错认总比错过好
——面孔视错觉的发生机制及其应用*
2023-02-12陈子炜
陈子炜 付 迪,3 刘 勋
(1 中国科学院心理研究所行为科学重点实验室,北京 100101)(2 中国科学院大学心理学系,北京 100049) (3 汉堡大学信息科学系,汉堡 22527,德国)
1 引言
人们有时会从某些物体上看到实际并不存在的物体,比如将猴面兰的花蕊看成猴脸、将天空中的云朵看成面孔。这类错误的视觉感知,即感知到本不存在的物体,被称作视错觉(pareidolia)(Liu et al.,2014)。这种错误感知即表现为个体对无意义的事物赋予了新的意义(Wang et al.,2022)。在发生视错觉时,个体一般会从事物中错误地感知到本不存在的动物、物体或事件。其中,个体更多地将物体错误地感知为实际并不存在的面孔,这被称作面孔视错觉(face pareidolia) (Liu et al.,2014;Ryan et al.,2016;Wodehouse et al.,2018)。那些能引起面孔视错觉的物体,则被称作类面孔物体(face-like objects)。
面孔视错觉的产生既源于个体的先天适应,也源于个体所处的后天环境。一方面,从进化学的角度,感知面孔的能力具有一定的适应性功能。个体为了有效规避环境中的潜在危险,往往会降低对带有社会信息面孔刺激的阈限感知,这导致个体更容易将物体错误地加工成面孔(Chen&Yeh,2012;Takahashi &Watanabe,2013)。此外,识别面孔以及面孔情绪也可促成个体对后续威胁和机会的预测感知(Ekman et al.,1987;Ryan et al.,2016)。尽管这种进化适应可能使得个体错误地将物体当成一张面孔,但其副作用也远低于错过一张真实面孔所带来的后果。另一方面,大脑不仅被动地接受自下而上的视觉信号,还会进行预测编码(Bar,2007;Palmer,1975)。当处在一个高度稳定且可预测的世界时,个体可将提取的感知信息基于经验和记忆进行对比并生成对所看到事物的预判(de Lange et al.,2018)。研究者认为,社会场景中的面孔可能被人赋予了重要的社会作用,进而导致人们对面孔存在较高的期望(Summerfield et al.,2006)。由于身处于社会环境中,个体对面孔具有较高期望,而当自上而下的期望同自下而上的视觉信号之间发生平衡失调时,面孔视错觉就会产生(Smailes et al.,2020)。
以往的研究除了比较面孔视错觉和面孔加工之间的联系,也关注视错觉在临床诊断和商业广告领域中的应用。个体在产生视错觉时看到的通常是现实中存在的事物(Palmer &Clifford,2020),而患者在产生视幻觉(visual hallucination)时看到的则更多是无意义的图案(Mamiya et al.,2016;Ryan et al.,2016)。虽然视错觉和视幻觉在症状表现上存在一定的差异,但两者在生理层面依旧存在一定相关(ffytche &Howard,1999)。因此,相关研究提出视错觉可作为视幻觉的一种亚临床表现(Akdeniz et al.,2020;Uchiyama et al.,2015)。视错觉除了可纳为视幻觉的诊断标准,也可用于研究有关孤独症患者对面孔的选择性注意。虽然孤独症患者相较健康成人在检索图片时会表现出对面孔,尤其是眼睛的回避(Frazier et al.,2017;Weigelt et al.,2012)。