基于多流卷积神经网络的跌倒检测算法
2023-02-18邬春学
张 陶,邬春学
(上海理工大学 光电信息与计算机工程学院,上海 200093)
0 引言
第七次全国人口普查显示,我国60 岁及以上人口为26 402 万人,占总人口的18.70%(其中,65 岁及以上人口为19 064 万人,占13.50%)。可见我国人口老龄化进一步加深,如何妥善地照顾老年人已成为社会各界关注的焦点问题。据调查,每年大约有30 多万人死于意外跌倒,其中60岁以上的老年人占一半以上,可见意外跌倒已成为老年人意外死亡的头号杀手,同时一半以上的老年人跌倒是发生在家里,而且大部分较为严重的后果并不是在跌倒的第一时间造成,而是由于跌倒后没有得到及时帮助和救护。通常,子女和其他看护人员无法对老年人进行全天候照看,因此开发一套高效实用的老年人跌倒检测系统尤为重要。系统能够准确地检测到老年人的跌倒行为,并发送报警信息以及时呼叫救援,从而避免情况进一步恶化。
1 相关研究
目前,针对跌倒检测的研究主要有3 个方向,分别是基于可穿戴设备的检测方法、基于分布式环境参数采集的检测方法以及基于机器视觉的跌倒检测方法。
基于可穿戴设备的跌倒检测[1-3]主要是人体佩戴集成了各类传感器设备,通过集成的传感器检测人体运动数据变化,如加速度、方位角等信息,以进行跌倒检测。Nho等[4]使用心率传感器和0 加速度计融合的基于聚类分析的用户自适应跌倒检测方法,通过特征选择提出最好的13维特征子集进行跌倒检测。但是可穿戴设备要求使用者实时佩戴设备,一定程度上会影响日常生活,并且设备还会受限于电量等因素干扰,有时老人也容易忘记佩戴,因而实际用户体验不佳。
基于分布式环境参数采集的跌倒检测技术[5-7]是通过在家居环境中安装传感器,主要采集地面振动[7]或压力数据、环境声音[8]以及雷达信号等之类的信息,分析人体在采集区域内的环境信息进行跌倒检测。该类方法对用户影响较小,无需实时佩戴设备,但是检测区域大小受限,若所有场景全覆盖则会造成成本增加,并且往往无法有效地区分振动源,容易受到环境干扰,从而导致误报,降低系统检测准确率。
基于机器视觉的跌倒检测技术[9-15]主要通过摄像头采集人体日常生活的影像,并对视频序列进行相应分析,提取出人体的一些特征信息,进而判断人体跌倒行为和非跌倒行为。Ge 等[9]以YOLOv3-tiny 目标检测算法为基础融合通道注意力机制和空间注意力机制,增加了检测准确性。Chhetri 等[14]使用增强型动态光流技术对光流视频的时间数据进行等级池化编码,从而提高跌倒检测处理时间并提高动态光照条件下的分类精度。基于机器视觉的跌倒检测是非侵入式的,不需要用户实时佩戴设备,因而不会影响老人的日常生活,其成本相对较小,并且检测范围广,因而获得广泛关注。
