基于时空信息融合的人体行为识别研究
2023-02-14于海港刘圣杰韩文静
于海港,何 宁,刘圣杰,韩文静
北京联合大学 北京市信息服务工程重点实验室,北京 100101
人体行为识别的应用场景越来越多元化,如在视频监控、人机交互等领域已广泛应用。但视频中的人体行为识别研究仍面临着时序信息捕获困难、参数量过大等问题。3D卷积和注意力机制方法的提出不仅能够提高提取网络高层语义等特征的能力,还能结合视频中的时序信息,为视频中行为识别问题提供有效的解决方法。
目前行为识别方法主要分为传统方法和基于深度学习的方法。传统的行为识别方法都是通过手动建立的基于时空兴趣点计算的运动描述,以时空关键点、密集轨迹方法等为代表。传统方法对于简单的图像分类是有效的,但是依赖于人工分析图像特征,面对复杂的场景难以解决识别问题。相比于传统方法,深度学习方法可以识别复杂结构,具有良好的特征提取能力和泛化能力。基于深度学习的行为识别方法可以分为三维CNN和二维CNN的结构。2014年Simonyan等人[1]提出的双流网络是二维卷积神经网络中的典型代表,该方法提出了将时间和空间信息单独提取再融合的思想,显著提高了识别的精度,但是相对独立的两个网络也阻碍了信息的交流,难以有效结合各个维度的信息。Tran等人[2]提出C3D网络,证明了三维卷积网络对于时空特征提取的有效性,通过增加一个时间维度的方式帮助捕捉时间信息。Feichtenhofer等人[3]提出X3D网络,之前的三维网络基本上都是在二维网络上对时间维度进行扩展,但时间尺度的扩展不一定是最佳的选择,X3D从输入的帧长度、帧率和网络的宽度等方面逐一进行扩张,得到最好的扩张模型。然而三维网络随着维数的增加,参数量也暴涨,导致计算速度缓慢。
近年来,注意力模型被广泛应用在时序动作识别,Roy等人[4]提出了SE注意力机制,通过压缩空间,针对通道进行建模的方式把重要的特征进行强化以达到提升准确率的效果。Ying等人[5]针对现有通道注意力机制对各通道信息直接全局平均池化而忽略其局部空间信息的问题,提出了矩阵操作的时空交互和深度可分离卷积模块。Cho等人[6]引入自注意力机制使网络具备提取高阶长期语义信息的能力。Wang等人[7]设计了运动模块提取视频中的动态信息。受上述方法的启发,为了解决网络对于时空信息捕获和参数量问题,本文首先设计了一种混合注意力机制,不同于SE等注意力机制仅对空间和通道等单一维度建模,引入三维卷积层同时对时间和空间进行建模,结合独立的通道注意力机制,每次计算都能够同时从时间、空间和通道三个维度进行信息的筛选。其次结合残差思想提出了一种时空残差卷积模块,在残差结构第一层嵌入上述混合注意力模型,减少冗余信息进入下层网络,时空残差结构通过本文的混合注意力机制引入少量的三维卷积层,有效捕捉时空信息,避免了传统三维卷积网络中参数量的暴增问题,能够灵活地嵌入到二维网络中。
1 相关方法
1.1 双流网络
CNN是现在基于视频中行为识别的一种先进的方法。然而,视频中的人类行为分析包括视频帧中时序关系的理解,把CNN用于捕捉这些关系还比较困难。双流网络增加一组独立的深度卷积神经网络捕捉时序信息,两组独立的深度卷积网络同时工作,即空间流(spatial stream ConvNets)和时间流(temporal stream ConvNets),可以在关联帧中捕捉动作信息。双流网络的网络结构如图1所示。时间流网络从相邻的几帧图片中提取光流信息,经过卷积操作提取高层特征,最终应用softmax函数计算时间流预测分数。空间流网络采用单帧的图像作为输入,计算空间流的预测分数。两个网络单独训练,最后将两个网络的结果进行融合得到最终的预测结果。

