基于知识蒸馏与ResNet的声纹识别
2023-02-15荣玉军方昳凡程家伟
荣玉军,方昳凡,田 鹏,程家伟
(1.中移(杭州)信息技术有限公司,杭州 310000;2.重庆邮电大学 自动化学院,重庆 400065)
随着物联网、智能设备、语音助手、智能家居和类人机器人技术的发展,以及人们对安全的日益重视,生物识别技术的应用越来越多,包括脸部、视网膜、声音和虹膜等识别技术[1]。其中声纹识别因易于实现,使用成本低而被用户广泛接受。声音是一种生物行为特征,它传递一个人特征相关的信息,比如说话人的种族、年龄、性别和感觉。说话人识别是指根据人的声音识别人的身份[2]。研究表明,声音因其独特的特征可以用来区分不同人的身份[3],除了虹膜、指纹和人脸外,语音提供了更高级别的安全性,是一种更加有效的生物识别技术。
说话人识别可分为说话人确认和说话人辨认2个任务,说话人确认是实现智能交互的关键技术,可广泛应用于金融支付、刑事侦查、国防等领域[4]。说话人确认是一对一的认证,其中一个说话者的声音与一个特定的特征匹配,可以分为文本依赖型和文本独立型[5]。与文本相关的说话人确认系统要求从固定的或提示的文本短语产生语音,利用说话人语音的尺度不变性、特征不变性和文本相关不变性等特性,对说话人语音进行识别[6],而与文本无关的说话人确认系统操作的是无约束语音,是一个更具有挑战性与实用性的问题。

当前,深度学习方法广泛应用于语音识别[10]、计算机视觉领域,并逐渐应用于说话人识别等其他领域,均取得了显著成效。2014年,Google的d-vector使用神经网络隐层输出替代I-Vector,虽然实验效果不如I-Vector,但证明了神经网络方法的有效性。循环神经网络(RNN, recurrent neural network)在语音识别方面效果良好,在处理变长序列方面具有明显优势,现在也被应用在说话人识别任务中。2017年,Snyder[11]等人使用时延神经网络提取帧级特征,语句级特征则从统计池化层聚合而来,利用PLDA进行后端打分,处理短语音的效果优于I-Vector,在它基础上加入离线数据增强后效果整体超过了I-Vector,成为新的基准模型。目前,有方法将图像领域的卷积神经网络用于说话人识别语音信号的预处理以提高说话人识别率[12],VGG结构网络[13],深度残差网络[14]等卷积神经网络结构也被用于处理说话人识别任务。尽管深度学习的应用使得说话人识别技术有了巨大进步,但目前还存在以下问题:1)对于短语2 s的短时语音识别性能差;2)缺乏对信道多变性的补偿能力;3)对于噪声条件适应性不足,鲁棒性差。
