居民出行异质性与城市活动结构
2023-02-18段晓旗田有亮刘沛林秦永彬
段晓旗,张 彤,田有亮,刘沛林,万 桥,秦永彬
1. 贵州大学计算机科学与技术学院,贵阳 550025; 2. 武汉大学测绘遥感信息工程国家重点实验室,武汉 430079; 3. 长沙学院乡村振兴研究院,长沙 410022
公共交通在人们的出行过程中扮演着越来越重要的作用,一般而言,像北京、深圳等大城市的通勤活动中,地铁、公交等公共交通具有便利、高效、价格便宜等优势,成为大多数人的首选[1]。人类出行行为产生了海量的位置数据,包括GPS、智能刷卡记录(smart card data)等,通过数据挖掘,可以发现其背后所蕴含的信息。这些信息可以帮助从活动空间的角度重新认识城市结构,如在深圳郊区居民的出行特征较为相似,即早上通勤、晚上回家,而发现居民出行行为影响下的城市活动结构,对于城市管理、交通规划及公共交通线路选择具有重要意义[2-3]。
城市结构表示在一定地域空间内地理要素的相对区位关系和分布形式,是在长期过程中人类空间活动和区位选择的积累结果[4]。而城市活动结构旨在研究人类活动对城市空间的影响,即人类出行活动模式、规律对城市区域的影响以及个体与城市区域之间相互作用的总结[5-6],如通常居民地的活动结构为个体的通勤-上班-回家,商业区域的活动结构为休闲娱乐等。然而,在不同的时间段,由于城市区域内个体出行时空需求多样,导致城市活动结构的变化更为复杂。先前的城市活动结构研究更多关注城市结构对出行行为的影响,自20世纪70年代开始,出行行为对城市结构的影响引起了地理学家的关注[7]。学者们从不同角度研究了城市结构的影响,如土地利用和居住区规模混合[8-9],或试图通过居民的出行行为来评估城市政策[10]。然而,人类的出行行为也会影响城市结构,所以应该超越物理环境和经济资源的空间分布来解释城市[11-12]。一个城市的底层结构,例如城市区域具有更多内部空间的相互作用以及城市中心如何与其附近区域相互作用,说明城市作为动态系统发挥作用,而非静态。考虑到城市离散的物理资源由居民个体出行活动链接成一个综合系统的纽带,那么,居民个体出行活动就代表了城市空间的相互作用。由于数据来源、分析工具及计算能力的限制,这些研究进展有限,大多数与城市活动结构的研究都集中在城市形态上。
当前,用于发现网络子结构的社区探测方法,使城市活动结构的探测研究不仅仅局限于研究中心性、功能区及其交互领域,社区内部的活动机制成为研究重点。社区探测为城市活动结构发现提供了基础。最具有代表性的研究为文献[13]提出的社区发现优化模型Modularity,其核心思想是比较社区内部和外部的差异来衡量分区质量,Modularity模型为后续谱优化算法[14]、Louvain[15]、FastNewman[16]等社区发现方法的优化提供了基础。文献[17]基于最小熵的原理提出了Infomap算法,该算法以双层编码方式将社区发现同信息编码联系到一起,通过编码长度确定最优的划分结果。文献[18]借鉴LDA的思想提出了MMSB(mixture membership block model)方法,该方法基于概率统计思想更好地解释了节点之间的边乃至整个网络的生成过程。文献[19]以郑州市为例,利用轨迹数据分析了城市中多中心结构的交互关系。文献[20]利用百度迁徙数据对中国城市的网络特征进行探测。文献[21]在人口流动的视角下利用统计分析的方法对南京市城市空间结构进行了刻画。然而实际上城市活动结构的动态探测,除了有动态的出行特征外,城市属性等静态特征也同样重要。上述方法或者只能处理单一的网络结构,或者只能处理静态的属性信息,并且处理海量的交通数据效率较低。
