基于生成对抗模型及光路分解的全局光照绘制
2023-02-28王妮婷王静雯欧阳娇
梁 晓,王妮婷,王静雯,欧阳娇
西南石油大学 计算机科学学院,成都 610500
全局光照(global illumination,GI)绘制是计算机图形学的重要研究问题之一。经典的全局光照绘制采用物理模拟的方法,对场景中的三维几何、表面材质、光源、摄像机等建立具有物理真实度的模型,并模拟光照传输过程,最终捕获经多次反射、折射后进入视点的光能。由于能够产生照片级真实感图片,该方法广泛用于动画与电影特效制作、视觉设计、数字娱乐领域。然而,物理绘制计算开销昂贵。以蒙特卡洛路径跟踪算法[1]为例,需要在每个像素投射至少上万条光线用于跟踪模拟,才能获得一幅近似收敛的绘制结果,这使得绘制的时间开销高达数十秒;而一旦减少跟踪光线的数目,将产生大量噪点,极大降低了视觉感受。因此,在保持画面真实感的前提下,减小绘制计算代价,是目前全局光照绘制的主要挑战。
近年来,卷积神经网络(convolutional neural networks,CNN)[2]以及生成对抗网络(generative adversarial network,GAN)[3]作为图像生成模型,在图像降噪、高分辨率图像生成、语义识别等领域获得了广泛关注和巨大成功。其核心是,在大量的观察样例中理解图像先验,隐式地学习真实数据分布模型并用于生成图像。受此启发,研究者们提出基于神经网络的全局光照图像降噪重建[4-6]。但是,降噪重建方法需要物理绘制产生噪声图像作为重建基础,具有不可忽略的计算成本和开销。并且降噪网络始终受到输入图像噪声水平的限制,一旦输入的SPP过低,重建质量将急剧下降。
图像生成的核心之一是学习图像的隐式表示[7]。然而,自然图像与全局光照图像所蕴含的特征不同,前者侧重呈现各类纹理,而后者对用户视觉感知贡献最强烈部分是光照与材质的交互,如全局漫反射、镜面反射、高光等。因此,两类图像具有不同的结构,其隐式表示及学习方法也应该有差异。若能抽象地建立光照传输及其与材质交互行为的表示,并编码到网络模型中,可避免代价昂贵的光照物理建模和计算过程。然而,光路传输行为极为复杂,光能在最终映入视点前会与场景连续地产生多次漫反射、镜面反射,在两类反射作用下新产生的光的强度、方向、颜色等具有不同的物理描述,这使得使用单一的模型难以有效表达全局光照。
为此,本文提出一种新的基于生成对抗模型和光路分解的全局光照深度绘制网络,将全局光照分解为镜面反射和漫反射两部分,分别设计自编码器GAN 独立地学习和推理各路光照,最后合成最终图像。根据不同光照分支的特性,选择特定、高相关性、计算廉价的图形辅助属性为主要输入,避免以物理绘制生成的噪声全局光照图像为输入,计算成本更小,且训练过程更高效、更有针对性。考虑到镜面反射光照生成中受非局部区域特征影响的特点,设计多尺度融合模块以在更大的感受野中自适应地提取有效特征。同时,使用混合损失函数稳定地生成图像。通过广泛的实验证明,本文框架与设计选择能够有效地保留全局光照图像中更多的高频细节。
1 相关工作
物理绘制包括了蒙特卡洛路径跟踪[1]、辐射度算法[8]及光子映射[9]等成熟的绘制框架,能够产生各类光照逼真的图像,但昂贵的计算开销始终是瓶颈。近年来,使用基于图像空间降噪和图像生成模型来重建全局光照图像的工作得到了大量关注和发展,本节分别介绍这两方面内容。
1.1 基于图像空间的降噪
