基于MVSNet多视角立体深度学习的储罐在位体积测量方法研究
2023-02-15刘桂雄肖天歌陈国宇
刘桂雄,肖天歌,陈国宇,黄 坚,3
(1.华南理工大学机械与汽车工程学院,广东 广州 510641; 2.广州能源检测研究院,广东 广州 511447;3.广州计量检测技术研究院,广东 广州 510663)
0 引 言
储罐容量一般具有标称值,对于具有精度要求的储罐,在完成制造后需测其体积,并通过计量获得实际储罐容量。储罐体积测量准确性直接关系民生计费的公平性与过程控制的准确性[1]。常见的储罐体积测量方法包括几何法(通过手动测量几何尺寸计算体积)、容量法(通过容量比较计算储罐体积),耗时较长、人力工作量较大。在储罐体积需快速测量或偏远、高危等特殊场合,由于已安放的储罐体积较大、移位测量困难等限制,传统的储罐体积测量方法较难满足需求。因此,研究高效率储罐在位体积测量技术与方法,具有重要学术价值与实际意义。
通过立体视觉技术实现三维物体模型重建,是实现物体体积快速测量的重要途径。目前多视角立体视觉(multi-view stereo, MVS)技术主要包括经典MVS方法[2]、基于深度学习MVS方法[3],其中经典MVS方法已应用于各种户外场景。如文献[4]以精确的激光扫描三维模型为参照,采用豪斯多夫距离,指出基于图像序列的三维重建模型精度较高;文献[5]提出面向多视角立体匹配的三维点云去噪方法,可快速、准确去除不同尺度的噪声点。文献[6]采用基于运动恢复结构(structure from motion, SfM)的三维地形重建方法实现对户外模型地形测量,有效提高高程测量效率。文献[7]分析各种多视角图像三维重建方法的技术原理及相关软硬件平台,指出多视角图像三维重建方法具有数据获取成本低、获取点云精度高、三维重建质量高等优势。文献[8]应用摄影测量与SfM技术,建立堆场散装物料数字高程模型,生成堆场料堆分布图,实现料堆总体积等指标计算。文献[9] 采用基于曲率和基于点云距离的特征提取方法分别对目标物体信息进行提取,并对两种方法进行对比,引入基于边界点邻域特征的边界提取算法得到目标物体的边缘轮廓信息。文献[10]提出一种列车车轮三维结构光检测中的点云处理方案。结果表明,该文所提出的列车车轮点云处理方案能够实现对三维点云数据的处理,最终得到列车车轮的三维曲面模型与基准模型的标准偏差为1.768 mm,实现对于列车车轮的三维检测。在基于深度学习MVS方法方面,文献[11]构建MVSNet网络实现在2D图像特征基础上的摄影几何表达端到端深度学习,可适应不同数量的源图像输入。文献[12]构建深度学习网络并进行多视角立体匹配,预测每张视图对应的深度图,提高模型重建精度。文献[13]实现以体素为三维模型表示方式的深度学习多视图物体三维重建。可见,基于深度学习的MVS方法可自动学习图像高层、全局的语义信息,有助于提高镜面反射、纹理稀疏对象的重建效果。但MVSNet的输入包括源图像、参考图像,以及每一个图像的相机内参、外参,外参的输入给实际应用带来不便。
因此,实现储罐在位体积测量,需完成相机姿态计算、储罐三维重建、储罐体积计算等一系列内容。为此,本文提出一种基于MVSNet多视图立体深度学习的储罐在位体积测量方法。先通过集成增量式SfM相机姿态计算、MVSNet储罐-相机深度预测、基于表面法线扩散的储罐三维重建,获得储罐密集点云;再研究基于立体几何拟合的在位储罐体积测量技术,提高储罐各种曲面结构拟合准确度,实现储罐在位体积测量。
1 面向在位储罐体积测量的MVSNet深度预测多视图立体视觉方法
面向在位储罐体积测量的MVSNet深度预测多视图立体视觉方法,目标是获得更多的高质量三维点。图1为方法框架,主要包括:1)基于增量式SfM的储罐显著特征稀疏重建与相机姿态计算技术,通过关键点检测、关键点匹配与立体几何校验、结构运动重建等步骤,获得参考图中储罐显著特征以及所有图像的相机内参、外参;2)基于MVSNet深度学习技术,计算得到各个参考图像中储罐到相机的光轴距离;3)基于表面法线扩散的储罐三维重建技术,获得储罐体积测量关键结构的稠密三维点云。