笔者提出一种采用知识蒸馏技术,将传统的I-Vector方法与深度学习相结合的方法,进行与文本无关的说话人确认。设计所使用的ResNet网络模型结构, 并对模型进行训练。比较不同打分后端下基准模型和增加数据增强后的实验结果,以及采用知识蒸馏的I-Vector模型与ResNet网络相结合后的实验结果,并对实验结果进行了讨论。
1 基于知识蒸馏与ResNet的声纹识别
笔者设计的声纹识别模型方法分为4步,如图1所示。1)对输入语音进行预处理;2)对输入语音提取I-Vector,采用训练好的I-Vector模型作为教师模型,ResNet为学生模型;3)将I-Vector模型与ResNet模型联合训练;4)利用PLDA方法或者余弦方法进行打分。
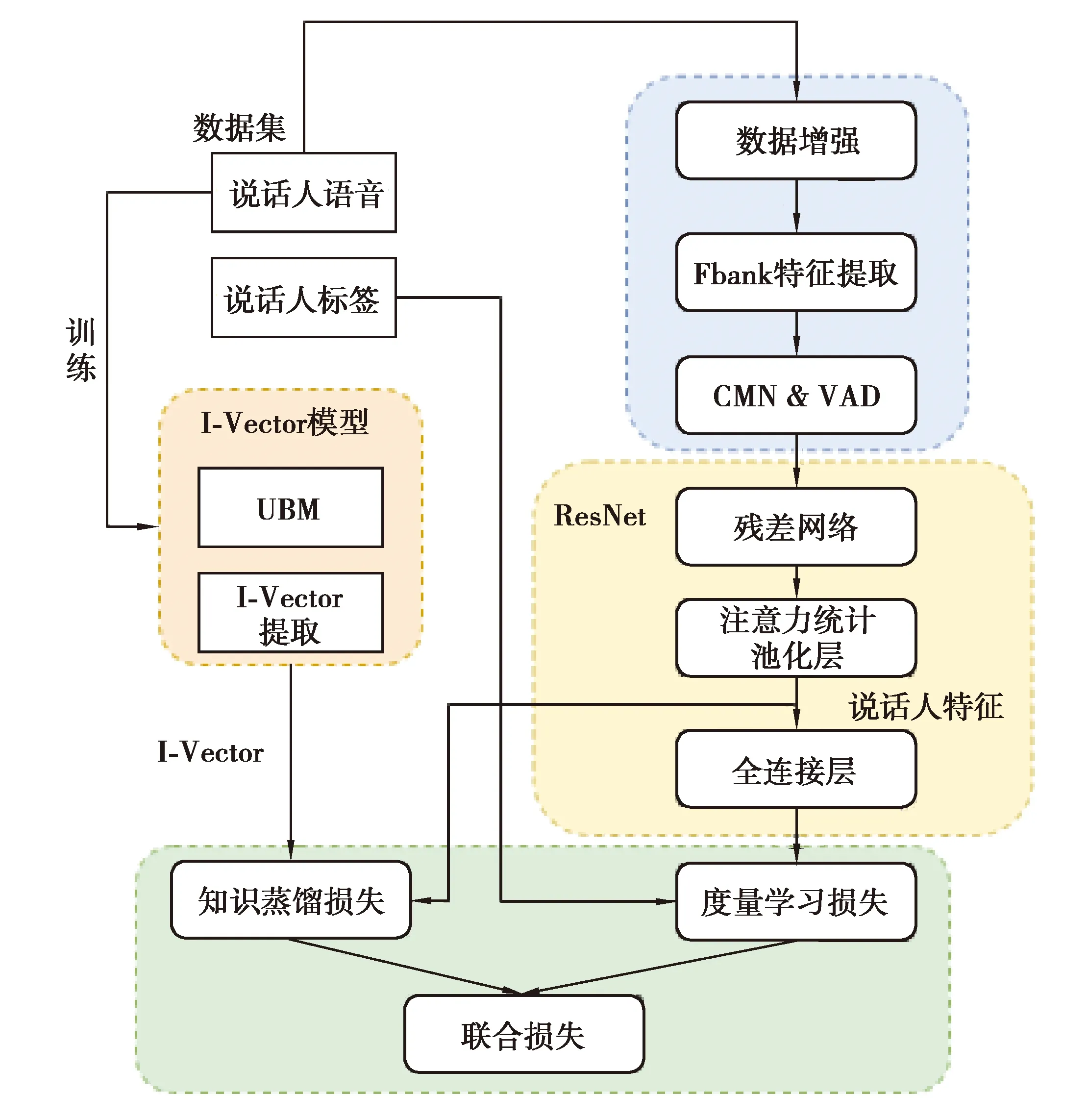
图1 基于知识蒸馏与ResNet的声纹识别模型框架图
1.1 语音预处理
原始语音的预处理主要进行的步骤为:
1)提取语音数据的Fbank(Filter Bank)特征。
2)对语音数据进行增强,包括使用噪声数据集与原始数据集叠加合频谱增强方法。
1.1.1 特征提取
Fbank是频域特征,能更好反映语音信号的特性,由于使用了梅尔频率分布的三角滤波器组,能够模拟人耳的听觉响应特点。Fbank特征的提取步骤为:
1)首先使用一阶高通滤波器应用于原始信号,进行信号预加重,达到提高信号的信噪比与平衡频谱的目的,
y(n)=s(n)-αs(n-1),
(1)
式中:y(n)是预加重后的信号;s(n)为原始语音信号;α是预加重系数,其典型值为0.95或0.97。
2)将预加重后的语音分割成多个短时帧,每一帧之间具有部分重叠。接着利用Hamming窗为每一个短时帧进行加窗操作,防止离散傅里叶变化过程中产生频谱泄露。
(2)
式中:w(n)即为窗函数;N为该帧的采样点数量。
3)对加窗后的语音信号进行离散傅里叶变换
(3)
其中:s(n)为一个短时帧语音信号;S(k)是其频率响应。根据频率响应计算功率频谱P(k)
(4)
4)最后使用梅尔频率均匀分布的三角滤波器对功率谱图进行滤波,得到了Fbank特征,该特征模拟了非线性的人耳的听觉响应。可以通过下列计算公式进行频率f和梅尔频率m之间进行转换
(5)
f=700(10m/2 595-1)。
(6)
通过上述过程即可得到作为网络输入的Fbank特征。
5)Fbank特征是频域特征,而通道噪声是卷积性的,其在频域为加性噪声,因此利用倒谱均值归一化方法(CMVN,cepstral mean and variance normalization)抑制该噪声。之后利用语音活动检测(VAD, voice activity detection)基于语音帧能量移除语音数据在中的静音段。
