混沌时间序列的核自适应滤波预测算法
2023-03-07王世元黄雪微王代丽
刘 强, 王世元, 黄雪微, 王代丽
(西南大学 电子信息工程学院,重庆 400715)
混沌现象[1]是由不附加随机因素的确定性非线性动力学系统产生而来。实际应用中,混沌信号往往受到不同程度的噪声干扰,经典的去噪预测方法主要有3类:局部预测法[2]、全局预测法[3]、自适应预测法[4]。其中,局部预测法利用局部数据特征拟合非线性函数,提高了处理速度;全局预测法利用全部数据的特征来表征非线性函数,对整个混沌信号的噪声实现有效抑制;自适应预测法自适应地追踪混沌的运动轨迹,通过简单配置参数确保了低数据量时仍然有较好预测精度。良好的去噪性能以及简单的参数配置使自适应预测法得到广泛应用。
在自适应滤波预测中,数据空间中的二阶相似性度量是高斯噪声环境下性能优越的测量方法,如基于均方误差(mean square error,MSE)[5]的仿射投影[6]和最小二乘法[7]。但是采用二阶度量的自适应预测方法在脉冲噪声中的去噪性能显著下降。为解决这些问题,非二阶相似度量方法被提出,如平均p阶误差(meanp-power error, MPE)准则[8],但一般情况下使用MPE准则仍不能在脉冲条件下提供理想的滤波性能。近几年,基于可再生核希尔伯特空间[5]的非线性度量方法成为研究热点。作为信息理论[9]的代表,相关熵损失(correntropic loss, C-loss)[10]和广义相关熵损失(generalized correntropic loss, GC-loss)[11-12]利用数据的高阶统计量,成功地衍生出一些在脉冲噪声情况下鲁棒的自适应滤波预测方法[4]。然而,熵损失性能曲面的非凸性导致其收敛性能较差。为提高熵损失性能,核风险敏感损失(kernel risk sensitive loss, KRS-loss)[13]因具有更好的性能曲面而被提出,然而KRS-loss在脉冲噪声中并不具鲁棒性。进一步,广义对数损失(generalized logarithmic loss, GL-loss)[14]被提出,用来抑制较大异常值的干扰。值得注意的是,在一些环境下,GL-loss比C-loss和KRS-loss具有更好的性能。