传统跌倒检测算法一般通过人工设计相关特征参数以表征运动目标,例如宽高比、质心高度等,再通过阈值分析法完成判断,但是人工选取的特征参数往往无法全面地表征目标。近年来,随着智能家居的不断发展,家居环境中视频监控的逐渐普及为家居场景中老年人的跌倒行为检测提供了新的解决方案。并且,随着机器视觉的发展,已经可以从监控视频中提取到人体轮廓和运动特征,再经卷积神经网络自动地通过卷积核提取目标特征[16],这样做既可避免佩戴相关设备,还克服了人工设计特征的片面性,进而达到对目标的智能化检测、监控和管理。
鉴于此,本文基于机器视觉的跌倒检测方法提出一种添加了融合流的多流卷积神经网络模型,以视频序列中提取出的人体轮廓图为空间流卷积神经网络输入,以运动历史图作为时间流神经网络输入,并新增融合流用于融合时间流和空间流特征提取网络中的时空信息,更全面地利用时空特征对跌倒行为进行检测。实验证明,该模型对跌倒行为检测具有良好的实时性和可靠性。
2 多流卷积神经网络
双流卷积神经网络的融合阶段是在单流网络的全连接层和分类函数之后的一种晚融合,这种融合方式在一定程度上忽略了时空信息之间的交互,无法充分利用网络中的所有有效信息[17]。鉴于此,本文在双流卷积网络模型的基础上,加入一个融合流网络,与时间流和空间流一起组成一个三支流的多流卷积神经网络模型,其网络结构如图1 所示。融合流单独于时间流和空间流作为一个全新的融合流网络,分别对时间流和空间流的最后两层卷积层进行时空特征融合,并将得到的两个时空融合特征进行融合得到多级时空融合特征,最后将这3 支流的输出进行晚融合从而得到最终跌倒检测结果。
从图1 可以看出,相较于传统的双流卷积模型,本文提出的多流卷积神经网络模型在特征提取阶段就进行了对应层级的特征融合。传统双分支结构的晚融合对特征提取网络中的时间信息和空间信息间利用不充分,致使丢失了网络浅层中的局部信息和网络深层中的全局信息。本文提出的方法对特征提取阶段对应层进行了一定程度上的早融合,即使用了全局信息,同时也保留了一部分局部信息,极大程度上结合了特征提取网络中的时间信息和空间信息间,弥补了传统双分支结构全连接层和分类函数之后晚融合特征的缺点。
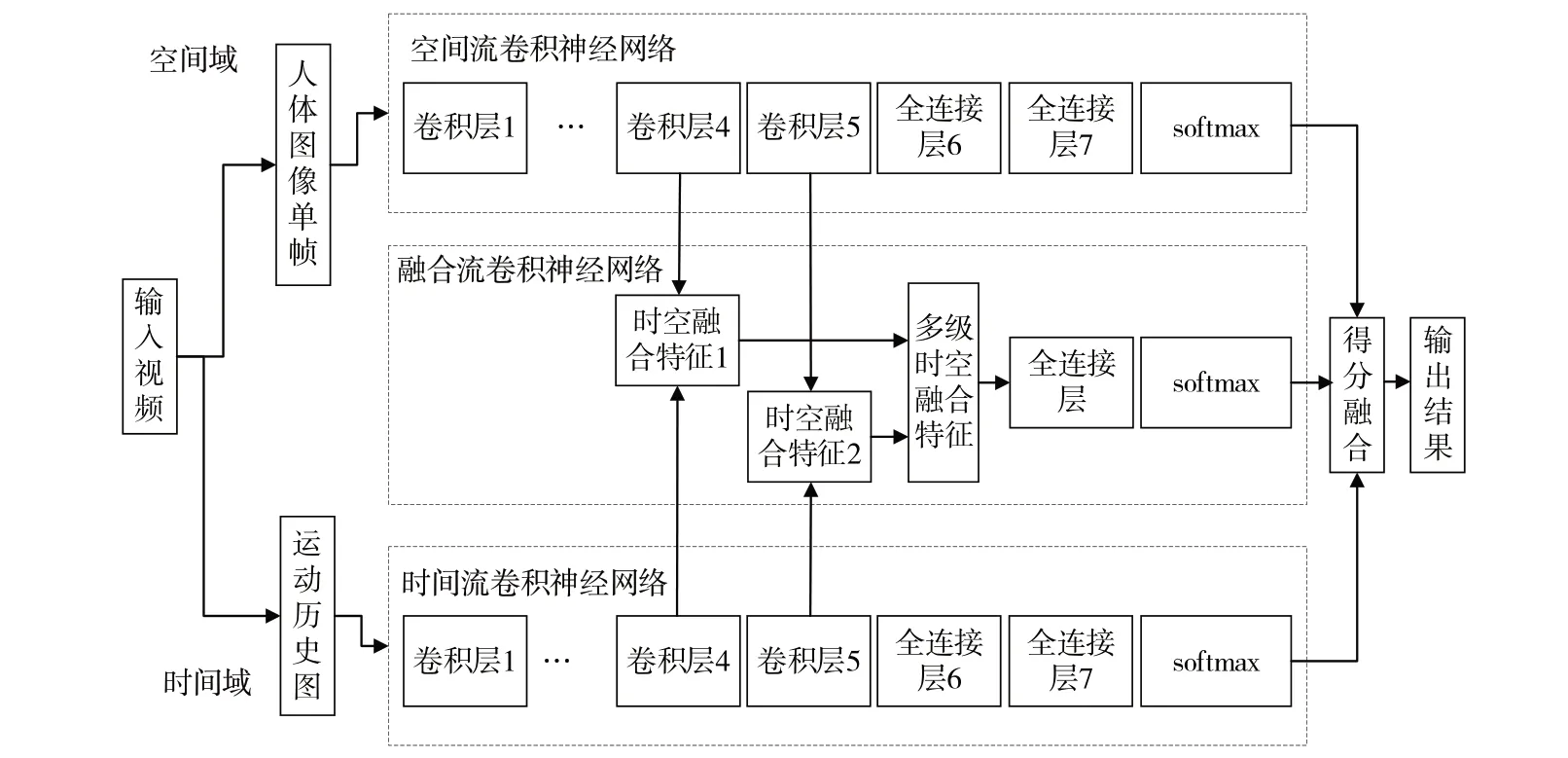
Fig.1 Architecture of fall detection network based on multi-stream convolutional neural network图1 基于多流卷积神经网络的跌倒检测网络架构
2.1 空间流卷积神经网络
