基于机器学习和遗传算法的混凝土预制构件吊装序列优化*
2023-02-25张沧海
张沧海,牛 咪,徐 照
(东南大学土木工程学院,江苏 南京 211189)
0 引言
装配序列规划(assembly sequences planning,ASP)概念来源于制造业,理论体系研究起始于20世纪80年代初。作为装配过程的核心内容,规定装配过程中产品及部件装配顺序,对包含几何、物理、约束等信息的装配模型,生成可行的装配序列集,并对序列集进行评价,选出一条最优装配序列。装配式建筑作为一种工业化建筑,兼具制造业和建筑业的双重属性,在一定程度上可借鉴参考制造业中一些较为成熟的装配序列规划理论,合理应用至预制构件装配领域。
装配式建筑序列规划问题一直是国内外学者关注点。蒋红妍等[1]归纳了装配整体式剪力墙结构主体工程不同类别构件间的吊装顺序。这种根据施工操作人员个人知识储备和以往实践经验进行吊装序列规划的方法相对更适用于预制构件数量较少、吊装序列方案简单的项目中。而Faghihi等[2]考虑预制构件间几何约束关系,通过系列推理规则推理吊装序列方案,利用BIM系统中检索的几何数据信息,并将其转换为约束矩阵,获得构件吊装序列。Liu等[3]利用智能优化算法,提出一种基于BIM的资源约束下的建筑项目综合调度方法。其使用粒子群算法自动生成优化的活动级施工计划,通过迭代优化对问题求解,协助项目管理者有效安排现场装配工作。
预制构件是装配式建筑基本单位,具有数量大、种类多、质量大、结构复杂、信息量大等特点,因此,对构件信息有效管理已成为保证装配式项目顺利开展的关键。Li等[4]、Jeong等[5]提出可从IFC物理文件中有效提取预制构件信息,并对预制构件进行正确分类。通过计算机识别和处理预制构件分类后的编码,将其与实际意义进行组合,可进行对特定对象的独特表达。但传统人工编码需耗费大量时间和人力资源,并且出错率较高。一些研究人员探索利用机器学习[6]和自然语言识别技术[7]来进行项目信息自动编码。与人工编码方式相比,智能编码技术可利用算法的高效计算能力和逻辑分析能力,按预先定制的编码规则和规范对建筑模型信息进行自动编码。
现有装配式建筑吊装序列优化大多集中于装配式建筑整体调度,只考虑了整个项目施工进度,差异化较小。而吊装逻辑不明确的同类型预制构件装配调度问题却未得到解决。因此,本文将与混凝土预制构件吊装前识别相关的构件属性信息进行提取,并利用机器学习技术进行自动分类编码,在完成构件唯一识别的基础上,通过对部分混凝土预制构件吊装相关数据进行加工处理,利用改进遗传算法,对同类型混凝土预制构件进行吊装序列优化,得到最优且合理的装配式构件吊装序列方案。
1 预制构件信息智能标注
1.1 预制构件信息分类与编码体系设计
对现有分类方法和编码系统进行研究和整理,目前国际上主要有ISO 12006-2,UniformatⅡ,Masterformat,OmniClass等标准,国内主要有 GB/T 51269—2017《建筑信息模型分类和编码标准》、JG/T 151—2015《建筑产品分类与编码》等。经过对比可知,国外发布的一些编码体系时间较早,各编码体系分类原则、编码结构及应用角度均存在一定差异。而国内目前发布的多为基于国外已有的较成熟体系,结合我国国情和行业规律,将其转化为适合我国的规范性文件。
信息编码是赋予编码对象具有一定规律、含义且能被计算机和人识别处理的符号。本文借鉴OmniClass分类体系,考虑装配式建筑特点,以预制构件为基本单元,对装配式建筑吊装预制构件进行编码,如图1所示。

