基于混合高斯-隐马尔可夫模型的动力电池实时热失控检测
2023-02-13廉玉波凌和平王钧斌
廉玉波,凌和平,王钧斌,潘 华,谢 朝
(比亚迪汽车工业有限公司,深圳 518118)
前言
电池安全作为消费者在购买电动汽车时最为看重的因素之一,对于电动汽车的综合竞争力具有至关重要的影响。而电池热失控的检测是电池安全功能的重要组成部分。热失控是电池安全研究的主要内容之一[1],其主要表现是当电池因超出额定工况使用,如过充、过放、高温、浸水等或由于挤压、尖锐物体刺破等外力作用,从而使动力电池在较短时间内温度快速升高,并在超过临界点后发生放热连锁反应,温度升高失去控制,最终引发火灾和爆炸等安全事故[2-3]。
目前针对动力电池热失控的检测主要包括基于气体检测的电池热失控检测技术、基于电池管理系统的电池热失控检测技术,以及基于算法的电池热失控检测技术。气体检测方法主要是利用气体传感器,通过检测电池内部电化学反应产生的二氧化碳及其他有害气体,从而实现早期的热失控预警[4-6]。基于电池管理系统(BMS)的电池热失控检测技术是通过对电池BMS 接收的参数进行监控,并通过指定简单的规则和阈值(如非工作状态电流阈值、温度阈值等),实现对电池热失控的早期检测[7-10]。而基于算法的检测是在基于BMS 检测的基础上,对接收到的信号进行数据处理,并通过算法计算得到当前电池的状态,其主要使用的方法包括有限元分析方法以及神经网络、支持向量机、卡尔曼滤波等机器学习方法[10-16]。
以上列出的方法均存在适用性较差的问题,尤其是机器学习方法虽然准确度较高,但无法处理变长数据,严重依赖历史数据训练。针对这些问题,本文中提出基于混合高斯-隐马尔可夫模型的动力电池实时热失控检测方法。
1 基本理论
1.1 隐马尔可夫模型
隐马尔可夫模型(hidden Markov model,HMM)是一种基于数据驱动的动态概率图模型[17],可以看作是混合高斯模型(Gaussian mixed model,GMM)在时间序列分析方面的扩展模型。GMM 模型通过多个高斯分布去拟合一个高斯分布无法拟合的数据,从而描述多峰数据的分布[18]。
