基于自动机器学习的采油井压裂效果预测方法
2023-02-17盖建
盖 建
(1.国家能源陆相砂岩老油田持续开采研发中心,黑龙江大庆163712;2.中国石油大庆油田有限责任公司勘探开发研究院,黑龙江大庆163712)
水力压裂是大庆油田开发过程中一种非常重要的增产方式[1-4]。水力压裂有着较为高额的成本,压裂后的产油效果直接决定了其经济效益。因此,亟需通过较为精确的预测模型对压裂后的产油效果进行提前预判,以达到压裂方案优化设计的目的。目前,对大庆油田压裂后产油效果的预测大部分是凭借经验或者多元线性回归等简单模型,导致了预测结果的不确定性强和准确度低。
机器学习是建立高精度预测模型的一种有效方法,正逐渐被应用到油气田勘探开发的各个领域[5-14]。诸多研究人员用机器学习来评估完井和增产措施的效果[15-18]。目前,机器学习在压裂中的应用多是针对致密油[7]与页岩气[19-21]等非常规储层;文献[22]利用机器学习对大庆油田油井压裂效果进行预测并取得了较高的精度,但存在一些问题:第一,在影响因素分析时,考虑因素不够全面,没有将可能影响压裂效果的压裂液、压裂类型等工程因素,以及沉积相、目的层深度等地质因素考虑在内。第二,在影响因素相关性分析与模型特征选择中,虽然采用了神经网络等方式,但仍局限于每个影响因素与目标变量之间的单因素分析,没有考虑影响因素之间的关联,导致特征选择不够客观。第三,研究中采用的基础数据集中样本数量少,可能造成预测模型的普适性与推广性不足。
机器学习算法的种类较多,每种算法适宜解决的问题不同。目前在使用机器学习算法解决问题时,会遇到以下2 个问题:第一,没有一种机器学习算法能在所有数据集上都有最好的表现。第二,大部分机器学习算法性能的优劣在很大程度上依赖于超参数优化。以上2个问题会造成即使花费大量时间和精力去进行机器学习建模,仍然无法达到更高的精度。自动机器学习满足了不同数据集对不同机器学习流程的需求,能够较好地解决上述2 个问题。目前流行的自动机器学习系统包括Auto-WEKA,Hyperopt-sklean,Auto-sklearn,TPOT 和Auto-Keras 等,它们能在不同的预处理器、分类器、超参数设置等流程之间执行组合优化,从而大大减少用户的工作量,并且降低机器学习使用者的门槛。应用自动机器学习建立了大庆油田N23区块的采油井压裂效果预测模型,并且利用研究成果指导了N23区块采油井压裂参数的优化设计。
1 数据准备
压裂措施数据来自大庆油田N23 区块,该区块主要发育萨尔图、葡萄花和高台子3个油层。萨Ⅱ、萨Ⅲ和葡Ⅰ是区块的主力开发油层组,为河流-三角洲沉积。密闭取心资料显示,油层中的孔隙大部分互相连通,平均孔隙度为26.6%,平均渗透率为1 184.8 mD,以细砂岩为主,含量为47.3%,粒度中值为0.13 mm,分选系数为3.4。该区块采用5 点法面积井网布井,开发井均为直井,通过向地层注水补充能量。