但有研究发现孤独症患儿依旧会产生面孔视错觉,只是发生的比例要低于正常儿童(Ryan et al.,2016)。同时,研究者在孤独症成年患者中也发现类似情况,低水平孤独症特质的个体依旧会对类面孔物体图片产生生理唤醒(Singleton et al.,2014)。除了临床诊断和干预,面孔视错觉也常被商家利用作为广告设计的元素(Wodehouse et al.,2018)。拟人化的商品广告,如将食品摆成类似面孔的印刷广告,会更多地吸引消费者注意,促进其购买行为(Delbaere et al.,2011)。此外,有研究发现,相较一般的印刷广告,加入人脸或类面孔元素均可增加品牌认知度和广告偏好(Guido et al.,2018)。
综上所述,当前有关面孔视错觉发生机制的探究还不够深入与充足,且尚未有一致结论。本综述将依次探讨面孔视错觉的相关研究范式、发生机制,以及对面孔视错觉在临床诊断、商业领域的应用和展望。以此为后续面孔视错觉范式的改进,以及面孔加工神经机制的探究奠定基础。
2 研究视错觉的相关范式
视错觉定义为外界刺激触发了个体对某种特定物体的感知(Liu et al.,2014)。由于目前有关面孔视错觉的研究采用的范式各不相同,使得个体产生的面孔视错觉也不尽相同。基于材料和研究方法的不同,可将以往研究神经疾病患者和精神疾病患者的幻觉症状时所用的范式分为现实监测范式(reality monitoring paradigms) (Brunelin et al.,2006)以及现实辨认范式(reality discrimination paradigms) (Smailes et al.,2020;Varese et al.,2012)。前者是通过实验模拟让患者自动产生幻觉,后者则是通过指导语让患者在知觉模糊的条件下产生幻觉。本文借鉴前人有关幻觉范式的分类标准,从视错觉监测范式(pareidolia monitoring paradigms)和视错觉辨认范式(pareidolia discrimination paradigms)这两类范式出发探讨面孔视错觉的产生。前者的特点是让被试观看带有面孔元素的物体图片,后者的特点则是仅呈现噪音图片诱发被试产生面孔视错觉。类似地,在Rahman 和van Boxtel 的研究中,他们将实验任务基于材料的类型进行命名,分别称作嵌入面孔任务(embedded face task)以及穆尼面孔任务(mooney face task)。此外,有研究类似地将测试基于材料类型分为场景视错觉测试(scene pareidolia test)和噪音视错觉测试(noise pareidolia test) (Nakata et al.,2022)。
2.1 视错觉监测范式
类似于在日常生活所产生的面孔视错觉,被试在视错觉监测范式中会观看类面孔物体图片并产生面孔视错觉。在一般的视觉面孔实验中,通过呈现不同类型的面孔刺激,要求被试对面孔刺激基于某种要求做出反应。除了反应时及正确率,研究者也会记录被试在接受面孔刺激时的其他指标,比如眼动中的扫视占比(Pereira et al.,2020)、ERP 中的N170 成分幅值(Proverbio &Galli,2016)或 fMRI 中枕颞叶区和前额叶区的激活情况(Akdeniz et al.,2018)。类似地,在面孔视错觉研究中,刺激材料在保留面孔刺激的基础上,增加了类面孔物体图片,有时也会增加纯物体图片作为对照(Proverbio &Galli,2016;Wardle et al.,2020)。本章节主要围绕该范式的材料选择、参数设置以及因变量采集这三个角度进行梳理。
