专用数据处理器综述*
2023-02-20刘忠沛吕高锋王继昌杨翔瑞
刘忠沛,吕高锋,王继昌,杨翔瑞
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
伴随着数据中心的不断发展,通信能力和计算能力成为数据中心基础设施紧密相关的2个重要发展方向。如果数据中心仅关注计算能力的提升,忽视通信基础设施的提升,那么数据中心的整体系统性能仍然会被限制。数据处理器DPU(Data Processing Unit)的提出背景就是应对数据中心的数据量和复杂性的指数级增长带来的性能瓶颈。它是新近发展起来的专用处理器的一个大类,是继中央处理器CPU(Central Processing Unit)、图形处理器GPU(Graphics Processing Unit)之后,数据中心场景中的第3颗重要的算力芯片,为高带宽、低延迟、数据密集的计算场景提供计算引擎[1]。
DPU可以作为CPU的卸载引擎,为上层应用释放CPU算力。例如,进行网络协议处理时要迅速处理10 Gb的网络需要大约4个Intel Xeon CPU核,相当于占去一个8核高端CPU的一半算力。如果考虑更高速度的网络,CPU算力的开销将会更大。Amazon把这些开销都称之为“数据中心税”——还未运行业务程序,先接入网络数据就要占去的计算资源。未来,需要将计算移至接近数据的位置,这是目前业界所公认的以数据为中心的体系结构下的创新。
DPU市场仍处于初步发展阶段,厂商对DPU的定义也各不相同[2 - 6]。目前市场上主流的DPU定义是NVIDIA提出的,即DPU是集数据中心基础架构于芯片的通用处理器。DPU的出现是异构计算的一个阶段性标志。与GPU的发展相似,DPU也属于应用驱动的体系结构设计;然而DPU面向的应用更加底层。它包含了:(1)行业标准的、高性能及软件可编程的多核CPU,基于ARM架构的占大多数,并与片上系统SoC(System on a Chip)组件共同工作。(2)高性能网络接口,能以线速解析并处理数据,高效地将数据传输到GPU和CPU。(3)各种灵活和可编程的加速引擎,可以卸载人工智能AI(Artificial Intelligence)、机器学习、安全、电信和存储等应用,以达到更高性能。(4)拥有开放性集成功能,将来可以集成更多功能。例如NVIDIA计划在之后的Bluefield-4[3]产品中,将GPU集成到DPU中,进而完成数据中心架构的终极整合。(5)NVIDIA DPU的软件开发包DOCA(Data center Infrastructure On a Chip Architecture)提供了统一的面向各种应用的编程接口,使用户注意力不必放在DPU的底层硬件接口而是直接对硬件进行编程。
综上,DPU可以在数据中心中通过更明细的分工来提升系统效率,实现总体成本最优化。本文首先介绍了DPU技术并与网络处理器NP(Network Processor)进行对比;然后基于运行至终结RTC(Run To Completion)模型与流水线(Pipeline)模型分析了DPU的硬件架构,介绍了目前业界的DPU产品、DPU的编程模型与DPU的应用;最后总结并展望了DPU未来的研究发展方向。
2 DPU体系结构
对DPU来说,核心问题是基础设施的“降本增效”,就是把“CPU处理效率低下、GPU处理不了”的负载卸载到专用DPU,提高整个计算系统的效率,降低整体系统的总体拥有成本TCO(Total Cost of Ownership)。DPU是体系结构朝着专用化路线发展的又一个标志。DPU最直接的作用是作为CPU的卸载引擎,接管各种基础设施层服务,释放CPU的算力到上层应用。
2.1 DPU处理模型
传统的NP转发模型可以分为RTC模型和Pipeline模型。RTC模型与Pipeline模型如图1所示。从名字上就可以看出,Pipeline模型来源于工业中的流水线模型,将一个功能(大于模块级的功能)分解成多个独立的阶段,每个阶段间通过队列传递产品。这样,对于一些CPU密集和输入/输出I/O(Input/Output)密集的应用,通过Pipeline模型,可以把CPU密集的操作放在一个微处理引擎上执行,将I/O密集的操作放在另外一个微处理引擎上执行,以此来达到最好的并发效率。
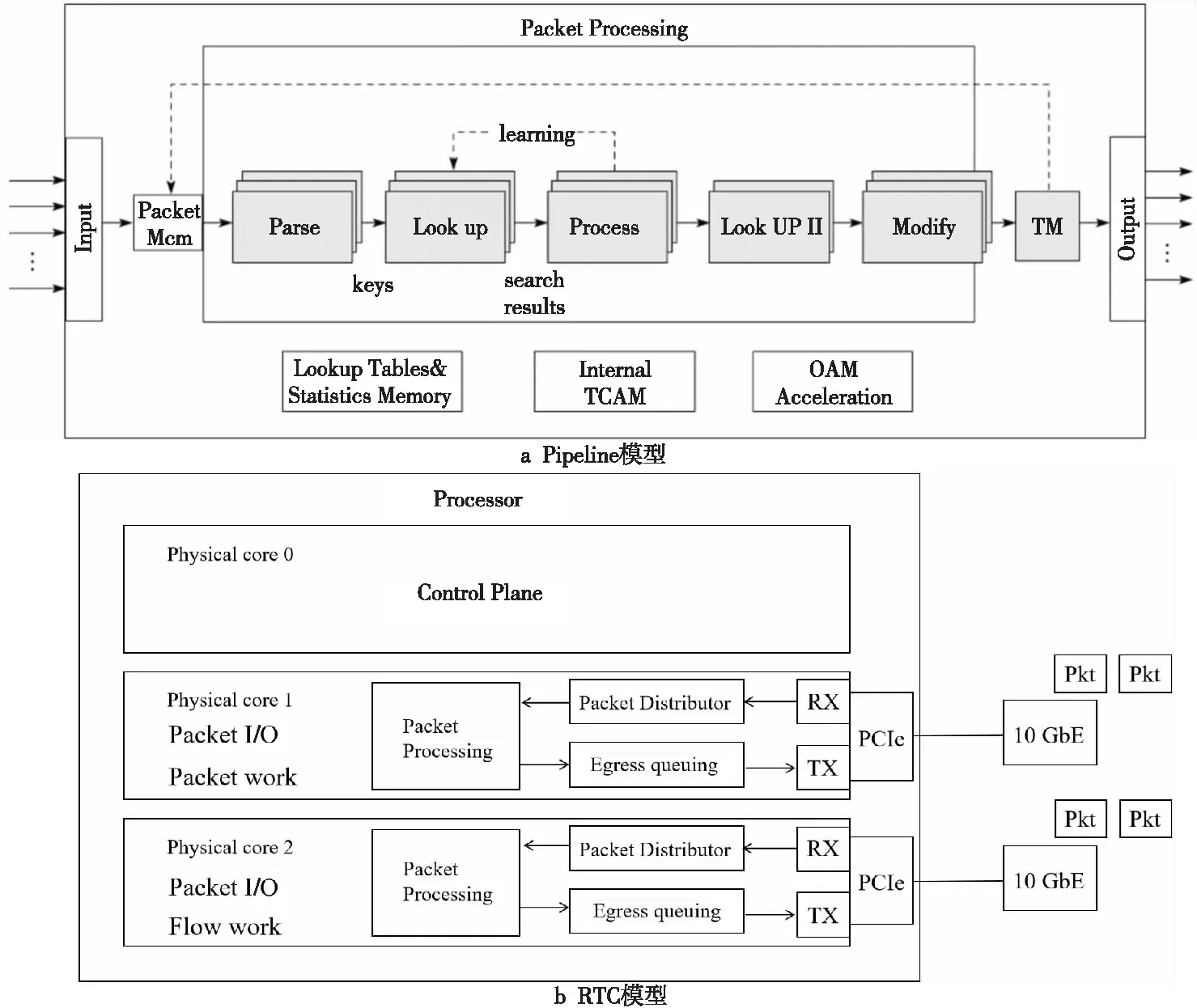
Figure 1 Pipeline model and RTC model图1 Pipeline模型与RTC模型
RTC模型是主要针对数据平面开发套件DPDK(Data Plane Development Kit)一般程序的运行方法[7],一般会将一个程序分成几个不同的逻辑功能,然而这些逻辑功能会在同一个CPU核上运行,CPU核通过指令调用对应的硬件资源来运行程序。水平扩展可以在系统的多个核上执行一样逻辑的程序,以此提高事务处理效率。但是,由于每个核上的处理能力大致相同,并没有针对某个逻辑功能进行优化,因此在这个层面上与Pipeline模型相比,RTC模型并不高效。RTC与Pipeline模型的对比如表1所示。

