基于Transformer 网络和多任务学习的园区综合能源系统电-热短期负荷预测方法
2023-03-06黄旭锐于丰源杨波潘军徐钦
黄旭锐,于丰源,杨波,潘军,徐钦
(广东电网有限责任公司广州供电局, 广州 510013)
0 引言
随着全球化石能源短缺和环境污染问题的日益严重,要实现“碳达峰碳中和”目标,核心是推动能源低碳转型[1]。综合能源系统(integrated energy system, IES)通过多种能源的协调规划和灵活调度,不断推动传统的能源利用模式变革,是助力双碳目标实现的关键技术[2]。IES涉及冷、热、电等多种能源形式的生产、传输、储存、转换和利用,在充分消纳可再生能源提高能源利用率的同时,实现多能源互补协调运行,最终实现环境友好和可持续发展的目标[3]。负荷预测是IES能量管理和优化调度的基础,其预测精度直接关系到系统的整体运行性能[4]。
在现有的负荷预测方法中,多数研究都针对单一负荷类型的独立预测展开。在单一电负荷预测方面,反向传播神经网络、支持向量回归(support vector machine, SVM)、决策树[5]、长短期记忆网络(long short-term memory, LSTM)[6]、极限学习机、广义回归神经网络[7](generalized regression neural network, GRNN)等机器学习的方法被广泛应用。在此基础上,有文献引入注意力机制,通过注意力权重选择性关注关键因素,挖掘负荷数据序列的内部规律和长期依赖关系,有利于提高负荷的预测精度[8-9]。文献[10]和[11]提出基于Attention(注意力)机制的短期负荷预测模型,通过充分利用负荷数据的时序特征,并采用注意力机制突出对负荷预测起到关键作用的输入特征,减少历史序列信息的丢失并加强重要信息的影响。针对单一热负荷预测的研究较少,文献[12]提出了一种基于机器学习的多步短期热负荷预测方法,比较分析神经网络、极限学习机、支持向量机、高斯过程回归等代表性机器学习方法预测模型。文献[13]提出了一种线性模型预测热负荷,基于智能电表采集到的数据建立黑盒方法,主要思想是识别曲线特征。文献[14]针对供热预测,结合差分进化和灰狼优化对支持向量机回归模型进行优化。
随着综合能源系统的快速发展,针对负荷预测的研究也逐渐从单一负荷类型的预测向多元负荷预测发展。文献[15]借助Stacking集成学习的思想和多目标回归的方法来协同预测IES多元负荷。文献[16]在多元负荷耦合性分析的基础上设计了一种基于径向基函数神经网络模型的预测方法。多任务学习结构凭借可以满足多元输出的要求以及共享网络层的优势也被应用于IES 多元负荷的联合预测[17-19]。