随着机器学习技术的不断发展,部分学者从数据驱动的角度对城市活动结构进行了探究。文献[22]利用出租车轨迹数据对城市各区域之间的联系进行探测。文献[23]用道路将城市划分为不同的单元,再基于数据驱动的方法处理POI和出租车轨迹数据,发现城市中各单元所具有的功能。文献[24]通过POI数据和通话数据以非监督方式对利雅得城市内部吸引力模式进行研究,发现了全局、市中心和居住地的3种吸引力模式。相比于传统的算法,数据驱动的方式能够提高计算效率,并且能够准确挖掘出海量数据下的关键信息,在城市活动结构探测中发挥了越来越重要的作用。
然而,在数据源多样且海量的背景下,对于如何融合各种来源的静态、动态数据,如通话数据、轨迹数据、刷卡数据、城市属性数据等,面临着前所未有的挑战;另外,居民出行特征具有时空异质性,如何在训练过程中顾及空间异质性,现有研究鲜有尝试。
针对以上问题,本文提出一种基于表示学习的数据驱动方法,引入高斯混合模型(Gaussian mixture models,GMMs)[25]得到每次训练的分类结果,并结合文献[26]的多层地理分异思想,即顾及乘客的出行特征异质性,通过输入属性矩阵和出行模式图完成居民的动态活动信息及静态属性信息的融合,最终实现城市活动结构的探测。本文的贡献主要包括:①将不同来源的数据进行融合,实现了多图融合、多信息挖掘;②顾及了时空异质性,本文将时空异质性的概念实际应用于表示学习的框架中;③实现了在进行发现城市区域表示的同时,也完成了城市活动结构(社区)的表示。
1 相关研究
1.1 出行活动中的时空异质性
居民的出行行为在时间和空间上表现出多样化特征,同一区域的人群由于目的不同导致出行线路、出行时间产生巨大差异,如早高峰流量最多的区域为商业区,而晚高峰则是住宅区。针对居民活动的时空异质性,文献[27]对城市中老人22个月的活动进行了统计,发现了老人的活动具有很强的异质性;文献[28]运用社会网络分析和修正的空间交互模型,探讨了南京在旅游活动中的时间异质性,发现每个景点的访问量会随着行程时间增加而下降。上述研究通过比较的方法对异质性进行了初步探测,而文献[26]从统计学的角度提出一种将空间异质性定量化表示方法,q-value,具体公式为
(1)

总之,异质性是居民活动过程中不可忽视的因素,在以居民出行为的城市活动结构发现过程中需要顾及不同出行模式的异质性,为进一步了解居民出行特征、准确表示居民出行行为,进而发现城市活动结构具有重要意义。
1.2 表示学习
表示学习是近年来计算机科学研究的热点,目的是将图结构Gn×n,映射到低维空间Rn×d,其中d≪n,其结果带有原始图结构的特征。表示学习的结果能够完成聚类、分类、边预测、推荐等下游应用。