Table 1 Comparison between RTC and Pipeline表1 RTC与Pipeline的对比
无论是对于可编程交换机还是智能网卡(Smart NIC(Network Interface Controller))来说,数据平面的可编程性都是重要的发展趋势。针对当前交换芯片和OpenFlow协议中的2个限制:(1)“匹配-动作”处理仅限于在一组固定的字段上进行;(2)仅定义了有限的包处理动作集,提出了RMT (Reconfigurable Match Tables)模型[8],这是一种新的基于精简指令集计算机RISC(Reduced Instruction Set Computing)的流水线架构,用于交换芯片,确定了基本的最小动作原语集,以指定报头在硬件中如何处理。RMT允许在不修改硬件的情况下通过修改匹配字段更改转发平面。与在OpenFlow中一样,设计者可以在资源允许的范围内指定任意宽度和深度的多个匹配表,每个表经过配置后具备在任意字段上进行匹配的能力。然而,相比于OpenFlow,RMT允许更全面地修改所有报头字段。
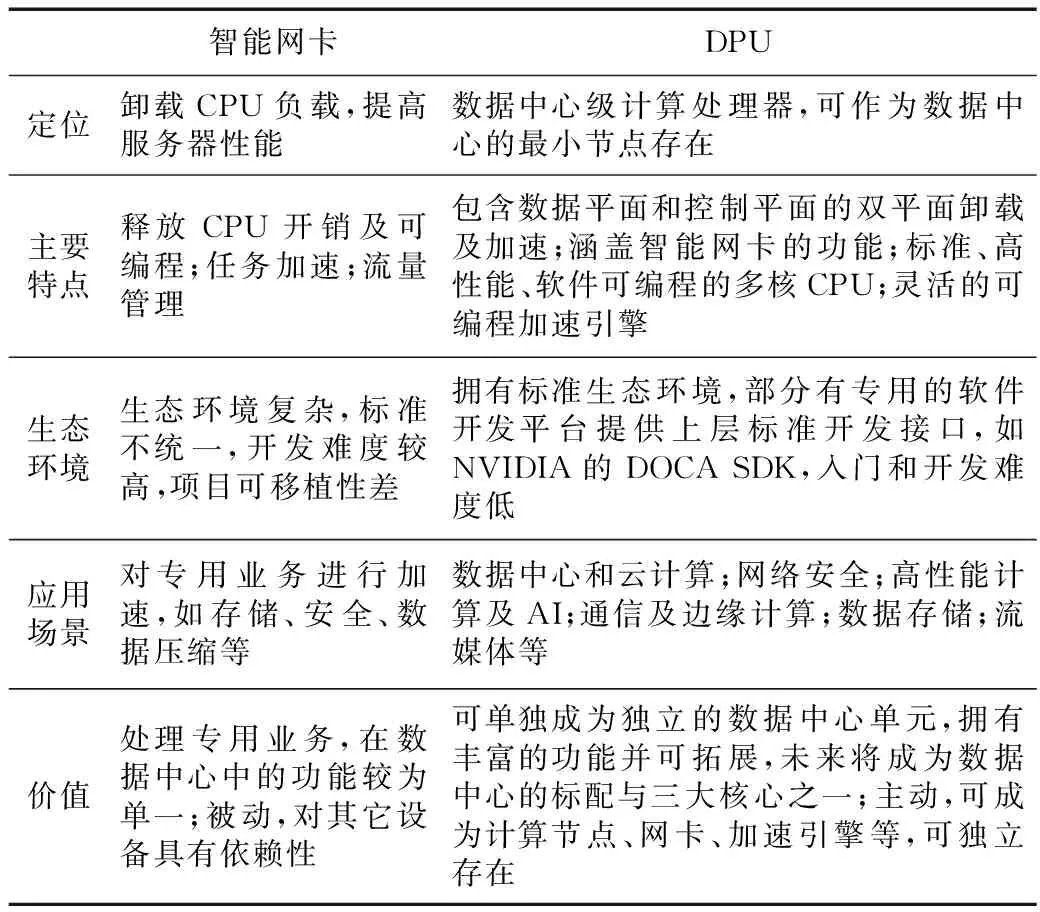
Table 2 Comparison between Smart NIC and DPU表2 智能网卡和DPU对比分析

Table 3 Comparison between NP and DPU表3 NP与DPU的对比

Table 4 Product introduction of DPU 表4 DPU产品介绍
从应用特征来看,可以把应用分为“I/O密集型”和“计算密集型”2类,一个处理器芯片是“I/O密集”还是“计算密集”只部分决定了芯片的结构特征,并不能完全定义芯片的主体架构。无论是I/O密集,还是计算密集,既可以以通用CPU为核心构造主体计算架构,也可以以专用加速器为核心构造主体计算架构。前者称为以控制为中心(Control-Centric)的模式,可对应RTC模型。后者称为以数据为中心(Data-Centric)的模式,可对应Pipeline模型。以控制为中心的核心是实现“通用”,以数据为中心的核心是通过定制化实现“高性能”。DPU比较偏向于以数据为中心的结构,形式上集成了更多类别的专用加速器,牺牲一定的指令灵活性以获得更极致的性能。DPU同时会配置少量通用核(如ARM(Acorn RISC Machine)和MIPS(Microprocessor without Interlocked Piped Stages))来处理一些控制平面上的任务,运行轻量级操作系统来管理DPU上数量较多的异构核资源,所以体现了一定的“通用”性,但性能优势并不主要取决于这些通用核,更多的是来源于大量的专用计算核。
2.2 DPU架构
CPU+xPU架构,是以CPU为中心,I/O路径很长,I/O成为了性能的瓶颈。通信的本质是共享内存,而冯·诺依曼架构的瓶颈在内存,这是DPU需要解决的本质问题。解决这个问题的核心方法是让计算发生在最靠近数据的地方,进而降低通信量以规避冯·诺依曼架构的瓶颈,并尽可能降低成本。传统的异构计算都是采用CPU的协处理器,随着I/O的数据量与网络流量的增速超过CPU计算能力,CPU的计算和I/O处理能力都会成为主要性能瓶颈。因此,以CPU为中心的架构需要变革。当前由指令控制流驱动计算;未来将以数据为中心,数据流驱动计算。如图2所示,传统“以计算为中心”的架构将随着数据量的增长转变为“以数据为中心”,而DPU将作为“以数据为中心”的服务器架构中的核心器件进行数据处理,并协调包括CPU与GPU在内的其他器件充分发挥其计算能力。
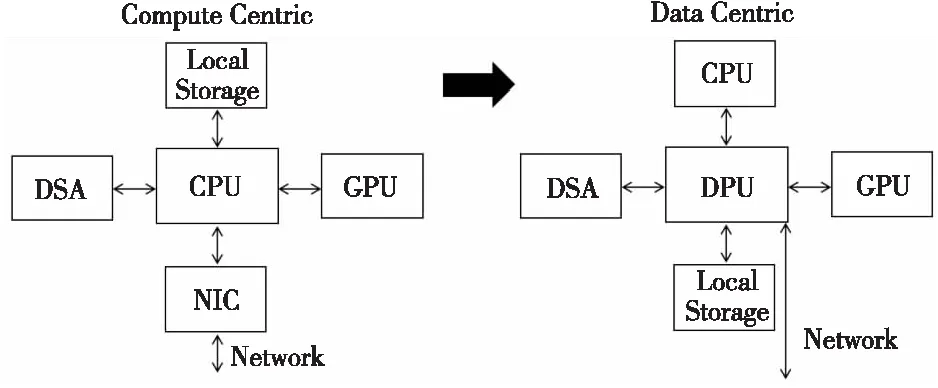
Figure 2 From compute centric to data centric图2 从“以计算为中心”到“以数据为中心”
数据平面与控制平面分离是软件定义网络SDN(Software Defined Network)中最核心的思想。DPU被定义为强化了数据平面性能的专用处理器,配合控制平面的CPU,可以实现性能与通用性的更好平衡。
大规模云计算网络面对着提高传输效率与可靠性等挑战。鉴于目前“以计算为中心”的数据中心体系中所存在的局限,一个宏观趋势是数据中心的体系架构将会从“以计算为中心”转向“以数据为中心”。为了满足“以数据为中心”的设计理念,研究人员提出了一个通用的DPU参考设计[2],如图3所示。该架构是RTC模型与Pipeline模型相结合的设计,其中控制平面通常由通用处理器核来实现,属于RTC模型,数据平面通常集成多个处理核,主要面向高速数据包处理,目前较为典型的方式是采用专用的加速引擎,属于Pipeline模型。例如,NVIDIA的BlueField-3系列DPU,就由16个ARM核及多个专用加速引擎组成;Fungible的DPU具有6大类的专用核以及52个MIPS小型通用核[1]。
