基于FPGA卷积神经网络的人脸识别系统
2023-03-06吴雯丽陈治铭莫梓健赵元睿
吴雯丽,陈治铭,莫梓健,赵元睿,齐 轩
(天津工业大学 电子与信息工程学院,天津 300387)
0 引 言
随着人工智能的发展,基于边缘计算的快速实时人脸识别成为重点研究方向,应用包括国家安全、反恐、社区管理、考生身份验证等。边缘计算是一种让外围终端进行数据处理运算的技术,可以不在云端指挥下实现独立工作,具有低延迟、高可用、高实时等优势,因此卷积神经网络越来越多被应用于边缘计算环境,而FPGA也由于其高效率、低功耗等特性逐渐成为边缘计算的理想平台。在人脸识别的实现基础上,研究人员也在寻求不同的算法以求硬件计算的更高速度,因此本文对人脸识别算法和与其对应的卷积运算加速电路进行设计,具有极高的日常使用和研究价值。
1 介 绍
1.1 卷积神经网络原理与结构
卷积神经网络是一个多层前馈神经网络,其设计参考了视觉神经机制感受野的原理,一个神经元可以响应一部分覆盖范围内的周围单元[1]。一个卷积神经网络可以有数十层乃至数百层,每层的输出神经元都是下一层的输入,各层学习检测图像的不同特征,可以从非常简单的特征开始,然后越来越复杂,直到可以唯一定义目标的特征为止。
在卷积神经网络中,卷积和池化这两种不同类型的层通常在前端交替出现,最后由一个或多个全连接层组成。卷积核初始时被赋予随机数,在网络训练过程的不断修正中,卷积核将学习得到合理的权重,用来提取图片特征。卷积层后通常进行一次激活操作引入非线性因素,本次网络中使用ReLU激活函数,这种激活函数计算简单并且高效,在随机梯度下降的过程中可以明显加快收敛速度,比maxout函数收敛快6倍。激活函数后连接池化层,池化又分为均值池化和最大值池化两种形式,也被称为子采样,主要作用是对特征降维。卷积与池化大大简化了模型的复杂程度,减少了模型的参数数量。最后,各特征参数被送入全连接层,在这里所有特征聚集到一起,其实现是一种特殊的卷积操作,在整个网络中起到分类器的作用,以辨别特征归属与类型。
1.2 研究背景及意义
2017年,梁云等人在Xilinx ZC706平台上采用Winograd实现了ResNet的130.4 GOP/s,使用FFT实现了YOLO的201.1 GOP/s,通过减少卷积所需的乘法次数来提高有效的DSP效率,提出了在FPGA上进一步加快运算速度的卷积神经网络快速算法[2]。2018年,施杰乔等人详细介绍了硬件实现CNN体系的基本结构,在DE2-115开发板上实现了面部识别的CNN体系,识别率达93%[3];李硕在Zynq-7000芯片上实现了张量神经网络的人脸识别,虽然损失了识别率,但减少了参数数量,最终达到每张图片32 ms的识别时间,识别率为95%[4]。2021年,王咏星等人介绍了“FPGA+ARM”架构的数字图像处理系统设计,提出了实时性高的图像采集和处理实现方法[5]。由上述研究成果可以了解到,深度学习理论和卷积运算加速器在硬件加速方面较为火热,并且近年有关FPGA图像识别的关键词出现频率较高[6],有进一步提高卷积运算加速和硬件加速的必要。
