考虑竞争传播的社交网络虚假信息反转研究
2023-02-21张亚明苏妍嫄李欣悦
张亚明 苏妍嫄* 李欣悦
(1.燕山大学经济管理学院,河北 秦皇岛 066004;2.燕山大学互联网+与产业发展研究中心,河北 秦皇岛 066004)
我国媒体多元化、社交性的发展倾向使得网民参与社会事件讨论的热情日益高涨,信息传播环境也因此发生了新变化,各类传播新现象层出不穷,虚假信息反转现象就是在此背景下产生的。所谓信息反转,是指人们对某一事件的态度、评价向对立面反转并集聚的现象[1],这一过程反映了事件的发展演变过程,因此对事件的完整呈现具有积极的推动作用。近年来,社交网络平台虚假信息频繁涌现,严重搅乱了网络舆论场的生态平衡,并产生了较强的负面影响。例如,一些当事人对初始消息恶意编撰,故意博取流量引爆热点,严重消磨了公众情感,消耗了公共资源;一些不良居心网民恶意煽动,信息传播过程中常充斥着网络暴力和言语攻击,使得当事人承受着巨大精神压力;还有部分媒介公开消息失真、失实或是进行错误倾向引导,导致媒介公信力受到质疑、舆论生态环境失衡。由此可见,社交网络虚假信息传播给政府舆情监管增加了很大难度,尤其负面情感通过网络迅速蔓延扩散,还会造成信任丧失、舆论环境紊乱,甚至可能危及正常的社会秩序。因此,将虚假信息反转作为研究对象,通过构建模型剖析反转规律与特点具有重要意义。
1 文献综述
信息反转已经成为近几年频繁发生的一种新型网络传播现象,该词最早出现在我国新闻传播领域,指信息扩散过程中出现的报道倾向、情感倾向突发逆转的现象[2]。目前相关研究重点主要集中于3个方面:
一是针对虚假信息反转特点,探究成因并提出应对策略。王雅倩[3]从传播主体、传播客体、传播符号3个方面分析了虚假信息反转的成因,并通过列举反转事件典型案例进行了相关因素分析。廖梦夏[4]提出了解释虚假信息反转成功的探索性分析框架,用fsQCA方法对2013—2019年43个典型反转事件进行了系统分析,结果表明框架化是对反转成功解释力最强的条件。通过众多学者对媒体传播特征的研究,总结来说,标签化的题目、浮夸娱乐化的报道、争求新闻首发性的不良风气,以及当前人们的碎片化阅读倾向,都是产生虚假信息反转的重要因素[5-11]。
二是探究虚假信息反转传播机制及演化路径。Guo L L等[12]采用模式匹配与机器学习的方法对社交网络平台数据进行情感分类和计算,建立了网络信息波动监测机制,监测、分析其波动与反转情况。Jiang G Y等[13]考虑官方新闻滞后性和公众摇摆心态,建立了两阶段谣言传播模型,探索突发公共事件中谣言逆转动态机制。Hou J D等[14]考虑个人社会权力及政府能力等多种异质性,以改进动态模型描述冲突环境下虚假信息的反转过程。Chen T等[15]通过模拟实验发现,信息强度、个人关注度及个体保护对虚假信息反转过程的影响。Xiao R B等[16]基于HK模型考虑自然反转参数和意见互动对个人观点选择行为的影响,探究了这种社会现象的潜在机制并揭示其动态特征。谢雪梅等[17]构建网络反转监管三方演化博弈模型,分析了知情者、媒体、政府的策略选择。霍梦雯等[18]以戈夫曼的框架生成和社会心理学的群体极化理论视角为切入点,分析事件反转、分化过程来明确反转发生机制。孙翠平[19]描绘虚假信息反转演化规律与整体态度倾向性,提出了两种反转类型,从动力学角度对网络空间竞合传播机制进行了深入研究。黄传超等[20]基于Deffuant与CODA模型,分析了认知偏差与无界信任对个体观点决策的影响,构建了个体选择行为与信息传播动态模型,探讨了不同条件下的个体认知特征。
