基于长短时记忆网络的车削设备预测性维护
2023-03-03刘嘉煜夏晓毛宋予熙
刘嘉煜,夏晓毛,宋予熙
(博世汽车部件(长沙)有限公司,湖南 长沙 410100)
1 引言
随着工业4.0时代的到来,日益增长的对于质量和产量需求及更复杂的制造系统,使得现代制造业对加工设备的稳定性和可靠性的要求日趋严格。为了提升生产效率,减少制造成本,合理维修策略的制定及对于设备运行状态的实时把控尤为重要。
20世纪90年代开始,两种维修策略在实际生产过程中运用较为广泛,一种是修复性维护,也被称为故障驱动的维修,是一种在设备故障已经出现后进行维修的方式,这种方式可能导致生产过程中非计划性的停机;另一种是按照固定的时间周期性进行预防性维护,维修计划主要根据工程师的经验决定[1]。Nowlan和Heap提出,89%的航空设备故障不存在状态急剧恶化阶段,故障可能按照某种模式随机出现[2],所以基于时间的周期性维护可能由于维修计划制定不合理造成生产资源的浪费或导致设备在两次维护间隔之间损坏。近年来,基于设备状态的预测性维护[3]由于其在降低维修成本,减少故障停机时间和延长设备使用寿命方面的潜力,在制造业的应用逐步增加。
预测性维护实现的核心在于通过非破坏性的方式对设备运行过程中能够反映其健康状态的数据进行监控,并基于实时数据进行诊断性分析和预测性分析,辅助维修计划的制定。诊断性分析旨在对特定故障进行探测,并确定其产生的根本原因,而预测性分析主要基于当前数据和历史数据对未来设备的工作状况和剩余使用寿命(Remaining Useful Life,RUL)进行预测。
设备状态的分析可依据其故障过程的物理公式,也可由数据驱动,通过数据挖掘的手段对其状态进行识别。由于设备的复杂性逐渐提高,其状态衰退机制难以明确,物理模型在实际生产过程中的准确应用受到了限制,因此,在先进的传感器技术和提升的计算机算力的帮助下,数据驱动下,运用传统机器学习和深度学习方法的预测性分析模式逐渐占据主要地位。