然而,采用上述度量的线性滤波器在复杂非线性混沌时间序列预测中都存在预测性能下降的问题。核方法[5]能够有效地解决非线性问题,如极限学习机[15]和核自适应滤波器(kernel adaptive filter, KAF)[5]。核方法的核心在于将原始空间中的内积操作转换到高维空间中,使用“核技巧”替换内积操作,从而降低计算复杂度。典型的核自适应算法包括核最小均方(kernel least mean squares, KLMS)算法[16-17]和核递归最小二乘(kernel recursive least squares, KRLS)算法[18]等。KRLS算法考虑先前的多个误差,与基于随机梯度下降的KLMS算法相比,该算法具有更快的收敛速度和更高的滤波精度。
值得注意的是,在KAF算法中随着输入的不断增加,算法网络尺寸会随之线性增长,最终导致巨大的计算和存储开销。为抑制网络尺寸的增长,一些数据稀疏处理方法被提出来,比如稀疏化[5]和量化策略[17]。但是,使用这些稀疏处理方法仍然存在网络尺寸次线性增长问题。相比之下,采用自适应K-Means采样[19]的Nyström映射[20]通过提前固定网络尺寸,在时间和空间复杂度上都表现出了更大优势。
近年来,脉冲噪声下的鲁棒性滤波算法日益成为一重要研究领域。本文提出一种新的广义对数核损失(generalized logarithmic kernel loss, GLKL),目的在于提高GL-loss在某些非线性系统中的性能。为解决核方法带来的网络尺寸线性增长问题,将GLKL与K-Means采样的Nyström映射和递归更新方式相结合,推导出一种新的鲁棒算法,即NRMGLKL-KM算法。该算法与稀疏化核自适应滤波算法相比具备更高的鲁棒性,与其他典型鲁棒核自适应滤波预测算法相比,该算法具备更快的收敛速度和更高的滤波精度。
1 背景
1.1 广义对数核损失的定义
为构建鲁棒性预测方法,GL-loss[14]作为两个随机变量X和Y的相似性度量被定义为
