基于深度学习的汽车故障知识图谱构建
2023-02-13李源洁耿黄政易红卫
胡 杰,李源洁,耿 號,耿黄政,郭 雄,易红卫
(1.武汉理工大学,现代汽车零部件技术湖北省重点实验室,武汉 430070;2.武汉理工大学,现代零部件技术湖北省协同创新中心,武汉 430070;3.新能源与智能网联车湖北工程技术研究中心,武汉 430070;4.上汽通用五菱汽车股份有限公司,柳州 545000)
前言
2021 年中国汽车工业经济运行报告指出:2021年我国汽车产销分别达到2 608.2 和2 627.5 万辆,汽车产业的蓬勃发展为汽车后市场也带来了新的机遇和挑战。而随着汽车新四化水平的提高,售后汽车检测维修的难度也逐渐加大。据统计,在汽车维修过程中约有70%的时间用于寻找故障,而只有30%的时间是用于故障维修。因此,在汽车故障诊断中如何快速准确地定位故障是十分必要的。
汽车故障诊断技术现有方法中,基于故障现象的故障诊断主要依靠维修技师的个人经验和查阅维修手册或知识库。技师经验需要大量实践来沉淀,且这些维修经验难以理论化、共享化;维修手册或知识库虽然实现了维修知识的共享,但也存在一定的局限性,例如,维修手册并不能囊括用户使用过程中可能出现的所有故障现象,即内容不够全面;而对于知识库,其一般的构建流程是人工手动将相关理论、专家知识以计算机语言的形式表达和存储,该过程需要耗费大量的时间,构建周期较长,同时,采用传统方式所构建的知识库时,无法体现知识之间的关联,容易形成知识孤岛。此外,基于故障现象的诊断过程中产生的维修案例数据如故障现象、故障原因等过于口语化,这些非结构化数据难以有效存储和使用。所以,亟需一种方式用于实现知识库的自动化构建,并建立知识之间的关联,完成对诊断知识的积累和复用,辅助技师完成故障诊断。
知识图谱(knowledge graph)这一概念由谷歌公司在2012 年率先提出,以提高其搜索引擎的性能,本质上,知识图谱是一种揭示实体之间关系的语义网络,可以对现实世界的事务及其相互关系进行形式化的描述[1]。知识图谱由多个三元组组成,三元组的一般结构为“实体-关系-实体”或“实体-属性-值”。自2012 年被提出以来,基于良好的关联性能,知识图谱目前已在诸如电商、金融、医学等多个领域得到广泛应用,而针对汽车故障领域,国内外也有一些学者已经开展相关研究,文献[2]中从互联网论坛爬取大量博主分享的诊断和维修经验,采用CIMAWA 算法提取文本中的诊断操作,并将各诊断操作按逻辑顺序依次连接,形成诊断流程图;文献[3]中以柴油发动机为研究对象,提出引入词集级注意力机制的方法完成实体抽取,使用融合多尺度注意力机制和BERT 的方法完成关系抽取,最后将构建的知识图谱与贝叶斯网络结合,完成柴油发动机故障诊断;文献[4]和文献[5]中以汽车产业链协同平台上的数据为来源,以基于规则的方法进行实体抽取,构建与故障相关的特征,采用神经网络和XGBoost分类器完成故障诊断。
