全自动驾驶地铁车辆编号识别方法研究与应用
2023-02-21杨朋朋
杨朋朋
(中铁第一勘察设计院集团有限公司,陕西 西安 710043)
全自动运行系统是地铁车辆中自动化程度最高的系统,其集成了通信、信号、控制和计算机等技术,使列车实现全过程自动化运行[1]。在无人区内自动完成车辆的唤醒、自检、启动、加速、减速、巡航、惰行、停车、折返及休眠等。停车列检库是车辆停放、列检作业的主要场所,按照功能划分为无人区及检修区,每2~3股道为一检修分区,分区间采用栅栏进行物理隔离。为了取代既有人工视觉记录列车车号的方式,实现无人区自动化运维,本文提出了一种基于深度学习的地铁车辆车号识别方法。
1 研究背景
国外学者对车号识别的研究起步较早,Mullot等[2]采用纹理特征进行集装箱及汽车车牌号码的识别及定位;Keck等[3-4]提出了集成计算机视觉系统,该系统主要用于列车监控视频数据的采集、处理和压缩。在国内,魏永胜等[5]设计了车底残留物检测、体积计算及车号识别系统;王欣蔚[6]提出了基于卷积神经网络的车号识别方法,在分析动车组车号图像特点的基础上,采用深度学习算法对列车车号进行字符分割及识别;王晓锋等[7-8]采用机械视觉方式进行车号识别。现有车号识别系统主要针对铁路货车,采用人工方式记录车号,缺少自动化识别方式。本文基于目标检测的YOLO算法,针对全自动驾驶车辆基地,提供了一种完善的车号识别方法,并通过工程实践对该方法进行了验证。
2 基于深度学习的车号识别
深度学习是机器学习的分支,是一种以人工神经网络为架构,对数据进行表征学习的算法。
2.1 目标检测模型
目前常用的目标检测算法可分为两类,一类是R-CNN 系列的Two-stage算法,需先使用选择性搜索算法[9](selective search algorithm)或 CNN 网络(如 RPN)来产生 Region Proposal,然后在候选框上进行目标分类与位置回归[10];另一类是One-stage算法,包括SSD以及YOLO算法等。相比而言,One-stage算法占用计算机资源少,计算速度较快,但准确率相对于Two-stage 算法较低。目标检测不仅要解决图片的分类,同时要对目标内容进行准确定位。表1选取典型目标检测模型进行了性能对比分析。结合全自动驾驶模式特点,为实现作业流程的智能卡控,节约计算资源,本文采用算力要求相对较低的YOLO算法。

表1 典型目标检测模型性能对比表
YOLO算法将输入的图像划分成S×S个单元格,当目标几何中心落入到某个单元格时,该单元格负责对目标进行检测。其他各单元格预测D个边界框置信度,D为数据集中被识别划分的类别数量,置信度为待检测目标的概率与该边界框和真实位置交并比(IoU)的乘积,用来表征预测位置回归精度。置信度Confidence计算公式为:
(1)
式中:Pr(Object)为方格中目标存在的概率。Pr(Object)的取值如下:
(2)
每个方格即每个单元实际预测的是方格的大小、位置及置信度,共包含5个预测值(x,y,w,h,Confidence),其中(x,y)为方格几何中心的坐标,w,h分别为该方格长、宽与整张图像长、宽的比。假定(x,y,w,h)取值均为0~1。分类时YOLO算法对所有方格的类别进行概率预测,假定方格类别为C,此概率是基于方格可信度下的条件概率值,以Pr(Classici/Object)表示,每个边界框的置信度计算公式如下:
(3)
设概率的阈值k=0.5[11],通过设置阈值剔除置信度较低的方格。综上所述,每个方格包含5个预测值,每张图像包含S×S个方格,因此每张图像的预测值为S×S×(D×5+C)。
2.2 硬件部署方案
由于停车列检分区检修通道宽度需满足简易高空作业车通行,因此车号识别系统硬件无单独立柱安装条件。段内车辆行驶速度大于20 km/h,为了保证获得准确的车号信息,机器视觉系统安装于运用库A端司机登车平台南侧,采用可调节吊杆机构吊装,保证镜头以最佳视觉拍摄车辆车号区域,具体安装位置如图1和图2所示。