(1)
式中:α>0,p>0。式(1)在处理异常值时具有较强的鲁棒性,已经广泛应用于鲁棒性算法研究。然而,在处理复杂的非线性系统问题时,基于式(1)的线性滤波算法不具备较强的非线性滤波性能。
利用核方法,GLKL函数通过提取数据的不同阶统计量,有效提升了在脉冲噪声下非线性问题的学习性能,GLKL定义如下:
dFX,Y(X,Y)。
(2)
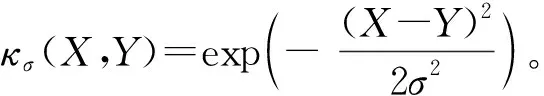
(3)
经验GLKL可以被描述为x=[x1,x2,…,xN]T和y=[y1,y2,…,yN]T之间的广义“距离”。
1.2 相关性质
关于GLKL的一些重要性质如下所示。
性质1:Lp(X,Y)是对称、正定且有界的。
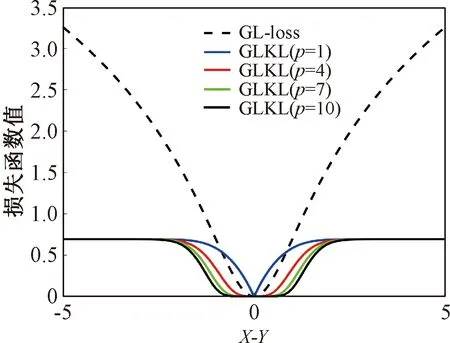
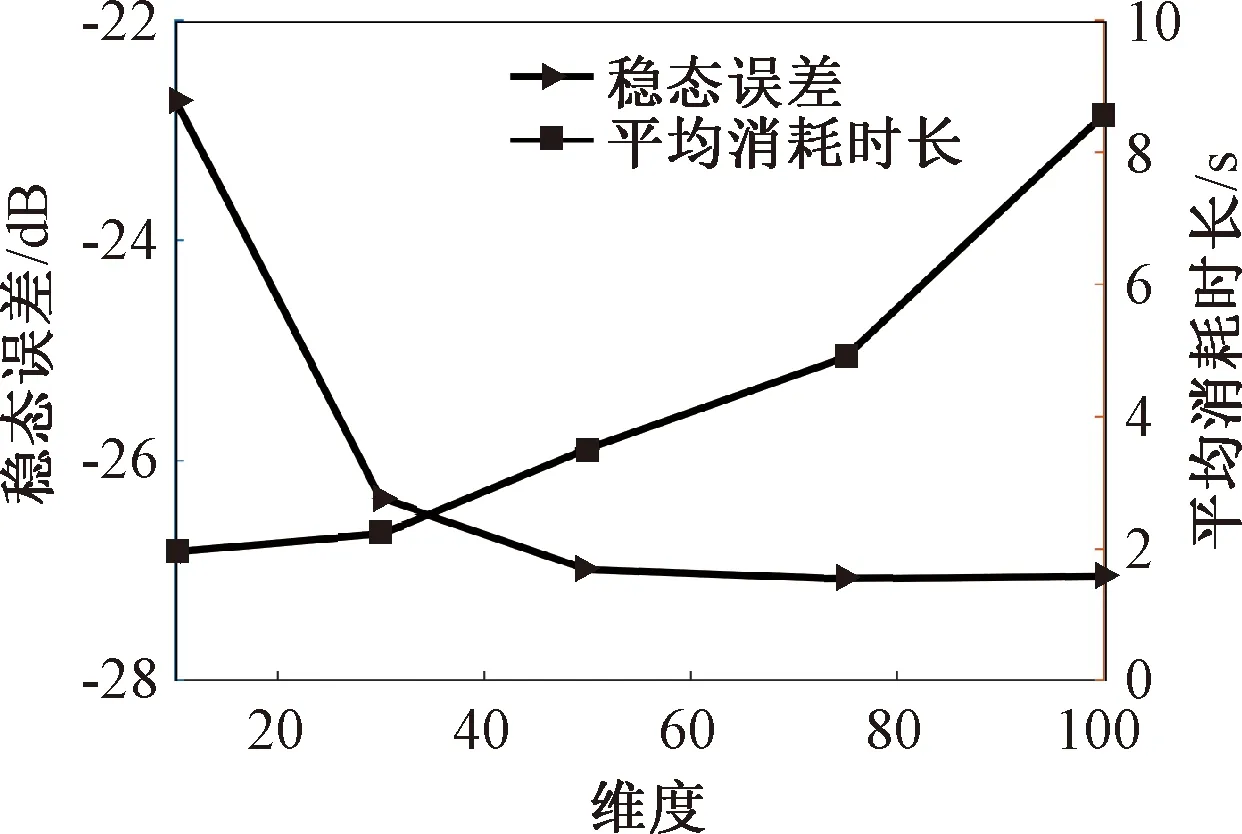
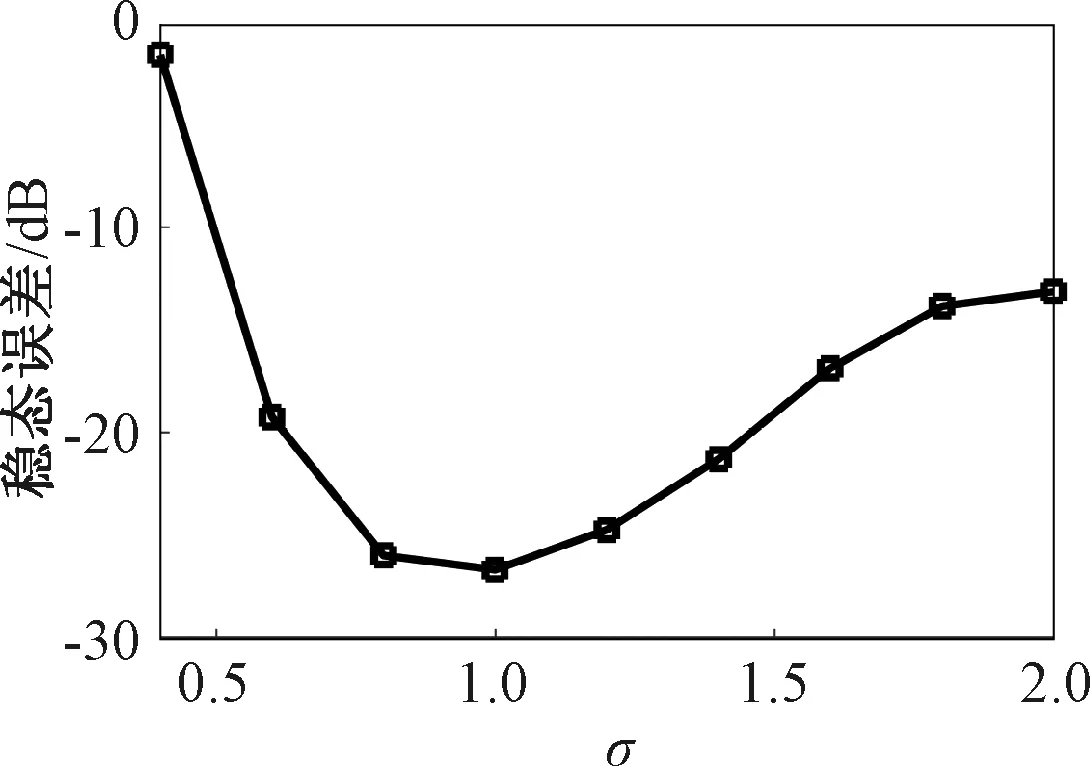
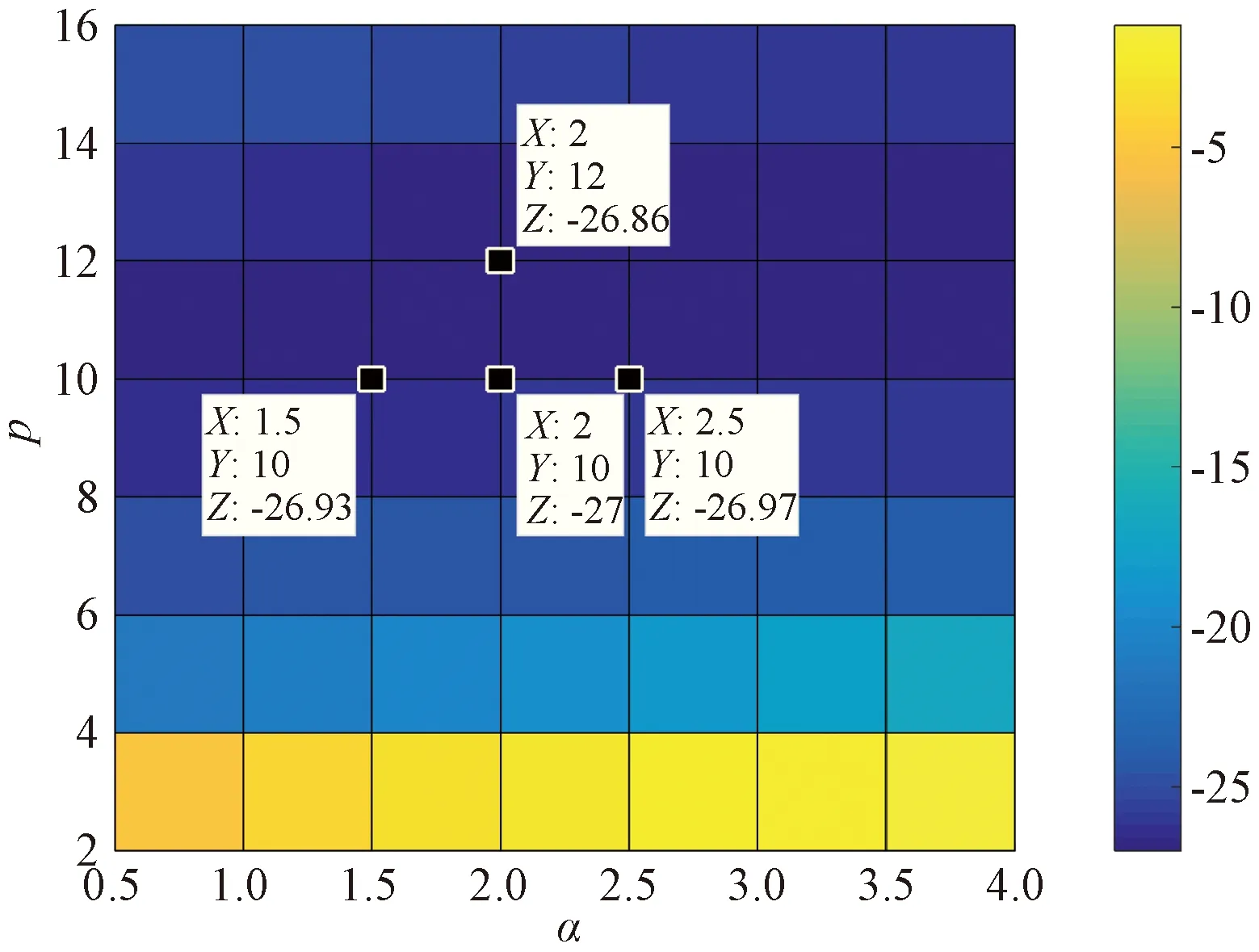
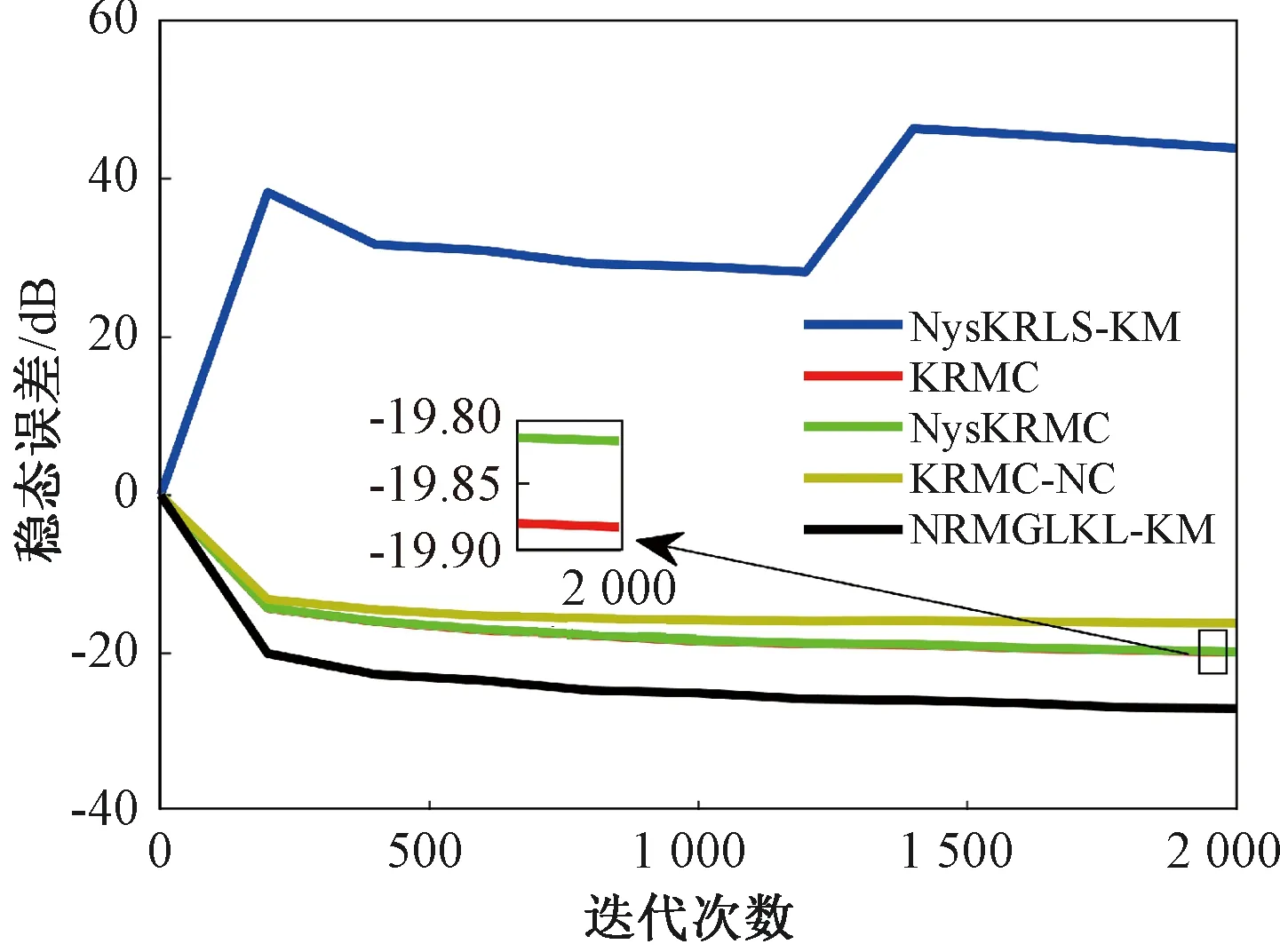
证明:由于κσ(X,Y)=κσ(Y,X),故有Lp(X,Y)=Lp(Y,X),即Lp(X,Y)是对称的。当0<κσ(X,Y)≤1,Lp(X,Y)是正定且有界的,即0 性质2:当σ足够大时,有 Lp(X,Y)≈(2σ2)-p/2E[|X-Y|p]。 (4) ≈(2σ2)-p/2E[|X-Y|p]。 (5) 由性质2可知,GLKL可以捕获误差的p阶绝对值。当σ=1时,GLKL可以视为MPE准则。 (6) 设置σ和α的值均为1,图1比较了在不同参数p下,GL-loss和GLKL的损失函数随误差变化的情况。从图1可以得出:①当误差趋近于0时,p越大,GLKL曲线就越平滑,即GLKL对稳态误差有更好的平滑性;②与GL-loss相比,在误差较大的情况下,GLKL的损失函数更平滑,即GLKL对大的异常值不敏感。 