图像空间降噪的基本原理是,对像素间的距离建立某种模型,搜索结构相似的像素值来恢复损失像素。传统图像过滤方法有双边滤波[10]、非局部均值滤波[11]、BM3D以及基于直方图的度量距离的降噪[12]等。随后,研究者提出了一阶、高阶等线性和非线性降噪方法。He等人[13]提出引导图滤波方法,假设像素与辅助图像具有线性关系,并使用边缘特征图引导过滤噪声图像,有效地避免了边缘模糊问题。受此启发,Bauszat等人[14]用具有几何结构的法线图作为引导,过滤间接全局光照图。Bitterli等人[15]提出非线性局部加权回归重构图像,提高了图像质量但增加了计算复杂性。
近年来,数据驱动的绘制得到了快速发展,研究者提出了基于神经网络的全局光照图像降噪重建。Kalantari等人[16]首次使用具有三层感知机的神经网络生成过滤核参数。Bako 等人[5]使用卷积神经网络KPCN(kernelprediction convolutional network)产生镜面反射和漫反射的自适应过滤核,再用于全局光照噪声图像的过滤,产生了逼真结果。Vogels 等人[17]在Bake 等人研究的基础上增加了时域特征提取模块和一系列非对称损失函数。Chaitanya 等人[4]提出一种交互式全局光照降噪网络RNN-AEMC,在自编码网络中嵌入RNN(recurrent neural network)[18]模块来平滑帧间不稳定性,最终以交互式帧率产生平滑的图像序列。
本文与降噪方法不同之处在于,本文方法不再以基于物理绘制的带噪全局光照图像为输入,而是通过学习光照传输表示来重建图像,使得网络不再受图像噪声水平的限制,影响重建质量。
1.2 图像生成模型
Goodfellow 等人提出生成对抗网络(GAN)[3]。其中,生成网络尽量学习真实数据分布以生成能欺骗判别网络的数据,判别网络则尽量正确地判别输入数据是来自真实数据还是生成数据。通过极大极小博弈,GAN在图像生成领域取得了瞩目的成果。
原始GAN 从噪声中生成图像,用户无法有效控制输出。为进一步约束生成内容,条件GAN 引入条件变量使生成网络的表现能力得到增强。Isola 等人[19]提出一种条件生成式对抗网络Pix2Pix,通过在判别网络添加额外限制(例如物体轮廓)作为图像生成的重要条件。Wang 等人[20]在此基础上提出一种coarse-to-fine 生成网络以及多尺度的判别网络来有条件地输出高分辨率图像。
近来,学习场景的抽象表示来生成渲染图像成为新的关键技术点。刘晓芸等人[21]采用径向基函数(radial basis function,RBF)神经网络拟合视点位置、光源位置和物体表面法线等与间接光照之间的非线性关系,避免了光线的多次求交,但无法有效重建复杂的渲染场景。Granskog等人[22]分解光照、材质和几何信息用于场景表示,以多角度观察图像为辅助,将G-buffer 属性转换为具有高光和反射的渲染结果。但该方法需要保证分解后各分量的正交性,实现难度较大。
2 本文方法
2.1 算法框架
如图1(a)所示,基于生成对抗模型和光路分解的全局光照绘制网络(简记为LD-GIGAN),包括生成网络和判别网络两部分。生成网络包含两个独立的自编码网络,分别是漫反射绘制网络Gdiff和镜面反射绘制网络Gspec。由于漫反射和镜面反射光照成因不同,两个网络具有不同的输入。具体是:漫反射光照主要表现纹理细节、颜色等,将法线、深度和反照率拼接为每像素7通道的输入,其中深度为1通道。镜面反射与材质反射属性高度相关,产生的光照依赖于视点,因此以法线、视点、深度、镜面反射纹理、粗糙度和视锥体外几何感知图(geometric perception map,GPM)等作为输入,共12 通道,其中深度、粗糙度和感知图均为1通道。
