中文分词技术研究进展综述
2023-03-08钟昕妤
钟昕妤,李 燕
(甘肃中医药大学 信息工程学院,甘肃 兰州 730101)
0 引言
随着人工智能的发展,自然语言处理(Natural Language Processing,NLP)任务在实现人机交互、个性推荐、智能搜索、风险调控等场景中发挥着巨大作用。相较于英文,中文存在字词边界模糊且语法结构复杂的问题,影响了计算机的直接处理性能。中文分词(Chinese Word Segmentation,CWS)则通过各类方法实现文本字词的明确划分及词性标注等功能,一直以来是NLP 任务的基础步骤之一。
而近期,学者们对CWS 研究的必要性产生了一些争议。2019 年,Li 等[1]经四项NLP 基准任务对比实验发现,由于未登录词、数据稀疏和跨领域等问题的存在,使得深度学习的词级模型因更容易出现过拟合现象而表现不如字级模型。但这不能否认分词研究的意义。2020 年,Chen等[2]表示字级模型中缺乏的词信息对于文本匹配任务是潜在有益的。此外,在实体识别等涉及术语的NLP 任务中,其效果直接受中文分词基础任务结果影响[3]。而杨佳鑫等[4]将分词后词性结果引入模型中更是实现了实体识别性能的有效提高。由此可见,中文分词仍具有其重要研究意义。
回顾中文分词方法(Methods of Chinese Word Segmentation,MCWS)发展的整个历程,可将其大致划分为匹配、统计、深度学习三大类。如图1所示,基于CNKI平台,通过对“中文分词方法”主题词检索获得的所有文献进行计量可视化分析,在其次要主题中对“分词方法”“字符串匹配”“基于统计”“神经网络”进行文献趋势对比发现,自2017 年以来,深度学习方法逐步代替匹配与统计两类方法成为分词方法研究的主流。本文主要基于近5年国内外CWS技术研究文献,介绍并总结分析其传统方法与深度学习方法的研究现状以及其面临的相关难题,探讨CWS技术研究的热点以及未来发展趋势,以期为后续研究提供思路和方向。
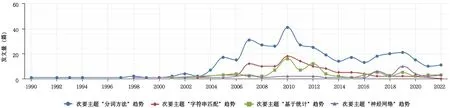
Fig.1 Word segmentation method,string matching,statistics based,neural network sub theme publishing trend图1 “分词方法”“字符串匹配”“基于统计”“神经网络”次要主题发文趋势
1 中文分词的传统方法
传统的中文分词方法主要为匹配与统计两大类,其现有研究已形成较为稳定的算法模型。
1.1 匹配方法
匹配方法主要通过各种算法将文本与词典进行匹配划分。匹配算法与词典构建皆是该方法的核心,直接影响了分词的效能与性能。经过研究发展,匹配算法主要形成了正向、逆向、双向等流派,词典构建则以二分、哈希表、TRIE 树等机制为主。其中,基于词长与语义大致呈正相关且主干成分常被后置的汉语规律,如杨文珍等[5]、张乐[6]等在进行中文分词时,大都采用逆向最大匹配算法。匹配算法的使用便捷高效,但此类方法的性能对词典的依赖程度极高,无法很好地处理词典中未出现的词以及多种可能的分词的情况,而这种情况在进行面向领域的中文分词任务时格外突出。由此,纯粹的匹配方法已不能满足目前的分词需求。在近期研究中,学者们大都将词典作为一种辅助手段,结合统计或深度学习的方法优化模型。其使用方法主要包括:通过构建领域词典[7-10]来提升模型在专业领域的分词性能,再通过动态更新词典[7]进行完善;利用词典构建伪标记数据[11]用于模型训练提高准确率。目前,词典的构建多是人工与统计方法的结合,而在初期,词典的构建主要源自专家们的手工构建,需耗费大量人力和时间。由此,随着计算机技术的发展,学者们开始尝试将数学的统计法应用于分词中实现机器自主分词。
1.2 统计方法
统计方法的基本思想是根据词组合出现的概率判断是否划分为词边界。该类方法能在一定程度上较好地解决分词歧义,且能识别出未登录词。当前CWS 研究中,常见的统计方法有N-gram 模型、隐马尔科夫模型和条件随机场模型等。
1.2.1 N-gram模型
N-gram 模型基于第n 词只依赖于前n-1 词的假设,攘括了词前所能获得的全部信息。凤丽洲等[12]利用标准词典和训练语料,通过组合词迭代切分,并基于N-gram 选择获取最优分词序列,在提升效率的同时实现了分词性能的提升。但在实际训练中,此类方法会因信息缺乏产生平滑问题,需要基于一定规模的语料进行训练。此外,因其参数空间随着n 值的增大呈指数增长,n 值在应用中大多取为1或2。