图1 GL-loss与不同的p下GLKL的比较Figure 1 Comparison of GL-loss and GLKL with different p (7) 式中:V=[λ1,λ2,…,λm]和D=diag[ζ1,ζ2,…,ζm]分别为矩阵W特征向量及其对应的特征值所组成的矩阵。故G中的元素可以近似表示为 =z(ui)Tz(uj)。 (8) 式中:z(ui)为ui映射到高维特征空间的近似函数。从式(8)中可以看出,φ(u)作为一个无限维的隐式输入,实际上可以用低维输入z(u)来近似表示。 Nyström映射中,核矩阵近似的精度主要取决于样本点的选择。K-Means方法作为一种经典的聚类方法,能够抽取与原始数据的分布基本一致的数据,有效地提高Nyström近似精度。K-Means采样是将给定的样本集分成k个簇,并将每个簇的质心作为样本。 步骤2 将每个数据分类到距离最近的一个簇中,即 (9) 步骤4 重复步骤2和步骤3,直到满足收敛条件。 一般地,当前质心与上一次更新所获得质心之间的欧氏距离小于0.001时,终止聚类过程。由于本文研究重点为在线学习,故此采样过程只会发生在初始化阶段。基于采样所获得的样本,本文提出以下鲁棒K-Means采样的Nyström递归最小广义对数核损失算法,即NRMGLKL-KM。 为使输入数据自相关矩阵可逆,引入一个范数惩罚项,广义对数核损失如下: (10) (11) 定义: (12) 令式(11)等于0,得 (13) 基于指数衰减的数据窗口,Ri和Ψi的在线更新形式写为 (14) 进一步,根据矩阵求逆引理,利用递归形式来计算式(13)中的Pi,即 (15) 将式(15)代入式(13),权重更新可表示为 (16) 本实验通过Mackey-Glass(MG)混沌时间序列预测来验证算法的预测能力。混沌时间序列的频谱分布状态十分丰富且能反映混沌系统中信号的激励特征,由以下非线性延迟微分方程获得: (17) 式中:a=0.2,b=0.1,τ=30。为实现数据离散化,采样周期设为6 s。式(17)中,时延参数τ越大,系统混沌程度越明显。从混沌系统中提取序列[xi-7,xi-6,…,xi-1]T用于估计期望输出di=xi。