表示学习发展到现在,大体上可以归纳为3大类:基于因子分解的方法、基于随机游走的方法,以及基于深度学习的方法[29]。基于因子分解的方法将图转换成矩阵的形式,例如领域矩阵、拉普拉斯矩阵等,对这些矩阵进行因式分解,从而保持节点之间的相似度,根据矩阵性质的不同其分解方式也多样,代表的算法有HOPE[30]、LLE[31]等。基于随机游走算法的代表包括Deepwalk[32]、node2vec[33]等,其核心思想为在网络中不断重复地随机漫游,最终形成一条完整的通过网络的路径,隐式地保留节点间的相似度,获取图中局部上下文信息。而对于深度学习与日俱增的研究导致大量基于深度神经网络的方法应用于图的表示中,深度自动编码器能够对数据中的非线性结构进行建模,如SDNE[34]使用自编码器(Auto-Encoder)同时优化一阶与二阶相似度,从而保留局部和全局结构,具有一定的稳健性;DNGR[35]则是结合了随机游走和自编码器的方法,能够捕获更高阶相似度;而VGAE和GAE则是采用了图卷积网络(GCN)和内积译码器,与卷积网络类似,图卷积网络通过在图形上定义卷积算子进行计算,解决了稀疏图难以高效计算的问题,同时可以学习节点之间的相似度,具有不错的泛化能力。
表示学习的方法在挖掘城市活动结构方面有着独特的效率和准确性优势,但在顾及静态属性特征以及出行模式异质性方面略有不足,这也是本文需要解决的问题。
2 研究方法
通过公共交通出行数据、POI数据和道路信息数据(在3.1节进行描述),旨在将城市分为若干社区,社区内部保留有居民的出行特征及POI属性特征。不同于传统的社区发现研究,本文不仅仅将高度交互的节点聚合,并且考虑到:①居民的出行应该是有向的;②其他的属性信息(如土地利用类型等),实现更为精确地表示。
数据处理过程首先将整个城市划分为相等的网格(大小为100 m×100 m),并将水体、山脉等不可达的区域删除;然后根据邻近站点将相似网格进行合并[34]形成格网组,格网组的个数为18 108。由此产生的网格具有不同类型的交通可达性,并可探测出高分辨率的出行结构,同时大大减少计算量。
本文的流程主要是:通过N个节点(格网组)之间的属性矩阵及其交互,将N个节点V={v1,v2,…,vN}∈RN×F通过表示学习模型得到U个城市活动结构C={C1,C2,…,CU}∈RU×D,其中,D为表示学习后向量维度。
2.1 相关定义
该模型利用自编码模型对节点的属性信息进行编码,并在编码到解码过程中顾及节点之间的交互信息以及异质性特征,有如下定义。
定义1:属性相似度矩阵Wa。作为局部静态属性特征,为自编码模型的输入数据,Wa={wa,ij}i,j∈(0,18 108),即
(2)

定义2:出行模式图Gp(V,Ep,Wp)。用来描述节点之间的出行信息相似度,V为节点(格网组)的集合,Ep为节点之间的边的集合,Wp为节点之间边的权重矩阵,将其定义为
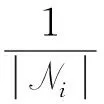
(3)
式中,|Ni|表示从节点i出发所到达的节点数量;rik(rjt)表示从节点i(j)到节点k(t)的流量与节点i(j)流出流量的比值;atti→k(attj→t)表示节点i(j)对于节点k(t)的吸引力,公式为
(4)
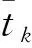
2.2 顾及居民出行异质性的表示学习方法