收集整理了该区块采油井压裂措施数据共887井次。数据集包含采油井的地质特征、措施前生产数据、压裂工程参数和措施效果。地质特征包括采油井坐标、措施目的层厚度、平均深度、渗透率、孔隙度、破裂压力和沉积相类型;措施前生产数据包括日产油量、含水率、日产液量以及沉没度;压裂工程参数包括压裂方式、压裂液体积、加砂量、压裂液类型、混砂比和裂缝条数。措施效果采用采油井压裂后稳定的日产油量,将该指标作为目标值开展研究。
2 研究方法
2.1 自动机器学习
自动机器学习工作流程(图1)包括3 个主要部分,分别是元学习(meta learning)、贝叶斯优化(Bayesian optimization)和模型集成(build ensemble)。

图1 自动机器学习工作流程示意Fig.1 Automatic machine learning process
2.1.1 元学习
为了提高效率,自动机器学习采用元学习[23]来预热贝叶斯优化流程。元学习可以实现从以前的任务中获得知识,应用该技术选择可能在目标数据集上表现良好的机器学习框架实例。从已有数据集库中选择与新数据集相似的数据集,将相似数据集的机器学习框架作为初始参数传递给贝叶斯优化流程,具体实现方法如下:收集OpenML 存储库[24]的开源数据集,对于每一个数据集,评估一组包括常规、信息论相关和统计相关的元特征[25]。然后,在2/3的数据上采用k折交叉验证进行贝叶斯优化,将剩余的1/3 数据作为测试集,将能使测试集获得最佳性能的机器学习框架作为最优实例储存。同时,计算本研究目标数据集Dfrac的元特征,在元特征空间中分别计算所有数据集与Dfrac的L1 范数并排序。Dfrac的L1范数表达式为:
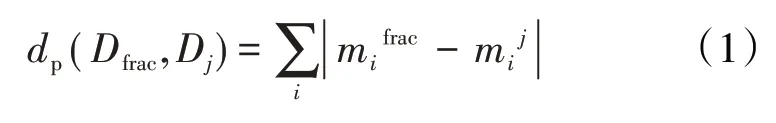
其中,L1 范数能够定义2 个数据集之间的相似度,L1 范数越小,相似度越高。最后,将与目标数据集相似度最高的25 个已储存的机器学习框架传送给贝叶斯优化流程。
2.1.2 贝叶斯优化
贝叶斯优化[26]的原理是通过拟合一个概率模型来捕捉超参数组合与其对应模型性能之间的关系,使用该模型选择最佳的超参数设置方向,计算超参数组合,用计算的结果更新模型,然后通过不断迭代使误差逐渐减小。基于树模型的贝叶斯优化在高维、结构化和部分离散的问题[27]上比基于高斯模型的贝叶斯优化[28]更为理想。而在基于树模型的贝叶斯优化方法中,基于随机森林的序列模型算法配置(SMAC)[29]比树状结构Parzen 估计方法(TPE)[30]表现更好,因此本研究中使用SMAC。SMAC 使用随机森林算法[31],通过每次评估1 折并尽早丢弃性能较差的超参数组合,来实现快速交叉验证。本研究在数据预处理、特征预处理和算法工程3个部分通过贝叶斯优化实现了自动化。