图1 机械视觉安装位置平面图

图2 机械视觉安装位置三维图
2.3 车号区域模型训练
1)数据集与图像的预处理。
设定相机拍摄速度为0.01 s/次,随机提取相机在不同检修分区捕捉到的2 000张车号图片,其中包含部分车号不全、角度不对正等存在多种缺陷的图片。为了增加深度学习的数据量,结合车辆基地现场条件,采取以下2种方式对图像进行增强:1)旋转,将每一幅训练样本图像分别旋转-3°和3°;2)添加噪声,对每一幅训练样本图像随机添加高斯噪声。
经过数据增强,样本量由2 000张增加到8 000张,将这些样本分为训练、验证和测试3个样本集,各样本集中图像的选取由随机数函数产生的随机数来决定。
2)模型训练。
分别使用YOLO V4 和YOLO V4 tiny模型对同一数据集进行训练。
3)评价指标。
①准确率。
对于一个N类任务,输出为一个N维向量,向量的每一个位置代表了一种类别,对应位置的值为预测目标属于该类的概率。假设A物体与B物体分类的输出向量为[m,n],如果m>n,则输出为A物体,反之为B物体。
②损失。
引入交叉熵损失函数,交叉熵损失函数输出的是正确标签的似然对数,和准确率有一定的关系,但是取值范围更大。交叉熵损失公式如下:
(4)

假设训练样本量为n,则交叉损失函数(Θ)为:
(5)
本文采用准确率(accuracy)和损失(loss)两个参数对检测结果进行评估,分析结果如图3所示。
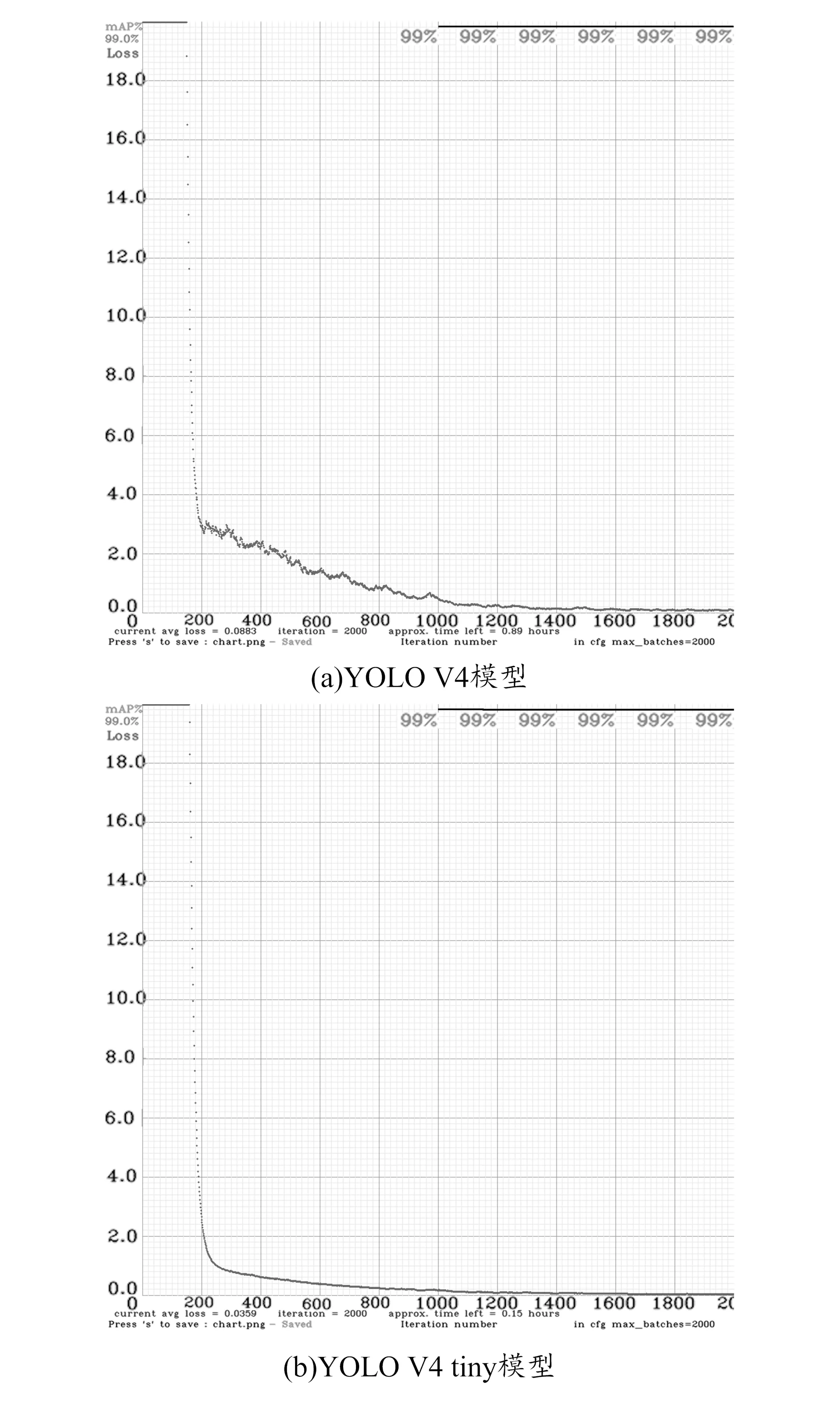
图3 平均损失-准确率变化曲线图
图3中细线表示迭代周期与准确率的变化,粗线表示准确率。由图可以看出,随着模型训练次数的增加,平均损失趋于零,准确率趋于1,说明模型预测值与对应的标签值越接近,模型的准确率也就越高。两个模型对车号区域的识别准确率都较高,区别在于YOLO V4 tiny模型容易将生活环境中的非车号图形误识别。由于应用中相机视野固定,不会拍摄到杂乱图像造成误识别,而YOLO V4 tiny模型的实时性更好,因此本文选取YOLO V4 tiny模型进行车号识别。
2.4 预处理
为了提高计算效率,减少计算资源占用率,增强算法的鲁棒性,对图像编号区域提取前先对地铁车辆车号类型及相对位置采用机器学习,选择完整车号图片,对车号区域进行预处理,原始车号图像如图4所示。

