基于多层级新闻的股价预测与交易策略研究
2023-02-14田嘉祺毛元丰
龙 文,田嘉祺,毛元丰
中国科学院大学 经济与管理学院,北京 100190
随着国民经济的发展和金融市场的完善,越来越多的人开始进行金融投资,其中股票成为重要投资工具。如何根据已有信息判断股价趋势并进行相应的交易操作是获得超额收益的关键。按来源,信息可以分为内幕信息和公开信息,利用内幕信息从事证券交易活动违反法律法规,假设市场中不存在内幕交易,那么信息的重要来源之一就是公开的财经新闻。
学术界关于新闻对股价影响的研究已有50年历史,很多研究都证实了新闻对股票价格和股票收益存在影响[1-6]。新闻可以被划分为多个层级,如公司新闻、行业新闻和市场新闻[7],其中市场新闻和行业新闻属于共性信息,公司新闻属于特性信息。研究由早期对市场新闻和行业新闻的关注,逐渐转向对个股新闻的关注,Durnev等[8-9]认为,股价变动与市场平均变动存在的较大差异主要是由个股信息导致的,Li等[10]认为,媒体对某一公司基本信息的报道会显著增加投资者的交易量;汝毅等[11]认为,违规公司的事前新闻报道存在不对称性的双向声誉溢出效应。近年来,国外学者开始关注多个层面的财经新闻,Shynkevich等[12]使用个股新闻、行业新闻等五种类别的新闻进行了系统性研究,发现基于五类新闻的预测在预测精度和交易回报率上表现最优。但国内学者很少对新闻层次进行区分,研究集中于个股新闻[13-14],或者按时间段或关键词[15-17]爬取全部新闻。虽然有研究划分了个股新闻与行业新闻,如徐伟等[18]对比个股新闻和行业新闻对股价的影响,发现个股新闻的影响更大,但研究对象仍是单层级的新闻,缺少多层级新闻的综合利用。
从研究方法上看,股价预测的研究起步较早,计量预测模型[19-21]被广泛应用。近年来,文本挖掘和机器学习在股价预测研究中的应用增多,随着一些技术难题不断被解决,得出的结论相对更准确,预测质量得到明显提升,其中支持向量机(support vector machine,SVM)被广泛使用,其在克服维数过大和过度拟合学习方面具有优势。Kim[22]基于技术指标利用支持向量机进行股价预测。黄进等[23]用结合了依存句法支持向量机预测金融领域的的舆情。戴德宝等[24]构建上证投资者情绪综合指数,使用支持向量机预测股指走势。SVM有多种核函数,针对如何充分利用各种核函数的特点以提高学习效果这一问题,多核学习模型产生并成为核方法研究的热点。与SVM相比,多核学习(multi-kernel learning,MKL)模型的灵活性更强,理论和实证研究已经证明其在决策函数的可解释性、核函数的选择、预测精度的提升等方面具有优势[25-26]。Shynkevich等[12]以及Nam等[27]基于MKL模型训练新闻文本,对股价做出有效预测。
根据以上文献,新闻对股价存在影响,且被认为是一项很重要的信息源并用于股价预测。而新闻具有多个层级,但国内学者很少对其关注。基于此,本文从新闻层级性入手,研究多层级新闻体系对股价趋势的预测作用,并以此建立交易策略进行模拟交易判断其对市场交易行为是否具有实际价值。同一经济体下同一行业的公司面临的法律环境和市场供需环境相同,信息一致,且经营情况具有强相关性[28]。因此,本文在个股新闻的基础上加入子行业新闻和行业新闻构建多层级新闻集。在方法方面,选择MKL模型以更好地利用各层级新闻包含的信息。