图1 TSN网络Fig.1 Temporal segment network
双流网络使用帧之间密集光流信息有效结合时空信息,提高了网络的性能。2016年Feichtenhofer等人[8]对双流网络做出了改进,提出了网络的最佳融合位置。Liu等人[9]提出将运动历史图(motion history image,MHI)和RGB图像作为输入信息,分别送入不同的基础网络进行训练、融合,根据融合结果计算出最终的预测分数。现在双流网络已经成为行为识别的主流方法之一,被广泛应用于行为识别任务。但是,上述双流网络通过相邻帧间的光流信息来提取时序信息,无论是空间流还是时间流都只是对视频中的某一帧或者某几帧操作,对于视频中的上下文联系是有限的。因此传统的双流网络难以处理时间跨度比较长的视频序列。2016年Wang等人[10]提出TSN(temporal segment networks)网络结构,有效解决长范围时间段的视频行为识别问题。
TSN的网络结构如图1所示,将整个视频分成K个小片段,对这些小片段进行随机采样,每个小片段中包含一帧RGB图像和两个光流特征图,这就是文中提出的稀疏和全局时间采样策略。将采样结果分别送入双流网络中进行训练,将两组训练结果输入到融合函数(文中用的均值函数)中得到预测结果。TSN建模方法如公式(1)所示:
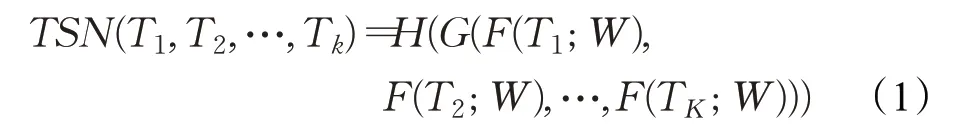
其中,(T1,T2,…,TK)代表视频片段,从视频中随机采样得到;F(TK;W)代表参数为W的神经网络,通过函数F返回每一个片段的得分;G表示共识函数,结合多个片段的得分推算出类别假设的共识结果,H使用softmax函数,通过共识结果预测视频中的行为类别。
1.2 残差网络
ResNet是由He等人[11]提出的一种高性能的神经网络。ResNet主要利用残差的思想,残差结构如图2所示。传统网络大都存在传递信息丢失、耗能,以及梯度消失、爆炸的情况。这会导致很深的网络无法进行有效训练。ResNet网络的提出在一定程度上解决了这些问题,它将信息绕过部分卷积结构直接传入到输出(原论文中提出的残差块结构),减少了信息的丢失,整个网络只需要学习差别的部分。目前常见的有ResNet18、ResNet34、ResNet50、ResNet101和ResNet152五种ResNet网络结构,这几种网络结构的主要区别在于使用的残差块及其数量不同。如表1所示是ReNet101网络结构。
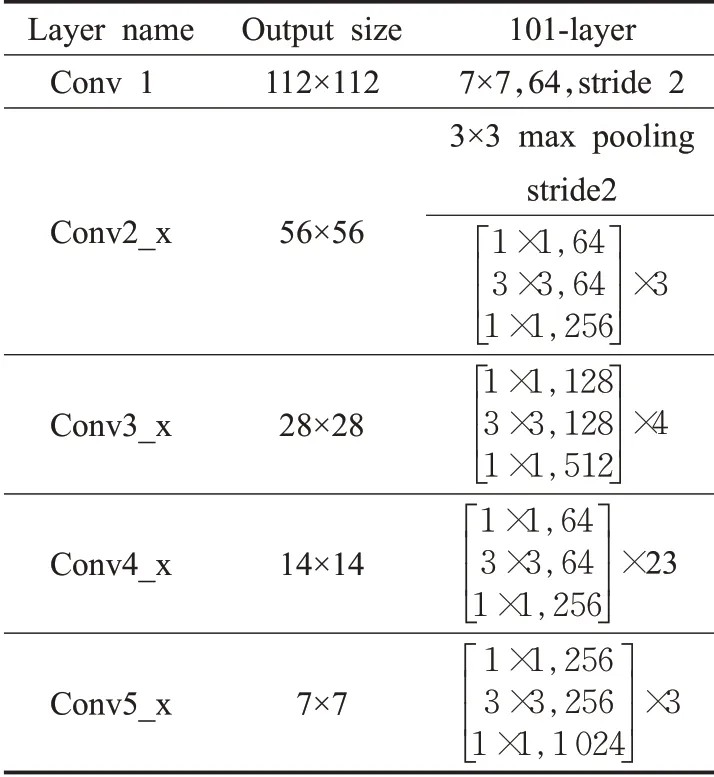
表1 ResNet101网络结构Table 1 Resnet101 network architecture
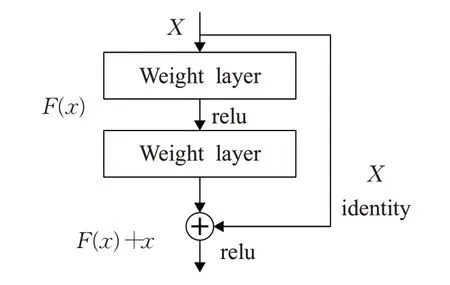
图2 残差结构Fig.2 Residual structure
