对地区基尼系数与幸福感关系的“现象核实”
——基于对数据生成过程的考察
2023-03-05高勇
高 勇
默顿①Robert K.Merton,“Three Fragments from a Sociologist’s Notebooks:Establishing the Phenomenon,Specified Ignorance,and Strategic Research Materials,”Annual Review of Sociology,vol.13,1987,pp.1-28.曾经观察到,虽然在核实现象存在之后再去进行解释是看似不言自明的道理,但是在科学研究中,与这个道理相反的事情并不少见。究其原因,或者是因为这样一种核对事实的工作很容易被贬斥为“纯粹经验性的事实收集”,或者是因为研究者在意识形态或理论期待的指引下会直接跳过这样一个“简单环节”。然而,“现象核实”(Establishing the Phenomenon)往往并不是一件轻而易举的事情,尤其研究对象是纷繁复杂的社会现象时。
本文就是对于地区基尼系数与幸福感之间关系的现象核实。研究地区基尼系数与幸福感的关系,其理论意义在于探讨行动者的主观观念或主观感受与所处社会情境的客观特征之间的关联机制。基于不同的调查数据,以往的研究对此得出了彼此冲突的结论。这种情况与研究者单纯以系数的统计显著性为指标的研究方式有关,它往往导致对数据生成过程的思考不足。本文试图一方面通过对数据生成过程的认真考察,揭示出地区基尼系数与幸福感之间的关联并没有足够坚实的统计证据,以完成这一基本的“现象核实”工作;另一方面,借此例证表明单纯以系数的统计显著性为指引和目标的工作方式是存在缺陷的,定量研究并不一定是线性的假设验证过程,而完全可以也应当是在经验数据与解释逻辑之间循环往复从而不断逼近事实真相的过程。
我们首先回顾和梳理有关地区基尼系数与幸福感之间关系的相关研究文献,明确这个经验问题的理论意义;然后进行常规的统计模型操作,看单纯依据系数的统计显著性为指标会得出何种结论;在此基础上再考察数据生成过程,以便挖掘出重要的控制变量来澄清背后隐藏的真正逻辑,说明两者之间的关系至少不像表面那样稳健,甚至可能只是一种统计假象;最后,我们再回到对经验问题的理论讨论中来,对社会感受的形成机制进行一些探索性的思考,并对其中涉及的研究方法取向进行一些反思。
一、问题的意义:主观感受与客观结构
行动者所处社会环境中的收入不平等程度与行动者的主观观念或感受之间有何关联,这是一个重要的研究问题。利用全国综合抽样调查数据(如CGSS)计算得出区县(甚至更小单位的)基尼系数(或泰尔指数等相似指标),然后引入回归模型进行分析,这是一种讨论收入不平等效应的常见做法。利用这种方法,研究者们考察了地区基尼系数对个体幸福感或生活满意度的效应、对于居民信任和政府信任的效应、对于收入差距容忍度的效应等等。
对相关研究的结论进行梳理后,就会发现一种令人不解的现象:在这些研究当中,区县基尼系数的效应多数都是显著的,但是在因变量相同的情况下,效应方向却时而为正,时而为负,并不确定。另外,有研究者发现了“倒U型曲线关系”,也有研究者发现这种曲线关系并不存在。基于不同的经验发现,研究者又各自提出了不同的解释逻辑。以地区基尼系数与幸福感的关系研究为例,在现在文献中大致有如下两类截然不同的结论:
(一)负向关系与“相对比较”逻辑
许多研究的结果显示,地区基尼系数与幸福感的效应估计值为负且统计显著,收入不平等程度显著地损害了各个阶层的幸福感。①王鹏:《收入差距对中国居民主观幸福感的影响分析——基于中国综合社会调查数据的实证研究》,《中国人口科学》2011年第3期;何立新、潘春阳:《破解中国的“Easterlin悖论”:收入差距、机会不均与居民幸福感》,《管理世界》2011年第8期;巫锡炜、肖珊珊:《地区差异与我国居民主观幸福感》,《青年研究》2013年第1期;黄嘉文:《收入不平等对中国居民幸福感的影响及其机制研究》,《社会》2016年第2期;王健、张焕明、李超:《收入差距对居民幸福指数的影响研究——基于2013年CGSS数据的实证分析》,《宁夏大学学报》(人文社会科学版)2017年第6期;Wu,Xiaogang and Jun Li,“Income Inequality,Economic Growth,and Subjective Well-Being:Evidence from China,”Research in Social Stratification and Mobility,vol.52,2017,pp.49-58.这些研究多数都是利用CGSS2005和CGSS2006年数据进行的。某些早期研究采用一般线性回归模型进行估计,这种研究方式忽略了数据本身存在的层级结构,可能高估参数的效应。