2 CNN体系结构
CNN离线训练,FPGA主要用于加速推理阶段[2]。故该体系结构在Python上采用TensorFlow搭建。CNN应有优越的识别能力和适合硬件的结构[7],如图1所示,此结构共包含3个卷积层、3个池化层、1个全连接层和1个输出层。
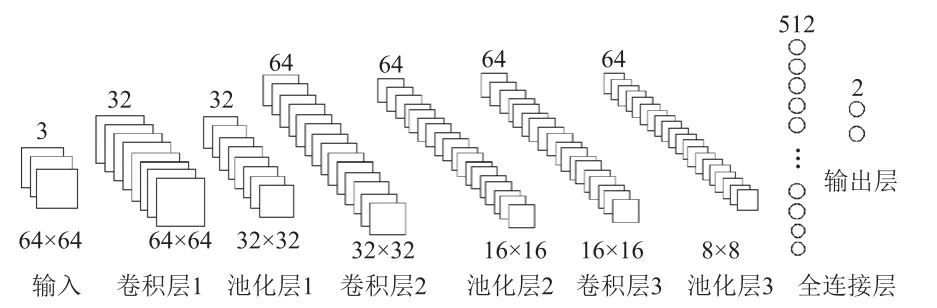
图1 CNN体系图
在CNN所有层中,卷积层占运算资源的90%以上,属于主要计算部分。卷积层的主要作用是对图片的每一个特征进行局部感知并提取抽象特征。采用滑窗操作可以保证局部旋转不变性和唯一不变性,有效提取人脸轮廓信息,经过机器学习的多次训练具有很强的分析能力[8]。具体操作如下:
池化层模仿人的视觉系统对数据进行降维,是对二维数据样本降采样的操作[9],具有特征不变性,不关心特征的具体位置而关心特征是否存在,相当于去掉了小部分不重要特征,同时2×2的池化可以减少1/4参数数量,对防止过拟合起到一定作用。常见的池化操作有最大池化和平均池化两种类型,实践证明,最大池化对提取特征纹理的效果更加突出,因此文中采用了步长为2的最大池化,用公式表示为:
式中:p(i,j)in表示输入特征图的第i行第j列数据;pout表示池化结果。
再由全连接层对特征整合,全连接过程可通过卷积实现,具体过程是以同特征图大小相同的卷积核对特征图进行卷积运算。最后,两通道数据依次与权重相乘相加可在输出层得到结果。
根据以上结构,设计得到CNN的硬件结构如图2所示。该结构经流水线设计串联,由3个卷积模块、3个池化模块,1个全连接模块,1个输出模块和许多存储器组成。
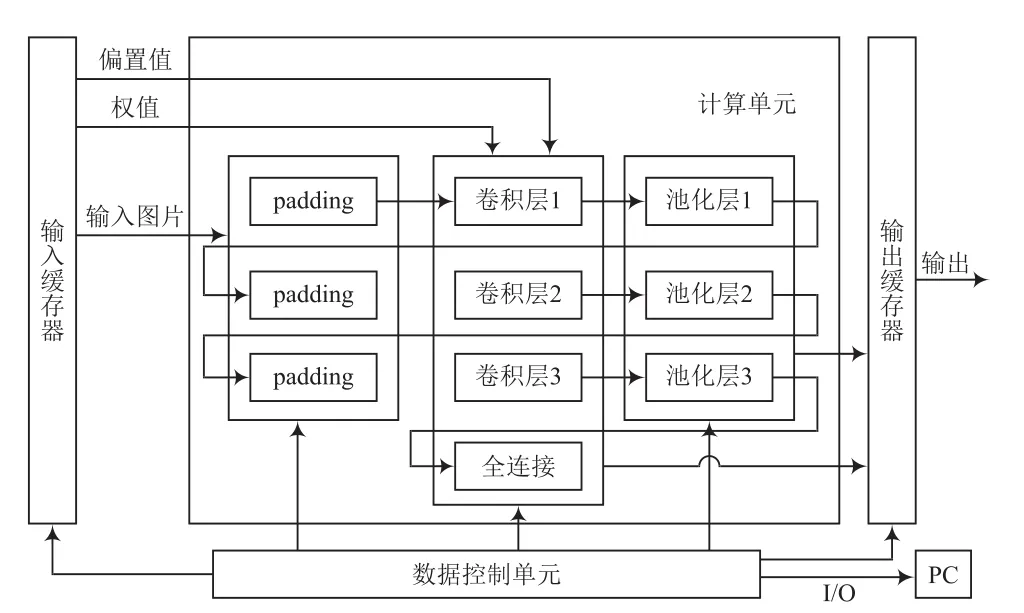
图2 CNN硬件结构
2.1 padding操作
通常进行卷积操作时,会导致特征图缩小(n-1)行(n-1)列数据,n为卷积核大小。如卷积核为3×3时,特征图会缩小2行2列。为保证卷积操作前后特征图尺寸一致,需在卷积之前采用padding操作为特征图在外围补0,效果如图3所示。硬件上该模块的输入包含时钟、复位和输入数据,输出包含RAM读写标志位和输出数据,通过状态机实现,将输入数据分为第一行,中间行和最后行3个状态,第一行和最后一行全部补位0,中间行在数据前后各添一位0。

