基于粒子群算法的生鲜产品即时配送路径优化
2023-02-22李娜
李 娜
(西安财经大学 管理学院,陕西 西安 710100)
1 问题描述及变量定义
1.1 问题描述
新零售背景下,多功能生鲜超市应运而生,人们越来越注重生鲜产品的新鲜度以及配送时间的长短,本文总结相关路径优化研究现状如下,张倩等[1]在研究配送路径时,建立以配送成本,产品新鲜度,碳排放量为主的目标函数,并利用果蝇算法进行求解;肖建华[2]用变邻域算法求解多车辆多配送中心的路径优化问题;王超[3]设置软时间窗约束研究即时配送的效果,并采用了布谷鸟进化算法求解PDVRP 问题。何美玲等[4]利用蚁群算法求解软时间窗的路径问题。姚臻等[5]以客户时间窗、客户满意度、碳排放为约束条件,建立以碳排放量为基础的总成本最小目标函数,并应用遗传算法求解数学模型,得出考虑碳排放成本对于物流配送成本的重要影响。杨霞等[6]考虑生鲜产品新鲜度在软时间窗约束的条件下对车辆路径优化问题的影响,并用插点分段的方式计算两需求点的距离,建立成本最小模型。秦馨等[7]根据当前订单分批模式从订单挑选搬运次数方面比较四种聚类算法的差别,最后得出相应结论。Fahimeh 等[8]针对订单拣选和交付计划这两个重要且相互关联的环节,从订单批次拣货处理以及向配送车辆分配订单、规划路线入手,以系统成本最小化为目标进行了充分研究,最终有效降低了系统成本并提高了拣选效率。Mar 等[9]也从订单拣选和交付流程着手,对存在多个拣选配送位置的拣配问题进行研究,最终不仅减少了拣选和交付成本,还避免了闲置资源的浪费。实际生活中,订单的产生是动态且具有规模性,需要考虑订单分拣造成的时间差异对于消费者体验度的影响,因此,考虑订单分拣过程中造成的惩罚成本、新鲜度成本以及运输过程中的运输成本非常重要。
1.2 问题分析
即时配送的货物主要为小型且分散,且不同入口订单来源的需求要满足多元化需求,整体呈现出一个动态的变化过程,现实中即时配送订单分配未按照一定的规范标准,同类型以及需求点相近的产品或有特殊需求的产品用户,比如有时间窗要求或要求增值服务的,未被合理分配在一起。即时配送的货物大多为三公里之内的货物,在智能化配送未完全普及的背景下,人工配送是主要的配送方式,而人工配送的路径并未完全运用智能化算法来分析配送路径的选择以及顺序,大多依赖于配送员主观上的认知,这些在很大程度上影响即时配送效率。
1.3 模型假设
1.3.1 问题假设