结合实际问题,混沌序列中需引入噪声干扰。 脉冲噪声环境由两个独立的噪声混合产生,表示为 vi=(1-bi)vx,i+bivy,i。 (18) 讨论样本数m对NRMGLKL-KM算法的性能影响,其中m的取值为[10,100]。图2展示了不同维度m对应的NRMGLKL-KM算法的稳态误差和平均消耗时间,其中稳态误差取最后100次迭代的mse均值,其他自由参数设置为γ=0.1、β=1、α=1、σ=1、p=10。从图2中可以看出:①NRMGLKL-KM算法的平均消耗时间随着m增大而增加;②在初始阶段随着m的增加,稳态误差下降比较明显,当m>50时,稳态误差的值几乎无变化。因此,为了平衡滤波精度和时间消耗,在本例中m的取值为50。 图2 在不同维度下NRMGLKL-KM算法的稳态误差和平均消耗时长Figure 2 Steady-state error and averaged consumed time of the NRMGLKL-KM with different dimension 讨论核宽σ对NRMGLKL-KM算法的滤波精度的影响。σ在区间[0.4,2.0]以0.2为间距取值,其他自由参数分别设置为m=50、p=10、α=1.5、γ=0.1、β=1。不同σ值对应的NRMGLKL-KM算法的稳态误差如图3所示,从图3中可以发现,当σ=1.0时获得最佳滤波精度,在σ过大或者过小时均会导致滤波精度下降。 图3 参数σ对NRMGLKL-KM性能的影响Figure 3 Influence of parameter σ on the performance of NRMGLKL-KM 讨论参数p和α对NRMGLKL-KM算法性能的影响,其中p在区间[2,16]以2为间距取值,α在区间[0.5,4.0]以0.5为间距取值。不同p和α对应NRMGLKL-KM算法的稳态误差如图4所示,其他自由参数为m=50、σ=1、γ=0.1、β=1。从图4中可以发现,随着参数p的增大,稳态误差先下降后升高,并且在p=10的附近达到最优;α在一定程度上对所提算法的影响较低。