超大规模计算集群监控系统的设计与实现
2023-03-04彭亮牛铁魏宝亮赵毅
彭亮*,牛铁,魏宝亮,赵毅
中国科学院计算机网络信息中心,北京 100083
引 言
高性能计算在大气、生态、高能物理、材料科学、生命科学等各个领域应用广泛,计算能力逐渐从P级向E 级发展,集群规模日益庞大且结构复杂[1-3]。为保障其持续稳定运行,需要自动化以及智能化的监控系统支持系统运维管理。与以往中小规模集群不同,节点和设备数超过10000 的超大规模计算集群具有系统架构复杂、监控对象绝对数量多、监控数据高度并发等特点[4-5],它的监控系统将面临性能、精准化、扩展性等多方面的问题:
(1)高度并发的数据传输问题。来自数万节点的百万条甚至更多监控数据,要在短时间内、频繁地汇聚与保存。
(2)海量监控数据快速读取问题。日均数百GB的监控数据在持续积累和存储后,需要在使用时被快速检索和读取。
(3)庞大系统中诸多业务的差异化精准监控问题。管理人员需要针对不同业务以及运维监控需求,定制化精准采集所需的监控数据。
(4)超大规模集群及多集群横向扩展问题。随着系统规模的持续增加,简单的二层Agent/Server 架构无法满足大量节点及多计算集群的统一监控需求,特别是对位于不同地域、不同架构的计算集群监控。
本文结合实际需求,设计和实现了一套工作于超大规模计算集群的监控系统,具备上万节点和设备的CPU、内存、网络、I/O 等运行状态数据、计算作业数据,以及管理员自定义监控数据的采集、分布式存储和快速读取能力,并在此基础上开发出自动故障告警、个性化数据展示等功能。同时,基于独特的架构设计,该监控系统具有良好的横向扩展能力,可支持异地集群监控数据的采集与接入。目前该系统部署和应用于中国科学院某超大型超级计算系统中,同时异地部署于中国科学院“地球大数据科学工程”的专用计算系统[6]中,对帮助管理员在海量数据中快速发现和定位故障,保障其持续稳定运行具有重要意义。
1 高性能集群监控发展现状
通过整机商业采购的高性能计算集群,常常捆绑有厂商自行开发的商业版集群监控系统。由于和硬件系统出自同一厂商,其具有良好的适配性和兼容性,能够最大限度地获取集群内各类硬件的状态及告警数据,并通过高度定制化的图形界面予以展示。不过,由于商业开发十分重视成本核算,因此商业监控软件在功能、监控范围及展示上往往比较固化,更新迭代较慢,很难及时满足运行管理中与具体业务相关的个性化监控需求。因此,这类监控软件更适合于单纯的对硬件系统的自动化监控和告警。
商业软件之外,Ganglia、Zabbix 以及近年兴起的Prometheus 等开源软件系统都可以实现集群监控功能,但也存在各自的局限性。如,Ganglia 采用多播方式完成数据传递,通过一个节点即可收集到同网段所有节点的数据,且支持分层管理和动态增删功能。但当集群规模持续增大时,由组播风暴产生的全局数据冗余特性会导致网络性能大幅降低[7]。Zabbix 功能齐全、模板化管理操作方便,但其数据存储于关系型数据库极大限制了自身的读写性能[8],降低了可扩展性。Prometheus 安装简单、插件丰富、查询高效,但在拉取数据时均需与监控端建立TCP链接,在面对超大规模采集对象时,需要另外搭建联邦集群缓解性能压力和数据丢失问题,增加了系统管理难度[9-10]。
综上所述,现有集群监控软件在面对海量数据采集、传输、检索时均有不足,难以满足10000 以上节点超大规模计算集群的实际监控需求,需要从软件架构、传输机制、业务耦合、数据存储等方面进行改进和优化。
2 系统设计
2.1 系统主体框架
超大规模计算集群监控系统主要由数据采集、传输处理、持久化存储、个性化展示,以及告警管理等模块组成,其主体框架如图1所示。
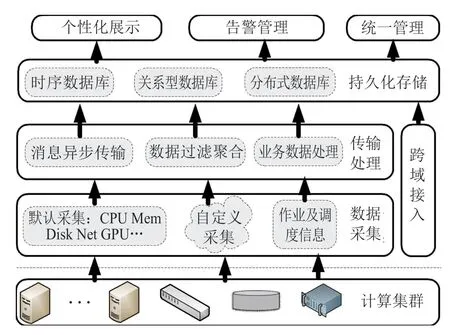