在基于传统机器学习方法的预测性分析模式中,对采集的数据进行特征提取并进行特征筛选得到设备状态的特征表示,这些特征被送入后续模型,如逻辑回归,决策树、支持向量机等,用于模型的训练。训练好的模型最后将用于设备健康状态预测。然而特征工程的好坏对模型的表现起到关键作用,这一过程需要较丰富的领域知识,数据预处理和不完全的特征提取可能导致原始数据中能够反映设备状态的信息丢失。
近年来,日益蓬勃发展的深度学习网络,如在自然语言处理(Natural Language Processing,NLP),图像描述等方面起重要作用的循环神经网络(Recurrent Neural Networks,RNN),为本质为时间序列的产线传感器采集信号的表征提供了新思路。这些方法直接通过深度神经网络从原始的时域信号中自适应地提取设备状态特征表示,无需额外的领域知识,可端到端地实现设备故障的预测。
为解决传统RNN梯度消失和梯度爆炸问题提出的长短时记忆网络(Long Short-Term Memory,LSTM)中引入了门的操作,其对于历史信息的记忆能力使其在捕捉传感器数据中的时序信息方面更具优势。Zhao R[4]等发现使用基于LSTM的网络可以获取传感器信号中的有效特征,并在刀具磨损预测任务上进行了验证。Zhao R[5]认为,除了时间上的信息外,不同维度传感器数据之间包含的空间关系和数据中的噪音会使得仅仅使用LSTM变得不够鲁棒,所以选择采取先使用卷积神经网络(Convolutional Neural Networks,CNN)提取局部特征。文献[6]中结合使用LSTM和CNN对原始信号进行特征提取后送入回归层,实现对刀具后刀面磨损值的预测。
常用的非破坏性设备状态监测方式包括采集声信号、红外信号及振动信号等[7],在Mourbray提出的P-F曲线中,振动信号能够以相对较早的提前量帮助识别设备的潜在故障[8],文献[9]中利用振动信号分别对设备的磨损,故障及剩余使用寿命进行了预测。同时考虑到实际生产环境中的噪声影响,传感器的成本及安装的难易程度,本文中选择采用振动信号进行设备故障的探测。
本文通过在车削机台刀杆上加装加速度传感器,以26 000 Hz的频率采集x,y,z三个方向的振动信号。利用车削机台不同的故障状态下,产品加工过程中的数据进行基于特征提取的机器学习模型和长短时记忆网络的训练,实现在真实生产环境下对机台的不同故障类别的实时探测。