区县基尼系数本身是一个宏观背景变量,因此数据本身具有层级结构,只有利用层级模型才有可能对此进行精准估计。后来的研究采用多水平模型(也被称为层级线性模型),使得估计值更为精准。对于地区基尼系数的估计方式有两类:一种是直接利用CGSS调查数据进行估算,另一种是利用样本量更大的2005年1%人口抽样调查数据进行估算②巫锡炜、肖珊珊:《地区差异与我国居民主观幸福感》;Wu,Xiaogang and Jun Li,“Income Inequality,Economic Growth,and Subjective Well-Being:Evidence from China.”,后一种估算方式应当更为精准。还有研究者在利用多水平模型进行系数估计后,还构建了面板数据来看地区基尼系数的变动引发的幸福感变动。③Wu,Xiaogang and Jun Li,“Income Inequality,Economic Growth,and Subjective Well-Being:Evidence from China.”对这些结果的解释主要是从“相对比较”的角度进行的:个体非常关注自身与他人相比的相对位置,这种比较和评估是在一个局部背景中相对于某一个参照群体进行的。拥有同样收入的个体,如果处在不平等程度更大的局部环境中,他就更有可能产生挫败感,进而降低其幸福感。
(二)正向关系与“隧道效应”逻辑
另有一部分研究的结果显示,区县基尼系数与幸福感之间呈现出显著的正向关联:收入不平等程度越高,幸福感反而越高。④Knight J.,Song L,and Gunatilaka R.,“Subjective Well-being and Its Determinants in Rural China,”China Economic Review,vol.20,no.4,2009,pp.635-649;马万超、王湘红、李辉:《收入差距对幸福感的影响机制研究》,《经济学动态》2018年第11期;刘自敏、杨丹、张巍巍:《收入不平等、社会公正与认知幸福感》,《山西财经大学学报》2018年第5期。这部分研究利用的数据包括2002年中国家庭收入调查(CHIP)数据、2010—2015年的CGSS五期面板数据、2014年社会发展与社会态度调查(NISD)数据等。研究者使用的统计模型既有一般线性回归,也包括层级线性模型。对于地区基尼系数与幸福感之间的正向关联,多数研究者是从所谓“隧道效应”的角度进行解释的。赫希曼等人提出,人们对于不平等的容忍程度是随着发展的不同阶段而变化的。①Hirschman A.O.and Rothschild M.,“The Changing Tolerance for Income Inequality in the Course of Economic Development,”Quarterly Journal of Economics,vol.87,no.4,1973,pp.544-566.在发展的早期阶段,尽管收入差距逐渐拉开,但是人们对于不平等具有相当的容忍程度,这是因为高收入者为他们提供了生活改善的希望与前景,如同处在交通堵塞的隧道中的司机在看到旁边车道开始移动时,即使自己还没有移动也会充满希望一样。这样一种看到他人状况提升而带来的希望就是“隧道效应”。赫希曼提出的隧道效应假说,针对的是随时间发展的动态过程中呈现的模式。但是上述研究将隧道效应的逻辑引来解释同一个时点对不同地区进行比较呈现出来的模式。②此外,赫希曼的“隧道效应”针对的主要研究单位是国别而非同一国家内部的不同地区。因此利用赫希曼的“隧道效应”对地区基尼系数的效应进行解释时,研究单位其实也发生了变动。由此看来,区域内收入不平等的适度增大,增强了人们对于未来生活福祉提升的预期,从而提升其幸福感。
(三)曲线关系与“隧道效应”逻辑的拓展
也有研究发现区县基尼系数与幸福感存在着倒U型关系:随着收入不平等程度的扩大,个体的幸福感呈现出先增加后减少的态势。③王鹏:《收入差距对中国居民主观幸福感的影响分析——基于中国综合社会调查数据的实证研究》;郝身永:《究竟是患寡、患不均还是患不公?——基于CGSS(2006)对居民幸福感决定的经验研究》,《云南财经大学学报》2015年第5期;孙计领:《收入不平等、分配公平感与幸福》,《经济学家》2016年第1期。这一发现的证据,是基尼系数的平方项在回归方程中的系数是显著的(且符号为负)。还有研究者甚至发现,这种倒U型关系在各个层面都普遍存在:不仅区县基尼系数有这种关系,甚至乡镇/街道和社区基尼系数与幸福感均存在显著的倒U型关系。对上述曲线关系同样可以从“隧道效应”的角度来进行解释。赫希曼指出,如果过了发展的早期阶段,收入不平等仍然持续扩大,那么人们对不平等就不再容忍了,就如同旁边车道一直移动而自己的车道却迟迟不动的司机,他必然会沮丧而且愤怒。由此推论,地区基尼系数与幸福感之间的关系是存在某个临界值或门槛的:在此之前收入差距拉大使人们对未来经济福利有更高的信心,因此促进幸福感;在此之后收入差距拉大引发更多负面影响。不过需要存疑的一点是,这种曲线关系大多是在一般线性回归模型中发现的,而利用层级线性模型进行的研究很少发现有“倒U型关系”存在。