图4 原始车号图像
1)图像裁剪。
目标检测程序从视频中获取完整车号画面,从原始图像中截取包含完整车号的最小图像,如图5所示,去除噪声的干扰。

图5 除噪声前的车号图像
2)二值化。
采用特定的灰度值T作为阈值对图像进行二值化处理,二值化后输出的图像g(x,y)可表示为:
(6)
式中:f(x,y)为原图灰度函数值。
参考文献[12],取T=127,当像素值小于T时,设为0,即黑色;当像素值大于T时,设为255,即白色,二值化后的图像如图6所示。

图6 二值化后图像
3)形态学处理。
由于部分线路位于地面之上,地铁列车运营时不可避免沾上泥土、灰尘等,因此车号可识别度相对于初始状态会有一定程度的降低,为了消除外部杂质对车号识别的影响,需对车号区域进行形态学处理。
①膨胀。
根据二值图像,将原车号图像区域沿着目标区域边缘扩大一周,使外部环境误断开的目标行合并连通。对于图像集合A以结构元素B进行膨胀的运算表示为A⊕B,计算公式如下:
(7)

②腐蚀。
与膨胀相反,腐蚀使边界向内收缩,将粘连在一起的不同目标分离,同时消除出现在图像里与目标区域不连通的孤立点,这些点往往是毛刺或者阈值分割后被误认为目标的背景像素点[13],对于图像集合A以结构元素B进行腐蚀的运算表示为AΘB[12],计算公式如下:
AΘB={z|(B)z∩Ac≠Ø}
(8)
式中:Ac为集合A的补集。
通过膨胀、腐蚀后的二值化图像分别如图7和图8所示,程序识别结果如图9所示。

图7 膨胀后的二值化图像

图8 腐蚀后的二值化图像

图9 程序识别结果截图
2.5 结果评价
训练样本数量n=2 000,训练样本识别结果及准确率见表2。

表2 样本训练数据统计表
由表可知,准确率大于99.74%,因此该模型满足了3σ设计原则,结果可靠。
3 结束语
为了进行较高速度行驶下的全自动运行车辆车号识别,本文结合现场条件将车号识别机械视觉安装于运用库A端司机登车平台侧面处,为了保证镜头以最佳视觉捕捉到车辆车号区域,单独设计了可调节吊杆结构。对比分析YOLO V4与YOLO V4 tiny模型对车号区域识别的准确性,采用YOLO算法对形态学处理完的图像进行字符识别,识别准确度大于99.74%,满足3σ原则,从而验证了训练模型以及算法的可靠性。