三是构建虚假信息反转预测模型。其中,田世海等[21]将自媒体信息反转要素层次化后,对其进行定量评价,构建了预测模型的贝叶斯结构并结合实例进行了仿真。夏一雪等[22]分析虚假信息反转预测机理,构造反转度指标,确定反转评估等级,为虚假信息治理决策提供理论支持。袁野等[23]通过识别虚假信息反转的风险因素,采用聚类分析和判别分析法构建了反转分类与预测模型,并利用SPSS 21对虚假信息反转案例样本进行合理性验证。田俊静等[24]将近几年的反转事件作为样本集,利用其描述属性和分类属性建立决策树模型,并采用测试集对决策树模型的分类性能进行评价,确定模型的精确度和可用性。
针对虚假信息反转现象的文献梳理可以看出,许多研究都集中在新闻传播学领域以及社会心理学领域,主要是定性分析其成因、特点及传播机制等问题,对相关主体提出切实可行的治理建议。虽然已经有部分学者尝试用各类定量模型对虚假信息反转现象背后的规律进行探索,但未能很好地解释清楚反转演化过程中多重信息竞争传播及治理策略选择变化,以及不同因素对主体策略选择的具体影响。因此,本文综合考虑社交网络虚假信息反转现象传播的影响要素,构建考虑竞争传播的社交网络SIR-HK虚假信息反转模型,同时以“高考答题卡疑被掉包事件”为例,对模型有效性进行验证,并进一步利用MATLAB进行数值仿真,分析有无虚假信息、真相信息出现时间及信息可信度等因素对虚假信息传播和传播者观点演化的影响。
2 考虑竞争传播的虚假信息反转动态演化模型构建
2.1 信息传播过程
2.1.1 参与主体
人群不同特质会影响其对信息的信任程度[25]和微博负面虚假信息的转载行为[26],借鉴SIR模型中传播主体的设计,将虚假信息反转中的主体划分为3种状态:易感者(Susceptible)即未参与但有可能参与虚假信息传播的群体,其人群密度用S(t)表示;感染者(Infective)即那些参与虚假信息传播的群体,其人群密度用I(t)表示;康复者(Recovered)即对事件失去兴趣且不再传播的群体,其人群密度用R(t)表示。
2.1.2 双重信息
在虚假信息反转过程中,信息传播具有冲突性、阶段性,即整个过程有多个可能存在真假相互对立的信息在传播,并且这些信息可能陆续出现,在不同阶段分别传播。在部分传染病中也能找到类似的规律,如艾滋病病毒感染者分为急性阶段、无症状阶段和艾滋病阶段,不同染病阶段患者的传染率等特性存在很大差别。因此,借鉴宋瑞等建立阶段性传染病模型的建模思想[27],对SIR模型进行改进,其基本传播状态转移示意图如图1所示。假设在传播阶段一,只有包含虚假信息的初始信息出现,在人群中传播,并影响他们所表达的观点。在传播阶段二,包含真相的信息成为人群中的主要传播对象,分别用αi和βi表示向感染者(I)和康复者(R)的转移概率。

图1 信息传播状态转移图
2.1.3 信息竞争传播规则
本文设定社交网络虚假信息反转过程中,仅存在两条相互冲突的真相信息和虚假信息,考虑到信息传播的衰减性,感染者参与信息传播将优先传播最新消息,并且不会受先前初始消息的影响。因此,对于参与了传播阶段一又再次参与传播阶段二的二次感染者,设定其在传播阶段二将不保留在阶段一的传播数据,根据计算规则重新计算相关参数。