通过多任务学习网络中的共享机制,各个子任务可以利用神经网络建立的共享学习层互相分享学习到的序列高维特征和网络参数等,以充分挖掘不同能源类型负荷的耦合特征。关于多任务学习结构中具体的神经网络搭建,文献[17]采用多个限制玻尔兹曼机和BP 网络构成的深度置信网络(deep belief network, DBN),文献[18]和[20]采用LSTM 神经网络,文献[21]采用径向基函数神经网络。Transformer网络结构由Google提出,摒弃了传统的Encoder-Decoder框架必须结合循环神经网络的固有模式,全部采用attention结构的方式捕捉序列间的关联性,其所具有的并行化计算和序列长期依赖性学习的优势为负荷预测带来了新的发展空间[8,22]。
基于上述分析, 本文提出了一种基于Transformer 和多任务学习的综合能源系统电-热短期负荷预测模型。首先介绍了Transformer 网络和多任务学习的基本原理;然后通过特征分析,构建多任务学习输入特征,基于Transformer 网络构建多任务学习权值共享层,最后通过全连接层输出多能负荷的预测值;最后分析了电、热负荷的预测结果,通过与DBN、LSTM 和SVM 模型预测结果对比及与单任务学习预测结果对比,验证了本文所提方法和算法的可行性。
1 基于Transformer的多任务训练理论分析
1.1 Transformer
本文的负荷预测模型网络采用基于注意力机制的Transformer模型,通过输入-编码-解码-输出4个步骤得到负荷预测结果。Transformer 主要应用在自然语言处理等领域,具有良好的特征抽取能力,解决了RNN 由于序列依赖关系导致的并行计算能力差的问题,改进了seq2seq 编码端损失信息的缺陷。其原理如图1所示。
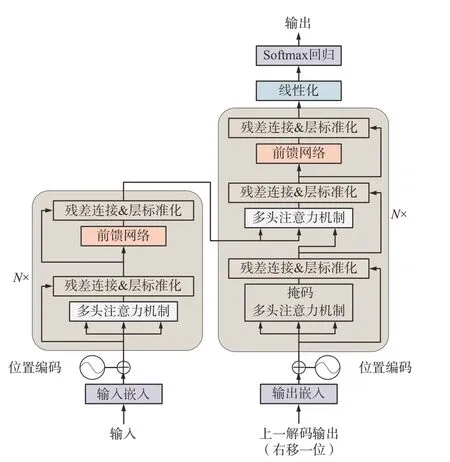
图1 Transformer模型Fig. 1 Structure of the Transformer model
设一条数据样本有p个数据,Transformer 的输入由单个数据值和数据位置向量相加得到。将得到的数据表示矩阵传入编码器,经过注意力机制处理后的数据传入前馈神经网络,并行计算得到的结果输入到下一个编码器。经过N次编码操作得到编码信息矩阵并传递到解码器中。解码器根据当前预测出的数据yi预测下一个数据yi+1,这个过程需要通过掩码操作遮盖住yi+1之后的数据。
Transformer中编码和解码的输入所添加位置编码向量能够表示当前数据的位置以及不同数据之间的距离。位置编码公式由CPE表示。
式中:Cpos为当前数据在样本中的位置;d为位置编码向量的维度;i为每个值的位置索引,偶数位置使用正弦编码,奇数位置使用余弦编码。
