基于知识图谱与协同过滤的个性化试题推荐
2023-02-18郭佩瑶曹伊梦
徐 硕,尹 隽,郭佩瑶,曹伊梦,周 杨,方 霖,钱 萍
(1.江苏科技大学 经济管理学院;2江苏科技大学 计算机学院,江苏 镇江 212100)
0 引言
随着社会信息化深入发展,教育模式、教育理念等受其影响发生了明显转变,促进了互联网教育行业迅速发展。于此同时,开发各类学习软件有力补充了传统教育模式的不足,为学习者带来了极大便利。尤其在2019 年末新冠肺炎疫情发生后,在线学习得到广泛普及。截至2022年6 月,我国在线教育用户规模已达到3.77 亿人[1]。试题作为一种重要的学习资源,伴随着学习者的整个学习过程,随着网络学习资源日益增多,学生难以查询合适的试题。为此,应充分发挥互联网技术优势,向不同学习者推荐符合他们自身学习情况的个性化试题。
协同过滤是近年来应用最广泛的推荐算法之一,在亚马逊和Netflix 等知名网站上均有所应用[2]。基于协同过滤的推荐主要包括基于用户的协同过滤(User-based Collaborative Filtering,User-CF)、基于物品的协同过滤(Itembased Collaborative Filtering,Item-CF)[3]。以上方法基于用户和物品的交互数据,探索其中表现出行为共性的用户或物品,通过在用户行为上“相似”的用户或物品进行推荐。然而,此类方法仅利用用户行为信息进行推荐,通常会忽略某些重要信息,从而影响推荐精度。
部分研究者引入知识图谱提高传统协同过滤的精度。周倩等[4]首先构建图书知识图谱,然后使用其中的信息进行图书近邻推荐,并与基于图书评分的协同过滤推荐进行结果融合,提高推荐精度。李浩[5]等利用循环知识图谱存储用户与物品信息,同时寻找最佳推荐路径结果融合传统协同过滤所得的结果,使推荐结果更准确。顾亦然等[6]利用电影关联构造电影知识图谱,首先使用RippleNet 模型进行推荐,然后使用传统协同过滤进行推荐,实践表明两种结果融合后既提升了推荐精度,又获得了较好的解释性。然而,上述研究仅将几种推荐结果进行简单叠加,并未充分发挥知识图谱改善协同过滤数据来源单一的优势,仍具有提升空间。