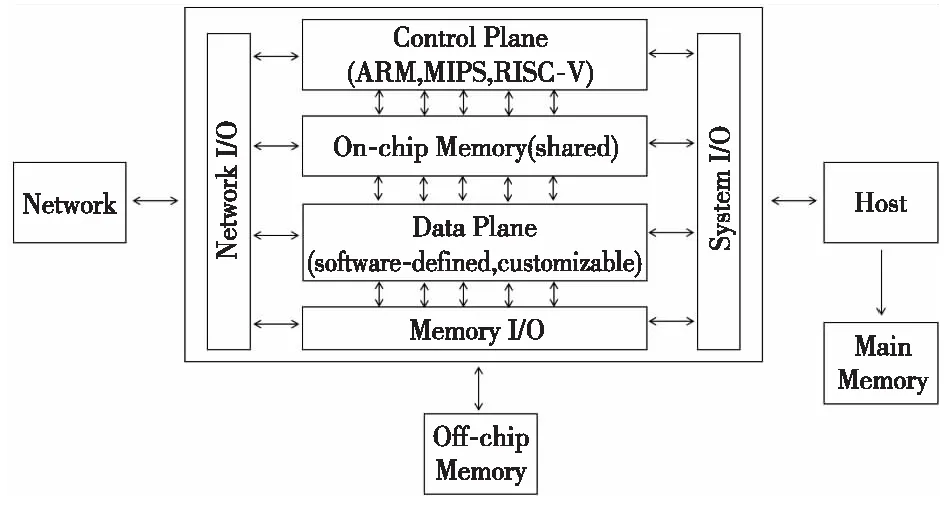
Figure 3 Reference design of DPU architecture 图3 DPU架构参考设计
宏观来看,DPU架构至少可以分为以下几个核心组成部分:
(1)控制平面组件:负责管理与配置,大多由通用处理器核来实现。控制平面负责DPU设备的运行管理,以及计算任务和计算资源的配置。运行管理通常包含设备的安全管理和实时监控2个主要功能。计算任务和计算资源配置方面,根据计算任务的实施配置数据平面中处理单元间的通路,以及各处理单元参数。根据资源利用情况实时进行任务调度及其在计算单元的映射和部署。当DPU集成第三方计算平台,如GPU、现场可编程门阵列FPGA(Field Programmable Gate Array)等,还需要参与部分卸载任务调度。由于控制平面任务种类多,灵活性要求较高,算力要求较低,大多由通用处理器核来实现,例如ARM、MIPS等。此外,控制平面与数据平面数据交互驱动程序需要进行深度优化,以此提高控制平面与数据平面的交互效率及任务调度效率。
(2)数据平面组件:主要负责高速数据通路的功能单元的集成,通常集成多个处理核。数据平面的功能主要分为高速数据包处理、虚拟化协议加速、安全加密、流量压缩和算法加速5类。数据平面既是整个DPU设计中最有挑战的模块,也是DPU设计的关键所在。DPU数据平面在处理核规模上要具有非常强的可扩展性。随着DPU数据平面处理核数量越来越多,再加上高并发处理线程运行,同时还要兼顾数据处理的灵活性,这就要求处理核之间的数据交互既要灵活又要兼顾高带宽。数据中心业务的复杂多变决定了DPU数据平台可编程性的硬性需求。这一部分各厂商的实现方式差别较大,有基于通用处理器核的方式,有基于可编程门阵列FPGA的方式,也有基于异构众核的方式,还有待探索。
(3)I/O组件:主要分为系统I/O、网络I/O和主存I/O。系统I/O负责DPU和其他处理平台或高速外部设备(如SSD(Solid State Disk))的集成。系统I/O通常传输数据量较大,因此对带宽要求极高,大多使用PCIe来实现。网络I/O负责DPU与高速网络相连接。为了能应对急剧增加的网络带宽,DPU中通常辅以专门的网络协议处理核来加速网络包的处理。主存I/O负责缓存网络I/O、系统I/O输入输出数据,以及数据平面中间数据结果。也可作为共享内存,用来进行不同处理核之间的数据通信。目前主存I/O主要包含DDR和高带宽存储器HBM(High Bandwidth Memory)接口类型[9]。2种存储接口相结合可以满足不同存储容量和带宽的需求,但是需要精细的数据管理,这也是DPU设计中具有挑战性的部分。
DPU也需要根据具体应用场景进行架构的改变,即具备可扩展性。DPU自身可以是包含CPU、GPU、FPGA、DSA(Domain Specific Architecture)和ASIC等各种处理引擎的一个超大的SoC,具有独立处理所有任务的能力。在一些应用层算力要求不高的业务中,作为最小计算系统的独立的DPU就能满足计算的要求。在业务应用层有更高的算力要求或者在业务和基础设施必须分离的场景中,DPU+CPU的中等计算系统能够满足其需求。在AI训练类的场景或者一些应用需要加速的场景,并且需要业务和基础设施分离的时候,就必须选择DPU+CPU+DPU组成的大系统。
nanoPU[10]是经过网络优化的新型CPU,是一种基于RISC-V的网络接口控制器NIC和CPU联合的设计。通过绕过高速缓存和内存层次结构,nanoPU直接将到达的消息存入CPU寄存器文件中。nanoPU将关键功能从软件转移到硬件,例如可靠的网络传输、拥塞控制、核心选择和线程调度,减轻CPU的算力负担。通过限制消息处理时间来限制尾部延迟,应用程序之间的线对线延迟仅为65 ns,比当前的最新技术快13倍。nanoPU作为一种创新架构可应用于DPU中,RTC模型与Pipeline模型相结合的形式将给DPU带来高速处理能力,显著降低了延迟并具备可编程能力。
2.3 DPU的主要功能
通过分析DPU的架构,可以总结出DPU的主要功能有:
(1)算力卸载。将不适合CPU执行的任务卸载到智能网卡或DPU上,可节约更多CPU算力以支撑更多的应用业务。
(2)虚拟网络控制平面隔离。DPU需要独立的网络控制平面,从主机中完全隔离,可以服务于各种资源池能力的组合和伸缩。
(3)主机侧总线通信的延展。
(4)网络侧无损网络传输。网络侧提供具有针对性的拥塞控制机制以及更强的负载均衡能力,降低长尾时延,提供更可靠、更高效的传输网络。
(5)精细化的测量和故障检测能力。精细化的流量测量支撑精细化的故障检测能力,使流量数据更透明。
2.4 DPU与智能网卡