2.1.3 模型集成
自动机器学习利用贝叶斯优化得到了很多性能较好的模型,如果仅保留性能最佳的一个模型而丢弃其他模型,那么在时间和计算力上都比较浪费。因此,储存性能较好的多个模型并构建一个集成模型。集成模型的效果通常优于单个模型[32-33],而当组成集成模型的各个基础模型单独性能很强且产生的误差不相关时,集成模型的表现会更好。另外,集成模型还会大大地提高模型的泛化能力,防止出现过拟合。采用集成选择(ensemble selection)来进行模型集成。集成选择[32]是一个贪婪的过程,它向一个空的集成中迭代地加入模型,力求使集成模型在验证集上的性能最好。
2.1.4 自动机器学习系统
本次研究采用的自动机器学习系统为Autosklearn2.0[34]。Auto-sklearn 在2016年首次由FEURER 等提出[35],它能够较好地实现上述3 项技术。与其他机器学习算法和Auto-WEKA,Hyperoptsklean 等比较成熟的自动机器学习系统相比,其在多数数据集上性能更优[35]。Auto-sklearn2.0 在老版本基础上,对模型选择、算法组合与策略自动化这3个方面进行了改善,这些算法的优化使得新版本的计算精度相比老版本提高了5 倍[34],笔者采用该自动机器学习系统运算24 h的结果。
2.2 常规机器学习
2.2.1 数据预处理
为了消除特征之间数量级差异的影响,对特征集进行了标准化,即:
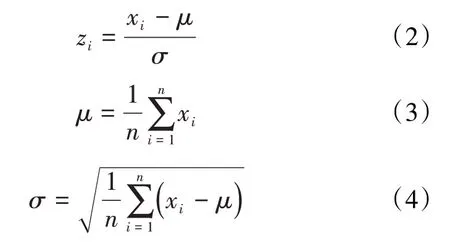
另外,按照75%和25%的比例将数据集随机地划分为训练集和测试集。其中,训练集用于模型训练和超参数优化,测试集不参与训练过程,仅用于评价模型的预测性能。
2.2.2 特征重要性评估及特征选择
评估特征重要性有助于特征选择,进而提高模型性能。封装法能够根据机器学习模型预测效果对特征的重要性进行评分,相比单因素分析更能体现特征对目标变量的影响程度。采用基于随机森林的封装法评估特征的重要性并进行特征选择,其具体实现方法为:对于每一个特征,将随机森林中每一个子决策树上该特征形成节点的Gini 指数下降程度进行求和,用这个指标来衡量特征的重要性[36]。与此同时,为了使特征重要性的计算结果更加稳定,运算过程采取7折交叉训练的形式。然后,采用贪婪过程来进行特征选择,即根据特征重要性程度由大到小,向算法模型中逐一加入特征,进而得到特征数量与模型精度和稳定性的关系,最终选择使模型得分高且得分标准差低的特征组合作为下一步模型计算的输入变量。
2.2.3 模型训练与优化
采取7 折交叉验证方式进行超参数优化,通过对比平均交叉验证误差来优选模型的所有超参数;然后,用优选的超参数在整个训练集上进行训练,并用从未参与模型训练的测试集来评价算法精度。7 折交叉验证方式能够充分高效地利用数据,并能够稳健地评估超参数性能,减少因数据集随机划分而导致的模型不稳定性,避免模型的过拟合。