为弥补传统协同过滤的不足,充分发挥知识图谱改善数据单一的优势,本文提出一种基于知识图谱与协同过滤的个性化试题推荐算法(KGeP-CF)。首先,引入知识图谱存储试题对应的知识点信息,利用TransE 模型、余弦相似度提取知识点间的相关性联系。然后,将提取的知识点相关性应用于试题相似度计算中,并非将两种推荐结果简单叠加,以充分保留知识图谱信息的完整性。最后,算法还考虑了用户学习情况,为用户推荐符合其学习情况的个性化试题,从而提升算法推荐精度,还避免了“千人一面”的推荐结果。
1 相关工作
推荐系统概念于1997年被正式提出,目的是帮助用户寻找与自身需求真正相关的内容。随着教育领域内互联网服务增长,教育资源数量大幅增加,信息过载问题愈发凸显。
为此,通常引入个性化学习推荐系统。该系统是教育领域的重要研究方向,具有强大而不可替代的推动作用,被广泛应用于各种智能教育系统中[7]。其中,协同过滤是目前最常用的推荐算法之一[8],它通过分析用户以往行为数据,得出众多数据背后的有用信息,但通常会面临依赖评分数据、数据稀疏等问题。一些学者对此开展了研究,柏茂林[9]改进了传统基于用户的协同过滤算法,形成最近邻居用户集合,对用户进行习题推荐。包志强等[10]提出一种改进协同过滤算法,通过关联规则预测无评分的项目,以缓解初始数据的稀疏问题,并与基于物品的协同过滤算法相结合进行推荐。孔祥仁[11]将聚类算法与推荐算法相结合,形成混合推荐算法,并将该算法应用于驾校练习试题推荐中。
然而,随着现代信息量急剧增长,传统协同过滤算法存在计算量大、计算特征单一的问题,通常只能依据用户自身偏好推荐内容。结合教育领域特点类比个性化推荐方法,该算法虽然通过用户间评分的相似度来预测学习者答题偏好并进行推荐,但忽略了课程试题相关的知识点信息及各知识点间丰富的语义关系,这些语义关系可系统、合理地呈现课程知识的前后关联,进而为用户推荐更精确的个性化试题,也使推荐结果具有更好的可解释性。