上述相关研究将知识图谱技术应用于汽车故障诊断领域,虽然极大地提升了知识库的构建效率和关联性能,但是在构建过程中仍然是只考虑了平面实体(flat entity)的获取,而并未过多关注故障文本中存在的嵌套实体(nested entity)和非连续实体(discontinuous entity)等问题。本文中基于某公司售后业务数据,针对故障文本中的嵌套实体问题和非连续实体问题,提出一种知识图谱构建流程,并利用知识图谱技术、自然语言处理技术,完成汽车故障知识图谱的构建。
1 数据来源与分析
1.1 数据内容
本文所使用的数据为某公司某款新能源车型一年的维修数据,这些数据从系统导出后以表格形式存储,相应字段的名称与数据类型如表1 所示。通过观察发现:数据包含了车辆信息、故障信息和维修信息3 部分内容,同时只有故障描述和处理结果字段为非结构化数据,其中故障描述字段包含车辆故障现象内容,处理结果字段包含排查步骤、故障原因、更换配件等内容。本文的目标即是分别从这两个字段中抽取出故障现象实体和故障原因实体,进而构建汽车故障知识图谱。
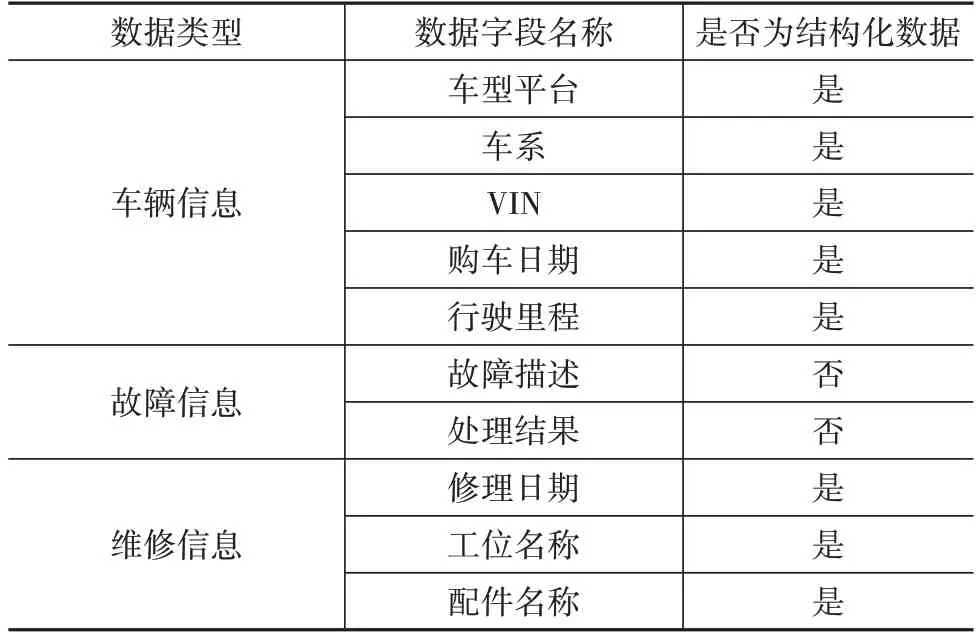
表1 业务数据分类及说明
1.2 数据特点
与通用领域的文本相比,故障描述字段、处理结果字段中的文本内容具有以下特点:
(1)两字段包含大量的专有名词,若直接使用HanLP、Jieba等分词工具,可能会造成结果不准确;
(2)两字段存在嵌套实体和非连续实体的问题,实体间的边界模糊、关系结构复杂,为后续的实体标注和抽取工作增加了难度;
(3)处理结果字段除了包含关注的故障原因内容,还包含排查流程、更换配件等内容,存在信息冗余。
对于上述特点,本文在构建汽车故障知识图谱时,特提出如下解决方案:针对问题1,采用基于字向量的BERT-BiLSTM-MUL-CRF 完成实体抽取任务,避免了分词错误所带来的影响;针对问题2,提出了一种新的实体抽取流程,将故障现象、故障原因预先拆分为故障部位+失效形式的组合形式,利用深度学习模型完成抽取,并设计了一种基于语法规则的匹配模板,对抽取的故障部位实体、失效形式实体进行重组,该流程不需要改变模型结构,且时间复杂度较低,能够较好解决文本中存在的嵌套实体和非连续实体问题;针对问题3,构建DPCNN文本分类器对文本中的内容进行预分类,使得在对故障原因实体进行抽取时,范围更加收敛。
2 汽车故障知识图谱构建方法
2.1 构建框架