本文可能的贡献有两个方面:一是多层级新闻体系的构建,本文用个股新闻、子行业新闻和行业新闻构成一个完整的立体新闻系统,补充了该领域的国内研究;二是结合了新闻信息集、模型两个维度,通过实验发现引入多层级新闻的MKL模型预测准确率最高,且其在实际投资活动中具有重要价值。
1 研究设计
1.1 数据获取
本文选择医疗行业为样本行业,主要原因如下:一是该行业较为典型,是当前也是未来的热点行业之一;二是该行业有规范的行业及子行业划分标准,便于构建多层级新闻体系;三是该行业新闻报道数量较为充足,能够满足研究的需要。本文以全球行业分类标准(GICS)为基础,参考证监会行业分类标准,将医疗行业划分为医疗保健用品、保健护理服务、生物科技、制药这四个子行业。
本文从医疗行业中选取15支新闻数量最多且覆盖全部子行业的股票作为研究样本,样本股票情况见表1。

表1 样本股票Table 1 Sample stocks
数据包括股价数据和新闻数据,研究期间为2013年8月至2017年3月。股价数据包括样本股的开盘价与收盘价,用以判断股价趋势,数据来源为wind。新闻数据是利用爬虫程序在新浪财经网站爬取的样本股的个股新闻及当天对应的子行业新闻及行业新闻,爬取内容包括新闻的标题、日期、正文等,共获得18 000余条个股新闻、近10 000条子行业新闻和34 000余条行业新闻。由于我国股市在交易日的15点停盘,因此本文认为15点之后的新闻对当天的股价不产生影响,将本交易日15点之后的新闻归入下一个交易日的新闻文本之中。周末、节假日等休市日的新闻,使用同样的方法进行处理。
1.2 文本预处理
本文使用Python中文分词工具“Jieba”对爬取的新闻文本进行分词处理分词,提取文本对应的特征词条。分词后导入停用词词典,筛掉停用词,降低噪音影响。之后,运用TF-IDF方法提取特征向量并计算权重,该方法常用于文本挖掘。TF为词频,用于计算该词描述文档内容的能力;IDF为逆文档频率,用于计算该词区分文档的能力,两者的表达式如下:

其中ni,j是词ti在文件dj中的出现次数,∑knk,j是文件dj中所有词汇出现次数的总和。

其中,|D|是语料库中的文件总数,|{j:ti∈dj}|表示包含词语ti的文件数目,为防止分母为0,通常使用(1 +| {j:ti∈dj}|)。

IF-IDF为TF与IDF的乘积,某文件内的高词语频率和该词语在整个文件集中的低文件频率可产生高TF-IDF值,即某个词对文章的重要性越高,它的TF-IDF值就越大。
1.3 模型选取
在提取每篇新闻的特征词频并计算权重后,以当日股价变化作为分类标签,对每支股票同一天的新闻集合进行训练,训练模型为多核学习(MKL)模型。
1.3.1 支持向量机
SVM是90年代中期发展起来的基于统计学理论的一种二类分类器,它与传统统计方法的不同在于它以最小化结构风险为原则,在不增加经验风险的前提下,将置信区间的范围最大限度地缩小,同时保证样本预测误差最小。
