联合多源分析的罪名预测研究
2023-02-28毛国庆林鸿飞
彭 韬,杨 亮,张 琍,毛国庆,林鸿飞,任 璐
1.大连理工大学 计算机科学与技术学院,辽宁 大连 116024
2.北京计算机技术及应用研究所,北京 100854
3.北京国双科技有限公司,北京 100083
随着人工智能的发展和司法信息化体系的构建,运用人工智能解决司法领域的需求成为近年来自然语言处理领域的研究热点。一系列人工智能在法律行业的应用被提出,例如法律判决预测、法律检索、法律文件生成等应用场景[1-3],这些法律人工智能应用与云平台和人机对话等技术结合,催生出在线法律服务、法律智能客服等新的法律电商平台LegalZoom、法信等,正逐步改变现在的法律服务市场。法律人工智能一方面可以为司法工作者提供辅助服务,如法律文书的整理分析和生成,简化司法人员的工作流程,另一方面为广大人民群众提供便捷、廉价的法律咨询服务,促进法律咨询行业标准化、透明化发展。人工智能在未来数十年间将会引起法律行业的一场大变革。
法律判决预测一般包括多类子任务:罪名预测、法条预测和刑期预测等[4]。本文主要关注于罪名预测任务,该任务是基于刑事法律文书中的案情描述和事实部分,预测被告人被判的罪名[5]。因为司法实践中存在被告犯有多个罪名的情形,所以罪名预测一般是多标签文本分类问题[6-7]。现有的罪名预测研究中使用的刑事法律文书数据集基本来源于裁判文书,裁判文书记录了当事人的诉辩主张、认定事实及说理部分和主文裁判结果部分[8]。裁判文书主要是司法人员在案件审理完成后整理撰写出来的书面性文本,精炼客观地描述了案件的经过,是提取案件描述内容的优质数据来源。但是,裁判文书侧重于对客观事实的描述(如司法鉴定结果)以及法院推定的案件逻辑,文书中往往省略了案发时双方的主观动机以及案件细节等因素,而这些因素往往在司法案件中难以确定,且对案件的判决结果起关键指导作用。为了进一步补充和丰富裁判文书中的细节,本文收集了部分裁判文书对应的庭审文书,结合裁判文书和庭审文书进行罪名预测。
针对目前罪名预测数据集依赖于裁判文书,但裁判文书对案件细节记录不够详实的问题,本文构建了一个裁判文书和庭审文书一一对应的多源联合分析数据集,并实现了罪名预测的部分深度学习模型探究单一文书对预测结果的影响。最后通过两种文书联合分析的实验结果,验证了庭审文书确实能补充裁判文书中缺乏的案件细节,增强模型罪名预测的准确性。
1 相关研究
法律判决预测任务起源于20 世纪六七十年代,受限于当时的研究手段,主要以统计方法结合司法知识,从文书法条表示、推理决策等角度构建系统化的判决预测模型[9-11]。基于数学模型和法律规则的这些方法的可解释性较好,但是模型的预测效果却不甚理想,法律判决任务还有较大的提升空间。