1.1.2 数据增强
在深度学习中,数据集大小决定了模型能够学习到内容的丰富性,对模型的泛化性与鲁棒性起着关键性作用。在研究中将采用2种数据增强方式:1)离线数据增强;2)在线数据增强。
离线数据增强方法在X-Vector模型中[18]最先使用,该方法采用2个额外的噪声数据集MUSAN和simulated RIRs[15],其中MUSAN数据集由大约109 h的音频组成,包括3种类型:1)语音数据,包括可公开获得的听证会、辩论等录音;2)音乐数据,包括爵士、说唱等不同风格音乐;3)噪声数据,包括汽车声、雷声等噪声。simulated RIRs数据集包括具有各种房间配置的模拟房间脉冲响应。离线数据增强的具体方式为,随机采用下列的一种方式进行增强:
1)语音叠加:从MUSAN数据集的语音数据中随机选取3—7条语音,将其叠加后,再以13~20 dB的信噪比与原始语音相加。
2)音乐叠加:从MUSAN数据集的音乐数据中随机选取一条音频,将其变换至原始语音长度,再以5~15 dB的信噪比与原始语音相加。
3)噪声叠加:从MUSAN数据集的噪声数据中随机选取一条音频,以1 s为间隔,0~15 dB的信噪比与原始语音相加。
4)混响叠加:从simulated RIRs数据集中随机选取一条音频,与原始信号进行卷积。
在线语音增强方法是一种直接作用于频谱图上的方法,可以在网络接收输入后直接计算。本研究中主要采用在线语音增强的其中2种方式:频率掩膜与时间掩膜方式。如图2所示,以下设置原始语音特征的频谱特征为S∈RF×T:
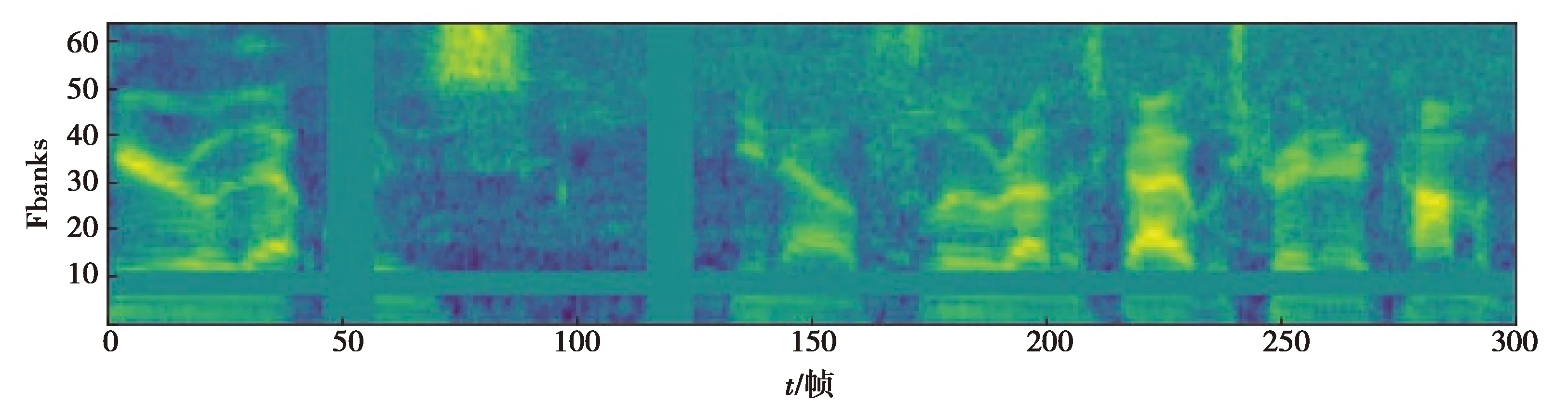
图2 频谱增强后的Fbank特征
1)频率掩膜:特征的频率维度是F,设置频率掩膜区间长度为f,f为可调参数。然后从区间[0,F-f]中任意选取掩膜区间的开始位置f0,最后对语音特征S的[f0,f0+f]区间进行掩膜操作,即将其区间内的值设置为0,该操作可重复多次。
2)时间掩膜:特征的时间维度是T,设置频率掩膜区间长度为t,t为可调参数。然后从区间[0,T-t]中任意选取掩膜区间的开始位置t0,最后对语音特征S的[t0,t0+t]区间进行掩膜操作,即将其区间内的值设置为0,该操作可重复多次。
1.2 I-Vector提取