判别网络用于判断生成网络产生的是否为真实图像。与文献[23]类似,将生成图像旋转多个角度以产生增强的配对数据后再送入网络判别真假,如图1(b)。面对多样化的样本分布,通过增加同一分布样本数据,有助于促进网络学习到更稳定的结果。

图1 本文全局光照绘制框架概览Fig.1 Overview of global illumination rendering framework
最终,将两个分支网络的生成图像通过逐像素乘法和逐像素加法合成全局光照效果图。下面将详细地介绍光路分解方法、全局光照绘制网络的具体实现以及损失函数的组成。
2.2 光路分解
研究者提出了不同的光路分解方法。图像处理领域常利用本征图像分解,将图像分为反射图和光照图[24-25]。Bauszat等人[14]将全局光照图像分解为直接光照和间接光照,对间接光照进行过滤重建。该方法主要恢复粗糙表面的光照反射,并未考虑光泽材质。曹天池等人[26]则基于像素聚类方法将图像分解为漫反射和镜面反射,结合场景深度进行光照估算,但对于高光像素较多、整体较亮的场景难以获得准确的分解结果。本文使用与文献[5,27]类似的光路分解思路,分为漫反射和镜面反射两部分。但是在真实渲染场景中,由于渲染方程的递归性质,光路组合十分复杂,将镜面反射和漫反射的计算完全分离是十分困难的。权衡计算开销和实验效果,本文仅实现主光线的最近击中点的镜面反射和漫反射光照的分离。
进一步地,考虑到漫反射光照中纹理和光照在结构、频率分布方面具有不同特征,将这部分再分解为辐照度(irradiance)和反照率(albedo)。光路分解及图像融合如式(1)所示:
其中,albedodiff为漫反射反照率,为漫反射辐照度和镜面反射分量。
2.3 全局光照绘制网络
2.3.1 生成网络
由于输入与输出具有较大的数据分布差异,若使用CNN 会由于网络容量过大难以实现有效映射[28]。而图像本身是低维流形在高维空间的表达,自编码器善于将高维数据映射到低维空间,同时保留数据的显著特征,能更有效地实现抽象特征之间的映射关系。本文以自编码网络为基础,每个网络均包括编码、特征映射和解码3 个阶段,由于光照生成的差异,在编码阶段采用了不同的设计。
(1)漫反射绘制网络
编码器阶段:包括4层编码,每层对特征图经过2次连续的非线性变换后,再进行下采样处理。在该阶段,编码深度每增加1,特征图的空间分辨率减小50%,但特征个数成倍增加。这样设计的目的是保留空间上的重要特征,同时产生有效的高层语义特征。
特征映射阶段:该阶段使用卷积层对高层语义特征进行连续的非线性变换,以学习复杂的隐式光照传输表示。
带跳跃连接的解码器阶段:包含与编码器阶段对应的层数。每层对特征图进行上采样以及连续的非线性变换,以实现逐层的特征映射和图像还原。由于下采样会产生大量信息损失,若直接在有损信息上进行上采样,容易导致模糊的合成图像。为此,使用跳跃连接[29]将编码阶段对应层的特征级联到解码器阶段对应层作为信息补充,之后再对融合的特征进行解码。
(2)镜面反射绘制网络
当场景中存在大量粗糙度低的材质,会产生高光、二次反射等大量的镜面反射光照。相比于平缓的漫反射光照,镜面反射受到入射光照、BRDF反射模型、视点等多种因素的影响,因此镜面反射自编码器相较于漫反射网络,在输入数据和编码阶段有自己独特的设计。