因此,为了达到理想的性能,在本例中将NRMGLKL-KM算法的参数设置为m=50、σ=1、α=2、p=10、γ=0.1、β=1。 图4 NRMGLKL-KM稳态误差随p和α的变化Figure 4 Steady-state error of NRMGLKL-KM versus p and α 为验证NRMGLKL-KM算法在鲁棒性和收敛性方面的优势,将NRMGLKL-KM算法与一些典型递归算法进行比较,如:NysKRLS-KM[18],KRMC[21],NysKRMC[20],KRMC-NC[21]。为达到理想的精度,对所有算法均设置了最优参数,其中各算法中γ,β以及m的取值均为γ=0.1,β=1,m=50。仿真结果如图5所示,所有算法的仿真结果数据和计算复杂度列于表1。从图5可以看出,与其他典型算法相比,所提算法在脉冲噪声中具有较高的鲁棒性,同时还具备更快的收敛速度和更高的滤波精度。表1中i为当前迭代次数,n为KRMC-NC在当前迭代中的字典大小。因为i和n的值最终会远大于m,所以相比于KRMC和KRMC-NC算法,所提算法具有更小的计算复杂度。同时从表1中可以发现,所提算法能够在更短的时间内达到比KRMC算法更高的滤波精度。 图5 MG时间序列下不同算法的稳态误差比较Figure 5 Comparison of the steady-state error of different algorithms in MG time series prediction 表1 MG时间序列下不同算法的仿真结果及计算复杂度Table 1 Simulation results and computational complexity of different algorithms in MG time series prediction 本文将原始空间中的广义对数损失映射到再生核希尔伯特空间,提出了广义对数核损失准则(GLKL),并给出了该准则的若干性质。GLKL准则在混沌时间序列预测中能有效地消除脉冲干扰。