高并发系统性能优化及其在电子资料平台中的应用
2023-02-26张淼鑫任新会党兰学侯彦娥
张淼鑫, 任新会, 党兰学, 侯彦娥
(1.河南大学 计算机与信息工程学院, 河南 开封 475004; 2.河南大学 教务处,河南 开封 475004)
0 引言
从小型门户网站、聊天系统,到大型的“12306”购票系统和“双十一”电商的秒杀系统,都体现了高并发系统的迫切需求。除了“双十一”不断刷新的交易记录外,另一个重要看点是各大电商平台如何处理峰值时刻的高并发情况[1-2]。许多用户都曾遭遇“系统繁忙”这类异常,说明高并发技术仍然面临挑战,具有相当大的提升空间。同样,电子资料平台也会面临各种高并发场景。例如,随着在线学习的普及,当老师在某一时间吸引大量学生时,学生们需要同时访问不同的课程材料、教科书或讲义,这就构成了大规模的高并发读取场景[3]。
早期典型的架构设计基于经典的技术栈进行开发,但是因为缺乏模块化设计,受单机性能制约较大,导致高并发的处理性能较差[4]。随着硬件性能的大幅提升,在对单机进行最优设计的前提下,目前架构设计普遍采取的方法是对系统进行横向扩展,搭建服务器集群,对合法的请求进行分流,并通过使用消息队列对请求进行“削峰填谷”的处理。为使数据库稳定地处理这些请求,往往利用缓存中间件减少对数据库的访问,并通过服务降级,减轻峰值期间的访问压力[5-6]。本文基于多级缓存、热点探测、分布式锁、分布式事务等技术,设计了一套高并发解决方案,并将该方案应用于电子资料系统进行测试。测试结果表明,该方案可为电子资料系统提供卓越的稳定性和可扩展性。
1 技术原理和系统总体架构设计
本文设计的高并发电子资料平台,主要支持文档收集、整理、检索、共享、阅读、下载、统计分析等主要功能,以及人员信息维护、部门信息维护、权限维护等辅助的系统功能。系统架构如图1所示,核心组成部分包括文档管理模块、检索与查询模块、共享与权限模块、用户管理模块、数据统计与分析模块。为支持高并发和大规模数据处理,系统引入了多级缓存,包括本地缓存、分布式缓存等,以减轻数据库负载;采用热点探测算法,以识别热门文档,减少系统瓶颈;使用分布式数据库和分布式事务处理,以确保数据的一致性和可靠性; 应用分布式锁机制,以协调多个并发操作,避免数据冲突。

图1 系统架构
2 高并发系统的实现
2.1 多级缓存与热点数据的处理
目前在高并发架构中使用较多的是分布式缓存,但是数据需要从远程缓存中获取,导致吞吐量下降,所以本系统使用的是多级缓存[7]。多级缓存主要分为3层,Nginx应用层缓存,Redis分布式缓存以及Tomcat的堆内缓存。缓存流程如图2所示。
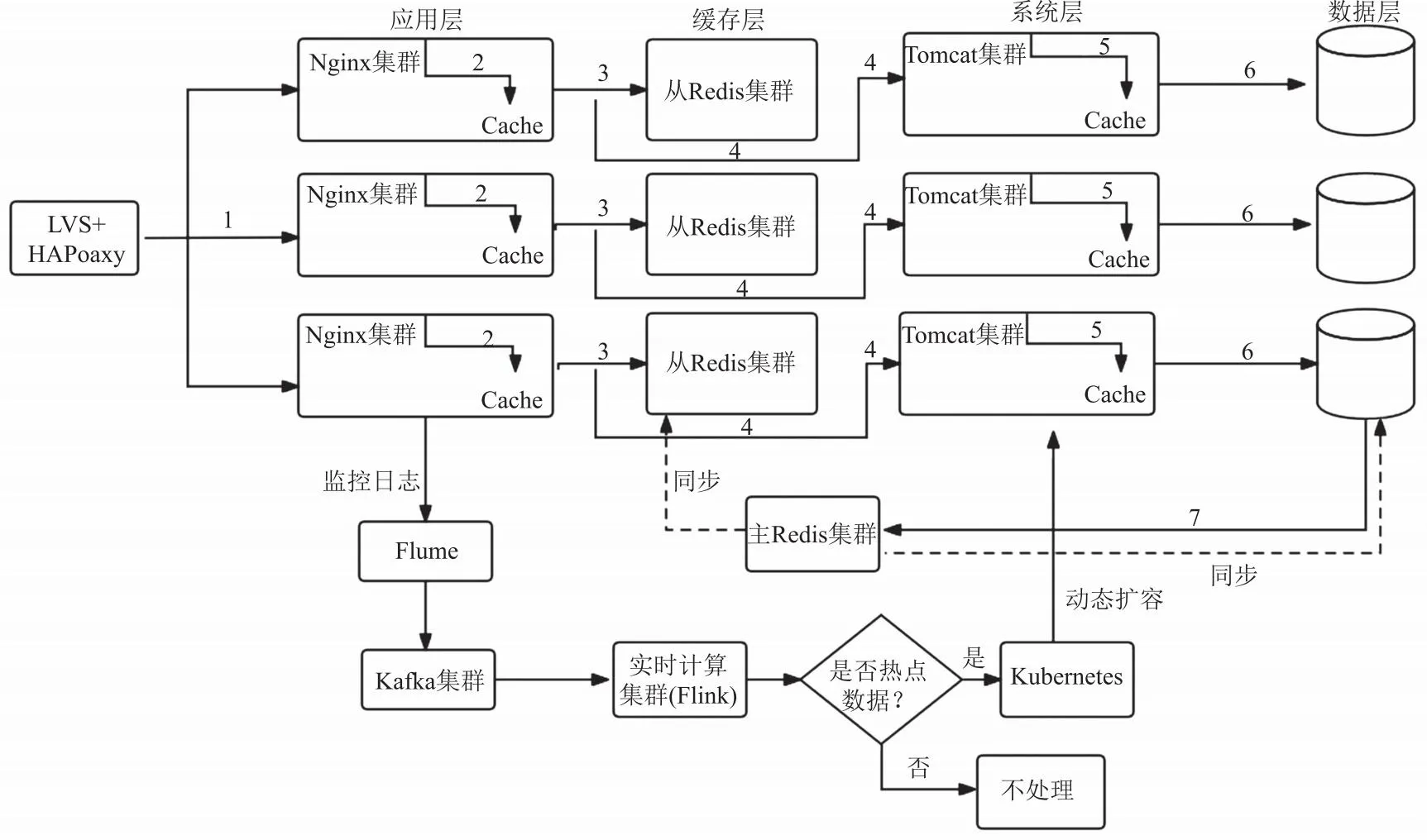
图2 多级缓存流程图