2017年Xie等人[12]提出了ResNet的改进版之一:ResNext网络,它是ResNet和Inception网络[13]的结合版,其核心就是残差结构和分组卷积的结合。众所周知,想要提升模型的表现,最简单也是最直接的方法就是增加模型的深度和宽度,但是会带来训练困难和模型复杂度增加的问题,所以Xie等人考量模型的另一个维度:基数(cardinality),在不增加模型复杂度的情况下,提高了模型的学习能力。Gao等人[14]提出Res2Net残差结构,将原ResNet结构的单个3×3卷积替换为多组3×3卷积并且在最后加入了SE结构。在不增加计算负载的情况下,增加了特征提取能力。但是SE结构只考虑了通道维度,所以本文结合时间、空间和通道信息设计了一种时空残差结构。
2 本文方法
2.1 双流时空残差卷积网络
本文采用TSN模型结构,以ResNet代替原TSN模型的基础网络。ResNet的残差结构能够很好地抑制较深的网络在反向传播时的梯度弥散情况,更适合用于视频的特征提取,为此本文提出了时空残差模块。视频相比图像来说含有更加丰富的信息,但是视频序列中的冗余信息量非常大。为此在时空残差模块中嵌入时空注意力机制和通道注意力机制,每次信息输入残差结构前先对信息进行筛选,通过权重分配抑制重复、无效信息。具体来说,在空间维上不同的空间信息被分配不同的分数,分数的大小决定了信息的重要程度。在通道上保证特征通道数不变,将空间维度进行压缩,评估每一个通道的重要程度,通过评估结果为每个通道生成权重,将该权重应用于原来的每个特征通道,学习每个通道的重要性,其本质在于建模各个特征的之间的重要性,进行权重分配。通过权重分配使模型能够自适应地将更多的注意力集中在重要区域,为后续进一步的特征提取提供了保障。将筛选后的信息输入残差结构进一步提取高层特征,提高网络的特征提取效率。网络总体架构如图3所示。首先从视频片段中提取RGB图像和光流图像,送入双流时空残差网络,经过一个7×7的卷积层和四个残差层提取深层次特征,每个残差层分别包含3、4、23、3个残差结构。最终将每个视频片段的结果加权融合得到行为类别。改进后的TSN模型沿用原TSN模型的建模方式,如公式(2)、(3)所示:
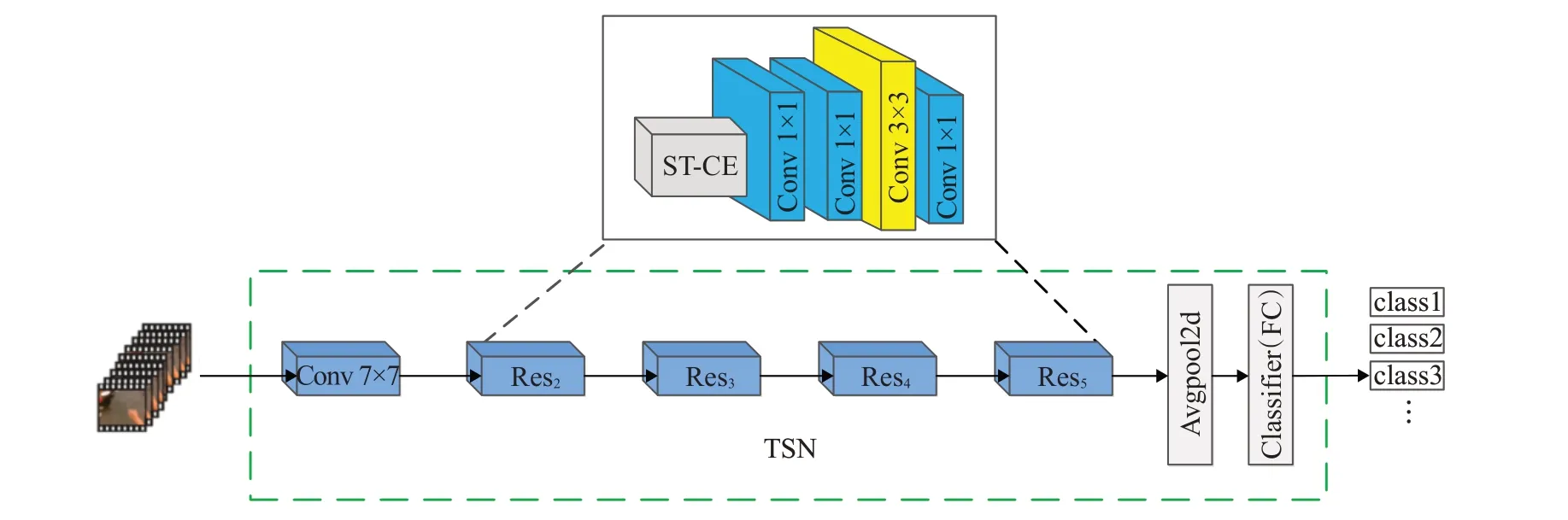
图3 双流时空残差卷积网络Fig.3 Two-stream spatio-temporal residual convolutional networks
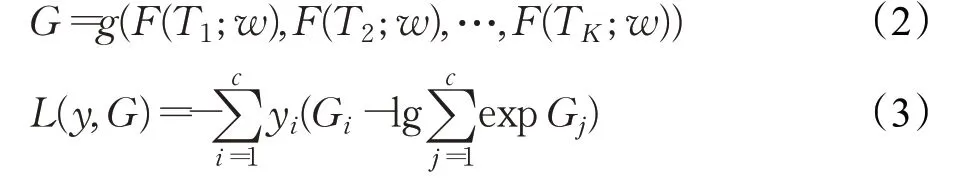
其中,(T1,T2,…,TK)代表视频片段,从视频中随机采样得到;F(TK;W)代表每个视频片段T在参数为W的神经网络上进行训练,最终返回每一个片段的得分;通过段共识函数G结合多个片段的得分推算出类别假设的共识结果,结合交叉熵损失(cross-entropy loss)得到最终的损失函数L。C为总类别数,yi代表第i类的真实值。
对于时间段网络,本文利用多个片段使用反向传播算法优化参数W,W关于损失值L的梯度推导如公式(4)所示:

其中,K表示TSN使用的视频片段数。多段视频一起通过反向传播算法优化参数,确保TSN模型是从整个视频中获取参数信息而不是其中一个视频片段,这种方式的好处是网络的参数可以结合整个视频进行参数优化。
2.2 ST-CE模块
2.2.1 时空注意力机制
许多动作使用单针图像就能判别类别,但是有一些动作是依赖于时序信息的,仅从空间单一维度建模难以准确地识别动作类别。传统的二维卷积只在空间上完成卷积和池化,其卷积结果是一张二维的特征图,多通道的信息被压缩,时间信息完全丢失。类似的,许多融合模型在时间流网络将多帧图像作为输入,但是通过一个卷积层后同样丢失时间信息。三维卷积已经被证实具有良好的时空信息提取效果,由于3D卷积和3D池化操作,卷积后输出依旧是3D的特征图,不仅携带外观特征而且还有运动信息,也就是说二维卷积仅针对单一维度建模对视频进行操作的方式,只是对视频的每一帧图像分别利用CNN来进行识别,通过这种方式得到的识别结果并没有考虑到时间维度的帧间运动信息,而使用3D CNN能够逐渐集中空间维度和时间维度的信息,更好地捕获视频中的时间和空间的特征信息。但是传统的三维网络将二维卷积扩展到三维卷积,无一不受参数量倍增问题的困扰。为了避免参数量暴涨等问题,本文引入少量三维卷积设计了时空注意力机制,同时提取时间、空间维度特征。
时空注意力结构如图4所示。首先对输入信息进行池化操作得到全局通道特征F,然后改变F的维度并将其送入三维卷积层中提取时空信息,如公式(5)所示,F*是F经过3D卷积层提取后的时空特征。
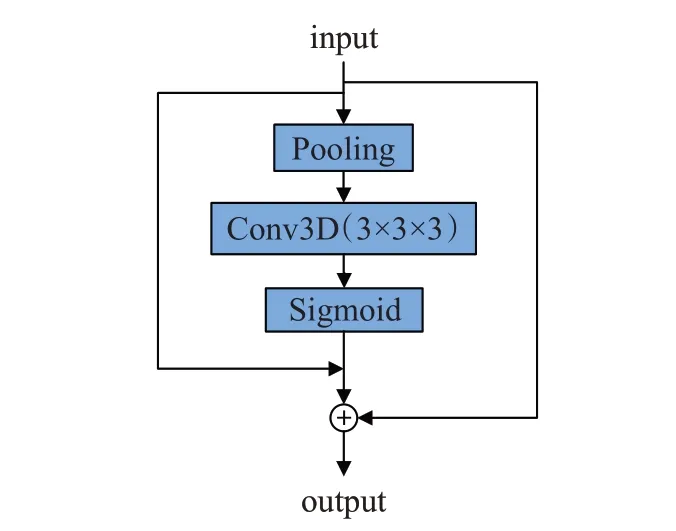
图4 时空注意力模块Fig.4 Temporal and spatial attention module