知识图谱有自顶向下和自底向上两种构建方式[6]。自下而上的构建方式是指先完成知识抽取,再定义本体信息;自上而下的方式则是先定义本体信息,再从数据中完成知识抽取。由于车辆故障知识图谱属于垂直领域知识图谱,专业性较强,图谱中包含实体数量较少,故本文采取自上而下的构建方式,构建流程如图1所示。
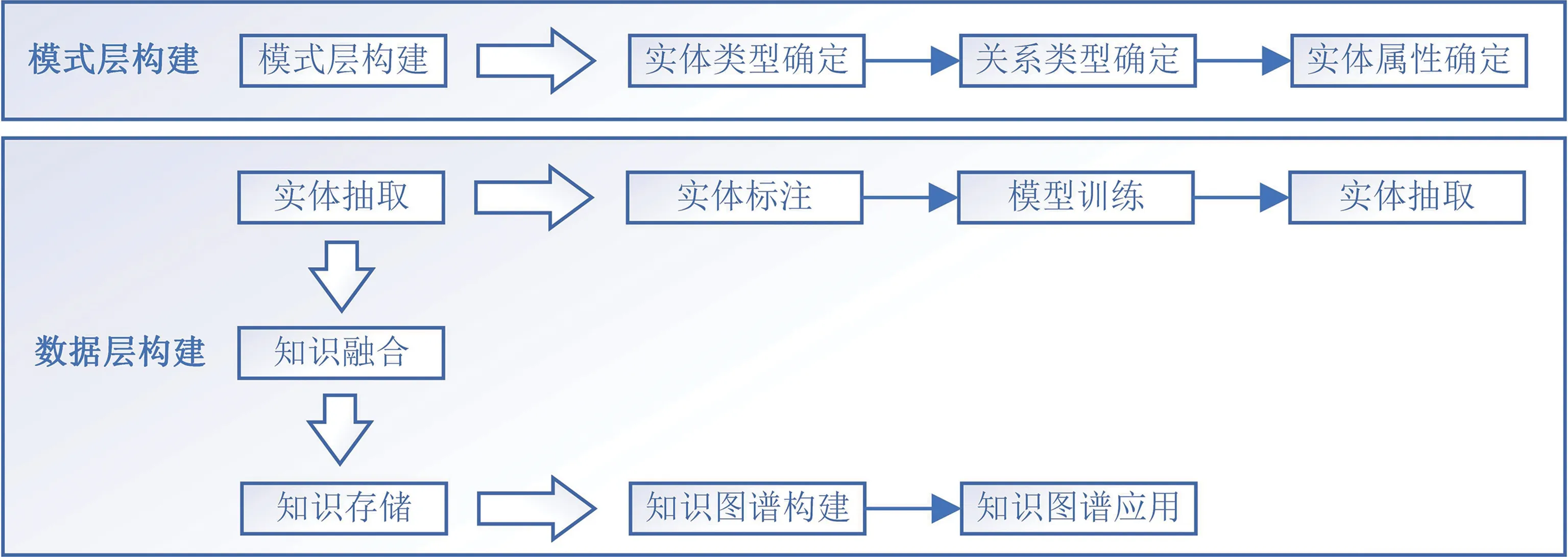
图1 汽车故障知识图谱构建框架
2.2 模式层构建
模式层构建在数据层之上,主要是通过本体库来规范数据层的一系列事实表达。本体是结构化知识库的模板,通过本体库而形成的知识库不仅层次结构较强,并且冗余程度较小[1]。本文所构建的汽车故障知识图谱模式层如图2 所示,主要包括车型车系、故障现象、故障原因等8 个实体和它们之间的7种关系组成。
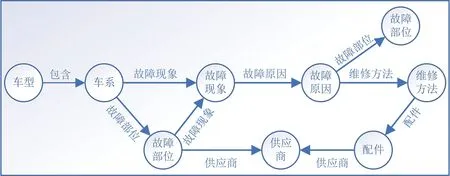
图2 知识图谱模式层构建
2.3 数据层构建
数据层主要是由一系列的事实组成,而知识将以事实为单位进行存储[1]。数据层构建主要包括知识抽取、知识融合、知识存储3 个任务,其中知识抽取作为主要任务。知识抽取包含实体抽取、关系抽取和属性抽取,由于本文数据采用表格形式存储,各字段之间的对应关系明确,因此只需要进行实体抽取。实体抽取又称命名实体识别NER(name entity recognition),它的主要任务是从非结构化文本中抽取结构化的实体;针对抽取后的实体可能存在一词多义或近义词的问题,需要进行知识融合处理,即实体消歧和共指消解任务;知识存储则是选用合适的存储方案对获取的知识进行存储,以便后续应用和维护。
文献[7]中将实体抽取的方法分为3 类:基于规则的方法、基于统计机器学习的方法以及基于深度学习的方法。其中,基于规则的方法需要制定大量的规则模板进行实体抽取,该方法存在规则冲突、组合爆炸、可扩展性差等缺点;基于统计机器学习的方法实现了模型的自学习,具有一定的扩展性,但是模型的效果依赖于人工选择的特征;基于深度学习的方法可实现端到端的实体抽取,在实体抽取任务中已经得到广泛应用。深度学习模型结构大致可以分为嵌入层、编码层和解码层3 层结构。嵌入层主要用来实现输入字符或词的向量化表示;编码层使用深度学习模型进行特征提取;解码层用于对深度学习模型的输出进行解码。现有研究主要集中在对嵌入层和编码层部分的研究,嵌入层部分相关研究主要关注如何更好实现输入的语义表示,如使用动态语言模型(BERT[8-9]、ELMO[10]等)、字词融合方法[10]等增强语义信息;编码层相关研究主要关注如何更好捕获隐含特征,如加入注意力机制[11-12]等。
目前,基于深度学习的实体抽取技术已经比较成熟,但大部分的研究仍然局限于平面实体的抽取,而对于嵌套实体、非连续实体的抽取,依旧面临一些困难。为解决这些问题,本文中针对故障文本的特点,提出了一种汽车故障知识图谱构建流程,具体包括:文本预分类、实体抽取、实体重组、知识融合、知识存储。