知识图谱是由节点和边组成的图网络结构,蕴含着实体间的关系信息,将知识图谱引入协同过滤算法可解决推荐结果缺乏可解释性的问题。康雁等[12]在协同过滤算法中融合知识图谱表示学习算法,能较好解决协同过滤推荐算法可解释性不强、推荐结果不理想的问题。
目前,知识图谱与推荐系统相结合的方法主要包括基于路径和表示学习的知识图谱协同过滤方法。前者的缺点是需手动设计路径,而后者能自动获取知识图谱中实体的语义嵌入[13]。知识图谱表示学习包括基于距离的模型和基于语义的匹配模型,目前采用最多的是基于距离模型中的Translating 系列算法,例如TransE 算法[14]、TransH 算法[15]、TransR 算法[16]、TransD 算法[17]等。吴玺煜等[18]利用TransE 模型获取知识图谱的语义信息,再将其融入协同过滤算法中进行推荐,解决了协同过滤算法未考虑语义信息的问题,提高了推荐精度。
基于上述研究,本文构建课程知识图谱存储知识点信息,并将课程知识图谱信息引入协同过滤算法解决传统协同过滤未考虑语义信息的问题,使推荐结果更具合理性和可解释性。同时,在推荐算法中还考虑了用户自身学习情况,以增强推荐结果与用户的匹配,使用户获得的推荐结果更精确。
2 KGeP-CF推荐算法
2.1 算法框架
本文所提推荐算法的具体框架如图1 所示。首先,通过知识抽取等方法构建课程知识图谱。然后,将知识图谱中的实体向量化,利用余弦相似度计算知识点相似度。接下来,使用矩阵化的用户做题数据计算试题相似度。再然后,结合两种相似度获得综合试题相似度。最后,考虑用 户学习情况计算试题可推荐性大小,实现试题推荐。
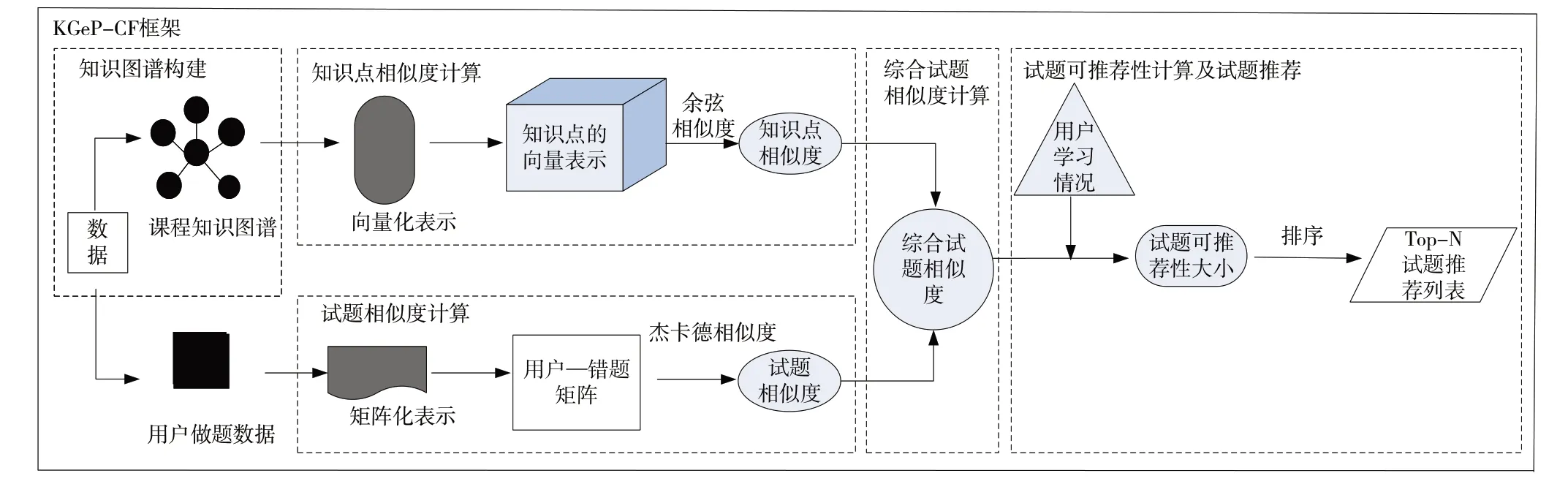
Fig.1 Recommendation algorithm framework图1 推荐算法框架
2.2 知识图谱构建
课程知识图谱属于领域知识图谱,本文采取手工构建方法进行本体设计(见图2),通过知识抽取得到知识点数据,利用知识融合消除数据歧义,最后将得到的数据存储至Neo4j 图数据库。在课程本体设计阶段,课程被分为章节与知识点,根据课程知识点存在的关系归纳定义了兄弟关系、同一关系、包含关系、前后继关系、相关关系和继承关系。