本文目的是将上述的属性相似度矩阵(R18 108×18 108)和出行模式图(R18 108×18 108)嵌入(映射)到低维空间,得到每个节点的向量表示,其中向量表示的结果蕴藏了输入矩阵的关键信息以及顾及了异质性特征。然后利用集成的图嵌入(表示学习)方法发现城市活动结构,如图1所示。

图1 集成的图嵌入(表示学习)方法Fig.1 Joint network embedding(representational learning) method
集成的图嵌入方法的基础模型为自编码(Auto-Encoder),该模型能够完成对图的非线性编码,并且顾及节点之间的一阶、二阶邻近[34]。自编码模型主要由两个部分组成:将输入数据映射为低维向量表示的编码器和将低维向量重构的解码器。编码器包括一个输入层和若干隐藏层,结构如下
(5)
式中,Yl为编码器第l层的结果;Wl和bl分别为编码器第l层的权重和偏差;σ为激活函数;假如自编码为k层,那么Yk为最终的向量表示,且维度远小于输入数据的维度。

(6)
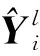
(1) 重构损失。重构损失可以表示为
(7)
通过最小化输入的属性数据与重构后属性数据的差异来保留二者之间的属性相似度。
(2) 出行模式损失。为了将出行模式信息保留在表示结果中,主要思路是将出行模式图嵌入低维空间,即出行模式的节点越相似,那么在低维空间中距离越近。因此,出行模式损失构建为
(8)
(3) 从节点嵌入到社区嵌入。在基于属性信息和出行信息完成节点嵌入之后,节点嵌入后的向量表示用来进行社区类型的发现。通过对节点向量进行聚类,那么具有相似属性和出行模式的区域形成一个社区类型。节点向量表示的默认形式通常为一维向量(d×1),由于每个社区类型通常包含多个节点,用一维向量表示社区类型会过于简化社区类型的复杂组合。因此,该模型使用多元高斯混合模型(GMMs)来增强社区嵌入的表示能力[25]。每种社区类型的特征是一个平均向量和一个协方差矩阵,二者共同提供了社区类型的总体特征。
然而,节点嵌入和随后的聚类过程可能不会产生高度紧凑的社区类型,因为初始节点嵌入过程不能充分考虑社区类型在嵌入空间中的聚集性。平均向量表示社区类型的中心,而协方差矩阵则表示与其中心相关的节点成员的紧致性。由于社区类型检测被视为一个典型的无监督学习问题,因此节点嵌入、社区检测和社区嵌入结合到一个集成的无监督优化模型中,该模型迭代地推导出节点和社区类型的优化嵌入,使社区结构更为准确[25]。节点嵌入可以通过减少节点与社区类型中心的差异来改进,前提是属于相同社区类型的节点应该紧密嵌入社区类型中心。当执行这种联合优化时,丢失信息被反向传播到联合嵌入方案(即自动编码器)并导出改进的节点嵌入。通过更新节点嵌入,致使属于相同社区类型的节点将进行更为相似的嵌入;反过来,在每次迭代之后可以训练出更为一致的社区类型结构。
假设有M种类型的社区,每个社区都服从多元高斯分布(φu,τu),其中φu∈Rd和τu∈Rd×d是第u类中节点向量的平均值和协方差。每种类型由多个区域(格网组)组成,具有相同高斯分布的区域(格网组)属于同一类型的社区。最合适的社区数量由gap statistic模型确定[30]。为了将社区类型检测和嵌入统一到一个集成优化框架中,根据式(8)中对Yi表示结果,需要继续优化以下似然函数
(9)