注意力机制接收的是输入或者上一个编码器的输出,将接收到的数据乘以不同权重得到Q、K、V3个矩阵。通过公式(3)自发得到数据之间的相似度。
式中:Q为查询矩阵;K为关注内容;QKT计算出对于Q在V上的注意力权重;dk为K矩阵维度,用于归一化注意力机制;softmax为归一化指数函数。
残差连接用于解决多层网络训练的网络退化问题,可以让网络只关注当前差异的部分。将输出表述为输入X和输入的一个非线性变换F(X)的线性叠加X+F(X),然后经过层标准化操作。残差连接如图2所示。

图2 残差连接示意图Fig. 2 Schematic diagram of residual connections
将Transformer 输出序列与训练样本对应的输出标签序列进行对比,最小化KL 散度损失函数以得到最优网络参数。KL散度是用来衡量两个概率分布的相似性的一个度量指标,用DKL表示。设P(X)为标签序列,Q(X)为Transformer 预测输出序列。KL散度计算如式(4)所示。
式中:q(xi)为Transformer预测输出序列中第i个负荷预测值;p(xi)为标签序列中q(xi)对应时刻的负荷值;l为序列长度。DKL(P||Q)为P(X)和Q(X)两个序列的KL 散度损失函数,DKL(P||Q)越小,表示两组数据分布越接近,通过反复训练神经网络以使Q(X)的分布逼近P(X)。
1.2 多任务学习
大多数机器学习模型都是独立进行学习,称为单任务学习。单任务学习用两个独立的神经网络分别预测电负荷和热负荷,每个网络只有一个优化目标,训练相互独立,这种方式易忽略任务之间的关联、冲突和约束等关系,难以考虑电热负荷之间的耦合,会导致负荷预测整体效果无法更优。多任务学习可以存在多个学习目标,通过使用共享机制并行训练多个任务。电热负荷间存在复杂的耦合关系,大量的共享信息存在于数据中,且这些耦合特点难以由传统特征提取方法得到。采用多任务学习的方法对电热负荷进行预测,能够有效使用复杂共享信息,有助于更好地提取抽象特征,预测效果更佳。多硬参数共享[23]是常用方法之一,底层参数统一共享,顶层参数各个模型各自独立。由于对于大部分参数进行了共享,模型的过拟合概率会降低。
多任务学习总体的损失函数来源于不同任务损失函数之和,损失函数的加权方式应该是动态的,根据不同任务学习的阶段,学习的难易程度,学习的效果等进行调整。电负荷预测和热负荷预测均是对系统负荷进行预测,要求两个预测任务以相近的速度来进行学习,根据此特性,选用动态加权平均方法,利用损失函数变化率,平衡多任务学习速度。设共有K个任务,任务k的权重αk(t)根据式(5)—(6)进行计算。