空间流的主要目的是从图片中提取出有效的空间信息,其输入的是从视频序列中提取的人体轮廓单帧,大小为224×224,经卷积神经网络训练后提取出图像序列中人体在空间上的表征。空间流卷积神经网络结构(见图2)主要由5 个卷积层、3 个池化层、2 个全连接层以及2 次归一化处理组成,采用自适应矩估计优化算法对网络参数作优化处理,并利用交叉熵损失函数计算损失值。网络中第一个卷积层使用7 × 7 的卷积核,第二个卷积层使用5 × 5 的卷积核,其余卷积层均使用3 × 3 的卷积核,通过多个卷积核对上一层的输出进行卷积运算,并通过Zero Padding 控制输出维度的一致性。激活层选用ReLU 函数进行稀疏化处理,以提高训练速度。池化层窗口均为2 × 2,并且都采取最大池化法。全连接层整合卷积层和池化层中的信息,解决了非线性问题,并添加了失活层用来防止过拟合,最后通过Softmax 输出空间流网络训练结果。
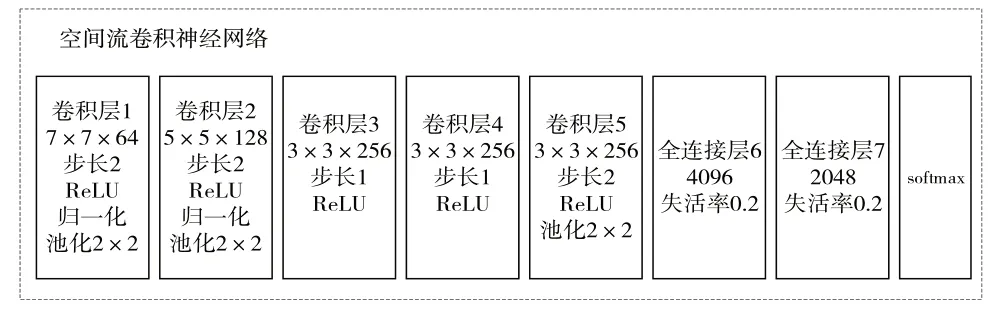
Fig.2 Spatial flow convolutional neural network structure图2 空间流卷积神经网络结构
因为卷积神经网络识别图像的理论依据是卷积可以识别边缘、纹理,然后通过不断的卷积提取抽象的特征,最终实现图像识别。但是图像中的阴影背景之类,由于其边缘模糊,没有明显轮廓,一定程度上会影响检测结果。因此,本文以背景差分法为基础,提出基于高斯混合模型的人体轮廓检测方法,具体流程如图3 所示。先对图像进行处理,输出人物轮廓图,并将其作为空间流的输入,可在一定程度上消除背景对检测的干扰[18],提高最终检测结果的准确性。高斯混合模型建模的主要步骤分为模型建立、参数更新、前景提取这3个步骤。
2.1.1 模型建立
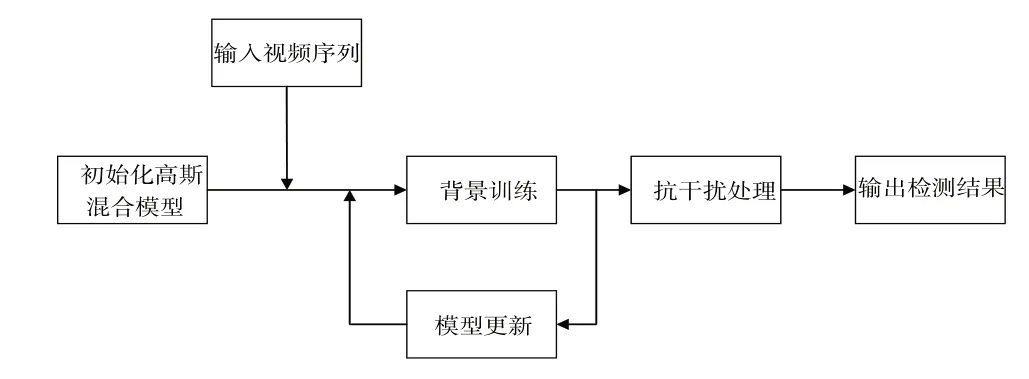
Fig.3 Overall block diagram of the human body contour extraction algorithm图3 人体轮廓提取算法总体框图
背景差分法主要将图像序列中的视频帧和背景模型进行差分处理,进而检测出前景图像。在整个运动目标检测中最重要的一步是背景图像建模,背景建模的精准度直接决定了检测准确度。同时,考虑到现实生活中背景图像是动态变化的,因此要对已经建成的背景模型进行适当的背景更新。
本文选用高斯混合模型(Gaussian Mixture Model,GMM)进行背景建模,高斯混合模型是用高斯分布精确地量化事物,将一个事物分解成若干个基于高斯分布形成的模型[19],在该模型中假设像素点之间相互独立,将视频序列中的每个像素点按多个高斯分布的叠加进行建模,每种高斯分布可以表示一种场景,多个高斯模型混合就可以模拟出多模态情形。因此,对每个像素点建立K 个高斯模型,概率密度函数可由K 个高斯模型的概率密度函数的加权和决定,具体如式(1)所示。
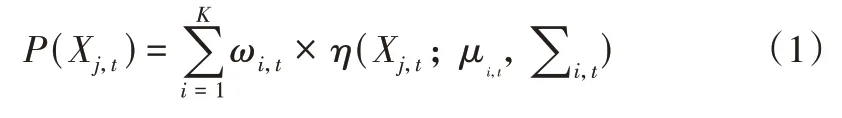
其中,Xj,t表示t时刻像素j的取值;K 表示高斯分布个数,一般设置为3~5;ωi,t表示t时刻第i个高斯分布的权重;μi,t为第i个高斯分布的均值;为协方差矩阵;η代表高斯分布概率密度函数。
