基于CNN与Bi-LSTM混合模型的中文文本分类方法
2023-02-18王佳慧
王佳慧
(新疆警察学院 信息安全工程系,新疆 乌鲁木齐 830000)
0 引言
文本分类是自然语言处理任务中的一项基础性工作,其在现实生活中的应用非常广泛。常见的应用场景有:新闻分类[1]、垃圾邮件过滤[2]、情感分类[3]、舆情分析[4]、意图分类[5]等。随着大数据时代的来临和信息基础设施建设的迅速发展,互联网上的文本信息呈现指数性增长。对文文本进行分类,不仅能够有效缓解信息过载问题,拓宽信息处理的应用领域,还可以为舆情分析和监控提供技术保障,使政府部门能够更加全面快速地掌握舆情动态,从而及时有效地开展舆论引导[6]。
目前,文本分类方法主要分为:基于传统机器学习的分类方法和基于深度学习的分类方法。基于传统机器学习的文本分类模型可以拆分为文本特征学习和分类器,根据选择的特征对文本进行表示,然后传入分类器中,就能实现文本分类。常用于分类的机器学习算法有:支持向量机(Support Vector Machines,SVM)[7],朴素贝叶斯(Naive Bayesian,NB)[8],K-最近邻(K-Nearest Neighbor,KNN)[9]等。基于传统机器学习的文本分类需要进行特征工程才能实现,特征的好坏会直接影响分类效果。而人工进行特征选择的难度,直接增加了利用传统机器学习方法进行文本分类的难度。
基于深度学习的文本分类方法不仅不需要人工选择特征,还可以挖掘出文本数据中的潜在特征。随着研究的不断深入,各种深度学习模型开始应用于文本分类。Kim[10]提出的Text CNN(Text Convolutional Neural Networks)模型,将主要用于图像领域的卷积神经网络应用于文本分类领域,并且在多个文本分类任务上取得了较好的效果。Kalchbrenner 等[11]提出一种动态卷积神经网络(Dynamic Convolutional Neural Network,DCNN)模型,该模型在池化层采用动态K 最大池化(K-Max Pooling),使得句子建模具有更好的适应性。Zhang 等[12]提出一种字符级别的CNN 文本分类模型,该模型不需要依靠语法信息和语义信息,就能实现理想的分类效果。与Text CNN 相比,该模型在面对拼写错误和表情符号时,具有更好的鲁棒性。除卷积神经网络,循环神经网络(Recurrent Neural Network,RNN)[13]也常用于文本分类。RNN 除能够读取当前信息,还能记录之前读取过的信息。长短期记忆网络(Long Short-Term Memory,LSTM)[14]通过改变循环层结构,改善了传统RNN 容易梯度爆炸和梯度消失的问题。门控循环单元(Gated Recurrent Unit,GRU)[15]作为循环神经网络的变体,也常用于文本分类。Lai 等[16]提出循环卷积神经网络(Recurrent Convolutional Neural Network,RCNN)模型。该模型先通过Bi-LSTM 获得文本的上下文信息,再将Bi-LSTM 获取的上下文信息和原本的词向量进行拼接,生成新的词向量。最后将新的词向量进行最大池化操作,提取重要特征。与传统词向量相比,该模型获取的词向量包含更加丰富的语义信息。
为了更好地提取特征,挖掘文本更深层次的语义信息,提升中文文本分类准确性,本文提出一种基于CNN 与Bi-LSTM 混合模型的中文文本分类方法。首先,使用Jieba分词实现中文文本分词;其次,利用词嵌入模型Word2vec,将词语转换成低维、稠密的词向量;再次,分别使用CNN 模型和Bi-LSTM 提取出文本的局部特征和全局特征,并且将局部特征和全局特征进行拼接融合;最后,将融合的特征送入分类器Softmax 中实现分类。
1 基于CNN与Bi-LSTM 的混合模型构建
1.1 模型结构
基于CNN 与Bi-LSTM 的混合模型结构如图1所示。
从图1可以看出,该混合模型主要由以下6部分构成:
(1)预处理层。将输入的中文文本进行分词,将词语作为文本表示的基本单元,然后利用构建的停用词表将停用词进行过滤。
(2)词嵌入层。将经过分词后的中文文本输入到词嵌入层,获取以向量形式表示的文本。
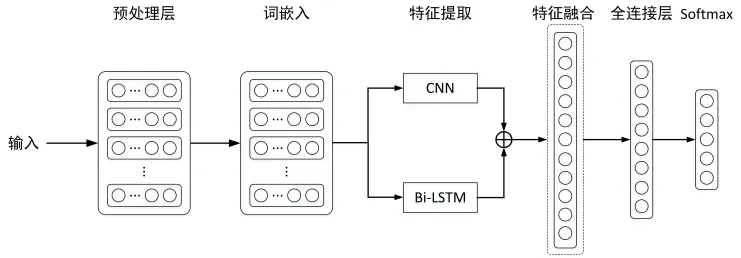
Fig.1 Hybrid model structure based on CNN and Bi-LSTM图1 基于CNN与Bi-LSTM 的混合模型结构
(3)特征提取层。特征提取层包含两条通道:一条通道把以向量形式表示的文本通过CNN 模型,实现文本局部特征提取;另一条通道把以向量形式表示的文本通过Bi-LSTM 模型,实现文本全局特征提取。
(4)特征融合层。将局部特征和全局特征进行融合,生成全新的特征向量。
(5)全连接层。将融合的特征向量输入全连接层生成特定维度的向量。
(6)Softmax 层。将全连接层的输出向量送入Softmax函数中实现分类。
1.2 文本预处理
本文所做的文本预处理工作主要包括:分词和停用词过滤。在中文里,词语是最小的能够独立运用的语言单位。不同于英文等语言,中文的词语之间并没有空格这种明显的标志以确定词语的边界,因此在文本表示之前,必须先将文本切分成词语。本文选择使用Jieba 分词工具实现分词[17]。Jieba 分词具有精确模式、全模式、搜索模式3种模式。其中,精确模式能够试图将句子最精确地切开,最适合文本分析,因此将Jieba 分词设置为精确模式。经过Jieba分词的中文语句如表1所示。