该模型仅设两阶段,若针对更加复杂的案例进行仿真,比如某信息存在多阶段多次反转的情况,可以按照该思想继续对模型进行扩展。在初始信息传播的阶段一,分别用α1和β1表示在初始消息的影响下易感者向感染者(I1),感染者向康复者(R1)的转移概率。阶段二在真相信息出现后,已经感染过的康复者(R1)可能重新成为感染者(I2)的概率为α2,而感染者(I2)退出信息传播成为康复者(R2)的概率为β2。
阶段一的动力学方程表示如式(1):
(1)
阶段二的动力学方程表示如式(2):
(2)
且有:
(3)
2.2 观点交互过程
2.2.1 初始观点值
如上文所述,本文假定整体传播过程中存在代表不同观点立场的虚假信息M1和新出现的真相消息M2,其预设观点倾向分别用A与B表示,数值为1或-1,二者相互对立。个体的观点倾向首先取决于所接触到信息的观点倾向Nk,在这个过程中,还受到观点可信度μk与自身素质指数εi(εi~U(0,1))的影响,素质指数越高,对信息真伪的辨别能力越强。以式(4)作为初始观点值的计算方式。考虑到信息传播的过程具有衰减性,在研究中假设参与传播主体的观点取决于其所接触到的最新消息。
(4)
2.2.2 主体影响力
用户在社交媒体平台既可以快速浏览传播的信息,还可以不设限的浏览相关的评论互动,浏览者会受到这些评论互动中观点倾向的影响,此时观点的交互关系更类似于一个无向的全连通网络,但并不代表所有用户所持的观点都会影响到浏览者。经典HK模型综合考虑了节点的从众心理和有限信任原则,将节点的观点演变过程全部归因于其观点阈值之内其他节点观点的影响,这一假设比较符合社会实际,但在虚假信息传播演化过程中,主体的观点交互还受到其他个体影响力大小的影响。以微博为例,所有话题的评论以热门程度和发表时间两种方式排列,但在默认的情况下,越热门的评论位次越高(由点赞数和二级回复数决定),对于绝大多数人来说,都会优先浏览默认排序下的热评,并会受到其观点倾向的影响,排序越低的评论,被浏览到的几率越低,影响其他人观点的概率也越低。
因此,本文对HK模型进行优化,添加影响力指数作为参与主体筛选交互邻居的标准之一,影响力越大的感染者,越容易让其他感染者持有与他相同的观点倾向。根据刘志明使用微博数据对网络结构的分析结果,微博信息传播中用户的影响力大小符合幂律分布。基于此,本文在构建观点演化规则的过程中,考虑参与信息传播主体的影响力大小Infi,以符合幂律分布的影响力矩阵代表所有感染者在观点交互过程中的影响力大小,影响力越大的节点,其所持观点越容易影响其他节点。
式(5)是将一组符合均匀分布随机数转化为一组符合幂律分布随机数的公式,由此可以得到一组符合任意分布幂的随机数。图2是一组分布幂为1.5的随机数,可以看出根据幂律分布的特性,影响力大的节点占比较小,影响力小的节点占比较大,这符合上文所分析的现实中在线社交平台上观点交互规律。
(5)
其中y是均匀变量,n是分布幂,x0和x1定义分布范围,X是幂律分布变量。

图2 分布幂为1.5的主体影响力指数随机分布结果
2.2.3 观点交互规则