2 模型构建
2.1 特征筛选
由于传统机器学习模型对于特征工程的要求较高,为提高模型的拟合准确度,首先要对特征值进行筛选,去除无关冗余特征。本文基于Fisher Score进行关键特征的选取,其主要思想为对不同类别区分能力较强的特征应该具有类内方差较小,而类间方差较大的特点[10]。记总样本数为n,第i类样本数为ni,i∈[1,...C],C为样本类别总数,第i类样本集为ωi,x(k)表示样本x在特征k上的取值, 表示第i类样本特征k取值的均值,
表示所有样本特征k取值的均值。则特征k的类间方差
类内方差
特征k在数据集上的Fisher Score
Fisher Score越大,则特征对于不同类别的区分能力越强。通过保留Fisher Score较大的特征进行特征筛选。
2.2 LSTM
LSTM是一种特殊的循环神经网络,通过不同的门结构来控制信息的传递。通过细胞状态的使用,使得模型对不同时间间隔前后的数据具有记忆功能。这一点为在时间上具有明显依赖性的设备状态监控提供了有力的帮助。
式中,i t为输入门,f t为遗忘门,o t为输出门,⊙表示逐元素相乘,σ(·)表示sigmoid激活函数。参数W f、为隐藏层神经元个数)、U f、和通过模型学习得到,且在所有时刻取相同值。
LSTM层最后时刻的输出 作为样本xi的特征表示,通过全连接层和softmax层预测得到不同类别的概率softmax的计算公式为
为使得模型学习到不同时间维度信息,通过堆叠多个非线性LSTM层的方式得到深层LSTM,模型隐层的输出在时间方向传递的同时也作为下一LSTM层的输入。在仅考虑过去时间步长信息的LSTM的基础上提出的双向长短时记忆网络,由于其信息流可双向传递的特点,为模型同时考虑过去与未来信息的影响提供了一种可行方式。
由于模型结构复杂,参数量巨大,而实际生产过程中可获取的样本量较小,为了避免模型过拟合,通过在全连接层之前引入dropout层的方式,在训练过程中随机隐藏部分隐层输出,对模型进行正则化。
2.3 深度学习模型训练