2.1.2 参数更新
为了适应背景动态变化,更好地描述图像的像素分布,模型匹配之后需进行参数更新,以保证算法准确性。首先将当前图像序列中每个视频帧的像素值和所建立的K个高斯模型进行比较,如果视频序列中某帧的K个高斯模型满足式(2),则称像素Xj,t和第i个高斯模型匹配。
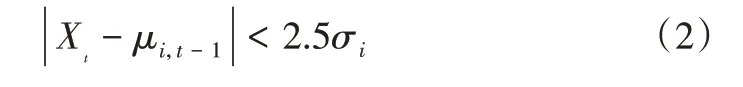
若不匹配,则新增一个高斯分布,并用其将权值系数最小的分布替代,其余分布的均值和方差保持不变,并按式(3)进行参数更新。
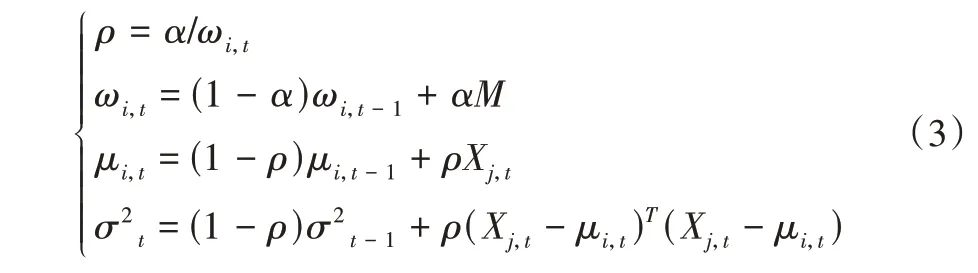
其中,α为学习速率,代表背景更新速度;ρ为参数学习速率;M为状态值,取决于匹配状态,匹配成功与失败分别对应1和0。
2.1.3 前景提取
训练完成后进行前景图像提取,针对图像序列中的每个视频帧,将其对应的K个高斯模型按照ω/σ的大小进行排序,并选中其中前B个模型对背景模型进行重构。
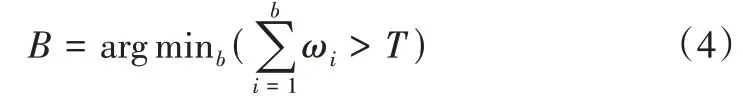
其中,T 为阈值,通常为0.5~1,本文设置为0.75,即判断前B个模型的权值之和是否大于阈值。
若这前B个高斯分布可以匹配上当前视频帧的任意高斯分布,则为背景,否则该帧为前景。图4 为不同场景下的人体轮廓检测图及其对应的前景图,可见能够实现对人体目标的准确检测。

Fig.4 Human contour detection map and foreground image图4 人体轮廓检测图及前景图像
2.2 时间流卷积神经网络
时间流和空间流类似,采用不同尺寸的卷积核对输入进行卷积操作,并经过池化、激活等操作处理,最后通过Softmax 函数得到时间流的训练结果。相比于空间流输入RGB 图片,时间流输入运动历史图(Motion History Image,MHI)以提取时间特征。MHI 是一种基于视觉的模板方法,通过计算时间段内同一位置像素值的变化,进而以图像亮度的形式表示时间段内目标的运动情况。与RGB 图片能够直接从视频中逐帧分隔得到不同,MHI 是从连续的RGB 图片或者视频中估算得到。图像中每个像素点的灰度值代表了在一组视频序列中该像素点的最近运动状况,运动发生的时间越近,则该点的灰度值越高。因此,MHI可以用来表征在一段时间内人体的运动情况,这使得其非常适合作为时间流网络的输入。
设H 为MHI每个像素的灰度值,则有:
其中,(x,y)表示像素点的位置,t表示时间,τ为持续时间,即运动时间的范围。δ是衰退参数,Ψ(x,y,t)为更新参数,由背景差分法定义:
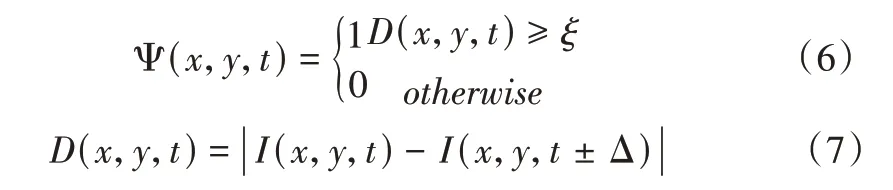