1.2.2 隐马尔科夫模型
隐马尔科夫理论(Hidden Markov Model,HMM)起源于马尔可夫过程(Markov Process,MP),描述将来状态仅依托当前状态,而无关于过去状态。但由于MP 限制条件在实际问题中难以满足,学者们在此基础上提出了双重随机过程的HMM。HMM 设立在齐次和独立两大假设前提上,主要涉及了隐藏的状态和序列观测两个随机过程,即任一点状态仅与前一点状态有关,而独立于其他点,且任一点观测只依赖于该点状态,而独立于其它点观测与状态。基于HMM,宫法明等[13]依据术语集判断并选择模型对应阶层,从而实现了领域下子学科的自适应分词。Yan 等[14]则利用HMM 对经词典匹配后的剩余文本进行二次分词,从而实现对未登录词的识别,并由此进一步完善词典。而基于独立假设的前提条件,HMM 无法很好地融合语境信息,存在效能不高的问题。对此,学者们进一步研究提出了条件随机场模型。
1.2.3 条件随机场
条件随机场(Conditional Random Fields,CRF)是一种无向图模型,在归一化时考虑数据的全局分布,从而克服了HMM 的不足,利用语境实现全局最优分词,成为统计方法中应用最为广泛的模型。基于CRF 模型,Lin 等[15]利用BIO 编码捕获数据隐藏变量和潜在结构,为每个输入序列选择最佳编码结果,并经实验验证了优越性。正是由于CRF 模型在序列标注问题上的良好表现,如Zhang 等[16]、Jun 等[17]、车金立等[18]众多学者们在近期研究中,将其与各类深度模型结合,以经深度模型输出的特征作为输入,进而获得最优序列标注结果。但由于其特征自定义且性能受特征限制的问题,当特征过多时CRF 模型更易倾向于过拟合和较低效率。
虽然统计方法能从一定程度上缓解歧义和未登录词问题,但此类方法构建的模型复杂度较高,且需要人工提取特征。随着人工智能的发展,基于深度学习的神经网络模型经过实验研究获得了更为精准高效的性能框架,学者们尝试将此类方法引入CWS任务中进行研究。
2 中文分词的深度学习方法
随着人工智能技术的飞速发展,中文分词的深度学习方法逐渐替代传统方法成为主流。该类方法主要通过各类神经网络模型使计算机能够模拟人的学习及分词过程。因此,模型大都基于已标注好的语料库进行训练,通过不断调整各参数实现模型的最优性能。相对于概率统计的分词方法,此类方法无需人工特征选择,更好地填补了统计方法的不足。目前的深度学习方法大多建立在卷积和循环等基础神经网络模型的变体之上。
2.1 卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)是基于卷积计算的前馈神经网络,包括卷积、池化、全连接等结构,在图像识别处理领域被广泛使用。近几年,学者们尝试将CNN 应用于NLP 任务中,并取得了不错的效果。传统CNN 的池化处理主要作用是精简特征,从大量特征中提取获得最具意义的,而这操作在进行NLP 任务时却会造成文本信息的遗失。因此,如Guan 等[19]、涂文博等[20]、王星等[21]大都使用无池化层的CNN 模型进行分词处理,在提高模型准确率的同时也加快了训练速度。深度学习的分词方法依赖于一定深度的网络模型,而随着神经网络层数的增加,会出现过拟合、梯度消失、网络退化等各种问题,这也是当前学者们重点研究的问题。王星等[22]先是通过跳跃膨胀宽度的卷积方式减少卷积层数提高效率,之后加深网络获得更丰富特征,采用残差连接[21]的方法来避免上述问题,并在小样本数据集上获得了更优效果。
2.2 双向长短时记忆网络
双向长短时记忆网络(Bidirectional Long Short-Term Memory,Bi-LSTM)是从循环神经网络(Recurrent Neural Network,RNN)发展而来的,可以很好地获取文本语境实现分词且对间隔较远或延迟较长的信息也有很好的学习能力,被广泛应用于CWS 任务的深度模型研究中。RNN可以通过传递序列获取上下文信息,但存在长期依赖的问题,即当词间距离过远时RNN 将学习不到词间信息。对此,学者们通过添加遗忘和记忆机制,在RNN 的基础上提出LSTM 模型,成功实现对长期信息的学习。但单层的LSTM 只能获取文本的前向信息,遗漏了下文中能对分词提供帮助的信息。