数据挖掘算法在实验室信息管理系统中的应用
2023-02-24李千慧
李千慧
(1.中煤科工集团沈阳研究院有限公司;2.煤矿安全技术国家重点实验室)
煤矿安全实验室依托中煤科工集团沈阳研究院有限公司国家重点实验室建设,以煤矿安全领域重大科学问题与关键技术创新研究为核心,围绕煤矿瓦斯灾害防治、煤矿火灾防治、露天煤矿地质灾害防治、煤矿灾害应急救援4 个研究方向,构建了较为系统的研究测试平台。煤矿瓦斯灾害防治方向涵盖煤层瓦斯涌出预测、瓦斯抽采技术、煤与瓦斯突出防治,实验室主要包括煤层瓦斯涌出预测、瓦斯抽采技术和煤与瓦斯突出防治3个研究单元,涉及孔隙率测定、煤的物理化学性质分析、吸附解吸测定、工业分析、煤与瓦斯突出参数测试、微观结构分析、残存瓦斯含量测定、煤尘爆炸性测定、突出模拟、煤样制备及煤的坚固性系数测定等实验项目。
实验室在此基础上积累了一定量的原始数据,在已有的基于B/S 结构(Browser/Server,浏览器/服务器)的实验室信息管理系统上,可以进行数据的录入、查询及简单的统计等表层处理操作。面对日趋增长的实验数据,如何获得数据之间的内在联系、规则和发展趋势,最大化地利用实验数据并从中获取更深层次的价值,是亟待解决的问题。数据挖掘算法(Data Mining)[1-2]作为数据库知识发现(Knowledge-Discovery in Databases,简称KDD)中的重要步骤,有效地解决了“数据丰富,知识贫乏”的问题。数据挖掘算法能够高度自动化地分析实验得出的数据,做出归纳性的整理,从中挖掘出潜在的模式,从而帮助科研工作者或矿方服务人员调整市场策略,规避风险,并进行瓦斯突出预测、情报检索、情报分析及模式识别等研究。
1 煤与瓦斯突出影响因素与预测指标
1.1 煤与瓦斯突出危险性评价体系
我国煤炭工业发展至今,采掘深度与强度不断地加大,过去一些不突出的矿井也出现突出动力现象,这种情况出现的次数和规模也日趋变大,防治与预测突出研究仍是重中之重的工作。煤与瓦斯突出的影响因素复杂且众多,主要从瓦斯因素、煤体因素、地质结构因素、地应力因素及其他因素进行选取指标[3-4]。煤与瓦斯突出预测体系见图1。
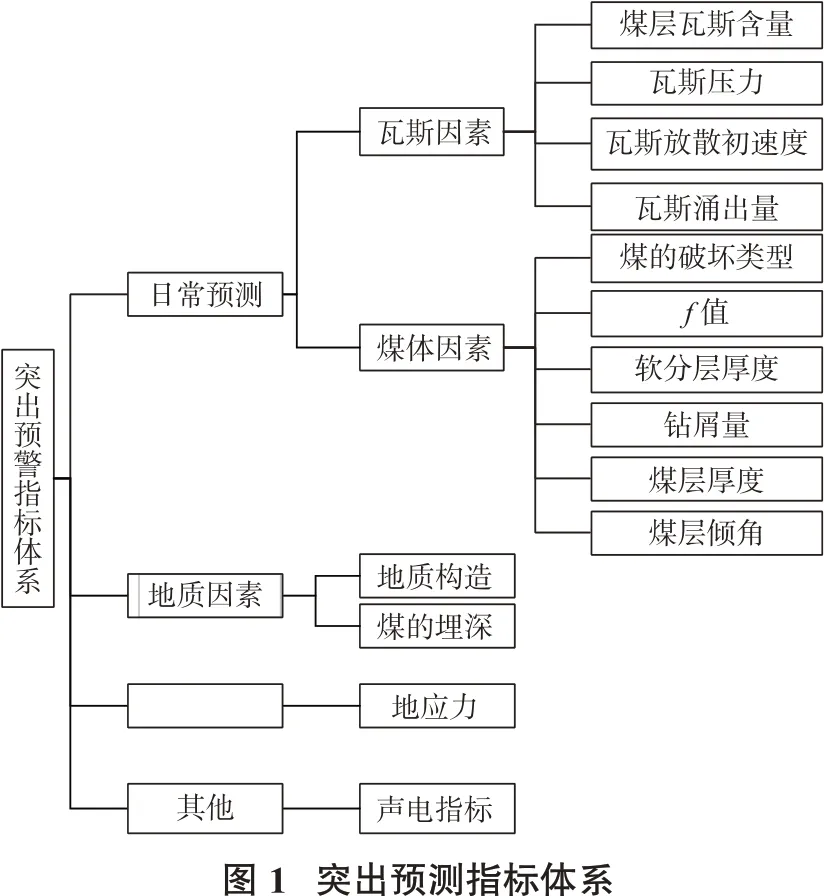