Nginx集群分为接入和应用两种,通过接入Nginx将请求分发到应用Nginx。为了提升缓存的命中率,这里的负载均衡算法在正常情况下采用的是一致性哈希算法,但是如果访问量到达了极限,就降级为轮询算法。接着在应用Nginx中读取本地缓存,本地缓存用Lua Shared Dict实现,并结合页面模板生成页面。如果Nginx本地缓存已经过期,那么系统将尝试从Redis中获取,同时更新Nginx的本地缓存。如果Redis中的数据被LRU(least recently used)算法清理掉,那么系统将发出HTTP(hypertext transfer protocol)请求到后端服务,数据生成服务首先在本地Tomcat的JVM(Java virtual machine)堆栈内存中查找,使用Ehcache缓存。如果JVM堆栈内存中的数据也被LRU清理掉,那么系统将重新请求源头服务以获取数据,然后再次更新Tomcat堆内存缓存和Redis缓存,并将数据返回给Nginx,Nginx再将数据缓存到本地。其中各级缓存的目标不同,由于Nginx本地缓存的容量有限,所以该级缓存用于支持对热点数据的高并发访问;Redis分布式缓存容量很大,可以支持海量的缓存数据,所以重点针对高离散数据的访问;最后一级Tomcat堆内缓存,主要用于对抗Redis大规模宕机,大量请求涌入数据生产服务时产生的压力。
系统除了要处理一些常用的热点数据之外,更重要的是要处理特殊场合出现的热点数据。常见的热点数据会被提前放入多级缓存,特殊的数据一般要通过分析、计算,在Nginx缓存层进行处理,即对热点数据的实时监测和追踪。对于热点数据的监测,可以使用数据调研,对历史数据进行分析做出策略,但是这种方法的缓存命中率并不能达到100%[8]。本文使用实时计算对热点数据进行监测,如图2所示。Flume框架主要用于海量数据聚合,Flink框架在集群环境中对有边界或者无边界的数据流进行计算,可对Flume采集的Nginx层日志信息处理分析。用Flume直接对接实时计算框架,如果数据采集速度远大于处理速度的话,会造成消息丢失或堆积,所以在它们之间引入消息中间件,不仅可在业务逻辑上进行解耦,而且相当于对数据进行了分桶处理,进行数据隔离。这里集成Flume和Kafka完成日志处理,随后使用Flink实时处理技术,统计某一时间内的文件访问量、点击率,从而实现目标的解析——将某一时刻访问量大的实体数据标识为热点数据。当这些数据被识别出来后,根据数据自身的特点将其放入多级缓存的各个节点。除此之外,为应对大流量的冲击,需要对Tomcat集群,也就是该数据所对应的业务处理服务进行扩充。本系统使用Kubernetes,程序自动调整参数值,对其相关服务扩容。
2.2 分布式锁
高并发系统中另一个重要的问题,是多线程场景下对并发数据进行更改和读取。在“先更新数据库、再更新缓存”的设计方案中,存在两个线程,即线程 A 和线程 B,它们同时操作同一条数据时可能出现以下情况:线程 A 更新数据库(X=1),线程 B 更新数据库(X=2),接着线程B更新了缓存(X=2),而线程 A 也更新了缓存(X=1)。最终在缓存中的值为1,而在数据库中的值为2,导致数据不一致。同样,使用“先更新缓存,再更新数据库”的方法也可能面临类似的问题。本系统通过加分布式锁解决此问题。传统的设计方案是用MySQL做分布式锁,但是MySQL做锁时要读取磁盘IO(input output),当访问量较大时,系统性能会比较低,所以本系统使用Redis作为分布式锁[9]。