随着司法信息化和人工智能的发展,研究者逐渐开始利用机器学习算法处理法律判决预测问题,主要思路是手动构造与提取案情描述的文本特征进行文本分类。Liu 等[12]收集了12 类罪名的刑事诉讼文档,从这些文档中提取重要的法律信息构建案件实例,然后通过k近邻(k-nearest neighbors,KNN)算法合并相似的案例,提取每一类案由的浅层文本特征作为依据,用以对诉讼文书进行判决预测。Sulea 等[13]通过提取犯罪事件、犯罪事实和法律依据等特征构建支持向量机(support vector machine,SVM)分类模型,在所构建的法国最高法院司法文书数据集上取得了不错的实验结果。Lin等[14]将研究重点放在“强盗罪”和“恐吓取财罪”两类罪名的区分上,通过定义21种法律要素标签,采用条件随机场(conditional random field,CRF)模型自动化标记文书中涉及的法律要素,将这些手动构造的特征输入广义加性模型进行分类。基于机器学习方法的法律判决预测主要有两方面局限性:一方面依赖于手动提取文本特征,这往往需要先验的领域知识为指导且操作较为繁琐;另一方面受限于较小的数据规模和有限的案件类别,这些机器学习模型往往只能在部分罪名案件类别实现较好的结果,当迁移到其他罪名的案件时,由于不同罪名的案件要素不同,机器学习模型的效果不甚理想,泛化性能较差。
深度学习技术的兴起不仅推动了许多自然语言处理应用的落地,也为法律判决预测提供了新的思路与解决方案。由于深度学习规模对数据的需求量较大,许多大规模的高质量司法文书数据集发布。以中国大数据司法研究院在2018年“法研杯”法律智能挑战赛发布的CAIL2018司法数据集[7]影响力最大,其中包含了268万份刑法法律文书,共涉及183 项罪名,极大地促进了深度学习算法在司法领域的落地与应用。一系列文本分类算法率先被迁移到法律判决任务中,循环神经网络(recurrent neural network,RNN)[15]因其优秀的序列建模能力被用于对文本上下文建模。为了进一步增强RNN的长文本双向建模能力,长短期记忆网络(long shortterm memory,LSTM)[16]作为RNN的变种在文本分类问题中性能进一步加强。卷积神经网络(convolutional neural network,CNN)因其易并行性和捕捉局部特征的能力,首先被大规模用在计算机视觉领域。随着TextCNN[17]模型的提出,CNN才开始逐步被用于文本分类任务中。TextCNN 模型利用多个不同大小的卷积核捕捉文本上下文中的n-gram 特征,通过池化层提取全局信息中的差异化部分实现文本建模。深度金字塔卷积神经网络(deep pyramid CNN,DPCNN)[18]为提升CNN提取深层特征的能力,采用了残差连接和步长为2的池化层,使得多层CNN 模型的收敛性能和算法复杂度都得到了保证。DPCNN模型如图1所示。Wang等[19]将CNN与LSTM模型相结合,提出了CRNN(convolutional recurrent neural network)模型用于文本分类。
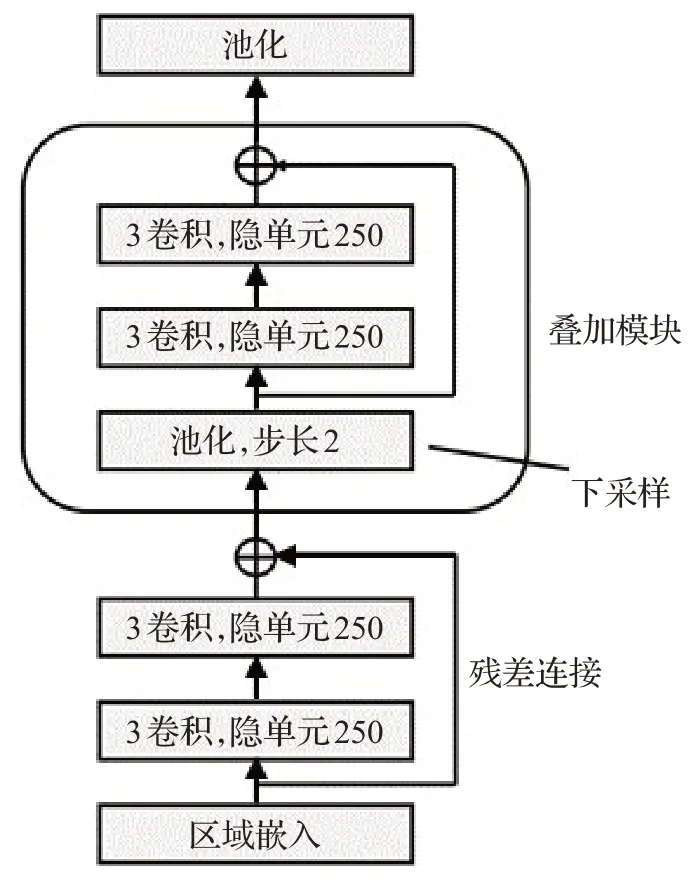
图1 深度金字塔卷积神经网络Fig.1 Deep pyramid convolutional neural network