对于深度学习模型,为获取最优权重,模型训练过程中,通过最小化损失函数交叉熵(Cross Entropy,CE),使用Adam进行模型权重的更新,并使用阶梯式的方式调整训练过程的学习率。交叉熵的计算公式为
3 实验验证
3.1 数据描述
为对比基于特征提取与传统机器学习算法的模型和深度学习模型对真实生产环境下运行设备的故障探测能力,本文通过在不同时间段进行的两次实验,分别采集了车削机台在两种不同故障状态及正常状态下的产品加工过程中的振动数据,其中,第一次实验的数据用作训练集,第二次实验数据用作测试集,故障状态及训练集与测试集划分见表1。振动数据来源于车削机台刀杆上安装的加速度传感器,传感器以26 000Hz的频率采集产品加工过程中x,y,z三个方向振动数据。

表1 数据集描述
3.2 实验设计
对于本文研究的车削工艺,一片产品的加工过程大致可分为进刀段、粗车段、精车段与退刀段,其x轴方向的振动信号如图1所示。由于进刀与退刀段的过程表现受周围环境影响较大,故本文中仅提取与当前工序状态相关性较强的粗车段与精车段数据进行后续的分析。同时,为消除加工不同型号产品引入的振动强度差异,将x,y,z轴数据处理为对于三轴总振幅的相对值。在数据预处理后,对表2所示模型进行了训练。
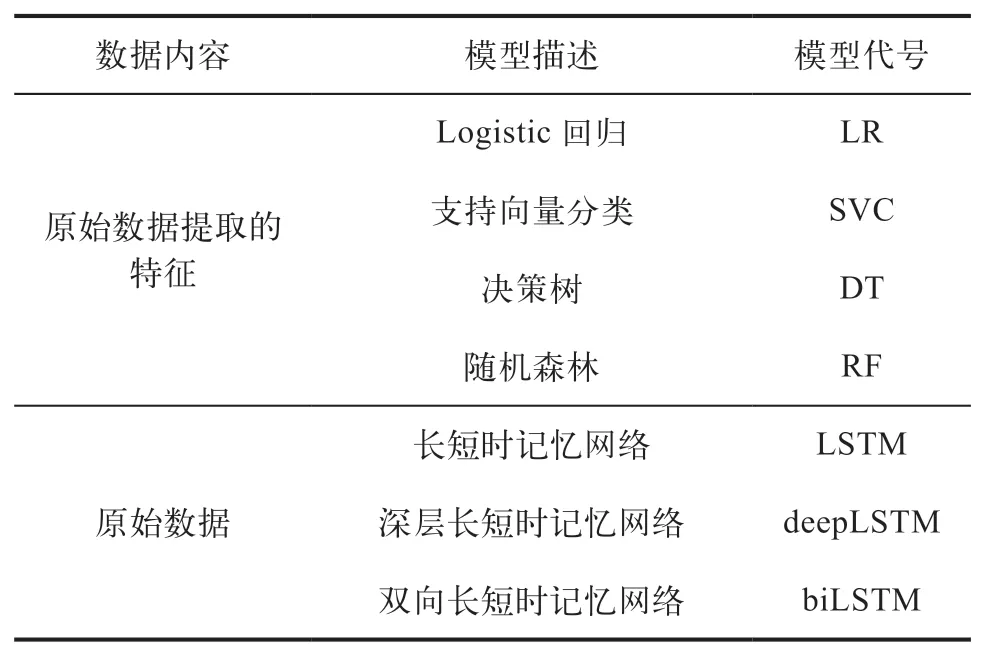
表2 模型及训练数据描述
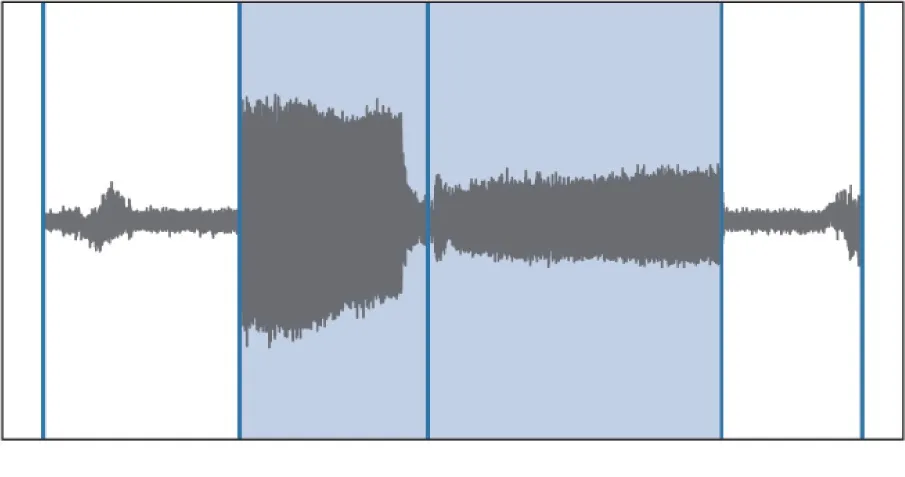
图1 产品加工过程中的x轴方向振动数据及加工阶段划分
对于传统机器学习模型LR,SVC,DT和RF,首先对x,y,z三个方向振动数据提取时域、频域、时-频域特征。样本数据记为样本数据的快速傅里叶变换,结果记为p(f),短时傅里叶变换,结果记为S(t,f),HHT(Hilbert-Huang Transform,希尔伯特黄变换)后得到的解析信号的实部与虚部分别记为a(t)与b(t)。其中,对于频谱偏度取均值,最大值对应频率及过95%置信区间的点个数作为特征值;频段的划分取用0Hz,