首先,不同研究在面孔和类面孔物体图片的采集上有所不一。如人脸图片可源于计算机合成(Petrican et al.,2012)和真实人脸采集(Akdeniz et al.,2020;Wardle et al.,2020)。类面孔物体图片的选择可源于互联网(e.g.,https://www.flickr.com/groups/facesinplaces/pool/)或相关书籍(Manesi et al.,2015;Proverbio &Galli,2016;Rekow et al.,2022;Taubert et al.,2017;Wardle et al.,2020),又或是类似阿尔钦博托(Giuseppe Arcimboldo,1527~1593)绘制的由各种物体所堆砌的人物肖像。此外,研究者也可基于任务难度和要求通过自行拼搭的方式生成类面孔物体图片(Rolf et al.,2020),如图1b 所示。

图1 日常生活中可引起面孔视错觉的图片。如a)天然的景观,b)拼搭的食物组合,c)汽车的车前框,d)可产生视错觉的画作(绝大多数图片来自https://www.flickr.com/groups/facesinplaces/pool/)
其次,图片材料的呈现方式也会基于实验要求存在一定差异。一般情况下,类面孔物体图片的呈现方式是单张图片呈现的。比如在探究帕金森症患者的幻觉症状是否同视错觉现象存在共同神经机制时,研究者让帕金森症患者依次观看动植物图片,要求患者在认为看到实际并不存在的物体时指出其位置(Uchiyama et al.,2015)。也有研究让精神分裂症患者和正常个体依次观看由水果蔬菜所组成的面孔,并询问被试是否看到水果中存在着面孔(Rolf et al.,2020)。在认知神经实验中,视错觉监测范式所用的材料也有所不同。一般情况下即呈现单张类面孔物体图片,记录呈现图片后个体电生理指标的变化(Akdeniz et al.,2018;Proverbio &Galli,2016)。除了单张图片呈现,也可将面孔、视错觉物体以及相匹配的一般物体两两呈现,根据个体对两种图片的关注时间长短来比较其对两种不同图片的喜爱偏好。比如同时呈现带有眼睛花斑和没有眼睛花斑的蝴蝶,要求被试基于图片对这两只蝴蝶喜爱程度及保护态度做出决策(Manesi et al.,2015)。又或是同时呈现正立和倒置的类面孔物体图片,通过分析个体对两类图片的关注时间来判断个体是否会产生面孔视错觉(Guillon et al.,2016),个体在正立的类面孔物体图片会关注时间更久,表明类面孔物体图片会使得个体产生视错觉,进而吸引更多注意。
最后,被试所需做出的反应类型以及刺激材料的呈现时间也会基于实验要求存在一定差异。如仅让被试观看类面孔物体图片,为了保证被试能集中注意力在图片本身,要求被试在特定条件下,如当图片存在倾斜或图片周围存在边框时,做出按键反应(Cao et al.,2016;Wardle et al.,2020)。然而更多的视错觉监测范式还是要求被试对图片做出按键反应。一方面,在被试的反应类型上,目前更多的行为研究关注被试的按键反应,如反应时,即类面孔物体图片呈现至个体报告产生视错觉的间隔时间(Akdeniz,2020;Akdeniz et al.,2020;Pereira et al.,2020)。除了按键反应时,也有研究在给孤独症患儿和正常儿童呈现正立和倒置的类面孔物体图片时,通过分析首次注视时长和总注视时长来比较两类儿童对类面孔物体图片的偏好程度(Guillon et al.,2016)。