图3 padding效果图
2.2 卷积模块硬件结构和池化模块硬件结构
本文借鉴LineBuffer结构[10]完成实现模块。滑窗部分采用移位寄存器实现,卷积中采用3个抽头,池化则用2个抽头。
对于卷积的硬件实现,选择合理的计算顺序非常重要。本文采用多张特征图同时与第n组卷积核卷积,所有特征图卷积完成后更换下一组卷积核的计算顺序,依次类推,最终相加即可得到卷积结果,比一张特征图先与多个卷积核卷积,再更换特征图的方式更简便、更快捷。其中,一张特征图的卷积模块如图4所示。特征图数据经过流动进入移位寄存器,每次时钟上升沿到来,滑窗内的9个特征图数据就更新一次,更新数据传入乘法器与内存中所存权值相乘,最后在加法器中依次相加再加上偏置数据得到卷积结果,三行数据计算完成后,输入处传入下三行数据继续计算,直到整张图片输入完毕。

图4 卷积结构
池化模块与卷积模块在滑窗部分相似。如图5所示。每两行特征图数据进入滑窗,图中比较器模块中包含3个小比较器,滑窗内数据通过比较得到最大值输出,两行计算完成后输入处传入下两行数据,依次类推得到整张图片结果,以达到最大池化效果。
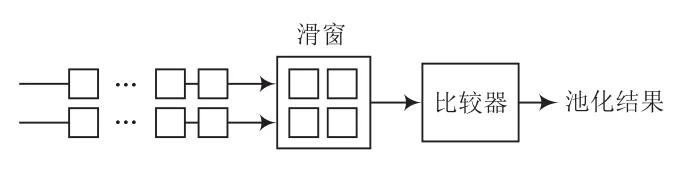
图5 池化结构
2.3 全连接模块硬件结构
全连接层的实现其实是一种特殊的卷积,卷积的操作我们已经非常熟悉,实现难度并不高,但是想要获得较高的运行速度和合理的数据分配,则需要仔细考虑优化问题。深鉴科技文章中提及的SVD方法可以较好减小权重矩阵,且SVD方法作为一种软件算法也可以在前端使用Python或MATLAB等快速实现,可行性高,但是该方法处理后的权重矩阵仍然需要非常大的存储空间。因此在硬件实现中如何安排计算顺序和访存方法很重要。
本文中将全连接层安排如下:全连接层中每个神经元都与前一层相连,仍通过卷积操作得到结果,具体操作如图6所示。用512个8×8×64的卷积核对64张8×8特征图进行卷积,每张特征图与对应卷积核相乘,64张乘积结果对应位置求和,最后加上偏置值就可以得到一个全连接层的输出,这样更换卷积核循环512次,即可得到全连接模块的512个输出。

图6 全连接结构
2.4 输出层硬件结构
输出层中的每个特征节点都有一定的权重,所有特征的权重共同决定输入所属分类的权重或概率。输出层用于计算分类概率,将全连接模块得到的512个数据通过计算得到2个数值,根据数值大小判断是否是本人人脸。操作过程如图7所示,2个含512个数据的权值缓存器与全连接层数据并行依次相乘相加,再加上偏置值,最后得到2个结果,传入比较器中得到最终结果。