3 500Hz,5 000Hz,65 00Hz,8 000Hz,9 500Hz,11 000Hz,26 000Hz,HHT作用于经验模态分解处理后得到的1~10层本征模态函数。由此,每个产品数据由264维特征向量表征,经特征筛选降维处理后,用于上述四类模型的训练。对于SVC、DT和RF,模型超参数的选择采用在训练集上进行5折交叉验证,最大化加权f1 score的方法。
对于可直接处理时序数据的LSTM模型,为减少采样过程中引入的随机性[11],以100个样本点为一组,对粗车段和精车段不同轴信号分别求取均值、标准差、最大值和最小值,保留100个时间步长,每个时间步长由32维向量构成。由于原始数据样本量较小而模型结构相对复杂,为防止过拟合的情况发生,对于每个产品的数据,通过随机截断的方式,生成1 000个样本,经过二次采样处理的训练集大小扩充为278 000。所用模型结构见表3和表4,对每种结构的模型分别尝试了单向与双向传递的网络。最后的输出均接入节点个数为3的全连接层和softmax层,得到不同类别的概率。
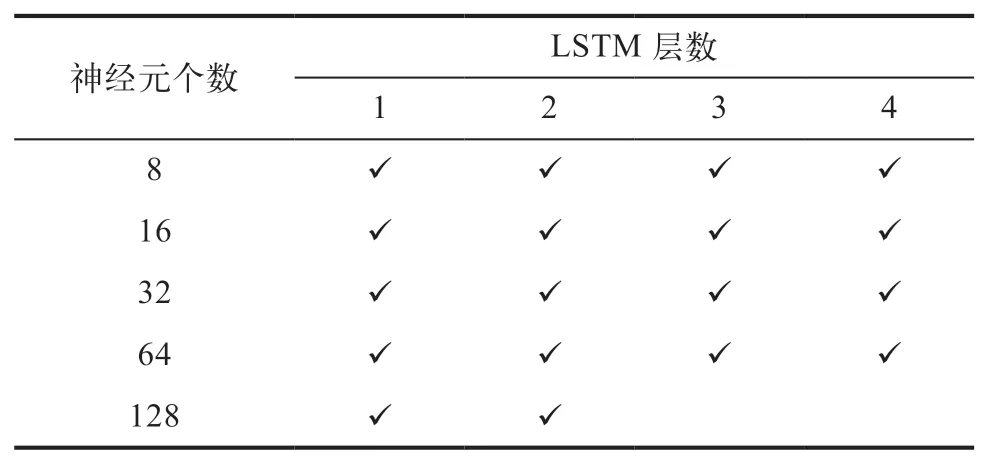
表3 隐藏层神经元个数相同的LSTM模型结构

表4 隐藏层神经元个数不同的LSTM模型结构
最终模型的表现使用加权精确率(precision),召回率(recall)和f1 score来衡量。对于每种机台状态类别i,其样本个数记为则对于类别i
式中,M代表混淆矩阵,M[i,j]为真实值为i,预测值为j的样本个数。模型总体的加权准确率、精确率、召回率和f1 score为
3.3 实验结果分析
不同模型在测试集上的加权平均精确率、召回率与f1 score,以及其分类结果的混淆矩阵见表5和如图2所示,其中LSTM(128)代表神经元个数为128的单层单向LSTM网络,deepLSTM(8-8-8)代表每层神经元个数均为8的三层单向LSTM网络,biLSTM(8-8-8)代表每层神经元个数均为8的三层双向LSTM网络。在Logistic回归、支持向量机、决策树与随机森林中,随机森林取得最高的精确率、召回率与f1 score,但其倾向于将设备正常状态误判为故障状态。