2.3.1 基于DPCNN的文本预分类
处理结果字段中包含故障描述、排查流程、故障原因、更换配件4个内容,如表2所示。
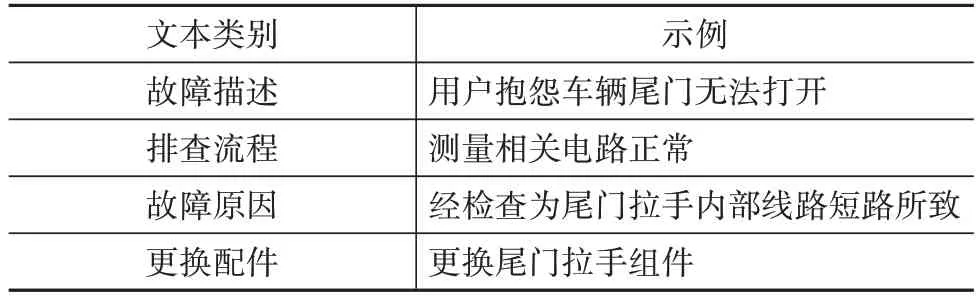
表2 文本类别及示例
若直接对处理结果字段进行实体抽取,由于存在其他类别信息会增加模型抽取难度,因此考虑对该字段中的文本内容预先进行分类处理,即文本分类任务。目前相关研究中,通常使用机器学习模型或者深度学习模型来实现文本分类,本文所使用的模型为Johnson 等[13]提出的深度金字塔卷积神经网络DPCNN 模型。该模型在TextCNN 模型[14]的基础上进行了相应改进,它通过等长卷积将第i个词的编码信息与其上下文的编码信息进行融合;通过1/2池化层增加了卷积核的感受野,用于捕获文本长距离依赖关系;通过残差解决CNN 网络中的梯度弥散问题。经过上述优化,与TextCNN 模型相比,DPCNN模型具有更好的文本分类效果,本文所使用的DPCNN模型结构如图3所示。
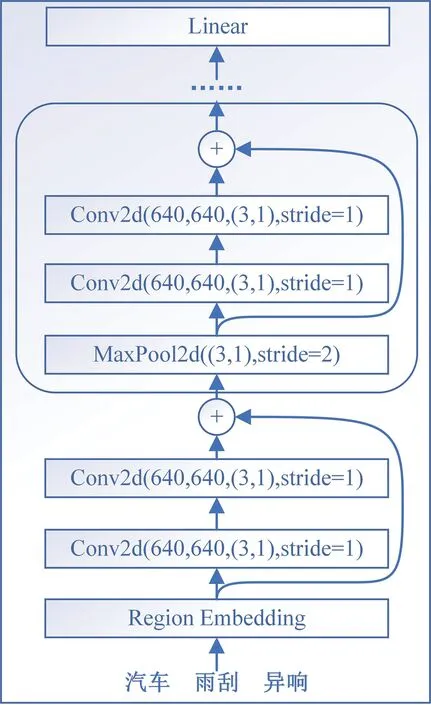
图3 DPCNN模型结构
2.3.2 基于BERT-BiLSTM-MUL-CRF 的实体抽取
在完成文本分类后,本文须分别从故障描述字段、处理结果字段中的故障原因文本抽取出故障现象实体和故障原因实体。经过观察,这两部分文本中存在嵌套实体问题和非连续实体问题,虽然目前已经有大量实体抽取的相关工作,但是很少涉及嵌套实体和非连续实体的抽取问题,其中对于嵌套实体问题,目前主要有以下几种思路。(1)基于超图的方法:如文献[15]中提出基于递归神经网络的嵌套实体抽取模型,在解码时,将超过设定阈值的类别输出,并作为当前token 的标签;使用KL-divergence 损失函数来计算多标签损失,但是模型的阈值设定存在主观因素。(2)基于数据标注的方法:如文献[16]中采用BILOU 标注法,将嵌套的实体标签进行组合,例如文中将“I-ORG”标签和“U-GPE”标签进行组合,形成一个新的标签“I-ORG|U-GPE”,这样嵌套实体对应的多分类任务就转化为单分类任务,该方法由于采用了复合标注,会造成不同类别样本分布不均,模型学习效果变差。(3)基于状态转换的方法:文献[17]中采用从外到内递归解码的方式搜索嵌套实体,直到不再检测到新的嵌套实体为止,该方法中内层嵌套实体的识别在外层实体的内部进行,因此外层实体的识别出现的偏差会随递归解码过程传播。(4)基于阅读理解的方法:文献[18]中引入MRC(mechine reading comprehension)框架,将NER任务转化为阅读理解任务,通过BERT 模型对问题和文本进行编码,并分别计算文本中每个位置为实体起始索引以及结束索引的概率,最后将起始索引与结束索引匹配,完成实体识别任务。