图1 预制构件编码结构
在编码总体设计中,楼栋号和楼层号以两位数形式表示。构件类别以1位大写字母表示,通常取构件类别首字母,如L代表梁、Z代表柱、Q代表墙、B代表板等。构件名称以两位数形式依次进行编码,对于墙来说,01表示预制外墙板,02表示预制外墙挂板,03表示预制内墙板。构件分类同样使用两位数编码,对于预制内墙板,01表示预制实心内墙板,02表示预制空心内墙板。流水号代表同类构件序号,通常为两位数,可根据预制构件实际数量进行相应扩展。例如,预制构件编码01-18-Q-03-01-06表示1号楼18层第6块预制实心内墙板。
1.2 基于IFC标准的混凝土预制构件信息提取
混凝土预制构件自动分类编码前,需先从BIM模型中获取与分类相关的构件属性信息。根据IFC标准中构件属性表达方式,选择所需的构件属性,通过IFCOpenShell库进行快速、准确提取。IFCOpenShell是一个用于处理IFC文件格式的开源软件库(LGPL),其提供了强大API,可直接、方便地检索IFC实体,再将提取的特征以表格形式呈现出来,用于后续机器学习分类。
1.3 机器学习数据集构建
根据混凝土预制构件不同特征,以墙体构件为例,提取相应属性,生成特征向量集,用于机器学习分类。根据可用性和范围,选择9个BIM模型进行构件属性信息提取实例验证,模型类型包括别墅、办公大楼、公寓等,如图2所示。模型中墙体实例数量最多且种类丰富便于分类,因此,选择以IFCWallStandardCase为例,从这些模型中收集墙体实例信息用于训练和测试。在模型中共收集了 1 718 个墙体实例,使用IFCOpenShell库提取每个实例Name, ObjectType, Material, MaterialThickness, LoadBearing, External属性及IFCBuilding实例和IFCBuildingStorey实例的Name属性等特征。

图2 BIM模型
将提取结果导出为Excel.xsl格式,并对每个实例进行人工标注。由于实例模型存在一定局限性,无法涵盖预制构件信息分类的所有类别且略有不同,因此,根据现有模型中墙体构件对构件类别和分类略有改动,根据模型中现有结构类型做了简单分类且补充了墙体材料信息。在实际工程中也可根据实际项目情况对编码结构在合理性范围内进行一定扩展。
在机器学习中,构件分类编码使用W-AB-XX-YY格式进行分类和注释。W代表构件名称为预制墙;A位表示该构件是否承重(0为非承重,1为承重);B位表示该构件是否在建筑内部(0为内墙,1为外墙);XX表示类别,01表示基本墙体,02表示填充墙,03表示女儿墙,04表示装饰性隔墙,05表示幕墙;YY表示墙体材料,01表示砌块,02表示混凝土,03表示铝板,04表示波纹板。人工分类标准如图3所示。

图3 人工分类标注
2 基于改进遗传算法的混凝土预制构件吊装序列计算
通过对混凝土预制构件编码,在完成构件唯一识别的基础上,以装配式混凝土结构建筑为应用场景,通过对混凝土预制构件吊装过程中的施工顺序采用数学语言进行描述,建立混凝土预制构件吊装序列具体计算模型。遗传算法具有较好的全局寻优能力,针对混凝土预制构件吊装施工实际问题,对遗传算法中的基本步骤进行适应性改进,从而找到合理且最优的装配式建筑吊装序列施工方案。
2.1 吊装序列优化对象选取
对于装配式混凝土结构建筑,目前国内主要以中高层或高层为主,不同类型装配式混凝土结构建筑间尽管存在一定差异,但吊装逻辑顺序仍存在较大相似性。如图4所示,受结构受力、施工安全、建筑稳定性等硬性约束条件的限制,装配式混凝土预制构件一般先吊装竖向构件(预制柱、预制墙等),再吊装横向构件(预制梁、预制板等),最后吊装装饰性构件(外墙挂板)。因此,根据GB/T 51231—2016《装配式混凝土建筑技术标准》中的指导性原则、硬性约束条件及结合项目实践经验,即可明确吊装顺序,无需过多优化。