特征F*包含了时空信息,经过激活函数Sigmoid函数计算得到包含时空信息的特征向量L。如公式(6)所示:

最后通过与原始输入特征逐点相乘的方式为每个像素点分配权重。如公式(7)所示:

每一个输入X都能通过向量L感知到时空信息的重要程度。相比传统的三维卷积,本文方法的计算效率更高。
2.2.2 通道注意力机制
SE注意力机制是典型的通道注意力机制。SENet主要关注通道之间的关系,通过对通道的压缩和激活学习不同通道特征的重要程度,抑制不重要的信息。
本文的通道提取机制是基于SENet的思想设计。不同于图像中的目标识别任务,对于视频中的人类行为来说,视频的时序信息非常重要,所以本文增加了1D卷积加强时间上的关联度,得到更好效果的通道特征。通道注意力结构如图5所示,具体来说先将输入图像进行空间平均池化得到全局空间信息的特征F,如公式(8)所示:
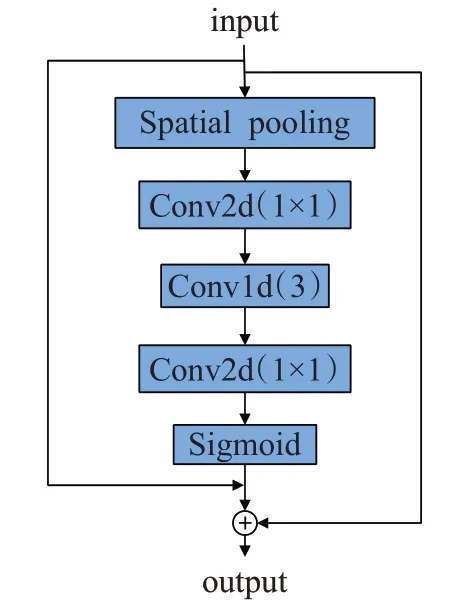
图5 通道注意力模块Fig.5 Channel attention module

