基于多标准和改进Siamese网络的相似航班号判断方法研究*
2023-02-24陈一新
孙 禾,陈一新
(1.中国民航大学空中交通管理学院,天津 300300;2.中国民用航空厦门空中交通管理站,福建 厦门 361006)
0 引言
航空运输的安全高效运行离不开空中交通管理部门的有效保障,而航班号是确定飞行器身份的首要标识。在正常情况下,管制员运用标准的管制规则,并结合自身的管制经验,通过观察雷达屏幕上飞机的运动态势,呼叫相应的航班号,以对特定航班发送管制指令。在此过程中,若管制员和/或航空器驾驶员混淆(看错、听错、读错等)1 个或者多个航班号,继而错误改变航空器飞行状态,都将造成重大的安全事故。近年来,已经发生多起因航班号混淆导致的航班危险接近事件,甚至触发飞机的TA告警(空中防撞系统告警),因此研究航班号的相似性并有效量化相似度对于保障空管运行安全具有重大意义。
我国民航航班号一般由航空公司英文代码和3~4位数字组成,如CCA8227、CSN3789 等。虽然受到疫情影响,但我国民航日均航班量已超过1.12 万班[1],受限于航班号分配规则及航班量突破性的增长,依据航班号编制的规则航班号可用总量为9 896 个,显然航班号重复的情况已不可避免,航班号相似的情况愈加严重。近年来,国内外学者提出以下2 种分析方法,一是采用信息距离的方法构造航班号对应位置距离矩阵[2-3],通过对应位置灰度的深浅可以直观呈现不同航班号之间的相似程度,继而可以在音素级水平为管制员和飞行员提供区分易混淆航班号的建议;二是采用编辑距离的方法计算2 个航班号的相似情况[4],将短文本字符串进行差异性比对,通过它们之间的编辑距离分析其相似程度。但目前提出的传统方法基本局限在客观计算字符之间的变化,往往忽略对语义信息的分析[5],而在实际运行中有些相似情况是人为主观判断的,包括形似、声似等多种情况,导致主客观识别相似程度上的差异。
综上所述,航班号相似性主要存在于形似,因此针对航班号这一短文本类型数据[6]容易混淆的问题,总结民航空管系统相似航班号相关管理规定,提出基于多标准的判断准则,应用主成分分析法统一量化相似度,并进一步构建1 种改进后的Siamese网络,使用机器学习方法自动判断航班号相似性,以期提高相似航班号的识别率,减少因航班号混淆造成的运行安全事件。
1 基于规则匹配的相似航班号判断方法
目前在管制系统中,应用最为广泛也是最为简便的是基于规则匹配的方法。民航局空管局发布的《民航空管系统相似航空器呼号管制运行操作指引》[7]中有关建议和规定对判断相似航班号提供一系列匹配规则,如航班号中字符字形相似,如“I”与“1”、“O”与“0”、“S”与“5”等;航班号与其他管制用语相似,如与跑道号相似,AAR036;与机型相似,CCA330;与高度层相似,CAO270等。