生鲜产品不区分种类,按照订单分配;假设生鲜产品初始配送新鲜度以及耐腐性能无差别;配送地点产品充足,不存在因产品短缺而引起的时间浪费;挑拣人员熟悉门店环境,可以及时挑拣;配送车辆统一出发,不考虑多时段车辆配送;配送过程中始终匀速行驶,不考虑行驶路程中突发因素对车辆速度的影响;假设配送过程中不发生堵车、车祸等意外情况;配送过程中的行驶速度是恒定的,不随路况发生变化;配送过程中配送车辆温度恒定,不受其他因素影响。
1.3.2 约束条件
配送车辆从生鲜产品配送中心出发,完成配送后返回配送中心;配送中心货物充足,能满足一切订单需求;每辆车辆载重量大于当车订单需求量;配送车辆实现众包配送,但订单需求方只能由一个配送车辆完成。
1.3.3 变量设置表
订单聚类中心I,配送中心O,需求点集合M={i},i=1,2,3,…,n,配送点集合N={J},J=1,2,3,…,n,运输车辆的集合K={k},k=1,2,3,…,n,需求点i 到配送点j 的距离dij,订单i 的需求量Ri,车辆k 载重量Zk,客户可接受配送时间[Ei,Li],时间满意度程度M(t),生鲜产品在t 时间的新鲜度H(t),生鲜农产品的变质率α。
2 数学模型构建
2.1 相似性函数
由于新零售模式的影响,更多的消费者倾向于通过线上购买物品,因此产生订单的位置是多样性的,配送端需要尽可能用最少的人力、物力、财力实现即时配送。K-means 聚类算法以需求点相距距离作为相似性的评价指标,以多个配送中心和分散需求点进行聚类,其结果受到K 值选取的影响,容易超出划定的配送范围,增加寻优的复杂过程。此算法契合于即时配送确定范围内的寻优问题。
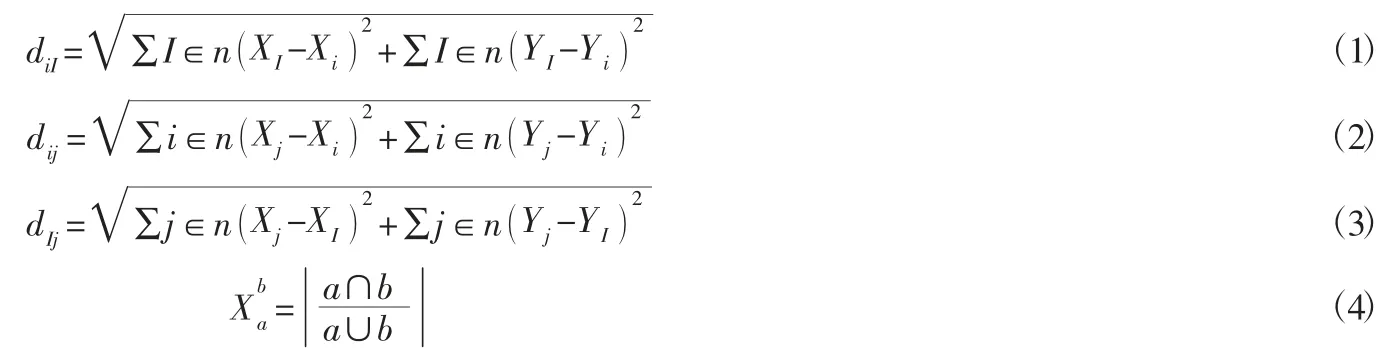
Step1:计算各需求点,配送中心,聚类中心之间相互的距离,diI表示需求点与聚类中心的距离,dij表示需求点到配送中心的距离,dIj表示配送中心到聚类中心的距离,(Xi,Yi)表示需求点坐标,(XI,YI)表示聚类中心坐标,(Xj,Yj)表示配送中心位置坐标。
Step3:更新订单位置,重新计算Step1,Step2,直至订单稳定,结束迭代。
2.2 惩罚成本
由于配送时间的限制性而产生一种惩罚成本,惩罚成本大小表示顾客对于即时配送时间的满意程度,两者之间的关系是此消彼长,密不可分的,CC表示惩罚成本,ε1,ε2表示早到或晚到客户点的时间惩罚系数,因此惩罚成本可表示为:

2.3 货损成本
产品新鲜度对于顾客的回头率具有非常重要的作用,本文引入新鲜度函数来体现生鲜农产品的货损成本,生鲜产品的新鲜度会随着配送时间和温度的变化而变化,假设生鲜超市农产品物流配送过程中可以保证产品恒温运输,α 为变质率,且为固定常数,H(t)表示生鲜农产品从配送中心O 到需求点i 中即时配送过程中发生的新鲜度变化。

当t=0 时,H(t)=1,此时生鲜农产品从配送点开始装车出发,假定新鲜度为1,经过运输过程中耗费的时间t,新鲜度逐渐下降,由此表现出递减的指数函数。
根据生鲜农产品需求量与下降的新鲜度成线性关系的假设,只考虑订单运输过程中的货损成本,P 为货物单价,α 表示生鲜产品货损率,ti表示配送车辆Ki行驶到订单i 的时间,t0表示配送车辆Ki从配送中心出发的时间,则货损成本为:

2.4 运输成本
生鲜产品从集中生产场所流入分散需求点主要通过物流配送来实现,在配送过程中成本支出最大的部分就是运输成本,运输成本始终贯穿配送的每一时刻,在企业经济效益中占据重要地位,受物流运输距离,车辆行驶速度等主要因素影响。忽略供应商到配送中心的距离,考虑从配送中心到需求点再到配送点的距离下的固定成本和车辆运输成本。
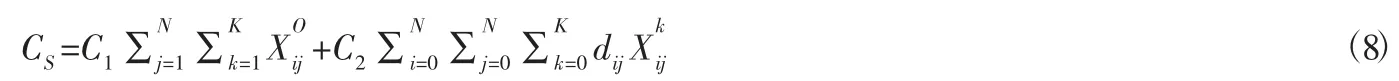
因此,建立目标函数模型:
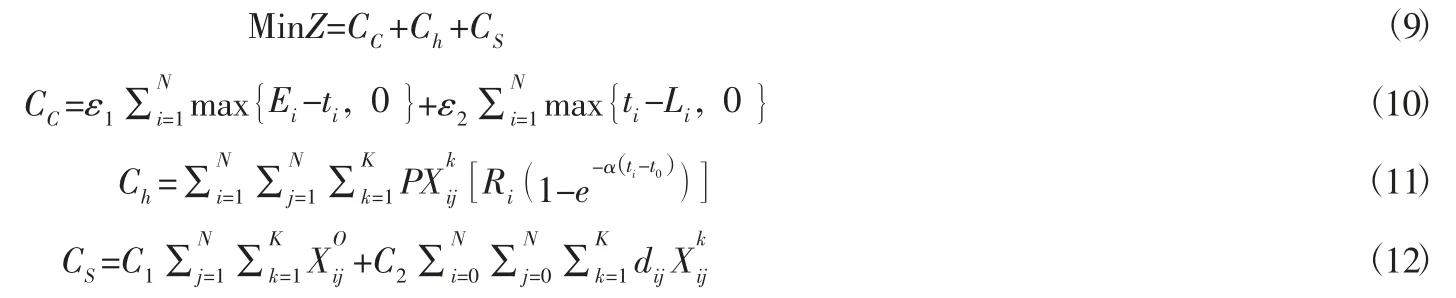
目标函数表示以总配送成本最小,具体又包括以订单分类影响的订单分类标准和配送时间,运输过程中产生的运输费用,货损费用,惩罚费用。
约束条件:

约束(13)表示多个订单需求量小于配送车辆载重量;约束(14)表示每个客户只被一个配送车辆配送;约束(15)表示车辆从配送中心出发到完成配送,并返回配送中心;约束(16)表示第k 辆配送车辆从第i 个需求点到第j 个配送点的概率,或0,1 代表配送,0 代表不配送;约束(17)Yki表示第k 辆车到第i 个需求点的概率,Yki=1 或0,1 代表配送,0 代表不配送。
3 粒子群算法模型
物流配送路径优化问题属于多变量、多目标的复杂线性问题,物流配送路径优化方法主要有精确算法和启发式算法两类。这两类方法又包含蚁群算法、遗传算法、粒子群算法、模拟退火算法以及禁忌搜索算法等,蚁群算法适用于多目标的优化问题,遗传算法适用于更复杂类型的优化问题,粒子群算法参数设置较简单,更适用于多峰高维的复杂计算问题[10-12]。但他们本身又具有一定的局限性,比如在粒子群算法全局搜索过程中易早熟收敛、陷入局部最优,需提出改进后的粒子群算法,克服粒子群算法的不足,能更好地解决配送路径问题。
3.1 粒子编码方式
在粒子群算法寻优过程中,每个粒子都代表着需求点被选的随机性,假设粒子维度v 与需求点数量n 相等,每个维度数代表相应待选择的需求点,Xi表示粒子i 的第一维编码原始值,原始值在[1,n] 内变化,相同的整数部分表示同一车辆配送,小数部分的数值大小表示配送的先后顺序,Ki表示粒子i 的第二维编码值,代表需求点选取的车辆编号,本文选取盒马生鲜12个需求点的实际位置坐标,按照数值越小越先配送的原则,进行编码排序,以配送中心作为初始聚类,则初始种群的配送方案(粒子)的编码和解码如表1 所示。