另一方面,也可将被试看到图片后的报告结果基于图片的实际属性进行分类,如将面孔视错觉发生程度定义为在所有呈现可引起视错觉的素材试次中被试报告看到面孔的比例(Mamiya et al.,2016)。此外,图片的呈现时间也会受到被试所需做出的反应类型和采集的数据类型影响。比如当采集被试的主观汇报(如口述是否看到视错觉图案,并指出其具体位置或大致象限),图片的呈现时间则为无限(Manesi et al.,2015;Rolf et al.,2020),或较长(如60 秒) (Mamiya et al.,2016)。当采集被试的眼动数据时,呈现时间则相对较短 (Guillon et al.,2016;Pereira et al.,2020)。类似地,有关视错觉的脑电或磁共振实验中,研究者也会根据实验要求调整图片的呈现时间。如有的实验将图片的呈现时间设置成3000 ms 以内甚至300 ms,以便获取相应的脑电成分(Cao et al.,2016;Proverbio &Galli,2016)或激活脑区(Wardle et al.,2020),但也有呈现时间在10 s 以上的情况(Akdeniz et al.,2018)。
2.2 视错觉辨认范式
面孔视错觉的产生既源于快速的自动化加工,也源于自上而下的期望。不同于视错觉监测范式通过使用类面孔物体图片,视错觉辨认范式通过指导语让被试产生自上而下的迷信观念(superstition)(Gosselin &Schyns,2003)或称作期望信号(predictive code) (Summerfield et al.,2006),以此使被试在纯噪音图片中产生面孔视错觉。本章节主要从材料选择、实验流程以及因变量采集这三个角度对此范式进行梳理。
首先,该范式所选择的材料即为噪音图片。视错觉辨认范式的特点即是个体从不存在面孔的噪音图片中辨认出面孔。以往研究所使用的视错觉辨认范式较为统一,包括了练习阶段以及实测阶段(Salge et al.,2020;Zhang et al.,2008)。实验要求被试当从噪音图片中辨认出面孔时进行按键,其中在练习阶段会包含不同噪音处理的面孔,比如25%、50%、75%噪音处理的面孔图片以及100%的纯噪音图片(Salge et al.,2020)。在噪音模糊处理上,较多的研究采用的是高斯模糊(Barik et al.,2019;Gosselin &Schyns,2003;Salge et al.,2020;Zimmermann et al.,2019),但也有研究采用其他模糊化处理,如将不同半径大小的高斯噪音点进行叠加,相较统一半径的高斯噪音图片,此类噪音图片的呈现会更加不规则化(Liu et al.,2014)。此外,也有采用碎片模糊化处理(Bowman et al.,2017;Rahman &van Boxtel,2022;Revankar et al.,2020)、1/f3frequency 处理(Mamiya et al.,2016)以及分形噪音处理(Hansen et al.,2010),如图2 所示。

图2 不同纯噪音图对比:a)为模糊化的图片;b)为高斯模糊噪音;c)为分形噪音