如何看待上述彼此冲突的研究结论呢?本文试图回到数据中,探测地区基尼系数与幸福感之间发生统计关联的机制,完成这一基本的“现象核实”工作。
二、常规的统计模型操作:以系数显著性为指标
在本节,我们用CGSS2013数据来对地区基尼系数与幸福感之间关系进行常规的统计模型操作,以了解两者之间是否存在经验关联以及关联的方向与强度。
(一)相关分析与一般线性回归
CGSS2013年数据中包括来自126个区县的被访者,多数区县都有100名左右的被访者。我们可以用这些被访者的家庭收入数据来估算他们所在区县的基尼系数。④这种估算当然并不精确,包括了一定程度的测量误差。我们在后面会讨论测量误差对分析可能带来的影响。数据中对于幸福感的测量是定序尺度的:“总的来说,您觉得您的生活是否幸福?”选项是从“非常不幸福”到“非常幸福”的五度区分。初步的计算表明,区县基尼系数与区县被访者的幸福感均值的相关系数为0.20(P<0.05)。区县基尼系数与幸福感确实是相关的,而且在统计上非常显著。两者是正相关关系:区县基尼系数越大,幸福感的评价值越高。
我们继续进行多元回归分析,这样就可以在控制其他相关因素的条件下,更为准确地了解它们之间的关系。我们纳入如下控制变量,包括性别、年龄、受教育年限、家庭总收入的对数、居住地类型(城市/农村)、身体健康状况、当前是否有配偶,然后运行多元回归(模型1)。模型1的结果显示在表1中第一栏中。我们看到区县基尼系数的回归系数为0.61,仍然是正的;这一系数值的t值为6.21,在统计上极其显著。看来,“隧道效应”的解释是更有道理的。
当然,如果“隧道效应”的解释是正确的,那么区县基尼系数与幸福感之间的关系就应该有一个先升后降的过程。我们在回归方程中加入基尼系数的平方项,以此检验这种曲线关系是否存在(模型2)。模型2的结果非常理想,平方项的系数为负且非常显著,这表明基尼系数与幸福感的关系确实存在这样一种先升后降的过程。倒U型曲线意味着某个临界值或门槛的存在:在此之前收入差距拉大使人们对未来经济福利有更高的信心,因此促进幸福感;在此之后收入差距拉大引发更多负面影响。根据系数估计值,这一U型关系的拐点大约发生在基尼系数为0.5左右,而多数样本区县的基尼系数在0.5以下,因此我们用线性关系来估计时它就表现为正向关系。
(二)统计模型的精细化
一般线性回归的诸多前提在此并不能够完全满足,因此我们应该在统计模型上进一步精细化,采用更“高级”的统计方式来提升统计估计的精度。
首先,因变量“幸福感”并不是一个定距变量,而是一个五类别的定序变量。因此,线性回归的模型设定并不完全正确,我们应当采用定序logistic的统计模型来进行估计才是更准确的选择。我们由此估计了模型3(见表1):多数变量的统计显著性几乎没有任何变化,而我们最关心的变量“基尼系数”的统计显著性甚至有了大幅度增加。统计模型的精细化并没有否决我们的前述结论,反而让我们对结论更有信心。
此外,CGSS数据是嵌入于某种层级结构(个体-居委会-区县)当中的,我们原先并没有在模型设定中注意这一点。样本中的案例并不是统计独立的,同一区县中的个案拥有相同的基尼系数值。基于此种考虑,我们可以采用层级线性模型(HLM模型),在模型设置中加入随机截距项。估计结果如表1中的模型4所示:区县基尼系数的效应仍然在统计上非常显著,虽然标准差有所增大,t值有所减小。看来,我们的结果是非常稳健的。
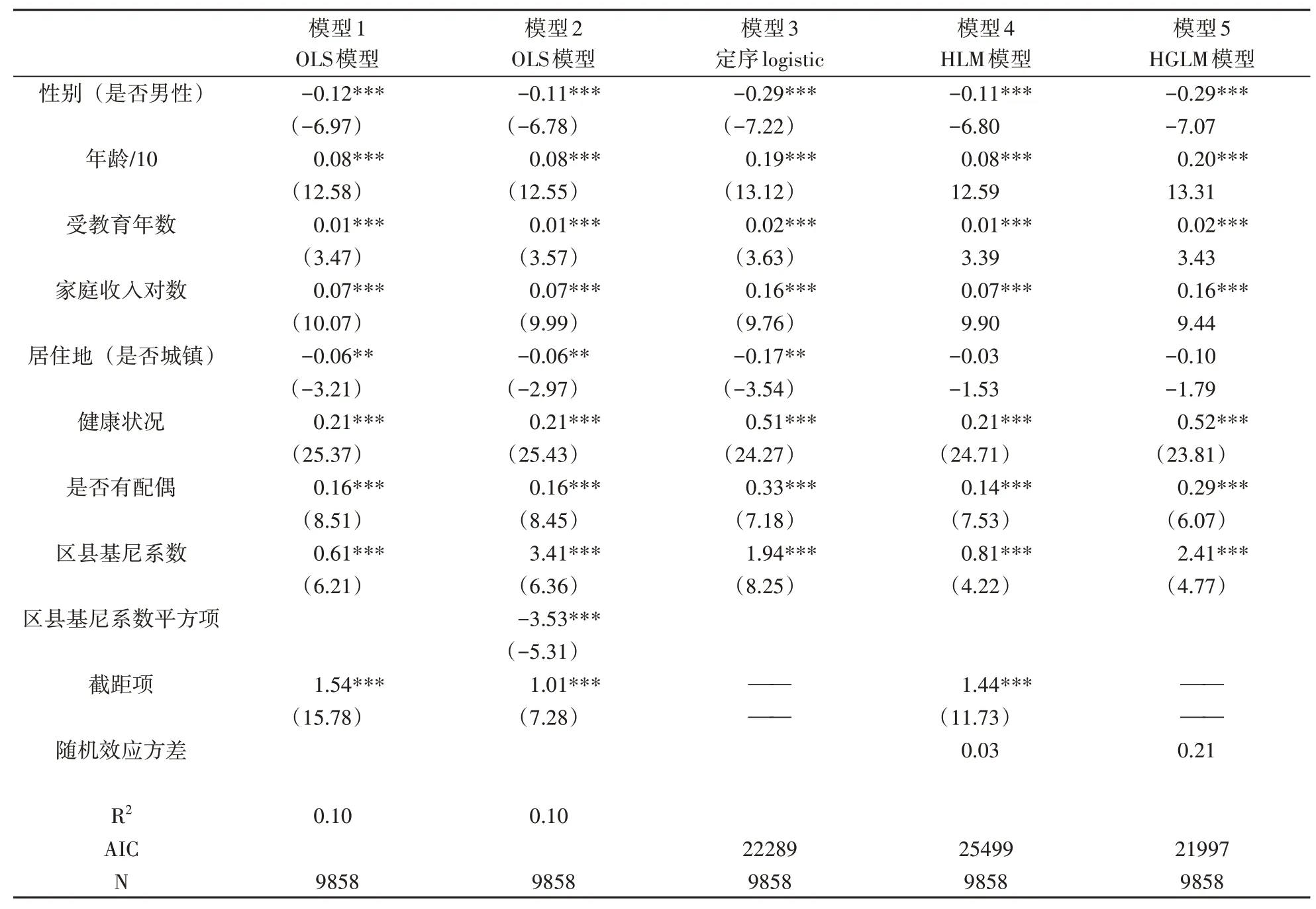
表1 对区县基尼系数与幸福感关系的初始模型拟合
在上面的层级线性模型中,我们是把因变量“幸福感”作为定距变量处理的。如果既考虑数据的层级结构,同时又考虑到因变量的定序特性,我们就应当采用广义层级线性模型(HGLM模型)。对于定序因变量来说,这种模型也被称为累积性连接混合模型(Cumulative Link Mixed Models),采用这样的模型才能得到最为精确的系数估计和标准误估计。在计算机软件的帮助下,我们再次运行了HGLM模型(模型5)。区县基尼系数的系数估计仍然非常显著。看来,更为复杂前沿的统计技术对于系数数值及其统计显著性有所改变,但是并不能推翻我们的前述基本看法。