表1 配送中心与粒子间的映射关系
粒子从多个配送中心出发,逐步访问各需求点位置、时间窗要求、商品新鲜度接受程度及配送车辆最大承载量,各需求点仅被访问一次,访问结束后返回配送中心。根据粒子形成的位置记忆,对需求点订单进行顺序编码和解码,如12 个需求点和3辆配送车辆的顺序解码后形成的配送顺序分别为车辆k1配送O1-3-O1;车辆k2配送O2-2-4-5-1-10-O2;车辆k3配送O3-7-8-12-11-O3,车辆k4配送O4-9-6-O4。如图1 所示。
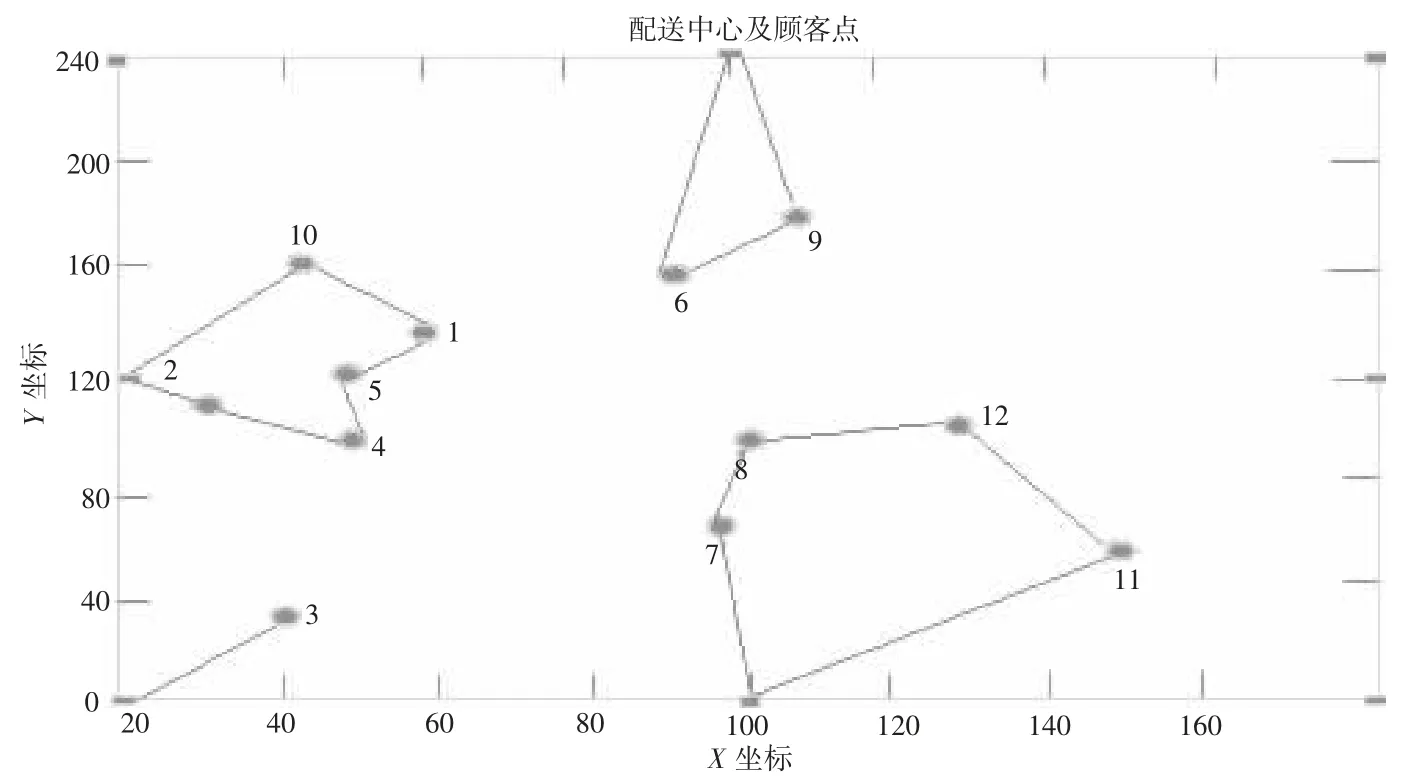
图1 多配送中心配送方案
3.2 改进粒子群算法
3.2.1 自适应惯性权重
根据K-means 把多个配送中心转化为单个配送中心求解,需求点i 到聚类中心I 的距离很大程度上是由距离惯性权重来决定的,粒子设置相应的适应度值,调整权重大小,对于路径优化有重要作用,因此适应度函数如式(18)所示:
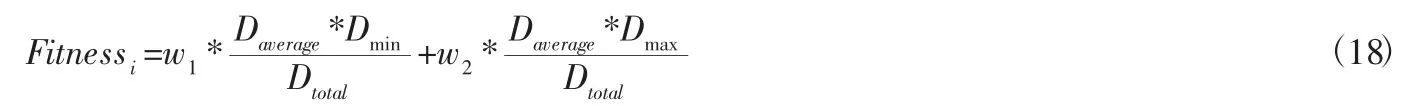
其中:w1,w2表示权重因子,且因即时配送的生鲜产品大部分为三公里之内的订单,则有w1+w2=1,w1>w2,Daverage表示需求点i 的平均配送距离,Dmin表示各需求点i 最低配送距离,Dmax表示最长配送距离,Dtotal表示各需求点i 总配送距离。
3.2.2 粒子位置,速度更新
实时更新粒子位置,速度粒子的位置和速度对于粒子群算法的选优过程占有重要地位,他们不仅能解决粒子陷入局部最优的局面,而且快速缩短寻优过程的时间以及准确度的提高,本文在更新粒子位置和速度时把订单产生的随机性考虑在内,不同的时间段会有新的订单取消和产生,更加准确设置合理的路径。
粒子位置更新:

粒子速度更新:
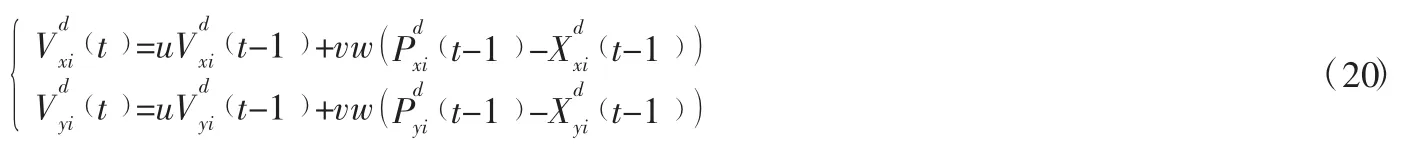
3.3 改进算法步骤
设置参数,输入需求点时间窗,位置坐标,假设车辆个数为n,求解的最大迭代次数为imax,本文取值200,当前迭代次数t=0,首先,初始化粒子的速度和位置,即明确需求点位置,根据K-means 聚类算法和订单相似性对订单进行合理划分,其次,按照上述得出的目标函数计算粒子的适应值,降低即时物流配送总成本。在相应的约束条件下得出单个粒子最优值pbest和群体最优值gbest,确定粒子初始最优解,逐步迭代,同时改进智能算法,直至迭代次数最大,完成路径优化。具体算法过程如图2所示。
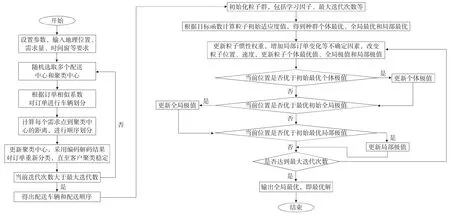
图2 算法过程
首先,对订单开始聚类分析:
Step1:输入客户基本信息,比如位置信息、时间窗要求等;
Step2:随机选取多个配送中心和聚类中心;
Step3:利用K-means 算法解锁粒子编码,根据订单相似性分配车辆,完成分批配送划分,并按照孰近原则划分先后顺序,持续更新需求点订单,直至订单相对趋于稳定,得出配送车辆和配送顺序的合理分配,否则返回Step2,重新迭代;
Step4:初始化种群,选择客户,引入算法,设置种群规模N,最大迭代次数imax,权重因子w1,w2等;
Step5:按照即时配送数学模型,计算每个粒子的适应度值,寻找种群粒子个体最优位置bpest和群体全局最优位置pbest;
Step6:更新粒子位置、速度、惯性权重,产生的个体最优和全局最优替代原来产生的个体和全局最优;
Step7:满足迭代次数,若是,则输出结果,若否,则Step6,重新执行粒子优化策略,直至迭代结束,得到全局最优解。
4 案例分析—盒马生鲜
4.1 案例基本情况
以某市某区域盒马生鲜即时物流配送为例,研究改进后的智能算法对物流即时配送的成本影响和效率影响,并提出相应意见,具体案例相关数据设置如表2、表3 所示。