SVM的具体原理是在n维空间中找到一个分类超平面,从而将空间上的点分类,分类依据是最大化预测点距超平面的距离,如果遇到线性不可分的情况,可以利用核函数将数据从低维映射到高维特征空间,将低维特征空间的非线性问题转换成高维特征空间的最优线性问题,特征空间由核函数来定义。另外,核函数可以在低维空间进行运算,避免了在高维空间中的复杂计算。根据泛函的有关理论,只要一种核函数K(xi,xj)满足Mercer条件,它就对应某一变换空间中的内积,即可用核函数替代内积,构造优化问题如下:

核函数的选取与构造是运用SVM解决实际问题的关键,目前研究中广泛使用三种形式的核函数,分别是线性核函数(line)、多项式核函数(poly)和高斯核函数(又称径向基核函数,简称rbf),表达式如下:
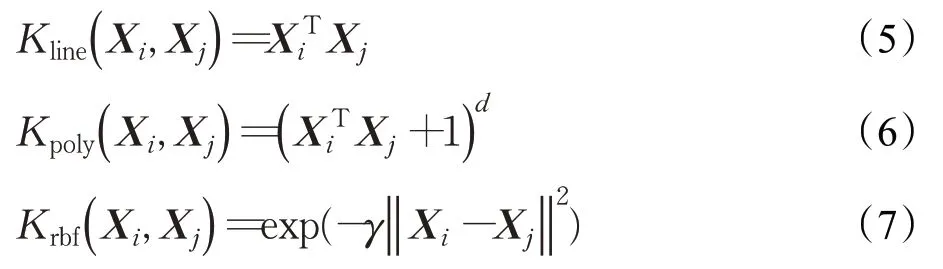
其中,Xi、Xj是低维特征向量,γ、r和d是人工设置的参数,d是一个正整数,γ是正实数,r是非负实数。
1.3.2 多核学习模型
多核学习模型是由核函数通过“积运算”或者“线性组合”的方式构造而成的。单核函数有局部性核函数和全局性核函数两类,其中局部性核函数学习能力强,泛化性能较弱,而全局性核函数泛化能力强,学习能力较弱,高斯核函数属于前者,多项式核函数属于后者。本文把这两类核函数结合起来,使用线性核、多项式核和高斯核的线性组合对样本进行训练,对每一个核也指定多组参数,将最优线性组合结果作为最终使用的模型。另外,与SVM不同,MKL模型加入学习权重这个变量,该变量也会影响训练精度,因此运用核函数可将特征空间中的数据表达问题转换成核权重的选取问题。三个基核函数表达式同式(5)~(7),多核学习模型见式(8):

其中,wj表示各基核函数的权重。
1.4 模型训练与分类器评估
本文根据股价涨跌为新闻打标签:如果价格上涨,那么当天的新闻被打上正标签,否则就打上负标签。将每支股票同一天的所有新闻作为输入,当日股价的涨跌作为标签,一同进入模型进行训练,其中80%的样本为训练集,剩余20%为测试集。
本文选择预测准确率作为评估分类器性能的标准,预测准确率用正确预测的样本占所有样本的比重表示,计算公式如下:

其中,TP表示标签为正样本,预测也为正样本的数目;TN表示标签为负样本,预测也为负样本的数目;FP表示标签为负样本,但预测为正样本的数目;FN表示标签为正样本,但预测为负样本的数目。
2 新闻对股价趋势的预测
2.1 个股新闻对股价趋势的训练
首先考察个股新闻的预测能力,运用SVM对个股新闻进行训练,预测准确率见表2,其中线性核函数的预测准确率为0.594,多项式核函数的预测准确率为0.608,高斯核函数的预测准确率为0.602,均大于0.5。由此可见,个股新闻对股价趋势的预测有一定的作用。
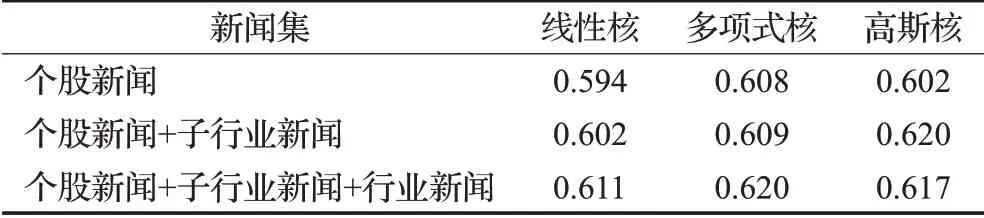
表2 基于不同新闻集各核函数的预测准确率Table 2 Prediction accuracies of kernel functions based on different news sets
2.2 多层级新闻对股价趋势的训练
2.2.1 基于SVM模型的训练