式中:t为迭代次数;Lk(t- 1)和rk(t- 1)分别为任务k在第t-1 次迭代时的损失函数和相对下降率;T为常数,用来控制任务权重的平滑度。多任务学习如图3所示。
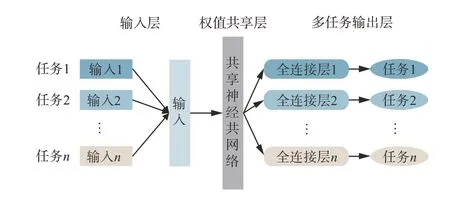
图3 多任务学习示意图Fig. 3 Schematic diagram of multi-task learning
2 电热负荷预测模型
2.1 输入特征构建
负荷的典型特征指标可分为气候特征指标和非气候特征指标两类[24]。其中,气候特征指标有:温度、降雨量、湿度、风速等;非气候特征指标有:负荷历史数据、日历规则、星期类型、能源价格等。表1为电热负荷预测模型输入特征。
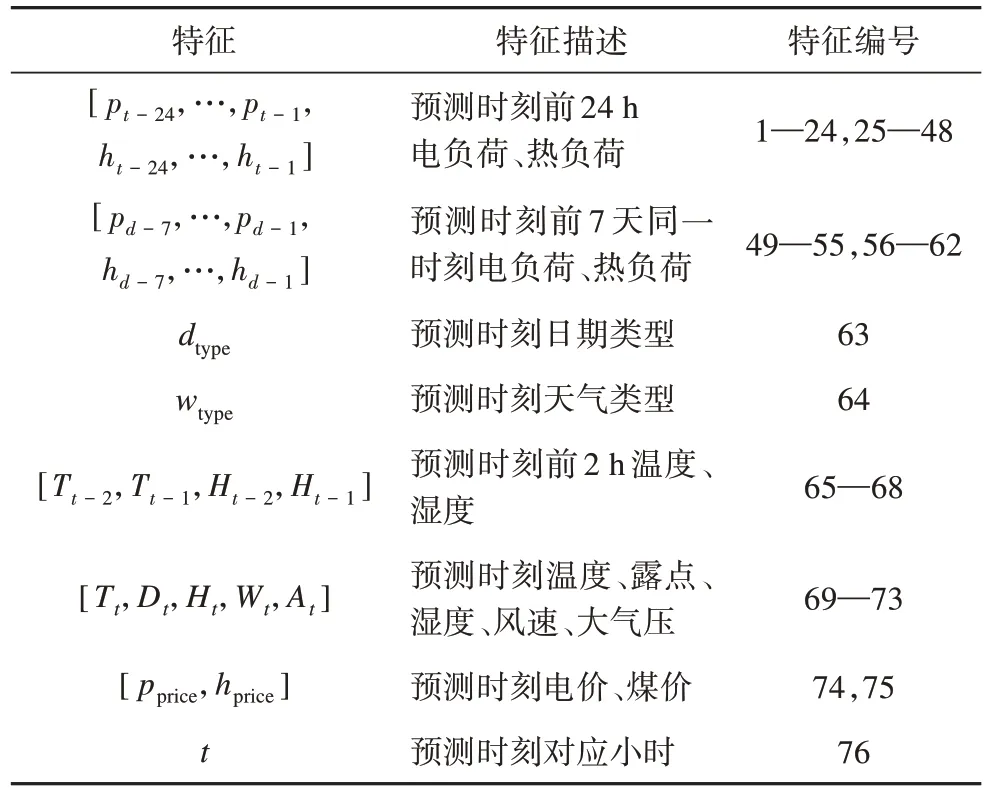
表1 电热负荷预测模型的输入特征Tab. 1 Input characteristics for electricity and heat load forecasting models
负荷预测需要在众多影响因素中,筛选出若干种影响最大的因素。特征选择操作可以提取反映负荷特性及其变化规律的典型指标。随机森林法可以对特征的贡献度进行深入分析,思想是计算每个特征在随机森林中的每棵树上的贡献度并取平均值,比较不同特征的贡献度大小。由于每棵树均基于基尼系数选择向下分裂的特征,基于基尼系数(GI)评价特征重要性作为贡献度的衡量指标。假设有a个特征X1,X2,…,Xa,特征Xj在某一棵树i的节点m向下分裂,分裂前的基尼系数为Gm,分裂后左右分支的基尼系数分别为Gl和Gr,分裂前后的基尼系数变化量Vginijm由式(7)计算得到。
假设该特征Xj在树i上分裂了h次,Xj在当前树的重要性由式(8)表示。
随机森林共有b棵数用到该特征,得到该特征重要性评分为:
最后将所有求得的重要性评分进行归一化处理,得到每个特征的贡献度。
各个特征对负荷预测的贡献度不同,与负荷特征相关性较强的特征对负荷预测的贡献度更大。将Vj按照由大到小顺序进行排列,重要性评分越高的特征代表贡献度越大。
2.2 预测模型构建
考虑到神经网络的训练需要消耗巨大的计算资源和时间成本,已训练完毕的神经网络参数固定不变,输入样本数据直接能够输出预测结果,采用离线训练+在线预测模式。训练完毕运用s折交叉验证的方法选出最优模型。方法是将整个样本库划分为s个大小相同的互斥子样本集。
每次迭代中,使用不同s-1 个子样本集训练模型,剩余的一个子样本集作为验证,并计算模型在测试集上的准确率。在s次迭代中,在每个子样本集上均构建了模型,并验证了每一个子样本集。s折交叉验证使用了无重复抽样技术,保证了每次迭代过程中每个样本只有一次被划入训练集或测试集的机会。计算出s次迭代的平均准确率,作为最终的模型准确率。选择s个模型中KL 散度误差最接近平均误差的模型作为最终的离线训练模型。Transformer 模型下电热负荷预测方法流程如图4所示。