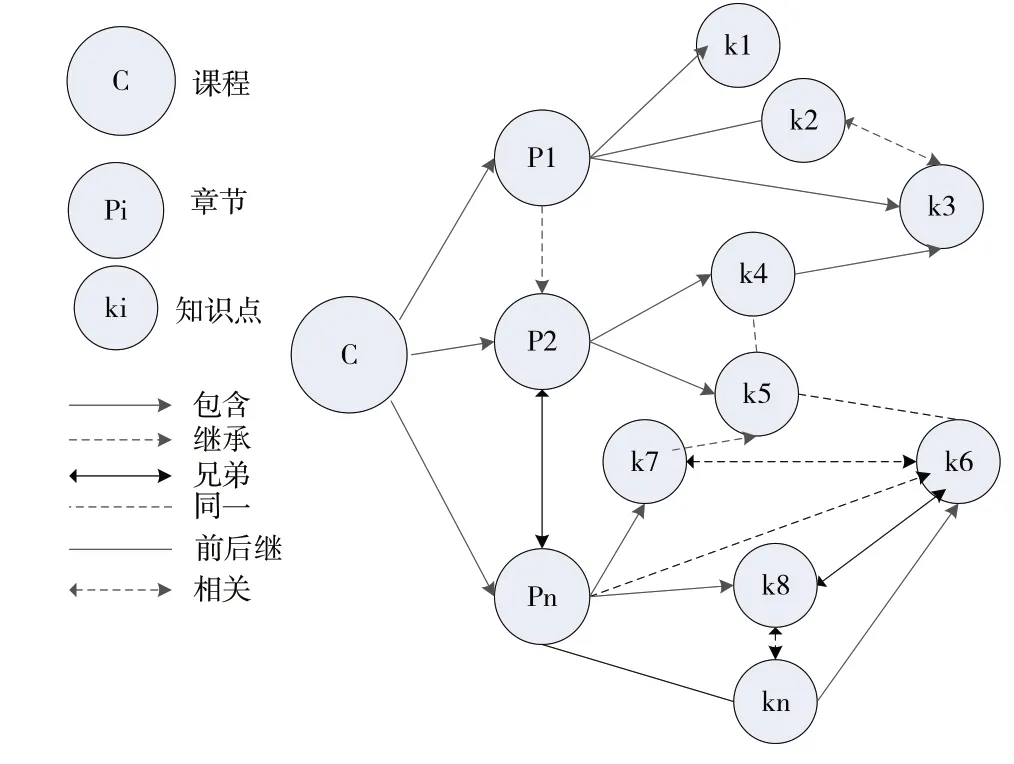
Fig.2 Design drawing of course ontology图2 课程本体设计图
由图2 可见,知识抽取主要包括实体抽取与关系抽取两部分。为保证所抽取的实体与关系质量,本文采取手工抽取方式首先抽取实体,梳理各章节知识点,抽取其中的知识点实体,然后按照各章节内部、每个章节间的顺序结合所学知识,抽取知识点关系。由于抽取的知识点实体来源于两本不同数据库教材,同一知识点实体可能存在差异,因此需要进行知识融合。本文采用实体对齐方法统一知识点实体,以消除数据歧义问题。
2.3 知识点相似度计算
本文使用经典的TransE 模型表示学习图谱中的知识点实体,得到代表知识点实体的低维向量。TransE 算法的原理为当一个三元组(h,r,t)为真时,则应满足h+r≈t,空间中的形式如图3所示。

Fig.3 Spatial form of the TransE principle图3 TransE原理的空间形式
TransE 算法通过构造初始实体和关系向量,不断带入三元组集合进行更新,最终得到训练好的实体和关系向量。在得到知识点实体向量后,便能计算知识点相似度。在方法选取上,采用了对向量友好的余弦相似度进行计算。
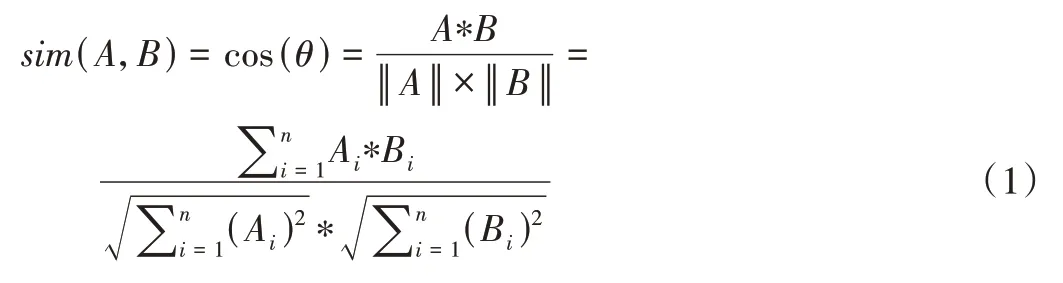
其中,A、B为知识点实体,Ai、Bi为知识点A、B的低维向量表示在维度为i时的分量。
2.4 试题相似度计算
在计算试题相似度前,先处理用户做题数据得到用户—错题矩阵M。矩阵M中行代表用户,列代表试题。当用户i做对试题j时,mij=0;当用户i做错试题j时,mij=1。通过该方式可通过矩阵形式存储用户做题情况。
由于用户做题情况仅为对、错这种二元变量,使用杰卡德相似度往往能取得较好的相似度计算结果。