Table 1 Jieba word segmentation result display表1 Jieba分词结果展示
除要完成分词工作,在预处理阶段还需要将停用词进行过滤。停用词指那些在文本中频繁出现的,但却对文本类别判断帮助不大的词语。将无用的停用词进行过滤,能够减少文本中的“噪声”,节省存储空间,提升文本分类效率。目前,哈工大停用词表、百度停用词表、四川大学机器智能实验室停用词表等一些主流的中文停用词表已被公开,并广泛应用于自然语言处理相关的各项任务中。但这些停用词表并非在所有任务上都通用,例如,百度停用词表中包含的“高兴”和“哈哈”等词可以表达喜悦的情感,在情感分类时,如果将这些词语当作停用词过滤,会直接影响到分类结果。因此,在面对不同的处理任务时,需要设置不同的停用词表。本文结合后续实验语料实际情况,对已经公开的停用词表进行筛选,确定实验使用的停用词表,并完成停用词过滤。
1.3 词嵌入
文本必须要转换成计算机能够识别和计算的向量形式,才能输入深度学习模型中进行特征提取。目前,将文本转化成向量的方法有很多,常见的有one-hot、tf-idf、ngram、Glove[18]和Word2vec[19]等。本文选择能够训练出低维稠密的词向量,并且词向量能够体现词语之间语义相似度的Word2vec 模型对文本中的词语进行表示。Word2vec是目前文本分类领域最常用的一种分布式文本表示方法,由谷歌的Mikolov 等人于2013年提出。Word2vec的本质是一个浅层的神经网络模型。按照训练方法不同,Word2vec可以分为CBOW 模式和Skip-Gram 模式[20]。CBOW 模式是根据上下文的词预测目标词,而Skip-Gram 模式是根据目标词预测上下文。CBOW 模式训练速度较快,但从表达语义信息的准确性方面看,Skip-gram 的模式效果更好。因此,本文最终使用Skip-Gram 模式完成词向量训练。Skip-Gram 模型结构如图2所示。
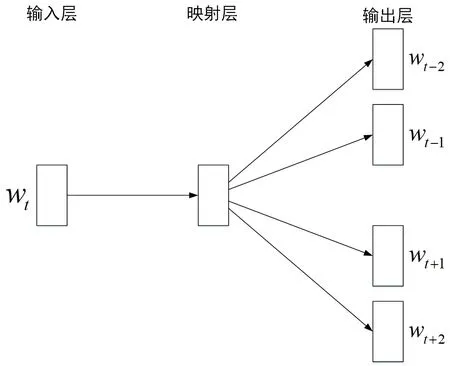
Fig.2 Skip-Gram model structure图2 Skip-Gram 模型结构
1.4 局部特征提取
文本的局部特征主要由CNN 模型进行提取(见图3),CNN 通道主要由卷积层和池化层两部分构成。
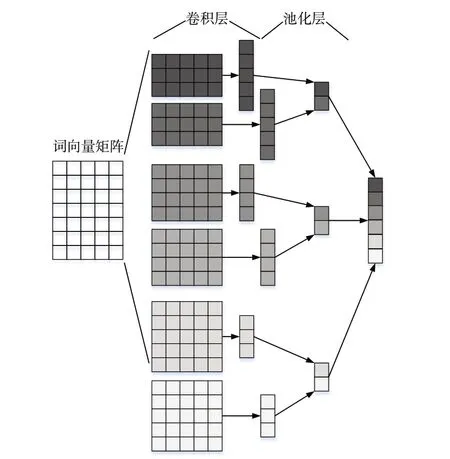
Fig.3 CNN model structure图3 CNN模型结构
在卷积层,首先需要使用不同尺寸的卷积核对已经向量化的文本进行卷积操作。卷积操作指每个卷积核都按照一定的步长对输入的文本矩阵进行扫描,计算出文本矩阵被扫描到的当前区域和卷积核之间的点积,生成特征矩阵。不同尺寸的卷积核代表着不同大小的感受野,使用不同尺寸的卷积核进行卷积能够提取出更加丰富的局部语义信息。
为了提高模型表达能力,经过卷积操作提取出的文本特征矩阵还必须要经过激活函数进行非线性转化。本文选择ReLU 作为激活函数,与其他激活函数相比,ReLU 函数没有复杂的指数运算,收敛速度较快,还能够在一定程度上解决梯度消失问题。ReLU 函数的计算公式如式(1)所示。
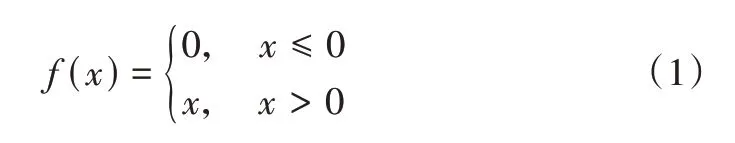
在池化层,需要对卷积层输出的特征作进一步筛选,从而降低特征维度。本文选择最大池化对文本特征矩阵进行池化操作,即只取出特征矩阵中最突出的一个特征,舍弃其他特征。经过池化后,从卷积层输出的原本维度不同的特征向量能够被转化成同一维度。
1.5 全局特征提取
文本的全局特征主要由Bi-LSTM 模型进行提取。LSTM 模型是一种特殊的RNN,它通过引入“门控机制”对传送过来的信息进行筛选,这在一定程度上缓解了传统RNN 非常容易出现的“梯度消失”和“梯度爆炸”问题。LSTM 模型内部结构如图4所示。