图4 电热负荷预测离线训练流程Fig. 4 Off-line training process for electricity-heat load forecasting
离线训练流程为全部a个输入特征经过特征选择按照贡献度大小排序分别筛选出p1个电负荷特征和p2个电负荷特征,合并电热负荷输入形成完整样本库。将样本库划分为s个大小相同的互斥子样本集,将每种划分方式的训练集输入Transformer 模型,电热负荷预测任务经过相同网络进行编码、解码等操作,共享权值,训练出s个不同的Transformer模型。用不同训练集对应的测试集计算网络的误差,并取与平均误差最接近的模型为最佳模型。通过全连接层分离电负荷预测结果和热负荷预测结果,得到的输出为当前时刻电负荷和热负荷预测值。最后评价两个子任务并进行综合评价。离线训练完毕,保存模型参数,在线决策是按照格式输入特征数据,经过固定参数的Transformer 多任务模型得到预测结果。
2.3 评价指标
基于Transformer 的多任务学习的本质是回归模型,常见评价指标主要有均方误差MSE,均方根误差RMSE,平均绝对误差MAE 等,主要针对单任务学习且度量的是预测数据和标签数据的误差。R-squared 方法既考虑了预测值与标签之间的差异,也考虑了标签数据的离散程度,是一个归一化的度量标准,由式(12)计算。
式中:yˉ为标签数据的平均值;yi和分别为第i个标签数据值和预测值。分子表示残差平方和,分母表示回归平方和。R2的取值为(0,1),越接近1,表明神经网络对输出的解释能力越强,模型对数据的拟合越好。增加特征数量,分母回归平方和会增加,分子残差平方和会减少,R2会增大;反之,R2减小。为了消除样本数量和特征数量的影响,引入Adjusted R-squared方法,由式(13)计算:
式中:n为样本数量;p为特征数量;R2adj为校正R2函数。增加一个有意义的特征变量,R2adj增大;若这个特征是冗余特征,R2adj减小,同时抵消了样本数量对R2的影响。利用式(13)可以单独对电负荷和热负荷预测结果进行评价。为了整体评价多任务学习模型预测精度,满足对不同负荷主导性和预测精度需求,可以增加权重以平均精度作为综合评价指标。
式中:αk为第k个任务的权重,根据式(5)-(6)进行计算,满足α1+α2+ …αk= 1,根据不同任务的预测需求调节对应权重。
3 算例分析
3.1 数据描述
