主键、以分钟为表字段的宽表。
2)对分组后的负荷进行数据处理,漏点补全(插值),并对96点负荷均为0的数据进行剔除。
3)提取每个用户T-1 负荷曲线的时域和波形特征。
4)使用PCA 对特征数据进行降维,提取主要特征。
5)将降维后的2 个新特征作为输入,设定LOF算法中邻域K和离群阈值λ。
6)计算样本p的离群因子LOFk(p)。
7)比较离群因子LOFk(p)与离群阈值大小。LOFk(p)>λ时该样本为异常负荷,否则为正常负荷,从而将有突变数据和无突变数据进行区分。
具体检测流程如图4所示。
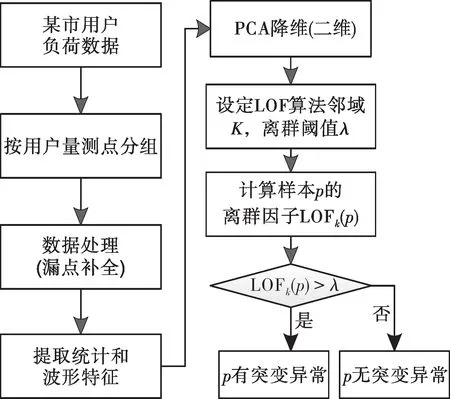
图4 检测总体流程Fig.4 Overall flow of testing
3 在线检测平台
用户负荷量测数据每15 min 更新1 次,且某市用户数量大,专变用户有4.7 万户,每天产生450 万条数据,公变用户有5.6 万户,每天产生540 万条数据。而负荷突变的检测需要每天进行,为了在数据量大的情况下将整个检测过程进行贯通,实现负荷突变检测的工程化应用,依托数据中台中数据读取和存储的优势,检测任务在公司创建的浙电数据中台中进行。
数据中台集成了阿里云各组件,其中max-Compute(大数据计算服务,原名ODPS)是一种快速、完全托管的TB/PB 级数据仓库解决方案[18]。MaxCompute向用户提供了完善的数据导入方案以及多种经典的分布式计算模型,能够更快速地解决用户海量数据计算问题。MaxCompute 支持SQL、MapReduce 和Python 等计算类型及MPI 迭代类算法,本文在数据开发过程中使用ODPS(开放数据处理服务)中SQL和Python的开发功能。
以数据中台中数据处理和分析组件为基础,每天定时对某市所有专变和公变用户负荷数据进行突变异常检测,平台中在线检测数据流如图5所示。

图5 在线检测数据流Fig.5 Online inspection data flow
在数据中台中实现整个流程的贯通。首先,从数据中台的ODPS 共享层中读取杭州T-1 的用户负荷数据;其次,通过ODPS SQL 开发功能对用户负荷量测数据和用户档案数据进行查看和关联;然后,使用PyODPS 开发功能编写负荷突变检测的Python 程序;最后,将有负荷突变的用户信息存储到ODPS分析层。
4 检测结果
以某市某天负荷数据为例,分别对专变用户和公变用户负荷曲线进行异常值检测。从数据中台ODPS 中取出数据并进行数据处理形成宽表,使用PyODPS 进行算法开发,分别从专变和公变用户负荷曲线中提取6 个统计和波形特征。基于PCA 降维后形成二维新特征,最终贡献率达98%,可极大程度地代表所有特征信息,并挖掘特征之间隐形特征,将二维特征以散点图形式进行可视化(如图6所示)。
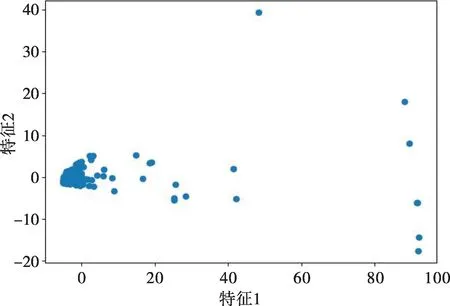
图6 降维后二维特征散点分布Fig.6 Scatter distribution of 2-dimensional features after dimensionality reduction
由图6可知,特征1数值在20以上的特征分布非常分散,负荷曲线特征有明显区别,检查数据后发现基本为有突变负荷数据;而特征1 数值在20 以下的基本为非突变负荷数据,只有少量数据为突变负荷数据。二维新特征可将突变和非突变负荷数据进行较为明显的区分,并作为异常值检测算法的输入。后续模型训练过程中也可根据降维后的特征规律对LOF离群阈值进行设置。
分别采用3σ算法、OneClassSvm 算法、Kmeans 算法、DBSCAN 算法对用户负荷数据进行异常值分析和检测,对检测出的用户负荷曲线可视化后进行人工判断发现:3σ算法和One-ClassSvm 算法会将某些光伏用户和较为平稳但偶尔有细微变化的负荷曲线误判为突变负荷;Kmeans 算法和DBSCAN 算法可能漏判某些连续突变的负荷曲线;其余方法均有误判或者漏判的情况,实践再次证明LOF算法为最优方法。
采用LOF 算法进行异常值检测后,得到的专变和公变负荷异常检测结果如表1 所示。可以看到,专变突变率为0.011,公变突变率为0.004。检测均能在2 min内完成,较快完成了取数据、负荷突变异常检测-存数据工作,从而每天都能对T-1的数据进行突变率检测。