特征F通过3个卷积层提取特征,如公式(9)所示,其中A是大小为1×1的二维卷积核;A1是大小为3的一维卷积核,这里增加一维卷积的目的是增强通道在时间维度上的依赖。

将F3经过激活函数Sigmoid函数计算得到特征向量L,将原始输入特征X点乘L得到包含通道特征的参数Y。如公式(10)、(11)所示:

2.3 时空残差结构
随着网络层数的增加,网络会出现退化的现象,浅层的网络会比深层网络取得更好的结果,并且难以有效地融合时间和空间信息。所以本文设计了时空残差结构,如图6所示,其中ST-CE模块由上述时空注意力机制和通道注意力机制两部分组成。两部分独立进行训练,将训练结果融合共同作用于网络。如公式(12)所示:

图6 时空残差结构Fig.6 Spatio-temporal residual structure

其中,Y1和Y2为通过时空和通道机制得到的包含时空特征的参数,N表示初始网络层。
传统的残差结构通过映射将底层的特征传到高层,避免了信息的丢失,但是大量的信息冗余无法避免,而且这种直接映射关系更多的是传递空间信息,缺少时序信息,所以本文将ST-CE模块嵌入残差结构的第一层对上层信息进行筛选。通过计算过滤视频帧间的冗余信息,将有效的时间、空间信息送入下一卷积层提取特征信息。改进后的残差结构每一次传递的信息都是经过过滤后包含了时间、空间和通道三方面的信息,实验证明时空残差结构有效解决了二维CNN的局限性。
3 实验结果与分析
3.1 参数设置
本文基于PyTorch实现TSN模型,在CUDA 10.1、单GPU下进行,本文使用小批量随机梯度下降算法学习网络工作参数,其中批量大小设置为256,动量设置为0.9。本文用ImageNet[15]的预训练模型初始化网络权值。实验开始设置一个较小的学习速率。对于空间网络,学习速率初始化为0.001,每2 000次迭代减少到1/10,整个训练过程在4 500次迭代时停止。对于时间网络,初始学习率为0.005,经过12 000次和18 000次迭代后学习率降至1/10。最大迭代次数设置为20 000次。在数据处理方面,使用了位置抖动、水平翻转、角切和尺度抖动等技术。对于光流和扭曲的光流的提取,本文选择了在OpenCV中使用Zach等人[16]提出的光流算法。
3.2 数据集
本文的实验遵循原始的评估方案:训练、测试和验证分割并取其平均精度。实验统一在UCF101数据集上进行验证。UCF101是动作识别数据集,从YouTube收集而得,共包含101类动作。其中每类动作由25个人做动作,每人做4~7组,共13 320个视频,分辨率为320×240,共6.5 GB。在动作的采集上具有非常大的多样性,包括相机运行、外观变化、姿态变化、物体比例变化、背景变化、光纤变化等。101类动作可以分为5类:人与物体互动、人体动作、人与人互动、乐器演奏、体育运动。
3.3 实验结果分析
本文将模型在UCF101数据集上进行测试,训练过程的准确率和损失结果的变换趋势,如图7、图8所示;与现在主流行为识别模型的结果对比如表2所示。相比于传统的二维、三维卷积网络[2,8,10,16-17],本文方法分别提升了9.9、2.6、0.9、2.0和0.6个百分点。本文的双流时空残差网络结合整段视频,更好地发掘、利用视频所包含的信息,得到了视频级的预测结果。采用扭曲的光流场作为新的输入模式抑制了背景运动,使网络更专注于视频中的人物。相比于传统的二维卷积网络,本文的时空残差结构能够对二维网络中每层输入的信息自适应地进行提纯。通过时空注意力机制和通道注意力机制的结合使用,同时结合时间、空间和通道三个维度的信息对输入的不同部分分配不同的权重,协助网络捕捉重要信息。相比于其他三维卷积结构,仅在残差结构中加入了少量3D卷积层,减少了由于3D卷积操作带来的计算量问题。能够灵活地嵌入到二维网络结构中,并且实现端到端的训练。加入ST-CE模块前后可视化结果如图9所示,红色区域代表图像中识别结果影响更大的区域。通过观察可视化结果可以看出未加入ST-CE模块前包含了过多的背景信息,加入后红色区域集中在目标关键位置。由此可见通过ST-CE模块有效抑制无用信息,使网络专注于有效区域上。综上,通过本文的双流时空残差网络提升了网络时空信息的融合能力,更适合解决视频序列的识别问题。
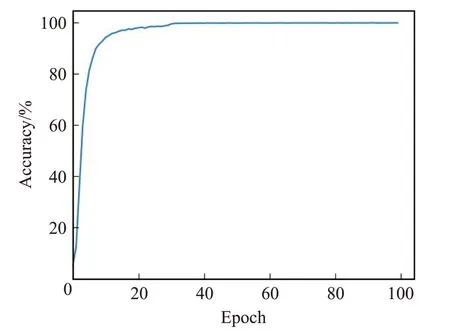
图7 在UCF101上的准确率变化曲线Fig.7 Accuracy curve on UCF101