其中,I(x,y,t)为视频序列第t帧中坐标(x,y)的像素点的强度值,Δ 为帧间距离,ξ为差异阈值,一般通过实验获取,不同的视频场景对应不同的阈值。
时间流的输入是连续3 帧的运动历史图,大小为224×224×3。本文将持续时间τ设为15,差异阈值ξ设为32。具体运动历史图的实现效果如图5所示。

Fig.5 Motion history image extraction effect图5 运动历史图提取效果
2.3 融合流卷积神经网络
融合流网络主要对时间流和空间流的最后两层卷积层进行特征融合,选取最后两层是为了弥补单层融合造成的信息缺失。由于卷积神经网络对卷积层叠加的特性,网络浅层中富含局部信息但缺少全局信息,而网络深层中富含全局信息,缺少局部信息,因而单层融合无法充分利用特征信息,而层数过多又会导致过多的无用信息,增加计算量。因此,综合考虑后选取最后两层进行融合,既可使用全局信息又保留了局部信息,同时平衡了计算量和网络精度。
2.3.1 多模态融合算法
传统的特征融合一般使用特征拼接、按位乘、按位加等,其操作复杂度虽然弱于外积,但不足以建立模态间的复杂关系,然而外积的复杂度又过高,运用在跌倒检测中计算量过于庞大。鉴于此,本文采用多模态融合算法(Multimodal Compact Bilinear pooling,MCBP),该算法将外积的结果映射到低维空间中,并且不需要显式地计算外积。
双线性池化是对双线性融合后的特征进行池化处理,双线性的实现就是向量的外积计算。由于双线性的特征维度特别高,因而压缩双线性池化(Compact Bilinear Pooling,CBP)这一概念被提出,CBP 是对双线性池化的一种降维近似。而MCBP 又是对CBP 的改进,可以用来融合多模态的特征值,拓宽了CBP 输入的特征维度。该算法包括数据降维和融合两部分。
首先是数据降维,使用Count Sketch 映射函数对两个模态的特征向量进行降维处理,得到特征的Count Sketch。记输入的特征向量v∈Rm,初始化一个零向量y,同时从{1,...,n}中随机选取样本参数向量h,从{-1,1}中随机选取样本参数向量s。经由投影函数式(8)开始降维处理。
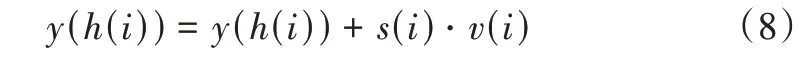
数据降维完成后,在融合阶段经由快速傅里叶变换(FFT)和快速傅里叶逆变换(IFFT)处理得到融合的特征。记k个输入特征为vj∈,降维处理后∈Rn。则可通过式(9)计算得到数据结果。
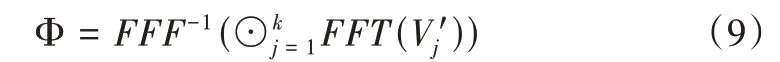
其中,FFT代表快速傅里叶变换,FFT-1代表快速傅里叶逆变换,⊙表示对应元素乘法。
MCBP 算法整体流程如算法1所示。
算法1:多模态融合算法

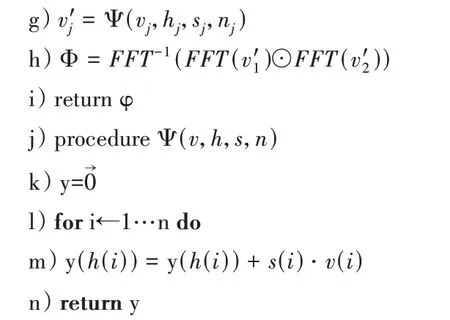
2.3.2 多模态融合模块