表1 专变和公变用户负荷异常检测结果Table 1 Results of load anomaly detection for dedicated and public transformer users
从检测出的突变负荷曲线来看,均有类似脉冲的突变点,或是存在连续跳变的点,能较为准确地检测到突变信号。为了寻找负荷突变的原因和规律,按发生频率进行分类,无论是毛刺型突变还是连续型突变,都可以分为偶尔型和长期型。
结合各类产业特点发现,偶尔型负荷突变的原因包括采集传输过程中遇到干扰、设备故障、天气变化、紧急使用高功率设备和偷电漏电等导致突发性用电变化;长期型负荷突变主要涉及养殖场、海港捕鱼、机械制造和建筑工地等产业,在工作时经常会发生短时间内负荷的剧烈变化。
典型的偶尔型突变负荷运行模式如图7 所示。此用户为某房地产开发有限公司某酒店分公司,图7 中展示了该专变从2022-01-01—04-21 的负荷曲线,这期间负荷基本都在50 kW 左右,最多未超过100 kW;但在21日出现了突变,负荷功率一度达到277 kW。研究发现,发生突变的原因为采集传输过程中遇到干扰导致,属于偶发的情况。此类突变异常检测可以应用于两方面:一是在用户画像或者负荷预测时需要对突变负荷异常数据进行剔除处理,为后续研究提供可靠的数据;二是对突变负荷具体干扰原因进行排查,在用电安全检查过程中对类似干扰进行提早准备或告警,避免再发生影响电网稳定运行的情况。

图7 案例1负荷曲线Fig.7 Load curves of case 1
典型的长期型突变负荷运行模式如图8 所示。此用户为某市某农防专变,图8中仅展示了该专变从2022-04-15—04-21 的负荷曲线。可以看到,除4月19日仅下午发生1次突变外,其余几乎每天均有2 次突变,时间点在02:00 和14:00 左右,具有一定的规律性。研究发现该用户在开展一体化灌溉排涝工作,属于长期且相对稳定发生的情况。此类突变负荷异常检测可以应用于三方面:一是为用户画像和负荷预测等研究提供规律性特征;二是在用电安全检查过程中重点关注这些长期负荷突变的台区,排除负荷突变可能引起的用电问题;三是依据这种长时间稳定的突变负荷规律,优化配电台区的调度管理,在存在负荷突变的情况下维持配电网的稳定运行。

图8 案例2负荷曲线Fig.8 Load curves of case 2
5 结语
本文提出了基于多维特征和LOF 算法的用户负荷突变异常检测方法,能针对所有用户较准确地完成对突变异常负荷的检测,具有普适性,可在数据中台中定时调用,实现了工程化应用。完成负荷突变异常检测后,可在中台中高效迅速地从不同地区、不同日期、不同行业等维度多层面统计、分析、处理和展示突变的负荷数据,为后续负荷预测、用户画像、用电安全检查、配电台区的优化调度管理等方面奠定了数据基础。