智能网卡(Smart NIC)具有独立的计算单元,除了能完成标准网卡所具有的网络传输功能之外,还提供内置的可编程、可配置的硬件加速引擎,提升了应用的性能,大幅降低了CPU在通信过程中的消耗,为应用提供更多的CPU资源。主要解决的问题是网络传输上无法线性传输数据问题,以及卸载更适合在网络上执行的业务[11]。最初的智能网卡具有3个重要特征:(1)释放CPU开销及可编程;(2)实现任务加速,通过专用加速器实现特定功能并保证数据转发的线速;(3)流量管理和监测。
DPU概念的确立是在2020年10月NVIDIA将基于Mellanox的Smart NIC卡命名为“DPU”,因此DPU延续了智能网卡“释放CPU开销”“可编程”“任务加速”和“流量管理”等功能。表2为智能网卡与DPU二者的对比分析。智能网卡中包括FPGA型和ARM核心型,FPGA型处理控制平面任务较为困难,ARM核心型则会因处理其它任务而负载过重;DPU包含数据平面和控制平面的双平面可编程卸载及加速,能够解决以上问题。
传统智能网卡上没有CPU,需要主机CPU进行管理,驱动通常是在所在主机内,而DPU完全不需要任何驱动。随着网络速度的提高,传统智能网卡将消耗大量宝贵的为通用应用程序而设计的CPU内核来进行流量的分类、跟踪和控制。Smart NIC实现了部分卸载,即只卸载数据平面,控制平面仍然在主机CPU处理。从总体上来说Smart NIC的卸载操作是一个系统内的协作。DPU实现了完全的卸载,包括软件卸载和硬件加速2个方面,即将负载从主机CPU卸载到DPU的嵌入式CPU中,同时将负载数据平面通过DPU内部的其他类型硬件加速引擎,如协处理器、GPU、FPGA和DSA等来处理。从总体上来说,DPU是2个系统间的交互协作,把一个系统卸载到另一个运行实体,然后通过特定的接口交互。智能网卡只能帮助CPU减轻部分压力,但整个系统的复杂度仍然由CPU侧软件处理;DPU要做到业务应用和基础设施分离,CPU侧的应用完全对底层系统无感。从云计算业务的角度看,DPU是把整个基础设施即服务IaaS(Infrastructure as a Service)完整地卸载到硬件进行加速。从功能性的角度来看,DPU除了拥有Smart NIC功能之外,还包括易于扩展且可用C语言编程的Linux环境。DPU有独立的CPU和操作系统,而智能网卡仅是驱动设备,因此,DPU是一种全新的软件定义基础设施的设备,而不是已有网卡设备的增强版。另外,DPU与智能网卡的最大区别是可作为数据中心的最小节点存在,拥有计算功能、网卡功能、加速计算引擎、安全引擎等并可拓展,未来将成为数据中心的标配与三大核心之一(CPU、GPU、DPU)。
2.5 DPU与NP对比分析
NP是一种主要用于各种通信任务的可编程器件,专门为处理数据包而设计的,具有较强的I/O能力[12]。NP器件内部通常包含微码处理器和硬件协处理器,多个微码处理器在NP内部并行处理,通过预先编制的微码来控制处理流程。针对个别较为复杂的操作使用硬件协处理器来进行加速处理,进而最大限度地结合业务灵活性和高性能。与通用处理器相比,网络处理器在网络分组数据处理上性能优势明显。NP不以通用处理能力如定点和浮点计算能力、CPU主频为主要性能指标,而是针对网络分组的处理和转发这一中心任务采取了架构上的优化,提供线速的分组转发能力NP主要聚焦通信相关的任务,而DPU可以支持P4(Programming Protocol-independent Packet Processors)与C语言混合编程,实现包括网络、存储、安全和虚拟化等所有底层I/O的卸载加速。以eBPF(extended Berkeley Packet Filter)卸载为例,eBPF程序通过快速数据路径XDP(eXpress Data Path)卸载方式,降低CPU占用率,提升eBPF运行容量和效率,使eBPF程序更靠近数据平面。eBPF卸载应用中,根据标准编写eBPF程序,通过底层虚拟机LLVM(Low Level Virtual Machine)将程序编译为eBPF bytecode,然后通过iproute clibbpf等工具将eBPF程序导入内核;eBPF通过验证后,实时编译工具将eBPF bytecode程序编译为芯片能运行的机器语言并部署在DPU上运行。
NP与DPU的对比分析如表3所示。NP偏向于基于通用处理器来进行专用化扩展,但是非常注重高通量的性能属性。NP要支持数Tbps的转发带宽,与DPU同为I/O密集型应用,然而NP主要以通用CPU为核心构造主体计算架构,以控制为中心,偏向于RTC架构;而DPU主要以专用加速器为核心构造主体计算架构,以数据为中心,偏向于Pipeline架构。
3 DPU编程模型
异构计算的一个特点是“异构”,即缺少“通用性”,开发难度较高。尤其是当DPU兴起之后的“多PU”共存(CPU+DPU+GPU/XPU)时代,怎么协同调度好每个处理器编程框架,使其发挥最大效用,同时形成一个对开发人员较为友好的软件开发生态,是当前比较重要的问题。
针对这个问题,根据职责分层与功能抽象的思路,一个针对DPU芯片应用场景的异构计算5层架构模型被提出。该模型定义了在异构计算场景下的通用开发架构模式,以此来降低包括DPU芯片在内的异构计算应用研发难度,提高开发、维护和迭代效率。