综上所述,本文假设观点在社交媒体平台上的交互过程中,个体观点同时受到观点相近节点以及较高影响力节点的影响,由此确定选择进行观点交互的邻居的筛选规则如式(6):
Ni(t)={1≤i≤N|θ(|Xj(t)-Xi(t)|-ζ)+(1-θ)(Infi-Infj)<0}
(6)
其中Ni(t)表示节点i在时刻t时的观点交互邻居集合,ζ表示观点阈值,本文中设定ζ=0.5,θ表示为个体选择观点交互范围时,观点阈值条件所占的比重。设置节点j对节点i的影响力aij公式如下,其含义为节点j的影响力在节点i观点交互范围Ni(t)内所有节点网络影响力之和的比例。
(7)
对观点影响指数进行归一化处理,得到观点影响力权重:
(8)
综上,可得到最终社交网络虚假信息反转中传播主体的观点交互规则,其中ρ为感染者对自身上一单位时刻观点的坚持度,ρ∈[0,1]。
Ii(t+1)=ρIi(t)+(1-ρ)∑wij×Ij(t)
(9)
2.3 SIR-HK模型构建
在信息传播规则的基础上,依据改进的SIR模型可以得到任意时刻各主体的传播状态,分别为易感者(S)、感染者(I)和康复者(R),同时感染者作为传播信息的参与者,在传播过程中又有不同的观点倾向,并且会在传播中互相影响,进行观点交互,因此在传播者动态变化的过程中,以观点动力学HK模型刻画感染者(I)观点倾向(观点A或观点B)的变化过程,信息传播规则和观点演化规则的内部逻辑关系如图3所示。

图3 信息传播规则和观点演化规则内部逻辑关系示意图
3 考虑竞争传播的SIR-HK虚假信息反转模型仿真与分析
为了更好地研究社交网络虚假信息反转过程中的信息传播和观点交互传播规律,利用MATLAB软件进行仿真实验研究。
3.1 模型算法步骤
考虑竞争传播的SIR-HK虚假信息反转模型基本算法步骤如下:
Step1:数值初始化,确定参与信息传播总人数为N,分别选取服从[0,1]均匀分布的随机数和服从[0,1]幂律分布的随机数作为个体的素质指数与影响力指数。
Step2:基本参数设定,设置信息观点值、信息可信度、主体之间转化概率、观点交互阈值等相关基本参数。
Step3:主体传播状态确定,通过上文的信息传播规则,确定各时间节点主体的传播状态(S、I或R)。
Step4:感染者观点值计算,通过上文的观点交互规则,确定各时间节点参与信息传播的感染者(S)的观点值。
3.2 基于“高考答题卡疑被掉包事件”的模型有效性验证
3.2.1 “高考答题卡疑被掉包事件”发展过程
2022年7月22日,网民@冰雨Icerain369(爆料学生家长苏某)在微博上发表博文(博文已删除),称自己的女儿高考试卷被人偷梁换柱,但并未引起大范围的关注。8月5日,微信公众号“波动财经”发表题为《河南四家长质疑考生答题卡掉包,纪委介入检察官实名举报教育厅信息不公开高招舞弊》的文章,在网络上引起热议。8月7日,河南省招生办公室在其官网发布《致全省招生考试战线同志们的一封信》一文,声明4位考生的考卷答题卡已被多次抽看对比,认定字迹相符,@紫光阁、@人民日报、@中国新闻网等博主对此进行转发,因事件真相出现反转,又有多个主流媒体微博账号进行转发传播,致使相关信息传播量在当天达到顶峰。
3.2.2 数据获取与处理
