基于朴素贝叶斯的影评情感分析研究
2023-02-27邓慈云余国清
邓慈云, 余国清
(湖南信息职业技术学院, 长沙 410200)
0 引 言
随着社会和经济的高速发展,人们在精神生活、娱乐等方面的需求越来越高,电影已经成为大众精神生活中不可分割的一部分。2021年中国电影市场累计票房达472.58亿,较2020年增长131.5%。2021年国产电影总产量740部,同比2020年增长13.8%。面对日益壮大的电影市场以及不同的题材,经常会发现同一部影片在不同平台上的评分存在较大的差异。
情感分析是指用机器学习的方法解析出文本中情感极性信息,归纳出用户的情绪、态度、倾向等情感意向的过程,其是自然语言处理(Natural Language Processing,NLP)的一个分支内容[1]。文本情感分析是指提取文本中主观信息的一种NLP任务,其具体目标通常是找出文本所对应的正负情感态度。情感分析可以在实体、句子、段落乃至文档上进行。对于情感分析,只需要准备标注了正负情感的大量文档,就能将其视作普通的文本分类任务来解决[2]。
近年来,诸多学者对影评的文本情感分析以及如何提高结果的准确率进行了研究,并取得了一定的研究成果。如:文献[3]中提出了在影评的文本情感分析中,将机器学习方法与分层技术结合,针对具有异质结构的文本数据的算法。文献[4]提出了使用Keras内置的Tokenizer模块建立字典,利用字典将影评文字进行预处理后,通过Keras框架构建MLP模型并训练。文献[5]提出了一种加入注意力机制的联合神经网络模型,用来对影评进行情感分析。文献[6]提出了一种基于Keras平台实现的双向LSTM(BiLSTM)的影评情感分析算法。综上研究分析,影评的文本情感分析的准确率依然不高,亟待进一步探索和研究更具实用性、通用性的算法和模型。
为了能够客观全面的了解观众对影片的真实感受,本文利用python作为编程语言,使用Scrapy框架爬取豆瓣电影网站影评数据,构建分类模型完成训练,并评估训练器的分类效果;最后利用训练后的分类器,对中文影评文本进行情感分析和文本分类,让观影者能够快速地从大量影评中得到有价值的信息,也让影视工作人员了解观影者的喜好以及主观情感倾向。
1 文本情感分析
1.1 数据来源
本文使用豆瓣网电影(https://movie.douban.com/chart)影评数据信息,其中数据字段包含:电影详情信息(电影类型、上映时间、演员列表等);电影短评内容(用户、是否观看、五星评分、评论时间、有用数、评论内容等),将其作为分析的目标数据。
1.2 数据采集
Scrapy是用Python语言开发的一个快速、高层次的屏幕/Web抓取框架,用于抓取Web站点并从页面中提取结构化数据。Scrapy使用Twisted异步网络请求框架来处理网络通信,不需要额外实现异步框架,而且包含各种中间件接口,能够灵活地实现各种需求[7]。
使用Scrapy框架爬取豆瓣电影影评数据的过程为:首先利用selenium实现模拟自动登录,然后从Top250电影排行榜里爬取电影信息和链接地址,接下来根据链接地址爬取相关影片的具体信息和影评信息并保存到csv文件中。
1.3 数据清洗
数据清洗是指在获取文本数据之后,对数据进行重新审查和效验的工作。主要包括:缺失值清洗、重复值清洗和错误值清洗。通过对采集的数据进行查看和分词后,影评文本中存在以下情况及相应处理方法:
(1)对于英文、长度过短、重复及无实际意义的灌水文本,可通过正则表达式进行英文识别,通过长度过滤内容过少的评论。
(2)对于有缺失值的文本,通过查找确认存在有缺失值的记录,然后使用Pandas库实现删除相应记录。
(3)对于存在简体、繁体混杂的文本,通过使用opencc库,实现将繁体中文转换成简体中文。
(4)去除停用词。汉语中有一类没有多少意义的词语,比如助词“的”、连词“以及”、副词“甚至”、语气词“吧”,称为停用词。借助预先准备好的停用词字典,通过查询字典的方式,剔除停用词。
1.4 基于朴素贝叶斯的情感分析算法
1.4.1 算法流程
基于朴素贝叶斯的情感分析的实现过程如图1所示。首先对影评使用jieba库进行分词,去停用词等预处理,然后构建分类模型并用训练集进行训练,同时利用测试集评估训练器的分类效果,最后利用训练后的分类器对分类文本进行情感分类。