最后,还有一个麻烦需要认真考虑,即测量误差问题。我们使用的核心自变量“区县基尼系数”是仅仅基于每个区县100个左右的样本而得出的,这里面应该包括了比较大的测量误差。我们还要考虑到,在CGSS数据中,抽样方式并非简单随机抽样,而是多阶段分层抽样。样本并不是随机分散于区县中的,而是汇集在区县中的少数村居委会。如果不同阶级在居住空间上有较大的集中性,那么这样一种抽样方式得到的样本的代表性就可能比较差,从而导致测量误差比简单随机抽样设计下要大很多。更何况,作为一种结构性测量指标的基尼系数比通常的矩统计量更容易产生较大的抽样误差。因此,这一核心自变量的测量精度是值得怀疑的。自变量存在测量误差确实会引发估计量不再是无偏和一致的,但是这种影响会使得估计值比真实估计值更接近于0,从而降低其统计显著性程度。①杰弗里·M.伍德里奇:《计量经济学导论:现代观点》,张成思译,北京:中国人民大学出版社,2018年,第249—252页。因此,即便区县基尼系数的测量确实存在较大的随机性测量误差,这也只能说明真实的效应值应该比我们估计出来的效应值更大,在统计上更为显著。测量误差的存在只能说明我们的估计值可能更偏向于保守,而不可能动摇我们的核心结论。
如果单纯以系数的统计显著性为评判指标,那么区县基尼系数与幸福感的正向关联是非常稳健的,得到了各种复杂统计模型的背书。疑问似乎已经得到解答,探索似乎已经可以结束。②以往的多数研究是到此为止的。但是,也有部分研究者(如Wu,Xiaogang and Jun Li,“Income Inequality,Economic Growth,and Subjective Well-Being:Evidence from China.”)意识到“可能存在着未观察到的地区特征会同时影响收入不平等与人们的主观福祉”,因此构建了省级层面的面板数据来解决这种遗漏变量偏差。然而这种策略能够有效的前提是面板数据分析中引入的时变变量没有遗漏;遗漏变量问题并没有因此消失,而只是转化了存在的形式。如下文所述,如果不对数据生成过程进行深入考察,面板数据分析这一统计技术也不能确保结论的可靠性。
三、对数据生成过程的考察:“地区类型”的引入
(一)对情境与主体的追问:是哪些县市推动变量关系得以呈现?
统计结果是对于变量关系的表述,这些变量本身又是对处于一定情境的社会主体特征的描述。因此,我们面对变量关系的上述表述时,也会希望再回到对社会情境与社会主体的理解上来:这种统计结果背后描述的是谁?是谁推动了这样一种统计结果得以呈现?这是因为有一些城市收入不平等程度特别高,同时人们的幸福感也特别高吗?这是哪些类型的城市?是不是通常所设想的那些大都市地区?或者,这是因为有一些城市收入不平等程度特别低,同时人们的幸福感也特别低?这又是哪些类型的城市?是那些经济发展更为滞后的地区吗?上述诸多信息并不包括在模型系数的显著性水平中,而必须再回到对数据的深入描述中才能掌握。
CGSS2013数据不提供调查案例所在区县的具体名称,但是提供了这些区县所在的省份信息。我们绘制出了每个区县基尼系数与幸福感均值的散点图,并加入了拟合曲线(如图1所示)。然后,我们对散点图中那些区县基尼系数小于0.3或者大于0.55的区县标注出所在省份。从这一散点图中,我们看出了重要的信息。
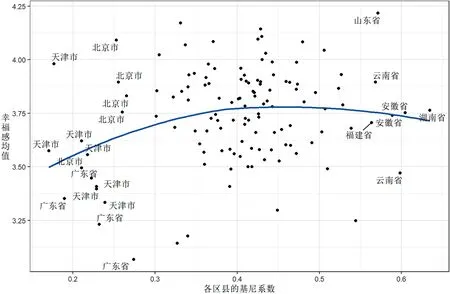
图1 区县基尼系数与幸福感均值的散点图
第一,那些基尼系数估算值低于0.3的区县大多处于北京、天津、广东省等大都市地区,基尼系数估算值高于0.55的区县则大多处于云南、湖南、安徽等相对而言并不太发达的地区。然而,如果我们要用“隧道效应”来进行解释,那么基尼系数应该是随着经济发展状况而提升的,那些相对不太发达的地区应是基尼系数较低的,发达的地区应是基尼系数较高的。经验数据的细节与理论解释并不相符。
第二,在基尼系数估算值的大部分取值范围中(大于0.3的部分),它与幸福感均值几乎不存在线性关系,拟合线近似于一条水平线。只有在散点图的左端,即当基尼系数小于0.3时,拟合线向上倾斜。左下方的一系列散点是形成这样一种拟合曲线的原因。由此看来,变量之间存在统计关联,是因为有一部分基尼系数估算值较低同时幸福感也较低的城市,而不是因为有一部分基尼系数估算值较高同时幸福感也较高的城市。
第三,大都市样本与非大都市样本在散点图中似乎分布在非常不同的区域,有着较为明显的模式差异。这种模式差异有可能会影响我们对于基尼系数估算值与幸福感之间统计关联的考察。
因此,尽管“隧道效应”可以通过对于模型系数的统计显著性检验,但是它与数据描述的上述细节无法吻合。这些探究源自对社会情境与社会主体的理解,它引导我们看到了更多的问题:为什么大都市样本中测算出来的区县基尼系数会比较低?为什么大都市样本与非大都市样本有不同的模式?这些模式会对我们原先的结果有何影响?为了回答这些问题,我们就需要认真查看数据的生成过程。
(二)为什么大都市样本的基尼系数测算值相对较低?