针对非连续实体问题,文献[19]中提出一种基于最大团(maximal clique)发现的非连续命名实体识别模型,即Mac 模型,其主要思想是采用段图(seqment graph)的方法,将文本中的连续或非连续实体表示为图中的节点,并将同一实体的片段进行用边进行连接,此时非连续命名实体识别问题就转化为发现图中最大团的问题;文献[20]中则是分析了嵌套实体和非连续实体的共性问题,并把非连续实体转化为嵌套实体来研究,使用堆栈结构,通过乘法注意力机制去捕获stack 区与buffer区元素之间的非连续性依赖,并通过该依赖程度决定下一步执行何种动作,进而找出文本中的非连续实体。
通过分析故障文本,得出如下结论:文本中的嵌套实体问题主要为故障部位实体和故障现象实体的嵌套,如图4 中的“左前轮”和“左前轮漏气”,嵌套结构为两层嵌套;非连续实体主要表现为故障部位或失效形式的重叠,如图4 中的“异响”。在语法结构上,嵌套实体多为主谓结构,即故障部位在前,失效形式在后;非连续实体中非连续部分通常会以“、”符号进行连接。基于上述特点,本文将故障现象、故障原因预先拆分为故障部位+失效形式的组合形式,构建模型完成对故障部位实体、失效形式实体的抽取,解决文本中的嵌套实体问题;之后对抽取的结果基于语法规则再次重组,解决非连续实体问题,最终获得故障现象实体和故障原因实体。
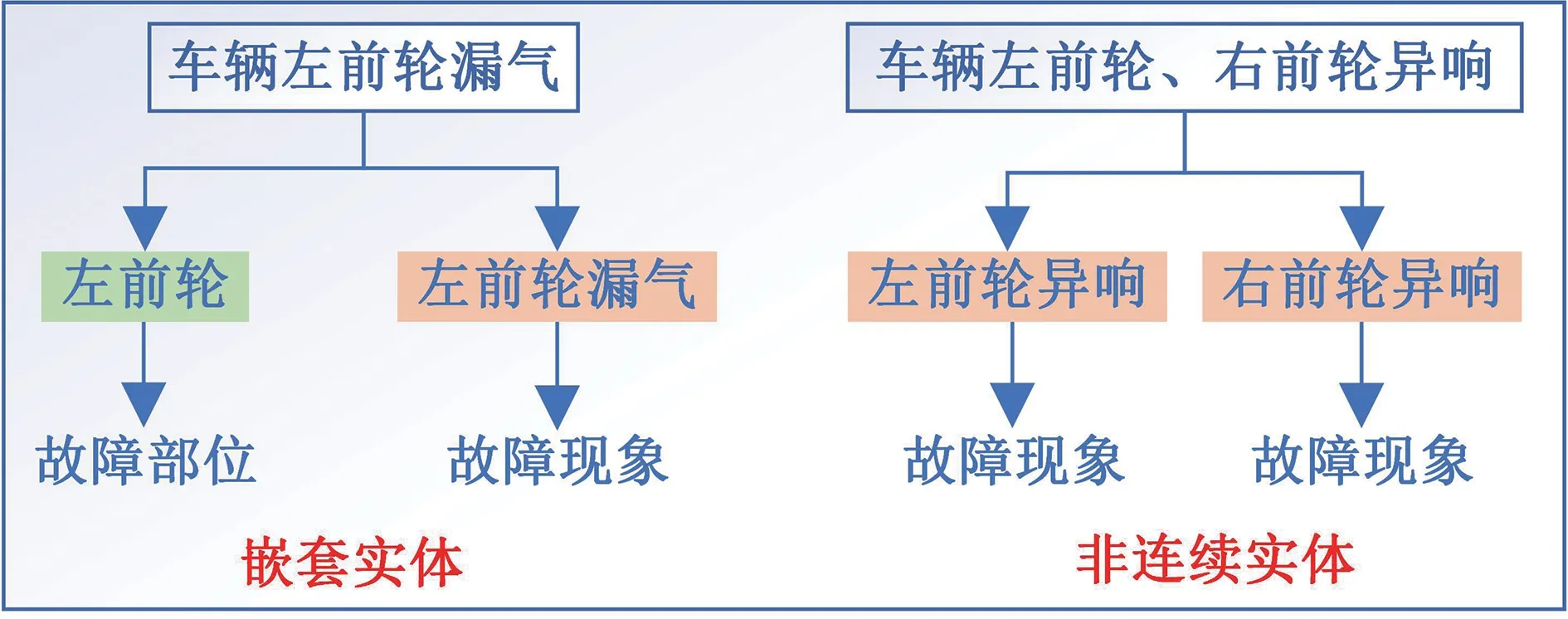
图4 嵌套实体与非连续实体举例
在利用深度学习模型进行抽取时,模型输入通常可分为单个字符输入、词输入以及字词融合输入。考虑到本文数据为专业领域文本,分词结果可能不准确,而分词所产生的误差最终又会影响模型的训练和预测,所以本文采用基于字向量的BERTBiLSTM-MUL-CRF 模型完成实体抽取,模型结构如图5所示。
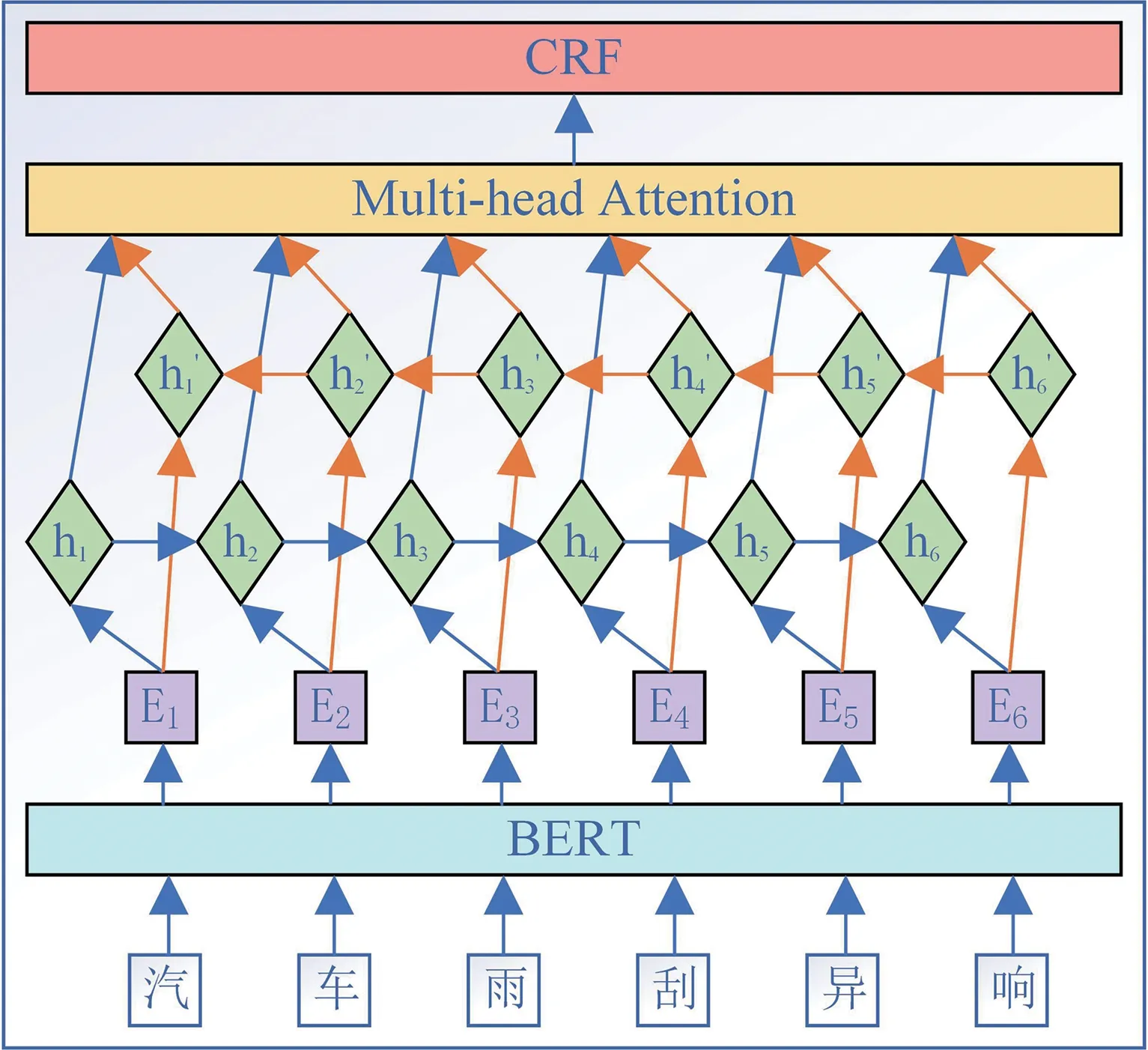
图5 BERT-BiLSTM-MUL-CRF 模型结构
在上述模型结构中,BERT模型作为嵌入层对每个输入字符进行编码,它基于自注意力机制,使得每个字符的编码信息能够融合上下文其他字符的信息,更好进行语义表示;BiLSTM 模型通过左向网络和右向网络获取字符的上下文信息,完成特征提取;注意力层用来捕获BiLSTM 输出编码中更加丰富的信息;CRF 层用来对注意力层的输出进行解码,与argmax 不同,CRF 层不仅考虑了标签的发射概率,还考虑了标签之间的转移概率,能够更好实现对输出标签序列的约束。
2.3.3 基于语法规则的实体重组