其次,相较视错觉监测范式,视错觉辨认范式的流程更为复杂。具体实验流程为,在练习阶段开始时告知被试,接下来的实验中有一半试次会呈现面孔图片,而另一半试次会呈现纯噪音图片。在练习阶段的第一个区组中,面孔图片没有经过噪音处理,但在随后的区组中面孔图片转为经25%噪音处理过的面孔图片。以此类推,在练习阶段的后续几个区组中,被试会更难以从噪音图片中辨认出面孔。此外,虽然在指导语中说明存在噪音处理过的面孔图片,但在练习阶段的最后一个区组中,只会呈现纯噪音图片。不同实验在练习阶段对面孔的噪音化比例有所不同,比如有实验使用10%、30%、60%以及100% (Salge et al.,2020),也有实验使用10%、50%、75%以及100%(Zimmermann et al.,2019)。该范式的核心即是让被试产生有关面孔的期望信号,并在练习阶段感受到任务难度的增加。在实测阶段中,研究者依旧告知被试有一半的试次呈现噪音处理过的面孔图片,但实则所有试次均只呈现纯噪音图片。若被试在实测阶段某一试次中报告称看到面孔,表明被试将噪音图片加工为面孔,这种错误判断即定义为产生面孔视错觉。
被试在该范式中之所以能产生面孔视错觉,主要源于指导语及练习阶段产生的期望信号。其中指导语的重点便是突出面孔图片在实测阶段的出现概率,即50% (Gosselin &Schyns,2003),也有指导语仅告知被试在实测阶段中会出现面孔图片(Barik et al.,2019)。但若未告知被试实测阶段中存在面孔图片,只要求被试在接下来的实测阶段看到面孔进行按键,则被试报告称看到面孔的试次占比会相较前者有明显降低(Salge et al.,2020)。有关该范式的行为数据,可以使用被试报告称看到面孔的试次数占总试次数的比例(Barik et al.,2019;Salge et al.,2020)。此外,也有研究基于信号检测论,获取被试对相应图片的敏感性及判断偏差(Bowman et al.,2017)。再者,诸多研究通过将判断为面孔的噪音图片同未判断为面孔的噪音图片分别进行聚类分析,来比较聚类点位置同一般面部局部特征之间的联系。研究者发现那些被识别为面孔的纯噪音图片,存在一些与眼睛、嘴巴等面部特征相似位置的聚类点,因此可能个体主观的期望对自下而上的视觉信号进行了特异性加工,进而产生面孔视错觉(Gosselin &Schyns,2003;Hansen et al.,2010;Liu et al.,2014)。
3 面孔视错觉的发生过程及神经机制
面孔视错觉的认知神经机制涉及到视觉信号的传输及面孔的错误识别。视觉的产生和辨认,既包含将初级视觉信号向上传输至负责识别相应事物脑区的过程,也包含将记忆信息反馈至识别区域同视觉信号进行匹配并做出判断的过程(Palmer,1975)。研究发现被试在两种任务中产生面孔视错觉的比例并不存在高度相关,以此提出需将两类实验结果分开进行讨论(Palmer &Clifford,2020)。一方面,在视错觉监测范式中,个体产生有关面孔的错误判断更多是源于外界材料与面部特征存在高度的相似性。另一方面,在视错觉辨认范式中,个体对面孔的期望产生了面孔视错觉,这种期望既源于主观意识,也可源于外界环境(Bar,2007)。视错觉监测范式和视错觉辨认范式均可让被试产生面孔视错觉。然而,前者侧重于个体从类面孔物体图片中提取并加工类面孔特征,随后产生有关该物体是面孔这一快速但错误的预测。后者则侧重于在相对较长的加工过程中,较早的加工预测并未导致个体将物体直接觉知为面孔,而是由于先前的期望信号促进个体对无意义特征的重解释,最终使得个体从纯噪音图片中错误辨认出面孔。此外,也有研究提出视错觉监测范式是让被试产生面孔视错觉,而视错觉辨认范式则是让被试在噪音图片中进行面孔检测(Rahman &van Boxtel,2022)。因此,考虑到两类范式的实验材料、实验目的等各不相同,个体产生面孔视错觉所涉及的认知神经机制可能也存在异同。