图8 在UCF101上的Loss变化曲线Fig.8 Loss curve on UCF101

表2 各模型在UCF101上的结果Table 2 Results of each model on UCF101

图9 注意力机制可视化热力图Fig.9 Visualized heat maps of attention mechanisms
其次,本文将ST-CE模块与SE和CBAM[19]注意力机制分别加入到网络中进行对比,结果如表3所示。相比之下ST-CE模块对于网络整体效果的提升优于SE和CBAM模型,验证了时空残差模块对于二维卷积网络时空信息捕捉效果。主要原因是本文的模块引入了3D卷积层。不同于SE等注意力机制仅对通道、空间等单一维度建模,3D卷积操作因其增加了时间维度,相比于2D卷积能够更好地结合时序信息进行特征提取,能够同时结合时间和空间信息,而包含了时序信息的特征对于基于视频的动作识别任务有更好的契合度。
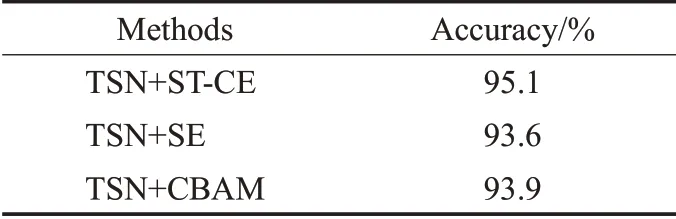
表3 不同注意力机制的对比Table 3 Contrast of different attention
3.4 消融实验
为了验证STE和CE模块的提升效果,本文将时空注意力模块和通道注意力模块单独加入到ResNet残差块中进行对比,如表4所示。其中FLOPs代表浮点计算量,在相同条件下,每个模块都能在增加较少计算量下提高性能。除此之外,对网络参数量进行了对比,相对于TSN网络来说,STE和CE只引入了1.9×105和2.39×106的额外参数,对于整个网络而言计算负担并没有增加太多,但是分别在UCF101数据集上提升了0.6和0.2个百分点的准确度。相比之下时空注意力模型对结果的提升更大,说明3D卷积对于网络时空特征的提取效果更显著。综合上述分析,STE和CE均对网络性能提升有所帮助,将STE和CE结合使用效果最佳。
4 结束语
本文提出了一种有效融合时空信息的双流时空残差网络。主要为了解决二维CNN对于视频中时空信息融合困难的问题。为此,本文提出了时空残差模块,通过引入三维卷积层和注意力机制融合时空信息,结合稀疏时间采样策略保证对整个视频的学习效率。该时空残差模块可以嵌入到二维卷积网络中结合时间、空间和通道信息进行特征提取,方便灵活。在UCF101数据集上进行实验,结果表明本文方法能够显著提升二维CNN的时空信息捕获能力。在未来,人体行为识别的场景越来越多元化,复杂的场景将给识别任务带来更大困难,Yuan等人[20]提出了一种特征迁移的方法给了本文以启发,将会继续研究基于时空信息的人体行为识别方法,以期实现在更复杂的环境下以更少的参数量达到更高的动作识别准确率。