首先,二次反射的成像受到视锥体内以及视锥体外的物体所反射的光照影响,而G-Buffer辅助属性只能提供视锥体内信息,若不能在输入提供足够的场景信息会导致网络产生不合理的光照。为此,本文采用一种视锥体外几何感知图(GPM)作为网络辅助输入,引导模型感知视觉锥体外的场景,以推理产生合理的光照图。GPM 是灰度图,每个像素编码了视锥体外物体与视锥体内可见物体之间归一化的欧式距离,其产生过程是:从视点位置向3D场景发射一条虚拟光线r,r穿过的屏幕像素记为P。若r与物体相交,交点为可见点并记为M,继续从点M引出镜面反射光线r′;若r′与物体相交,记交点为N,将MN的欧式距离记为点P的GPM值。扫描完所有屏幕像素后,将所有非0距离归一化到0 到1 范围内,从而产生GPM 灰度图。若视点发生变化,同一可见点对应的N点也会改变,需要提供新的GPM。以上信息获取方便,并且能够确保提供正确的场景感知信息,这对产生合理的光照非常重要。虽然降噪网络不需要采集此类信息,但需要使用物理绘制引擎产生噪声图像。与其相比,本方法的输入计算代价更小。
其次,镜面反射光照需要提取不同尺度感受野下的特征,以获得空间上更全局的结构信息;而传统卷积层仅能产生单一感受野范围的特征。为此在编码器采用一种多尺度特征融合模块(multi-scale feature fusion block,MSFFB),如图2(a)所示。即在编码阶段的每一层中,同时使用两种尺度为3×3和5×5的卷积核,再使用concatenate操作来融合不同尺度特征,之后级联到解码阶段对应层。
2.3.2 判别网络
判别网络是一个典型的卷积神经网络,如图2(b)所示,由连续的卷积层组成,卷积核为3×3,每个卷积层接Leaky ReLU 函数和Batch Normalization;卷积核数目在步长为1 和步长为2 的卷积后成倍增加;网络最后为一个一维、sigmoid 激活的全连接层。在传统判别网络基础上,本文增加了特征损失以及旋转损失。

图2 全局光照绘制网络结构Fig.2 Global illumination rendering network structure
2.3.3 损失函数
图像质量的判别取决人类视觉系统,使用单一的距离函数难以有效地描述预测图与参考图之间的差异。大量文献[19,30]表明,单纯使用L1或L2损失容易产生模糊的重建图像。因此,本文利用判别网络并扩展标准对抗损失函数来学习隐式的距离模型,以促进图像重建的质量。如式(2)所示,共使用像素级损失Lpixel、特征损失Lfeat以及旋转损失Lrotation三种函数对最优化目标进行自适应、多角度的约束,后两者均为对抗损失函数。
其中,γ1、γ2和γ3为超参数。
(1)像素级损失
使用L1损失来描述预测图与参考图之间的逐像素差异,相对于L2损失,L1损失对异常值更稳定。若用y表示参考图,Lpixel可表示为:
(2)增强的对抗损失
首先,为弥补像素级损失的不足,使用特征损失在多个抽象层描述预测图与目标图之间的差异。具体是,利用判别网络的特征提取功能产生预测图和目标图在多个中间层的抽象表示,并用L1距离来描述两者之间的差异。该损失可描述为:
其中,D为判别网络,Dj为网络的第j层特征提取结果,Cj、Hj和Wj为第j层特征表示的通道数、高度和宽度,βj为第j层特征的比例系数。这种损失描述了预测图与目标图在多个层次抽象表示的差异,能够促进生成网络在多个尺度上生成更符合目标的统计数据,进而产生逼真图像。
其次,为增加判别网络的稳定性,将预测图和目标图旋转多个角度产生扩展的真假图像配对,送入判别网络。旋转角度集合用Rot表示,Rot={0°,90°,180°,270°},每个旋转角度下真假图像配对将产生一个旋转损失,4个损失的总和为最终旋转损失,可描述为:
3 实验结果与分析
为了验证方法的有效性和合理性,进行了如下实验。首先,将本文方法与基线网络进行比较。其次,分别从光路分离方法、网络收敛性以及混合的损失函数等方面来验证网络结构的有效性。最后,分析方法局限性。
3.1 数据集及实现细节
3.1.1 数据集
基于数据驱动的绘制网络需要大量的训练数据来提取合成时所需特征,同时避免过拟合。本文使用Bistro[31]、Sun Temple[32]、Zero Day[33]等NVIDIA ORCA 三维室内场景作为主要的三维场景,此外,还包括Pink Room、Sponza、Living Room 等常用的图形虚拟场景。这些场景具有丰富的光照条件、不同的表面材质和各类几何形状,极具代表性。
数据集产生的方法如下:使用基于DirectX Raytracing(DXR)的路径跟踪方法漫游场景,每隔一定时间步长保存<图形辅助属性集合,漫反射目标图像,镜面反射目标图像,视锥体外几何感知图>数据对,最终共产生6 000对数据集,其中5 400 个数据对用于模型训练,600 对用于模型验证。所有图像分辨率均为512×512。根据场景不同,目标图像采样率为10~30 kHz。其中,图形辅助属性集合直接从G-Buffer中提取,包含法线、深度、反照率、视点、粗糙度和镜面反射纹理。为了降低走样的输入对合成效果的影响,图形辅助属性集合中的所有数据都进行8倍MSAA反走样处理。
3.1.2 实现细节
本文使用Tensorflow 2.0 来实现网络,运行平台的GPU 为NVIDIA TITAN Xp,显存12 GB。生成网络在Bottleneck block 中添加标准的高斯噪声,增加随机性。同时在encoder 编码网络使用Batch Normalization层稳定训练,使用Leaky ReLU 激活函数(参数为0.2),仅最后一层卷积层使用tanh 激活函数。总损失函数的三个超参数γ1、γ2和γ3之比为2∶5∶100。在特征损失上选择第2、4、6层产生最终特征损失,并将对应的超参数βi设置为1.5,1,1。漫反射和镜面反射分支网络均使用相同的判别网络结构,但各自独立训练。训练时使用自适应的Adam 算法[34],初始学习率为2E-4,衰减率分别为0.9和0.99,批处理大小为4。每个分支在单块TITAN Xp的GPU上训练花费约12 h。
3.2 图像重建质量与网络性能评估
为评估图像重建质量,与降噪网络KPCN[5]和三种图像生成网络Pix2Pix[19]、RBFNet[21]、UnetGAN[20]进行对比。其中,KPCN 采用光路分离的双分支CNN,分别独立推理漫反射和镜面反射的过滤核参数,再使用学习到的过滤核对含有噪声的全局光照图像进行降噪。Pix2Pix是以条件GAN为基础的单分支网络,使用法线、镜面反射纹理等作为条件,端到端地合成图像。RBFNet 方法中,使用经典的光线跟踪算法计算直接光照,训练有监督的RBF网络获得间接光照的拟合函数。UnetGAN以Res-Unet作为生成器,合成高分辨率真实感图像。
主观感知和客观指标对比如图3、表1 所示。由实验结果数据可知,本文在主观感知和客观指标上明显优于以上三种图像生成方法,也表明在网络架构、损失函数等方面增加约束,能够有效地避免伪影图像的产生,提高图像质量。Pix2Pix 更倾向于生成平滑的几何形状,对镜面反射重建几乎是无效的。UnetGAN 具有复杂的损失函数作为约束,其重建效果较Pix2Pix 更为清晰。RBFNet 网络受聚类中心选择的影响,在复杂场景下,拟合函数对场景间接光照的表达能力有限,其能一定程度地重建高光轮廓,但对镜面反射成像细节的呈现能力相对较弱。