融合流网络主要对时间流和空间流的最后两层卷积层进行特征融合。本文基于MCBP 算法设计了多模态特征融合模块(Multimodal Feature Fusion Module,MFFM),用来对特征值进行融合调整。首先,要将对应层级的时空特征使用MFFM 进行融合得到对应的融合时空特征,待最后两层卷积层都融合完成后,将得到的两个融合时空特征再次经由MFFM 模块进行融合得到最后的多级融合时空特征。MFFM 模块具体结构如图6所示。
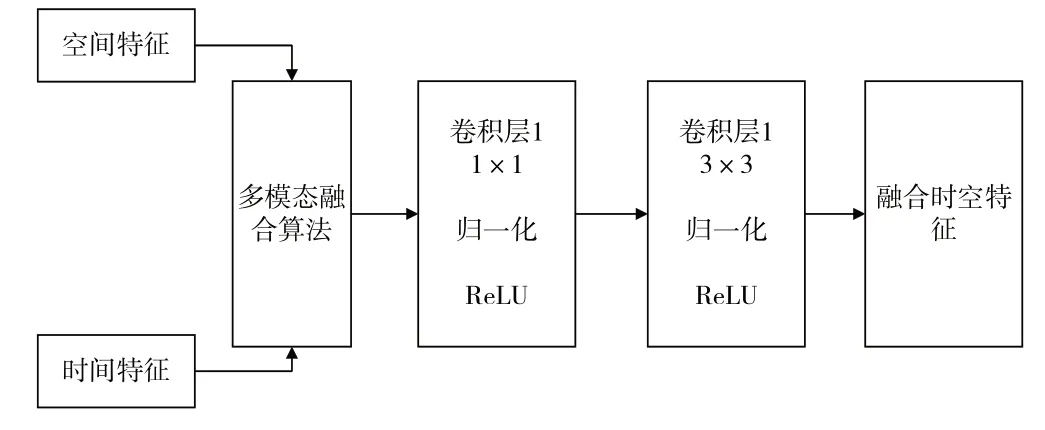
Fig.6 Multi-modal feature fusion module图6 多模态特征融合模块
MFFM 包括特征融合和特征调整两个阶段。特征融合阶段主要使用MCBP 算法对输入的多个特征进行降维融合。特征调整阶段主要通过特征调整网络对融合得到的时空特征进行噪声问题和感受野调整,特征调整网络经由2 个卷积层、2 个激活层和2 次数据归一化处理。通过特征调整可对融合特征作进一步优化,以降低数据维度并抑制噪声,提高预测精准度。
2.4 模型融合
多流卷积神经网络一共有3 个分支,通过相应处理分别提取空间特征、时间特征以及多级融合时空特征,最后将3 个分支的输出进行融合得到最终检测结果。设f是神经网络提取的特征向量,其中θ为Softmax 分类器参数,则将f分类为类别j的概率p(j|f)为:
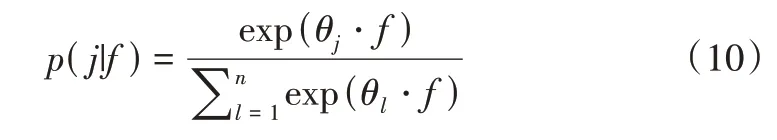
记Ps为空间流神经网络检测的分数结果,Pt为时间流神经网络检测的分数结果,Pf为融合流神经网络检测的分数结果。最后,整个多流网络检测为类别j的概率scorej为:
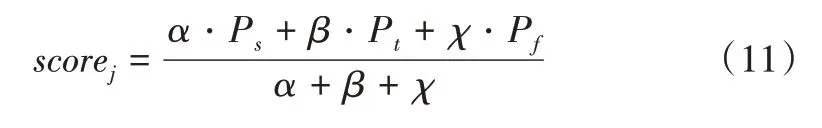
其中,α、β、χ分别是空间流、时间流和融合流对应的权重,本文设置α=1,β=2,χ=1。
3 实验与结果分析
3.1 实验数据集与实验环境
实验中使用Pytorch[20]深度学习环境,损失函数使用交叉熵损失函数,动量参数设置为0.9,初始学习率设置为0.001,批数据大小设置为48,训练轮数epoch 设置为100。
为验证实验检测准确性,实验在Le2i 和蒙特利尔两个公开的跌倒数据集进行检验,Le2i 跌倒检测数据集包含家庭、办公室、教室及咖啡厅4 种场景,且存在假摔视频及无人视频。数据集使用单摄像头拍摄,刷新率为25Hz,分辨率为320×240。蒙特利尔数据集是由蒙特利尔大学公开的摔倒数据集,该数据集包含24 个场景,利用8 个IP 视频摄像机拍摄,视频刷新率为120Hz,分辨率为720×480。
