基于语义向量的汉语动词“看”用法研究*
2023-03-07王义娜
杨 艺,王义娜
(北京航空航天大学,北京 100191)
人类通过视觉、听觉、触觉、嗅觉、味觉等感知方式与客观世界进行互动。在多种语言中,感知动词是人类表达对世界认知的语言载体。Viberg发现,视觉感知在五类感知情态中最为突显,数量也最多,且语义具有多样性和统治性[1]113-162。因此,视觉动词在整个感知动词范畴中具有重要且特别的地位。
视觉动词“看”是现代汉语中最高频使用的感知动词。首先,通过检索大型语料库,发现北京大学中国语言研究中心的CCL语料库中共有541 666个“看”的例句,北京语言大学开发的BCC汉语语料库中共有3 723 796个“看”的例句。“看”在《现代汉语频率词典》中使用度和频率排名第31位,在动词中的频率仅次于“来、去、到”,在感知动词中频率最高[2]492。此外,以往研究均表明了“看”具有多义性。《现代汉语词典(第7版)》中“看”有9个释义、44个词条。中文词汇网络(https://lope.linguistics.ntu.edu.tw/cwn2/query/)中“看”有12个词义。以上词频统计均可证明“看”是汉语母语者最常用的动词之一。
以往研究主要运用定性或语料库定量方法考察少数“看”类词或短语,本研究以分布语义理论(distributional semantics)为基础,结合计算语言学的语义向量(semantic vectors)方法和语言学统计研究方法,对感知动词“看”所组成的二字、三字、四字词汇或短语进行定量研究。
一、现代汉语动词“看”的多义性与多功能性
(一)动词“看”的多义性
与其他感知动词相比,视觉动词更具多义性。《现代汉语词典(第7版)》[3]729-730中的“看”共有9个释义:(1)使视线接触人或物;(2)观察并加以判断;(3)取决于;决定于;(4)访问;探望;(5)对待;(6)诊治;(7)照料;(8)用在表示动作或变化的词或词组前面,表示预见到某种变化趋势,或者提醒对方注意可能发生或将要发生的某种不好的事情或情况;(9)用在动词或动词结构后面,表示试一试。
中文词汇网络是由台湾地区学者开发的中文词汇释义平台(https://lope.linguistics.ntu.edu.tw//cwn2/),在对外汉语中运用广泛,具有一定的国际影响力[4]14-23。其认为汉语动词“看”包括以下语义:(1)用眼睛观察;(2)仔细查看特定对象;(3)仔细观察,作为判断或决定的标准;(4)透过视觉来理解或欣赏;(5)以特定态度对待;(6)决定于后述条件;(7)拜访、探望后述对象;(8)医生诊治病人;(9)病人接受诊治;(10)对事件做判断;(11)提醒,注意;(12)时态标记,表事件或动作的尝试。
虽然上述两种文献对“看”的词义界定存在分歧,但是可以发现“看”具有多义性。“看”的语义涵盖了视觉感知、观察、判断/推断、认知、就医、人际交往、尝试态标记等多个维度。
与此同时,“看”类结构非常丰富,既有被词典收录的动词,又有成为短语或话语标记的二、三、四字结构,它们彼此之间的联系也较为复杂。以往研究往往关注几个“看”类结构之间的比较[5]9,“你看”或“我看”的比较[6]8,或者是“看”与其他动词“想、说”等的横向对比[7]5,鲜有文献对“看”的所有用法进行整体研究。
(二)动词“看”的多功能性
以往研究对于“看”的多功能研究,主要从四个方面展开:(1)感知动词;(2)情态;(3)言据/传信;(4)话语标记。由于绝大多数研究“看”的文章均提到了其作为感知动词本身的用法,本文主要关注“看”作为情态、言据、话语标记时的用法。
以往研究表明,“看”类结构可以充当表达言者对命题确信程度的情态标记。赵彧认为,“看起来、看上去、看情况、看样子”的虚化过程经历了从“行域到知域、句法主语到言者主语、命题成分到情态成分、自由度低到高”四个阶段[8]50-59。范伟将部分“看”类结构划分成情态成分,认为“看起来、看来、看样子、看上去、看似”表达确信程度较低的揣测型认识情态[9]76-82。
“看”类表达不仅可以表达感知,还可以表达基于感知或推断的言据(信息来源)[10]11[11]65-78。朱永生认为,“看、看到、听到、听说”等动词可以表达言据,其中“看到、听到”的言据性强,“看”的言据性中等,“听说”的言据性最弱[12]7。
“看”的短语也可以充当话语标记。曹秀玲等认为“我看、你看”可以形成征询意见的一对表达,其中“你看”要求听者发表意见和看法,“我看”用于表达言者的意见或推断[13]13。“你看”更可以表示“寻求对方认同、劝慰和说服对方、责备抱怨”等用法。曹秀玲等对汉语中的“看来、看起来、看上去、看样子、看这意思、如此看来、由此看来、这么看来、这样看来”等结构进行研究后发现,“看”类结构从感知动词逐渐演变成了元话语标记,是表达推断的主要形式[14]13-20。
综上所述,现代汉语动词“看”相关的用法具有多义性与多功能性。基于此,我们提出以下研究问题:基于语料训练而成的语义向量能否反映前人研究中所发现的特征?语义向量能否帮助我们发现其他特征?