图3 与基线网络对比Fig.3 Comparison with baseline networks
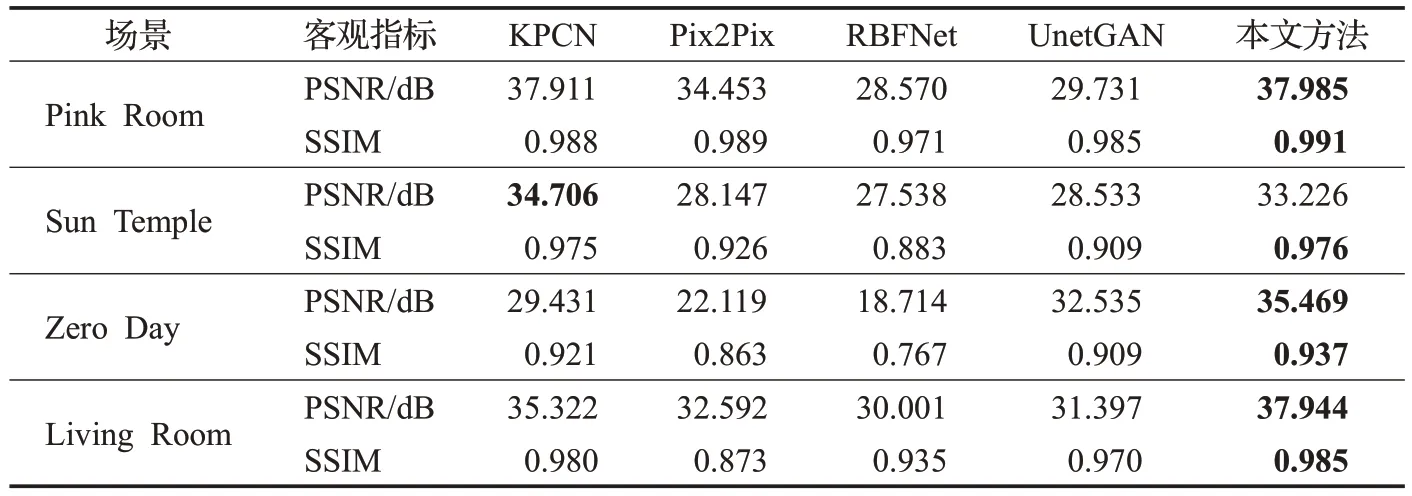
表1 图像质量的客观指标对比Table 1 Comparison of objective indicators of image quality
与同样基于光路分离的KPCN方法相比,即使缺少了带噪声的全局光照绘制结果作为引导,本文仍然能够产生与之可比较的、甚至大多数更优的光照图像。例如,对于Zero Day场景,本文在两个角度的绘制效果明显更优。再如,Pink Room场景中红色球体表面的各种反射结构更明晰,而KPCN存在杂色且结构并不十分规则。以上数据说明,以GPM作为引导图,学习光照表示的方法能够高质量地产生复杂的光照效果。
在网络性能上,对512×512 分辨率的图像,物理绘制时间约是1 min,KPCN、Pix2Pix、RBFNet、UnetGAN以及本文方法的预测时间分别是150 ms(每个分支约75 ms)、40 ms、69 ms、64 ms和96 ms(每个分支约48 ms)。本文方法和同为基于光路分解的KPCN 方法结果相近甚至更好,但由于不用对每个输入求梯度方差,本文方法花费的预处理时间更少。其余三种方法虽推理时间相对较少,但客观指标和图像重建质量都明显低于本文方法。因此,在质量和性能上进行权衡,本文方法优于对比方法。
3.3 网络结构有效性评估
3.3.1 光路分解方法
为验证光路分解网络结构的有效性,将与无光路分解网络对比重建质量,并将后者简记为nonLD-GIGAN,如图4 所示。nonLD-GIGAN 的实现方式为:保留本文模型的漫反射自编码网络,采用与本文方法相同的输入、学习率等。同时,为了保证公平性,减少两者网络容量的差异,增加了网络层数和卷积核数。
由图4 可知,本文方法能产生更逼真的高频光照,如Pink Room 场景中茶几、花瓶具有清晰的几何结构,而对比方法的重建结果较模糊。同时,本文的重建结果具有更丰富的明暗变化,而不进行光路分解的方法丢失了较多反射信息,如Sun Temple 场景对墙上反射的光照的刻画。
产生以上差异的原因是,受到网络容量、网络架构、数据等限制,nonLD-GIGAN 难以学习到复杂的光照传输表示。而本文将不同结构性的光照进行独立地推理,本质上是在求解空间增加了约束,进一步避免了二义性,能有效地提高图像质量,加快网络收敛。图5 是本文与无光照分离的nonLD-GIGAN在网络收敛性方面的比较。
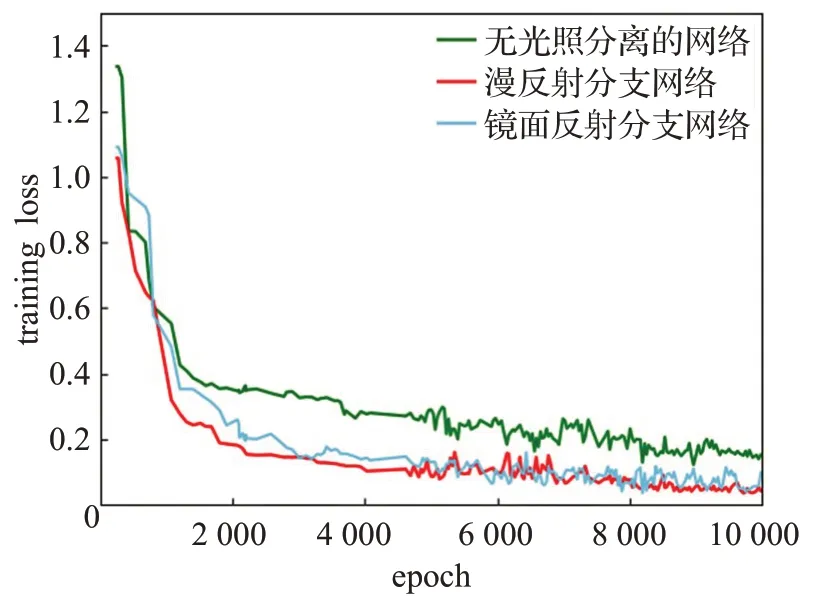
图5 本文方法的网络收敛性Fig.5 Network convergence of this paper method
同样是基于光路分解求解镜面反射和漫反射,KPCN和本文方法有着本质的区别。KPCN通过图像降噪获得过滤后的低噪图像,受输入图像的噪声水平影响较大。图6展示了分别选择16 spp和32 spp图像作为输入的分量降噪效果。可以发现降低输入图像的采样数导致难以恢复光泽表面的高频细节,如Living Room的镜面反射分量,同时,其漫反射分量也一定程度地发生了颜色偏移。本文方法通过求解各图形属性与两个分量的非线性关系来获得高质量全局光照图像,在金属高光和镜面成像细节上优于32 spp KPCN,而漫反射分量求解简单,两方法效果无明显差别。