对于K个高斯分布叠加而成的混合高斯分布,其概率密度函数为
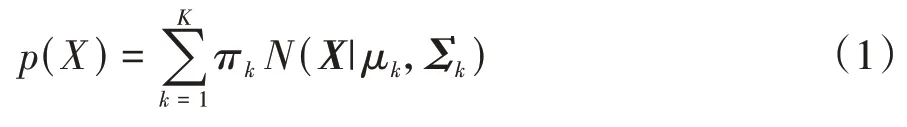
式中:μk和Σk分别为第k个高斯分布的均值和协方差矩阵;N(X|μk,Σk)是混合模型的第k个分量,πk是该分量的权重,且满足。
动力电池的热失控过程可以看做是一个高斯混合随机过程,并可以由K=3 个高斯分布表示3 种安全状态:安全状态Z1、有风险状态Z2、热失控状态Z3,如图1所示。
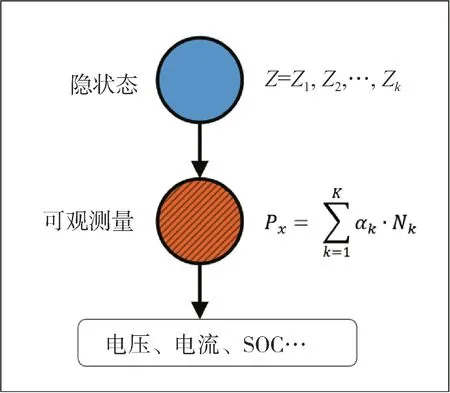
图1 热失控的高斯混合模型
但高斯混合模型没有引入时间维度,只能分析某一个时刻的状态或分析无时间参数的状态量,因此不适用于时间序列分析建模的任务。可以通过给高斯混合模型的隐状态增加马尔可夫性的状态转移过程,构成应用于时间序列分析的隐马尔科夫模型。
隐马尔科夫模型基于如下3个假设。
(1)马尔可夫假设,即状态构成1 阶马尔可夫链:
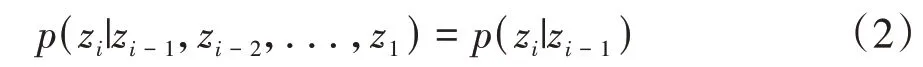
(2)齐次性假设,即状态的转移与具体时间无关:

(3)观测独立性假设,即观测变量仅与当前状态有关:
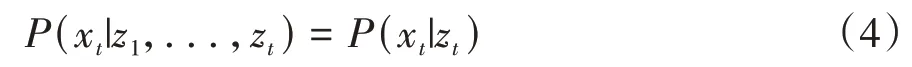
隐马尔科夫模型由两个随机过程组成,分别是状态转移过程和观测过程。状态转移过程无法被观测,只能通过输出的可观测序列推断得到。观测过程是指系统处于状态zt的情况下,系统表现出的可观测变量为xt的过程。在满足观测独立性假设时,隐藏的状态和可观测变量之间存在发射概率P(xt|zt),对应每种隐藏状态和每种可观测变量的发射概率可以用混淆矩阵B表示。对于一个HMM 系统,可以用λ={π,A,B} 表示模型中的所有参数,其中π表示模型的初始状态,如图2所示。