式中,pr(vi∈Cu)表示节点i是u类型社区的概率;Yi为i节点向量表示。那么,从节点嵌入到社区嵌入的损失函数可以表示为
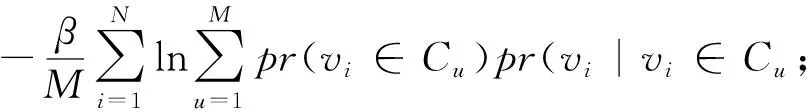
Yi,φu,τu)
(10)
式中,β为平衡参数;M为社区类别的数量。
通过最小化式(10)中的损失函数,可以导出最佳的节点和社区类型嵌入。同时,还可以得到最优解pr(vi∈Cu)。假设Yi未知,可根据式(9)更新节点嵌入。这种迭代的节点嵌入过程可以引导相同社区类型的节点具有相似的嵌入,如图2所示。
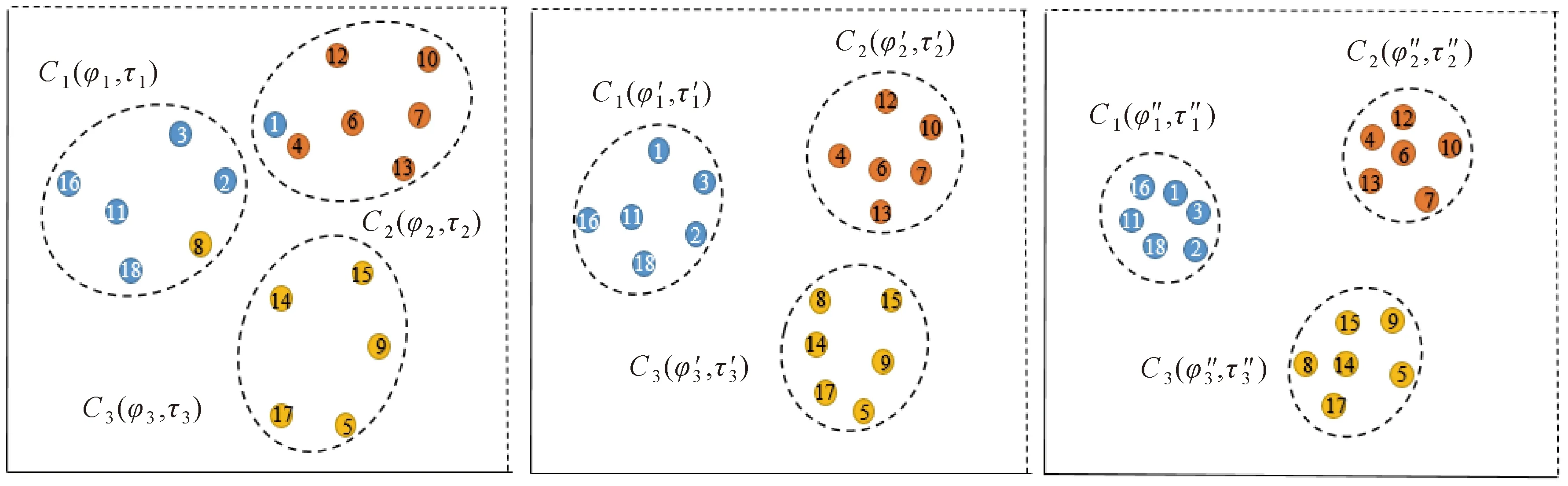
图2 社区发现和节点嵌入的迭代过程Fig.2 Iterative process of community discovery and node embedding
(4) 顾及异质性的表示。在完成节点嵌入到社区嵌入之后,社区之间的居民出行行为表现出比较强烈的异质性。以此为前提,那么需要顾及不同社区之间的异质性特征,因此,根据地理探测器的原理[26],相同群体(社区)的群内差距较小,群体(社区)之间的距离较大,有主函数
(11)
(12)
训练:利用PyTorch框架进行编码,调整参数之后的学习率确定为0.000 5,自编码的层数为4层,每层神经元的个数为[18 108,5000,2000,128]。通过Pytorch中的Adam优化器,根据反向传播原理,使得训练朝着损失变小的方向发展。那么,利用基于自编码模型的表示学习方法将属性相似度矩阵(R18 108×18 108)和出行模式图(R18 108×18 108)嵌入(映射)到低维空间,得到每个节点的向量表示(R18 108×128)。
3 结果分析
3.1 数据描述
深圳市是我国改革开放的先驱,人口超过1250万,占地面积2000多平方千米,毗邻香港特别行政区。深圳市拥有国内最为完备的公交、地铁系统,包括8条地铁干线、199个地铁站点和808条公交线路、6226个公交站点,如图3所示。
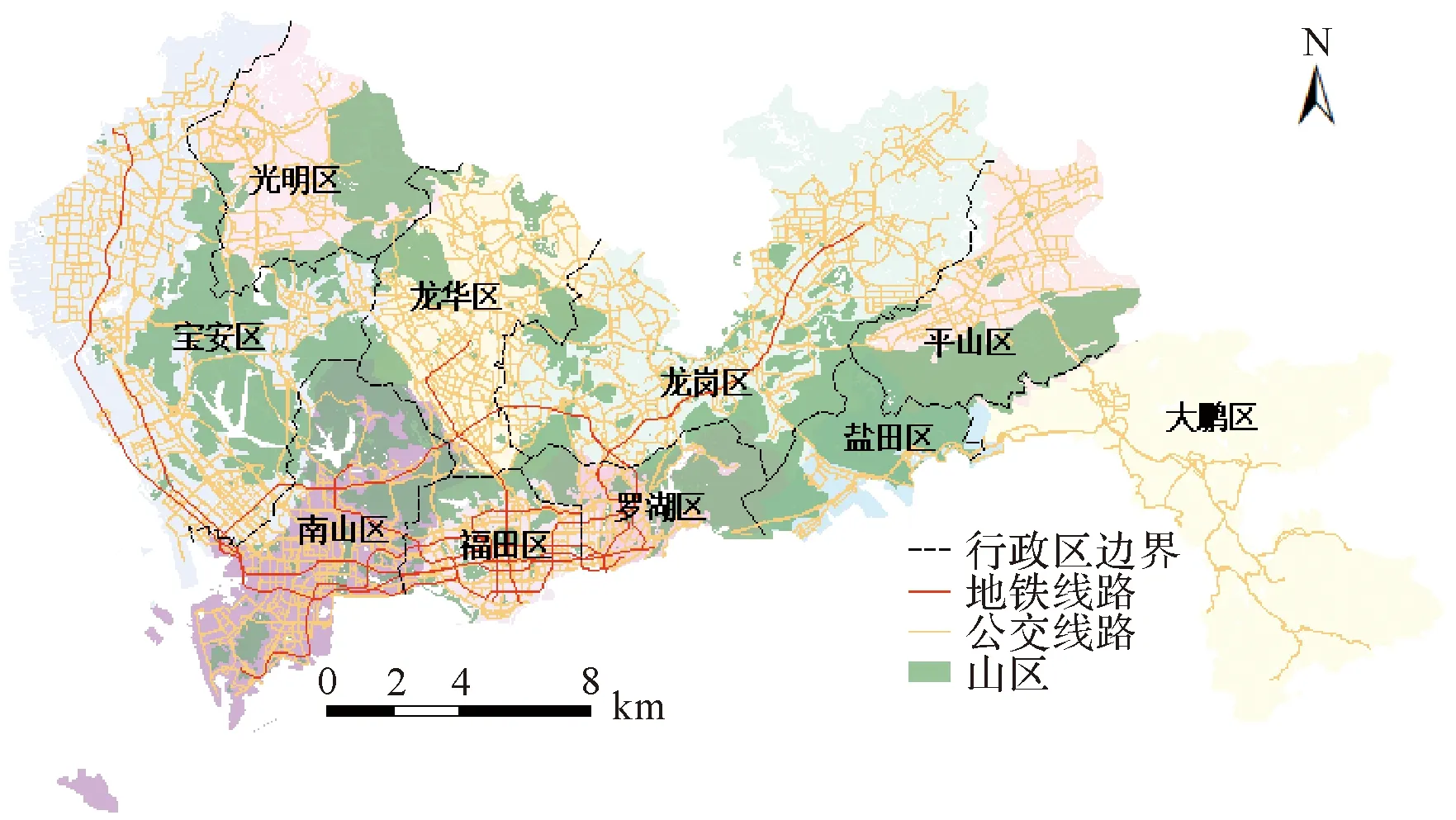
图3 研究区Fig.3 Study area
本文基于SCD、公交轨迹数据、公交网络和道路信息,利用文献[36]的方法对公交出行进行重建。时间为2017-04-03至2017-04-09,记录了出行时间、出行地点、到达时间、到达地点及中转站点,见表1。在一周时间内,搜集了超过40 000 000条记录。具体的数据描述见表2。

表1 2017年4月3日乘客出行示例Tab.1 Example of trip for passengers on April 3, 2017

表2 数据描述Tab.2 Data description
深圳市总共有9个行政区和1个功能区。一般认为罗湖、福田、南山区为深圳的中心区,并且向宝安、龙岗、龙华区扩张。中心区分布有密集的商业区、居住区等,由于市中心土地用途多样,居民可以通过短途出行前往工作和休闲中心。尽管如此,由于工作机会位于罗湖、福田和南山区的中心区域,以及龙华区南部和龙岗区西部,大多数在郊区居住的居民在工作日通过地铁系统进行长途通勤。在一些郊区和远郊区(如宝安、光明、龙华、平山和龙岗区的北部),工业区和城中村仍然是主要的土地利用类型。这些地区的特点是临时工和城市村民集中在此,他们对于公共交通使用相对少于市中心地区的居民。