本算例采用的数据来自于我国北方某地区微能源系统2019 年全年的电、热负荷数据以及该地区气象数据,其中气象数据包括温度、湿度、露点等。本文预测的是未来1 h的电、热负荷值,因此数据采集频率为1 h,一天24个时间节点,共8 760个样本。将该数据按照模型预测的要求分为训练集、验证集和测试集。三种数据集划分的比例为6∶3∶1,模型在训练集上进行学习,验证集用来评价模型的学习能力,测试集用来展示模型的预测效果。
3.2 数据预处理
上述原始数据集来源不同的采集系统,电、热负荷主要来源于用电采集系统和能量管理系统,气象数据主要来源于当地气象站数据采集装置。这些数据在采集和存储过程中难免会出现数据缺失异常等情况,因此对该数据集进行数据挖掘之前,需采取一定的手段对其进行预处理。首先对数据集进行质量检测,包括数据异常值和缺失值检测,其次对检测出的坏数据进行修正。本文采用箱型图来判定数据出现的异常值情况,如图5所示。图中Q1到Q3分别为下四分位点和上四分点,涵盖了数据分布最中间50%数据,IQR为四分位距,IQR=Q3-Q1。设定数据落在(Q1-1.5×IQR,Q3+1.5×IQR)范围内为正常值,范围之外为异常值。

图5 异常值判别箱型图Fig. 5 Box diagram of outlier discrimination
对于缺失值和异常值的修正采用均值插值法,如公式(15)所示。通过求取相应位置前后n个数据的平均值对其进行替换,这里取n= 4。
3.3 特征重要性分析及选择
微能源网系统中的电、热负荷不仅与历史负荷有很强的相关性,同时也受到天气因素、日期类型的影响,因此根据历史负荷、天气因素以及日期类型初步构建输入特征,选择预测时刻前24 h的历史负荷、预测时刻的天气特征、以及日期类型作为初步输入特征。在这些特征中,存在部分不相关或者冗余的特征,增加了模型的复杂度。为了对初步输入特征进行特征选择,本文采用了随机森林法来计算初步输入特征的贡献度,通过特征贡献度指标来对负荷历史数据、温度、湿度、风速等特征进行选择,提取反映负荷特性及其变化规律的典型特征指标。如图6(a)、(b)分别为初步输入特征指标对电、热负荷预测的贡献度。

图6 初步输入特征贡献度排序图Fig. 6 Sorting diagram of contribution degree of preliminary input features
从图中可以看出,初步输入特征指标体系中的各个特征对负荷预测的贡献度是不同,与负荷特征相关性较强的特征对负荷预测的贡献度较大,相邻时刻的历史负荷对未来负荷值的影响较大,因此特征贡献度相对较高。温度具有明显的季节特性,因此其与电、热负荷的相关度也相对较高。
3.4 模型超参数设置