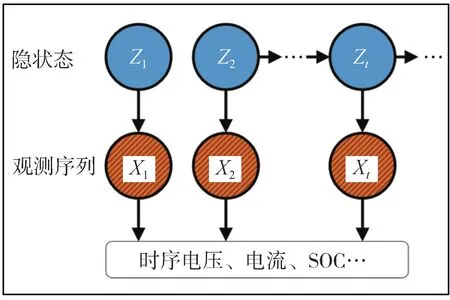
图2 热失控的隐马尔科夫模型
1.2 Baum-Welch(BW)算法求解模型参数λ
已知长度为T的观测序列和隐藏状态序列时,可以使用BW 算法求解模型参数 {π,A,B}。BW 算法的原理是EM 算法,在E 步求出联合分布P(X,Z|λ)基于条件概率P(Z|X,λ)的期望,在M步最大化这个期望,得到更新的参数λ。如此不断迭代,直到模型参数的值收敛。
在实际BW 算法的流程中,需要首先随机初始化模型的参数πi,aij,bj(k)。在E 步,对于每个样本d,分别计算其前向概率和后向概率前向概率是通过递推得到的,每个序列的前向概率的初始值为

对于接下来的每一项,都有:
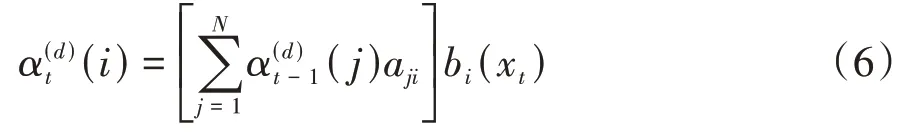
同理,后向概率也可以从序列的末尾从后往前递推得到。
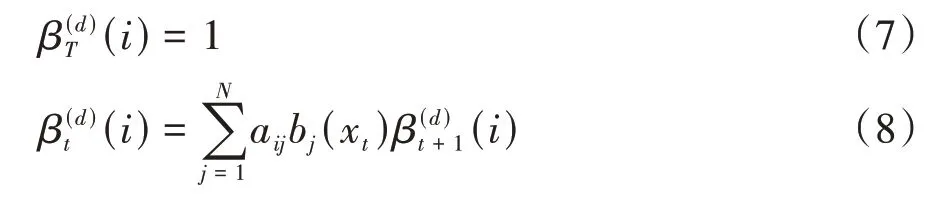
接下来在M 步,对于全部的D条时间序列,更新模型参数πi,aij,bj(k)。


如此反复迭代计算,直到模型收敛,即可得到当前序列下的模型参数 {π,A,B}。
1.3 Viterbi算法求解隐藏序列
当得到模型参数后,给出一个新的观测序列X=(x1,x2,...,xT),可以使用Viterbi 算法求解隐藏状态序列Z=(z1,z2,...,zT),从而达到热失控状态检测的目的。
其算法首先对t=1,2,...,T时刻,初始化并递推计算局部状态:
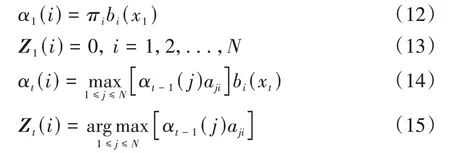
计算T时刻最大的前向概率αT(i),也就是可能性最大的隐藏状态的概率,此时的ZT(i)即为T时刻的隐藏状态:

1.4 算法流程
本方法的流程主要包括模型训练阶段和模型预测阶段,如图3 所示。在模型训练阶段,采集到历史数据经过特征工程,接入HMM 模型中,并通过BW算法求解参数。在模型预测阶段,实时采集的信号输入到训练好的HMM模型中,通过维特比算法求解当前的隐藏状态,达到实时检测的目的。
