关于不同函数组合提高深度学习 预测准确度的探讨
2023-02-19赵开宇
赵开宇
(作者单位:四川省广播电视科学技术研究所)
随着以大数据、人工智能为代表的数据产业的不断发展,海量数据的运算对人工智能提出了更高的要求。如何快速、准确、高效地通过深度学习完成机器对数据的自动处理是时下的技术热点。本文主要针对“Softmax + 二次代价函数”“Softmax +交叉熵代价函数”“Sigmoid + 交叉熵代价函数”三种具有代表性的函数搭配,进行深度学习拟合收敛比较,探讨提升深度学习准确率的技术方法。
1 样本程序(手写数字识别)介绍
由于人的笔迹各不相同,手写数字识别的功能就是通过深度学习,准确识别不同笔迹下的正确数字,如图1所示:

图1 手写数字识别效果示例
1.1 程序的编程思路
程序运用的是国际开源社区上成熟的MNIST训练数据集,该数据包含6万个数字图和1万个测试图。每个图由28×28=784位的矩阵组成,将矩阵向量中的每个元素按由“白”到“黑”取0~1的不同数字(保留小数点后1位),代表不同的颜色深度。例如:“0”表示颜色最浅,“1”表示颜色最深。数字转化矩阵如图2所示:

图2 数字转化矩阵
将每个图片28×28的矩阵向量转换成1×784的一维向量,目标标签取数字0~9的数字,最后通过“one-hot vector”取最大值所在位置索引,得到1×10的一维标签向量。MNIST训练集包括60 000张图片,则可得60 000×784的矩阵向量,通过神经网络784×10的矩阵向量深度学习,得到60 000×10的目标向量。
1.2 程序的编译环境
程序使用的Anacoda Navigator 3 搭建的软件环境,语言为Python 3.9.7,深度学习工具为Tensorflow 2.5,IDE使用Jupyter Notebook。
2 “Softmax+二次代价函数”的特点与运行效果
2.1 Softmax(激活函数)
Softmax的公式:

Softmax是一种归一化函数,它能将K维实数向量Z压缩到另一个K维向量σ中,σ中的每个元素表示其对应K元素的概率值,概率值介于0~1,且概率和等于1。
例:设a1=[4.2, 5.3, -1.1, 2.4],则Softmax(a1)=[0.23955214 0.71965441 0.00119575 0.0395977 ]
Softmax的回归模型如图3所示:

图3 Softmax回归运算模型
Softmax的函数图像如图4所示:

图4 Softmax函数图像
2.2 二次代价函数的公式

C表示代价,n表示样本数,x表示样本,y表示实际值,a表示输出值(预测值)。
2.3 使用梯度下降法对二次代价函数进行求导计算

z表示神经元的输入,σ(z)表示激活函数,C表示代价,y表示实际值,a表示输出值(预测值),w表示神经网络权重值,b表示偏执值。
由式(3)、式(4)可知,w和b的梯度与激活函数的梯度成正比(梯度可近似理解为斜率),激活函数的梯度越大,会使得w和b的梯度越大,进而预测值和实际值间的调整越大,拟合(收敛)速度越快。
故,二次代价函数比较适合具有线性特征的数据拟合。
2.4 “Softmax+二次代价函数”具体程序


备注:由于全部数据的损失函数使用梯度下降法太费时,这里引入了batch(批次),使用批量梯度下降法。
2.5 程序输出结果
“Softmax+二次代价函数”输出结果如下:

结果显示:16次训练,准确率上升到0.911。
3 “Softmax+交叉熵代价函数”的特点与运行效果
3.1 交叉熵代价函数的公式:
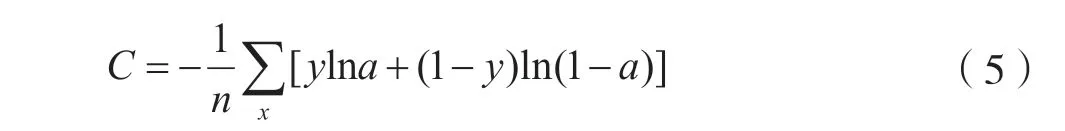
C表示代价,n表示样本数,x表示样本,y表示实际值,a表示输出值(预测值)。
3.2 使用梯度下降法对二次代价函数进行求导计算
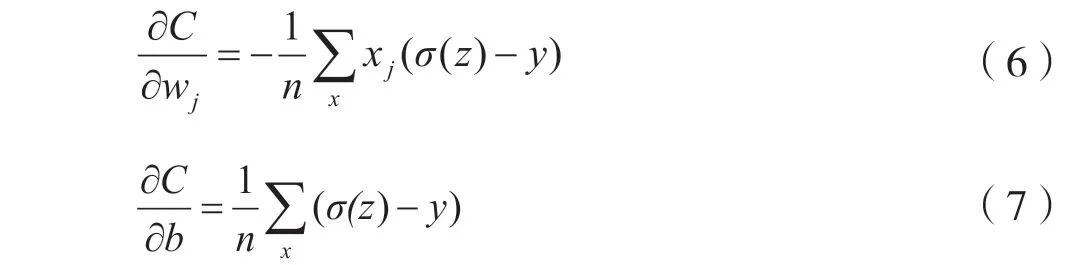
由式(6)、式(7)可知,w和b的梯度与激活函数的梯度无关,仅与σ(z)输出值与实际值的差成正比。差值越大,w和b的梯度越大,进而预测值和实际值间的调整越大,拟合(收敛)速度 越快。
故,不同于二次代价函数适合线性关系数据拟合,交叉熵代价函数比较适合非线性数据的拟合。
3.3 “Softmax+交叉熵代价函数”具体程序改动
在“Softmax+二次代价函数”的程序基础上,将损失函数
“loss = tf.reduce_mean(tf.square(y-prediction))”变更为
“loss =tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction))”
3.4 程序输出结果
“Softmax+交叉熵代价函数”输出结果如下:结果显示:16次训练,准确率上升到0.9211。