其中,N(a) ∩N(b)为既做错题目a又做错题目b的用户数目,N(a) ∪N(b)为做错题目a或做错题目b的用户数目。
2.5 综合试题相似度计算
为得到更高的推荐精度和可解释度,需对两种相似度加权取均值,得到综合试题相似度。本文采用加权几何平均数计算两种相似度的综合相似度。只有当二者均较大时,其几何均值才较大,以得到更综合的相似度结果。

其中,1、m分别为Jab、sim(A,B)的权值。
2.6 试题可推荐性计算
传统协同过滤并未考虑推荐对象的自身情况,会使推荐结果与用户匹配度不够。因此,在推荐试题时本文结合了用户对此类试题的掌握情况,从而增强推荐结果与用户的匹配性。但用户对某类试题的掌握程度,通常取决于用户对试题考查知识点的掌握情况。为此,本文定义识点掌握程度来度量用户对某知识点的掌握情况。
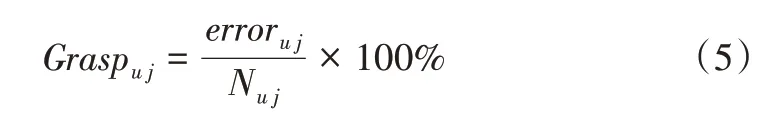
其中,Graspu j表示用户u对知识点j的掌握情况,值越大表示掌握程度越差,errori j为用户u在知识点j上的错题总个数,Ni j为用户u所做知识点j的试题总数。
结合综合试题相似度与用户学习情况,便能计算试题可推荐性大小。以用户u为例,其待推试题i的可推荐性大小的计算公式为:
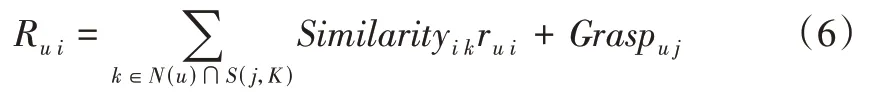
其中,Similarityi k为试题i与错题k的综合相似度,Graspu j为用户u对试题i对应知识点j的掌握情况,N(u)为用户u的错题集合,S(i,K)为试题i最相似的Top-k 试题的错题集合,ru i=1。
最后,根据用户待推试题可推荐性大小的排序结果,取排名前k的试题形成Top-k 试题推荐列表,并将列表试题推送至用户,完成试题推荐。
3 实验结果与分析
3.1 实验数据集