在CGSS的抽样方案中,存在着必选层与抽选层的设计①更多细节请参阅《中国综合社会调查(CGSS)第二期(2010—2019)抽样方案》,http://cgss.ruc.edu.cn/xmwd/cysj.htm。:
1.必选层是指那些发展处于国内领先水平的大城市。CGSS第二期调查是从直辖市、省会城市和副省级城市共36座城市中,最终选取了经济水平、教育水平及城市开放性程度综合指标最高的五个城市进行调查,分别是北京、上海、天津、广州、深圳。对于必选层中,总样本量为2000户,样本均为城市家庭户。在必选层中,街道是初级抽样单元,首先抽取40个街道,每个街道中抽取2个居委会,每个居委会抽取25个家庭户。
2.抽选层是指除去必选层市辖区以外全国所有家庭户。在抽选层中,总样本量为10000户,样本既包括城市家庭户也包括农村家庭户;区县作为初级抽样单位,首先抽取100个区县,每个区县中抽取4个居委会或村委会,每个居委会或村委会抽取25个家庭户。
3.抽选层中的区县需要进行居委会与村委会的配比。配比是根据区县城市化水平(非农人口比重)来决定的:非农人口比例在95%以上的区县,4个二级抽样单元全部是居委会;这一指标在50%—95%之间的区县,抽取3个居委会和1个村委会;指标在15%—50%之间的区县,抽取2个居委会和2个村委会;指标在15%以下的区县,抽取1个居委会和3个村委会。
在这样的抽样设计方案下,我们可以有如下推断:
第一,不同类型地区的样本的城乡异质性有很大差异,而城乡异质性直接影响测算出来的基尼系数大小。必选层中的大城市样本全部来自居委会,基尼系数因此会较小;抽选层中的区县样本中既有居委会也有村委会,基尼系数因此会较大。区县样本中居委会/村委会的配比与测算出来的基尼系数之间的关系如表2所示。

表2 CGSS2013样本区县中居委会/村委会的不同配比与基尼系数的关系
第二,不同类型地区的样本数量及代表性有所不同,这同样影响测算出来的基尼系数大小。大都市地区样本的初级抽样单元为街道而不是区县,多数区县中最终仅被抽到了2个居委会(50个家庭户样本),且在同一街道;非大城市地区样本中的初级抽样单元为区县,所有区县都被抽中了4个村委会或居委会(100个家庭户样本),且在不同街道。利用地域集中程度更高、样本量更小的数据,测算出来的基尼系数当然会更低。此外,如果从严格的抽样理论上来看,大都市地区样本对区县并无代表性。
第三,不同类型地区的居住隔离程度有所不同。由于城市房产价格的原因,大都市地区居住于同一居委会中的居民家庭收入往往较为接近。在农村地区,隶属于同一村委会的村民因收入提升而搬离本村庄的可能性固然存在,但相对城市而言较小。如果大城市地区存在更严重的居住隔离的情况,利用上述多阶抽样方式测算出来的基尼系数也会相对偏小。
(三)在大都市样本与非大都市样本中,变量关系可能存在什么样的不同模式?
由于不同地区类型内部的城乡异质性有非常大的差异,也由于不同地区类型在抽样中居委会与村委会的配比并不相同,因此测算出来的区县基尼系数取值范围有很大差异。基于上述考虑,我们认为有必要区分样本中的必选层(大都市地区)与抽选层(其他地区)来进行分析。我们先来直观地看一下双变量之间的散点图(图2)。图2中的两个图其实是由图1拆分而成:左边显示的是数据中必选层(大都市地区)的情况,右边显示的是抽选层(非大都市地区)的情况。

图2 区分大城市样本与非大城市样本分析
从图2中我们可以直观地看出如下几点:
第一,不同地区类型的基尼系数取值范围完全不同:非大都市地区测算出的区县基尼系数没有低于0.3以下的情况;大都市地区测算出的区县基尼系数除了上海市外,没有高于0.4的情况。
第二,在非大都市地区中,区县基尼系数与幸福感均值并无明显的线性相关关系。在大都市地区中,粗略看起来两个变量存在着正向相关,但是图中右上角的几个散点非常特殊,它们都来自于上海样本(图中用十字形来代表),这些地区基尼系数估计值与幸福感均值都远高于其他都市地区。看来上海市样本在大都市地区也有特殊性,我们有必要将其作为单独对象来进行分析。①其原因值得探讨,但是这并非本文的主旨。在去除上海样本后,大都市地区的区县基尼系数与幸福感均值之间并不存在任何明显的相关关系。