根据知微事见网络舆情案例库显示,该事件影响力指数为72.7,高于86%的社会类事件;微博影响力指数为77.6,高于91%的社会类事件;前后共计79家重要媒体参与,其中,央级媒体占69.0%,高于94%的社会类事件。由于该事件涉及“高考”“教育公平”“暗箱操作”等众多触及大众敏感神经的标签,因此在网络上引起轩然大波,甚至让人一度怀疑高考的公平性。
本研究中参与信息传播人数的数据来源于知微事见案例库,具体如图4所示;观点变化的数据来源于根据新浪微博#高考答题卡疑被掉包#、#高考答题卡疑被调包后续#等相关话题下的热门微博下的用户评论。从数据的可得性方面来说,网民@冰雨Icerain369(爆料学生家长苏某)在微博上所发博文由于已经删除,且未在网络上引起大范围的讨论,因此无法获取相关评论数据。因此,本研究通过相关话题检索,在微博上搜索2018年8月6日22时—8月9日21时全部热门微博,并根据“高考答题卡疑被掉包事件”的发展脉络,综合考虑各博主的粉丝数量、新闻报道时效性以及相关微博评论数量,从热门微博中找出各个阶段最具影响力的微博,并根据发布信息所持观点倾向进行分类,结果如表1所示,进而爬取相关微博评论数据作为分析各阶段网民观点的文本数据来源。

表1 社交网络信息传播各阶段最具影响力的微博
采用Python爬虫功能爬取以上微博评论共7 024条,经过数据清洗、删除不相关及重复评论后,得到数据3 924条。对以上所有评论按照时间顺序进行排列,采用人工标注的方法对每条评论的内容进行观点值标注,设置认为高考答题卡存在掉包以及参与传播初始信息的自媒体及相关主流媒体的观点为负值,设置认为不存在高考答题卡掉包情况以及官方调查结果的观点为正值,客观理性(如提出建议、理性分析、客观报道、观望)的观点值为0,并在此基础上根据观点强硬程度进行细分,针对初始信息,令轻微质疑绝对值取值为0.1、0.2、0.3分,中度质疑绝对值取值为0.4、0.5、0.6分,严重质疑绝对值取值为0.7、0.8、0.9、1分;对于真相信息,评论中一般相信绝对值取值为0.1、0.2、0.3分,中度相信绝对值取值为0.4、0.5、0.6分,绝对相信绝对值取值为0.7、0.8、0.9、1分。因发酵速度非常快,因此以1个小时作为一个观点监测区间,将一天划分为24个区间,分别计算各个监测区间的平均观点值,得到“高考答题卡疑被掉包事件”的平均观点演化图如图5所示。

图5 实证案例社交网络信息观点交互过程
3.2.3 模型有效性验证
图4和图5展示了“高考答题卡疑被掉包事件”中信息传播和观点交互的实际演化趋势,根据实际情况得出改进的SIR-HK模型的参数:初始时刻各类型占网民总数的比例为S(0)=0.95、I1(0)=0.05、R1(0)=0、I2(0)=0、R2(0)=0,主体之间的转化概率α1=0.45、β1=0.15、α2=0.4、β2=0.15、α3=0.05、β3=0.15;虚假信息可信度μ1=0.8;真相信息可信度μ2=0.9;真相信息1出现时间tm1=25,真相信息2出现时间tm2=50,进而得到信息传播与观点演化的仿真结果如图6和图7所示。对比两幅图可知,SIR-HK虚假信息反转模型仿真模拟曲线与实际数据得到的趋势图基本吻合,这说明本文构建的模型具有一定的有效性。

图6 信息传播过程模型仿真结果
3.3 数值仿真分析