图7 输出层结构
3 并行度设计
在神经网络的前向传播过程中,参数数量庞大,操作过程复杂,非常适合用FPGA加速发展。FPGA最大的优点是可以并行处理数据,实现这一点的关键是使用FPGA的BRAM来缓存和处理数据。因此,为了充分发挥FPGA并行流水线处理的优势,算法运用并行流水线式很有必要。设计中采用Altera公司出品的Stratix IV系列EP4SGX230KF40C2芯片,芯片中DSP资源有限,共含有1 288个乘法器,支持2个18 bit的定点乘法,14 283 Kb的片内存储空间。本次设计采用流水线设计,涉及大量卷积计算,每张并行图片需要9个乘法器支持,中间运算结果也较多,故需对各层并行度进行分配,在设计好时序的情况下,本层可以同时对多张特征图采用统一的卷积核运算,结果直接送入加法器中,节省缓存时间。
为保障资源的高利用率,在卷积层1中对3张图片进行并行计算;卷积层2中对32张图片进行并行计算;卷积层3中对64张图片进行并行计算;全连接层对2个通道的8×8图片进行并行计算;输出层同时对两行矩阵依次对应相乘。其中,卷积层和池化层的并行设计如图8所示。
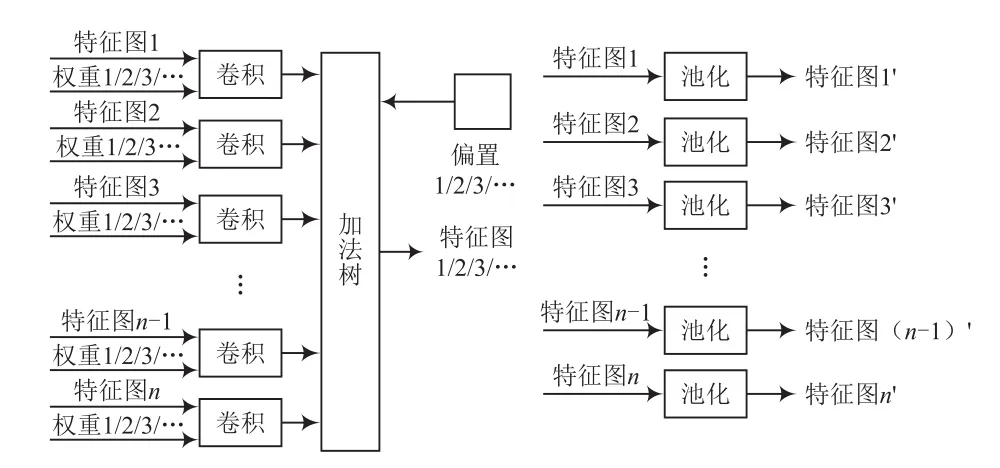
图8 卷积、池化并行结构
其中,“/”表示同时输入权重1和偏置1,可以得到特征图1;同时输入权重2和偏置2,可以得到特征图2,依次类推。需要说明的是,权重1表示的是时刻1输入的一组权重,不同的特征图接收的是组中不同权重。
4 实验结果
本文使用LFW人脸数据库中13 991张人脸图片以及自行采集的真人10 000张照片作为数据集,设计的CNN架构在TensorFlow上训练,将训练后模型的权重和偏置导出并存入RAM中。文献[11]中指出,16 bit定点数据可以满足加速器计算精度的要求,因此本文中模型参数、输入输出数据和中间结果均处理为16 bit定点数参与运算。在Quartus Prime Standard 18.0工具中设计Verilog脚本,在FPGA上实现网络结构,目标器件为Stra1tix IV系列EP4SGX230KF40C2芯片。将需要识别的人脸图片分为3张64×64大小的RGB图像并做归一化处理,存入ROM以作输入。人脸识别平台搭建如图9所示。

图9 人脸识别平台搭建
为说明FPGA对人脸识别功能的实现情况,对其做功能验证。对输入图片采用本文的卷积神经网络结构识别,各操作工作状态如下。
(1)padding
图10、图11中变量hang表示输入数据属于的行数;state_c表示状态机当前状态,1为第一行,2为中间行,4为最后一行;可以看出,随着行数变化,当前状态也在变化,并且输出data_out在第一行和结尾行输出为0。图12中变量hang对应的输出data_out在该行数据前后都添加了0。

图10 padding仿真图(1)

图11 padding仿真图(2)

图12 卷积仿真
(2)卷积层
图12中左侧两框表示移位寄存器采到的卷积核,右侧两框表示该行末尾舍掉的卷积核,舍掉的卷积核不参与运算,从参数data1_row(第一行卷积核的合并数据)、data2_row(第二行卷积核的合并数据)和data3_row(第三行卷积核的合并数据)看出,错误的卷积核没有被送到卷积核参数中,并且输出norm_result正常运行,完成了卷积功能。
(3)池化层
图13中变量out_da1和out_da2表示最后要进行比较的两个数,输出out_data会在下一个时钟将两数中较大的一方输出,完成最大池化操作。

图13 池化层仿真
(4)输出层
图14中,in_data1是输入图片特征的第一条通道数据,in_data2是输入图片特征的第二条通道数据;weight是输出层权重,bia1是通道一的偏置,bia2是通道二的偏置;outflag是输出标志位,由00变为01时表示所有计算已经完成,可以输出最终结果;out_data是最终结果。可以看出,在运算完成后,标志位发生变化的下一个时钟,out_data正确输出了最终结果。

图14 输出层仿真
表1展示了人脸识别系统每层的资源利用情况,可以看出,BRAM和DSP资源主要集中在卷积模块,因为这些地方的数据量和运算量较大,必然会消耗更多存储资源和运算资源[9]。

表1 资源利用表
测试时,先将模型数据和图片数据存入FPGA,将420张测试图片依次输入,完成运算后最终得到正确图像的数量。最后,正确识别图片413张,误识别7张,识别率为98.3%,总计算时间为8.8 s,每张图片的识别时间为21 ms,而PC上每张照片的识别时间为32 ms,可以看出,加速效果较好。
5 结 语
本文提出了一个用于人脸识别的卷积神经网络结构,并将其在FPGA上实现。实现过程中对卷积神经网络的卷积层、池化层、全连接层、输出层使用Verilog HDL语言搭建硬件结构,并且探究设计了各层内的并行性,以提高硬件资源利用率。测试表明,模型准确率达98.3%,证明本文所设计的结构有实用价值。