许多研究人员对罪名预测任务也研发了许多特定的深度学习模型。Jiang等[20]2018年在ACL会议上提出了一种基于深度强化学习的罪名预测模型,该模型可以提取案件描述中的关键性要素,模型的可解释性和实验性能都获得了较好的实验结果。Xu等[21]针对易混淆罪名的语义相似导致错误分类的问题,使用了图蒸馏算子计算相似罪名之间的差异化信息,再通过注意力机制[22]提取这些差异化信息,提高了CAIL2018 数据集上罪名预测任务的准确率。以上工作主要是基于单一的裁判文书进行,但裁判文书只对案件进行了概括性描述,内容不够全面详实。
2 多源联合分析数据集构建
2.1 多源数据集构建
为了进一步扩充数据来源,本文选择司法信息化程度较高的上海市,从上海法院网的网络直播板块(http://shfy.chinacourt.gov.cn/chat/more/state/4/page/1.shtml)中收集了上海市地区的高质量庭审对话文本,包含了上海市14个区人民法院以及上海市第一、第二、铁路运输中级人民法院的4 863 个案件,时间跨度从2010 年3 月至2020 年8 月。本文依据庭审文书的时间、法院名、罪名等要素,在中国裁判文书网(https://wenshu.court.gov.cn/)上检索对应的裁判文书,将庭审文书与裁判文书一一对应,总计获得2 647个相互匹配的案件文书,其中包含刑事案件1 743个,民事案件820个,以及行政案件84个。刑事案件案由占比如图2所示。
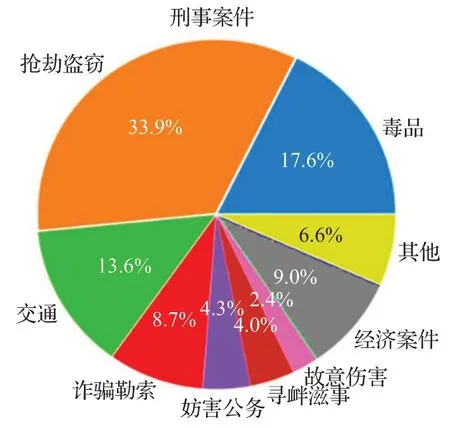
图2 刑事案件案由分布Fig.2 Distribution of criminal cases
本文主要研究罪名预测任务。鉴于民事案件主要是关于民事权利、义务性质的纠纷,不涉及罪名判决,因此只选择刑事案件数据展开后续研究。
2.2 数据筛选与标注
由于多人多节案件涉及的作案主体比较复杂,本文参考CAIL2018 数据集的形式,进一步筛选了单人犯罪案件1 426起,针对这些案件,结合裁判文书与庭审文书一一标注其罪名。因为数据规模比较有限,本文标注完成后发现所有案件均只涉及单一罪名,不存在数罪并罚的情况,所以本文的罪名预测任务为单标签分类任务,不同于CAIL2018中的多标签分类。
本文运用正则表达式进一步去除裁判文书和庭审文书中出现的罪名,并考虑到法律条文与罪名之间可能有较强的关联关系,因此本文也进一步去除了所有正则匹配成功的法律条文信息,从而本数据集中裁判文书和庭审文书中所有罪名均用“###”符号替代,所有法律条文均用“$$$”符号替代。对标注后的1 426 条数据统计分析后,发现数据集分布极不均衡,部分罪名(例如非法狩猎、偷越国边境等)出现频次极低,不超过5 次,对后续划分数据集和模型预测都会造成较大困难。为更好地验证多源联合分析数据集的有效性,将罪名出现频次30次以下的数据全部筛去,最终保留了1 104条数据,其中涉及了8类罪名,各类罪名对应的数据规模如表1所示。

表1 刑事案件罪名分布Table 1 Distribution of crimes in criminal cases
2.3 多源数据分析