本文通过建立Transformer 多任务模型来实现电、热负荷预测,而模型的超参数设置对预测结果也会产生一定的影响。Transformer模型的超参数主要有迭代训练次数(epochs)、批量大小(batch_size)、交叉验证折数(s)以及多任务权重(α1、α2),将其分别设置为epochs=100、batch_size=64、s=10以及α1∶α2=0.6∶0.4。为了突出Transformer 模型对电、热负荷预测的显著优势,分别引入深度置信网络、支持向量机以及长短期记忆神经网络作为对比算法模型,通过设置相同的迭代训练次数来增加可对比性。
3.5 电-热负荷预测结果分析
多任务学习模型的损失函数为单任务损失函数的加权求和。本文对电、热负荷进行预测,均采用均方误差作为损失函数,由于任务数量为2,因此电、热负荷损失函数的权值分别为0.6 和0.4。如图7所示,通过绘制总Loss曲线来诊断Transformer多任务预测模型的性能以及泛化能力。图中可以看出,在迭代初始时刻,损失函数值呈急剧下降趋势,但随着训练的进行,总损失的下降趋势变得平缓,且训练集损失和测试集损失都已经开始收敛,两者之间的差值也越来越小,此时模型训练效果最佳。

图7 Transformer多任务预测模型损失曲线Fig. 7 loss curves of Transformer multi-task prediction model
表2 分别给出了Transformer、深度置信神经网络(DBN)、支持向量机(SVM)以及长短期记忆神经网络(LSTM)模型对电、热负荷预测在测试上的表现。采用R2 评价指标来评估各模型的预测效果。可以看出Transformer 模型对电、热负荷预测比其他对比模型在测试上的表现更好一些,预测精度更高一些,这主要是因为Transformer 模型具有很好的学习能力,能够充分学习隐藏于数据内部的特征。但在训练时间方面Transformer 模型略逊于其他单任务模型,主要是因为Transformer 模型的网络结构较为复杂,模型在训练时参数学习较多,因此模型训练的时间成本有所增加。
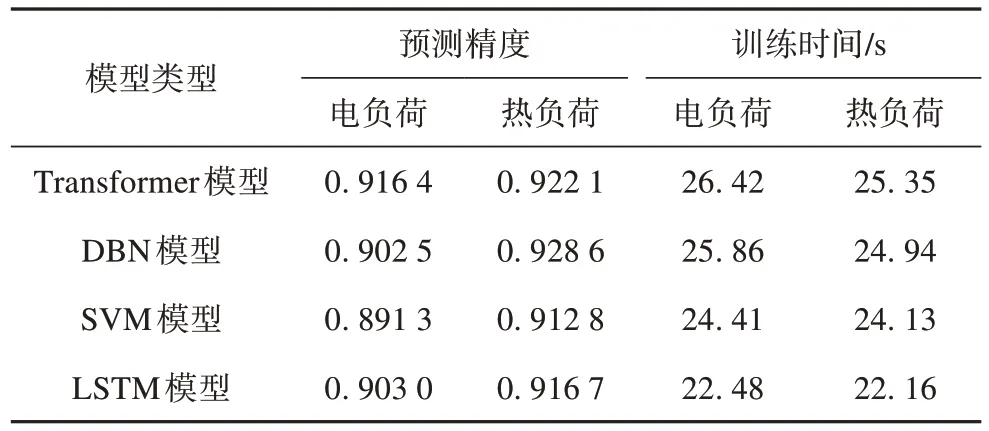
表2 多任务模型与单任务模型预测效果对比分析Tab. 2 Comparative analysis of prediction effect between multitask model and single-task model
表3 为Transformer 多任务学习模型和DBN 多任务学习模型的电、热负荷预测效果对比,可以看出Transformer 多任务模型对电、热负荷的预测结果要优于DBN 多任务学习模型,主要因为多任务学习通过共享层学习,能够充分学习不同负荷之间存在的非线性耦合特性,使得模型能够更加有效的表示输入特征与输出量之间的关系。Transformer多任务预测模型的预测时间与DBN 多任务预测模型较为接近,但在负荷预测精度方面得到了较高的提升。