结合业务流程设置分布式锁,将Redis的相关节点传入对象,调用该对象的trylock(waitTime, leaseTime, unit)对其加锁,其中waitTime代表请求锁的等待时间,leaseTime代表锁的有效期,unit 代表时间单位。以下为尝试获取锁的伪代码示例:
Public boolean trylock(waitTime, leaseTime, unit){
newLeaseTime = getLeaseMillis(leaseTime);
remainTime = getRemainMillis(waitTime);
lockWaitTime = calcLockWaitTime(remainTime);//每个等待实例时间与1比较取最大值
failedLocksLimit = failedLocksLimit();//允许获取锁失败的次数
for(ListIterator
lockAcquired = lock.tryLock();
If(lockAcquired)
acquiredLocks.add(lock);//获取到该锁了,加入队列
failedLocksLimt = failedLocksLimit();//获取锁失败重试机制
}
rFuture.syncUninterruptibly();//key过期后用中断方式释放期锁
}
算法依次在N个实例上尝试获取锁,使用相同的键(key)和随机值,当客户端将锁设置到Redis时,再设定网络连接和响应的超时时间。超时时间应短于锁的自动失效时间,以避免客户端陷入等待服务器端Redis响应的情况(即使服务器端的Redis已经失效)。如果服务器端未在规定时间内响应,客户端应该尽快尝试另一个Redis实例。客户端可以通过将当前时间减去获取锁时的起始时间,计算获取锁所用的时间。只有当超过一半的Redis节点成功获取了锁,并且所用时间短于锁的失效时间时,才被认为成功获取了锁。如果成功获取了锁,那么键的实际有效时间则等于有效时间减去获取锁所用的时间;如果由于某些原因未能成功获取锁,在至少N/2+1个Redis实例中未能获取锁,或者获取锁所用时间已经超过了有效时间,则客户端应该在所有Redis实例上执行解锁操作(即使在某些Redis实例上根本没有成功加锁)。图3是加锁过程的流程图。
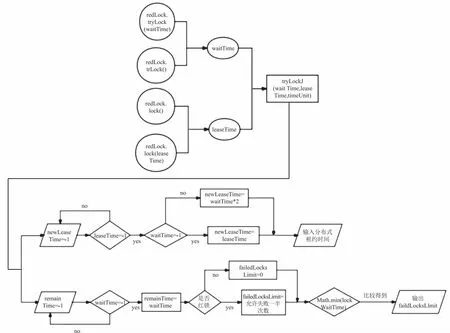
图3 加锁流程图
2.3 分布式事务
分布式文件系统中的一种数据操作过程,其中一个请求可能需要调用多个服务,并在这些服务中的每一个都连接到各自的数据库。所以当其中某一个事务执行失败,就会出现数据不一致的问题。传统的解决方发是采用“两阶段”提交 ,但是“两阶段”提交中只有协调者设置了超时机制,而参与者没有设置,所以当协调者宕机,接受消息的参与者也宕机时,事务的状态就不确定了[10]。所以本系统使用的是“三阶段”提交,在参与者中也引入超时机制,并且在第一阶段和第二阶段之间引入一个中间状态解决该问题,图4是“三阶段”提交的状态机。