于是,学者们通过叠加双向的LSTM 进行结合上下文信息的分词学习,形成了Bi-LSTM 模型。在此基础上,学者们通过信息融合、强化逆向等方法获得更多的上下文信息,实现模型优化。李雅昆等[23]利用加法器实现每层双向LSTM 网络的信息融合,从而获得更加充分的上下文信息。郭正斌等[24]依据词典逆向匹配具备更优效果和下文对分词具有更大影响两点,提出强化逆向序列的Bi-LSTM 模型,通过多加一层逆向的LSTM 获得了更多的下文信息。此外,针对RNN 的长依赖问题,学者们在LSTM 模型基础上,提出了一种兼具简单和高效的循环门单元(Gated Recurrent Unit,GRU)模型。
2.3 双向门限循环单元
相较于LSTM 模型中的输入、遗忘和输出三个门函数,GRU 模型仅用更新和重置两个门函数来保留重要特征。因此,GRU 模型相较于LSTM 所需参数更少,具有更优的分词效率,成为当前主流的深度模型之一。Che 等[25]基于GRU 提出了一种改进的双向GRU-CRF 模型,无需挂载分词字典和堆叠神经网络的层数就可达到与叠加三层的BiLSTM 模型分词性能相似的分词结果。Zhang 等[26]进行了Bi-GRU 和Bi-LSTM 的CWS 性能对比实验,验证了双向门限循环单元模型(Bidirectional Gated Recurrent Unit,Bi-GRU)在具备更简单结构的同时,兼具更快的分词效率,且不损失分词精度。但当训练规模达到一定程度后,Bi-LSTM 相较于Bi-GRU 模型具备更好的分词准确率。
2.4 BERT预训练模型
随着各类神经网络模型的训练研究,不乏有分词结果表现优异的模型,若在进行新任务将其作为初始模型,再根据新任务特性做些许精调,便能实现任务目标,使模型无需从零开始,这便是预训练模型的意义。2019 年,Ma等[27]在深度模型的基础上,通过预训练实验对比验证了其对提升分词性能的有效性。在当前CWS 研究领域中,先通过预训练模型获得通用特征再用于MCWS 中进行模型训练已成为研究热点之一。其中,最常见的便是BERT 预训练模型。BERT 基于双向Transformer,实现了对字两侧文本信息的充分利用且能动态生成字向量和词向量,为下游应用提供了更高效率。Yan 等[28]在其联合模型中对比是否引入BERT 模型的分词性能,验证了其对性能的提升。此外,BERT 模型只需通过添加一层输出的微调就能实现在不同领域任务中的应用,具有很好的普适性。俞敬松等[29]基于BERT 模型,根据语句分割少的特性,实现了适用于语料匮乏的古汉语文本的MCWS。而经实际应用发现,BERT 模型尚存优化空间。在其改进研究中,针对不同方向主要衍生出了两种模型:一方面,对于BERT 模型复杂参数、运行效率的优化,产生了更为轻便和快捷的ALBERT 模型;另一方面,对于BERT 模型处理性能的优化,产生了更为准确的ROBERTA 模型。胡昊天等[30]在非遗文本的分词模型对比实验中更是进一步验证了上述两种模型的特点。此外,由于训练样本生成策略的改变,即mask 标签替换从字变为全词,产生了如BERT-WWM、ROBERTA-WWM 等基于全词掩码的预训练模型。之后,哈工大讯飞联合实验室通过不引入掩码标记的自监督学习方法提出了PERT 预训练模型。众多预训练模型的产生为模型训练提供了更多选择。由于各类预训练模型在不同任务和环境中的性能表现不同,在分词应用中,需根据实际需求做进一步抉择。
CWS 研究过程中的各类方法都有其优缺点,单一的方法已无法充分满足目前CWS 高效、高准确率的需求,需融合各类方法,取长补短,形成更优的分词模型。目前的融合模型研究大多基于以神经网络模型为核心的特征提取层,先由预处理模型将句子转为字、词向量作为其输入序列,后经统计模型作为解码层进行概率最大化的序列标注,实现三类方法的充分融合。
3 中文分词面临的难题
3.1 传统难题
中文分词发展以来一直面临着两大难题,即歧义和未登录词,极大地影响了分词模型的性能和普适性。
3.1.1 歧义
歧义包括交集型与组合型:交集型即两词相连且存在重叠部分;组合型即一词可再细分为多个词构成。解决此类问题的关键在于找到导致歧义的歧义点。Li 等[31]通过在初始分词结果的基础上提取歧义点来构造新的分词,之后采用最大熵模型训练新的分词,通过选择每个歧义点对应概率最高的新分词作为有效分词,实现歧义消除,进一步提高分词性能。