二、研究方法与研究对象
(一)研究方法
分布语义学起源于Harris提出的分布假设,其核心观点是“The distribution of an element will be understood as the sum of all its environments”,即一个元素的分布是它所有环境的总和[15]146-162。Firth认为“word is characterized by the company it keeps.”(一个词的特点是由它周围共现的词来体现的)[16]1-32。换言之,两个词的分布环境越相似,其语义和功能就越相似。说明两者的分布具有相似性,也就是功能较为相似。而且,利用分布语义学理论发现的相似词不一定是近义词,也可以是反义词、上义词、下义词等[17]149-188。反义词往往会和相似的词共现,说明二者在功能上具有相似性,其差异仅仅体现在语义对立的程度上。这一理论是语料库语言学和计算语言学研究语义的重要基础。
此后,由认知语言学家Gries和Divjak提出的行为特征分析法也将这一思想沿用到了多义词与近义词的分析对比研究中[18]75[19]153-164。他们对句中的主语、谓语、宾语、状语、补语等进行细粒度标记,再运用聚类分析等统计工具对近义词或多义词进行分类,以找出相似的语义或相似的词。这一方法曾用于研究俄语“尝试”类动词[20]23-60和英语“主要”义副词[21]198-288,为词义消歧和近义词区分提供了很好的方法。但是这一方法需要人工标注,工作量较大,可以研究的范围也很有限。
同样基于分布语义学的语义向量,是一种基于机器学习与自然语言处理的新技术,早期只要运用于机器学习和心理语言学等领域,近年来逐渐运用至具体语言现象的研究。Baayen等结合计算语言学与定量语言学的研究方法,提出语义的相似性可以由分布的相似性来体现,而分布的相似性可以由向量的相似性来体现[22]1-39。Hilpert明确指出,基于类符(token-based)的语义向量空间(semantic vector spaces)不仅能够运用至语料库研究中,还可以运用在理论驱动的研究中[23]393-424。这一思想是运用语义向量对比语义相似性的理论基础。其优势在于:语义向量由计算语言学家利用真实语料库训练而成,是一串可以用于计算的数值型向量,比行为特征分析法中的细粒度标注更加高效,可以研究的范围更广,不再局限于少数几个词或构式的对比研究。