目前,国内尚未公开统一的答题数据集,本文实验数据来自江苏科技大学信管系实际教学中学生的做题情况,主要包含学生答题得分数据和试题数据。实验数据集共分为两组,数据集1 包含53 名学生在每道题上的答题得分数据,共涉及119 道试题。通过试题数据将试题与知识点相互对应,以此得到每道试题的对应知识点,在此基础上处理实验数据得到包含6 307 条答题记录的数据集。用于构建课程知识图谱的数据来源于《数据库系统概论(第5版)》[19]《数据库系统概念》[20]。经过知识抽取等步骤,最终得到包含1 349 个节点和2 054 个关系的数据库课程知识点及关系数据集。数据集2 包含65 名学生在HTML、CSS 两个章节习题上的答题得分数据,共涉及102 道试题。将数据进行上述处理后,最终得到包含149 个节点和316个关系的Web 课程部分章节知识点、关系数据集以及包含6 618条答题记录的全部数据集。
通过Python 调用Py2neo 库,将数据库知识点与关系、Web 前端知识点与关系批量存储至Neo4j,构建课程知识图谱,部分知识图谱如图4所示。
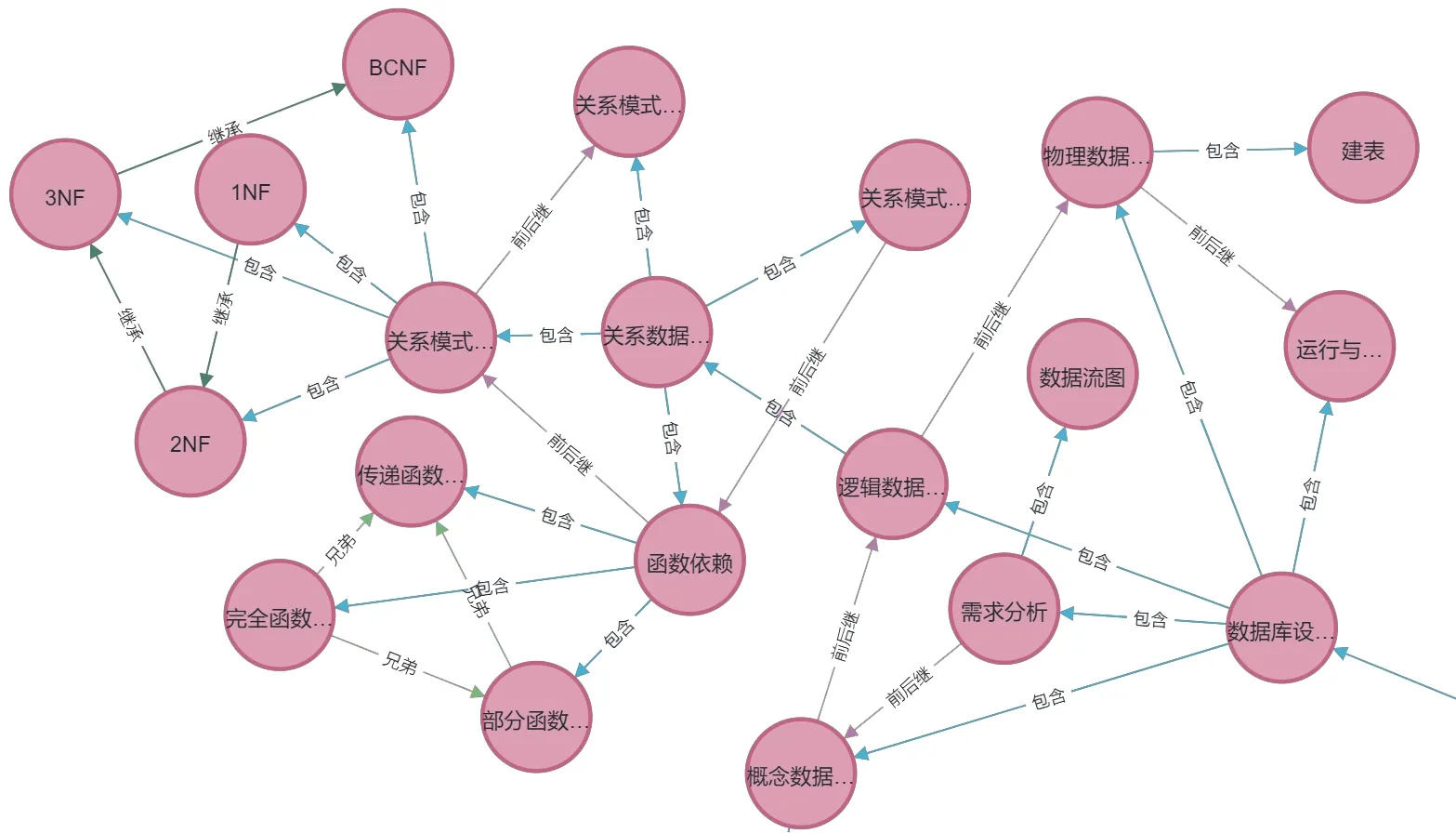
Fig.4 Partial knowledge graph图4 部分知识图谱
3.2 评价指标
本文选取命中率(Hit Ratio,HR)、归一化折损累计增益(Normalized Discounted Cumulative Gain,NDCG)和覆盖率(Coverage)这3 个常用的评价指标来评价推荐算法性能。其中,HR 反映推荐算法的准确性;NDCG 反映推荐算法对结果的排序性能;Coverage 反映推荐结果的全面性,值越大代表推荐结果越全面。

其中,N、K分别表示推荐用户总数和推荐列表长度,N(S(u) ∩R(u)@K)表示既属于用户u的错题集合S(u),又属于用户u的试题推荐集合R(u)@K的试题数目。

其中,u表示用户序号,i表示试题在推荐列表位置,当所推的第i个试题为u号用户的错题时relu i=1,反之relu i=0。
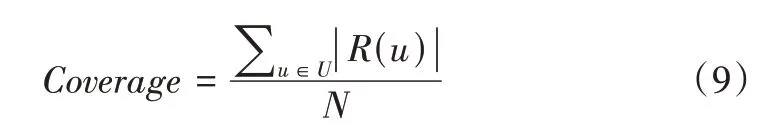
3.3 比较实验