POI分布具有明显的空间异质性。深圳市拥有54 897个商业点和194个娱乐场所,大部分位于市区(福田、南山和罗湖区);在宝安、光明、龙华和龙岗区的住宅区,分布着一些小型商业点。教育点(3540个)、政府机构(5394个)和医疗服务(7520个)也分布不均:福田和南山区占主导地位,而其他地区的教育和医疗机会很少,在坪山和大鹏,几乎找不到商业和教育机构。宝安、光明西部、龙华、坪山中部、龙岗北部、大鹏边远地区等地有旅游景点群(186个)。
3.2 结果分析
根据本文方法,对深圳市工作日和周末进行了城市活动结构探测,并对探测结果分别进行了分析。
将训练后的嵌入结果,根据Gap Statistic算法[37]和轮廓系数[38]的结果,将工作日(周一至周五)和周末(周六、周天)的城市分为5类。由于城市中每个区域的居民出行模式不同,导致即使相邻区域也会有较大的异质性,深圳市中心区域表现得尤其明显。而在公共交通线路相对不发达地区,如坪山等,具有相对单一的结构。
由图4可知,不管是工作日还是周末,第Ⅰ类社区变化不大,集中分布在龙岗北部、坪山地区和宝安北部等郊区,距离地铁站点较远;第Ⅲ类社区主要分布在南山、罗湖和福田区中心区域,以及龙岗北部距离地铁较近的区域,该类社区公共交通较为发达;第Ⅳ类社区主要分布于宝安、龙岗、龙华等地铁线路发达的地区;第Ⅴ类社区都集中分布在南山、罗湖和福田中心区域。
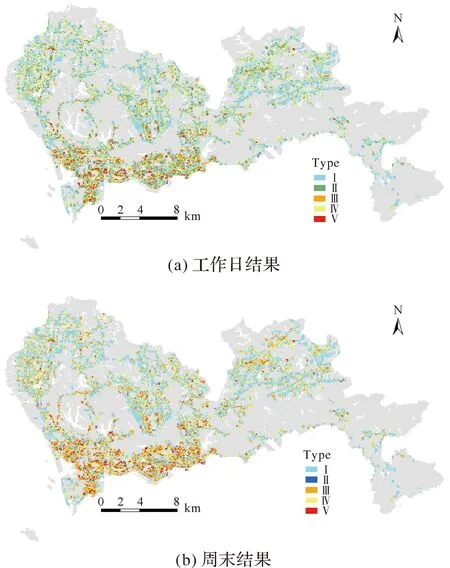
图4 工作日和周末结果Fig.4 Results of joint network embedding on weekdays and weekends
工作日第Ⅱ类社区的地铁线路发达,而周末第Ⅱ类社区只分布于中心区,具有明显的地理空间分布差异。在工作日,第Ⅲ类社区的节点数量要小于周末中第Ⅲ类节点数量,主要由于居民在周末更能呈现出一种随机性,说明周末居民出行的随机性增加。为了进一步发现每个社区的特征,统计了每类社区的平均出行时间、平均逗留时间、平均出行距离,并绘制了图5。

图5 城市活动结构统计Fig.5 Statistics of urban mobility structure
由图5可知,工作日各社区的出行时间(图5(a))、逗留时间(图5(b))都要大于周末所对应的社区,这是由于工作日通勤等因素的影响,出行者数量大于周末,因此,导致工作日出行所用的时间要长;工作日居民由于上班的原因,需要在工作地逗留较长时间。工作日中第Ⅱ类社区的出行距离要大于周末,结合第Ⅱ类社区的空间分布,可以得知第Ⅱ类社区的居民主要进行长距离的通勤活动,而在周末大部分居民的出行为了满足休闲、娱乐等要求,需要进行远距离出行到达商业POI分布密集的中心地段,因此其他社区居民的出行距离比工作日长。如图5(b)所示,第Ⅱ类与第Ⅴ类社区逗留时间差异较大,第Ⅱ类社区逗留时间为5 h左右,而第Ⅴ类社区逗留7.5 h左右。造成这种差距的原因,主要是周末中第Ⅴ类社区的居民购物、娱乐、与朋友聚餐等的需求要比第Ⅱ类社区的居民要强;通过对比深圳市房价数据,周末第Ⅱ类社区主要分布于最高房价地区(平均15万左右),第Ⅴ类社区分布在次高房价地区(平均12万左右),来自次高房价地区的中产阶级人群(第Ⅴ类社区)更愿意享受节假日的闲暇时光,因此,在周末逗留时间要大于来自高房价地区的第Ⅱ类社区人群。