图4 装配式混凝土结构建筑吊装逻辑
而对于同类混凝土预制构件,如同一楼层或同一施工区域的内墙,则缺乏硬性约束条件。当构件数量较多时,吊装逻辑顺序不明确。因此,可通过建立柔性约束进行吊装序列优化。选取某一楼层或某一施工区域内同类构件为基本对象研究混凝土预制构件吊装序列优化。
2.2 混凝土预制构件吊装序列规划模型创建
吊装序列规划不仅要生成规则上可行的吊装顺序,更是为了获取符合装配式混凝土结构建筑施工实际要求且吊装成本最低的装配序列[8]。因此,需根据混凝土预制构件吊装影响因素建立吊装序列方案评价指标体系,确定目标函数,对可行的吊装序列按一定标准进行评价和选择,并采用改进遗传算法对最优吊装序列方案进行求解。
2.2.1吊装序列方案评价指标识别与量化
吊装过程可简单描述为预制构件吊运和安装,首先采用起重设备将正确识别后的目标预制构件吊运至指定空间位置,再对目标预制构件进行安装、校正工作。通常可通过分析吊装时间、吊装难度对吊装序列方案进行评估[9],如表1所示。
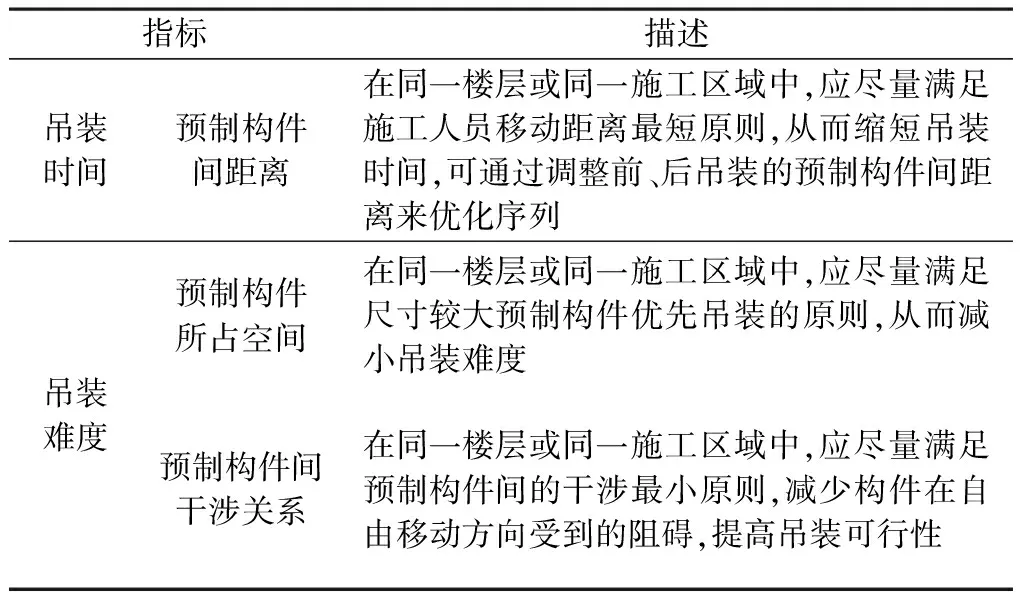
表1 吊装序列方案评价指标体系
1)吊装时间
为尽量避免安装工人不必要的来回移动从而减少移动总路程,可通过预制构件安装位置间的距离关系最短来表示,如式(1)所示:
(1)
式中:dij为预制构件i到预制构件j之间的最小距离,实际工程中应考虑施工人员实际移动路线的可行性,dij= 0则表示紧前吊装的预制构件与紧后吊装的预制构件在设计上存在连接关系;v0为施工人员移动速度。
2)吊装难度
吊装难度可由吊装强度和可行性两部分来决定。吊装强度是指受构件质量、尺寸等因素导致吊装的难易程度;吊装可行性是指在预制构件吊装过程中,可能会受到其他已吊装构件的阻碍,其上下、左右、前后自由移动的方向受到干涉,导致该预制构件不易、甚至无法安装的情况出现。存在干涉的方向越多,则安装难度越大,实际工程中还应考虑干涉对预制构件安装的影响问题。
预制构件所占空间的量化描述引入惩罚值[10]原理,按预制构件所占空间大者优先吊装的原则,当紧后预制构件尺寸所占空间大于紧前预制构件所占空间时,则产生1个惩罚值,从而阻止违背吊装原则情况的发生。惩罚值可按紧后预制构件所占空间与紧前预制构件所占空间的比值确定,当比值<1时,惩罚值设为0,如式(2)所示:
(2)
式中:B为同一楼层或施工区域中同类型预制构件间所有可能的惩罚值;bij为预制构件i,j产生的惩罚值;xi为预制构件i所占空间;xj为预制构件j所占空间。
预制构件间的干涉关系量化由受干涉的安装方向表示,如式(3)所示:
(3)
式中:Ci为构件安装的受干涉程度,取值为0~1,当Ci= 1时表示所有安装方向均发生干涉,该构件无法进行吊装,Ci越小说明构件受干涉程度越低;gi为可能发生干涉的自由移动方向数量;fi为无其他预制构件干涉下的可安装方向数量。
2.2.2吊装序列方案评价目标函数构建
建立吊装序列评价的目标函数,需同时考虑各种影响因素。综合式(1)~(3),构建装配式混凝土结构某一楼层或某一施工区域内的同类别预制构件吊装序列综合目标函数,如式(4)所示:
min(F)=w1T+w2B+w3C
(4)
式中:w1为构件间距离权重系数;w2为构件所占空间权重系数;w3为构件间干涉关系权重系数。
按各指标重要程度确定权重系数,且w1+w2+w3=1。可以看出,预制构件吊装序列的时间越短、构件所占空间的惩罚值越小、构件之间受干涉程度越低,则目标函数值越小,即目标函数值与评价指标量化值呈正相关关系。
2.3 基于改进遗传算法的吊装序列优化求解
遗传算法编码与解码实现了序列优化问题的变量与生物染色体转换的过程,采用实数编码形式[11],将预制构件吊装序列表达成基因型的串结构数据。染色体由按一定顺序的多基因组成,不同基因顺序的染色体对应不同吊装序列方案。如图5所示,吊装序列为123456789,则表示同一楼层或同一施工区域内同类型预制构件吊装顺序依次为1号构件→2号构件→…→9号构件。