实验首先对视频数据进行预处理,使用OpenCV 库将数据集的视频数据按照帧数截取成相应的RGB 图片,然后采用COLOR_BGR2GRAY 对图像作灰度化处理,并将图像尺寸转换为224×224 后输出得到实验所需的图像序列,再对图像序列进行相应处理,提取出的人物框架和运动历史图将分别作为空间流和时间流的输入,并利用融合流对特征提取网络中的时空特征融合,最终融合得到输出结果,按照相应的实验指标验证实验的有效性。
3.2 实验评价指标
为了客观评价本文模型在人体跌倒检测中的检测效果,规定TP 表示真阳性,即跌倒行为成功检测为跌倒事件;FP 表示伪阳性,即非跌倒行为检测为跌倒;FN 为伪阴性,即跌倒行为检测为非跌倒。采用在ICDAR 大赛中规定的准确率P、召回率R 及综合F 值3 个指标对模型性能进行评估。
准确率P 表示在所有检测样本中成功检测为跌倒事件所占的检测为跌倒事件的比例,可表示为:

召回率R 表示所有跌倒样本中检测为跌倒的部分在所有跌倒样本中所占比例,即模型对跌倒行为的检测能力,可表示为:

F 是准确率和召回率的调和平均数,用来综合评价模型检测能力,可表示为:
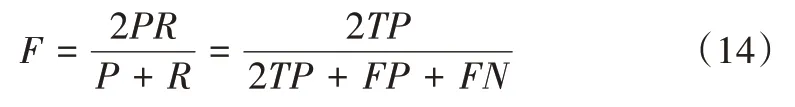
3.3 实验结果及分析
为了验证本文新增的融合流网络输入层数对跌倒检测精确度的影响,在实验数据集上设置了4 组对照实验,分别是使用传统双流卷积网络和三组分别添加了从对双流网络最后一层到最后三层的卷积层融合的多流卷积网络的精确度比较,结果如表1所示。

Table 1 Comparison of accuracy of multi-level spatiotemporal feature detection表1 多级时空特征检测精确度比较
由表1 可知,当增加对双流网络最后一个卷积层的融合流后,整体网络检测精确度为93.2%,较传统卷积网络上涨1.4%,验证了时空融合特征的有效性。而融合最后两层卷积层时,整体精确度又上涨0.3%,但当选用最后三层卷积层时整体精确度却只增加了0.1%。由此可见,随着融合层度的增加,多流网络的检测精确度确实有所增加,但同时不断增加的融合层一定程度上增加了计算量,并且随着层数的不断增加,检测精确度的涨幅越来越小。因此,为了平衡计算量和检测精度,本文选取对时间流和空间流的最后两层进行时空特征融合处理。
此外,还在两个数据集上分别进行实验与比较,为了验证本文多流卷积网络检测跌倒事件的有效性,将其与其他跌倒检测方法在检测效果上进行比较。为了确保验证的有效性,训练和测试的所有条件保持一致,输入尺寸均为224×224,具体性能指标比较如表2、表3所示。

Table 2 Comparison of the detection effectiveness of each model on the Le2i dataset表2 Le2i数据集上各模型检测准确性比较