Fig.4 LSTM model structure图4 LSTM 模型结构
可以看出,LSTM 模型中主要由3 个不同的“门”和1 个“记忆细胞”构成。3个不同的“门”指“忘记门”“输入门”和“输出门”。
“忘记门”决定了什么信息应该被删除,不能够继续传送下去,其公式如式(2)所示。其中,ht-1是上一时刻隐藏层传入的信息,xt是当前时刻输入的信息。
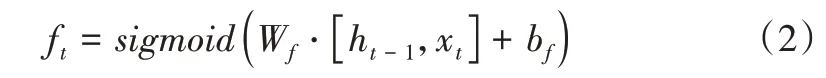
“输入门”决定了什么信息应当留下继续传递给“记忆细胞”,其公式如式(3)所示。
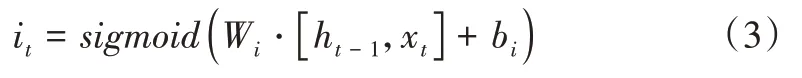
经过“输入门”的筛选,此时“记忆细胞”会进行更新,其公式如式(4)所示。其中,Ct-1是上一时刻的记忆细胞所存储的信息。

“输出门”决定了什么信息应当保留被输出。其公式如式(5)所示。
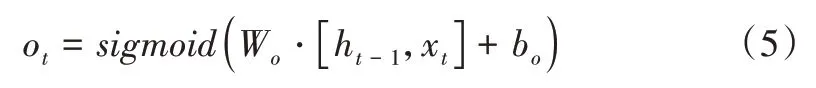
当前时刻隐藏状态的信息,需要输出传送给下一时刻的LSTM 单元,由ot和记忆细胞共同决定,其公式如式(6)所示。