本研究拟基于上述语义向量的研究方法,利用腾讯人工智能实验室开发的向量数据库(https://ai.tencent.com/ailab/nlp/en/embedding.html),对比汉语中“看”类结构的内部区别与联系。腾讯的向量数据库基于最新的汉语使用实例训练而成,既包含词汇,又包含短语,每一个表达有一个200维度的向量,保留至小数点后第6位。本文以“看到”和“看起来”为例,在腾讯的向量数据库中会提取到以下信息(1)为节省空间,文中仅列出每个词向量的前10个维度。:
看到 -0.227 376 0.265 075 -0.010 188 0.057 698 0.057 491 -0.105 616 -0.021 323 -0.195 779
-0.301 350 -0.101 818……
看起来 -0.191 275 0.169 436 0.315 327 0.046 116 -0.087 502 0.188 463 -0.048 364 -0.153 132
-0.120 526 0.335 885……
但是,数值型向量本身不具有可解释性。因此,在获取向量后,还需要运用降维技术对数值进行计算处理。本文运用多维尺度分析(multidimensional scaling,MDS)和t-SNE(t-distributed stochastic neighbour embedding)两种降维算法将200维的数据投射至两维的平面上,将数值型向量转换成距离进行语义对比分析。MDS算法需要先将语义向量转换成相异性矩阵(dissimilarity matrix),再将相异性矩阵可视化。这一算法的优点是可以较为准确地获取词与词之间的距离,以此来判断它们在语义上的相似性。t-SNE算法擅长抓取数据中的类别,能将数据聚类到二维平面上,但是点与点之间的相对距离不具有可分析性。两种降维方法各有利弊,后文将结合使用,以便综合分析。
(二)研究对象
本研究中对于“看”类结构的范围是基于腾讯的语义向量来决定的,主要考虑以下因素:(1)从结构形式上,只考虑一至四字结构;(2)从频率上,只考虑在CCL语料库中频率较高的用法,排除少数不常用的结构,如“看懵”;(3)从语义上,排除自身语义不能自足的结构,如“我看他”,但是保留了表责备的“你看你”;(4)排除“看”在名词中的用法,如“看法、看客”。基于以上标准,在腾讯数据库中检索包含动词“看”的所有向量,排除以上情况后,共得到169个由“看”和其他成分组成的结构。这些表达主要包括单音节动词“看”、双音节动词“看到、看见、看来”、双音节结构“我看”、三音节结构“我看到、看上去、看起来”、四音节结构“由此看来、我们看到、可以看到”。在得到所有包含“看”的词汇和短语后,在R语言中对上述169个表达进行数据分析,并运用ggplot()函数对语义向量进行可视化。