本文针对裁判文书和庭审文书进行了一些初步的统计分析,统计分析结果如表2 所示,其中词表大小为采用jieba分词工具的精确模式分词后统计得出。从统计数据中不难分析得出,庭审文书的文本长度普遍长于裁判文书,且平均文本长度相差了7.8倍,从词表大小亦可观察出庭审文书的词汇更加丰富,可能与庭审文书中较多的口语化表达有关。
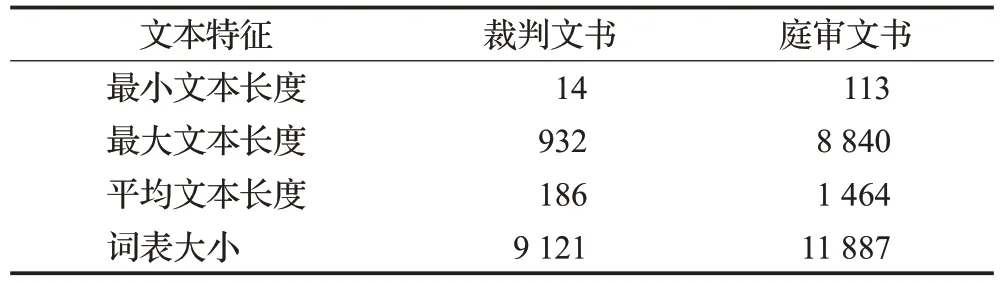
表2 裁判文书与庭审文书文本特征统计值Table 2 Statistical values of text characteristics of judgment documents and court documents
为进一步分析两类文书的区别,本文选取了一个故意伤害案件作为样例,由于文本长度过长,只节选了部分内容,裁判文书全文和庭审文书全文链接已给出。示例如图3所示。

图3 裁判文书与庭审文书示例Fig.3 Examples of judgment document and court document
庭审文书主要由审判员、公诉人、被告人、辩护人等的对话内容组成,依据司法机关提供的各项证据,公诉人对被告人提出对案件关键细节的质询,而被告人和辩护人为自己的动机和行为等进行辩护,审判员则通过双方提供的信息挖掘案件事实进行司法判决。从图3 中裁判文书与庭审文书的对比可以看出,裁判文书对案件的概述较为精炼简洁,而庭审文书对案件动机、案发过程、案后处理等多个角度进行了补充,一方面为司法人员的审判提供了细节,另一方面庭审文书为实现基于庭审过程的法律判决人工智能系统提供了新的可能。
3 模型训练与结果分布
为了验证本文构建的多源联合分析罪名预测数据集的效果,在该数据集上进行了大量的实验及分析。
3.1 实验设置
数据集划分:本文在上一节构造的数据集的基础上按照每一类罪名85%、5%、15%的比例划分了训练集、验证集、测试集,数据规模如表3所示。

表3 数据集分布Table 3 Dataset distribution
评价指标:本文采用的评价指标参考CAIL2018 评测中罪名预测的评价指标[23],假定数据集中共有M类罪名,对每一类罪名i,计算得出TPi(真阳性)、TNi(真阴性)、FPi(假阳性)、FNi(假阴性)。宏平均指标计算公式如下:
微平均指标计算公式如下:
3.2 基线模型
本文主要实现了基于机器学习和深度学习的基线模型。
3.2.1 基于机器学习的模型
机器学习方法主要采取了数据预处理、特征工程和模型选择三个步骤。数据预处理主要包括分词、去除停用词等步骤。特征工程主要提取句子中的一元分词(unigram)和二元分词(bigram)的词频逆文档频率(TFIDF)。模型选择部分本文选择了以下四个机器学习算法:
(1)支持向量机(SVM)[24]
(2)基于高斯分布先验的朴素贝叶斯(Gaussian naive Bayes,GNB)[25]
(3)梯度提升树(gradient boosting decision tree,GBDT)[26]