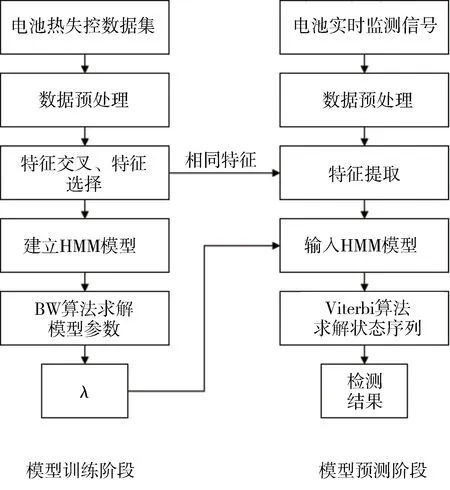
图3 算法流程图
2 数据来源与特征处理
2.1 数据来源概述
本文使用的数据来自于实验室获得的动力电池在模拟实车运行环境下的状态数据。在实验中,对某型号三元锂离子电池串联组成的电池组进行测试,其单体电压窗口为2.8-4.2 V。图4 所示为三元锂离子电池在模拟实车运行环境下典型充放电过程的电压、电流和温度变化曲线,模拟时长为24 h。

图4 电池参数变化曲线(典型值)
在建模的数据准备阶段,需要为数据人为标注标签。实验室模拟的车辆运行工况下的电池数据中,对于未触发热失控的动力电池,可以认为其状态始终为安全状态Z1,既该电池的时序数据中每个数据帧的标签都是Z1。为获取热失控实例,实验对少量电池采取针刺、电池内部置入有缺陷隔膜等方式人为触发热失控。对于此类动力电池的数据,在检测到温度开始升高、且此次温度升高最终发生热失控的时间片段中,其标签均设置成热失控状态Z3;且把Z3之前的最后一次充放电循环的时间片段的全部标签,均设置为有风险状态Z2;其余的标签均设置为安全状态Z1。
基于刚体和微小变动量假设,将零件特征或要素的几何变动量用SDT(small displacement torsor,小变量簇)表示。SDT是由沿x,y,z轴的3个平移自由度和3个旋转自由度相对应的微小偏移,以dx、dy、dz、δx、δy、δz来表示。用这6个分量的变动范围可以描述零件特征或要素相对于其应在位置或状态的几何变动域。
2.2 特征处理
由于GMM-HMM 模型无法像神经网络算法那样,可以进行自动的特征提取,因此本模型的特征提取与特征选择是影响模型最终实现效果的重要因素。选用机器学习特征工程、统计学特征和电化学特征3 种方式,同时对原始时序数据进行处理,组合出较多的新特征。经过对原始数据进行处理后,得到的新特征如表1所示。