如图6 所示,由于本文预先对故障现象、故障原因进行了拆分,因此在完成故障部位实体、失效形式实体的抽取后,需要对实体进行重组,以获得最终的故障现象实体和故障原因实体。因此,本节结合2.3.2 节所述故障文本的特点,设计了一种基于语法规则的匹配模板,如表3 所示,用来完成对实体的重组。

表3 基于语法规则的实体匹配算法
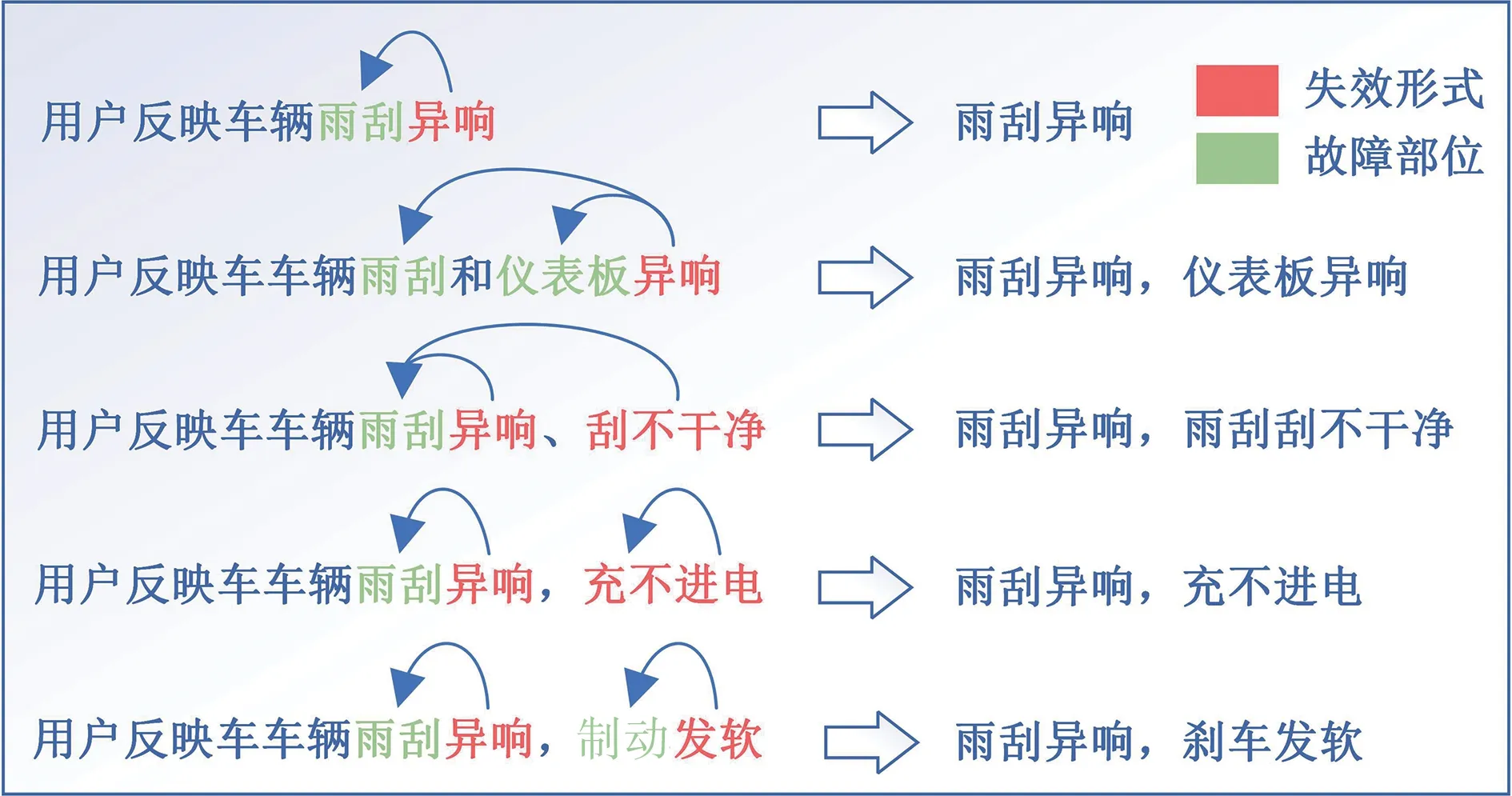
图6 实体匹配示意图
为更好解释本文的实体匹配算法,现以故障现象“右前门、右前翼子板、前蒙皮发黄,制动灯不亮”为例,对匹配算法进行解释说明,过程如图7 所示。首先,经过模型抽取,分别得到以下故障部位实体和失效形式实体:[右前门,右前翼子板,前蒙皮,制动灯],[发黄,不亮],依次获取故障部位实体和失效形式实体在故障现象文本中的索引列表L1,以及失效形式实体索引列表L2,本例中,L1为[0,4,10,13,16,19],L2为[13,19];之后,按从小到大的顺序将L1中的元素依次压入栈内,在压栈之前,判断该索引是否为失效形式索引,若为真,则将栈内所有元素弹出,同时将弹出的故障部位索引与失效形式索引一一配对;最后,将这些匹配完成的索引对与故障部位、失效形式进行映射,就得到了最终的故障现象。需要注意的是,本例为失效形式不连续的情形,当遇到故障部位不连续的情形时,首先需要通过语法规则,将失效形式实体合并成列表L′,如图6中例3所示的[异响,刮不干净],假设列表L′长度为n,同时以n个失效形式实体中的最小索引作为列表L′的索引,并将该索引添加至列表L1和L2中。之后采用同样的方式将列表L′与故障部位实体进行配对,假设符合配对条件的故障部位实体数量为m,则将L′中的n个失效形式实体与m个故障部位实体一一匹配,最终得到m×n个故障现象实体。
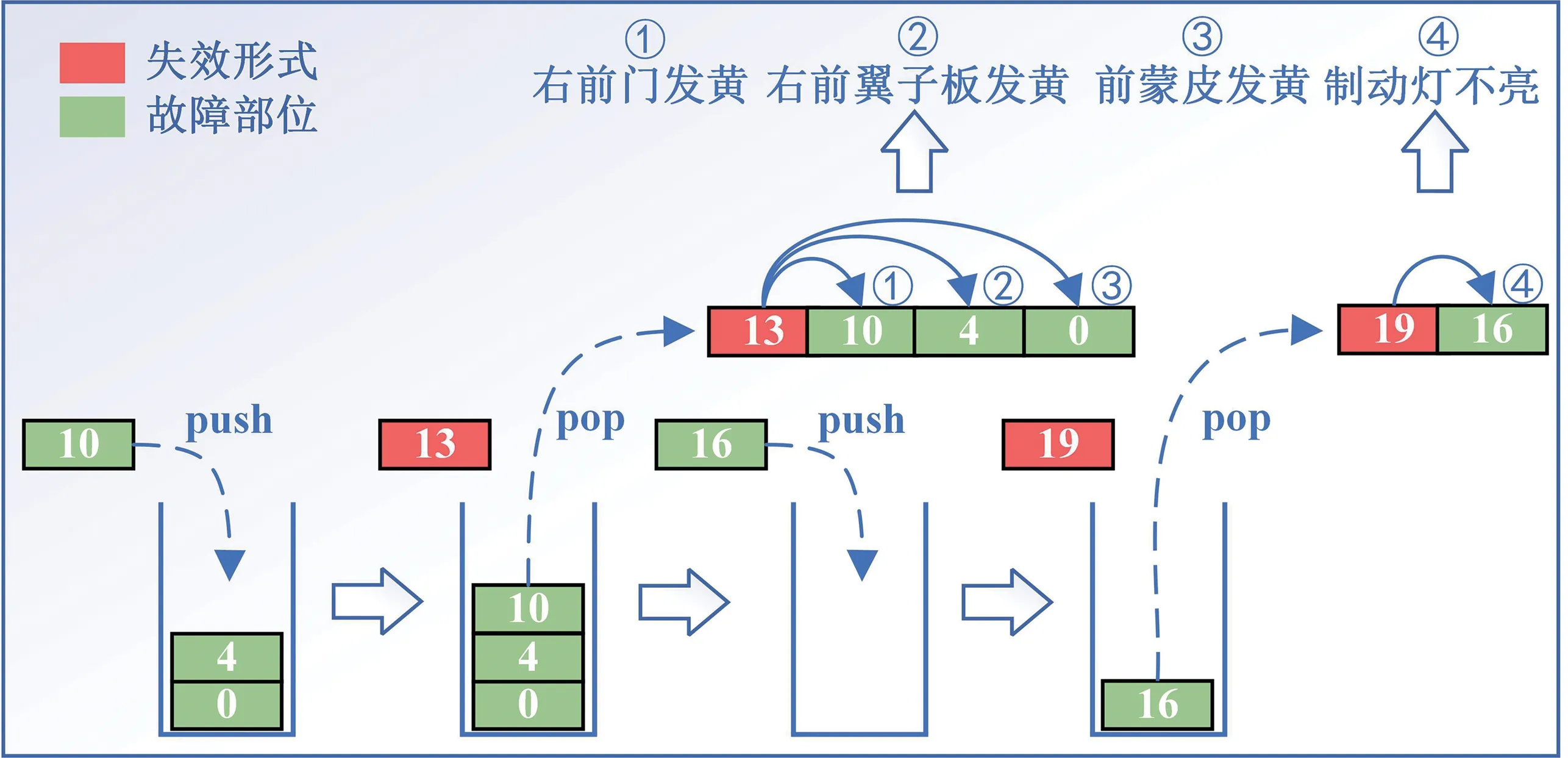
图7 实体匹配示例
2.3.4 知识融合
知识融合是融合各个层面的知识,包括不同知识库的同一实体、多个不同的知识图谱、多源异构的外部知识等,并确定知识图谱中的等价实例、等价类及等价属性,实现对现有知识图谱的更新[21]。在汽车故障诊断领域,主要是解决近义词的问题,即共指消解任务,目前,针对共指消解任务,主要有3 种方法:基于术语的方法、基于结构的方法和基于深度学习的方法。基于术语的方法主要关注实体的名称、属性、标签等信息,常用比较方法有word2vec、TFIDF 值、Jaccard 系数等;基于结构的方法通过分析实体结构上的相似度来完成对齐,该方法与分布式假设的思想相同;基于深度学习的方法是利用知识表示学习将图谱中的实体和关系都映射成低维稠密空间向量,使用神经网络模型自动获取隐式特征,在隐式向量空间计算实体相似度。本文中采用术语相似度和结构相似度相结合的方法来完成共指消解任务。