3.1 自动产生面孔视错觉
根据 Bar (2007)提出有关感觉预测的过程,面孔视错觉的产生也存在类似情况。如图3a 所示,个体首先提取类面孔物体的局部特征,随后将提取出的特征同大脑记忆中的概念进行类比(analogy),在类比过程中联想(association)类比物的相关属性,并根据特征重叠较高这一标准从类比的过程中得出预测(predication)。最终基于预测,个体快速得出类面孔物体可能是面孔的结论。同日常生活中产生视错觉类似,在视错觉监测范式中,被试直接观看类面孔物体图片,此时面孔视错觉的产生也是一种自动且又快速的过程(Guillon et al.,2016)。
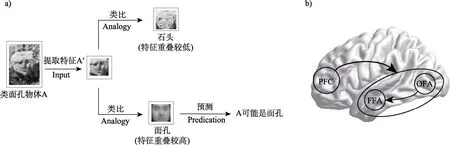
图3 自动产生面孔视错觉的认知神经机制:a)个体提取类面孔物体的局部特征,随后将特征同大脑记忆中的概念进行类比,类比过程中伴随着有关类比物的联想过程,并根据特征重叠度从类比过程中得出预测。最终基于预测,快速得出类面孔物体可能是面孔的结论;b)快速产生面孔视错觉的神经机制。
自动产生面孔视错觉的神经机制,主要集中在涉及类比过程的梭状回面孔区(fusiform face area,FFA)。有研究提出,在以200 至300 ms 的时间呈现图片时,个体会整合类面孔物体图片中所带有的低级类面孔特征并激活相应的面孔检测脑区,而非将类面孔物体图片进行重新加工(Wardle et al.,2020)。同时,使用视错觉监测范式的神经影像研究也发现,让被试观看类面孔物体图片会激活梭状回面孔区(Wardle et al.,2020)。也有研究使用两张不同面孔所组成的复合面孔,通过对该区域进行经颅直流电刺激后发现,个体将复合面孔识别为同一张面孔的误报率有所降低,即个体降低了对复合面孔的整体感知(Yang et al.,2014)。此外,Gulsum 等人(2018)发现前额叶(prefrontal cortex,PFC)同梭状回面孔区在个体产生面孔视错觉的试次均存在激活。也有研究者提出个体在视错觉监测范式中产生面孔视错觉时,前额叶参与到自上而下的反馈信号输出,且梭状回面孔区接受来自前额叶的信号以及来自枕叶面孔区(occipital face area,OFA)的视觉信号(Wardle et al.,2020),如图3b 所示。
此外,类面孔物体图片种类繁多,导致图片本身所带有的低级特征其差异性也较大。有研究提出,个体可能将物体图片中的部分低级特征,如形似眼睛和嘴部的图案,整合为一个中级特征,进而向上传输至梭状回面孔区(Palmer &Clifford,2020)。此外,Proverbio 和Galli (2016)在探究面孔视错觉的性别差异时发现,女性被试相较男性被试在激活了枕叶及顶叶的基础上,还会激活涉及社会和情感信息加工的颞上沟(superior temporal sulcus,STS)、扣带回以及眶额叶皮层(orbitofrontal cortex,OFC)。上述结果也说明了面孔视错觉的产生可能并非仅涉及浅层的面孔感知,也涉及有关社会线索的深层加工(Palmer &Clifford,2020)。
3.2 主观诱导产生面孔视错觉