(4)随机森林(random forest classifier,RFC)[27]
3.2.2 基于深度学习的模型
LSTM[16]:先用一个双向LSTM 得到句子的上下文表示,然后通过两层LSTM提取高层语义特征,取序列尾部的隐层向量送入分类器分类。
TextCNN[17]:使用大小分别为2、3、4、5 的一维卷积核建模文本的局部特征,再通过最大池化层提取特征,拼接不同卷积核的特征后送入分类器分类。
DPCNN[18]:如图1所示。
CRNN[19]:用CNN提取局部特征后,通过两层LSTM提取序列特征,取序列尾部的隐层向量送入分类器分类。
3.2.3 超参数设置
本文采用基于百度百科预训练的中文300 维词向量[28],学习率为0.000 3,训练最大轮次为50 轮,dropout值为0.5。LSTM的隐藏层维度为256,由于裁判文书和庭审文书的长度不同,LSTM 针对两类文本的最大序列长度分别设置为300 和2 000。CNN 的输出通道数为250。
3.3 实验结果
综合分析表4实验结果,可以得出一些结论:(1)基于深度学习的模型效果远高于机器学习的方法,说明在判决预测任务上深度学习方法确实提取特征的能力更强。(2)机器学习方法中,梯度提升树算法的效果远优于其他机器学习算法,但与深度学习算法的表现尚有一段差距。(3)深度学习算法中卷积神经网络类算法的整体表现优于循环神经网络的表现,其中TextCNN模型表现最佳,说明裁判文书中的局部特征对于罪名预测任务有重要价值。
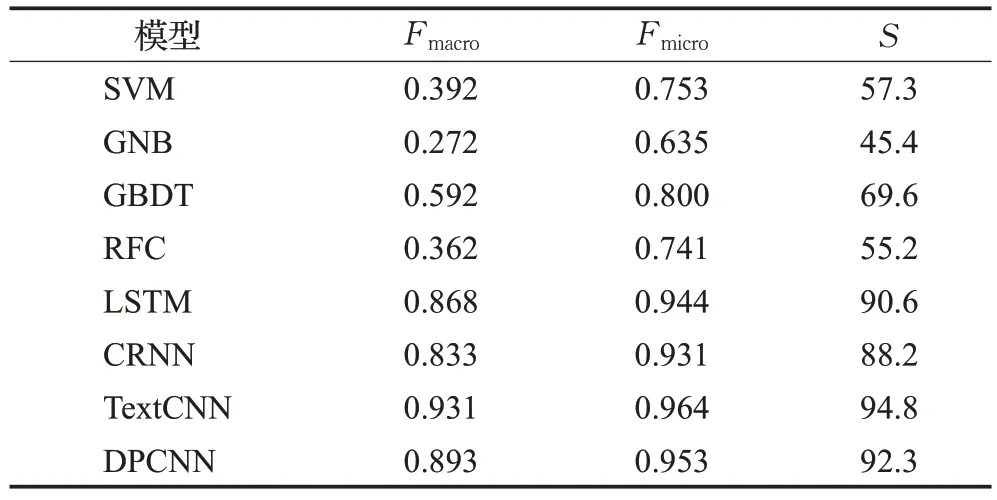
表4 裁判文书罪名预测分类实验结果Table 4 Experimental results of charge prediction classification of judgment documents
结合表4 与表5 的实验结果,可以得出一些新的结论:(1)庭审文书的实验结果与裁判文书对比可发现,整体上实验结果逊色于裁判文书的结果。这可能由两部分原因构成,一是庭审文书的文本长度较长,且表达过于口语化,这对于模型的文本建模能力提出了巨大挑战,二是庭审文书中部分数据记录并不十分详细,只记录了一些司法审判的程序性对话内容,不包含案件的细节性信息。(2)LSTM 模型和CRNN 模型在裁判文书上效果较好,但是在庭审文书上模型效果崩溃。这可能是由于庭审文书文本长度过长,循环神经网络在时间步上进行反向梯度传播时会导致梯度消失,从而导致模型参数无法得到有效训练。(3)Text-CNN 模型和DPCNN 模型依然表现最为良好,说明卷积神经网络较适用于长文本的建模,也表明了庭审文书在一定程度上也可以作为罪名预测的原始文本,尽管其效果逊色于裁判文书,但是庭审文书不需要专业的司法人员撰写,获取成本较低,可作为切入罪名预测任务的另一角度。
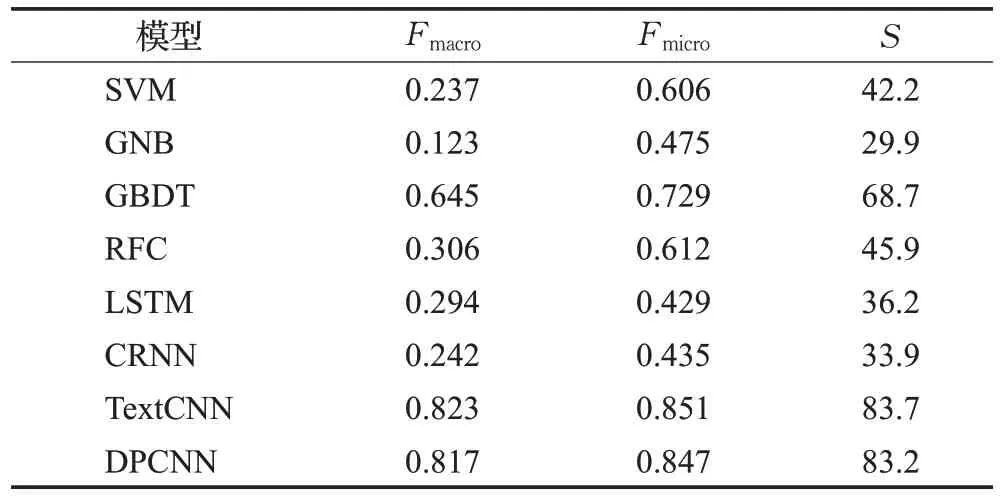
表5 庭审文书罪名预测分类实验结果Table 5 Experimental results of charge prediction classification of court documents