本文选择Item-CF、User-CF、KGeP-CF-NUC、LFM、Hete-CF[21]共5种推荐算法与KGeP-CF算法进行比较。其中,KGeP-CF-NUC 为不考虑用户学习情况的KGeP-CF模型;LFM 模型为经典的隐语义模型,通过先挖掘用户隐藏“兴趣”,再根据用户“兴趣”匹配相应类别物品完成推荐;Hete-CF 算法通过用户—用户、项目—项目、用户—项目等关系构造元路径进行推荐。
3.4 实验结果
考虑到本文算法仅面向学生的试题进行推荐,在实验中选取N=10 进行Top-N 推荐,采取8∶2 的比例划分训练集与测试集。
3.4.1 权值参数设置
权重参数m在综合试题相似度的计算中起到重要作用。为了确定式(4)中知识点相似度权重m的最佳取值,以获得最好的试题推荐效果。本文进行7 组实验,m依次取0.125、0.25、0.5、1、2、4、8,重复5 次实验取各项评价指标平均值,实验结果如图5-图7所示。
由图5、图6 可见,随着m增大HR@10、NDCG@10 先增大后减小,并且在m=1 处取得最优值。由图7 可见,当m处于[½,2]时,Coverage 均能取得较优值。因此,为了获得最佳的推荐效果,本文选取m=1进行实验。
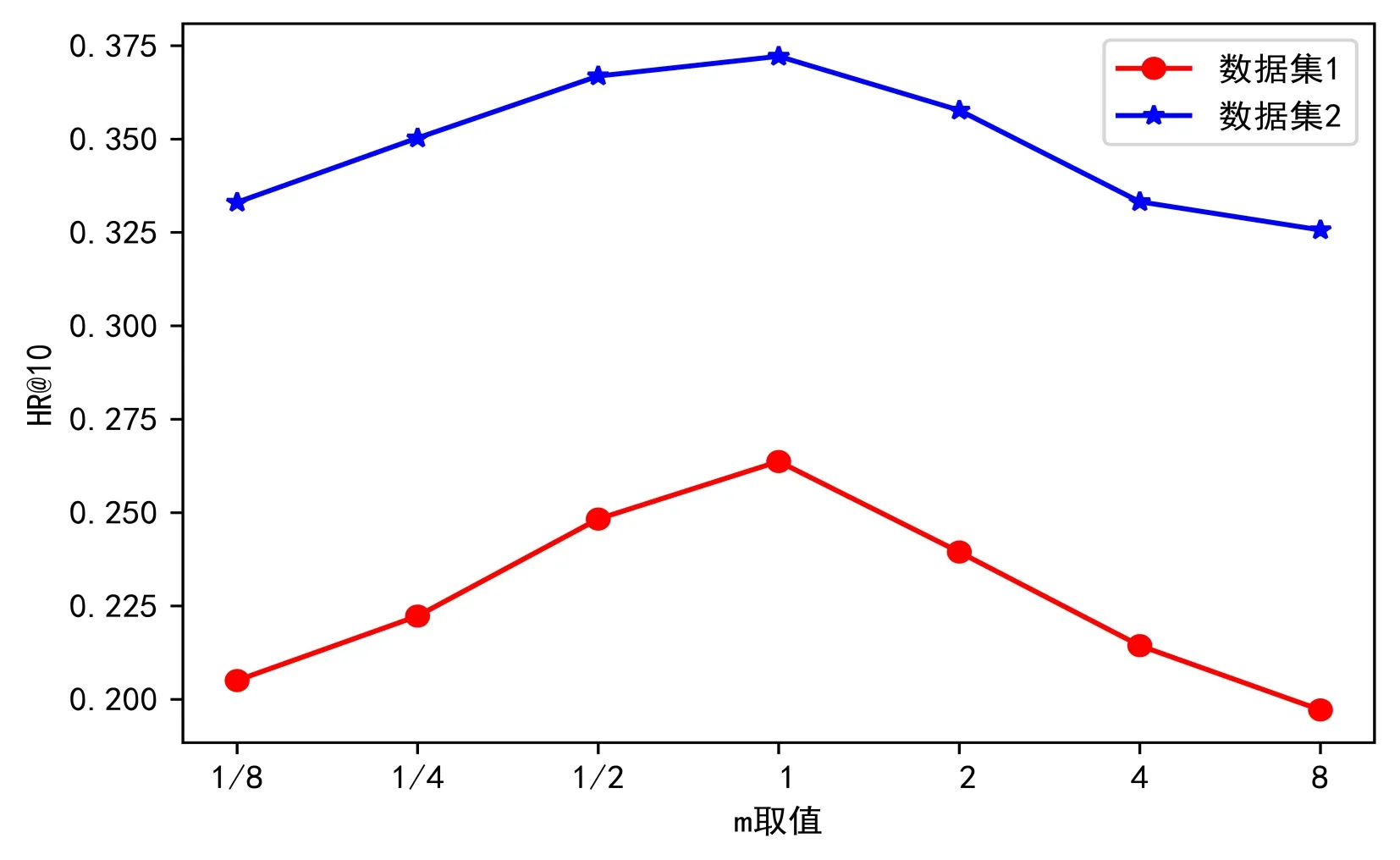
Fig.5 Curve of HR@10 changing with the value of m图5 HR@10随m取值变化曲线
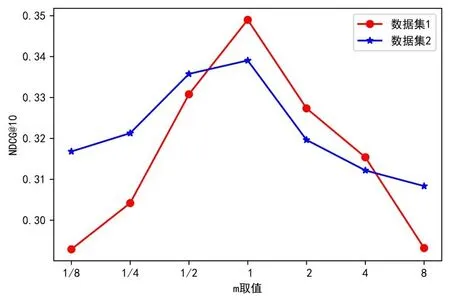
Fig.6 Curve of NDCG@10 changing with the value of m图6 NDCG@10随m取值变化曲线
3.4.2 算法比较
本文选取了User-CF、Item-CF、LFM、Hete-CF 和KGeP-CF-NUC 共5 种算法进行比较。其中,LFM 模型隐含类别数量F=10,学习率α=0.02,正则化率ratio=1。不同算法在两个数据集上的指标比较情况如图8 所示,具体指标数值如表1所示。

Fig.7 Curve of Coverage changing with the value of m图7 Coverage随m取值变化曲线