4 “Sigmoid+交叉熵代价函数”的特点与运行效果
4.1 Sigmoid(激活函数)
Sigmoid的公式:

Sigmoid是一种阈值函数(非归一化函数),与Softmax不同,概率值介于0~1。
例:设a2=[4.2, 5.3, -1.1, 2.4],则Sigmoid(a2)=[0.98522597 0.9950332 0.24973989 0.9168273]。
Sigmoid的函数图像如图7所示:
由图5可知,Sigmoid函数的梯度变化有一个“慢—快—慢”的过程。
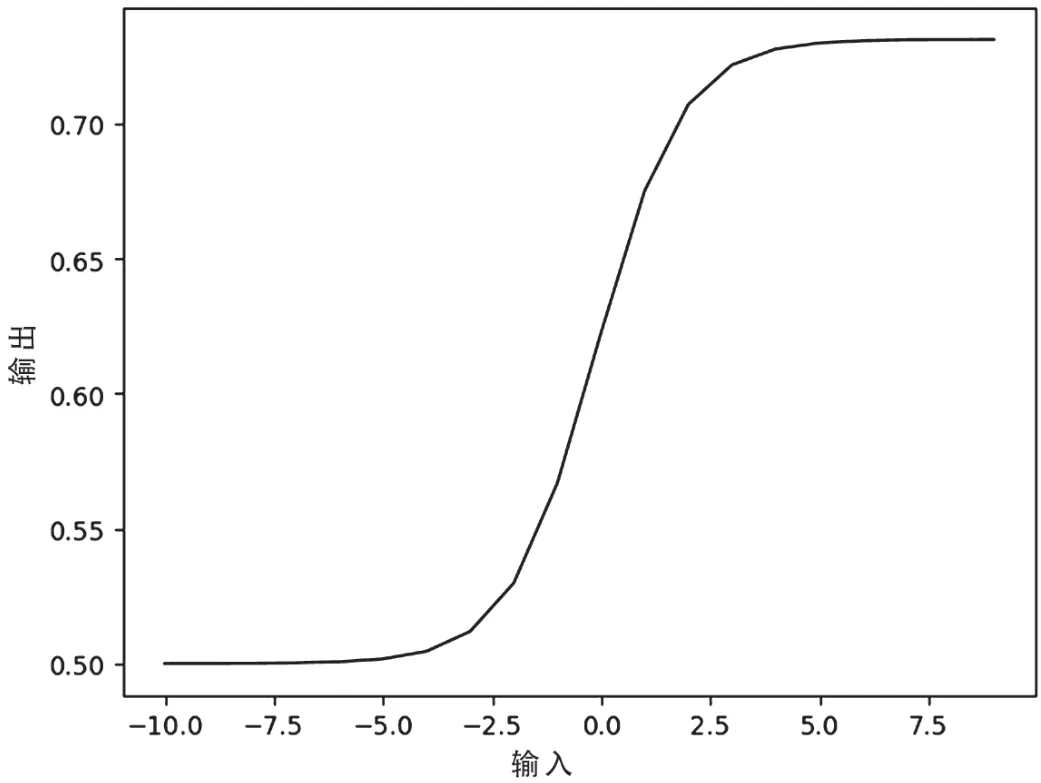
图5 Sigmoid函数图像
4.2 “Sigmoid+交叉熵代价函数”具体程序改动
在“Softmax+二次代价函数”的程序基础上,
激活函数不变依然是Softmax,因为使用交叉熵的前提是对数据进行归一化处理。
将损失函数
“loss = tf.reduce_mean(tf.square(y-prediction))”变更为
“loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=y, logits=prediction))”
4.3 程序输出结果
“Sigmoid+交叉熵代价函数”输出结果如下:


结果显示:16次训练,准确率上升到0.8927。
5 三种函数搭配的运行结果比较
对“Softmax+二次代价函数”“Softmax+交叉熵代价函数”“Sigmoid+交叉熵代价函数”三种函数搭配的运行结果进行准确率比较,如表1所示:

表1 三种函数搭配的运行结果比较
结果数据图形如图6所示:

图6 三组函数搭配的准确率效果比较
6 结语
在对输入数据的适用范围上,交叉熵代价函数比二次代价函数适用更广。若神经元数据有线性特点,则二次代价函数效果更佳。
在训练次数较少的深度学习中,在数据拟合(收敛)效率上Sigmoid不如Softmax。