2.2.4 机器学习算法
为了与先进的自动机器学习进行比较,采取了随机森林[31]、支持向量回归[37]和神经网络[38]这3 种较为成熟、在算法结构上差异较大且在大部分数据集上性能较好的机器学习算法,利用这几种算法进行建模,并对比算法之间的预测性能。
支持向量回归是支持向量机的一种形式,它使用不敏感损失系数作为损失函数:
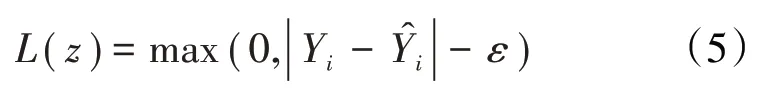
支持向量回归模型的主要超参数有核函数、不敏感损失系数、惩罚参数和宽度系数,将这几个参数作为待优化的超参数。
神经网络是一种由大量神经元相互联接构成的运算模型。当网络参数设置不当时,容易导致模型的过拟合现象。因此,为了提高模型的泛化能力,采用了早停技术(图2)、L2 正则化、批量标准化和dropout的正则化方法。L2正则化表达式为:

图2 早停技术示意Fig.2 Early stopping technology
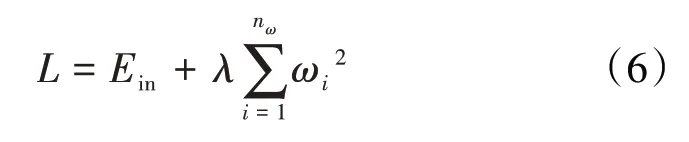
神经网络的调整参数包括激活函数类型、优化器类型、学习率、神经元数和batch_size。
随机森林是由众多弱学习器(决策树)集合而成的一种强学习器。影响该算法精度的2个重要超参数分别为子模型的数量和节点分裂时参与判断的最大特征数,对这2个参数进行优化。
2.2.5 支持库、超参数调整及模型评估
采用Scikit-learn 模型包[39]来实现支持向量回归和随机森林算法,用基于Python的Keras[40]来构建神经网络模型。超参数调整则通过网格搜索来完成。将决定系数和均方误差作为评估模型性能的指标,其表达式分别为:

3 结果分析与讨论
3.1 数据统计分析
各个变量之间的线性相关性用Pearson 相关系数进行描述(图3)。其中,0,1和-1分别为完全线性无关、完全线性正相关和完全线性负相关。另外,采用箱线图描述压裂后日产油量与影响因素之间的关系(图4)。每一个箱线的区间为该组分类数据的第1个四分位到第3个四分位。
从图3 可以看出,措施前日产油量与压裂后日产油量的线性相关性最强,Pearson 相关系数为0.70。措施前含水率、日产液量也与目标变量有着较强的相关性,同时,图4也表征出这些措施前生产数据对压裂后日产油量有着较为明显的影响。分析可知,油井实施压裂的大部分原因是由于近井地带储层堵塞等问题造成了产液能力下降,这类问题导致的产液能力下降是一个渐变的过程,而当油井日产液量有一定幅度的异常下降时,就会及时根据情况开展压裂等措施,很少会等待日产液量下降至原来的一半甚至更少时才采取补救措施,因此,油井日产液量、日产油量这2 个指标能在很大程度上描述油井压裂后的产油潜力。另外,压裂前含水率对压裂后日产油量也有较大的影响,这是由于油井压裂前含水率能够在一定程度上描述油井周围储层的含油情况,部分油井周围储层含油情况较好,含水率较低,但由于日产液量下降等原因造成日产油量较低,需要通过压裂来增产,这类油井在压裂后产油效果也较好。