图1 面向在位储罐体积测量的MVSNet深度预测多视图立体视觉方法框架

特征测量点Tn需符合模型要求条件是深度da、db为正,并且重射误差en不超过误差上限t。
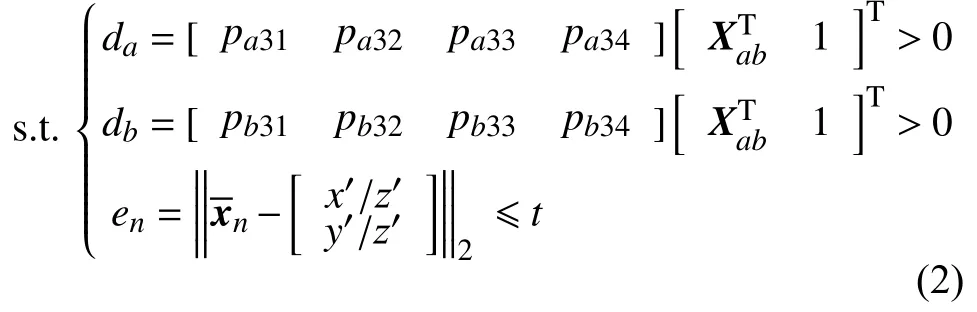
式中:
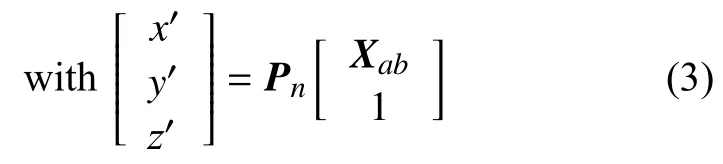

图2为基于增量式SfM的储罐显著特征点与相机姿态计算结果图。
图2 基于增量式SfM的储罐显著特征点与相机姿态计算
图3为储罐-相机深度预测MVSNet算法模型,输入是从不同视角拍摄的同一储罐的重叠图像、所有图像的相机参数,经过特征提取、正应性变换建立体积成本、深度图优化后,输出每个图像的深度估计。

图3 储罐-相机深度预测MVSNet算法模型
储罐-相机深度预测MVSNet深度学习网络模型,采用8个卷积层的2D CNN提取N个输入图像的深层特征并进行密集匹配;其中第3个、第6个卷积层的步长设置为2,将特征图分为1、1/2、1/4三种尺度。2D CNN输出是N个32通道1/4尺度特征图。
设参考图像I1、源图像和相机本体,对应于特征图旋转、平移为。通过可微分正应性变换,所有的特征图都被变形到参考相机的不同像平面上,形成N个立体特征卷。设n1为参考相机的主轴,正应性矩阵Hi(d)表示第i个特征图、深度d的参考特征图之间的坐标映射;Hi(d)为3×3矩阵。则有可微分正应性变换为

从立体特征卷Vi(d)到变形特征图Fi深度d的坐标映射可由平面变换x′~Hi(d)·x得到。

储罐-相机深度预测MVSNet算法模型的损失包括初始深度图、精炼深度图损失,通过深度约定真值、估计深度差的绝对值均值计算得到。此外,由于整个图像中深度约定真值不完整,只考虑深度约定真值存在位置。设有效的2地面真实像素集为pvalid,像素p的地面真实深度值为d(p)、初始深度估计为、细化深度估计为,则模型损失为
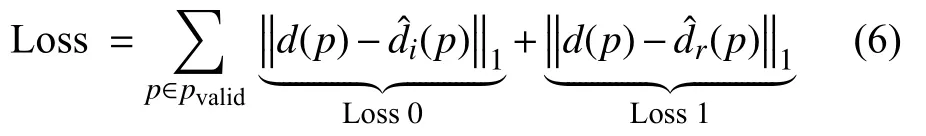
图4为储罐MVSNet算法模型预测的相机-储罐深度结果,再经过基于表面法线扩散方法[14]重构,可以得到储罐三维模型。