为进一步探索社交网络虚假信息反转规律,采用控制变量法进行数值仿真模拟。基本初始值设定为:初始时刻各类型用户比例为S(0)=0.95、I1(0)=0.05、R1(0)=0、I2(0)=0、R2(0)=0,主体之间的转化概率α1=0.3、β1=0.1、α2=0.1、β2=0.1;虚假信息M1观点倾向N1=-1,可信度μ1=0.9;真相信息M2观点倾向N2=1,可信度μ2=0.9;真相信息出现时间tm=30,个体对自身上一单位时刻观点的坚持度ρ=0.4。

3.3.1 有无虚假信息对虚假信息反转过程的影响
1)信息传播过程。若社交网络平台没有虚假信息出现,则整个过程只有真相信息参与传播,相反若有虚假信息出现,则虚假信息与真相信息在网络上先后出现并传播。代入上述参数数值可得到两种情况下社交网络信息传播达到平衡时各人群所占比例,如图8、图9所示。其中,横轴表示演化时间,纵轴表示各主体所占比例。从演化时间来看,有虚假信息传播过程的弛豫时间明显更长,需要更长的时间才可达到传播稳定状态。从主体比例变化情况来看,两者的易感者变化趋势相同,但在真相信息出现后,有大量的康复者重新加入传播过程中成为感染者并开始传播相关信息,推动相关话题继续发酵,使得感染者人数再度增长。

图8 无虚假信息作用下信息传播过程
2)观点交互过程。使用观点交互规则模拟两种状态各时刻的感染者所表达观点的动态变化如图10和图11所示。由于观点交互后期,参与观点交互的感染者人数越来越少,如果仅有几人,将可能出现平均观点非常极端的情况,此时数据不具有参考意义,针对这种情况予以人工平滑拟合或删除。

图11 虚假信息作用下观点交互过程
可以看出,在无虚假信息的情况下,参与信息传播的感染者的观点经过一段时间的交互后很快达到平衡,且观点平均值与其所传播的信息所持观点倾向全程保持一致。在存在虚假信息的情况下,感染者首先受到虚假信息的影响,持有与其倾向相同的观点,在真相信息出现后,感染者所持观点开始迅速动摇并开始反转,直到与真相信息所持观点倾向保持一致,且在信息传播到达稳定后,观点交互仍然在继续,可以视为针对该信息相关的讨论和观点表达仍然没有平息。
两种情况对比可知,虚假信息的存在不仅会扩大感染者的规模,吸引更多的网民参与到相关话题的讨论中来,进而增强话题讨论热度,还将延长信息传播的弛豫时间、增加观点交互的时间,进而大幅延长信息传播生命周期。同时,参与讨论人数的增加与传播周期的延长还会增加次生舆情出现的可能性。除此之外,网民的观点在真相信息出现后发生反转的结果也可以得出以下结论,即虚假信息的存在可能是导致社交网络话题观点反转的重要影响因素。
3.3.2 真相信息出现时间对虚假信息反转过程的影响
1)信息传播过程。为了进一步分析真相信息出现时间对社交网络虚假信息反转过程的影响,令其他参数设定值不变,分别设定真相信息出现时间tm=25、30和35,进而观察信息传播过程参与主体的状态变化,结果如图12所示。可以看出,真相信息出现时间对弛豫时间的影响并不是很大,真相信息出现用时较长的情境拥有稍长的弛豫时间。然而需要注意的是,真相信息出现速度越快,出现后参与传播的感染者绝对数量越多,对照现实中的信息传播案例,出现这一结果可能是由于此时正是社交网络话题发酵速度高涨阶段,突然出现所持完全相反观点倾向的真相信息对人们的冲击,比话题快要消退时再出现真相信息对人们的冲击要大得多,在更大的冲击下,人们加入社交网络信息传播、表达观点的欲望也就更强烈。