第三,尽管分组分析时两个变量并不存在任何线性关系,但是当两者合并起来时,由于代表大都市的散点位于左下角,代表非大都市的散点位于右上角,结果使得两个变量之间看似存在正向相关关系。这是一个类似于经典的“辛普森悖论”的结果。
我们进一步把非大都市区的样本按照区县中居委会与村委会的配比进行细分,然后进行分组分析,结果如图3所示。图3中共有四个小图,分别代表4个二级抽样单元中有1个居委会到4个居委会的情况;根据CGSS的抽样方案,这实际上代表不同的城市化水平。从图3中可以看出:第一,二级抽样单元中居委会比重越高的区县,测算出来的基尼系数也越小,因此散点越靠近左端;第二,基尼系数与幸福感的关系方向在第一组中是正向的,在其他三组中是负向的,总体而言并不存在稳定的模式;第三,如果说基尼系数与幸福感之间存在关系,那么这种关系的强度也很微弱。①在第三组中存在一个明显的离群点,我们用三角形表示。为了更好地描绘变量间的关系趋势,第三组中的拟合线是排除此离群点之后拟合的。
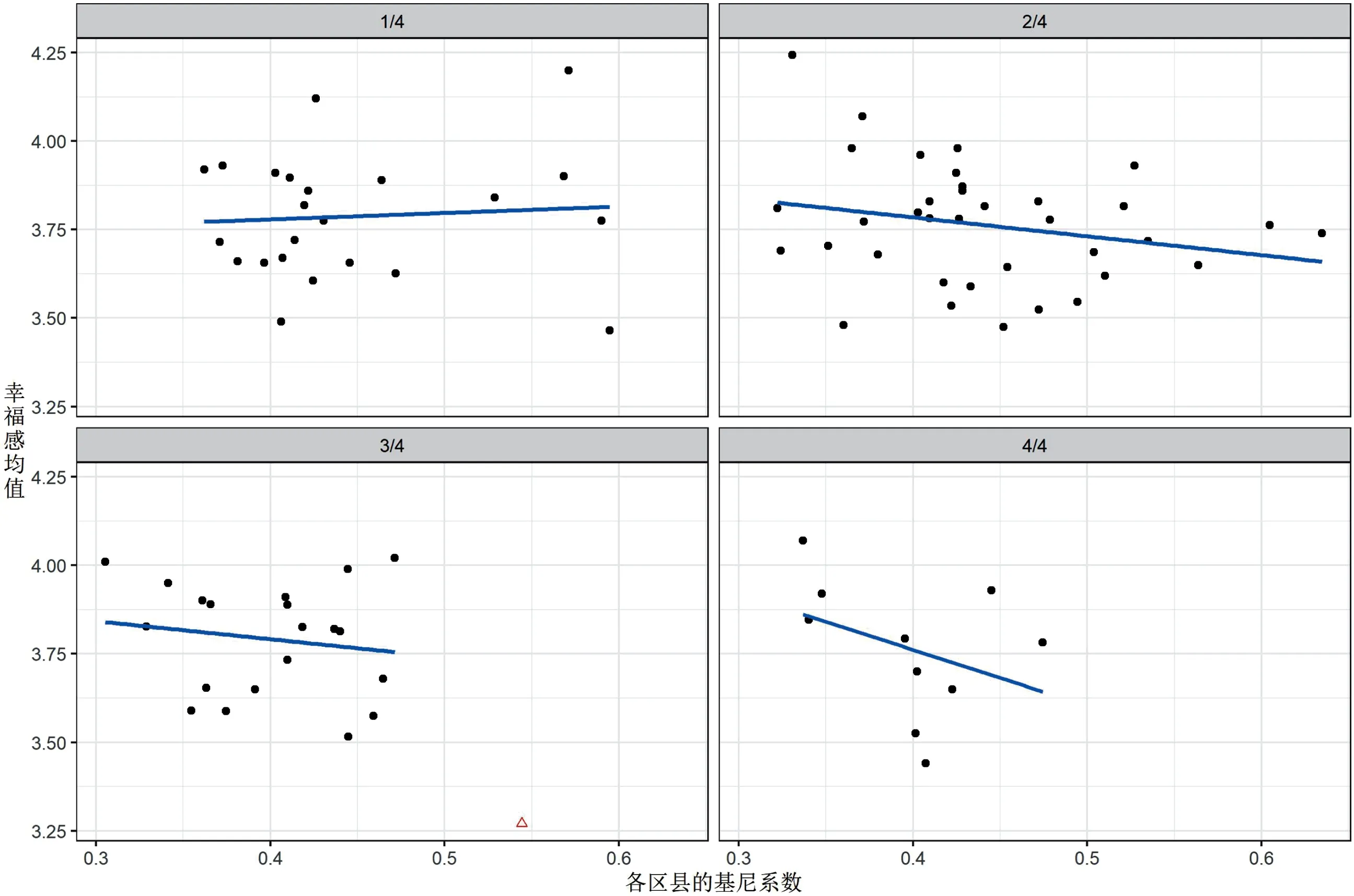
图3 非大都市区中区分城市化水平分析
四、再回到统计模型与系数显著性中
(一)对原先模型的修正
通过对数据生成过程的了解,我们意识到前面的模型是需要修正的。第一,模型遗漏了一项最为重要的变量——所属区县的类型(大都市/非大都市)。这一遗漏变量与基尼系数的取值有非常强的相关关系,与幸福感之间也有较强的相关关系。我们必须把这一变量补充到模型当中,再来进行检验。第二,在大都市样本中“上海”地区具有较为特殊的性质,它进入样本与否会使大城市地区的分析结果发生极大改变,因此我们有必要把“是否上海”作为单独变量纳入模型中,以增强模型分析的稳健性。第三,大都市样本中在区县层面是没有代表性的,因此相对于非大都市样本而言,我们必须更为保守地对待其分析结果。
据此,我们分别对大都市和非大都市区县进行最为简单的OLS回归(表3模型6)。结果表明,无论在大都市区还是非大都市区,区县基尼系数与幸福感之间的关系在统计上都是不显著的。在区分了区县类型之后,原先的结论被否决了。当然,OLS回归在统计估计上并不是最佳的选择,考虑到因变量的定序层次以及数据的层级特性,我们需要选用HGLM模型来进行更精准的估计(表3模型7)。在采用了HGLM模型之后,部分系数的估计及其显著性水平确实发生了改变,但是整体而言改变并不大。尤其是,区县基尼系数的效应无论在大都市区还是在非大都市区都是不显著的。
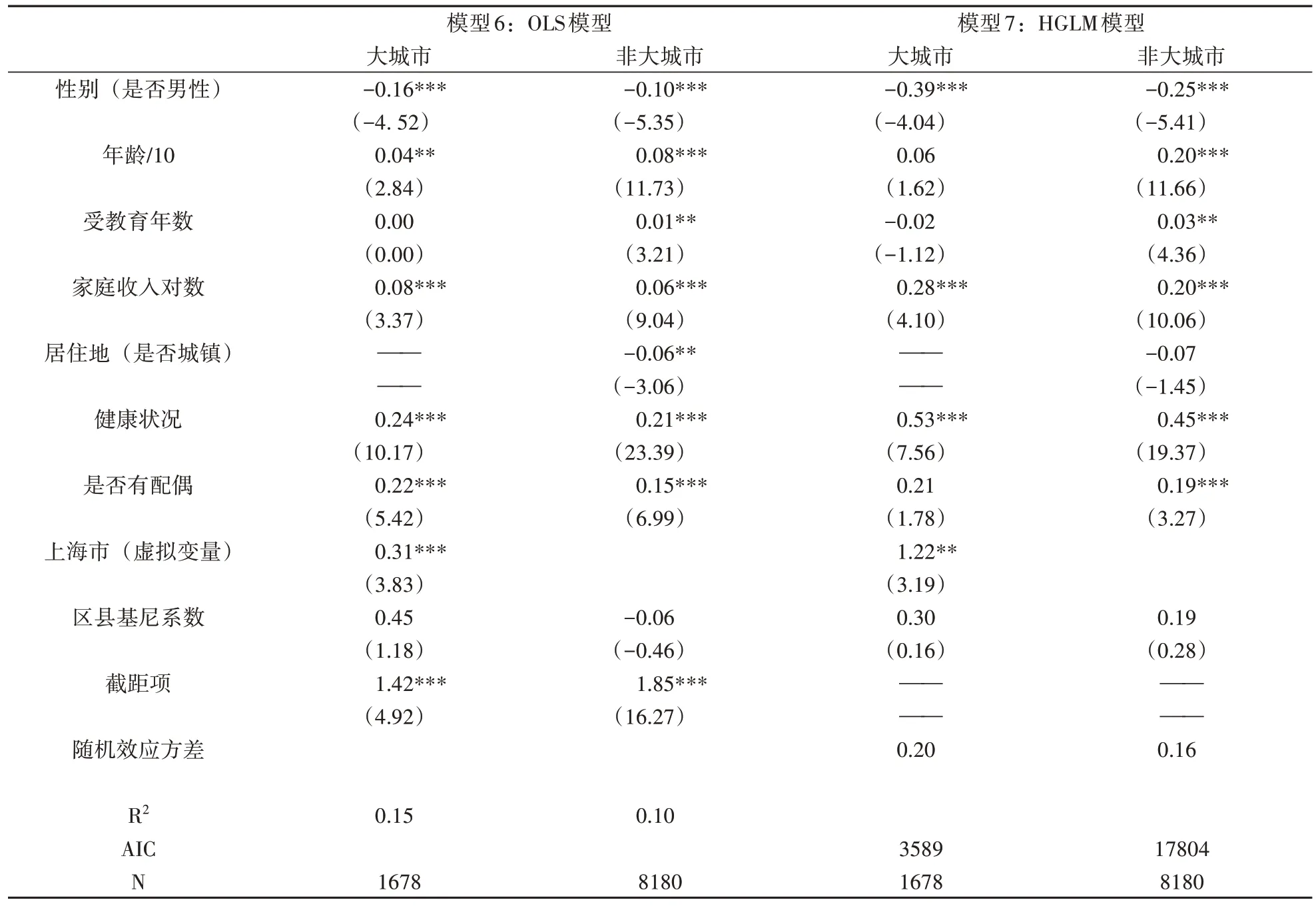
表3 纳入区县类型之后的模型估计
对于前述“曲线关系”的说法,我们也进行了验证。在区分了大城市样本与非大城市样本之后进行的HGLM模型中,基尼系数与基尼系数的平方项均不显著(模型估计在此略去)。由于遗漏了地区类型这样一个关键变量,原先的模型分析存在误导性。事实上,一旦引入这一变量进行分组分析,区县基尼系数的效应就可能会消失或者大幅降低;区县基尼系数与幸福感之间的关系并不是稳健存在的。①我们根据样本中居委会与村委会的配比(这又是由其城市化水平决定的)将非大城市样本分为四组,然后分组进行了回归模型拟合。结果同样显示,在每一组中区县基尼系数对于幸福感的效应在统计上均不显著。
上述结论是与CGSS数据的抽样方式相关的。许多研究者意识到从CGSS数据中计算区县基尼系数可能存在较大误差,因此从更大规模的数据(如全国1%人口抽样调查)中去取得相对准确的地市基尼系数估计值,然后与CGSS数据进行匹配关联。②巫锡炜、肖珊珊:《地区差异与我国居民主观幸福感》;Wu,Xiaogang and Jun Li,“Income Inequality,Economic Growth,and Subjective Well-Being:Evidence from China.”这样计算出来的基尼系数误差会相对较小。但是在这样的数据生成过程中,基尼系数测算值与地区类型之间的关联是否存在,这仍然是值得探索的问题。