根据《防治煤与瓦斯突出规定》[5],影响煤与瓦斯突出的主要因素有煤层瓦斯压力、瓦斯放散初速度、煤的坚固性系数和煤的破坏类型等。
1.2 瓦斯突出预测指标
采掘工作面日常预测指标包括钻屑瓦斯解析指标K1、钻屑量S等。通过历史瓦斯涌出特征指标(可解吸瓦斯含量指标、瓦斯解吸速度指标、瓦斯涌出分析特征)、历史K1、S值的数据及当前瓦斯涌出特征,推算当前K1、S值。当K1≥0.5或S≥6 kg/m时,即判定危险性。对工作面日常预测指标和历史预测循环的测定数值进行综合分析,连续统计几个历史预测循环的测定数值,根据其变化趋势和幅度对工作面瓦斯突出危险进行判断,其均值超过临界指标的60%时,即进行超前预测。
由于煤与瓦斯突出机制复杂且具有一定的未知性,所以需要从多种角度分析,除了选择以上几种参数外,还应选取煤的瓦斯残存量、煤层坚固性系数、煤的瓦斯放散初速度等指标作为预测参数,表1为煤层突出危险性鉴定指标。

2 数据挖掘算法的结构和过程
数据挖掘算法[6-10]对大量相关数据进行重复地迭代处理,通过归纳分析,明确样本对象与数据之间的关系,在此过程中建立数据挖掘模型是关键点之一。图2为数据挖掘过程。

挖掘过程主要是对原始数据的特征分析,部分数据已经在实验室信息管理系统中集成。从系统中选取数据对象作为研究样本,进行预处理,控制数据范围,可达到去除冗余数据,提高数据挖掘的效率的目的。预处理一般包括数据清洗、数据集成、数据规约、特征提取、离散化处理。经过处理的数据则进入到分析方法的过程,分析方法包括关联分析、聚类分析、决策树等方法,也可进行综合利用。分析处理过的数据对象可能存在结果不明确或未达到满足评价的水平,可进行重复迭代以上的分析过程,直到得到最优值为止。
3 数据挖掘算法的应用
3.1 聚类算法原理
K-maens 聚类算法[11-16]是一种经典数据挖掘算法,首先要认定簇。簇是由空间欧式距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标,也就是选定K值。通过初始参数K值及每一类的初始聚类中心对相似的数据点进行划分,划分后的聚类中心与本聚类中其他点之间距离均值迭代优化,获得最优的聚类结果。K-means聚类算法具有计算简单、收敛速度快、处理数据量大等优点,但该算法分类结果非常依赖初始参数K的选取,由于煤与瓦斯突出机理的影响因素之前存在模糊性和不确定性,K值的选取不能够确定,故需要借助模糊C 均值法对其进行优化和改进。