为研究裁判文书和庭审文书的互补性,本文进一步结合两类文本进行罪名预测研究。对于机器学习模型,本文将两个文本拼接起来输入到机器学习模型中。对于深度学习,鉴于循环神经网络在长文本中的不佳表现,且其训练时间较长,因此未进行相关实验。而Text-CNN 和DPCNN 模型,则分别建模两个文书后,拼接其隐藏层向量再送入分类器分类。实验结果如表6所示。
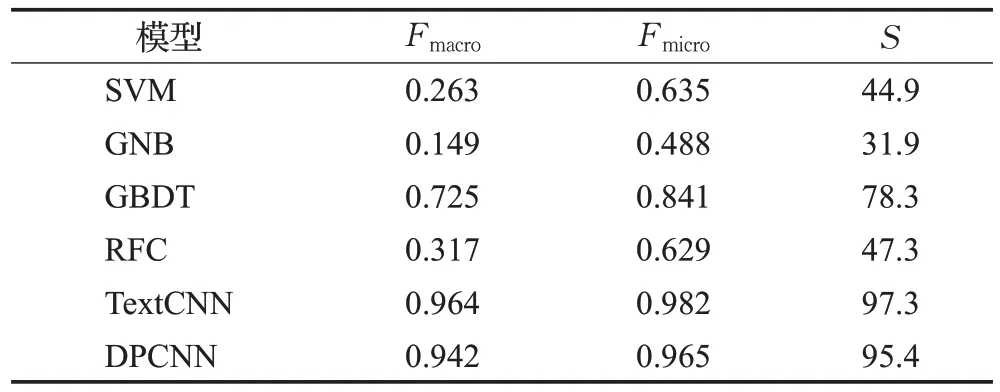
表6 裁判文书结合庭审文书罪名预测分类实验结果Table 6 Experimental results of charge prediction classification of judgement documents combining court documents
从表6 实验结果可看出:(1)SVM、GNB 和RFC 模型效果相较于单一的庭审文书的结果略有上升,但是较单一的裁判文书的结果相差较远。这可能是两类文本拼接会导致“噪声”,“噪声”对模型的影响占主导作用。(2)对于GBDT、TextCNN和DPCNN这些文本建模能力较强的模型,两类文本联合分析的实验结果优于任一单一文本的实验结果。说明庭审文书确实在一定程度上丰富了裁判文书的信息,两者具有一定的互补关系,也侧面验证了GBDT、TextCNN和DPCNN模型的鲁棒性,能够消除两类文本中的“噪声”因素,提取有效的司法语义信息。
3.4 消融实验
为研究不同领域的预训练词向量对模型的影响,本文采用Li等人[26]在百度百科、人民日报和微博等语料上预训练的词向量,分别评估对实验结果的影响。实验结果如图4所示。
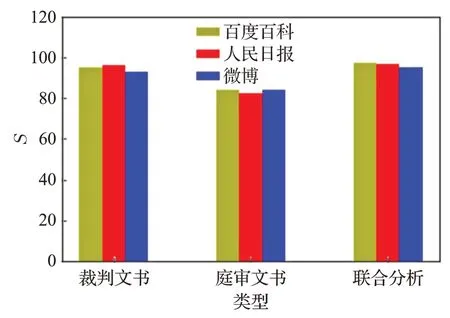
图4 词向量对模型的影响Fig.4 Influence of word vector on model
分析图4可得:(1)对裁判文书分析,人民日报词向量的实验结果最好,微博词向量的实验结果不佳,可能是由于裁判文书与人民日报都是书面性表达。(2)对庭审文书分析,微博词向量表现最佳,人民日报词向量表现不佳,这可能是由于庭审文书与微博均为口语性表达。(3)对两类文书联合分析时,百度百科词向量结果表现最佳,可能是由于百度百科词向量的词汇覆盖度较好,能够兼顾两类文书的词汇表达进行向量表示。
4 结束语
针对目前罪名预测任务主要基于单一的裁判文书,可能存在案件细节缺失的问题,本文构建了一个结合裁判文书和庭审文书的多源联合分析司法罪名预测数据集,并采用了一系列机器学习和深度学习模型验证两类文书在罪名预测任务中的作用。实验结果表明,两类文书在信息上确实存在一定的互补性,可以提升罪名预测任务的准确性。
在下一步工作中,将从两方面延续本文的研究内容:(1)继续挖掘庭审文书中的多人对话文本结构,尝试采用一些对话建模技术进一步提升分析庭审文书的能力。(2)将该数据集的任务继续拓展到法条预测、刑期预测、司法问答等其他法律智能领域之中,以新的角度看待法律智能面临的各个问题,进一步促进法律人工智能的落地与应用。