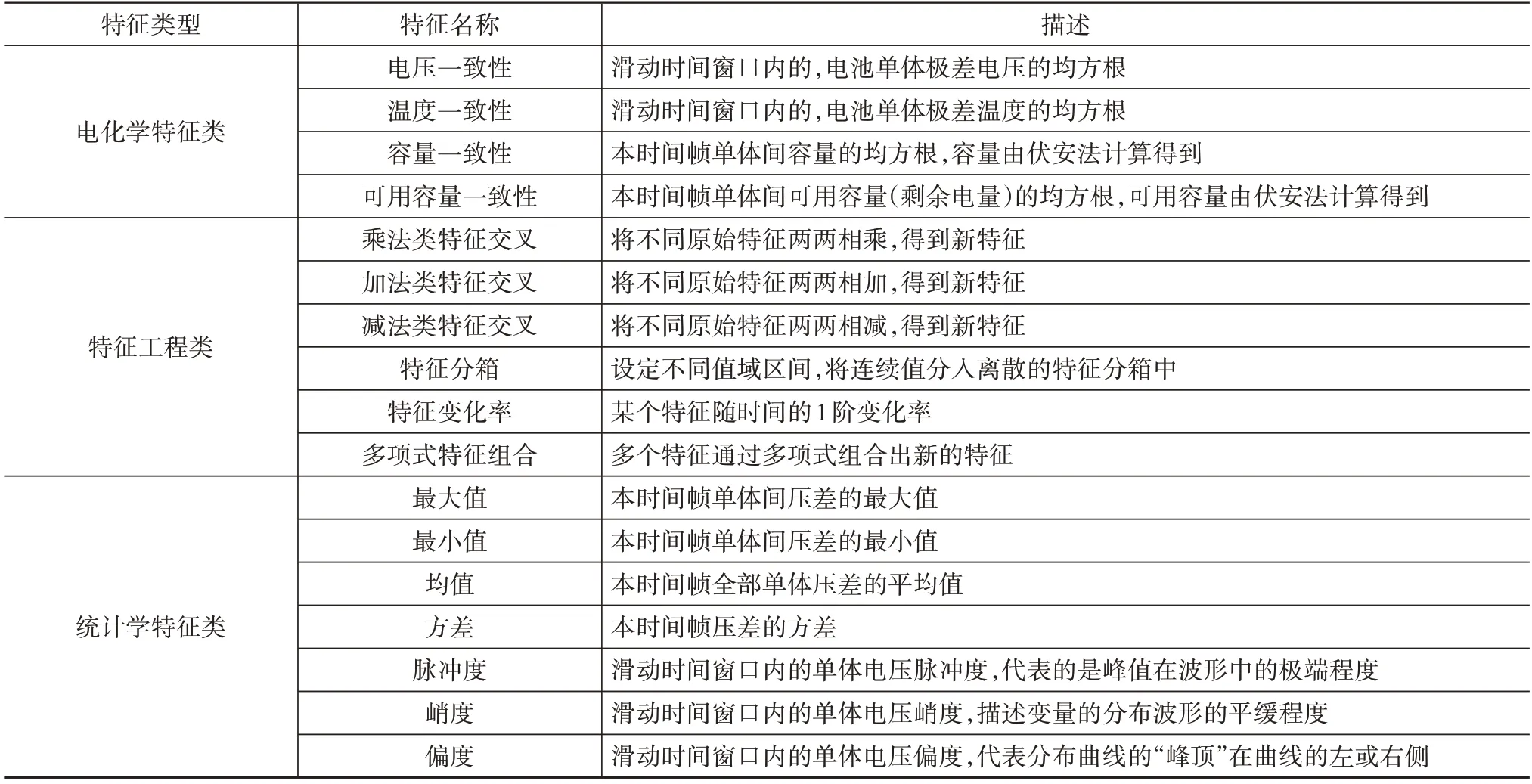
表1 处理后特征类别与描述
以上特征较为全面地反映了电池在充放电循环内的电化学表现,但大量的特征会降低计算效率,且将概率空间扩张到极高维度,使模型的随机取样都落入高维空间的表面,导致无法获得最优解。为解决该问题,通过递归特征消除(recursive feature elimination)的方式逐步降低特征的维度,这是一种寻找最优特征子集的贪心算法。递归特征消除的主要思想是反复构建模型,筛选并排除掉最差的特征,在剩余的特征上重复这个过程,直到筛选出涵盖信息量最大的少数特征。
本文中使用混合高斯模型(GMM)作为递归特征消除的特征筛选器,选择GMM 的理由是GMM 与HMM 存在算法原理上的相似性,本质都是基于图算法的贝叶斯概率模型,都包含一个隐变量和一个可观测状态。常规的递归特征消除算法对机器学习模型训练得到的权重值取绝对值,并剔除掉最小绝对值的特征。但GMM 作为基模型,不存在可以量化的特征权重值,因此本文使用交叉验证(crossvalidation)法结合递归特征消除法进行特征选择。
原始数据经过特征工程、统计学特征分析和电化学特征分析后,得到有效特征共54 个,如图5 所示。这里使用贪心算法的思想,从54 个特征中选出53个特征(共有54种组合方式)分别训练出GMM 模型并计算最优误差,选择损失最小的模型所用的那53 个特征,回到上一步继续削减特征的数目。如此迭代循环,直到这个过程无法为降低模型误差带来收益为止。在特征消除的递归过程中,GMM 最优模型的模型损失经历了逐渐下降再逐渐上升的过程,如图6所示。
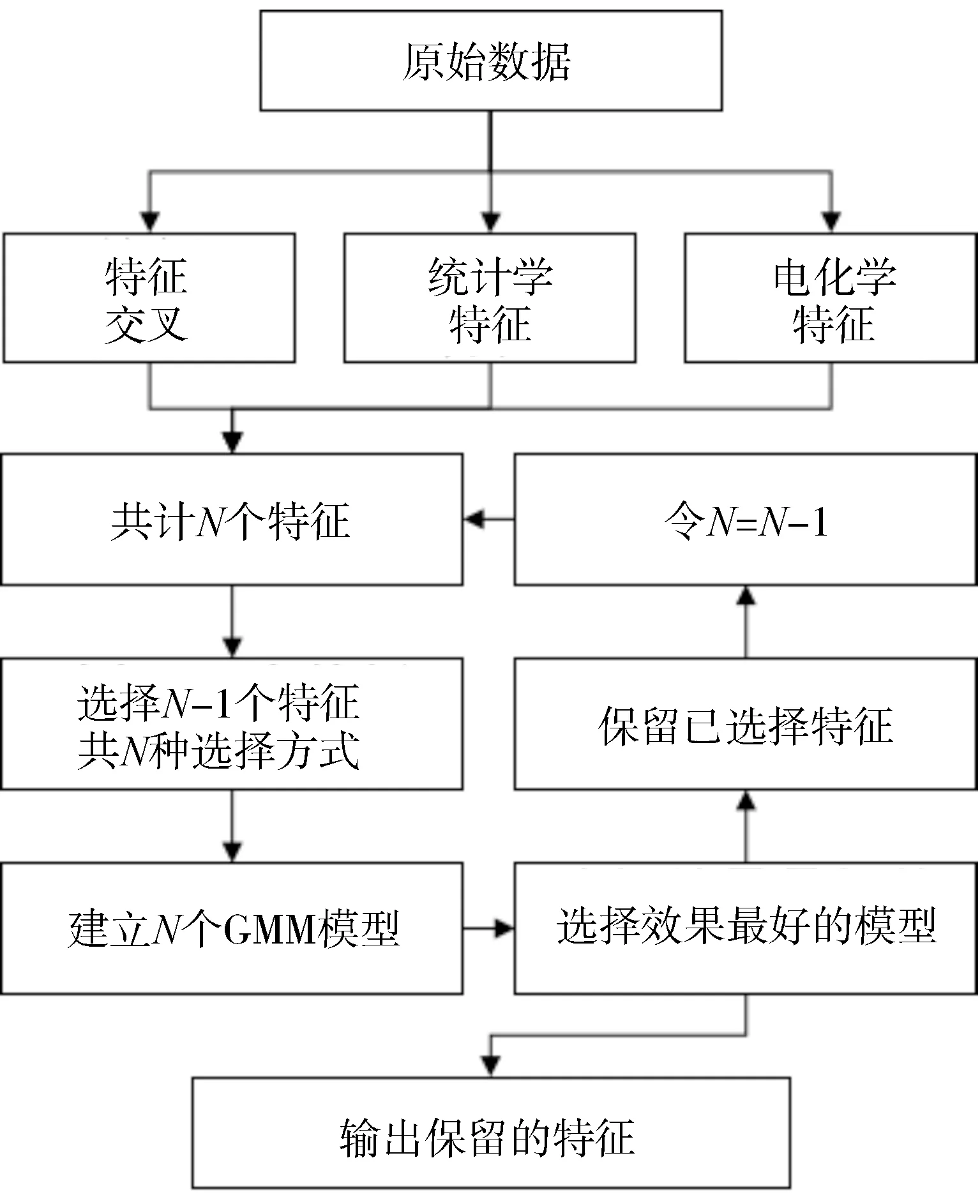
图5 特征选择流程