针对2 个相关航空器航班号相似性,提出多项匹配规则,当2 个航班号符合匹配规则时,即可判定为相似航班号,举例如下:
1)相关的2 个航空器,航班号字符完全相同。
2)相关的2 个航空器,其一航班号可以由另一航班号全部字符重新排列顺序后获得。
3)相关的2 个航空器,航班号位数相同,且4 位航班号中3 个同样位置的字符或者3 位航班号中2 个同样位置的字符相同。
4)相关的2 个航空器,某一航班号中连续3 位字符构成的字符串包含于另一航空器呼号末尾4 位连续字符构成的字符串中。
采用基于规则匹配的方法可以简单便捷地快速识别出相似航班号,但当2 个航空器满足匹配规则时,部分会呈现高度相似性,而部分相似程度一般,相似程度难以量化,因此还需要进一步识别,以便有针对性地进行相似航班号预警。
2 基于多标准的相似航班号判断方法
鉴于航班号为5~7 位的字符串,因此可以采用基于字符的方法,计算文本之间的距离以判断2 个航班号的相似性。本文综合多个判断标准,量化得到统一的相似度。
2.1 航班号编码预处理
在计算航班号字符距离之前,首先采用One-Hot编码对航班号进行预处理,针对航空公司英文代码,编码步骤如下:
1)确定要编码的对象为航空公司的英文呼号,一共26 种类别(26 个大写字母)。
2)将英文呼号简化为有2 或3 个字母的样本,每个位置有26 种类别,字母所在的位置为1,其他位置为0,最后将其合并成为1 个完整的向量。根据26 个字母的编排约定特征排列的顺序:A-1,B-2,…,Z-26,得到稀疏编码表。
3)对稀疏编码表中全为0 的列进行删除,得到最终的紧密编码表。
本文以相似航班号“CXA8571”与“CQH8571”为例,根据One-Hot编码的规则,得到紧密编码表如表1所示。

表1 “CXA8571”与“CQH8571”的紧密编码表Table 1 Close code table of“CXA8571” and“CQH8571”
2.2 航班号之间的欧式距离
欧式距离是多维空间中任意2 个坐标的直线距离,无量纲。n 维向量空间的2 点M(x1,x2,…,xn)和N(y1,y2,…,yn)的欧式距离D1如式(1)所示:
对“CXA8571”和“CQH8571”进行欧氏距离计算,提取表1数据得到向量M,N分别为M=(1,0,1,1,0,8,5,7,1),N=(1,1,0,0,1,8,5,7,1)。
将M,N带入式(1)得到:
2.3 航班号之间的曼哈顿距离
曼哈顿距离可以解释为2 个坐标在固定的多维坐标系上的直线距离在所有坐标轴上产生的投影的距离的总和,这个距离是2 点之间在没有任何捷径下的最大距离。
n 维向量空间的2 点M(x1,x2,…,xn)和N(y1,y2,…,yn)的曼哈顿距离D2如式(2)所示:
为更好地表示相似航班号的相似程度,同样取曼哈顿距离的倒数作为相似航班号的特征之一。
针对相似航班号“CXA8571”和“CQH8571”进行曼哈顿距离计算,得到:
2.4 航班号之间的余弦距离
余弦距离通过计算任意2 个空间向量的夹角大小得到向量的相似程度。2 个向量之间夹角越大,距离越大。当2 个向量夹角为180°时,它们之间的差值达到最大;当2 个向量的夹角减小到0°时,此时2 个向量完全重合,距离最小,相似度最高。余弦距离D3如式(3)所示:
取S3=D3=cos(θ) 作为相似航班号的特征之一。
针对相似航班号“CXA8571”和“CQH8571”进行余弦距离计算,得到:
2.5 航班号之间的汉明距离
汉明距离D4表示2 个同样长度的字符串中不同字符数量。由于汉明距离比较的是文本不同的位数,因此在计算相似航班号相似度时,将汉明距离相似度记为S4=1-D4。
针对相似航班号“CXA8571”和“CQH8571”进行汉明距离的计算,经过One-Hot编码预处理后,得到:
2.6 航班号之间的文本编辑距离
文本编辑距离是将1 个字符串转化为其他字符串的最小编辑操作。规定字符串的编辑操作有以下3 种:1)将1 个元素替换成另一个元素;2)插入1 个元素;3)删除1 个元素。每1 个操作,将其步长记为1。最终得到文本编辑距离D5如式(4)所示:
式中:x代表计算出来步数;y代表最长的字符串长度。
针对相似航班号“CXA8571”和“CQH8571”进行文本编辑距离计算。首先创立1 个矩阵,矩阵的维度要在2 个字符串长度的基础上各加1;随后根据上述计算规则,每1 个元素的增加、替换、删除,都会导致步长加1;最终得到相似结果为S5=D5=2/3。
2.7 特征的主成分分析
由于判断标准不同,得到的相似度过于分散,难以得出最优解。因此,针对不同相似度计算方法得到的航班号相似度特征,采用主成分分析方法,将众多具有一定相关性的指标重新组合成1 组新的相互无关的综合指标,从而结合多个标准形成1 个统一的相似程度量化值,取各个标准之所长,便于对航班号的相似程度进行更好地识别。主成分分析步骤如下:
1)各相似度标准特征构成的原始数据矩阵X如式(5)所示:
式中:xnp为特征矩阵中的数据。
2)建立变量的相关系数矩阵R,如式(6)~(7)所示:
式中:rij代表着系数之间的相关性,当rij为0 时,表明元素之间不满足线性相关。
3)矩阵R的特征根λ1≥λ2≥…≥λp>0 及特征根所指示的单位特征向量如式(8)所示:
式中:ai为单位特征向量,i=1,…,p;api为新旧指标的单位关联系数。
4)主成分如式(9)所示:
式中:Fi表示新的指标。
5)综合性特征的主成分贡献率和累计主成分贡献率分别如式(10)和式(11)所示:
贡献率:
累计贡献率:
式中:h1,h2,…,hm为新特征的贡献值。
当综合性特征的累积贡献率达85%~95%时,特征值h1,h2,…,hm所对应的第1,第2,…,第m(m≤p)个主成分可近似表示所有的主成分结果。