三、研究发现
通过对上述“看”类词汇短语进行降维处理,我们发现运用MDS和t-SNE的组合可以发现一些和以往研究相关的规律,且两者规律存在差别。
如图1所示,运用MDS对腾讯数据库中“看”类结构进行可视化后,发现横轴尺度较大,纵轴尺度较小。dim1主要体现了“看”是否带有修饰语,体现了“看”类结构的固化程度。整体而言,没有过多修饰语的“看”类结构位于左侧,有时间、方式、结果等修饰语的“看”类结构位于右侧。在图1的最左侧,较多的是字典收录的词条,如“看、观看、看见、查看、看到、看待”。即使是未被收录的四字短语,如“在我看来、可以看到、能够看到、不难看出”,也都是较为常用且固化的话语标记。随着横轴向右,修饰成分与“看”的关系越来越松散。一是出现了“看+补语”的结构,如“看涨、看跌”,表示言者预见到了某种变化趋势。二是更容易出现主谓结构,如“我看见、记者看到、小编看到、外人看来、人们看到”,这些是常见的“主语+感知动词”表言据的结构。三是有时间、方式、程度修饰语“看”类结构,如“目前看来、如今看来、表面看来、总的看来、很难看到、回头看看、短期来看”,越往右结构越松散,在语料库中对应的频率也就越低。最靠右的是“笑看、看够、速看、看腻”等用法,这些结构在汉语中不是一个独立的词或短语,与“看”共现部分的语义较为凸显,在合成新表达时影响了整个词的语义。
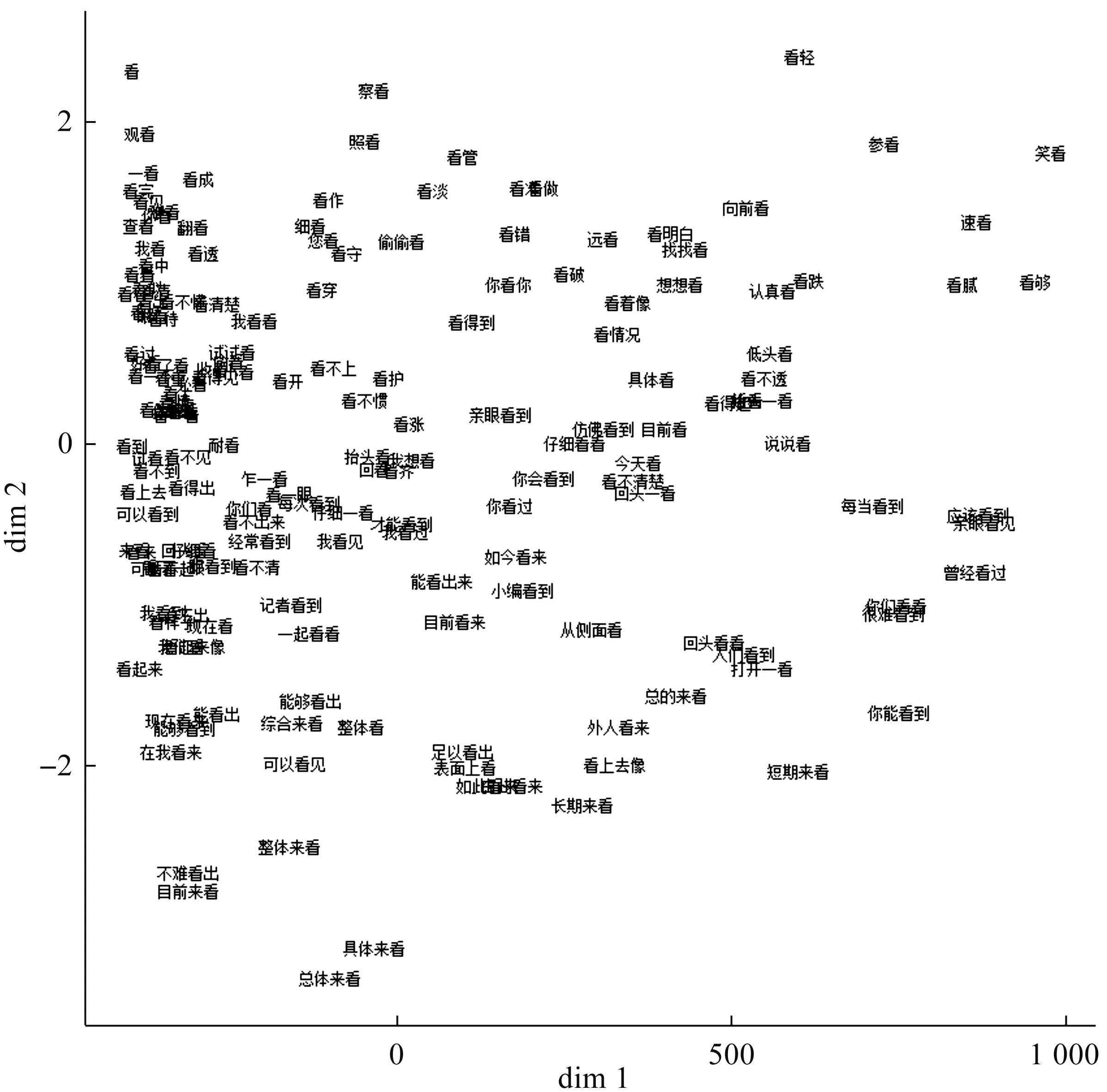
图1 “看”类结构的语义向量MDS图
因此,“看”类结构修饰语和固化程度会影响其语义。无修饰语的词,或是常见动补结构的词,固化程度更高,语义更加相似。有修饰语且固化程度低的词,其语义容易受到修饰语的影响,语义差别更大。
dim2非常明显地反映了汉语中“看”类结构的字数/音节数影响其语义。单音节“看”位于左上方,双音节结构大部分位于上半部分,三音节结构位于横轴附近,四音节结构基本上位于图1下半部分。结合曹秀玲等的研究可以发现,单音节或双音节结构多为动词,绝大多数情况下位于句中充当述谓。随着结构变长,其用法也随之改变,从句内走到句外,成为小句标记或话语标记。“看”和“观看”位于图1左上角,如例1、例2均符合字典释义中的“用眼睛观察”,为典型的视觉感知义。
例1:有时有200多人聚在一起观看这台9英寸的黑白电视。(2)本文所有例句均来自CCL语料库。
例2:他最喜欢看日出,每天早上天一亮就爬起来,叫我陪他看太阳。
相比之下,四字短语多为话语标记,其语义更加抽象,主要集中在图1的下半部分。例3中的“具体来看”是一个话语标记,在上下文中具有承接作用。“具体来看”之前的部分是对于整体的概括,之后的部分则添加了更多细节,如“18枚金牌,亚洲占了11枚”“其中中国5枚、日本3枚、韩国2枚、乌兹别克斯坦1枚”。这些数据为言者表达自身观点提供了很可靠的论据。