图1 训练过程和分类过程
1.4.2 朴素贝叶斯
朴素贝叶斯是分类器中最常用的一种生成式模型,其基于贝叶斯定理将联合概率转化为条件概率,利用特征条件及独立假设简化条件的概率进行计算。朴素贝叶斯法的目标是通过训练集学习联合概率分布p(X,Y),由贝叶斯定理可以将联合概率转化为先验概率分布和条件概率分布之积[8],表达形式如下:
p(X=x,Y=ck)=p(Y=ck)P(X=x|Y=ck)
其中,类别的先验概率分布(p(Y=ck)),可以通过统计每个类别下的样本多少(极大似然)来估计。即:

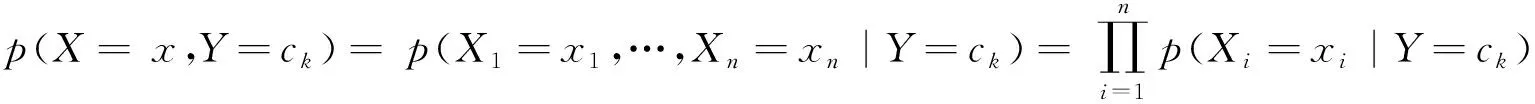
在预测时,朴素贝叶斯法最终的分类预测函数为
1.4.3 朴素贝叶斯分类器
朴素贝叶斯分类器通过计算一个样本属于某一类的概率(后验概率),进而比较概率大小,来决定样本的分类结果。分类器需要数据集作为已知样本集,并且需要这些样本的分类结果,最后对新给出的样本集进行分类。具体来说,假设已经得到样本集D={x1,…,xn},每一个xi都有k个特征,分别记为ai,可能类别为Y={y1,…,ym},根据每个xi的特征,其会被分类到某一个yj类中[9]。朴素贝叶斯分类器的特点是实现模型简单,且分类快速而精确。
本文从豆瓣网站爬取Top250排行榜中约40 000条影评作为语料库。对影评分析情感倾向时,将评分中的推荐、力荐、还行视为积极评论,用数字1表示;将较差和很差视为消极评论,用数字0表示,积极评论和消极评论各占50%。图2给出了样本实例,其中第一列数字为情感标签,第二列文字为影片评论内容。

图2 标注情感标注的影评评论示例
(1)训练集与测试集的分割比率
如何设定训练集和测试集的分割比率,对朴素贝叶斯分类器的性能影响十分明显。本文使用Python的可视化工具pyecharts,绘制精确度和分割比例折线图,找到训练集和测试集的最佳比例为6∶4。其中,影评数据的60%作为训练集,40%作为测试集。
(2)分类器的选择
sklearn的naive_bayes模块提供了高斯朴素贝叶斯、多项式朴素贝叶斯和伯努利朴素贝叶斯等3种用于构建朴素贝叶斯模型的类,其分别对应3种不同的数据分布类型。本文实验选择的是多项式贝叶斯分类器。
2 实验结果分析
2.1 情感分类结果分析
通过模型训练,获得适合影评情感分类的新模型。为了验证训练模型的效果,采集了300多条来自豆瓣网站的影评记录,并事先进行人工情感标签标注(数字1、0分别对应积极评论和消极评论)。测试中,将分数大于或等于0.5的评论判断为积极评论,否则判断为消极评论。将预测结果与人工判定结果进行对比,准确率达到了92%,证明该模型训练过程是有效的。测试结果如图3所示。
图3 测试结果
2.2 情感值分析
通过对影评数据的情感分析得到情感值(取值范围0~1)。通过使用matplotlib可视化工具,绘制出情感建议值的直方图,如图4所示。由图中可以发现,观众对该电影整体的情感倾向是积极的。其中情感值分布在0.1和1.0左右的数量占比约为3.2%,情感值分布在0.5以上的数量占比约为84.1%。
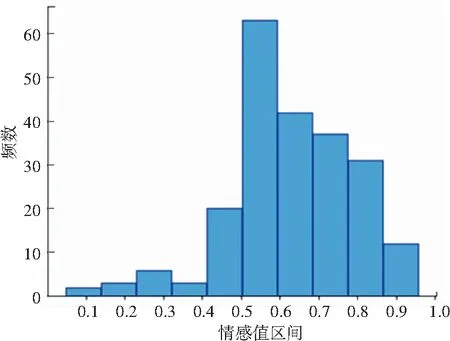
图4 情感值区间统计
3 结束语
在各种各样的分类器中,朴素贝叶斯法可算是最常用的一种生成式模型,其具备实现简单,收敛速度快等特点,但由于特征独立性假设过于强烈,有时会影响准确性。本文提出使用Scrapy框架爬取网站数据,选用多项式贝叶斯分类器构建朴素贝叶斯模型,jieba库进行分词,正则表达式和pandas库进行数据清洗,opencc库实现中文繁体和简体的转换的方法实现影评情感分类。通过使用python语言编程,利用真实影评数据验证了本方法的有效性。但是本次试验的影评大多数是短评,文字数量在100个字左右,在将来的研究中会考虑文字数量更多的长篇评论。