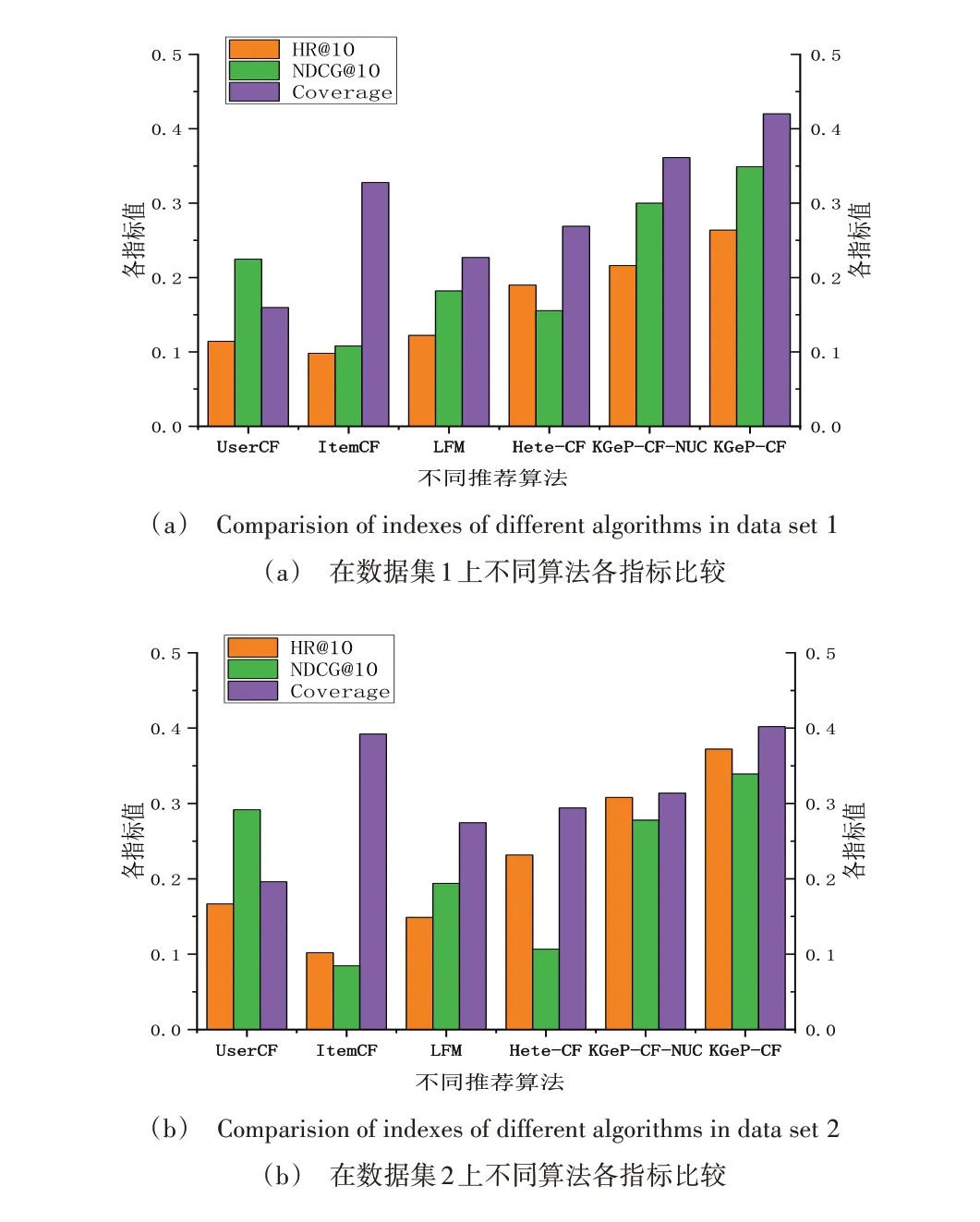
Fig.8 Index comparison of different algorithms in two data sets图8 不同算法在两个数据集上的指标对比
由 图8、表1 可 知,Item-CF、User-CF 在HR@10、NDCG@10 指标上表现不佳,可能原因是协同过滤算法只基于用户做题数据进行推荐。Item-CF 在Coverage 指标上表现较好,这与其通过不断寻找“相似物品”进行推荐的特点相关,能使推荐结果覆盖面更广。由于KGeP-CF-NUC、KGeP-CF 算法的试题相似度计算部分基于Item-CF 算法,因此两者保留了Item-CF 算法推荐结果更全面的特点,但比较可知通过表示学习利用知识点等信息能显著增强推荐精度和排序性能。将KGeP-CF 与不考虑用户学习情况的KGeP-CF-NUC 比较发现,考虑用户学习情况后算法性能在精度、排序性能、结果覆盖性方面提升了15%~30%。实验证明,KGeP-CF 算法通过知识图谱引入知识点信息,并结合用户学习情况推荐的方法能有效提升试题推荐性能。
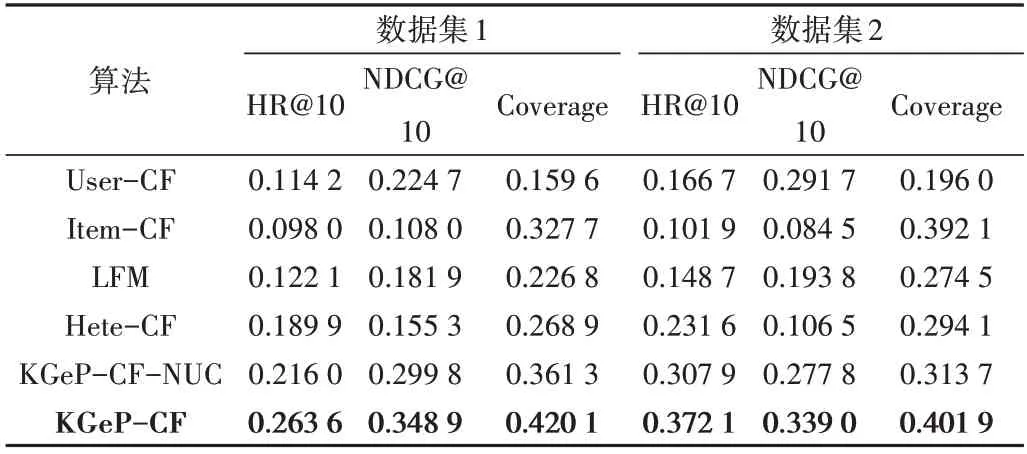
Table 1 Index values of different algorithms on the two data sets表1 不同算法在两个数据集上的各指标数值
4 结语
传统协同过滤算法通常仅考虑用户做题数据,忽略了某些十分重要的信息。为此,本文提出一种基于知识图谱与协同过滤的个性化试题推荐算法。通过引入知识点间的关系对传统协同过滤中用户行为信息进行补充,还考虑了用户学习情况,使用户获得更准确的个性化试题推荐。实验表明,该算法相较于传统算法能有效提升试题推荐性能。
此外,这种通过知识图谱引入第三方信息并加入用户自身学习情况的个性化推荐算法,不仅可应用于试题推荐领域,对于其他应用场景也具有一定的参考价值。