对给定的500 个相似航班号对进行处理,通过主成分分析得到新特征计算结果z1~z3如式(12)所示。经过计算,新的特征值在主成分分析总得分中的权重为:λ1=0.65,λ2=0.28,λ3=0.053。
式中:x1~x5为各距离特征。
取任意10 对相似航班号,得到主成分得分如表2所示。

表2 主成分分析得分Table 2 Score of principal component analysis
通过分析实验中500 个航班对,95%以上的非相似航班号数据排序集中在[0.08,0.15]这个范围内,航班号序号分布在[1,62]之间,范围覆盖整体数据的12%,可以将其视为1 个合格的参考标准。因此当主成分相似度≥0.15 时,认为航班号相似。取一线管制单位得到的50 对非相似航班号特征值带入到提取到的450 对相似航班号特征数据集中,共计500 对航班号数据进行验证,得到识别率如表3所示。可以看到经过主成分分析后,识别率较单独1 个判定标准有所改进。

表3 相似特征标准与识别率Table 3 Similarity feature standards and recognition rate
3 基于改进Siamese网络的相似航班号判断方法
采用多标准量化的相似航班号判别方法,虽然该方法便于理解且适用范围较广,但判定的阈值需要人为设定。当阈值较大时,识别率有所提高,但相应的非相似航班号被误识的概率也会变大。因此矛盾始终存在,需要不断调整,需要采用1 种智能学习方法,自动判断航班号相似性。
3.1 Siamese网络的建立
目前很多学者对多种深度网络结构[8]进行研究,其可用于文本及图像的检测与识别[9],而Siamese网络是1 种用于相似文本检测的非线性测量学习结构[10-11],通过文本对的比对进行学习分类。同时构建结构相同权值共享的2 个网络,将2 个文本分别输入2 个网络,通过隐含层减少计算的维度,将其转换为向量,通过距离度量的方式计算2 个输出向量的距离,以此来判定2 个文本的相似程度[12]。本文所设计的模型结构共有2 个分支,如图1所示。
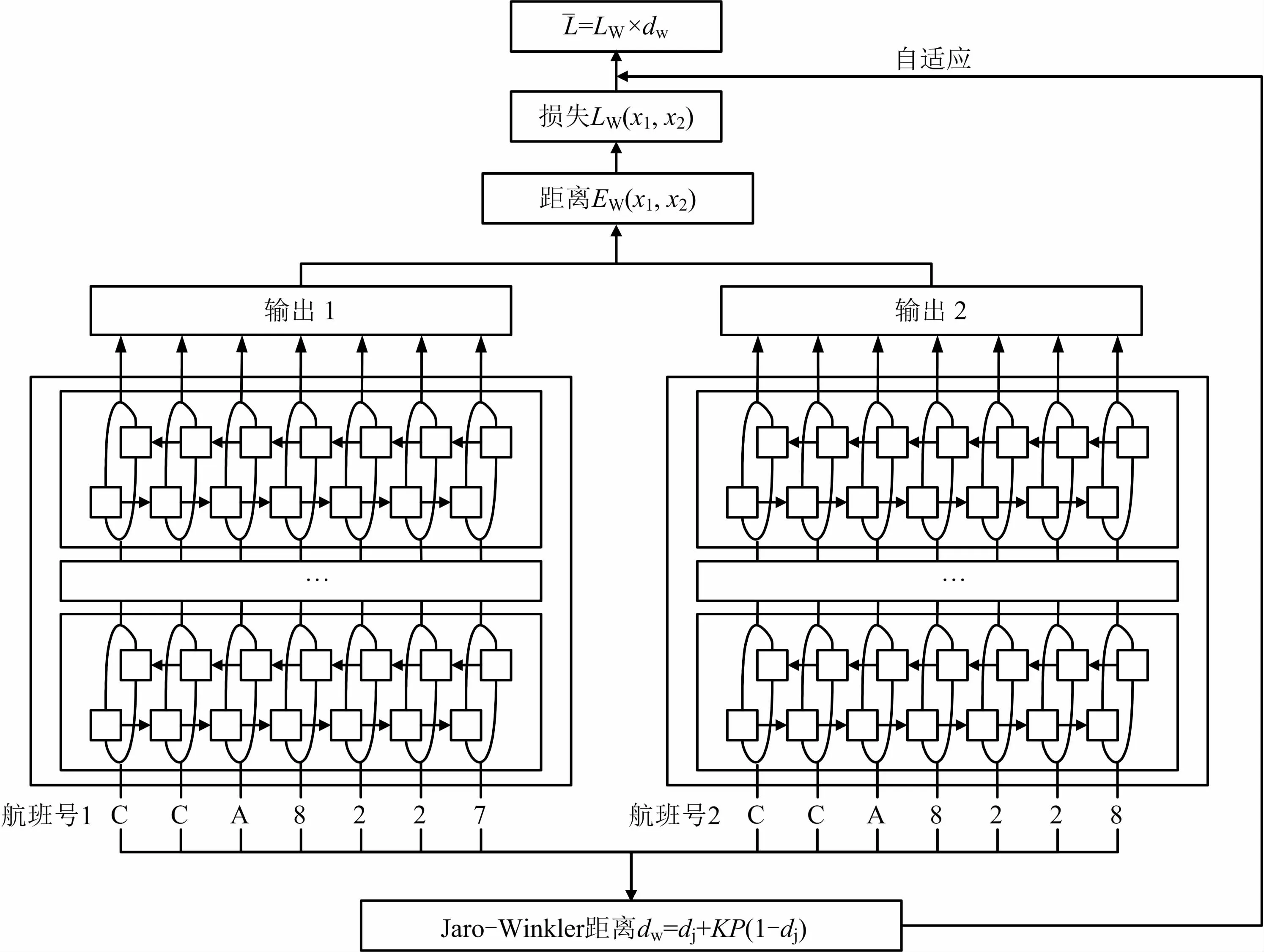
图1 自适应Siamese网络结构模型Fig.1 Adaptive Siamese network structure model
首先,建立1 个5 层的Siamese网络,输入层为航班号按位编码,一般前3 位为字母,后3 位或4 位为数字;隐含层为3 层,采用双向长短期记忆(bidirectional long short-term memory,BiLSTM)的增强网络结构,每层50 个节点,采用前馈算法;在输出层得到2 个航班号转化为向量的特征值,继而通过欧式距离计算差异值。