图4 基于MVSNet深度学习的储罐-相机深度结果图
2 基于立体几何拟合在位储罐体积测量方法
图5为基于立体几何拟合在位储罐体积测量方法流程图,具体流程为旋转储罐点云使地面与xOy平面平行,用平行于xOy平面圆形拟合储罐,积分计算得到储罐体积。其中x坐标表示宽度,y坐标表示深度,z坐标表示高度。

图5 基于立体几何拟合在位储罐体积测量方法流程图
设储罐点云Ptank,地面与xOy平面夹角为,则旋转后储罐点云Ptank-xOy为:

通过圆形拟合储罐时,采用基于法线信息和k邻域分布的双阈值约束点云边缘提取算法[15],最后积分每个拟合圆形,计算得到储罐体积。
3 实验研究
1)某三等标准金属量器。使用同一台工业相机,从不同角度采集该标准金属量器图像。应用本文面向在位储罐体积测量的MVSNet深度预测改进多视图立体视觉技术,重建得到储罐测量关键结构的稠密三维点云(图6),高质量点云数量245 980个,比经典COLMAP框架的点云数量分别增加15.6%,测量得到该标准金属量器体积2.025 m3,而已知该标准金属量器实际体积为2.000 m3,故应用本文技术测量该量器体积精度为98.77%

图6 三等标准金属量器稠密点云模型
2)某金属储罐。使用同一台工业相机,从不同角度采集该标准金属量器图像。应用本文面向在位储罐体积测量的MVSNet深度预测改进多视图立体视觉技术,重建得到金属储罐测量关键结构的稠密三维点云79 678(图7),比经典COLMAP框架的点云数量分别增加13.2%,测量得到该金属储罐体积为1.018 m3,而已知该金属储罐实际体积为1.025 m3,故该金属储罐测量精度为99.32%。
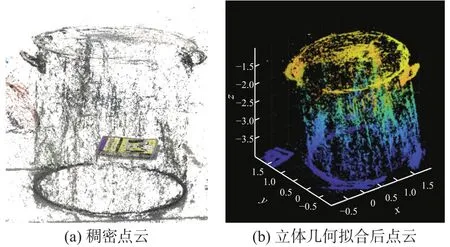
图7 金属储罐稠密点云模型
在实验上位机主要硬件为Intel i7-7820X CPU、NVIDIA GeForce GTX 1080Ti GPU×2;软件环境为Windows10、Python3.6、Pytorch 1.6、CUDA9.2、CUDNN 7.6.5。表1为本文与 COLMAP的 MVS点云重建主要指标对比表,本文方法提取到点云提取时间分别为28.2 min、29.3 min,比经典COLMAP框架分别增加15.6%、13.2%,重建时间缩短34.7%、39.2%。

表1 本文与COLMAP的MVS点云重建主要指标对比表
4 结束语
本文研究了一种基于MVSNet多视角立体深度学习的储罐在位体积测量方法,主要工作为:
1)创新性提出面向在位储罐体积测量的MVSNet深度预测改进多视图立体视觉方法,结合基于增量式SfM的储罐显著特征稀疏重建与相机姿态计算技术、基于MVSNet深度学习深度预测技术、基于表面法线扩散的储罐三维重建技术,获得储罐体积测量关键结构的稠密三维点云。
2)提出基于立体几何拟合在位储罐体积测量方法,旋转储罐点云使地面与xOy平面配准,基于法线信息和k邻域分布的双阈值约束点云边缘提取算法,拟合储罐圆形拓扑结构,积分计算得到储罐体积。
3)在两种储罐上进行初步实验,本文方法提取到的高质量储罐点云数量比经典COLMAP框架的点云数量分别增加15.6%、13.2%,储罐在位体积测量时间分别为28.2 min、29.3 min,满足储罐在位体积测量需求。
本文通过提取储罐外表面点云计算得储罐外体积,还需要研究储罐壁厚、附件等体积影响因素的补偿方法,从而实现储罐容积精确测量;此外,本文方法不仅可用于储罐体积测量,也可用于其他异形结构的体积测量,具有可推广性。