图6 中的前期损失下降阶段主要是由于特征维度的降低,模型更易收敛,最终的收敛结果虽然仍然是局部最优,但距离全局最优越来越近。而后期损失函数的逐渐上升过程主要是由于消除了过多的特征,导致数据的信息丢失过多,使模型难以拟合。所以递归特征消除的最佳停止点就是损失函数从下降转变为上升的临界点处,在本文中最终保留了14 个特征,如表2所示。
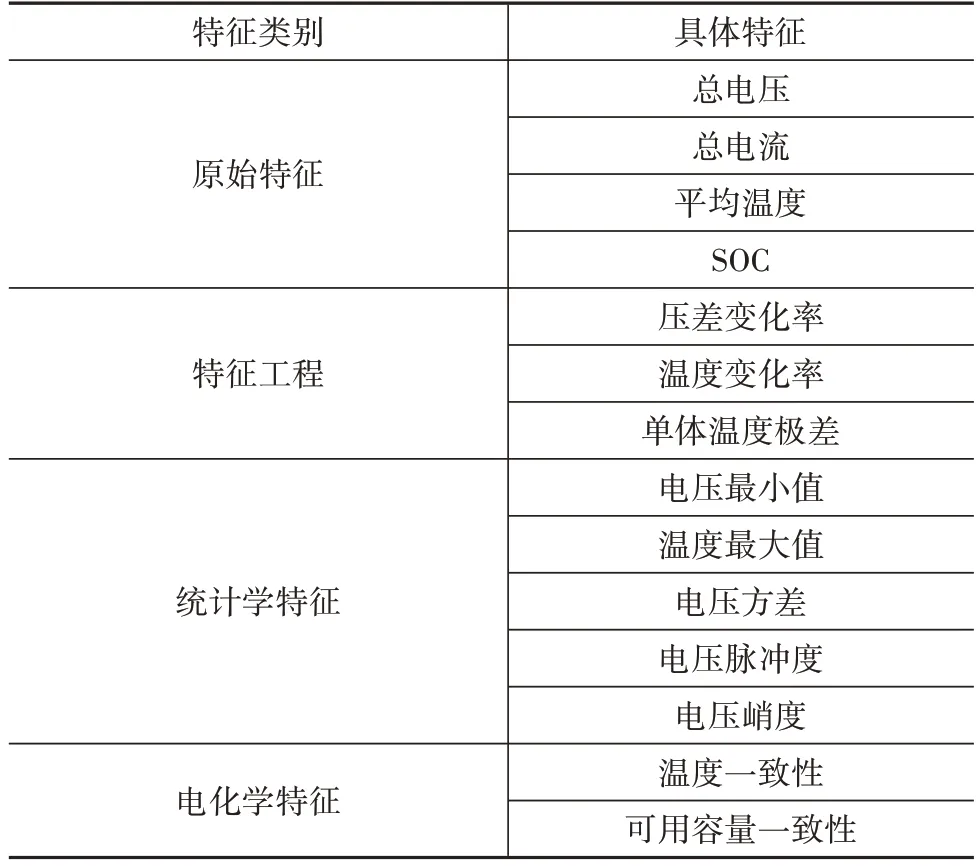
表2 经过特征选择后的特征
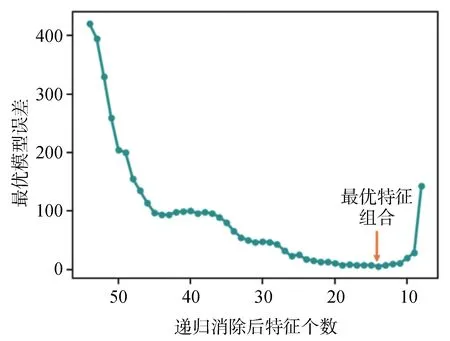
图6 GMM最优模型的模型损失
3 实验与讨论
3.1 电池热失控状态识别模型建立
为建立HMM热失控检测模型,提取每个三元锂离子动力电池组的全部时序数据作为一组原始数据,将全部的电池数据随机打乱组成数据集,并将数据集的70%作为训练集。按照上文的GMM方法,先通过特征组合手段扩充到54 组特征,再使用递归特征消除14 组特征向量并组成观测序列,设置隐状态数NZ为3,收敛误差为10-4,BW算法最大迭代次数为100。输入到模型中,使用BW 算法训练,得到HMM模型。图7 所示为经过GMM 迭代优选后的特征,经HMM 模型后学习得到的模型内参数在最终结果的损失函数的降低趋势。由图7 可知,模型收敛的速度较快,说明上述GMM 与HMM 结合的方法确实可实现从非时序数据到时序数据的迁移,且在迁移后保持训练数据在HMM上的收敛,说明模型已经学习到了有效的参数λ。

图7 模型训练误差下降曲线对比
模型识别使用维特比算法作为电池热失控的检测算法。选择全部电池数据的30%作为测试集,抹去其标签,作为新产生的数据,以与实验采集频率相同的每10 s 一帧的数据流量接入训练好的HMM 模型中,得到的训练结果见图8。表3 为模型表现统计。由表可见,HMM 时序模型对电池热失控的识别效果较好,训练集准确率可达100%,测试集识别率达到94.1%。

表3 模型表现统计表
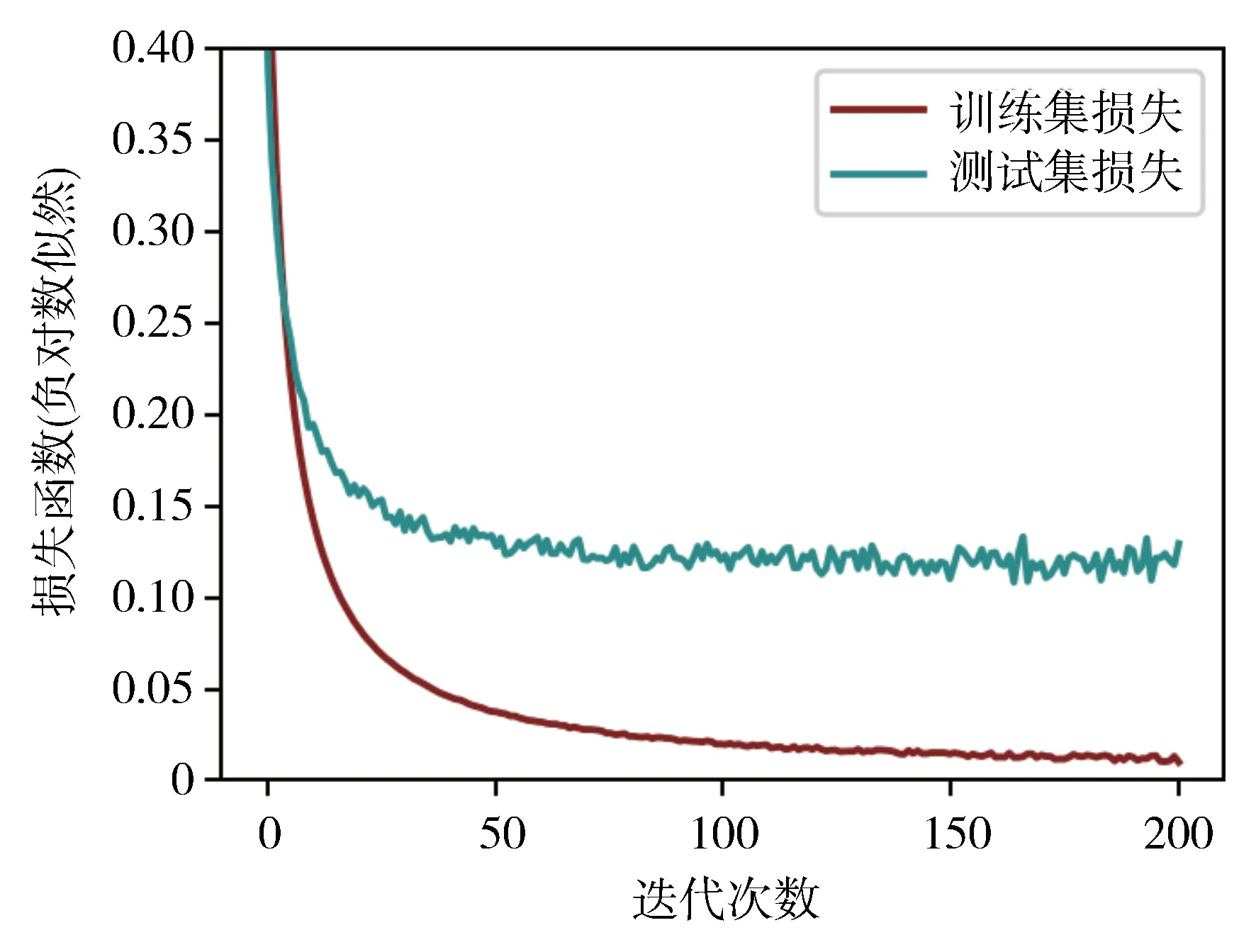
图8 HMM模型训练结果
3.2 模型效果对比