我们需要去追问是哪些县市在推动变量关系得以呈现,然后去进行分组分析或引入新的控制变量,才能真正澄清变量关系的真实模式。③如前所述,构建面板数据也并不能够真正解决遗漏变量可能带来的偏差。在进行面板数据分析之后,我们仍然需要去追问是哪些县市在推动变量关系得以呈现:哪些县市的收入不平等程度出现了上升,哪些县市出现了下降。我们利用CGSS2010—2015年数据构建了省级层面的面板数据,尽管对面板数据的初始分析会呈现出统计显著的变量关系,但一旦引入地区类型变量后,就会发现变量关系至少在非大都市区中并不稳健,在大都市中的显著关系也主要起因于少数城市的特殊变化。限于篇幅,对面板数据的分析在此无法呈现,有待未来深入讨论。
(二)对于以往研究中效应方向变动不居的一种可能解释
如前所述在对区县基尼系数与幸福感(及其他主观指标)的研究中,存在一种令人困惑的现象:区县基尼系数的效应方向时而为正时而为负,并不确定。对此的解释之一是区县基尼系数的测算中存在较大的测量误差,但前面的分析揭示出了另一种可能的解释。在图4中,我们利用假想数据对此进行直观演示。

图4 利用假想数据演示的两种可能性
在图4中,方形散点代表来自大城市地区的区县;圆形散点代表来自非大城市的区县。大城市的多数区县的基尼系数测算值都低于来自非大城市的区县。如果对大城市和非大城市进行分组分析,区县基尼系数与幸福感之间并不存在关联(图中的虚线代表分组的回归线)。但是一旦把两组数据合并而不加区分,那么区县基尼系数与幸福感就会呈现出一种有关联的假象(图中的实线代表不分组的回归线)。更重要的是,此时如果样本中的大城市地区幸福感低于其他地区时,不分组估计出来的基尼系数效应值就是正的(如图4中左图所示);当样本中的大城市地区幸福感高于其他地区时,不分组估计出来的基尼系数效应值就是负的(如图4中右图所示)。当然无论正负,这种效应其实都只是一种“统计假象”。①以往文献中发现区县基尼系数与幸福感呈负向关系的研究多数采用的是CGSS2003—CGSS2006年数据,而发现区县基尼系数与幸福感呈正向关系的研究多数采用的是CGSS2010—CGSS2013年数据。CGSS2003—CGSS2006数据不再公开案例所在区县编码,我们无法就上述推断进行直接验证。不过,从CGSS2010—CGSS2013年数据看,这几年中大都市居民的幸福感确实有所下降。
五、再回到对机制解释的追究中
上述一系列考察达到的最终结论是:地区基尼系数与幸福感的统计关联并不稳健,至少当前我们并没有足够坚实的统计证据能够判定两者的关联机制和方式。这样一个结论似乎是完全否定性的,其实不然。在本文开头提及的默顿的那篇文章中,他还提到了科学研究中的另一个常见现象:“明确的无知”(specified ignorance)往往是通向知识的道路的第一步。所谓“明确的无知”,就是明确我们在哪些方面需要了解而还没有足够的了解。它不是对知识无限性的泛泛而谈,而是需要经过努力才能够明确的内容。因此,我们的结论并不完全是否定性的,其中包括了未来应该努力澄清的机制解释方向。
如前所述,研究地区基尼系数与幸福感的关系,其理论意义在于探讨行动者的主观观念或主观感受与所处社会情境的客观特征之间的关联机制。我们意识到,在这里需要澄清的几个重要问题如下:
1.在行动者的日常生活世界中,他们对于社会平等程度的感知何种程度上取决于微观生活情境中的具体关系性体验,何种程度上取决于宏观世界中的抽象性测量(如“地区基尼系数”)?或者,抽象性测量是如何能够通过日常生活世界的中介而能够被行动者感知到的?
2.如果说行动者对社会平等程度的感知是有时间和空间的限定的,那么他能够感知的平等程度的参照系在空间上有多大范围?是否不同的行动者有着不同的空间参照系范围?
3.都市与非都市区构成了完全不同的社会情境。在不同的生活情境中,人们对于社会平等程度的感知机制是否一样?他们对社会平等程度的重视程度是否一样?