3.1 DPU异构计算架构5层开发模型
一般说来,异构计算在定义每一层功能时,要达到以下几个目标:(1)各层职责单一;(2)层间边界清晰;(3)层内功能实现独立;(4)灵活易扩展。
基于上述目标,将一个异构计算的系统抽象为5层,如图4[2]所示,自下而上分别是:领域特定架构DSA设备层、DSA操作层、计算引擎层、应用服务层和业务开发层,具体详述如下:
(1)DSA设备层代表的是执行异构计算的DSA处理器和集成了该处理器的硬件设备。异构计算设备需要具备以下2个核心要素:①支持专用计算操作的指令集;②CPU或其他DSA设备的标准通信接口。
(2)DSA操作层是对DSA处理器的指令集的管理以及对基础开发平台的整合,该层完成了对硬件资源的抽象,从而使上层软件对底层设备透明。它基于如DPU芯片等DSA处理器提供的指令集,对上层提供更加抽象和编程友好的接口。
(3)计算引擎层是对计算逻辑的封装,为上层提供通用的计算能力。与DSA操作层的对计算资源封装不同,它使用DSA操作层提供的资源访问接口,依据上层应用层软件对算力的需求,提供了可复用的算子集合及执行接口。
(4)应用服务层是数据处理的应用服务软件,也是算力的需求侧。应用服务层代表具有通用功能的软件系统,这些软件系统可以利用计算引擎提供的算子进行异构计算,以此提升计算性能。
(5)业务开发层是针对某特定领域的业务系统。业务开发层是与现实中业务场景最为相似的软件系统。它是根据不同场景下具体业务需求定制的,整体异构计算架构实质上就是解决业务层遇到的性能瓶颈,而且也要保证底层构建对具体的业务系统完全透明。
3.2 P4编程模型
P4是数据平面上的高级编程语言,能够改进OpenFlow的不足。P4语言的设计初衷其实是想要达到以下3个目标:(1)协议无关性:网络设备不与任何特定的网络协议相关联,用户能够使用P4语言描述任何网络数据平面协议和数据包处理行为。这个特点由自定义包解析器、匹配-动作表的匹配流程和流控制程序来实现。(2)目标无关性:用户不必过分在意底层硬件的细节就能够编程数据包的处理方式。(3)可重构性:用户可以在任何时刻改变包解析和处理的程序,并在编译完成后对交换机进行配置,真正实现现场可重配能力[13]。
以这些目标为出发点,P4语言对编译器进行了模块化的设计,使用标准格式的配置文件进行各个模块之间的输入输出。
图5是P4抽象转发模型[14]。它包含:(1)解析器:将数据包头从报文中提取出来并根据数据包头解析图解析,剩余的载荷与头部分开缓存,并且载荷不参与后续匹配。(2)匹配-动作表:多级匹配-动作表阶段组织起来形成流水线,分为入口流水线和出口流水线2部分。入口流水线的匹配-动作表决定了报文的输出端口与队列,基于入口流水线的处理,报文可能被转发、复制、丢弃或者触发流控;出口流水线的匹配-动作表主要负责修改数据包头部。(3)定义控制流: 编程人员可以按照P4语法规范定义控制流以及每张匹配-动作表要匹配什么样的数据包、执行什么样的动作,从而达到自定义数据平面流水线处理逻辑的目的。(4)缓冲区:缓冲区用来缓存载荷与交换机队列中等待被匹配动作表处理的已解析的头部。(5)逆解析器:将修改后的报文头与原报文合并发送出去。

Figure 5 Programming model of P4 图5 P4编程模型
以实现简单的负载均衡为例,假如想要将源IP地址为245.22.0.0/16的报文目的IP地址修改为192.168.4.121并从M端口发送出去,这一过程使用P4实现的具体步骤如下所示:(1)使用控制程序和动作表配置更改各个模块的功能。(2)报文到来时,解析器负责根据解析图提取的报文头中的目的地址与源地址字段,将提取字段传给匹配-动作流水线并将原报文存入缓冲区。(3)匹配-动作表提取出源地址并进行动作匹配,若源地址为245.22.0.0/16,则执行修改目的地址为192.168.4.121的操作。(4)在逆解析器中将修改后的报文头与原报文合并发送。
除P4外,OpenFlow[15]作为软件定义网络SDN中的网络通信协议规范了消息传递应用程序接口API(Application Programming Interface)来控制转发平面的功能,以改变网络数据包所经过的网络路径。SDN应用程序就可以利用这个API提供的功能来实现网络控制。然而作为OpenFlow的基础的具体数据平面是不能改变的。而且OpenFlow只允许在一组固定的字段上进行匹配-动作处理,仅定义了有限的包处理动作集。与P4的任意字段匹配与修改相比,OpenFlow对数据平面的控制十分有限。
FlowBlaze[16]、NICA(Network Interface Card Architecture)[17]或hXDP(hardware eXpress Data Path)[18]等系统在RMT或eBPF等FPGA之上提供了更高级的抽象。每次程序员更新程序时,编译器都会重新配置这种更高级别的抽象,而不是每次都合成一个新的FPGA比特流,这样将会增加逻辑部署的时间开销。在P4诞生前,这些系统的灵活性弱于RTC模型,可编程性差。