图1 监控主体架构Fig.1 Architecture of monitoring system
数据采集模块通过在监控端部署采集代理定时收集默认指标、自定义指标以及业务相关数据,整理成约定的数据格式,发布至消息管道。数据处理组件依据消息主题订阅管道中的数据,在对其解析处理后实时写入数据库,同时为了减轻系统存储和展示的压力,将默认采集指标的原始数据进行多种粒度聚合。告警管理模块定期对指标数据进行规则过滤分析,如发现异常则产生告警提示。持久化存储按时间序列对收到的运行负载数据、日志数据、告警信息等分类存储。展示模块则实现对系统中单点、整体监控情况等进行多维度展示。总域管理系统通过跨域接入模块汇集来自各分域管理子系统的健康状况、在线负载、故障报警等重要状态信息,实现多集群集中展示、统一管理。
2.2 监控数据采集
监控数据采集如图2所示,主要分为3 类:

图2 数据采集流程Fig.2 Process of monitoring metrics collection
(1)预置采集项:需要在监控对象上部署采集代理,对通用指标进行采集。默认包括CPU、内存、以太网络、IB 网络、磁盘、I/O、系统基础信息、关键系统日志等信息,并可根据需要灵活配置其采样开关、采样频率、过滤条件等,降低对监控对象的资源损耗。
(2)自定义采集:针对预置采集项之外的批量化监控需求,如:特殊硬件的监测指标、不能安装采集代理的网络和存储设备、具体应用服务的运行状态,以及系统管理员关注的个性化状态信息等,采用自定义脚本的方式实施采集。自定义脚本支持Shell、Python 等语言编写,执行结果输出成预定义的标准Json 格式,由采集代理负责发布至消息管道。
(3)调度信息采集:针对高性能集群常用的LSF、PBS、Slurm 等作业调度系统,采集作业数量、运行状态、队列信息、消耗机时数、在线用户等信息。为降低代码复杂度,调度信息由独立的模块完成采集。该模块部署在可提交计算作业的节点中,采集结果通过消息管道回收并解析入库。
2.3 监控数据传输
一个节点单次默认采集400 余项监控指标,经处理后聚合成20 条1KB 的监控数据。在10,000 节点的超大规模计算集群中,每次采集将产生20 万条数据,并由各个节点经网络并发写入后端数据库系统。采用传统的同步传输机制不仅效率低且容易出现数据拥塞。为此,本文采用了基于消息中间件的异步传输模式,减少了请求响应时间,同时解耦了通信双方。
为避免对集群计算业务的影响,监控数据均通过管理网络传输。如图3所示,发送端和接收端通过“发布-订阅”的方式进行数据的收发,每条数据均携带主题(topic)标签,接收端基于主题进行消息过滤,主要有以下两种场景:
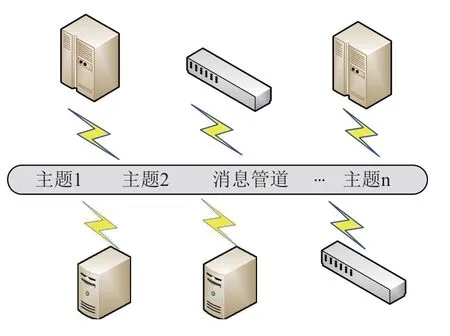
图3 消息中间件数据传输Fig.3 Data transmission base on Message-Oriented Middleware
(1)采集数据的传输:采集组件将采集到的指标信息及故障规则触发信息等封装成约定的Json 格式,通过RESTful 接口直接发布到消息管道。监控管理端从消息管道按照主题类型订阅自己需要的数据。发布者和订阅者异步解耦,消息中间件也无需关心所服务的应用程序环境。
(2)规则数据的发布:监控管理端定时检查告警规则设置或触发脚本是否发生变化,并将更新部分推送到数据管道。监听该主题的在线节点订阅该消息,由此实现各个节点上规则脚本及任务的更新,无需登录或链接到各个客户端节点进行批量更新操作。
2.4 数据持久化存储