同时,在提出的GLKL准则中引入了K-Means采样的Nyström映射,从而推导出一种新的基于K-Means采样的Nyström递归最小GLKL预测方法,即NRMGLKL-KM算法。通过实验仿真确定自由参数对算法性能的影响,选择最优参数以提高滤波精度。除此之外,在脉冲噪声环境下进行混沌时间序列预测仿真。仿真结果表明:与稀疏化核自适应滤波算法相比,所提算法在脉冲噪声中具备更高的鲁棒性,同时,相比于他典型鲁棒核自适应滤波预测算法相比,该算法具备更快的收敛速度和更高的滤波精度。
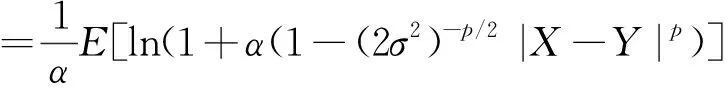
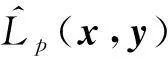
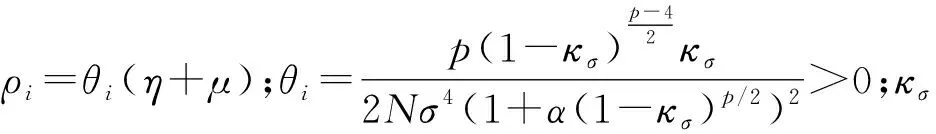
2 算法推导
2.1 Nyström映射
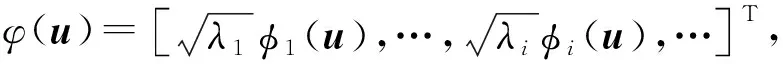
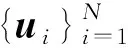
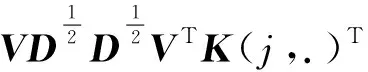
2.2 基于K-Means采样的Nyström映射
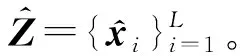
2.3 基于K-Means采样的Nyström递归最小广义对数核损失算法
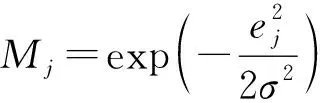
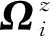
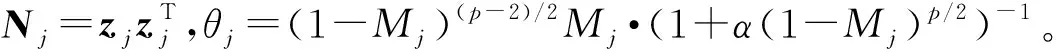
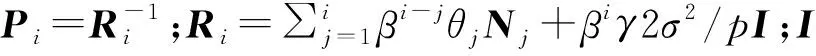
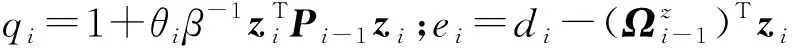
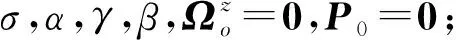
3 仿真
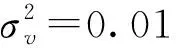
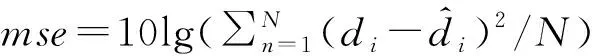

4 结论