只要上述三个问题还没有澄清,我们就不太可能确信自己掌握了地区基尼系数与幸福感之间的因果关联。例如,如果行动者对社会平等的感知完全取决于具体关系性体验,而与抽象性测量只有微弱的间接关系;如果行动者对社会平等的感知的空间参照范围根本不是自己所在的区县;如果在特定情境中,行动者对社会平等根本并不在意,那么上述两个变量之间就不可能存在稳健的关联。行动者的主观感觉过程是复杂而微妙的,它不会从根本上脱离客观结构的限定,但也不会是抽象的客观结构的直接对应物。未来的研究应当针对上述分解之后的每个具体机制环节进行探索与验证。
六、方法上的讨论:独角戏,还是二重奏?
最后我们进行一点方法上的反思。阿博特曾说,“好多人把社会科学当成了独角戏,而非二重奏。他们眼里,社会科学就是自己的一番长篇大论之后,再抛出一个刻板的问题,现实则像旧小说里的矫情淑女,只是点头或摇头。真正的研究者不一样。他们知道,现实才不那么老实,它有层出不穷的花招来戏弄和挑逗研究者,直觉和方法之间在不断进行交锋。社会科学实践并不是旧小说,而是现代言情剧。”①Abbott,A.,Methodsof Discovery:Heuristicsfor the Social Sciences,New York:Norton,2004,p.3.那种单纯以系数的统计显著性为指引和目标的定量研究方式,看起来确实很像阿博特所戏谑的“旧小说”,尤其是它似乎不太明白,有时候现实世界这位淑女点头与摇头回应的可能根本不是自己所提出的那个问题。要真正理解点头摇头的意思,办法只能是坐下来与她进行多轮交流。
因此,我们得到统计参数显著的结果而验证了自己的预设时,研究并没有结束,甚至这只是研究的开始。统计学家费舍尔(Ronald Fisher)在被问及如何在观察研究中从相关中推出因果时,曾经回应说:“把你的理论充分展开”(Make your theories elaborate),也就是说“在构建因果假设时,研究者要尽可能充分地展现这个道理的各种不同后果,然后再用观察研究来发现每个后果是否都能立得住”。②Cochran,W.G.and Chambers,S.P.,“The Planning of Observational Studies of Human Populations,”Journal of the Royal Statistical Society,Series A(General),vol.128,no.2,1965,pp.234-266.在社会学的研究中,这意味着我们需要从变量关系的表述再回到对社会情境与社会主体的理解上:是谁推动了这样一种统计结果得以呈现?如何推动?它又出现在何种社会情境中?数据的细节与上述理解相符吗?我们需要从单一的经验假设中推衍出丰富的经验细节,然后去数据中再进行验证。当然,不可能所有的细节都能被完美地验证,但是这个过程中蕴含了对社会世界产生新洞见的可能性。研究就不再是线性的假设验证过程,而成为在经验数据与解释逻辑之间循环往复从而不断逼近事实真相的过程。③Lieberson,S.and Horwich,J.,“Implication Analysis:A Pragmatic Proposal for Linking Theory and Data in the Social Sciences,”Sociological Methodology,vol.38,no.1,2008,pp.1-50.
在这个过程中,对数据生成过程的认真推敲是非常重要的。任何数据都是通过人为手段经过一定程序在某一“社会”空间和“社会”时间中得来的,因此有必要对数据收集方式带来的可能后果进行思考。如果不能够深入数据本身,不对数据生成过程进行推敲,忽视细节核对与分组分析,即便使用再“高级”的统计模型与技巧,定量研究也仍然会衍生出大量缺失稳健性的结论。在社会学研究的“可复制性”④Freese,Jeremy and David Peterson,“Replication in Social Science,”Annual Review of Sociology,vol.43,no.1,2017,pp.147-165.已经引起诸多研究者重视的当下,这一点尤其需要强调。