在对个股新闻进行训练的基础上,逐步加入子行业新闻和行业新闻进行训练,其预测准确率见表2。
由表2,对于同一新闻集,线性核的预测精度最差,多项式核最好,高斯核居中;逐步增加子行业新闻和行业新闻能提高预测精度,其中增加行业新闻对预测准确率的提升作用较大,增加子行业新闻对预测准确率的提升作用相对较小。
2.2.2 基于MKL模型的训练
考虑到各层级的新闻具有不同的内容和特征,本文分别运用不同的核函数训练多层级新闻集中每一层级的新闻,以考察使用多种核函数是否能提升预测准确率,预测准确率如图1所示,图中大立方体中的每一个小立方体代表新闻和核函数的组合,共有33=27组预测结果。图中包含27个立方体,代表了在多层级新闻集中利用三种核函数训练三个层级新闻,其颜色深浅代表预测准确率的高低,颜色越深表明该组合的预测准确率越高。
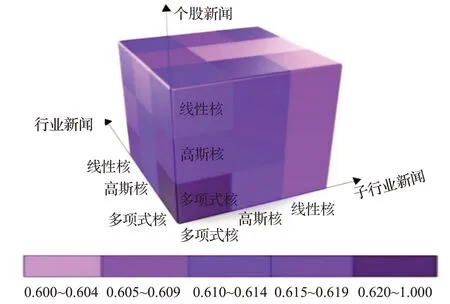
图1 基于多层级新闻的各核函数的预测准确率Fig.1 Prediction accuracies of kernel functions based on multi-level news set
由图1,从样本总体来看,三个层级的新闻均使用多项式核函数训练的预测准确率最高。虽然这个结果没有体现出采用不同核函数的优势,但进一步对具体股票进行分析发现,在15支样本股中,有9支股票(片仔癀、上海莱士、天目药业、爱尔眼科、中源协和、沃森生物、白云山、云南白药、中国医药)使用不同的核函数训练三层级新闻,比使用同一种核函数训练的准确度有明显提升。这在一定程度上映证了不同层级的新闻确实具有不同的特征,利用不同的核函数有区分地进行训练有机会提高预测准确性。
为更好地利用不同层级的新闻,本文进一步在各层级新闻内部使用MKL模型。由表2,在三种函数中,线性核函数表现最差,而线性核函数被证明是高斯核函数的特殊形式[29],因此此处使用的多核学习模型中只考虑高斯核函数和多项式核函数。以1%为步长逐渐调整不同层级新闻的比重以及不同层级新闻中两种核函数的比重,最优模型的预测准确率达到70.35%,该模型中各层级新闻和各核函数所占比例如表3所示。
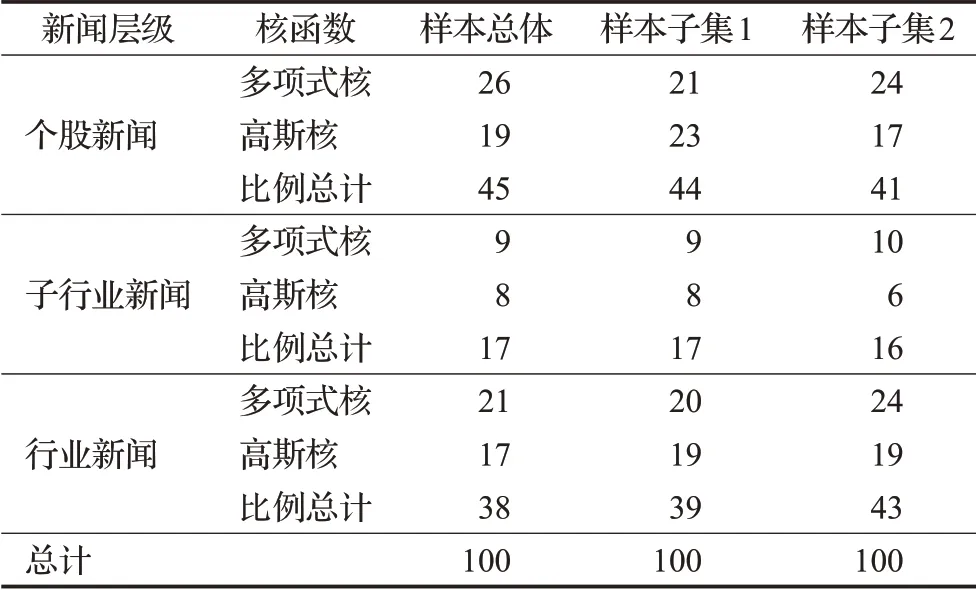
表3 多核学习模型中各层级新闻、各核函数的比重Table 3 Ratios of news and kernel functions in multi-kernel learning model 单位:%
由表3进一步看到,在新闻层级方面,个股新闻和行业新闻所占权重相对较大,合计超过80%,子行业新闻的权重相对较小;在核函数类型方面,多项式核函数的比重略大于高斯核函数。
将以上实验的预测准确率由小到大排序,如图2所示。不加*表示只使用个股新闻,加*表示使用个股新闻、子行业新闻和行业新闻构成的多层级新闻体系。无论使用何种核函数,相比个股新闻,使用多层级新闻集都能提升预测准确率,其中使用MKL模型可以使预测准确率得到最大程度的提升,这映证了MKL模型在实际应用的优势。

图2 所有实验的预测准确率Fig.2 Prediction accuracies of each experiments
2.3 稳健性检验