3.2 数据预处理
实验数据类别和单位较为复杂,为了减少不必要的迭代次数,数据需要先进行归一化处理,处理公式如下:
3.3 K-means计算步骤
使用每个样本点(数据或对象)到该类中心的最小误差平方和函数,找出使平方误差函数最小的k个聚类,使生成的结果簇尽可能紧凑和独立。平方误差准则定义如下:
式中,E为数据中全部对象的平方误差的总和;p为空间中的点,表示给定的数据对象;mi为簇Ci的平均值(p和mi都是多维的)。
采用欧氏距离计算点之间的距离,例如选取2个样本x和y,x=(x1,x2,x3…xn),y=(y1,y2,y3…yn),其之间的距离计算公式如下:
K-means聚类算法步骤如下:
(1)初始化聚类中心,选择出k个对象(k个初始簇)。
(2)计算所有点到初始对象的最短距离距,形成簇。
(3)计算步骤(2)形成的簇中对象的均值,更新簇的中心点。
(4)迭代以上过程至更新后的中心或均值没有明显变化。
3.4 实例分析
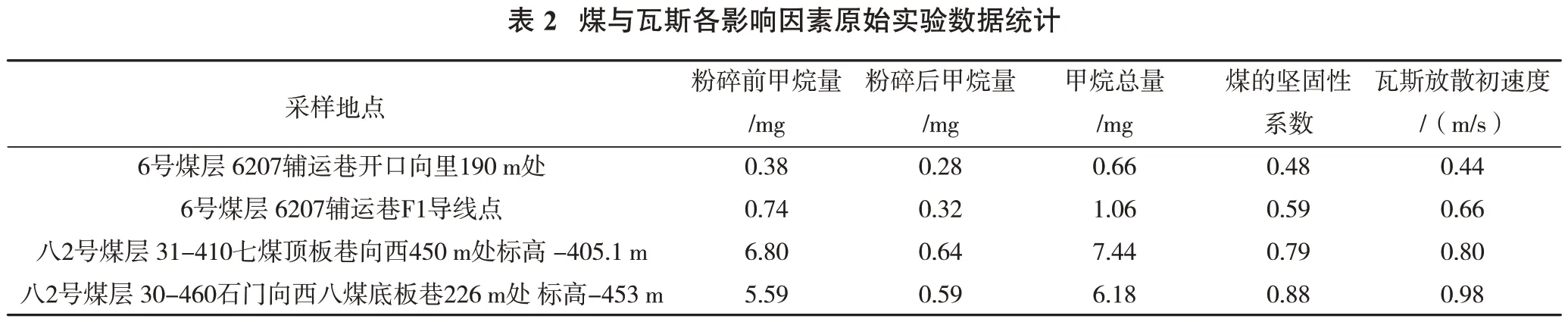
影响矿井煤与瓦斯突出的地质因素复杂多样,除了单一的非线性预测方式,还可选取部分实验项目的原始数据作为样本进行聚类分析,数据如表2所示。
#建立兰德系数,查看最佳聚类效果

#最佳聚类为6
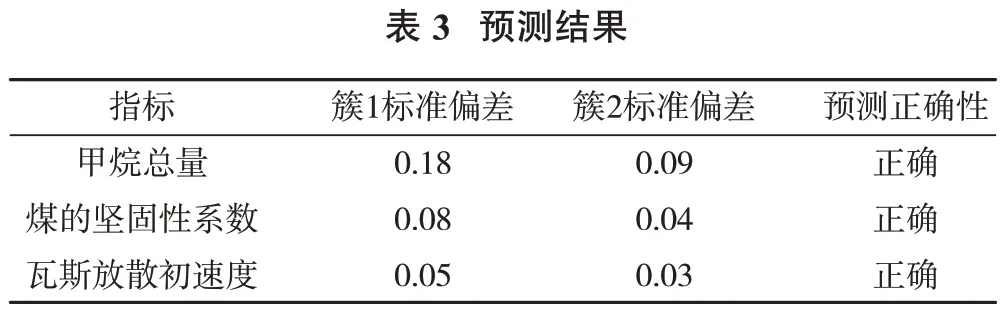
通过聚类得到各簇的标准偏差较小,其预测结果如表3 所示,可知,影响矿井煤与瓦斯突出的主要因素为甲烷总量、煤的坚固性系数和瓦斯放散初速度,与矿井实际情况相符,K-means 聚类算法行之有效。
4 结语
数据挖掘算法在实验室信息管理系统中的应用对瓦斯突出实时预测具有现实意义。
(1)能够高度集中反映煤层采掘揭露和地质勘探等手段测试的瓦斯地质信息,采掘进度和防突信息。
(2)可准确预测未开拓开采区域的瓦斯压力、瓦斯含量、瓦斯涌出量,反映矿井瓦斯赋存情况和涌出规律与瓦斯突出危险性。
(3)可以作为区域突出危险性预测和防突措施制定的依据,能够准确判断煤与瓦斯突出事故是否发生、发生强度、发生地点,指导井下职工选择合理的避灾路线迅速撤离灾区,避免造成的重大经济损失,最大限度地挽救井下职工的生命。