为对比GMM-HMM 模型与传统机器学习模型在热失控时序检测上的效果,对该电池型号下热失控数据在常见电池安全算法的表现进行了测试与对比。其中包括传统的结合双指数内阻等效电路模型的卡尔曼滤波方法和常见机器学习方法。
本文中选取的结合双指数内阻等效电路模型的卡尔曼滤波方法。首先构建多个测试内阻的双指数模型,将双指数模型输入到扩展卡尔曼滤波器中,使用与本文模型相同的数据进行训练,得到模型参数。然后对训练好的双指数模型进行求导,得到所述目标电池在所述预设时间段内的内阻下降速度,识别所述目标电池的热失控状态。
为对比本文模型与其他常见的机器学习模型的表现,使用支持向量机(SVM)与人工神经网络(ANN)作为在同样训练数据下的对比模型。由于这两种模型无法处理变长的数据,因此在数据的预处理上采用时间窗口的处理方式:将经过与GMMHMM 模型相同的递归特征消除操作后,将时间序列截取为多个10 min 的时间窗口(共60 帧),每个时间窗口只对应一个标签,即该窗口最后一个数据帧的标签。
SVM 热失控检测模型使用基于高斯核的“onevs-rest”多元SVM分类模型,输入为将时间窗口平铺后的序列,共840个特征(14个递归特征消除后的特征×60 帧),输出为3 个类别(安全状态Z1、有风险状态Z2、热失控状态Z3),Gamma 值设置为0.07,惩罚系数设置为1.0,正负样本的权重比为2∶1,并使用启发式收缩的训练方法加速训练。
ANN 热失控检测模型搭建了一个5层的神经网络,其输入层包含840 个输入,第1 个隐藏层含有168 个神经元,第2 个隐藏层含有21 个神经元,输出层的神经元个数为3,分别对应3 个类别(安全状态Z1、有风险状态Z2、热失控状态Z3)。神经网络的最后一层的激活函数为softmax 函数,其余激活函数均为sigmoid 函数,损失函数使用交叉熵损失,学习率为10-3。