3.1.2 未登录词
未登录词(Out-Of-Vocabulary,OOV)包括已有词表中未录入的词和训练语料中未出现的词,而由一般语料库训练的分词模型在特定领域任务应用下更为突出。目前,学者们大多基于新词发现的方法来缓解OOV 问题。Wang等[32]采用Bi-gram 算法和左右信息熵先后进行新词提取,构成新词词典,取得了更优的分词效果。Jun 等[17]提出将术语词典、新词检测和BILSTM-CRF 模型结合的MCWS,实现在特定领域下提高术语词的识别性能。由此可见,新词发现的方法能进一步完善词典,从而提高分词的准确率。但目前的新词发现方法对原有词典依赖较高[33],且其性能存在着一定提升空间,有待进一步优化研究。
3.2 新难题
随着深度学习方法的流行和分词技术在更多领域和场景中的广泛应用,一些影响其性能的新难题随之产生。
3.2.1 语料依赖
深度学习方法大多基于语料训练调整网络模型,从而获得更优性能。这从一定程度上决定了其对语料规模和质量的依赖性。其中,针对语料质量问题,由于词间没有明确的划分标准,且受到各种语言学理论影响,现存的几大语料库在注释上也有着不同的差异,由此训练获得的模型性能评估亦存在着一些不确定性。因而,如何统一分词标准,用更高质量的语料进行模型训练成为值得学者们研究的方向之一。其中,刘伟等[34]利用语义信息对语料中的不一致字串进行分类,实现了语料库的修正,提升了语料质量。针对语料规模问题,学者们主要通过充分利用大量未标记数据和局部标注数据的方法来缓解模型对语料规模的依赖问题。在利用未标记数据方面,Zhang 等[35]基于语义相似度抽样策略,从未标记数据中提取有用样本句子应用于模型训练,从而改进模型性能,Liu 等[36]基于后验正则化变体算法,利用词典和未标记数据作为间接监督纳入模型训练,在跨域场景下验证了该方法在训练数据不足时的有效性;在利用局部标注数据方面,Yan 等[37]通过不确定性和重复测量两种样本选择策略获得信息特征,并经上下文选择在每个信息字符周围选取子串进行局部标注,从而实现在少量标注数据的情况下有效地提升CWS 性能。此两类方法均基于一定的概率抽样方法从未标记或局部标记数据中获得有效特征,从一定层度上缓解了模型对语料规模的依赖问题。
3.2.2 多领域分词
随着CWS的广泛应用,文本处理过程中会出现同时涉及到多领域专有知识的情况。如在法律类文本中,分词可能同时面向法律、金融、科技等领域的专有术语,而这种现象在内容种类繁杂的社交类文本中将更为突出。在通用领域和专有领域的现有分词方法研究中,由于训练语料领域限制而造成分词模型适用性差和性能低等问题,现有方法往往无法充分满足新的分词需求。学者们通过使用涵盖多领域内容的语料、字典以及实现领域敏感等方法来提高分词模型的多领域适应性。张琪等[38]采用涵盖史政、典制、诗歌等多种题材的标注语料进行模型训练,实现对多领域先秦典籍的实用分词。Yuan[39]在经通用语料训练的CRF 模型基础上,采用多领域高质量字典和主动学习方法调整模型,降低了跨领域对其分词性能的影响。多领域语料和字典能从一定程度上提升分词模型的多领域适应性,但当涉及不同领域切分歧义等情况时,无法很好地准确分词。因此,及时准确地确定目标领域能有效缓解上述情况,进一步提升分词性能。Liu 等[40]基于NER 模块,根据模块优势对处理语料,实现领域敏感。Gong 等[41]通过采用切换器在多标准间进行自动切换,实现多种语料库的重复利用。上述方法均对字典或语料具有较高依赖,而同时涉及多个领域的语料和字典的构建更是需要相应领域专家的参与,构建需求颇高。因此,在面向多领域分词研究中,亟待学者们对相关机制做进一步优化,在降低其对字典和语料依赖的同时,进一步提升分词模型的多领域适应性。
4 结语
从近几年MCWS 研究中可以看出,各类方法有其自身的优缺点,而单一类的方法已无法充分满足实际需求,且在此发展过程中产生的语料依赖和多领域难题是目前乃至未来亟需解决的重点问题。由此本文总结CWS 未来研究趋势如下:
(1)推进以神经网络为核心的融合方法研究,实现更精简、更快速、更精准的CWS。
(2)通过统一标准或评估方法提升语料质量,确保模型研究的有效性。
(3)降低对语料的依赖性,充分利用未标注数据和局部标注数据,获得语料未增的分词性能提升。
(4)通过领域敏感机制优化等方法进一步获得兼具多领域信息文本的高效分词能力。