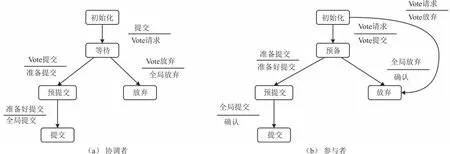
图4 “三阶段”状态机
这里将提交分为3个阶段:①CanCommit,②PreCommit,③DoCommit;角色为协调者和参与者。在CanCommit阶段,协调者开始写本地日志,进入WAIT状态,同时向参与者发送VOTE_REQUEST消息并等待参与者的响应,参与者会响应VOTE_ABORT或者VOTE_COMMIT消息。在PreCommit阶段,协调者会通知参与者准备提交或者取消事务,并写REDO和UNDO日志,但不做提交。此时如果协调者接收到参与者的VOTE_ABORT消息,会写GLOBAL_ABORT日志,进入ABORT状态,并向参与者发送GLOBAL_ABORT消息。如果收到的是参与者发送的VOTE_COMMIT消息,协调者将会写PREPARE_COMMIT日志,并进入PRECOMMIT状态,再向所有的参与者发送PREPARE_COMMIT消息,之后等待并接收确认消息,一旦收到GLOBAL_ABORT,则写日志流程结束,不进入下一阶段,如果收到PREPARE_COMMIT,则进入DoCommit阶段。该阶段协调者会向所有的参与者发送GLOBAL_COMMIT消息,并接收参与者的GLOBAL_COMMIT确认消息,写END_TRANSACTION日志流程结束,如果其中参与者无法接收到来自协调者的请求,会在超时等待后,继续进行任务提交。
3 系统性能测试
将本文设计的高并发解决方案应用于电子资料系统,并使用JMeter执行教学资源访问的性能负载测试,通过逐渐增加每秒并发请求数,评估系统的整体性能。结果发现,在不同请求数量的并发负载下,系统始终保持相对稳定,具有良好的稳定性和准确性。表1是不同并发数的系统性能测试数据,通信消耗时间约为2 ms,即使在有10 000个并发访问时,服务调用时间的平均值也保持在300 ms以下。随着并发量的增加,系统没有出现任务异常,可见该高并发设计解决方案在处理大流量式数据时,在数据处理平均耗时和延迟时间等方面表现出了理想的性能。这一性能表现可以满足大部分企业的数据处理需求。
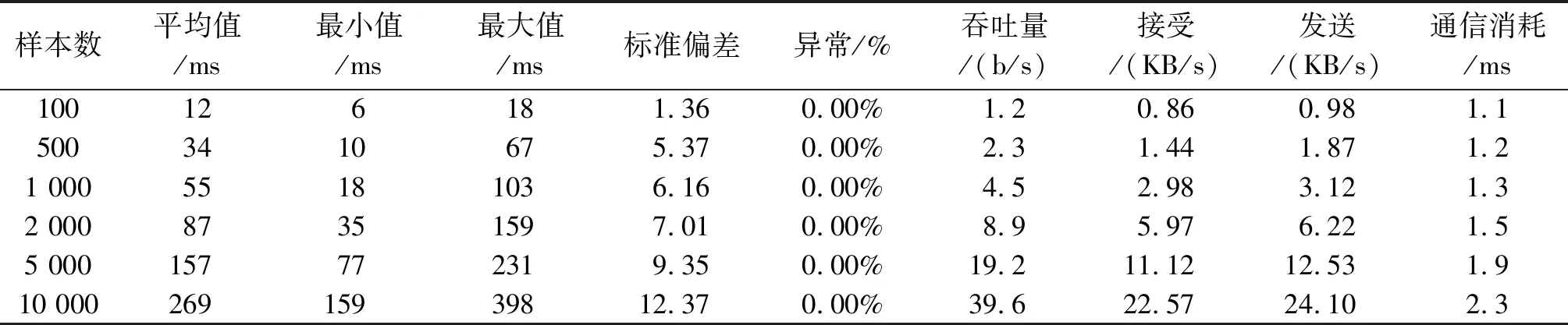
表1 系统性能测试表
4 结束语
高并发读写场景的有效处理是一项具有挑战性的任务,对于在线教学至关重要。通过合适的系统设计和技术选择,能够确保系统稳定处理大规模的并发请求,在电子教学资料系统中提供高效的教学资源访问,为学生和教育工作者提供良好的学习和教学体验。需要综合考虑缓存、负载均衡、数据库优化、CDN(content delivery network)等策略,以确保系统性能和数据一致性,为在线教学提供更多便利。