训练完毕后的模型效果对比如表4 所示。其结果说明,相比于常见的非时序机器学习算法(支持向量机和人工神经网络),HMM 模型对动力电池的热失控检测准确率更高,且需要的训练时间大大缩短。且常见的非时序机器学习算法在对数据的处理较死板,只能识别定长的时间序列数据,因此需要更复杂的数据处理。在检测效果方面,非时序机器学习算法的机器学习算法接收的数据为平铺后的时序数据,因此数据维度大大增加,再次引发上文提到的维度灾难问题,导致模型训练缓慢,收敛困难,且准确率较低。而业界较为常见的卡尔曼滤波方法对实际电池数据的准确性表现较差,虽然训练较快且可以处理变长数据,但卡尔曼滤波的模型内部是以线性变换为主,难以反映电池热失控的复杂内部变化过程。
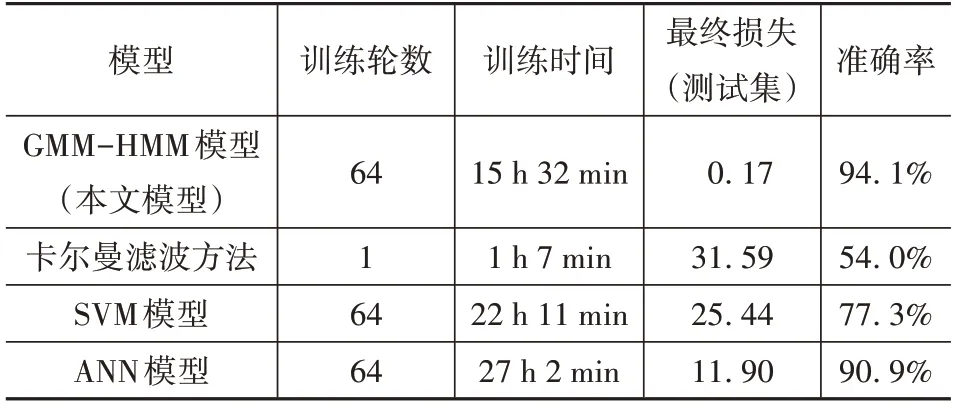
表4 模型效果对比
4 结论
在《节能与新能源汽车技术路线图2.0》规划中,新能源汽车将在2035 年占汽车总销量的50%~60%,成为主流车型[19]。而随着消费者对新能源电动汽车的行驶里程以及安全性能的要求不断提高,对电池热失控的实时检测成为电池安全的重要课题。本文中提出一种基于GMM-HMM 的电池热失控实时检测方法。
(1)从实验室模拟的工况循环周期下动力电池的充放电过程中取得表征电池状态的原始特征,并使用基于GMM的递归特征消除方法选择最优特征。
(2)使用基于 HMM 的锂电池热失控识别算法,通过 Baum-Welch 算法进行模型训练,分别对动力电池3 种不同的热失控状态(安全状态Z1、有风险状态Z2、热失控状态Z3)进行建模。
(3)建立 HMM 模型后,将当前的观测信号通过维特比算法,对观测序列进行解码,计算出当前模型是否处于热失控状态。模型对比结果表明,HMM 模型与卡尔曼滤波、支持向量机和人工神经网络模型相比,对锂电池的热失控检测准确率更高,训练时间短,模型收敛快,且可以处理任意变长的数据。
下一步的工作将着重于训练数据的增广与多样化处理,对模型标定进一步优化,尝试采用无监督学习方法对模型标签进行自动标注,从而提高模型的准确率与泛化性能。