假设一帧语音特征的大小为F,即Fbank特则维度为F,将数据集中第i条语音的特征表示为Oi=(oi1…oi2…oiTi)∈RF×Ti,式中:Ti表示该语音的帧数;oit表示第t帧的特征向量,t=T1,T2,…,Ti。在I-Vector框架中,假设每一帧的特征向量oit都由各自的高斯混合模型(GMM,gaussian mixture model)生成,同一条语音中的不同语音帧特征由同一模型独立分布生成,而每条语音所对应的高斯混合模型都由通用背景模型(UBM,universal background model)进行均值超向量平移操作得到
μi=μ(b)+Twi,
(7)
式中:μi,μ(b)∈RCF,μi为第i条语音对应的GMM的均值超向量,μ(b)为UBM的均值超向量;C为GMM模型分量的数目;T∈RCF×D为I-Vector提取器,定义了总变化矩阵;wi∈RD为总变化空间内服从标准高斯分布的隐变量,对其进行MAP估计,即可得到I-Vector。
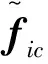
(8)
(9)
式中,γc(oit)为第c个高斯分量的后验概率
(10)
接着可通过以下计算得到I-Vector
(11)
式中:Li为
(12)
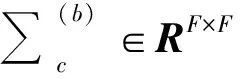
估计总变化矩阵T的过程即为I-Vector模型的训练过程,使用EM算法训练模型,其中E步骤为
〈wi|Xi〉=ui,
(13)
(14)
M步骤为
(15)
式中,N为数据集中包含的语音总数。利用I-Vector模型解决短时语音与信道失配问题,并学习到信息“教”给基于ResNet的声纹识别模型。
1.3 基于ResNet的声纹识别设计
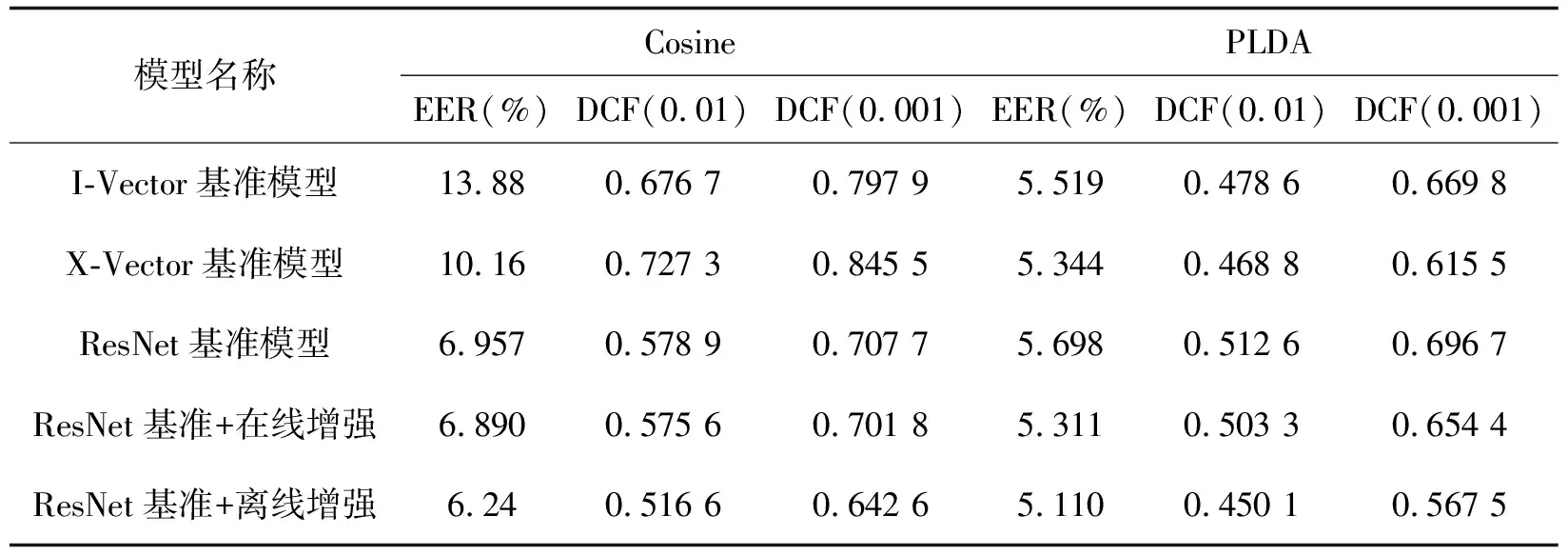
笔者设计的基于ResNet声纹识别模型结构如表1所示。
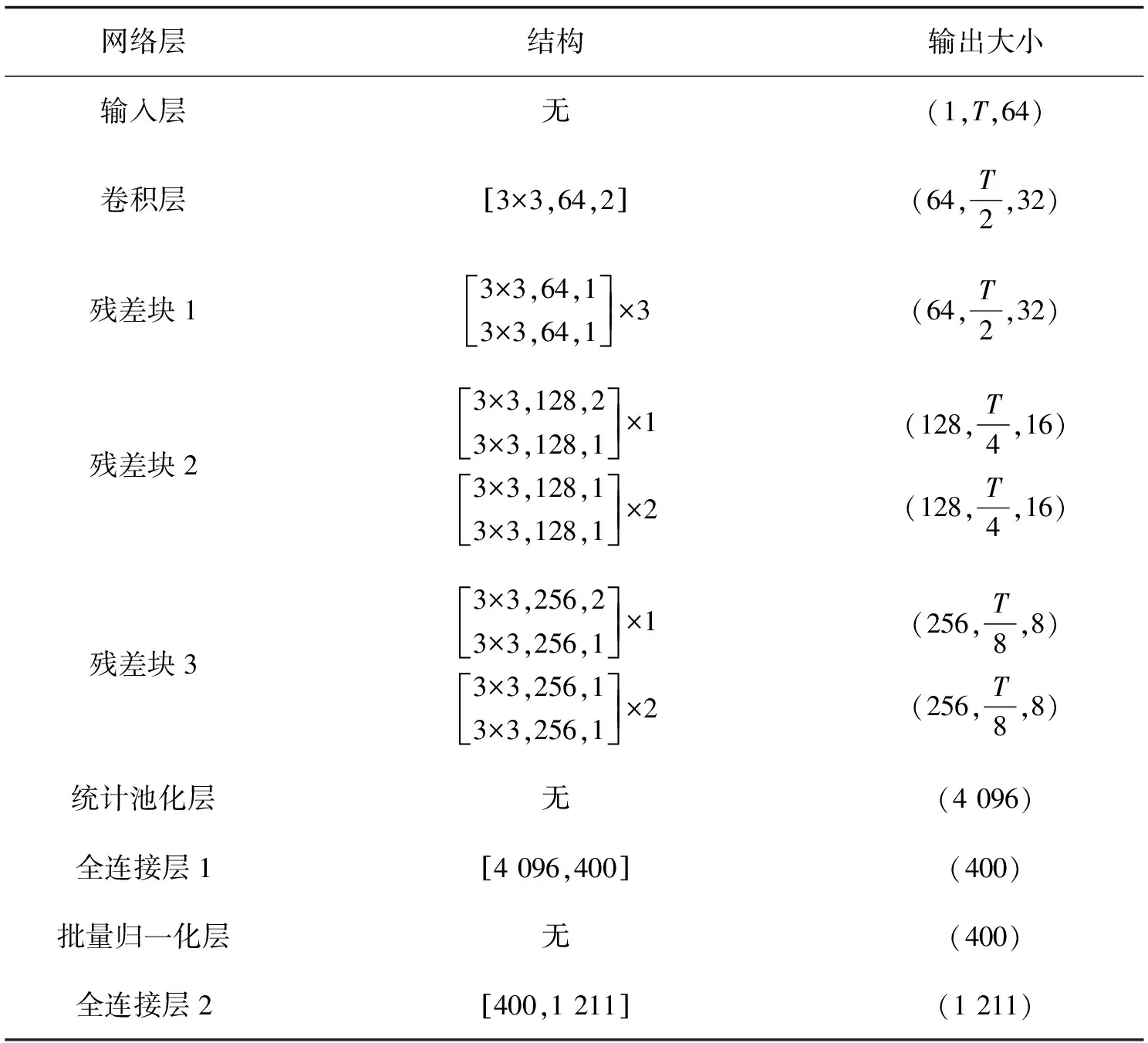
表1 ResNet的具体结构
在表1中,[·,·,·]表示卷积的卷积核的大小、通道数、卷积步长。输出大小中T为输入特征的帧数。在每一个残差块后都接有批量归一化层与ReLU激活函数。
从表1的结构中,网络输入是大小为(1,T,64)的张量,Fbank特征维度为64,网络结构中的卷积层、残差块2、残差块3对输入采取了通道数翻倍、频率维度减半、时间维度减半的操作。全连接层1的输出即为提取的声纹特征,全连接层2为分类层,仅仅在训练过程中使用,1211为训练数据集包含的人数。
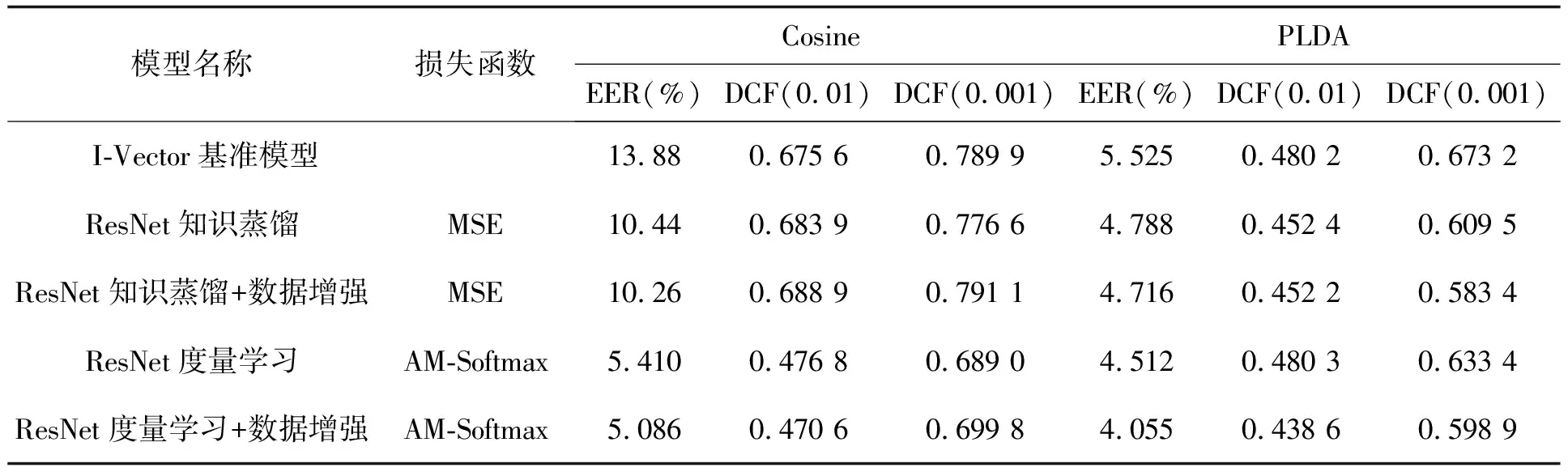
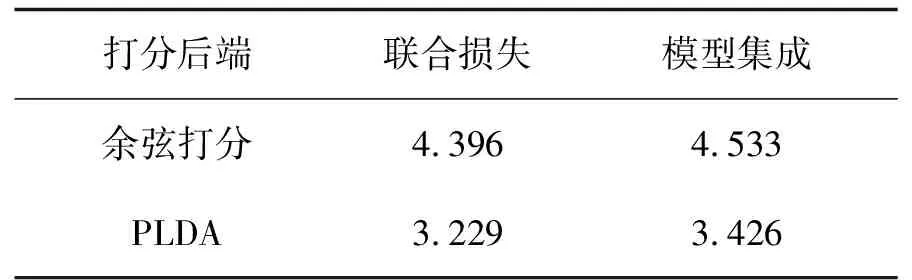
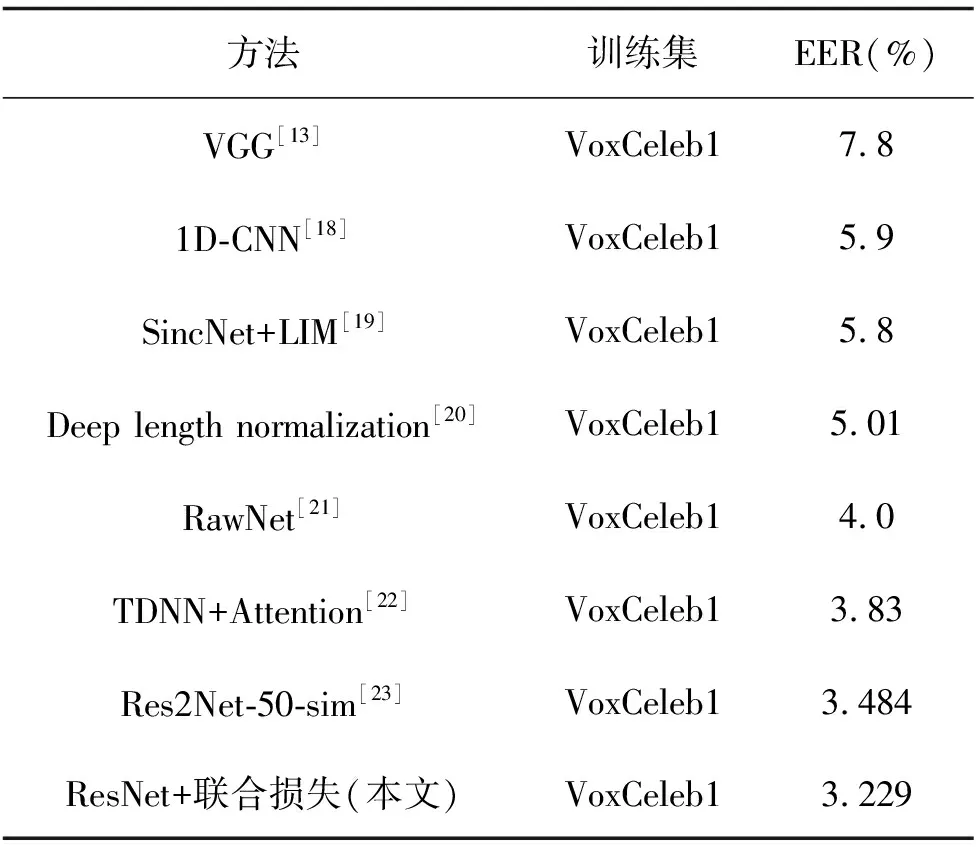