图6 镜面反射和漫反射分量图像质量对比Fig.6 Comparison of image quality of specular and diffuse components
KPCN使用两个相同的CNN作为降噪网络,网络规模和参数量更少,但是收敛速度慢,训练时间约为本文方法的1.5倍。
3.3.2 多尺度融合模块
正如第2.3.1 小节所提到,由于漫反射光照特征表现的平缓性,而镜面反射光照受反射模型、视点等多种因素影响,需要更多的全局信息来重建复杂的镜面反射和高光等特效。本文仅针对镜面反射分支设计多尺度特征融合模块(MSFFB)。
为了证明MSFFB 模块的有效性,图7 展示了是否添加MSFFB模块的生成图像与参考图像的对比。在传统的跳跃连接中增加MSFFB 模块,生成图像的瓶身反射成像清晰,边缘分明,与不使用MSFFB 相比,质感有所提升。

图7 有/无MSFFB模块的图像质量对比Fig.7 Comparison of image quality w or w/o MSFFB module
3.3.3 损失函数
本文使用三种损失函数来对优化目标进行描述,包括像素级损失以及两种增强的对抗损失。
图8展示了增强的对抗损失函数的有效性。其中,基线测试为仅有L1损失,如图8(1),L1+Lfeat为在基线测试基础上增加了特征损失,如图8(2),L1+Lfeat+Lrot{0,90°}为增加两个角度的旋转损失,如图8(3),L1+Lfeat+Lrot{0,90°,180°,270°}为本文方法最终所采用的损失函数组合。

图8 不同损失函数组合下的图像高频细节对比Fig.8 Comparison of image high-frequency details under different loss function combinations
实验证明,仅使用L1损失容易产生模糊的图像,增加了对抗损失后的重建结果均优于前者。这也证明,单一的硬编码距离函数难以有效描述复杂的视觉感知模型。场景中具有丰富的几何细节,本文的特征损失在多个尺度上描述了图像之间的语义级差异,有效地保证了高频几何细节的重建。从图8中可以看出,图像中墙面雕花轮廓分明。当继续增加旋转对抗损失后,能够稳定地产生更自然的高质量图像。
3.4 讨论与局限
本文的输入包括多种图形辅助属性。在数据采集阶段,若任何一个输入存在明显走样,这类伪影都会或多或少反映到最终的合成图像上。尽管在数据预处理时,已对输入属性和参考图像进行简单的反走样,但是相乘、相加等后处理操作会将分支或者输入图像的轻微走样误差进一步放大化,最终使得部分视点下合成的图像仍然存在明显的边缘锯齿,影响图像的观感质量,如图9所示。在未来工作中,将尝试采用神经网络进行后处理,使得合成运算完全在抽象空间中进行,从而尽可能纠正走样误差。

图9 局限性Fig.9 Limitations
4 结束语
本文采用光路分解框架,将光照解构为镜面反射和漫反射两个独立的分支,并分开进行有监督的训练和预测,运用逐元素相乘和相加操作来合成最终图像。该框架使合成任务更具有针对性,重建出了逼真的全局漫反射、镜面反射和金属材质高光等效果。
下一步工作将继续优化网络结构,用于简化模型并提高推理速度。其次,为进一步提升绘制速度,考虑利用时域上的连续性来提高当前帧的图像质量以及帧间稳定性。