图3 影响压裂后日产油量各因素相关性热力图Fig.3 Heat map of correlation between various factors affecting oil production rate after hydraulic fracturing
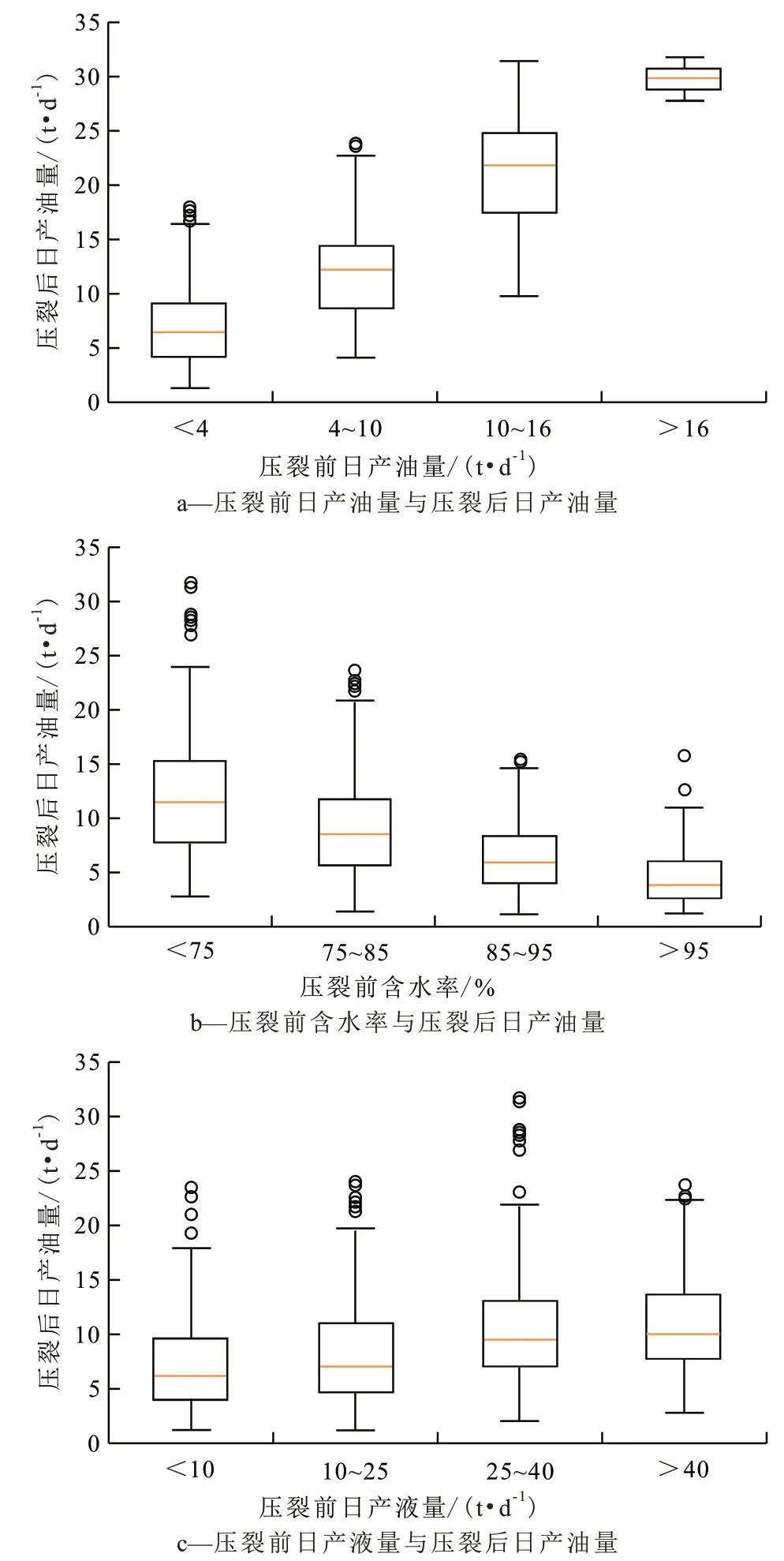
图4 影响因素与压裂后日产油量关系箱线图Fig.4 Box plot of relationship between influencing factors and oil production rate after hydraulic fracturing
Pearson 相关系数只能描述变量之间的线性关系,箱线图也仅能定性地查看影响因素与目标变量的变化趋势,而且2 种分析方式均为单因素分析。然而,在实际的压裂问题中,压裂后日产油量与影响因素之间可能存在非常复杂的非线性关系,而且受多因素同时影响。因此,需要探究更加适合的方法来进一步评价各个特征对于目标变量的影响程度。
3.2 特征重要性分析及特征选择
基于随机森林封装法的特征重要性评价结果如图5 所示。总体来看,压裂后日产油量受压裂前各项生产因素影响最大,其次是地质和工程因素。这意味着对采油井生产情况进行实时监测,并依据动态指标合理地选择压裂井和目的层对于措施效果更为关键。另外,加砂量和压裂液体积也对压裂后日产油量起了重要作用。这是因为这2个因素与形成裂缝的长度和导流能力有一定的关系。

图5 各特征重要程度(Gini指数法)Fig.5 Feature importance based on Gini index
分析模型R2可知(图6),模型的拟合精度在特征数量为6 后逐渐平缓;特征数量达到15 时,模型不但获得了较高的精度,且达到了非常低的标准差,即稳定的性能。因此,按照重要程度选取前15个特征作为3种常规机器学习算法的输入变量进行计算。
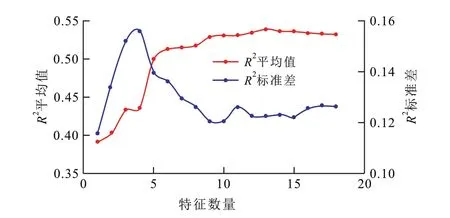
图6 交叉验证中模型R2平均值与标准差随特征数量变化关系Fig.6 Relationship between mean value and standard deviation of R2 with feature number in cross validation
3.3 机器学习预测模型建立