统计池化层(statistics pooling)是声纹识别模型中所特有的结构,用来处理语音输入序列变长问题。卷积层也可以接收不定大小的输入,但对于不同大小的输入,其输出大小也会不同,但在声纹识别任务中,需要将不同大小的特征映射至固定维度大小的声纹特征。残差块将维度为F0的Fbank特征变为形状为X∈RC×F×T的多通道特征,其中:C为通道数;F和T对应于网络原始输入O∈R1×F0×T0中的特征维度F0和T0,F 图3 注意力统计池化层结构 首先为每个帧级特征计算标量分数scoret scoret=vTf(WRCt+b)+k, (16) 式中:f()表示非线性激活函数;RCt为第t个通道的特征;v,W,b,k为要学习的参数,接着利用softmax函数在所有的帧上做归一化操作,得到归一化分数αt: (17) (18) 通过这种方式,利用加权平均提取到的语句级特征将关注到信息量更丰富的帧,接着使用加权标准差将统计池化与注意力机制相结合 (19) 将加权平均值与加权标准差拼接后作为全连接层的输入,提高了语句级声纹特征的可区分性。将ResNet提取到的声纹特征记为Embedding。 1.4.1 后端打分 使用2种后端打分策略:PLDA打分后端与余弦打分后端。 1)PLDA打分计算过程:记2条语音的I-Vector分别为u1,u2,使用对数似然比进行打分 lnN(u1|m,∑+VVT)-lnN(u2|m,∑+VVT), (20) 式中:p(u1,u2|H1)为2条语音来自同一说话人的似然函数,p(u1|H0)与p(u2|H0)分别为u1和u2来自不同说话人的似然函数。 2)余弦打分后端计算过程:记2条语音的Embedding分别为x1,x2,使用2向量的余弦距离计算得分 (21) 1.4.2 训练损失函数 研究使用的第一种损失函数是蒸馏损失,它是I-Vector与经ResNet提取到的Embedding之间的均方误差(MSE,mean squared error),将一个批次中的第i个样本的I-Vector记为ui∈RD,ResNet提取到的Embedding记为xi∈RD,两者之间的损失由以下公式计算 (22) 式中B表示一个批次的大小。通过优化这一损失,可以使ResNet提取到的Embedding向I-Vector学习,由于I-Vector服从高斯分布,与PLDA中的假设相符,所以使用这种损失可以提高以PLDA为打分后端时的声纹识别模型性能。 第二种损失为度量学习损失,采用的为additive margin softmax(AM-Softmax)损失,它的计算过程为 (23) 最终,笔者提出一种将2种损失相结合的基于知识蒸馏的联合损失函数 Lcombine=γLm+(1-γ)Ld, (24) 式中,γ为超参数,0≤γ≤1,可以控制2种损失之间的比例。 