LSTM 模型通过设计能够对信息进行选择性的“记忆”与“更新”,但其在当前时刻只考虑到了上文信息,并没有考虑到下文信息。Bi-LSTM 模型通过将一个前向的LSTM模型和一个后向的LSTM 模型进行叠加,实现了文本上下文信息的同时获取。Bi-LSTM 模型结构如图5所示。
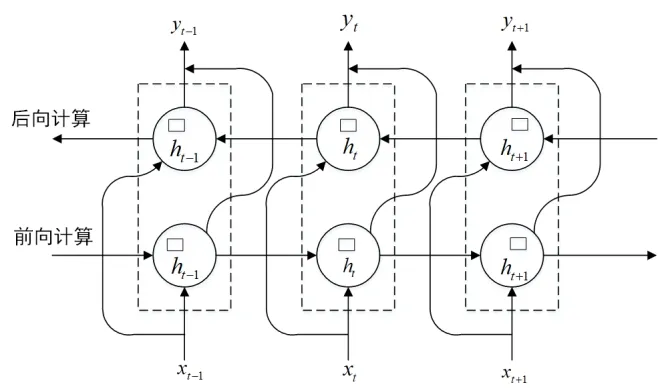
Fig.5 Bi-LSTM model structure图5 Bi-LSTM 模型结构
Bi-LSTM 模型在t时刻的隐藏状态ht是由t时刻前向LSTM 模型的隐藏状态和后向LSTM 模型的隐藏状态共同拼接而成。拼接具体实现如式(7)所示。

利用Bi-LSTM 模型特征提取最终是为了进行文本分类,因而并不需要采集Bi-LSTM 模型每一时刻的输出,只需将Bi-LSTM 模型最后一个时刻的输出提取出来作为特征。最后一个时刻的输出示包含了上下文语义信息的特征。与CNN 模型、LSTM 模型相比,Bi-LSTM 模型能够挖掘出更加丰富的全局语义信息。
1.6 特征融合
常用的特征向量融合方法有:拼接、按位相加、平均等。将特征向量直接进行拼接,能够有效保留文本的原始特征,避免特征减损。因此,本文选择将CNN 模型所提取文本的局部特征和Bi-LSTM 模型提取出的全局特征拼接成为一个特征向量,代表当前文本特征。假设CNN 模型提取出的特征是Fc,Bi-LSTM 模型提取的特征是Fl,这两个特征经过拼接生成新的特征F,计算公式如式(8)所示。其中,⊕ 表示向量拼接操作。

1.7 分类结果获取
经过融合的特征需要先传入全连接层。全连接层的主要作用是将特征向量经过线性运算整合成任意维度的向量。后续要使用Softmax 分类器进行分类,因而此处输出向量的维度必须与分类的类别数相同。特征向量经过压缩后,再传入Softmax 层就可以实现分类。这一过程,可以用式(9)表示。其中,F是经过融合后的特征,Wc是全连接层的权重,bc是偏置值,y表示预测的分类结果。

Softmax 函数能够将输入的数据进行归一化,即将输入转换成0~1 的概率。其中,概率值最大的一类,即为预测结果。
2 实验与结果分析
2.1 实验数据
为了验证本文提出模型的有效性和适用性,本文选择使用复旦大学中文文本分类语料和谭松波酒店评论语料作为实验数据,分别进行实验。
复旦大学中文文本分类语料是一个多分类语料,包括农业、电脑、环境、体育等20 个类别,各类别数据不均衡。该语料共包含19 637 条数据,其中训练集9 804 条,测试集9 833 条。本文从中抽取数据量最多6 个类别,共计14 951条数据进行实验。
谭松波酒店评论语料是从携程网上自动采集,并经过整理形成的二分类情感语料。该语料共计10 000 条,其中正向情感7 000 条,负向情感3 000 条,语料本身并没有进行训练集和测试集划分。本文从中抽取5 000 条正向数据和3 000条负向数据进行实验。
将筛选整理后的数据以6∶2∶2 的比例重新划分成训练集、验证集和测试集,形成最终实验数据。实验数据划分情况如表2所示。

Table 2 Division of experimental data表2 实验数据划分
2.2 实验环境
为了提高模型训练速度,本文选择使用GPU 进行加速运算。具体实验环境配置如表3所示。