支持向量回归、神经网络、随机森林这3种常规机器学习算法与自动机器学习预测模型的预测性能对比结果(表1)显示,各种算法建立的模型在测试集上性能由好到差依次为自动机器学习、随机森林、神经网络和支持向量回归。随机森林虽然在测试集上也展现了较好的性能,但是其在训练集上的R2过高,说明该模型存在着较为严重的过拟合现象,模型的泛化能力较弱。从图7 可以直观地看出,自动机器学习预测模型在训练集和测试集上的预测结果均较好。自动机器学习预测模型在测试集上的R2为0.695,均方误差为7.81,预测结果相对误差的平均值为18.96%,标准差为16.97%,好于其他算法,因此优选其为最佳的压裂效果预测模型。为了对比该模型在现有预测水平上的提升效果,从采油与地面工程运行管理系统中提取压裂方案,查询压裂后日产油量预测值,计算实际压裂后日产油量和方案预测值之间的相对误差,统计得出测试集的方案预测相对误差平均值为76.49%,标准差为78.52%。对比可知,本研究建立的压裂效果预测模型可在目前水平上将预测相对误差的平均值降低57.53%,标准差降低61.55%,预测精度与稳定性均大幅提高。最优自动机器学习预测模型中各基础预测器参数信息见表2。
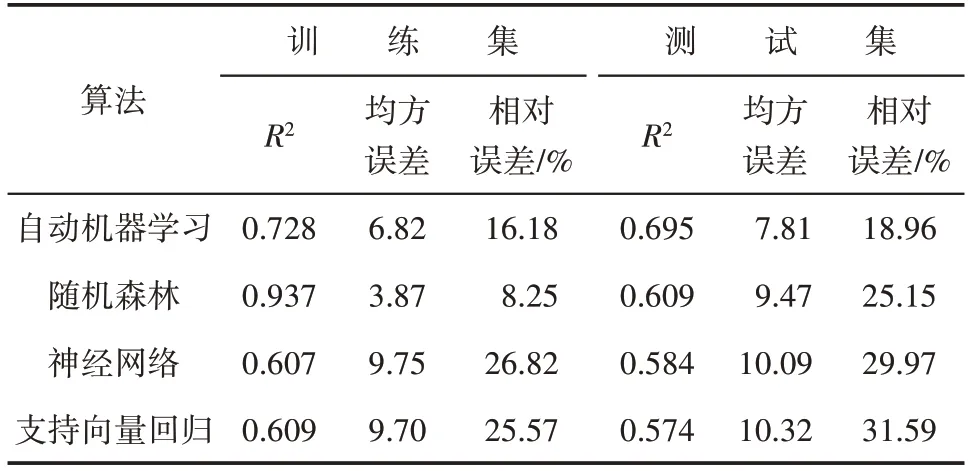
表1 各种算法在数据集上的预测性能Table1 Prediction performance of algorithms on data set
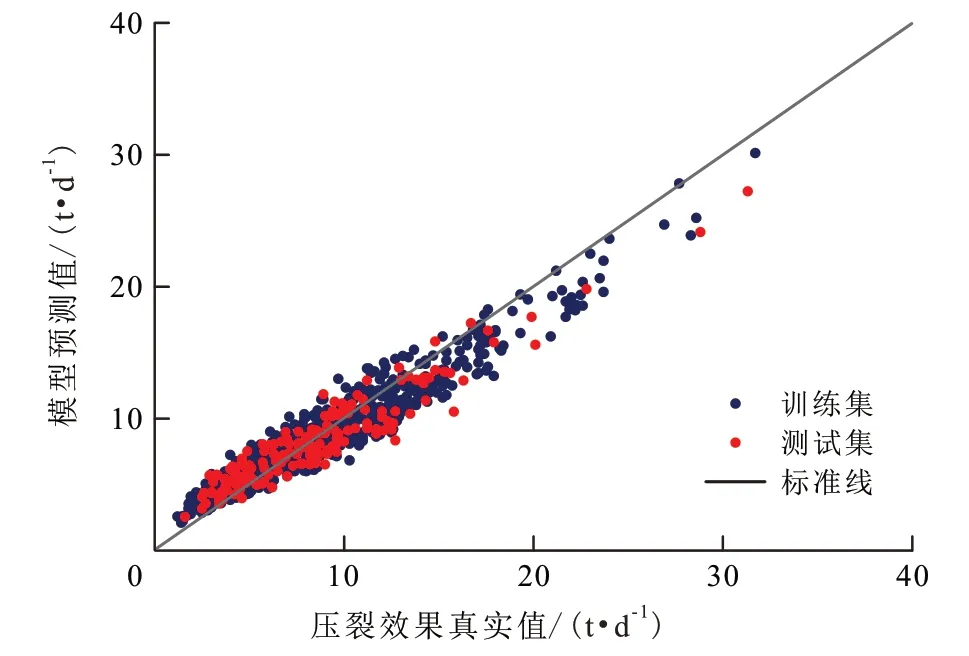
图7 自动机器学习预测模型的预测值与真实值对比Fig.7 Comparison between predicted values of automatic machine learning prediction model and real values
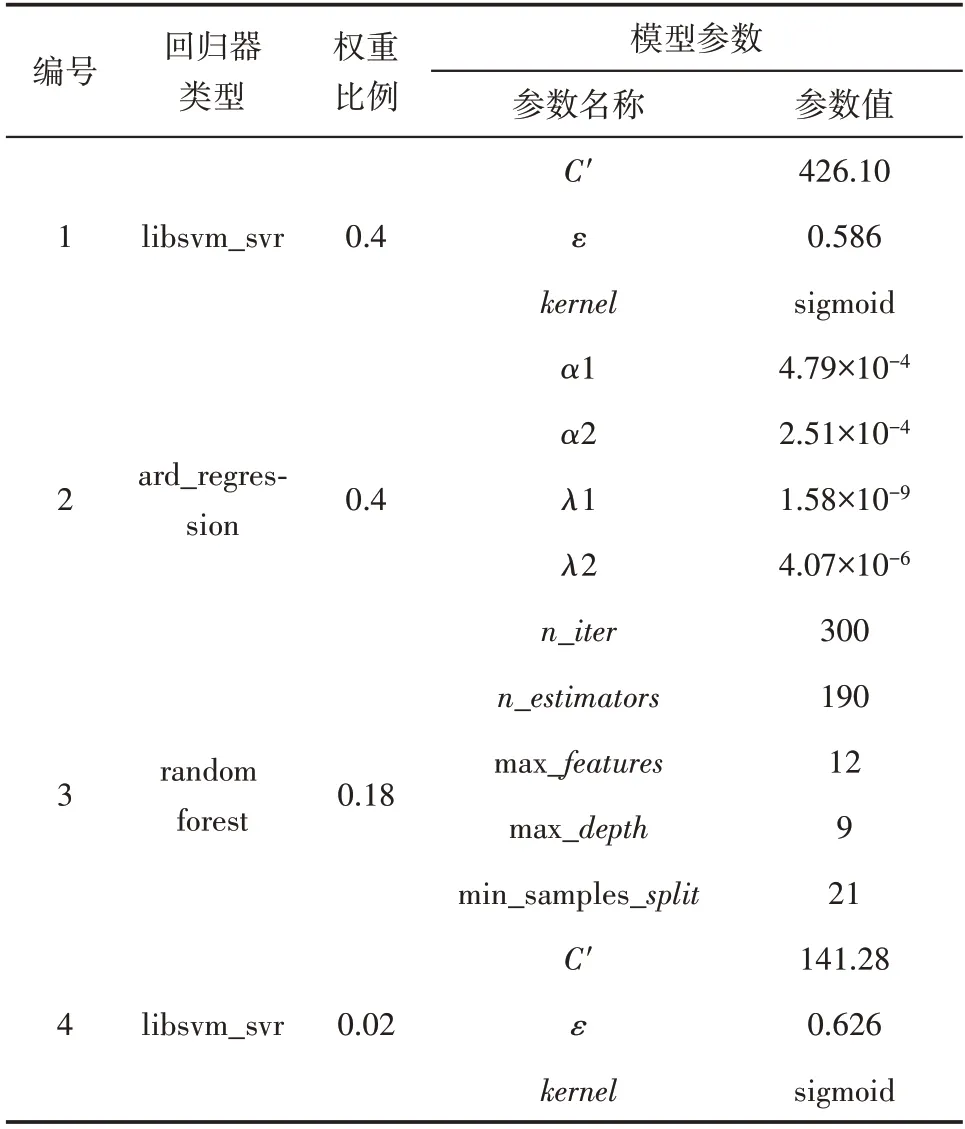
表2 最优自动机器学习预测模型中各基础预测器信息Table2 Information of base regressors in optimal automatic machine learning model
4 应用情况
4.1 经济效益测算
利用本研究建立的模型可大幅提高压裂后日产油量预测精度,进一步辅助压裂方案的制定与优化,最大程度提高压裂投资产生的经济效益。具体经济效益测算过程如下:①选取8口已压裂井,利用自动机器学习预测模型对压裂参数进行重新优化,得到每口井的最优压裂方案参数与压裂效果预测值。②利用上述模型在测试集上的相对误差平均值来估算每口井措施效果的范围,并与原方案的实际效果进行对比,求取参数优化后相比于原方案增加的初期日增油量。③压裂有效期选取4 个月,假设模型优化方案比原方案额外日增油量在压裂有效期内按指数关系递减(图8),有效期末额外日增油量趋于0,再通过求取积分估算有效期内总的额外增油量。④选取油价为70 美元/bbl,汇率为6.37,通过计算即可得到模型优化方案相比原方案的额外经济效益。从模型优化增加经济效益测算结果(表3)可以看出,经过模型优化压裂参数后,选取的8 口井相比原方案平均可额外增加经济效益3.2×104~27.4×104元/井次,平均为16.1×104元/井次。额外总增油量的表达式为:
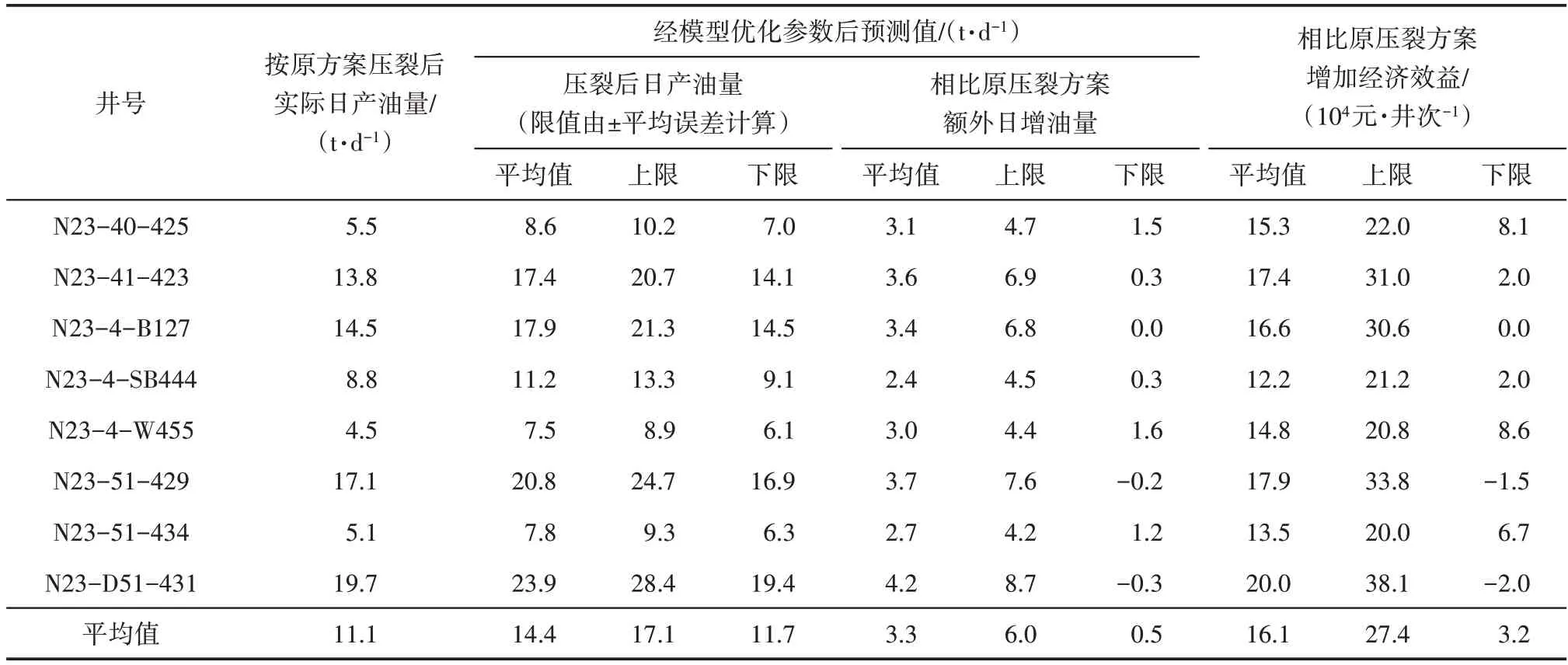
表3 模型优化增加经济效益测算结果Table3 Economic benefits increased by model optimization

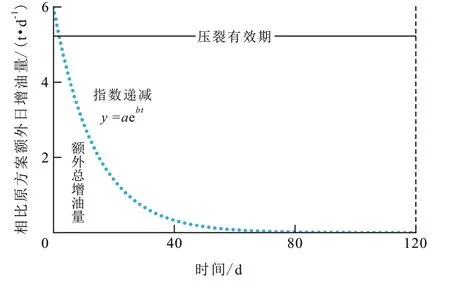
图8 自动机器学习预测模型优化后压裂方案较原方案额外增油量示意Fig.8 Extra oil increment of optimal scheme compared with the original scheme
4.2 矿场应用案例
为了进一步验证模型的精度与现场应用的可行性,利用上述建立的自动机器学习预测模型对4口采油井进行压裂方案的设计与优化。
监测N23 区块采油井日产液量、产液剖面等各项动态指标变化情况,结合井组注采关系、连通关系等地质条件与地层能量、剩余油饱和度等开发参数,选定4 口采油井开展压裂措施。压裂方案设计优化涉及地质和工程2 个方面的参数。首先,模型考虑的各项地质因素主要受压裂目的层位的影响。分析各采油井的生产层位、产液剖面和连通情况等信息,每口采油井初选3 个目的层进行排列组合。压裂工程方面选取压裂液类型和加砂量这2个对模型效果影响较大的参数。加砂量选取12,15,18,21,24 这5 个数值,压裂液类型则将胍胶压裂液、缔合压裂液和其他压裂液作为待选。将每口井的所有选层、加砂量及压裂液类型进行逐一组合,可得到90 个压裂方案,详见表4。将所有压裂方案参数输入自动机器学习预测模型进行计算,优选出各采油井的最佳方案如表4 所示。2019 年6 月开始,按最优方案对这4 口采油井实施了压裂改造,实际效果(表5)表明,压裂后采油井的日产油量和模型预测值非常接近,本文建立的自动机器学习预测模型对实际矿场的预测性能较好。该自动机器学习预测模型对大庆油田N23区块的水力压裂设计与优化具有指导意义,模型经过简单的参数修改便可预测其他开发区块,简单易用,推广性强。

表4 压裂参数优化情况Table4 Optimization results of hydraulic fracturing parameters
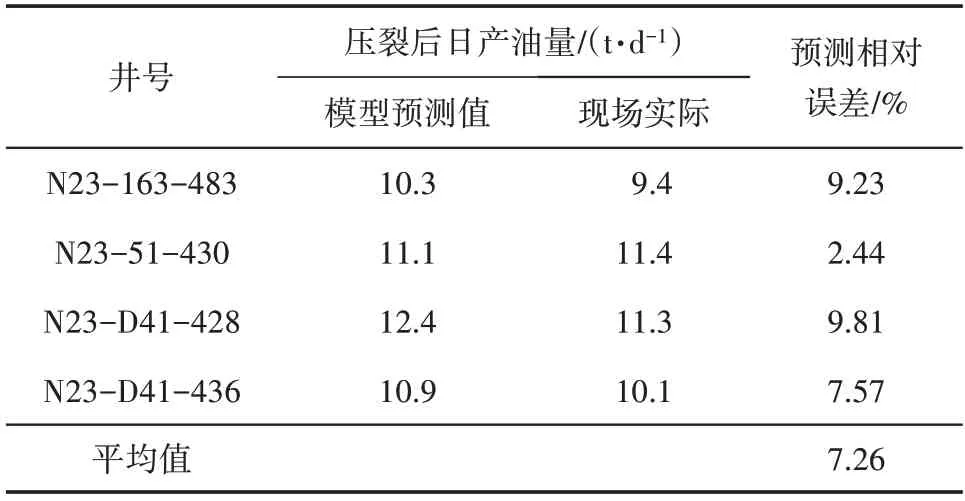
表5 最优压裂方案效果预测及施工后实际值Table5 Effect prediction of optimal hydraulic fracturing scheme and actual values after hydraulic fracturing