图5 染色体结构

适应度函数具有非负性且与目标函数相关,根据式(4),建立适应度函数,如式(5)所示:
(5)
式中:f为适应度函数值,最大适应度函数值对应的染色体代表最优吊装序列方案。
种群中每个个体依次通过选择、交叉、变异等遗传操作来实现下一代种群的产生。对于预制构件吊装序列规划,遗传操作产生的子染色体中的基因值不能重复且形成的新个体代表的吊装序列要符合预制构件间硬性约束条件,因此,采用轮盘赌选择法选择优秀个体,选择部分映射交叉算子作为实施染色体交叉操作的方法,并采用交换变异的方法进行变异操作。
采用设定迭代次数的方法终止遗传算法计算。通过反复迭代多次进化逐渐逼近最优解,当目前种群平均适应度逐渐收敛保持不变,说明遗传算法已迭代完成。
3 实例验证
3.1 基于RF的构件自动分类与编码
对随机森林(RF)、支持向量机(SVM)和K-邻近(KNN)等分类算法性能进行比较,根据分类精度(见表2),选择自动分类编码最佳算法。

表2 不同机器学习模型分类结果
原始样本集由多类预制墙基本构件数据构成,将原始样本集按8∶2的比例分为训练集和测试集,使用网格搜索法来确定学习机器最佳参数。下面的核心代码实现了随机森林的最佳数量和最大深度的参数搜索,决策树数量从20到100个搜索,最大深度从2到20个搜索。

from sklearn.ensemble import RandomForestClassifierfrom sklearn.model_selection import GridSearchCVparam_grid = [{’n_estimators’:range(20,100),’max_depth’:range(2,20)}]forest_clf = RandomForestClassifier()grid_search = GridSearchCV(forest_clf,param_grid,cv=10,scoring=’accuracy’)grid_search.fit(X,Y)
随机森林算法最佳参数为69棵决策树,最大深度为16。同理,使用相同方法可得到SVM算法和KNN算法的最佳参数,并得到最佳分类精度。不同机器学习分类结果如表2所示。在包含343个实例的测试集上进行验证,随机森林模型的F1值为0.99,相比SVM,KNN算法更有优势,因此,最终选择RF算法对混凝土预制构件进行分类。
经过机器学习将构件分类后,即可获得构件类别、名称和分类码段编号,再将楼栋、楼层信息赋予编码,流水号根据检索出的同类构件按顺序依次赋予编号。通过以上流程,即可完成对混凝土预制构件自动分类编码。
3.2 吊装序列优化
以某高层住宅装配式混凝土剪力墙结构建筑中的内墙板构件为例,对采用遗传算法计算混凝土预制构件吊装序列的方法进行实例验证。装配式混凝土剪力墙结构建筑某一预制标准层部分结构平面如图6所示。对于同类构件,预制内墙板一般按顺时针或逆时针顺序逐块吊装,在这种情况下逻辑顺序更明确且可避免施工人员间不必要的移动距离和构件间的互相干涉问题,只需考虑所占空间对吊装序列方案的影响即可。