由表2 各模型的检测结果比较可知,在Le2i 数据集上本文提出的基于多流卷积神经网络的检测模型与现有网络模型相比,准确率方面有较大提升,为所有测试模型中精确度最高,并且其在各种指标上的性能均优于其他算法,可见添加融合流之后检测依据的特征信息更充分,模型性能有所提高,进一步说明本文结合了融合流的多流神经网络的有效性。
由表3 可知,在蒙特利尔数据集上的实验结果与在Le2i 数据集上的结果相同,本文提出的多流卷积的跌倒检测算法依旧拥有着最高的准确率,相比双流网络精确度增加1.8%,较VGG16、GBDT 和SVM 增加3.9%、3.6%和5.8%。并且,本文方法在两个数据集上的检测精确度差距不大,由此也证明了本文多流卷积神经网络在跌倒检测方面的普适性。
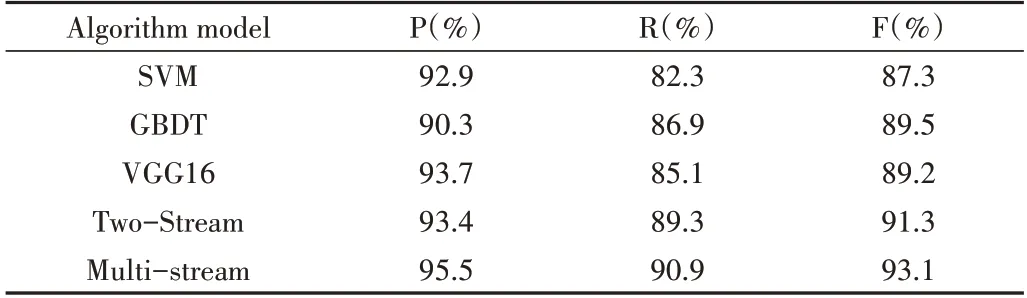
Table 3 Comparison of the detection accuracy of each model on the Montreal dataset表3 蒙特利尔数据集上各模型检测准确性比较
同时,由于跌倒检测在时效性上有着较高要求,因此本文比较不同模型处理单个视频帧图片所耗时间,如图7所示。其中,横坐标表示不同的比较算法,纵坐标表示处理时间,单位为ms。由图7 可知,本文多流卷积神经算法虽然处理时间比SVM 和GBDT 算法长,但是考虑到精确度提升,本文提出的基于多流卷积神经网络的检测算法可以满足跌倒检测要求。
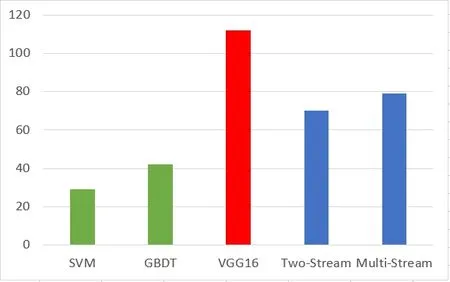
Fig.7 Comparison of the detection speed of each model图7 各模型检测速度比较
最后,针对数据集中的假摔及无人场景进行针对性实验。针对无人场景,由于画面中并无人物出现,因而会导致人物轮廓图及运动历史图均为纯黑色图片,对其进行单独测试后发现,针对无人场景,并不会出现误判情况。对于假摔场景,本文从两个数据集中选取共计50 组包含假摔的场景进行针对性实验,最终在50 次实验中,有2 次发生误判,也证明了本文算法检测的有效性。
4 结语
传统的双流卷积神经网络虽然结合了时空特征信息、多特征提取以及融合判断,但是其融合发生在全连接层和分类函数之后,忽略了时间信息和空间信息间的交互。为了解决传统双流卷积网络时空特征交互信息交互不足的问题,提高人体跌倒行为检测准确率,提出一种添加了融合流的多流卷积神经网络模型。多流网络利用空间流网络提取帧内外观信息,利用时间流网络捕捉帧间运动信息,并利用新增的融合流模块加强网络对细节信息的捕捉,很好地结合时空信息,更充分地利用特征提取网络中的全局信息和局部信息。最终实验表明,相较于传统检测方法,本文提出的多流卷积神经网络在处理跌倒检测问题时较传统方法提取特征能力更强,检测更全面、更精确,证实了模型的有效性。同时,该方法也有待改进之处,后续研究中可通过增加注意力机制等方法进一步提升网络精确度。