5 结论
依据矿场压裂统计数据分析了大庆油田N23区块的采油井压裂增产情况,采用自动机器学习建立了一个精度高、稳定性强的采油井压裂效果预测模型。各项统计结果表明,采油井水力压裂的各影响因素与压裂后日产油量存在定性关系;利用封装法进行了特征重要性评估,得到对模型影响较大的特征为:压裂前日产油量、含水率、加砂量等。利用自动机器学习建立的预测模型精度高于支持向量回归、神经网络和随机森林这3种常见机器学习算法,模型在测试集上的精度高达0.695,预测相对误差仅为18.96%,比目前降低了57.53%。经过模型优化的压裂方案较原方案平均可额外增加经济效益约3.2×104~27.4×104元/井次;另外,利用自动机器学习预测模型对N23 区块采油井压裂增产方案进行了优化,结果显示,模型计算出的最优参数组合方案实际效果较好,而且现场的实施效果与模型预测值非常相近。自动机器学习预测模型对N23区块压裂措施参数设计具有指导作用,现场可行性高,模型推广性强。
符号解释
a,b——回归公式系数;
C'——支持向量回归算法中的惩罚因子;
dp(Dfrac,Dj)——目标数据集与数据库中第j个数据集之间的L1范数;
Dfrac——目标数据集;
Dj——数据库中第j个数据集;
Ein——未包含正则化项的训练样本误差;
i——元特征个数;
j——数据集个数;
k——交叉验证的折数;
kernel——支持向量回归算法中的核函数类型;
L——损失函数;
L(z)——不敏感损失函数;
——目标数据集中第i个元特征值;
——第j个数据集中第i个元特征值;
max_features——random forest 算法中寻找最佳分割时要考虑的特征数量;
max_depth——random forest算法中树的最大深度;
min_samples_split——random forest 算法中拆分内部节点所需的最少样本数;
MSE——均方误差;
n——样本的数量;
n_estimators——random forest算法中决策树的数量;
n_iter——ard_regression算法中的最大迭代次数;
nω——待学习参数的数量;
R2——决定系数;
t——压裂后生产天数,d;
tmax——压裂有效期,d;
V总增油量——额外总增油量,t;
xi——第i个样本特征在标准化前的数值;
X测试集——测试集特征;
X训练集——训练集特征;
——所有样本目标变量的平均值;
Yi——第i个样本目标变量的实际值;
——第i个样本目标变量的模型预测值;
Y训练集——训练集目标变量值;
zi——第i个样本特征在标准化后的数值;
α1,α2,λ1,λ2——ard_regression算法中的模型系数;
ε——不敏感损失系数;
λ——正则化参数;
μ——所有样本的平均值;
σ——所有样本的标准差;
ωi——第i个网络层待学习参数。