工作日中第Ⅰ类社区出行距离最远,用时也最长,而逗留时间却最少,说明此社区的出行模式为处于偏远地区的远距离出行;第Ⅱ类社区出行时间、出行距离第二长,逗留时间5 h左右,说明此类社区的出行模式为近市中心的中远距离出行;第Ⅲ类逗留时间较长、出行距离较短、出行时间较短,为市中心附近的中远距离出行;第Ⅳ类出行时间与第Ⅲ类相似,而逗留时间较短,与最近地铁站的距离较远,说明此类社区的出行模式为远离市中心的中短距离出行;第Ⅴ类社区出行所用时间最短,逗留时间较长,出行距离最短,与最近地铁站点距离最近,而此类社区的居民基本上是在本区域内活动,逗留时间较长,那么此类社区居民的活动模式为位于中心区域的近距离出行。
在周末,第Ⅰ、Ⅲ、Ⅳ、Ⅴ类社区与工作日的出行模式类似,第Ⅱ类社区的节点较少,完全位于深圳市中心地区,交通便利,为中心区近距离、短逗留出行。为了分析社区之间的流量关系,绘制了工作日和周末的流量图(图6)。

注:圆的大小表示社区的面积大小、颜色表示不同社区类型与图4一致,圆内的统计图表示各类POI密度分布比例,箭头的方向表示流量方向,箭头的粗细表示流量大小。图6 社区之间的流量Fig.6 Flow between communities
由图6可知,从POI分布的角度看,不管是工作日还是周末,第Ⅰ类社区的POI分布密度较小,第Ⅴ类POI分布密度较大;在周末,第Ⅱ类社区各类POI分布密度都很大,主要由于其位于中心城区。相比于周末,工作日的整体流量要高很多,由于第Ⅴ类社区主要位于城市中心区域,工作机会、娱乐等吸引力较大,而第Ⅰ类社区位于相对偏远地区,公共交通不发达,与其他社区的联系不那么紧密。
在工作日,联系最为紧密的为第Ⅲ类、第Ⅴ类社区,主要由于第Ⅲ类社区位于中心区周围,二者之间的可达性较好、吸引力较强;第Ⅱ类、第Ⅴ类社区之间的联系也较为密切,有地铁线路穿过第Ⅱ类社区,并且能够达到第Ⅴ类社区。在周末,第Ⅱ类与第Ⅴ类社区的联系较为紧密,主要是因为二者都位于城市中心区域,公共交通线路发达、可达性好、吸引力强。
3.3 与其他方法比较
为了验证本方法的可靠性,本文选取了经典的Combo算法[39]和深度学习中的GraphEncoder算法[40]进行比较。其中,Combo算法提供了一种通用的优化框架,以适应不同目标函数的社区发现;GraphEncoder算法基于自编码模型进行节点的聚类,其效果由于传统的聚类算法,层数为4层,根据Gap statistic确定聚类数目为10,由于Combo和GraphEncoder只能处理一个网络,因此输入相似度矩阵计算为属性和公交出行模式矩阵的权重相等,即W=0.5wa+0.5wp。
本文利用式(11)对结果进行定量化评估,依据为是否顾及不同分区之间的空间异质性。由于Combo算法不产生节点嵌入,因此使用W来计算它的模块化的值,本文提出的模型在工作日和周末都明显优于Combo算法和GraphEncoder算法,二者由于只考虑当地社区内的公交连接,不利用长途出行信息的提取,因此可能无法检测到有意义的公交出行社区。此外,Combo不考虑属性相似性和出行联系的细节(例如吸引力、旅行时间和目的地分布),而这些都是帮助识别动态社区结构的关键因素。GraphEncoder是一种典型的深度学习聚类方法,可用于社区检测,然而,它只考虑节点出度、入度及相似度信息,因此没有考虑必要的旅行动态。