3 算例分析
3.1 文本分类实验
3.1.1 算例情况
本文从原数据处理结果字段中选取部分数据进行切分,最终获得4 000条数据。将数据标注为故障现象、排查流程、故障原因和更换配件4 个类别,并按照6∶1∶1 的比例划分为训练集、验证集和测试集,用于模型的训练和测试。
3.1.2 评价指标
使用准确率P、召回率R和F1值3个指标对每个类别的预测结果进行评价;使用各类别预测结果的加权平均对模型整体预测结果进行评价。
3.1.3 参数设置
本文所使用的DPCNN 模型参数设置如表4所示。
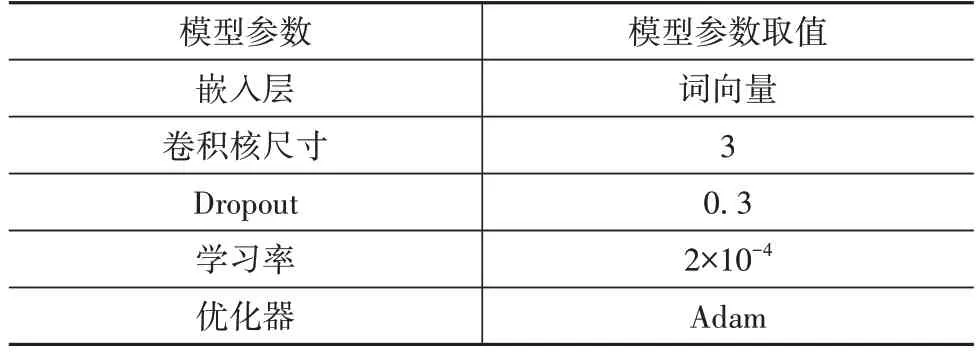
表4 DPCNN参数及取值
3.1.4 文本分类结果与分析
选用机器学习中的SVM 模型、KNN 模型和深度学习中的TextCNN、VDCNN 模型,进行对照实验,各模型的实验结果如表5所示。
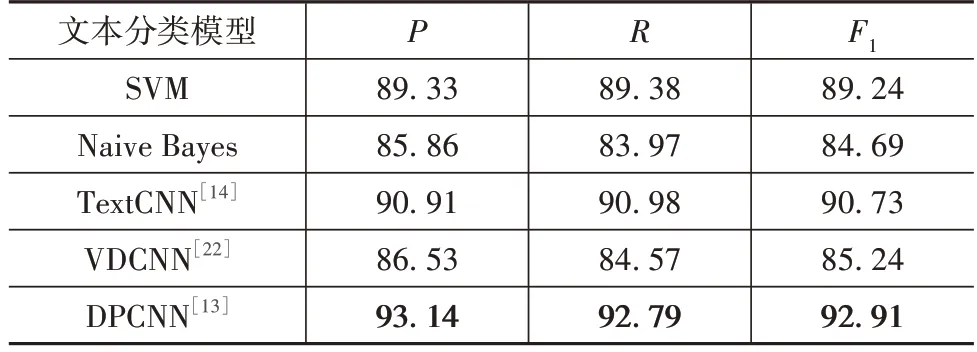
表5 文本分类结果 %
从上述结果可知,与机器学习模型相比,3 种深度学习模型表现更好,而DPCNN 模型基于前文所述的优点,取得了最好的实验结果。
3.2 实体抽取实验
3.2.1 算例情况
从故障描述字段和经过处理结果字段中的故障原因文本中选取4 200 条数据,采用BIOS 标注法进行标注,并按5∶1∶1 的比例划分为训练集、验证集和测试集。
3.2.2 评价指标
使用实体级别的准确率P、召回率R和F1值对模型评价外,同时使用各实体预测结果的加权平均来评价各模型的整体表现情况。
3.2.3 参数设置
本文所构建的BERT-BiLSTM-MUL-CRF 模型参数设置如表6所示。

表6 BERT-BiLSTM-MUL-CRF 参数及取值
3.2.4 实体抽取结果与分析
引入IDCNN-CRF、Lattice LSTM-CRF 等模型进行对照实验,各模型实体抽取结果如表7所示。
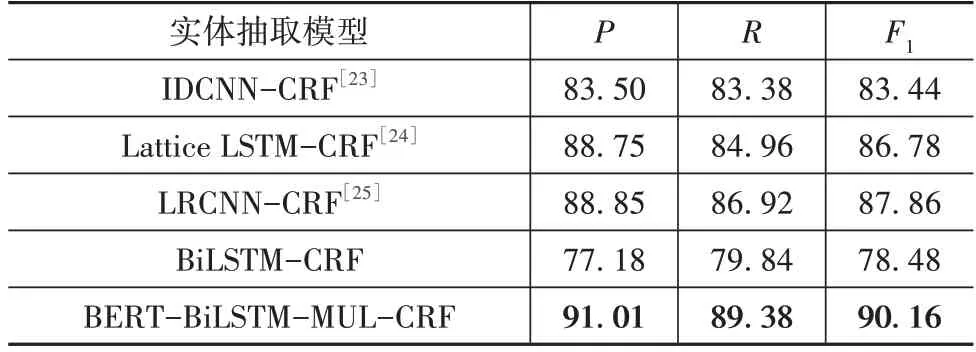
表7 实体抽取结果 %
从表7 可以看到:本文所使用的BERTBiLSTM-MUL-CRF 模型在加入BERT预训练模型和注意力机制之后,较原模型而言,其各项评价指标提升了10 多个百分点;同时,也看到Lattice LSTMCRF 模型和LRCNN-CRF 模型也取得了较好的效果,Lattice LSTM 模型在基于字符NER 的基础上,通过门控单元,将与当前字符匹配的所有词汇信息融入到原LSTM 模型中,同时利用了字符和词汇信息。LR CNN 模型采用卷积神经网络提升了模型的运行速度,同时考虑到在匹配词汇信息时,多个词汇之间可能会存在冲突。因此该模型通过引入Rethinking反馈机制,利用高层语义弱化错误候选词的权重。另外,从图8 也观察到,相较于其他模型,本文模型分别对不同实体抽取时,也都取得了最佳的F1值。