P4提供了一系列抽象,以供用户将交换机理解为图5中的模型,并根据这个模型进行开发。DPU作为数据中心中网络相关的数据处理、卸载载体,可成为P4编程模型新的应用场景。通过P4的3个特性为DPU设计可编程的数据平面,可最大限度发挥DPU在数据中心中的作用,使DPU适应不断变化与发展的网络协议与数据处理业务。
4 DPU行业现状
当前DPU市场十分广阔,各厂商相继推出DPU产品[2-6]。如表4所示,DPU方案类型大致可以分为3种:(1)以通用众核处理器为基础DPU,以多核ARM为核心,可编程灵活性较好,但是应用针对性不够,对于特殊算法和应用的支持,与通用CPU相比并无太显著的优势;(2)以专用核为基础的异构核阵列,这种架构的特点是针对性较强、性能较好,但是牺牲了部分灵活性,如IPU;(3)结合了前面二者优势,即将通用处理器的可编程灵活性与专用的加速引擎相结合,正在成为最新产品的趋势。
4.1 基于ARM架构的DPU
NVIDIA推出的BlueField系列DPU,能够支持网络处理、安全和存储功能,并且实现了网络虚拟化、硬件资源池化等一系列基础设施层服务,可以从业务应用中将数据中心的基础设施服务卸载和隔离出来[3],实现了由传统基础设施到现代基于“零信任”环境的转型。BlueField-3 DPU是首款为AI和加速计算而设计的达400 Gbps的DPU,基于ARM架构,采用ARM+ASIC+专用加速器构成SoC,可以通过ARM核处理部分控制平面的任务,具备一定的通用能力。在BlueField-3中,数据路径加速分组DPA(Data Path Accelerator)包括16个处理器核,可并行处理256个线程任务。BlueField-3是首款支持第5代PCIe总线并提供数据中心时间同步加速的DPU。在兼容性上,通过使用DOCA[1]库,BlueField-3与上一代DPU上开发的应用保持完全的软件兼容性,得到了更高的性能和可扩展性。
最早进行类DPU功能产品研究和开发的是AWS(Amazon Web Services)。AWS走的同样是ARM+ASIC+专用加速器构成SoC的技术路线。AWS为了寻找新的方法来改进纯软件虚拟机管理程序架构,探索更灵活可行的虚拟机管理方式,研发出Nitro[19]卸载卡。2015年初,AWS在计算实例中采用了硬件与定制ASIC芯片。ASIC芯片具有功耗低、性能高、成本低和可靠性强的特点,将此用于承载AWS虚拟机管理程序,能够使服务器的几乎全部CPU与内存资源都可用于运行业务负载。AWS提出的架构创新,使最小的成本承担最紧要的部分(虚拟化),得到了接近裸机服务器的高性能。
Netronome Agilio SmartNIC采用ARM+网络流处理器NFP(Network Flow Processor)+专用加速器组成SoC的技术路线,能够加速OVS(Open VSwitch)和Contrail vRouter,提供更好的CPU效率,更低的复杂度,增强可伸缩性,提高网络性能[6]。在OVS应用程序中,Agilio CX SmartNICs可以回收原本专用于OVS的服务器CPU资源的80%以上,同时向更多的应用程序提供5倍或更多的数据吞吐量。相比于应用于计算节点的Agilio CX系列,Netronome也研发出了应用于裸金属服务器的Agilio FX以及用于服务器节点的Agilio LX,以应对服务器和网络弹性带来的挑战[22]。
博通采用了单芯片的方法装配Stingray SmartNIC[21]。博通采取的技术路线是以通用众核为基础的同构众核DPU,运用了通用SoC和ASIC,网速能达到100 Gbps,也配备了通用的工具包。用ASIC作为卸载功能芯片,是DPU几种方案中定制化程度最高、效能最好的方案,但是可移植性差[23]。
4.2 基于ASIC的DPU
阿里云智能在2017年10月发布第一代神龙服务器[20]。神龙采用FPGA+ASIC的技术路线,具有高弹性、高稳定和高性能等特点,能够将整个阿里巴巴经济体业务全面迁移到公共云上。它真正使用软硬融合、软硬件协同设计的模式,改进了以往虚拟化技术与当前计算架构不友好的地方,使用专用芯片来解决虚拟化技术带来的性能损耗问题,完全发挥处理器和内存等计算资源的性能。第1代神龙,主要为了解决上云后如何支持裸金属服务。在神龙(X-Dragon)卡里,一个神龙芯片进行高速数据平面的转发,另一个芯片作为加速引擎,将控制平面完全卸载到芯片中。整个生命周期的管理、所有的接口都和虚拟机保持一致。第2代的神龙不仅可以支持裸金属系统,还可以支持虚拟机。它为虚拟机设计了几乎不占资源的Hypervisor(称为Dragonfly),可以支撑很多的虚拟机系统,完全做到资源和性能无损。第3代神龙架构拥有极致的性能,所有的数据平面路径全面芯片化,存储、网络、数据都芯片化,其性能处于业界顶尖水平[24]。
4.3 基于FPGA的DPU