Combo和GraphEncoder算法在工作日的社区检测结果如图7和图8所示。由图7可知,Combo算法得到的结果显示出很强的局部性模式,因为它执行了模块化优化原则,并提取了具有较强的内部连接社区。Combo算法的缺点是它不考虑连接深圳市区和郊区的长途旅行。此外,多源信息(如属性化信息)没有办法利用Combo算法建模,更没有体现空间异质性特征。

图7 Combo算法得到的工作日分区结果Fig.7 Results of weekdays via Combo algorithm
与Combo算法相比,GraphEncoder算法在揭示全局社区结构方面取得了更好的结果,因为它能够建立高阶相似并将模式图转换为节点之间的嵌入(图8),在顾及空间异质性方面优势不明显。并且,该方法也不能融合属性信息,这一缺陷导致了不同社区类型节点数产生不平衡的结果。

图8 GraphEncoder算法得到的工作日分区结果Fig.8 Results of weekdays via GraphEncoder algorithm
由表3可知,本文的方法q值得分都很高,说明社区之间居民出行的差异性比较明显,很好地顾及了异质性;而Combo算法在顾及异质性方面要比GraphEncoder算法效果好,主要是因为该算法内部有modularity的优化能在一定程度上体现社区之间的差异。由此可见,本文方法除了能够融合静态、动态信息外,还能够顾及到社区之间的异质性特征,使得最终的表示结果更为准确。
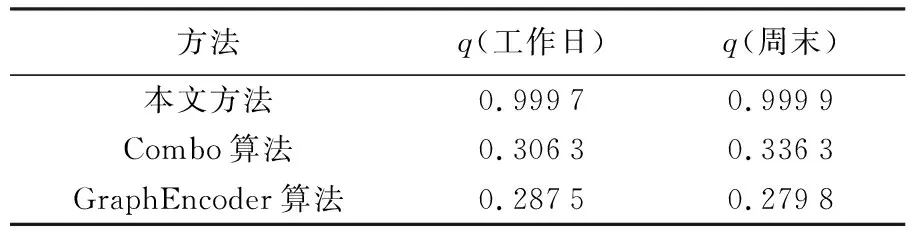
表3 各方法的比较Tab.3 The q-values comparison of baseline methods
4 结 论
本文提出一种顾及异质性的城市活动结构发现方法,该方法通过融合静态属性信息及动态的出行信息,实现城市活动结构的表示。该方法在训练过程中,实现了从节点嵌入到社区嵌入的过程,并在此过程中纳入地理探测器的思想,顾及了异质性特征。以深圳市的刷卡数据为基础,验证了该方法的有效性,结果表明,深圳市居民出行具有明显的多样性,与行政区划关系不大,在空间上表现出强烈的差异性。
通过对特定城市活动结构中常见的出行模式进行分析,可以揭示公交服务不尽如人意的原因。特别地,本文通过城市活动结构探测结果发现深圳市工作和居住的不平衡是导致市区主要工作中心和郊区单功能居住区早晚高峰时间定向流动的主要因素之一。在缓解交通问题的其他战略交通规划工作中,交通城市活动结构发现地图也可用于优先考虑未来的土地开发计划[41],例如在特定区域开发高科技园区和办公楼,以促进整体交通无障碍性。对于公共交通出行较少的城市活动结构,应鼓励公共交通导向型发展,以促进公共交通乘客量和减少汽车使用。通过所提出的方法,可以深入理解城市,包括居民的流动性和可达性、社会不平等、不同城市地区的功能[42-43],以及随着时间的推移验证现行公共交通系统的有效性。这些知识可以为城市规划者和管理者提供环境可持续、公平和高效的公共服务提供参考。在后续的研究中,计划研发先进的多层、多任务嵌入技术,例如地铁和公交服务之间的传输,以更好地进行模拟层间之间的交互。