当单独使用蒸馏损失MSE时,相当于使用无监督训练,I-Vector直接与Embedding计算损失;单独使用度量学习损失AM-Softmax时,仅使用ResNet模型训练,未有监督训练,未利用I-Vector进行知识蒸馏;使用联合损失时,既使用了蒸馏损失MSE,也使用了度量学习损失AM-Softmax进行训练。3种损失都用来更新ResNet网络的权值。 笔者所提出的模型使用VoxCeleb1[17]公开数据集进行训练,该数据通过一套基于计算机视觉技术开发的全自动程序从开源视频网站中捕捉而得到,完全属于自然环境下的真实场景,说话人范围广泛,场景多样。其中包括一个验证集和一个测试集,分别用于模型的训练和测试,数据集的数量统计如表2所示,此外,从测试集中随机抽取了37 720对语句用于模型的验证。在拥有了原数据后,使用离线增强和在线增强方法对原数据进行数据增强,对比分析数据强化对实验结果的影响。数据增强策略中的离线增强方式增加的样本数量为100 000个,在训练之前加入数据集;另一种是在线增强方式,频率掩膜参数设置为10,重复次数为1次,时间掩膜参数为15,重复次数为2次,即参数F,Nf,T,Nt分别被设置为10, 1, 15和2。 表2 模型数据集统计 基准模型用于和本实验中所设计的模型进行性能比较,从而证明本实验中的模型有效性。实验使用的基准模型包括I-Vector、X-Vector,2种模型均使用Kaldi框架实现。I-Vector模型的语音特征使用24维的梅尔频率倒谱系数(MFCC, mel frequency cepstral coefficents),经过了二阶差分处理、基于滑动窗口的CMN和VAD处理后为72维,所用的UBM模型具有2048个高斯分量,所得的I-Vector维度为400。X-Vector模型的语音特征使用30维MFCC,并经过了基于滑动窗口的CMN和VAD,网络结构为5层的TDNN,说话人特征为512维,其使用了离线增强方式的数据增强方法,增强的样本数量为100 000个,并在训练之前加入数据集,网络训练所用的损失函数为交叉熵损失。2种模型均采用PLDA打分后端,并在PLDA前,使用LDA将离线增强后的数据维度降至200维并进行了L2归一化。 本次实验使用基于PyTorch的深度学习框架构建了所需要的ResNet模型,使用单个NVIDIA Tesla P100显卡训练30个迭代。使用Kaldi框架提取64维的Fbank作为输入特征,并经过了基于滑动窗口的CMN和VAD。