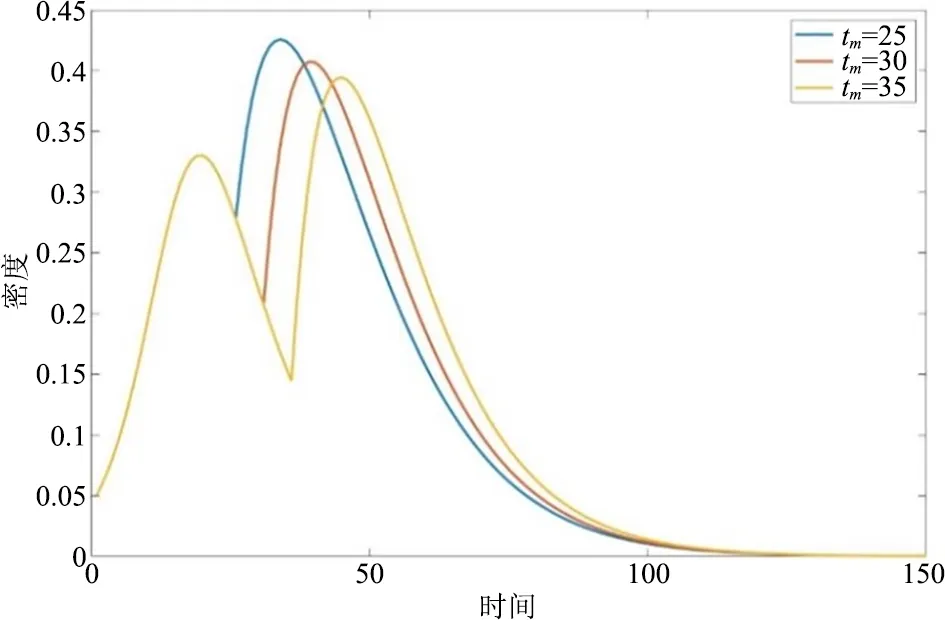
图12 真相信息出现时间对社交网络信息传播过程的影响
2)观点交互过程。图13刻画了真相信息不同出现时间下感染者所持观点的变化情况。对比不同的情境,从观点反转过程所需时间来看,真相信息出现时间越早,观点反转速度越慢,转变过程越温和。根据图像粗略估计tm=35与tm=25这两种情境的反转速度,发现前者比后者快了近一倍。从观点的极端性来看,真相信息出现时间越晚,“观点极化”现象越明显,如在图13中,tm=35的情境无论是在真相信息出现前还是真相信息出现后,其观点平均值的绝对值都较其他两种情境更大。

图13 真相信息出现时间对观点交互过程的影响
综上所述,真相信息出现的时间对弛豫时间影响不大,但会影响参与信息传播的感染者数量,且出现时间越早,感染者绝对数量越多。对观点交互过程来说,真相信息出现越早,观点反转过程越温和,“观点极化”现象越不明显。因此,可以得出结论,如果初始信息有部分不真实或者滞后的信息,需要真相信息来纠偏,那么发布真相信息的速度越快,越有利于社交网络虚假信息的管控,越不容易出现网民观点极端化的现象。
3.3.3 信息可信度对社交网络虚假信息反转过程的影响
人们接受社交网络中的信息时,会先判断其可信度来决定自己所持观点。本文设定虚假信息与真相信息具有不同可信度的4个情境(具体数值如表2所示),分别为虚假信息高可信度、真相信息高可信度,虚假信息高可信度、真相信息低可信度,虚假信息低可信度、真相信息高可信度,虚假信息低可信度、真相信息低可信度,通过相应的数值仿真,来研究信息可信度对感染者观点交互过程的影响。

表2 信息可信度情境设定
图14为4个情境下观点的动态交互结果,可以看出,只有在两条信息都为高可信度时,感染者才会更愿意相信相关信息所持的内部观点倾向;如果虚假消息是低可信度,即使真相信息为高可信度,人们也不愿意相信真相信息所持的观点倾向;如果虚假信息是高可信度,真相信息是低可信度,那么在真相信息出现后,人们也会逐渐对真相信息所持观点失去信任;若虚假信息和真相信息都为低可信度,那么在真相信息出现后,人们对于信息所持观点的信任程度会比初始信息所持观点的信任程度更低。

图14 信息可信度对观点交互过程的影响
由此可以看出,人们对于信息的信任是非常脆弱的,但凡有一条信息的可信度较低,就会打破整个信息传播过程中建立起来的所有信任度,尤其在社交网络虚假信息反转过程中,发布信息所持观点的不断摇摆本来就易降低网民的信任,如果再裹挟难以让人信服的内容,将进一步降低网民对所传播信息观点的信任,如果信息来源于官方政府,会让网民产生对政府公信力的质疑;如果信息来源于网络媒体,则会大大降低网民对相关网媒的好感,造成舆论风波。
3.4 虚假信息治理对策启示
根据上述仿真结果可知,竞争传播使得社交网络整体感染者规模不断扩大,信息传播弛豫时间逐渐延长,感染者观点更易发生反转,且观点交互时间也日益增加。真相出现时间越早,社交网络整体感染者绝对数量越多,观点反转过程越温和,相反则“观点极化”现象越明显。传播过程中,当出现可信度较低的信息时,即使之后出现了可信度较高的异质信息,主体也将不再给予较高的信任度。根据上述研究结果,可围绕政府、媒体、网民3类主体得到如下虚假信息治理对策启示。