例3:带领中国队参加了慕尼黑世锦赛的宋兆年告诉记者,本届大运会柔道比赛称得上世界水平,有10个在慕尼黑世锦赛获得奖牌的运动员前来参赛,其中包括4名世界冠军。“具体来看,亚洲柔道还是占有一定的优势。”宋兆年扳指数来:包括团体赛在内,本届大运会柔道比赛共产生了18枚金牌,亚洲占了11枚;其中中国5枚、日本3枚、韩国2枚、乌兹别克斯坦1枚,优势明显。
根据它们的相对位置,也可以找到一些特例。它们没有与同长度的其他表达聚在一类,这说明其用法出现了变化。其中,“看到”的位置偏下,说明“看到”不仅可以表达视觉感知,还可表达视觉言据或认知、心理活动,其用法出现了从物理层面到认知层面的引申。具体用法如例4、例5:
例4:我常看到他一榻横陈,喷云吐雾。
例5:从这里边,我们可以看到在布达佩斯学派中,为什么对上层精英给予非常的重视,并使用自上而下的视角。
例4中“看到”用于表示言者在视觉上观察到的内容,但是例5中“看到”的语义已经由视觉感知变成了更为抽象的观察,这种观察更多的是经过思考、推断、逻辑推理而得出的。
“看来”和“看样”的位置位于横轴之下。《现代汉语词典(第7版)》中收录了“看来”词条,其释义为“到根据经验或已知情况做出大概的推断”。从例6的具体举例“不图赚钱,治病救人”可以分析出胡庆余的做法“坚持了胡雪岩先生的传统”。这说明“看来”的语义相比其他双音节词更为抽象,不再像“看见”和“看看”等词一样表达视觉感知。
例6:这位一代巨商,给这家药店定的调子是“不图赚钱,治病救人”。看来今天的胡庆余还是坚持了胡雪岩先生的传统的。
腾讯的语义向量与t-SNE算法结合后,较为清晰地展示了汉语中三字、四字结构的演变词源,具有相同词源或类似语义的词语聚在了一起。虽然这些表达在图2中会有重叠,影响读图但是重叠越明显,就说明他们的语义相似度越高。
图2对于现代汉语“看”的分类较为清晰,合理恰当地反映了在使用这一结构时的几种不同场景,说明“看”的短语用法受到了其词干的影响,其中“看到、看出、看来、一看、来看”的聚类较为明显,说明这些词的能产性很高。横轴左侧有一个与“看到”有关的聚类,左上象限有一个与“看完、看过”相关的聚类,右上象限有一个与“一看”相关的小类,体现了汉语中的“看”与完成体相结合的表达。(-20,-20)位置有一个“看+补语”的组合,如“看清、看破、看透、看穿、看准、看中”。右下象限有一个可以表达认识情态和言据的聚类,包括“看起来、看上去、看起来像、看着像”。右下象限有一个以“看来”为核心的聚类。