Table 3 Experimental environment表3 实验环境
2.3 评价指标
衡量分类模型性能的常用评价指标有:准确率(Accuary)、精确率(Precision)、召回率(Recall)、F1 值(F1-score)等。假设当前分类为二分类,根据文本真实标签和分类模型预测标签,经过实验后的文本可以实际被划分为TP、FP、TN 和FN 4 种情况。TP 代表实际标签为正,模型预测也为正的文本数;FP 代表标签为负,但是模型预测却为正的文本数;TN 代表实际标签为负,模型预测也为负的文本数;FN 代表实际标签为负,但是模型预测却为负的文本数。
准确率、精确率、召回率和F1 值的计算公式如式(10)—式(13)所示。

可以看出:①准确率这一指标虽然能够非常直观地展示出分类正确的样本数量占样本总数的比例,但在各类别样本数量特别不均衡的情况下,样本量大的类别会绝对主导准确率大小;②精准率和召回率此消彼长;③F1 值充分考虑了精确率和召回率这两项评价标准,是精确率和召回率的调和平均数,用F1值评价模型较为客观。
综上所述,本文选择使用准确率和F1 值作为此次实验的评价指标。
2.4 实验设置与结果分析
为避免单次实验可能存在的偶然性和误差,使实验结果更具说服力,本文将每次实验重复5 次,取5 次实验结果的平均值作为最终结果。
2.4.1 模型参数选择实验
深度学习模型参数设置非常关键,合适的参数能够帮助模型提升分类性能。为了使基于CNN 与Bi-LSTM 的混合模型获得最好的分类效果,本文选择对模型中的部分参数进行实验确定。模型参数选择的实验数据使用谭松波酒店评论语料。
(1)Word2vec 词向量维度选择。为了训练出具有更好表征能力的高质量词向量,本文主要针对Word2vec模型中的词向量维度进行实验。将Skip-Gram 模式下训练出的不同维度的词向量送入本文构建的混合模型中进行实验,实验结果如图6所示。
由实验结果可知,词向量维度并不是越大越好。在Skip-Gram 模式下进行训练时,词向量维度等于300 时,分类准确率最高。因此,本文将Word2vec模型的词向量维度设置为300。
(2)隐藏层单元个数选择。隐藏层单元个数是Bi-LSTM 模型中的一个重要参数。本文将Bi-LSTM 模型中隐藏层单元个数设置为64、128 和256 分别进行实验,实验结果如图7所示。
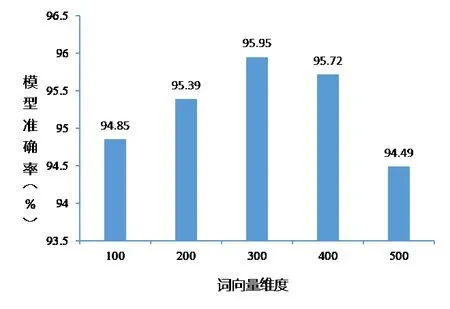
Fig.6 Experimental results of dimension selection of word2vec图6 word2vec词向量维度选择实验结果
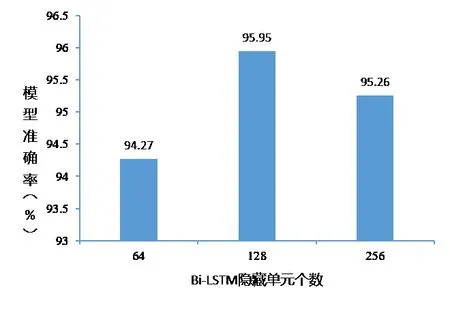
Fig.7 Experimental results of number selection of hidden layer cells图7 隐藏层单元个数选择实验结果
由实验结果可知,隐藏层神经单元个数为128 时,模型准确率最高。因此,本文将混合模型的隐藏层单元个数设置为128。
(3)卷积核数量选择。卷积核数量指进行卷积操作的卷积核个数,卷积核数量决定着生成的特征图数量。但并不是卷积核个数越多就越好,卷积核个数过多很容易造成模型过拟合。本文将每种卷积核数量设置为64、128 和256分别进行实验,实验结果如图8所示。

Fig.8 Experimental results of convolution kernel number selection图8 卷积核个数选择实验结果
从上述实验结果可知,当每种尺寸卷积核个数设置为256 时,模型准确率最高。因此,本文将混合模型中每种卷积核个数设置为256。
除以上经过实验确定的参数外,模型中还有卷积核尺寸、学习率、批大小等参数需进行设置。本文参考相关文献[21],将模型其余参数进行设置,设置情况如表4所示。