CPU、内存、网络等指标数据推送至消息管道后,后端数据处理组件订阅监控数据,一方面通过storm组件对各类数值型数据进行流式聚合,形成5 分钟、1 小时、1 天的多维度聚合数据;另一方面直接对原始数据进行告警规则过滤判断;最后,将原始数据、聚合数据、告警数据等信息写入相应的数据库。海量数据入库有可能出现资源抢占的情况,为保障数据的完整性,入库异常时数据将自动以字节方式快速缓存至本地文件,待入库恢复正常后,再从本地文件写入数据库持久化。
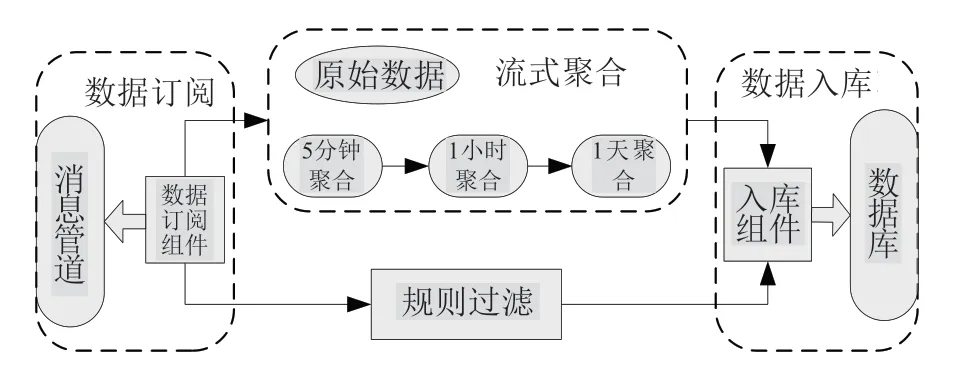
图4 数据处理流程Fig.4 Process of data processing
监控数据按照指标类型区分成如表1所示的10类主题,每一组中又含有多项具体指标,进行分组分类存储。

表1 监控指标分类Table 1 Classification of monitoring metrics
根据数据的特点和用途,采集到的数据分类存储至多个数据库中:负载状态数据存储于时序数据库;字符型日志数据存储于分布式数据库;资产信息、规则信息、告警信息等存储于关系型数据库。
同时,考虑海量数据搜索、展示等方面的压力,采用以下存储策略:
(1)聚合数据长期保存,保证历史数据延续性;原始数据则按照实际需求短期保存,过期自动清理,以充分利用存储空间,提高存储性能。
(2)频繁访问的近期数据放置在热数据区保证快速读取,较远历史数据存储在冷数据区,在大跨度查询历史数据时将有效提高系统响应速度。
2.5 告警管理
告警管理支持预定义和自定义两种告警规则。预定义告警由规则过滤组件定期从数据库同步阈值规则,在入库前数据处理组件将对默认采集的指标数据进行规则判断,当指标超出阈值范围时自动将异常信息转入到告警模块。自定义告警由运管人员根据实际需求编制规则脚本,通过监控管理端下发至选定节点,创建定时任务。如图5所示,系统周期地执行规则脚本,并简洁的以“0”或“1”表示是否为异常事件,同时按约定的Json 格式返回具体故障信息到消息管道。告警模块对返回的海量故障信息进行过滤、去重和合并压缩处理,降低告警风暴,方便运管人员准确、直观地收取告警信息。

图5 自定义告警流程Fig.5 Process of self-defined alarms
告警按紧急程度区分为以下3 个等级:
特大告警:用于对直接导致整个集群服务中断的故障告警,如:调度服务中断、LDAP 认证异常、子网管理中断、核心数据库无法使用、资源供给异常、关键节点宕机、登录服务异常等。该类告警一旦触发,将即时在24 小时监控大屏展示并发送告警邮件、微信或短信给管理人员。
重大告警:用于对虽然发生但集群仍然可以提供基本服务的故障告警,如:次关键节点运行状态异常、大规模存储设备部分异常、时间同步服务异常等。该类故障一旦触发,除系统展示外,将发送告警邮件给管理人员。
一般告警:用于对一般故障告警,如:单节点挂载、网络、负载、CPU 温度、加速卡等异常。该类告警的触发将直接在监控系统告警页面以列表形式展示,同时可按需配置邮件告警。
2.6 跨域数据对接
系统采用松散耦合的分布式架构横向扩展。集中管理系统与分域管理系统在物理上、逻辑上均采用分离设计,利用http协议实现两者之间的数据交换。分域管理系统紧邻计算集群部署,或直接部署于计算集群中,用于对集群内部的硬件运行状态、负载运行状态、日志信息、基础环境信息的收集和分析,并进行本地持久化存储和个性化展示,可自成体系工作。各分域关键状态数据经聚合、压缩后将通过标准的RESTful 接口实时传输至集中管理系统进行统一监控,缓解海量数据对系统展示及存储上压力过大的问题。
3 系统功能实现
3.1 开发工具
超大规模计算集群监控系统主要采用Java、go、shell 语言编程实现。后端基于MySQL、InfluxDB、Elasticsearch 等开源软件存储监控数据、资产信息。前端展示基于grafana 实现。采集端与持久化层数据的耦合基于轻量级的分布式消息中间件实现。不同组件之间通过RESTful 接口交换数据。