为检验多层级新闻集预测的稳定性,在15支样本股票中随机抽取两个子集,每个子集均包含10支股票:子集1包括同仁堂、片仔癀、上海莱士、中源协和、沃森生物、中恒集团、云南白药、仁福药业、康美药业和中国医药;子集2包括片仔癀、天目药业、中源协和、沃森生物、白云山、中恒集团、云南白药、复星药业、康美药业和海普锐,然后使用MKL模型对两个子集进行训练。
两个子集的最高预测准确率分别为71.12%和70.01%,表现较为稳定,其各层级新闻和各核函数比例如表3所示,总体来看,核函数和各层新闻的比例结构相似:多项式核函数比重略大于高斯核函数;个股新闻和行业新闻比重较大,各占40%左右,子行业新闻的比重较小,占20%左右。这一结果与2.2节对样本总体进行训练得到的结果基本一致。
表4对比了两个抽样子集与总体的预测准确率,在多层级新闻体系下,虽然三个集合在核函数分配比例存在一定差异,但预测准确率基本稳定在70%,相比表现最好的核函数——多项式核函数,MKL模型的预测准确率有明显提升。

表4 各样本下基于多层级新闻的预测准确率Table 4 Prediction accuracies based on multi-level news under each sample
3 基于多层级新闻预测的交易策略模拟
根据以上实证结果,各层级新闻都能在股价预测中发挥作用,用MKL模型训练多层级新闻体系的预测准确度最高。因此,本章将基于该提升作用,利用上述模型构建交易策略,并通过模拟交易,检验其在实际应用中的有效性。
3.1 样本内股票交易策略收益检验
本节首先考察新闻对未来股价趋势的预测能力随时间的变化情况,以便进一步建立交易策略。考虑到新闻对股价的影响时效相对较短,故本文只对比了当日新闻对当日股价趋势、后一日股价趋势及后两日股价趋势的预测准确率。针对多层级新闻体系,分别采用SVM模型和MKL模型进行训练,结果如表5所示。需说明的是,根据表5,三个基核中,多项式核函数的预测效果最好,故本节使用的SVM模型基于多项式核。
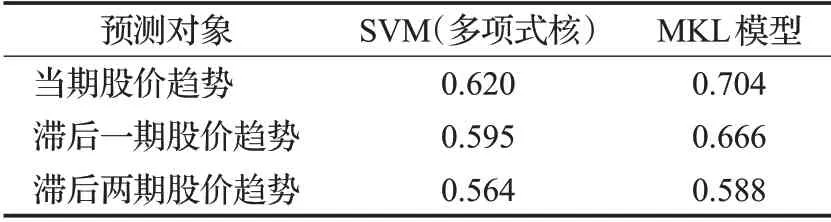
表5 当期新闻对多时期股价趋势的预测准确率Table 5 Prediction accuracies of current news on multi-period stock price trend
由表5,MKL模型的预测准确率优于基于多项式核函数的SVM模型。滞后期股价趋势的预测准确率均大于50%,与当期相比,滞后期股价趋势的预测准确率有一定程度的下降,滞后一期的准确率下降相对较小,不到4%,滞后两期下降较为明显。因此本节选用多核学习模型基于当天新闻预测滞后一天的股价趋势,并根据预测的股价趋势进行交易。若预测得出后一日股价上升,则在当日收盘时买入并在第二日收盘时卖出;若预测后一日股价下降,则不进行操作。因为该模型为理论模型,所以暂不考虑交易费用的问题。
为了更好地展示基于多层级新闻的MKL模型的优越性,每支股票都显示三种日均收益情况,分别是一直持有该股票的日均收益率,使用SVM(多项式核函数)模型训练个股新闻并按照预测结果操作的日均收益率,使用MKL模型训练多层级新闻体系并按预测结果操作的日均收益率,如图3所示。