在不同结构的LSTM模型中,3层隐藏层,每层8个神经元的结构取得了最好的表现,在测试集上的f1 score为0.875。导致人工构造特征进行训练的传统机器学习模型表现整体劣于不同结构的LSTM模型的原因,一方面可能在于模型拟合能力的限制,无法捕捉不同工况下采集的振动模式的差异,另一方面可能在于人为构造特征导致的有效信息丢失。

图2 不同模型预测结果的混淆矩阵
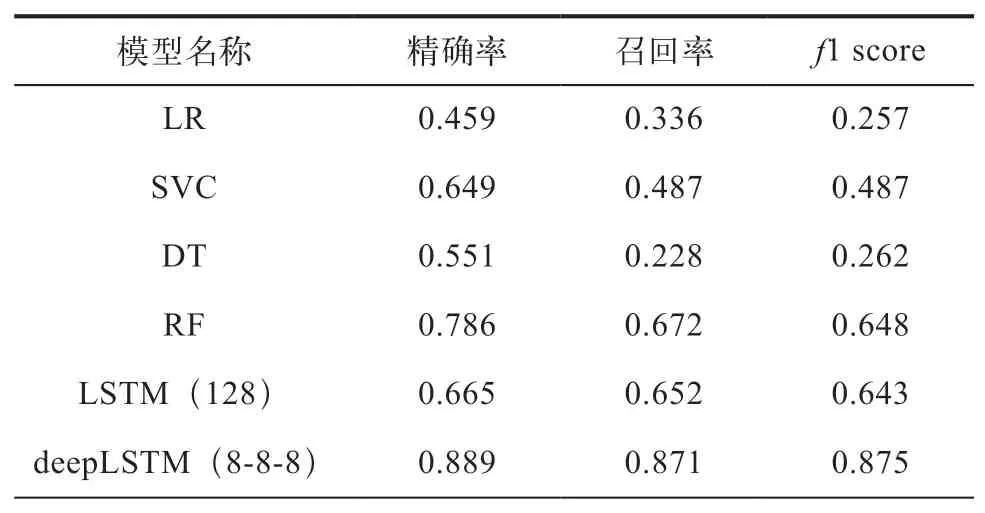
表5 不同类别模型表现对比

(续)
图3和表6对比了使用不同LSTM模型结构得到的f1 score。在所有本文中尝试的结构中,每层神经元个数均为8的三层单向LSTM网络得到了最高的预测准确度。其中对于单向传递的LSTM,当每层神经元个数均为8或16时,隐层从一层到三层,模型的预测准确度逐步提高,但四层模型的表现劣于一层。当模型层数为2,3,4层时,双向LSTM的准确度反而低于单向LSTM。对于三层LSTM,隐藏层使用相同神经元个数的模型预测能力优于每层使用不同神经元个数的模型。
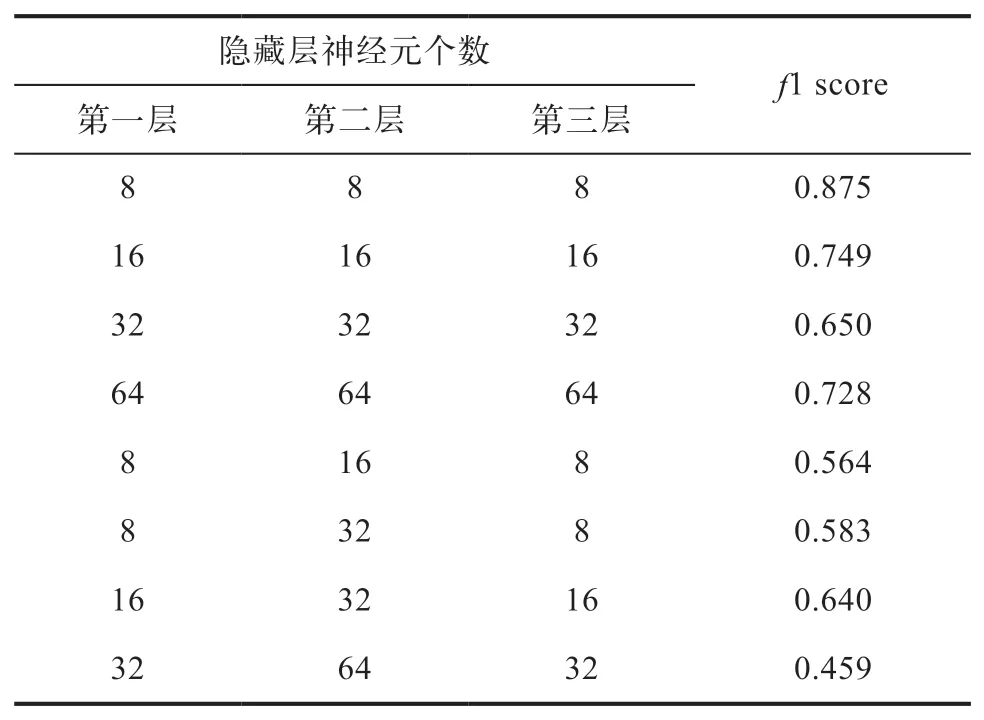
表6 不同神经元个数的3层LSTM准确度对比
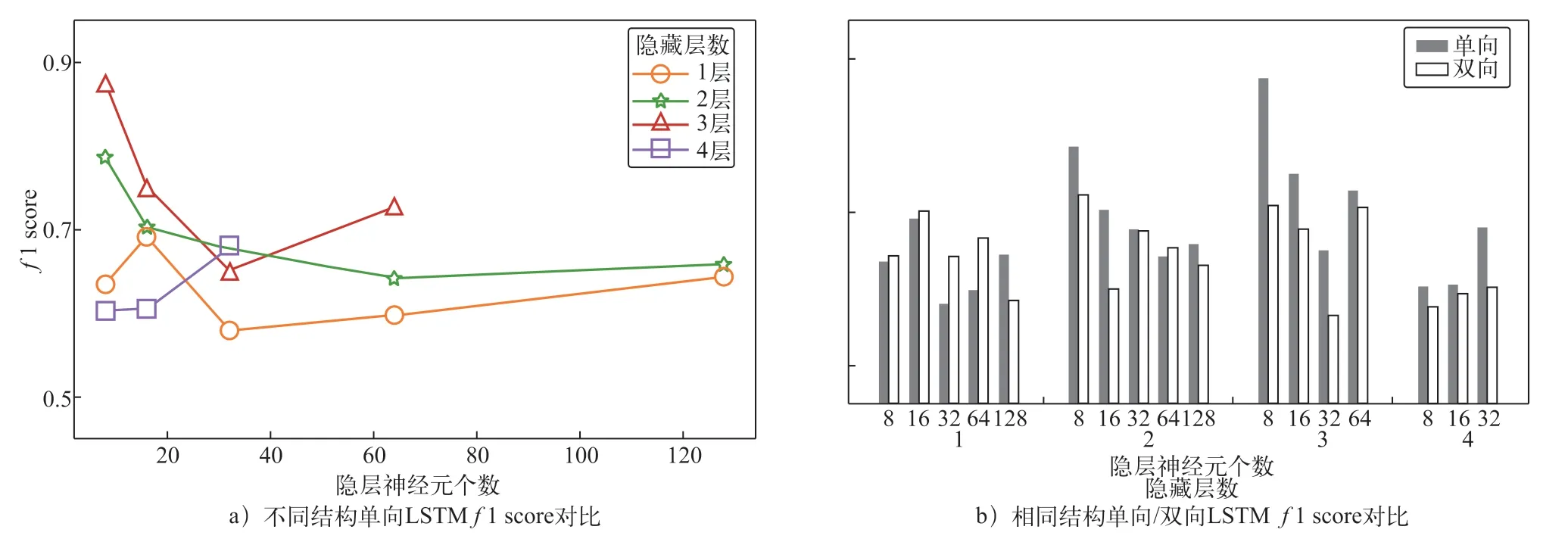
图3 不同LSTM模型结构预测结果的f1 score
4 结束语
本文使用产品加工过程中的振动数据,尝试对车削机台的两种常见故障进行预测,以实现生产过程中的预测性维护功能。在综合对比了Logistic回归、支持向量机、决策树及随机森林等使用数字信号处理方法所提取特征进行训练的传统机器学习模型,与不同结构的使用原始数据进行训练的LSTM在不同时间段采集的生产数据上的预测表现后得出,能有效捕获时序信息的深度学习网络LSTM,对车削机台故障预测的能力整体高于传统机器学习模型,最高的准确率可达87.5%。
为提高预测结果的准确度,多源异质数据融合已成为设备健康度监测的主要趋势。由于本文中仅考虑振动数据,后续工作中会结合更多数据源,如伺服电机数据及外部环境温度数据等,向更多类别的故障预测方向进行探索。