其次,同样针对航班号对应位的编码,计算编辑距离。根据航班号短文本英文字母+数字的特点,本文采用Jaro-Winkler距离进行计算。Jaro-Winkler距离dw=dj+KP(1-dj),其中dj表示最后得分,K为前缀部分匹配的长度,P为标准值0.1。
最后,将2 分支结果相乘,作为整个模型的损失函数进行迭代学习。相比于传统的Siamese网络,对于损失函数的修正可以在很大程度上自适应航班号之间本身就已经固有的相似情况,因此更加符合客观要求。
3.2 基于BiLSTM 的增强网络结构
网络的数据训练集为三元组(x1,x2,y),其中x1和x2为文本序列,y∈{0,1}表示2 个序列的相似程度。当2 个序列相似时,y=1;当2 个序列不相似时,y=0。这样能最小化相似文本之间的距离并最大化不同文本之间的距离。
由于传统的循环神经网络容易发生梯度消失,本文采取BiLSTM 网络结构。假设输入序列为(x1,x2…,xT),在每1 个时间步t∈{1,2,…,T},通过方程ht=σ(Wxt+Q ht-1) 更新隐含状态向量ht,其中W为输入层至隐含层权重,而Q为上一时间步的ht-1至隐含层的权重,σ(x) =(1 +e-x)-1。通过序列更新隐含层的状态,引入记忆状态mt和3 个门(输出门、输入门、忘记门),通过每一步时间的更新控制信息流,其中输出门ot决定下一节点mt的数量;输入门it决定在此步时间内输入xt的数量;忘记门ft决定上一步时间的记忆是否要忘记。网络各层参数更新公式如式(13)~(18)所示[13-14]:
式中:Wi,Qi为输入门的权重参数;Wf,Qf为忘记门的权重参数;Wo,Qo为输出门的权重参数;Wm,Qm为记忆状态的权重参数;表示中间记忆状态;mt-1表示上一时间步的记忆状态。
3.3 对比损失函数自适应修正方法
通过计算对比损失函数实现模型的反馈学习,首先计算2 个网络输出向量的距离EW(x1,x2)= fW(x1)-fW(x2)2,传统Siamese网络的对比损失函数为LW(x1,x2) =yL+(x1,x2) +(1-y)L-(x1,x2),其中L+(x1,x2)=EW2表示y=1 时的损失,L-(x1,x2) =max((1-EW),0)2表示y=0 时的损失,并且当EW大于margin 时L-=0。
但在将数据输入网络之前,已基本可以通过计算编辑距离大体获得航班号的相似情况,因此本文首先计算2 个航班号之间的Jaro-Winkler距离,使用计算结果修正对比损失函数,使网络能够自适应航班号的客观相似情况。
假设输入文本序列为x1和x2,计算Jaro-Winkler距离中最后得分,其中n 为匹配的字符数,r为换位的数目。
接着计算Jaro-Winkler距离,即当2 个文本起始部分就相同,给予更高的分数。对于航班号,起始部分代表着航空公司代码,相同公司的航班更容易混淆。
最后对网络输出向量的距离EW进行修正,所得修正后的距离,如式(19)所示:
若2 个文本之间的编辑距离较大,更接近1,说明2个文本已经较为相似,对于总的对比损失函数改变不大;若编辑距离较小,更接近0,说明2 个文本不相似,对于总的对比损失函数改变较大,从而需要进一步增加类间距离,加快算法的收敛。而对于本身编辑距离偏小而标定为相似情况的航班号,通过自适应Siamese网络学习的数据可以避免编辑距离单一衡量标准的情况。修正前后的对比损失函数变化如图2所示。

图2 修正前后的对比损失函数变化Fig.2 Changes of contrastive loss function before and after cor rection
3.4 相似航班号识别结果分析
为测试网络学习的效果与性能,分别采用不同数量的相似航班号数据训练网络结构,最终测试结果如表4所示。分析不同样本数量下,3 种相似性分析方法的识别率,如图3所示。需要说明的是,由于训练样本的不同,识别率可能会略有改变,但整体趋势基本相同。
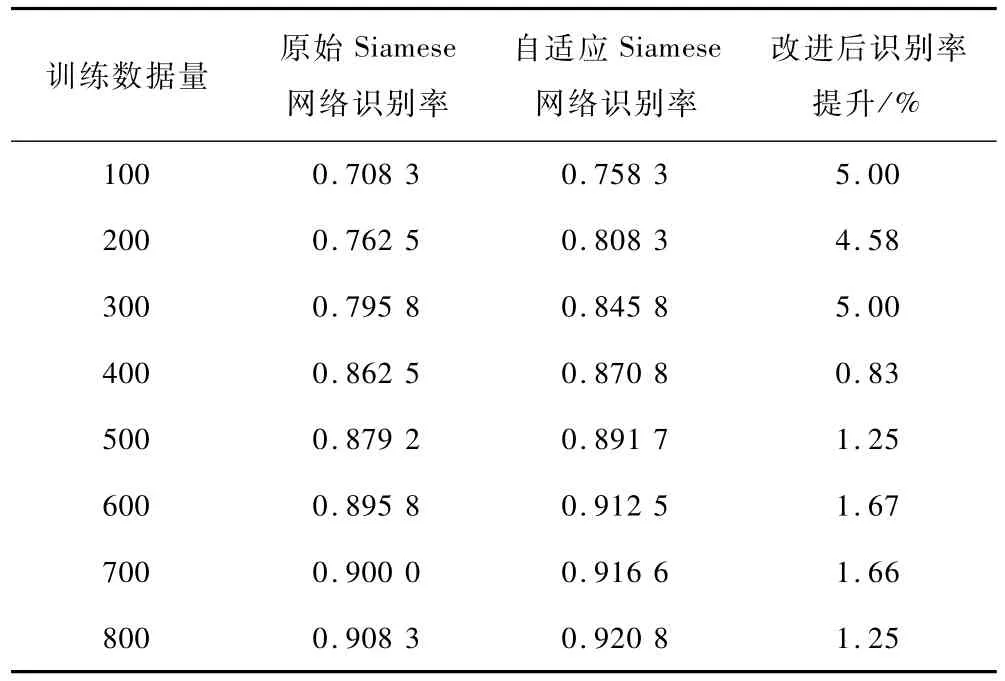
表4 相似航班号识别结果对比Table 4 Comparison of r ecognition results of similar call signs
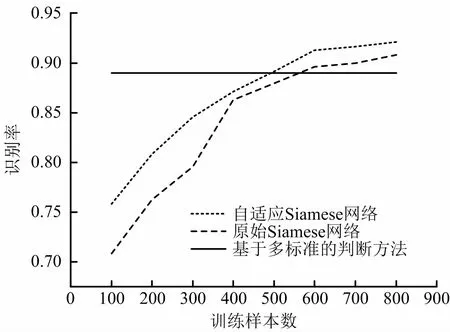
图3 不同方法的识别率变化Fig.3 Change in recognition rates of different methods
结合表4和图3可知,相比于基于多标准的判断方法,当训练数据过少时,自适应Siamese网络学习不够充分,识别率较低,而当数据有一定积累(本次实验需要约500 条训练数据)就可以突破多标准判断方法识别率上限,并且有大幅度的提高,比多标准判断准则提高约3%,说明算法有效;相比于原始Siamese网络,改进的自适应Siamese网络在相同训练数据量的情况下,识别率均大于原模型,平均提高约2.7%,说明增加编辑距离的修正可以更加准确识别航班号的相似性,并且改进后Siamese网络对小样本条件下识别率提高尤为明显,效率提高显著。
4 结论
1)相似航班号混淆是一直困扰空中交通管制员的问题之一,针对以往判定条件单一、未考虑语义的情况,本文从相似航班号规则匹配、多标准相似航班号判断、人工智能算法自动判断,层层深入分析相似航班号判断方法。
2)基于规则匹配的判断方法简便快捷,适用于快速处理的场景,但相似度难以量化,无法提供更加精细的预警;基于多标准的判断方法,结合各种常用的文本之间相似性判断标准,通过主成分分析法得到统一的量化值,适用范围广且受到样本的影响较小,缺点是判断阈值需要人为设定,识别率与误识率的矛盾始终存在。
3)基于改进的Siamese网络采用机器学习方式自动判别相似航班号,且准确率提升明显,缺点是受到训练样本的直接影响较大,对于新出现的相似航班号不够友好。