表2 用户点位置和时间窗要求

表3 相关参数设置
4.2 模型求解
本文将多个配送中心配送转化成多个单配送中心出发,再利用K-means 算法选取其中一个需求点i 为聚类中心,粒子从聚类中心I 配送出发,逐步访问各需求点位置、时间窗要求、商品新鲜度接受程度以及配送车辆最大承载量,各需求点仅被访问一次,访问结束后更新需求点信息直至稳定形成位置记忆,最后返回配送中心。以需求点1 作为更新的聚类中心,解码结果如表4 所示:
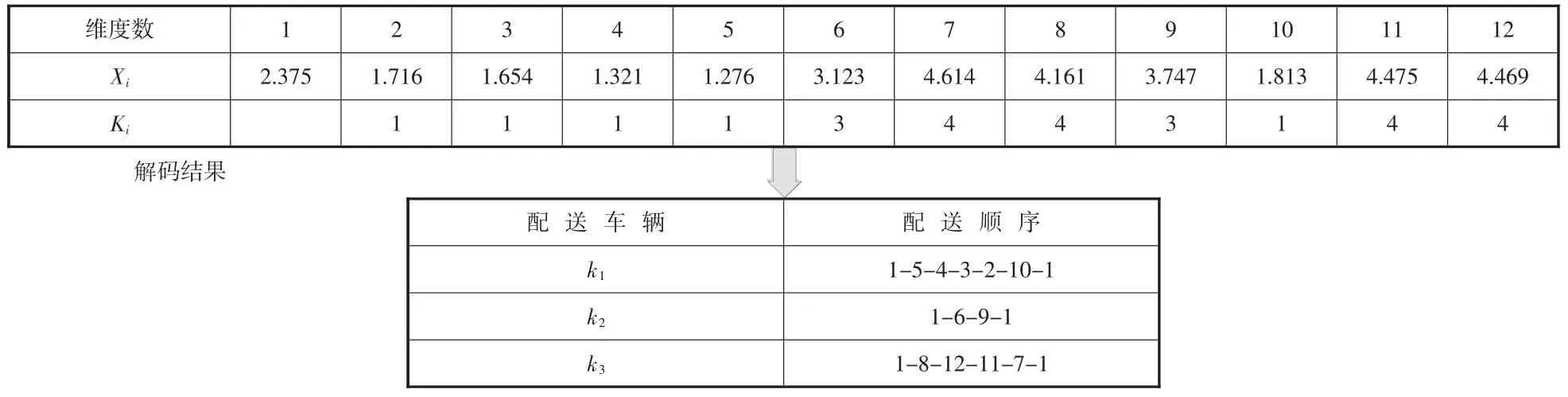
表4 聚类中心与粒子间的映射关系
根据粒子形成的位置记忆,对需求点订单进行顺序编码和解码,形成的配送顺序分别为车辆k1配送1-5-4-3-2-10-1;车辆k2配送1-6-9-1;车辆k3配送1-8-12-11-7-1,由图3 所示。

图3 聚类中心配送方式
4.3 算法比较

表5 改进算法对目标函数的影响

表6 改进算法与传统算法对比
5 结论
由此可知,注重物流运输效率、加强管理上的模式,提高物流服务质量,优化粒子适应度值,改变粒子惯性权重,更新粒子位置和速度对于粒子的寻优过程至关重要,不仅有效避免粒子陷入局部最优,同时又能保证整个寻优过程高速、准确进行,提升客户满意度,高效完成订单配送。优化订单的划分标准,注重订单的个性化服务,以及特殊需求,提高客户满意度,最终降低536 元配送总成本,提高12%的配送效率。