Cosine和PLDA打分被用于模型结果评估,其中均采用等错误率(EER,equal error rate)和最小检测代价功能(minDCF, minimum detection cost function)来衡量模型的性能,等错误率是指当决策阈值变化时,错误接受率(FAR,false acceptance rate)与错误拒绝率(FRR, false rejection rate)相等时FAR或FRR的值,检测代价是说话人识别中常用的一种性能评定方法,定义式为DCF=Cfr×FRR×Ptarget+Cfa×FAR×(1-Ptarget),其中Cfr和Cfa为错误拒绝和错误接受的惩罚权重,取Cfr=Cfa=1,Ptarget为目标说话人在总人群中的比例,最小检测代价即阈值变化时,检测代价的最小值。2种指标的值越小,表明模型性能越强。在 AM-Softmax损失函数中,缩放因子α和附加距离m分别设置为30和0.2。在训练中,输入被截断或填充为3 s的长度,以形成大小为128的小批量数据。使用初始学习率为0.001的Adam优化器,将验证集数据用于检验训练效果,当验证集上的结果没有得到改善时,将学习率衰减到之前的1/2。 如表3所示。其中DCF(0.01)表示检测代价函数中的p-target参数为0.01,基准模型都使用了交叉熵损失函数。 表3 基准模型实验结果 ResNet基准模型的性能具有较好的稳定性,在余弦打分后端和PLDA打分后端下的结果相差不大,在余弦打分下的实验结果相较X-Vector和I-Vector模型有很大的提升。ResNet基准模型采用在线增强后,PLDA打分下的实验结果优于ResNet基准模型,而余弦打分下的实验结果变化不大。ResNet基准模型采用离线增强后,在2种打分方式下,所有性能指标相较于ResNet基准模型都有了很大的提升,并且同样优于采用在线增强方式的ResNet基准模型。因此对于同样的数据处理流程,离线增强方式更为复杂,但能获得更好的结果,在线增强方式计算速度快,仍然值得尝试。 采用知识蒸馏技术的ResNet模型使用了MSE损失函数,基于度量学习的ResNet模型损失函数使用AM-Softmax,从表4可以看出,针对知识蒸馏技术优化的损失方法,ResNet模型结果明显优于I-Vector基准模型,因为ResNet是从I-Vector中提取和学习部分相关参数且得到了更好的结果,这证明了ResNet方法和蒸馏损失方法结合的有效性。采用基于度量学习的损失函数AM-Softmax得到的模型结果优于I-Vector基准模型和采用知识蒸馏技术得到的模型结果。