3.2 功能实现
超大规模计算集群监控系统实现了对集群内重要监控信息的准实时采集。针对单个服务/计算节点,采集CPU、内存、磁盘、网卡、GPU 等负载信息,messages、dmesg 等日志信息;针对网络设备采集各个端口当前配置状态/实际状态,端口流量、错包数/丢包数等信息。针对作业调度系统,采集当前运行作业数、排队作业数、成功/失败作业数等统计信息,解析了当前及历史作业的ID、提交用户、资源使用量、状态、执行节点等信息。
在展示上,实现了集群全局视角与单节点/子系统视角相结合,可对数据灵活检索、聚合、排序,且支持自定义的展示界面。整机视角以简洁、突出重点为原则,着重展示平均CPU 利用率、平均内存利用率、共享存储I/O 带宽及IOPS、整机作业成功/失败个数、重大告警等核心信息,如图6所示。单节点/子系统视角以详实直观为原则,除常用的负载信息,还提供中断占比、SWAP 利用率等展示,如图7所示,方便管理人员快速分析节点运行状态。
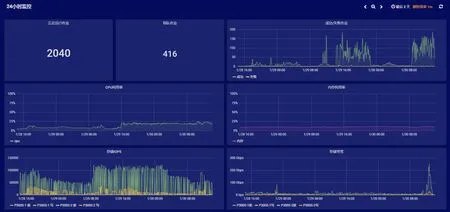
图6 整机7x24 小时监控展示Fig.6 Display for 7*24h monitoring of the total cluster
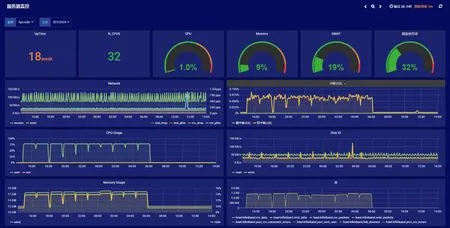
图7 单节点监控信息展示Fig.7 Display for monitoring of single node
故障管理实现了故障规则个性化设置、故障自动告警等功能。运维人员可根据应用需求编制个性化脚本、模块设置告警规则,自行定义检测指标、检测方式、执行节点、触发阈值、执行周期、告警级别、告警通知等参数,在系统的统一管理下自动运行、回收与展示结果,以满足不同业务、不同场景的监控需求,如图8所示。
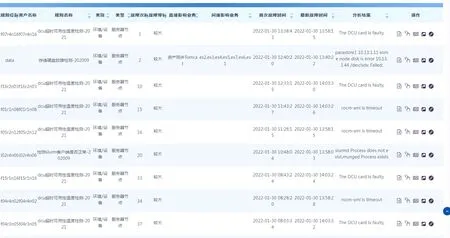
图8 故障告警信息列表Fig.8 Alarm information list
3.3 应用效果
超大规模计算集群监控系统已部署于中国科学院某超大型超级计算系统,以及“地球大数据科学工程”专用计算系统中。根据不同监控需求,以30秒/次或60 秒/次的采集频率,实现了对集群中全部节点、分布式存储、管理网络、高速计算网络等设备,以及集群调度服务、认证服务等核心组件和服务运行状态的监控。日均采集数据量208GB,累计解析作业信息674 万余条。在被监控节点和设备数上万的情况下,从成功采集数据到持久化存储或触发告警均在30s 内完成。在灵活的自定义采集和规则定制功能支持下,完成了运管人员关心的故障事件捕获和自动告警通知,特大告警事件捕获率达99.9%。同时,还实现了核心业务、资产信息、告警信息之间的关联展示,帮助运管人员快速定位故障,应用效果良好。
由于采用分布式消息中间件、流式数据处理、分布式数据库,以及组件式软件架构,监控系统具有良好的横向扩展能力。在多中心监控模式及必要的硬件支持下,可实现十万以上节点的统一监控。
4 小结
本文设计和实现了一种超大规模计算集群监控系统,通过自定义数据采集、消息中间件、分布式数据存储等方式,满足节点和设备数超过10,000 的超大规模计算集群的个性化、灵活监控需求。目前该系统部署于中国科学院某超大型超级计算系统和“地球大数据科学工程”专用计算系统中,运行良好,减轻了管理人员的运维强度。下一步,将基于已经采集和积累的集群状态数据、作业负载数据,尝试利用人工智能方法研发数据关联分析、故障自动诊断、运行趋势预测等智能化运行管理功能。
利益冲突声明
所有作者声明不存在利益冲突关系。