在2021年6月英特尔推出了全新的基础设施处理器IPU(Infrastructure Processing Unit)[4]。IPU采用FPGA+X86组成SoC的技术路线,是一个可以安全地加速和管理数据中心基础设施功能与可编程硬件的网络设备,目的是让云和通信服务提供商减少在CPU方面的开销,充分发挥其效能。IPU增强了基础NIC中丰富的以太网网络功能,通过高度优化的硬件加速器和紧密耦合的计算引擎的组合来实现任务加速。适应性是通过标准且易于使用的编程框架实现的,该框架结合了硬件和软件功能[25]。IPU可以通过专用协议加速器来加速基础设施功能,包括存储虚拟化、网络虚拟化和安全;通过把软件中的存储和网络虚拟化功能从CPU转移到IPU,从而释放CPU算力。还能进行灵活的工作负载分配,提高数据中心利用率。
5 DPU应用
DPU比较典型的应用场景有:数据中心和云计算、网络安全、高性能计算及AI、通信及边缘计算、数据存储和流媒体等。当前最主要的3大应用场景主要包括网络功能卸载、存储功能卸载及安全功能卸载。
5.1 网络功能卸载
随着云计算网络的发展,网络功能卸载的需求开始产生,主要是对云计算主机上的虚拟交换机的能力进行硬件卸载,从而减少主机在网络上消耗的CPU算力,提高可售卖计算资源。
目前除了公有云大厂商采用自主研发的云平台外,绝大部分私有云厂商都使用开源的OpenStack云平台生态。在OpenStack云平台中,虚拟交换机通常是Open vSwitch[26],在云计算中主要负责网络虚拟化的工作,以及虚拟机与同主机上虚拟机、虚拟机与其它主机上虚拟机、虚拟机与外部的网络通信。虚拟交换机的场景是最通用的应用场景,所以,虚拟交换机的发展状况也直接影响着虚拟化网络的发展。Mellanox最早提出在其智能网卡上支持OVS Fastpath硬件卸载,提供接近线速转发的网络能力。在OVS Fastpath卸载后,OVS转发报文时,数据流首包依然进行软件转发,在转发过程中生成Fastpath转发流表并配置到硬件网卡上,这个数据流的后续报文则可以直接通过硬件转发给虚拟机。由于早期的Mellanox智能网卡还没有集成通用CPU核,OVS的控制平面依然在物理主机上运行。后来在BlueField-2上,由于集成了ARM核,所以NVIDIA在与UCloud的合作中,将OVS的控制平面也完全卸载到网卡的ARM核上,这样在主机上就可以将OVS完全卸载到网卡上。
伴随着越来越多的业务部署在云中,部分之前在专用设备或者特定主机上运行的网络产品也逐渐关注在云服务中的按需扩缩容能力,因此出现了网络功能虚拟化NFV(Network Functions Virtualization)产品。NFV产品主要以虚拟机或者容器的形态部署到云计算平台上,对外提供对应的网络功能,如负载均衡、防火墙、网络地址转换、虚拟路由器和深度包检测等。此类NFV产品之前全都是基于DPDK在X86 CPU上运行,但是CPU算力达到上限,吞吐能力难以支持对应的网络带宽。DPU智能网卡的出现,为NFV加速提供了资源和可能性[27]。
面对计算量与数据量的激增以及各种应用对低延时的要求,当前TCP/IP软硬件架构以及对CPU要求较高的技术特征很难满足应用的需求,主要原因是各种复杂的操作导致时延太大,存储转发模式以及丢包也会带来额外的时延。而与TCP/IP相比,RDMA通过网络在2个端点的应用软件之间实现Buffer的直接传递,不需要CPU、OS和协议栈的介入,可以避免网络数据的处理和传输消耗过多的资源,可以实现端点间的超低时延、超高吞吐量传输。RDMA的本质是一种内存读写技术。RDMA和TCP/IP网络对比[2]如图6所示。可以看出,RDMA的性能优势主要体现在零拷贝以及不需要内核介入[28]。通过DPU实现对RDMA技术的卸载可以有效提高通信效率,RoCEv2是目前主要的RDMA网络技术,以NVIDIA的Mellanox和Intel为代表的厂商,都支持RoCEv2的硬件卸载能力。
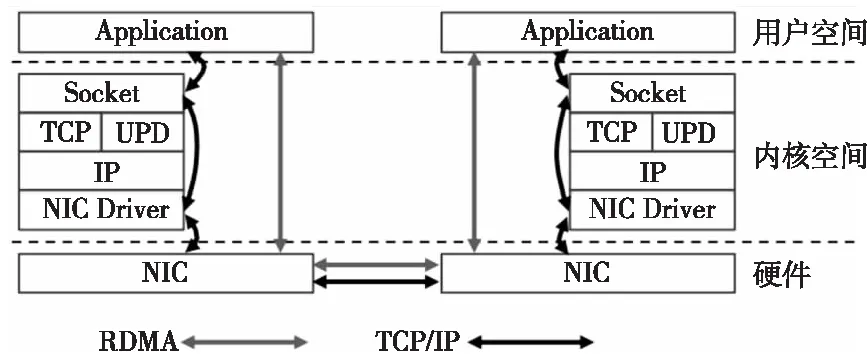
Figure 6 Comparison of data sending and receiving of RDMA and TCP/IP 图6 RDMA和TCP/IP收发数据对比图
5.2 存储功能卸载
NVMe-oF(NVMe over Fabric)[29]协议是为了使用NVMe通过网络结构将主机连接到存储,能够对数据中心的计算和存储进行分解。NVMe-oF协议定义了使用各种通用的传输协议来实现NVMe功能的方式。NVMe-oF提高了以往数据存储协议的性能,也可以为高度分布式、高度可用的应用程序实施横向扩展的存储。可以把NVMe协议扩展到存储区域网络SAN(Storage Area Network)设备,不仅能够提高CPU的使用效率,也能够加速服务器与存储应用程序之间的连接。
NVMe-oF主要支持3大类Fabric传输选项,分别是光纤通道FC(Fibre Channel)、RDMA和TCP,其中RDMA支持InfiniBand、RoCEv2和iWARP。