1)政府应构建科学高效的虚假信息监测预警系统,有效引导舆情走势。第一,快速响应,缩短信息传播真空期。相关事件发生后,政府应以灵敏的“嗅觉”定位公众关注的“焦点”,针对核心问题快速排查、规范整治、及时通报,建立有效的问题反馈与解决机制,缩短权威信息的真空期,压缩虚假信息的传播空间。第二,积极作为,把控网络舆情发展方向。政府要充分发挥公权力的管控优势,通过微博发布政务信息,对社会关切热点问题进行积极回应,与网民良性互动,进而把控网络舆情治理主动权,降低舆论危机爆发风险。第三,事后复盘,治理社会根源问题。社交网络虚假信息反转事件结束后,政府有关部门应当及时进行全流程梳理,从传播走势、应对举措以及处置效果等角度进行全流程回顾,做好虚假信息处置效果评估总结工作。
2)媒体应第一时间核实事件来龙去脉,保障信息真实性、专业性、完整性。第一,去伪存真,保障信息真实性。媒体作为从事信息生产和发布的专业节点,是规避虚假信息的关键一环,因而要保持较高的专业水准和职业素养,严查信息源头,客观报道事实真相。第二,设置议题,保证内容专业性。媒体要全面设置报道议程,对新闻生产、传播渠道、传播效果等各个方面加以控制,坚持正确舆论导向,塑造权威可信的媒介形象。第三,及时跟进,推动信息有效闭环。官方等权威媒体要及时跟进发布结果,以实现信息传播的有效闭环,减少舆论对公检机关执法不力的质疑,降低公众产生“没有处置”“没有管理”的不良观感。
3)网民应不断提高自身素质,有理有据倒逼事实真相。网民是社交网络虚假信息反转过程中最活跃的主体,而高素质网民群体能够在虚假信息反转的整个过程中发挥直接积极的作用。第一,冷静客观,避免情绪化“输出”。社交网络虚假信息反转过程中多伴随负面情绪化特征,网民应提高警惕,冷静客观地看待事件,避免只靠主观臆断,以刻板印象进行角色代入,先入为主笃定“站队”发出非理性言论。第二,提高素质,有理有据倒逼真相。社交网络信息来源多元、真假混杂,网民应当加强自身媒介素养,强化责任意识,谨慎对待自己发布、转发的每一条信息,不传谣、不信谣,倒逼事实真相。
4 结 语
新媒体时代,社交网络虚假信息频繁涌现严重搅乱了网络舆论场生态平衡,并给政府舆情监管增加了难度,社交网络虚假信息反转成为亟待解决的重要科学问题。本文将SIR传染病模型与HK观点动力学模型相结合,构建了考虑竞争传播的社交网络虚假信息反转模型,同时以“高考答题卡疑被掉包事件”为例,对模型有效性进行验证,并进一步通过数值仿真分析揭示社交网络虚假信息反转规律。研究发现,虚假信息的出现将扩大感染者的规模,延长信息传播弛豫时间,并促使感染者观点发生反转。真相信息出现时间对弛豫时间影响不大,但会影响参与信息传播的感染者数量,且出现时间越早,感染者绝对数量越多,观点反转过程越温和,“观点极化”现象越不明显。此外,传播过程中较低可信度的信息将影响主体对后续信息的信任。
鉴于此,综合以上理论成果并结合中国国情得出以下启示:①政府应构建科学高效的虚假信息监测预警系统,快速响应缩短信息传播真空期,积极作为,把控网络舆情发展方向,并做好事后复盘,治理社会根源问题;②媒体应第一时间核实事件来龙去脉,科学分析,精准判断,以保障信息真实性,合理设置议题,保证内容专业性,并及时跟进,推动信息有效闭环;③网民应不断提高自身素质,遇事做到冷静客观,避免情绪化“输出”,进而有理有据倒逼事实真相。