图3 样本内股票交易策略收益率Fig.3 Return rates of stock trading strategy in sample
由图3,在不考虑交易费用的前提下,对样本内全部股票,使用基于个股新闻的多项式SVM模型和基于多层级新闻的MKL模型都能提升股票收益率。较买入并一直持有的策略,前者将日均收益率平均提升0.04个百分点,最高提升了0.17个百分点;后者将日均收益率平均提升近0.07个百分点,最高提升了0.18个百分点,即后者的提升能力高于前者,这表明在市场交易中,使用MKL模型训练多层级新闻预测股价趋势对获得较高收益有实际价值。
3.2 样本外股票交易策略收益检验
为进一步检验模型的有效性,在样本外本文选取四支同行业的股票(东阿阿胶000423.SZ、长春高新000661.SZ、福瑞股份300049.SZ、贵州百灵002424.SZ),将它们基于上述MKL模型进行预测,并根据预测的股价涨跌情况,运用3.1节的交易策略进行模拟操作。
四支样本外股票的收益率情况如图4所示,对于样本外股票,基于个股新闻的多项式SVM模型和基于多层级新闻的MKL模型的交易操作同样对收益率有提升作用,其中前者平均将日均收益率提升近0.04个百分点,最高提升了0.11个百分点;后者平均将日均收益率提升0.07个百分点,最高提升了0.12个百分点,与样本内股票相同,后者对收益率的提升程度更高。对比图3和图4发现,样本内与样本外股票日均收益率的提升程度非常接近,其中针对多层级新闻的MKL模型对收益率的提升程度更大,这说明在行业内MKL模型具有普适性,能够使样本实现最优预测的模型同样可以提升同行业样本外股票的收益率,这进一步说明了引入多层级新闻的MKL模型对交易策略构建的有效性。
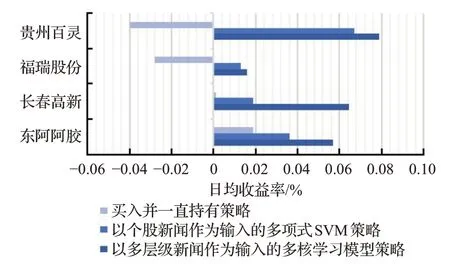
图4 样本外股票交易策略收益率Fig.4 Return rates of stock trading strategy outside sample
4 结论与展望
本文重点关注多层级财经新闻对股价趋势的预测作用,为充分地利用各层级新闻的特征,运用MKL模型展开实证研究,最终通过构建交易策略检验其在市场交易中的有效性。
本文发现不仅个股新闻能在股价趋势预测中发挥作用,对应的子行业新闻和行业新闻也能在股价趋势预测中发挥作用;不管是针对个股新闻中还是多层级新闻体系,对各核函数的比例进行分配,即形成MKL模型,都可以更好地学习和利用文本中的信息;使用多层级新闻体系和MKL模型可以最大化地提升预测准确率,相比只考虑个股新闻的SVM模型,引入多层级新闻的MKL模型将预测准确率提升了10%。此外,较买入并一直持有的交易策略和基于个股新闻的SVM的交易策略,基于多层级新闻的MKL模型的交易策略获得的收益最高,从而验证了该方法具有重要的实践价值。
以上研究结论对该领域的研究及投资决策具有重要意义,该领域研究中,要注重新闻的层级,全面地掌握各层级新闻,有区分地处理不同层级的新闻;投资者在进行投资决策时,有必要重视多个层级的新闻,并不只是局限于对目标企业新闻的搜索与关注。本研究还有以下不足之处:样本数量有限、所选行业有限等,希望未来得到进一步的完善。