NVMe支持Host端(Initiator或Client)和Controller端(Target或Server),如图7[2]所示,目前DPU智能网卡硬件加速主要应用在如下4种场景:(1)普通智能网卡硬件加速NVMe-oF Initiator。(2)支持GPU Direct Storage的智能网卡加速NVMe-oF Initiator和NVMe-oF Target。(3)智能网卡硬件加速NVMe-oF Target。(4)DPU芯片硬件加速NVMe-oF Target,该场景是通过DPU芯片提供多个PCIe Root Complex通道以及多个100 Gbps的网卡实现的超大吞吐量的存储服务器。
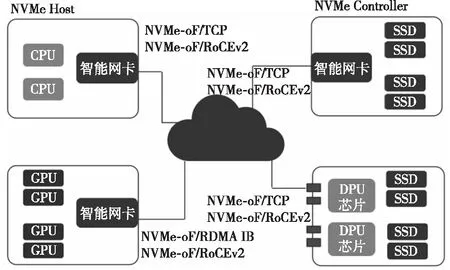
Figure 7 Hardware offloading mode of NVMe-oF图7 NVMe-oF硬件卸载方式
5.3 安全功能卸载
在安全领域有很多的安全功能产品,比如下一代防火墙NGFW(Next Generation FireWall)、网站应用级入侵防御系统WAF(Web Application Firewall)和DDoS(Distributed Denial of Service)防御设备等。云和虚拟化技术在不断发展,越来越多的安全功能产品的实现方式转为虚拟化方式,并通过云平台来部署管理。数据中心中大量的数据可能流经这些安全功能产品,因此转发数据时的效率对整体网络的吞吐量和时延会有很大的影响。使用基于X86的软件方式来实现,需要大量CPU资源来处理对应的业务逻辑,具有明显的性能瓶颈。通过DPU对这些安全功能产品进行硬件加速是必然趋势。由于安全功能产品对报文处理的深度不同,所以在DPU的卸载方式上也会有所不同。
如果把云平台虚拟化应用在传统的网卡上,那么Hypervisor以及对应的虚拟化网络都是在主机操作系统上实现的,这样一旦遭受攻击导致Hypervisor被攻陷,主机操作系统的根权限(root权限)被拿到,那么虚拟化网络配置就可以被篡改,租户网络也会受到攻击,甚至会影响其它计算节点受到范围更广的攻击。DPU智能网卡能够把虚拟化网络的控制平面完全卸载到DPU上,和主机操作系统隔离开,即使黑客攻陷了Hypervisor,获取了主机操作系统的root权限,也无法篡改虚拟化网络的配置,能够将黑客的攻击范围限制在主机操作系统上,不会影响到虚拟化网络及其它主机,进而达到了安全隔离的效果。
6 结束语
DPU是一类专用处理器,CPU则是一类通用处理器,二者的差异导致二者将可能有不同的发展历程。专用计算体系结构和通用计算体系结构所面向的应用场景有所差异,专用计算主要面向数据平面,而通用计算主要面向控制平面。未来DPU的发展可能会有如下3个趋势:
(1)控制平面采用RISC-V指令集[30]。RISC-V架构具有简洁、模块化的特点,方便组织,很容易通过一套统一的架构适应纷繁复杂的应用场景。可以通过灵活选择不同的模块组合,来满足定制化设备的需要。该指令集还拥有足够的软件提供支持,为新指令集提供了良好的发展生态,未来数据中心DPU需要RISC-V所带来的轻量级与灵活性优势。
(2)数据平面融合RMT架构。RMT允许在不修改硬件的情况下通过修改匹配字段来更改转发平面,相比OpenFlow,允许更全面地修改所有报头字段,使硬件支持足够灵活的可编程性,几乎不带来额外的损耗。RMT通过可重配置的转发模型,解决了当前交换机芯片协议相关性问题,做到了协议无关的流水线处理。对于以数据为中心且I/O密集的DPU来说,与RMT相结合将更有利于发挥DPU的数据处理效率与灵活性。
(3)数据平面在RMT的基础上采用与RISC-V指令集相结合的nanoPU架构[31]。采用nanoPU架构的DPU设计将显著降低云服务提供商的RPC尾部延迟,给微服务带来更高的稳定性与可编程能力,提高细粒度任务的调度与运行效率。
目前DPU技术架构也遇到发展瓶颈。目前主流的DPU采用FPGA+SoC解决方案,预计在200 Gbps网络,芯片面积将达到800 mm2,功耗将达到150 W,芯片面积和单卡功耗都将达到上限。FPGA厂商开始有转向FPGA+ASIC混合方案的趋势,而ASIC架构的灵活性不足,硬件逻辑不可变,需求变更开发周期长,长期演进风险高。标准化方面,运营商多云多业务场景需适配不同类型智能网卡,产品落地面临接口解耦压力,标准化较为困难。同时,DPU的成本、带宽、集成度、灵活性及可靠性等核心指标相互制约,需要在不同应用场景进行适当的权衡。
在未来可以采用多种处理引擎共存来共同协作完成复杂系统的计算任务。并且,CPU、GPU、FPGA以及特定的算法引擎,都可以被集成到更大的系统中构建一个更大规模的芯片,称之为“超异构计算”。通过软硬件融合的超异构,进一步提升DPU的系统规模,使DPU能够覆盖更多复杂计算场景。
DPU的发展任重而道远,需要为DPU的发展提供更加开放良好的生态环境,基于“软件定义”的思想,构造更加完整的DPU软硬件体系。DPU的发展前景十分广阔,未来将在信息化时代发展中大显身手,提高产业效能,成为新的生产力。