Table 4 Model parameter settings表4 模型参数设置
2.4.2 特征融合对比实验
为了验证基于向量拼接的特征融合方法的有效性和优越性,本文将其与向量按位相加、向量按位相加后平均这两种融合方法进行对比实验。两个向量能够进行按位相加的前提条件是向量维度相同。CNN 模型提取出的特征Fc的维度与卷积核个数有关,Bi-LSTM 模型提取出的特征Fl与隐藏单元个数有关,两种特征向量的维度并不相同。为了让这两种向量转换为同一维度,实现按位相加,将CNN 模型提取出的特征Fc进行线性变换,转换成与特征Fl维度相同的向量。线性变换中的参数通过模型训练确定,特征融合对比实验数据使用谭松波酒店评论语料。实验结果如表5所示。
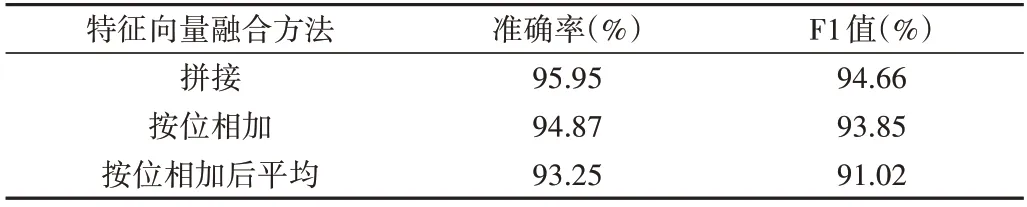
Table 5 Experimental results of feature fusion comparison表5 特征融合对比实验结果
从以上实验结果可知,使用向量拼接方法,得到的分类准确率和F1 值最高。该方法能够有效保留文本的原始特征,避免特征减损。
2.4.3 分类模型对比实验
为了验证基于CNN 与Bi-LSTM 的混合模型的有效性和优越性,本文选择了多个常用于文本分类的机器学习模型和深度学习模型作为对比模型进行实验。分类模型对比实验分别在谭松波酒店评论语料和复旦大学中文文本分类语料上进行。面对不同的实验语料,混合模型的参数设置保持不变,与模型参数选择实验确定的参数保持一致。
(1)机器学习模型。本文主要选取KNN、NB 和SVM 这3 种机器学习模型作为对比模型。这3 种模型都是先进行预处理,再利用TF-IDF 实现文本向量化,然后送入机器学习模型中实现分类。其中,KNN 中的K 值设定为11,SVM的核函数设定线性核函数。
(2)深度学习模型。本文主要选取CNN、LSTM、GRU、Bi-LSTM 和 RCNN 这5 种深度学习模型作为对比模型。这5 种模型都是先进行预处理,再使用Word2vec 模型实现文本向量化,然后将训练好的词向量送入深度模型中提取特征,最后将特征送入Softmax 函数中实现分类。这些深度学习对比模型的参数设置和本文构建的混合模型参数设置保持一致。对比实验结果如表6所示。

Table 6 Experimental results of classification model comparison表6 分类模型对比实验结果
从上述实验结果可知:①在文文本分类这一任务上,大部分深度学习模型的分类效果是优于传统机器学习模型的;②在3 种机器学习模型中,SVM 模型的分类效果最好,在酒店评论数据集上,SVM 模型取得了较高的准确率和F1 值,超越了深度学习模型LSTM;③在5 种深度学习对比模型中,CNN 模型和RCNN 模型分类效果最好,LSTM 模型分类效果最差,可能是因为本文进行实验的语料偏短,导致LSTM 模型在一定程度上无法充分发挥其捕捉全局信息的优势;④本文构建的基于CNN 与Bi-LSTM 的混合模型在中文文本分类这一任务上的表现优于其他对比模型,将局部特征和全局特征进行融合能够在一定程度上有效提升文本分类准确率和F1值。
3 结语
本文提出一种基于CNN 与Bi-LSTM 混合模型的中文文本分类方法,该方法能够有效挖掘出文本的深层次语义特征,改善了CNN 模型难以获取文本全局特征和Bi-LSTM难以获取局部特征的问题。将本文提出的模型与常用于文本分类的机器学习模型及深度学习模型进行实验对比,实验结果表明,基于CNN 与Bi-LSTM 混合模型的文本分类方法能够有效提升中文文本分类准确性。在未来研究中,尝试将注意力机制加入模型,进一步提高模型适用性和分类准确性。