图6 某一预制标准层部分结构平面
预制内墙板间的布局较杂乱无章,且当内墙板数量较多时可通过排列组合随机形成众多吊装序列方案,不同方案间的指标关系也有所差异,因此,更有必要对其吊装逻辑做进一步规划。预制内墙板Q1,Q2,Q3,Q4,Q5,Q6,Q7,Q8,Q9评价指标相关数据信息如表3所示。对于图7中不存在连接关系的预制内墙板(如Q2,Q3),混凝土预制构件间的距离按构件间最靠近部分的距离计算;对于存在连接关系的预制内墙板(如Q1,Q2),安装间距默认为0。混凝土预制构件所占空间按内墙板实际尺寸,相互比较得到所占空间惩罚值。混凝土预制构件间干涉关系在同一楼层或同一施工区域内仅考虑在水平面内的前、后、左、右4个方向上的移动,采用发生干涉方向数量与无干涉下的预制内墙板可安装方向数量比值来表示预制内墙板受干涉程度,受干涉程度最大的为预制内墙板Q5,Q8。Q8两端夹在Q7,Q9中间,虽然Q8仍有2个方向可自由移动,但由于预制混凝土内墙板质量和体积较大,实际安装过程中当有2个方向发生干涉,其在另外2个自由移动方向上的移动也将变得十分困难,Q5同理。当只有1个方向发生干涉,有3个方向可自由移动时,对吊装施工影响较小,且为避免约束条件太多而导致可行的吊装序列方案过少造成遗传算法过早收敛,在吊装序列方案中仅考虑避免Q3,Q4先于Q5安装及Q9,Q7先于Q8安装的情况。

表3 预制内墙板评价指标相关数据信息
为避免构件间距离和所占空间指标绝对值降低指标间的可对比性从而对算法优化结果产生影响,对指标属性值进行规范化处理,如式(6),(7)所示:
(6)
(7)
规范化处理后,T′,B′数值分别如表4,5所示。使用MatlabR2021b对上述遗传算法进行求解计算,程序运行环境为Win10/64位,12GB内存。遗传算法各参数设置如表6所示。

表4 T′ 数值

表5 B′数值

表6 遗传算法参数设置
最终计算结果为:预制内墙板吊装序列为Q1,Q2,Q3,Q5,Q4,Q6,Q7,Q8,Q9。最优个体出现在第133代,最优适应度值为1.72。遗传算法在预制内墙板吊装序列规划求解过程中每代最优解变化情况如图7所示,展现了迭代次数与平均适应度的关系。由图7可知,在迭代开始初期,解的优化效率较高,能较快趋近于最优吊装序列,随着迭代次数增加,种群平均适应度变化趋向平稳,逐渐收敛,说明遗传算法达到成熟。由计算结果可知,预制内墙板吊装序列方案具有一定合理性,符合混凝土预制构件通常沿1个方向依次吊装的吊装原则。且经过多次运算测试,所得的最优吊装序列方案始终为相近混凝土预制构件前后顺序相连,确保了混凝土预制构件内墙板就近安装及所需的安装空间。因此,此优化算法达到了预期吊装序列规划的目的。

图7 遗传算法计算结果
4 结语
在装配式建筑发展的大背景下,对预制构件智能化管理、装配施工精准化控制的要求不断提高。围绕装配式建筑吊装信息智能标注与序列优化进行了研究,首先实现对混凝土预制构件智能标注,在BIM技术基础上,通过机器学习对构件信息实现自动化编码,为目标混凝土预制构件吊装前的身份识别提供了标注基础。在混凝土预制构件吊装施工准备阶段,提出混凝土预制构件吊装序列规划模型,运用遗传算法对构件吊装序列进行规划,但仍有不足。
1)提出的基于IFC标准和随机森林的构件自动分类编码,仅针对IFCWall墙体实例进行属性提取和随机森林模型训练验证,未包括其他类型预制构件。
2)在预制构件吊装序列规划中使用的改进遗传算法,求解计算的初始种群为全局随机搜索,当装配式建筑某一层或某一施工区域需规划序列同类别预制构件数量较多时,可能会错过最优解或延长求解时间。
因此,扩充数据集预制构件类型和解决全局随机搜索的不足,将是今后的研究重点。