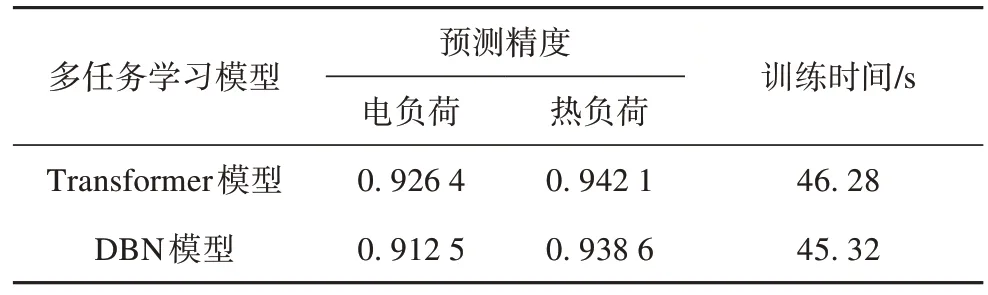
表3 多任务模型与单任务模型预测效果对比分析Tab. 3 Comparative analysis of prediction effect between multitask model and single-task model
如图8(a)、(b)所示,分别为工作日和休息日电、热负荷预测效果图。从图中可以看出,Transformer 多任务学习模型的拟合效果要更好一些,而且在一些负荷波动比较大的时刻也能够很好地拟合。对于多任务和单任务学习模型的预测误差只要集中在峰谷时刻。
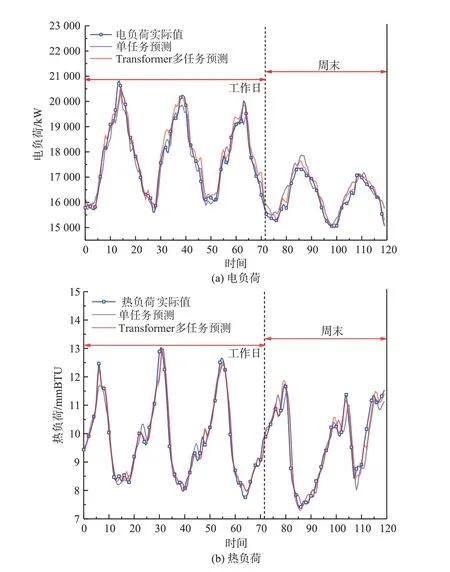
图8 多任务与单任务模型预测效果图Fig. 8 Prediction effect of multi-task model and single-task model
为了进一步刻画Transformer 多任务模型的学习性能以及在测试集上突出表现。可以绘制预测残差分布曲线,如图9(a)、(b)所示,分别是多任务模型和单任务模型的电、热负荷预测残差分布图。从残差分布图中得出,多任务学习模型的电、热负荷预测残差分布较为集中,为单任务学习模型的电、热负荷预测残差分布较为离散。残差分布图能够反映多任务模型在电、热负荷预测中的优越性和有效性,同时也能够反映出多任务学习模型具有很好的泛化性能。
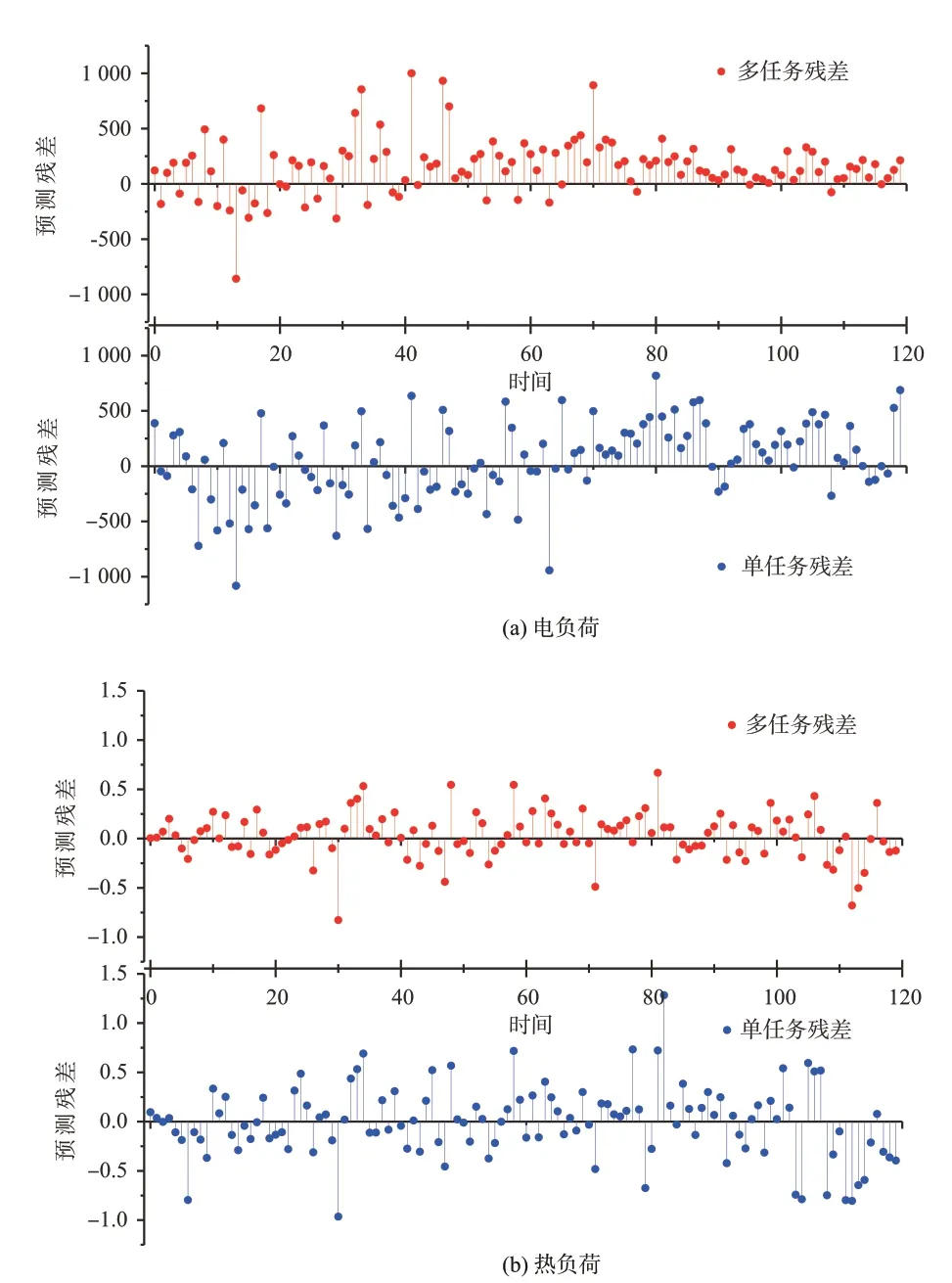
图9 多任务与单任务模型预测残差分布图Fig. 9 Prediction residuals distribution of multi-task model and single-task model
4 结语
本文针对综合能源系统电-热短期负荷预测,考虑电-热负荷之间的耦合性,提出了一种基于Transformer网络和多任务训练的模型,通过构建多任务学习输入特征和基于Transformer 网络的多任务学习权值共享层,最后通过全连接层输出多能负荷的预测值。采用实际微能源系统的数据验证所提方法和算法的有效性,分析了与DBN、LSTM 和SVM 模型预测结果的对比及与单任务学习预测结果的对比,算例结果表明本文所提模型可以充分学习电-热耦合特征,提高负荷预测的精度。在未来的研究中,将进一步考虑气、冷等负荷的预测,挖掘分析多元负荷之间深层次的耦合性,提高IES 多元负荷预测的精度