因此,考虑采用联合训练的方式来提升实验效果。 表4 三种模型的对比实验 在联合训练中,使用的模型都是ResNet模型,采用在线增强进行数据增强,从上表可看出,γ分别取0.2、0.1、0.05,γ控制这2个损失之间的比例,通过减小γ来强调蒸馏损失。结合表4和表5可以看出,针对损失函数,使用MSE损失和AM-Softmax损失联合训练的方法能够很大程度的提升模型的结果,实验结果还表明,AM-Softmax损失有助于提高模型在Cosine打分下的性能,而MSE损失有助于提高模型在PLDA打分下的性能。 表5 联合训练实验结果 模型集成是指通过分数融合的方式,集成采用MSE损失函数和AM-Softmax损失函数的2种模型,2种模型使用离线增强,将它们测试集的打分结果进行加权平均,然后再计算EER等性能指标。 从表6中可以看出,在余弦打分后端与PLDA打分后端下,模型集成的性能均略低于联合训练方式,2种训练方式实验结果相差不大,但相比于模型集成需要训练多个模型进行集成,而联合训练只需要一个模型,节约了计算资源,更加高效。 表6 模型集成的实验结果 结合以上实验可以得出性能最好的是采用数据增强和联合损失的网络结构,表7展示了和其他论文中同样使用VoxCeleb1数据集的说话人识别方法的实验结果的比较。 表7 与其它方法对比的实验结果 从表7可以看出,提出的方法与其他方法对比,EER最低降低了8%,达到了3.229%,性能均优于表中提到的其他方法。 提出了一种基于知识蒸馏与ResNet的声纹识别方法。将传统无监督声纹识别方法与基于深度学习的声纹识别方法相结合,用蒸馏损失MSE约束ResNet声纹特征和I-Vector的差异,提高了声纹识别的准确率。此外,研究进一步采用了2种不同数据增强方式对数据集进行扩充,增强了模型对噪声环境的适应性,提高了系统的鲁棒性,验证了2种增强方式在声纹识别任务中的有效性。设计的ResNet模型包括了注意力统计池化,结合知识蒸馏损失与度量学习损失设计了新的联合训练损失,相较于模型集成的方法,在2种打分后端下,联合训练方法的EER均低于模型集成方法。构建了端到端的声纹识别模型,与大多数基于深度学习的方法相比,能够将EER进一步降低为3.229%。
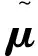
1.4 基于知识蒸馏的联合训练
2 实验与结果分析

2.1 基准模型
2.2 模型训练
2.3 主要实验结果分析
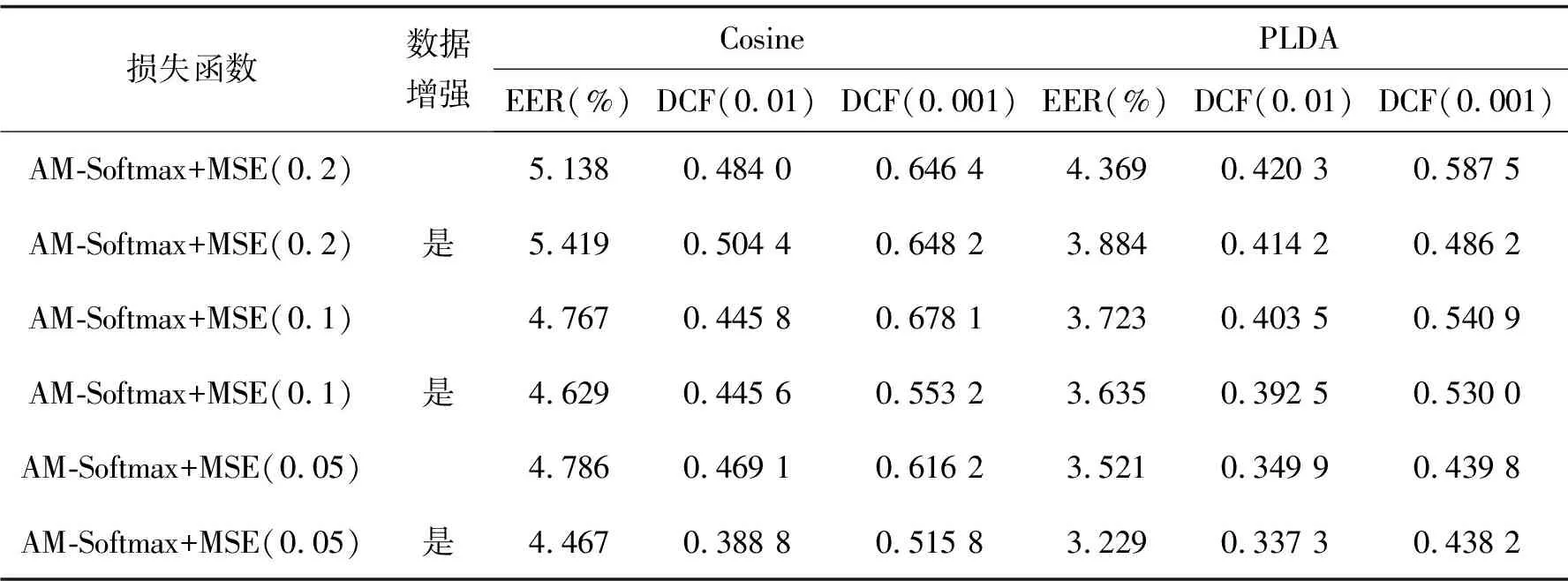
2.4 联合训练与模型集成的对比
2.5 与其他方法的对比
3 结 语