图8 各模型F1值情况
3.3 实体重组
在完成故障部位实体和失效形式实体的抽取后,采用本文设计的匹配模板进行重组,以获取最终的故障现象和故障原因。本文实验数据中,包含嵌套实体的样本共计9 537 条,其中,既包含嵌套实体又包含非连续实体的样本共计452条。
在进行实体重组时,首先选取452 条包含非连续实体的样本,使用本文所提出基于语法规则的匹配模板,对得到的故障部位实体和失效形式实体进行重组,得到故障现象实体和故障原因实体,最后人工对重组的结果进行核验,经过计算,匹配模板的准确率可达到63.3%。之后,选取只包含嵌套实体的样本共计2 000 条,采用同样的方式进行重组,经过人工校验,准确率为86.8%。
从实验结果来看,本文所设计的模板对于非连续实体的匹配准确率低于嵌套实体。这是由于嵌套实体中,内层实体完全位于外层实体的内部,实体之间的跨度更小,而非连续实体的跨度更长,因此相应地会具有更高的识别难度。就整体情况而言,本文所设计的模板对于嵌套实体和非连续实体都取得了较高的准确率,同时模型的时间复杂度较低,提升了图谱的构建效率。
3.4 知识融合
如图9 所示,本文中采用术语相似度和结构相似度相结合的方法,对重组得到的故障现象实体和故障原因实体进行对齐融合。通过先前构建的汽车故障知识图谱模式层了解到,故障原因实体与维修方法实体链接,而维修方法为结构化数据,可直接进行比较,因此可以首先对故障原因实体进行对齐,之后再对故障现象实体进行对齐。在相似度计算时,由于术语相似度更容易计算,因此优先计算实体的术语相似度,结构相似度用以辅助判别,考虑到抽取故障现象与故障原因实体文本较短,本文选用Jaccard系数作为评价指标。
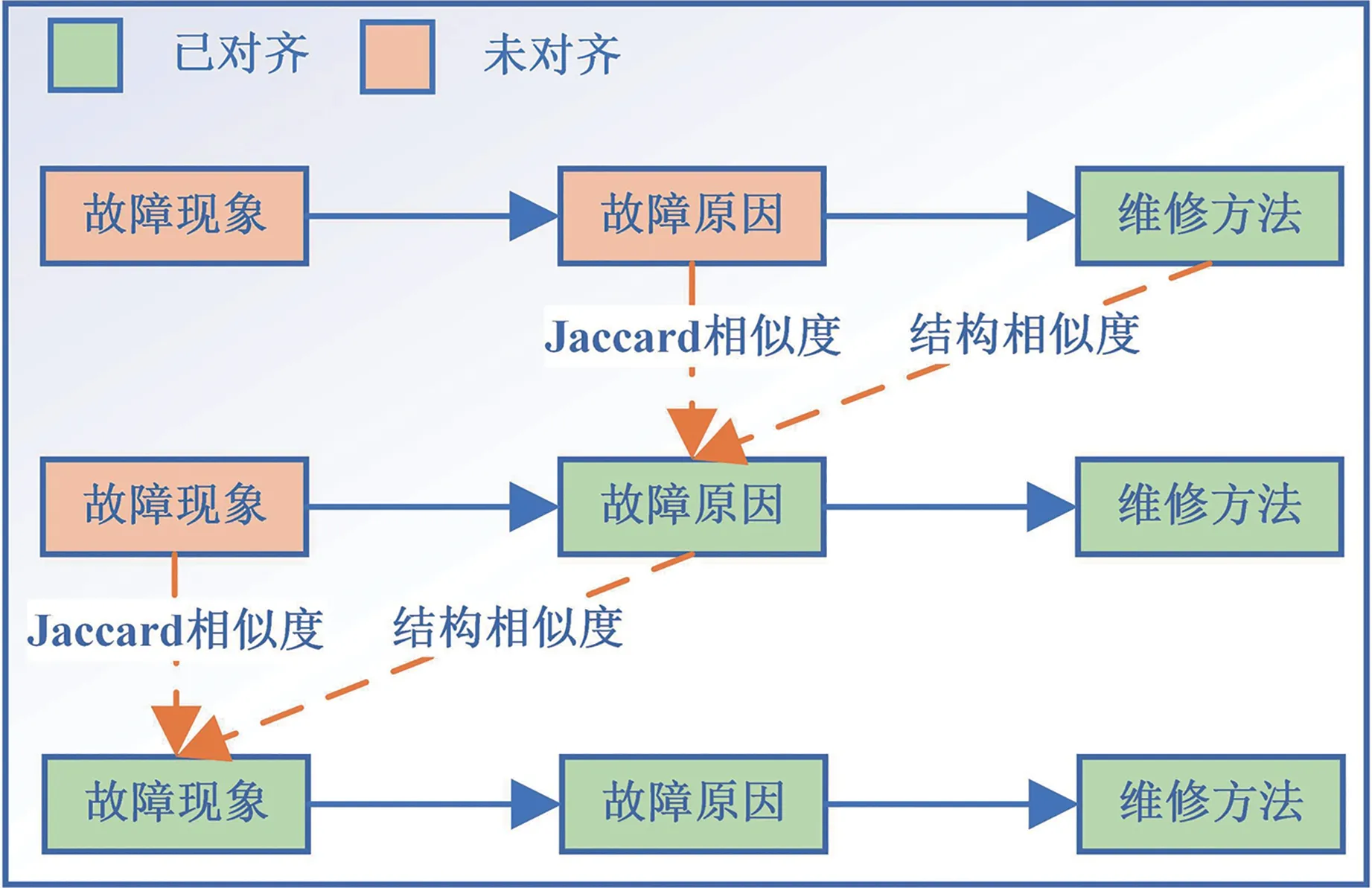
图9 共指消解流程
3.5 知识存储
在对故障现象和故障原因实体融合处理后,本文使用Neo4j 图数据库对构建的汽车故障知识图谱进行存储,部分存储结果如图10所示。
图10 知识图谱部分存储结果
4 结论
本文中将知识图谱应用于汽车故障诊断领域,在传统知识图谱构建流程的基础上,针对文本特点,加入了文本预分类和实体重组。基于DPCNN 的文本分类模型用于从目标字段剥离出故障原因相关内容,缩小了实体抽取范围;将故障现象、故障原因拆分为故障部位+失效形式的组合模式,采用基于字向量的BERT-BiLSTM-MUL-CRF 模型完成实体抽取任务,并使用基于语法规则的匹配模块完成实体重组,有效解决了文本中的嵌套实体和非连续实体问题,提升了图谱构建效率和准确率,为后续构建基于知识图谱的故障诊断奠定了基础。