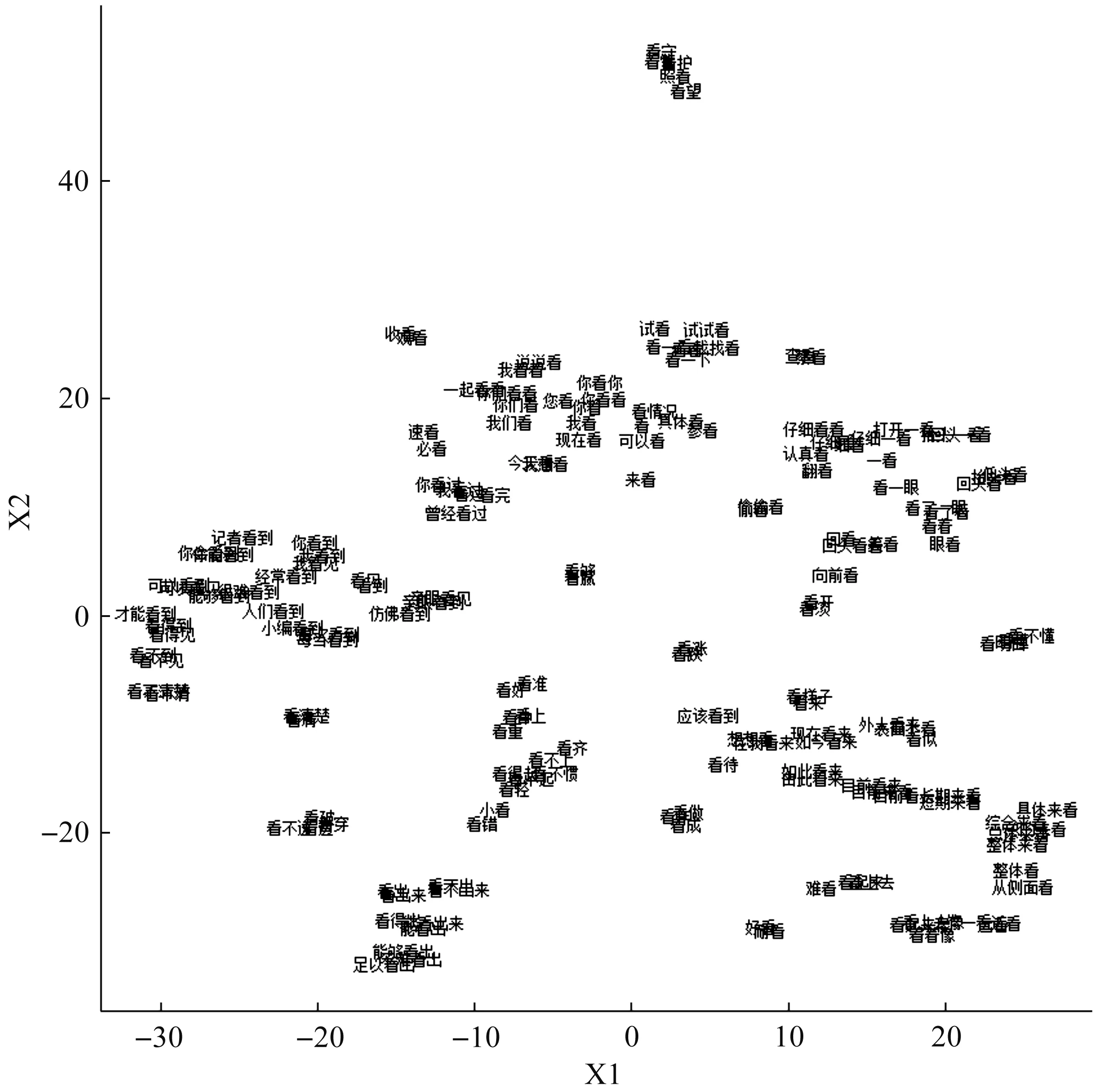
图2 “看”类结构的语义向量t-SNE图
以“看出”为例,图2左下角形成了一个与“看出”相关的聚类,其成员包括“看出、看出来、看不出、看不出来、看得出、能看出、能够看出、不难看出、足以看出”。其中“看出”和“看出来”高度重叠,“看不出”和“看不出来”高度重叠,“能够看出”和“不难看出”中的“能够”和“不难”均可表示言者对命题的确信程度,可以判断它们为语义功能基本相似的不同变体。
此外,还能看到一些单独成对的“看”类近义词或反义词:“看涨”和“看跌”,“好看”和“耐看”,“看够”和“看腻”,“看破、看穿、看透”和“看不透”,“看懂、看明白”和“看不懂”,“收看”和“观看”,“看清”和“看清楚”,“看作、看做”和“看成”,“看起来”和“看上去”等。不管它们是近义词还是反义词,他们的语义向量相似度高,都能说明他们的使用语境基本一致,在很多语境中可以用于替换或否定,却不影响整句的通顺和接受度。例如,“看起来”和“看上去”的用法在绝大多数情况下均可互换:
例7:我看起来/看上去很外向,事实不然,我害羞而且不喜欢客套,……
例8:闺女呀,看起来/看上去人家早就下手了。
例9:看起来/看上去,事体永远弄不清楚了。
例7和例8中的“看起来”和“看上去”可以互换,说明其功能高度相似。例7位于句中,表达基于视觉感知的评价;例8位于句首,表达基于言者整体观察的推理;例9的“看起来/看上去”与主句用逗号隔开,表达言者基于自身思考对抽象事物的推理。由此可见,“看起来”和“看上去”在语义和句法位置上呈现出高相似度,这是他们在图2中呈现聚类的原因。
图1、图2的结果在一定程度上印证了前人的研究发现。同时,语义向量的定量研究可以发现一些前人研究尚未关注的整体规律。多维尺度分析发现,“看”类结构在有无修饰语时差别明显,固化短语和非固化短语之间有明显差异,四字结构与其他结构具有明显的差别。经过t-SNE聚类,“看”的结构出现了以词干为核心的聚类,说明四字结构的语义容易受同源二字词的影响。因此,“看”类的内部语义差异主要由上述因素造成。
综上所述,语义向量能够在一定程度上反映“看”类结构的用法。“看”是汉语中最高频的动词之一,具有多义性和多功能性,本身是一个较为复杂的语言现象。运用腾讯人工智能实验室的语义向量和MDS、t-SNE等降维方法,对不同“看”类结构的异同进行了可视化和定性分析,发现“看”类结构的内部语义差异主要体现在固化程度、结构长度、词干类型三个方面。同时,这一方法结合自然语言处理和统计可视化的成果,为汉语词汇短语研究带来了新思路。