在日常生活中,有时他人会先产生视错觉,个体则在他人的引导下产生视错觉。个体可以通过外界的主观期望,来促成加工及类比并产生后续的预测,最终产生面孔视错觉。该过程如图4a所示,个体提取某一物体的局部特征,并将该特征同大脑记忆中的概念进行类比,由于特征重叠较低,初步得出该物体不是面孔的结论。但若重叠度适中或主观期望让个体认为该物体中可能存在面孔,则继续进行类比。在随后的类比过程中个体可能会降低类比条件,如仅通过识别面部的局部特征来判断面孔的有无,又或增加类比次数重新提取其他特征并再次类比。在较长的类比预测过程后,个体得出物体可能是面孔的结论。同上述情况类似,在视错觉辨认范式中,个体并未收到来自他人的提示,但由于实验指导语使其相信在实测阶段中存在带有面孔的噪音图片。人的大脑会将感观接收的信号同自上而下的期望进行匹配(de Lange et al.,2018),这种视错觉即是源于先前所产生的期望信号(Salge et al.,2020)。同视错觉监测范式相似,有研究发现当被试汇报从纯噪音图片中看到面孔时,其枕叶面孔区和梭状回面孔区也存在一定程度的正激活(Zimmermann et al.,2019)。
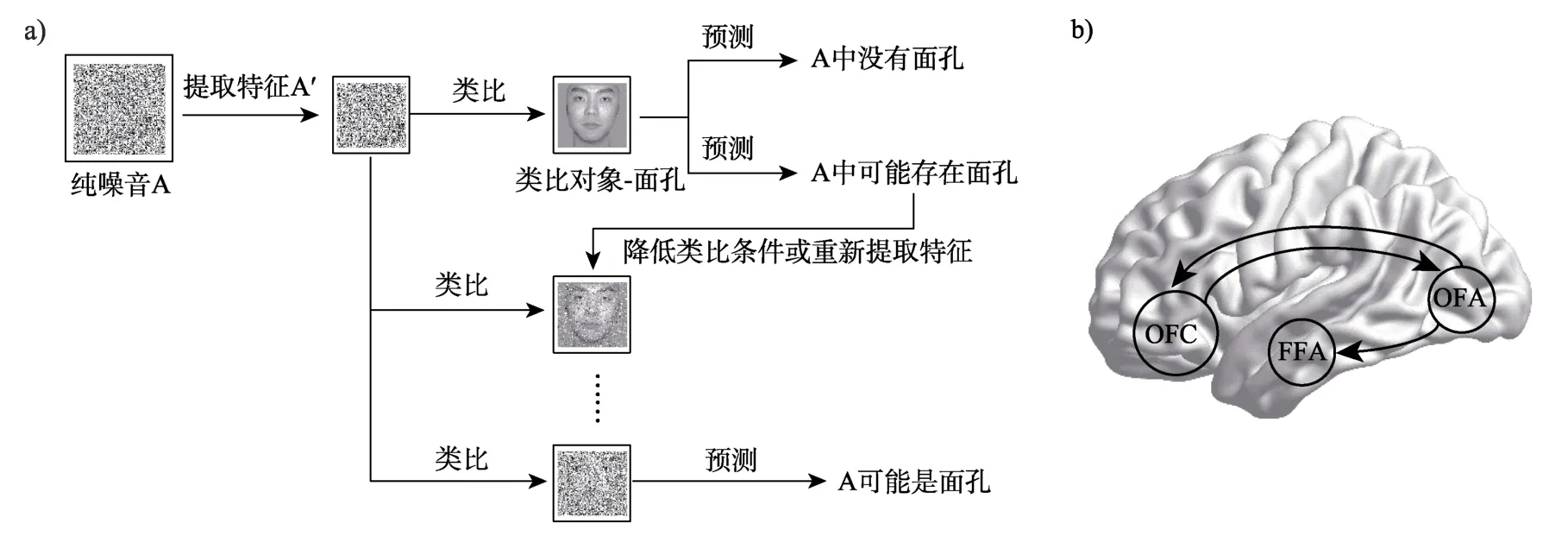
图4 主观诱导产生视错觉的认知神经机制:a)个体提取噪音图片的局部特征,并进行类比,若特征重叠较低,初步得出噪音中没有面孔,但若重叠度适中或主观期望认为噪音中存在面孔,通过降低类比条件或重新提取特征进行类比,最后得出噪音中存在面孔;b)期望诱导产生面孔视错觉的神经机制。注:眶额叶皮层(orbitofrontal cortex,OFC),梭状回面孔区(fusiform face area,FFA),枕叶面孔区(occipital face area,OFA)
除了激活枕叶面孔区和梭状回面孔区,在视错觉辨认范式中个体也会激活眶额叶皮层来产生相应的期望。如图4b 所示,有研究提出,被试在纯噪音图片中检测到面孔,可能涉及到 OFC、OFA 以及FFA 三个区域之间的联系,即OFA 指向FFA 的单向连接,以及OFC 和OFA 之间的双向连接(Li et al.,2010)。在上述三个区域中,OFC 涉及自上而下的主观期望,OFA 负责加工面部的初级特征,这种早期加工则可进一步促进对后续面孔的表征(Calder &Young,2005)。当个体产生主观期望时,OFC 向OFA 传输自上而下的反馈信息,促进个体在噪音中进行面孔特征的检测和提取。如果检测到类面孔的特征,OFA 会将视觉信号向上传输至FFA 进行有关面孔的进一步加工,同时也会向上传输至OFC,进一步增强OFC 向OFA所传输的期望信号,产生迭代强化。但当没检测到面部特征时,OFC 同OFA 之间则是负强化,进一步削弱来自OFC 的期望信号。
3.3 视错觉产生时的类比、联想与预测
针对视错觉的发生机制,学者基于不同的范式提出相应的观点。一方面,有研究提出面孔视错觉的产生可能源于个体对面孔-物体的敏感性降低,也可能是判定面孔的标准降低(Zhou &Meng,2020)。另一方面,也有研究从感观预测的角度(Bar,2007),提出视错觉的产生可能源于类比、联想和预测这三个过程(Rekow et al.,2022)。个体首先从类面孔物体中提取局部特征,并与记忆表征中的类比物及联想到的属性进行类比,并根据特征重叠度较高这一标准进行预测。在此过程中,个体对面孔-物体的敏感性降低表现在提取特征上,对面孔判定标准降低则表现在预测过程。使用视错觉监测范式的研究更注重于单次感观预测过程,即个体从类面孔物体图片中提取类似面部的特征并与记忆中其他特征进行匹配。因此,相关研究对视错觉的解释更侧重于涉及面部初级特征加工的枕叶面部区(Wardle et al.,2020)。相反地,使用视错觉辨认范式的研究则更关注指导语所产生的期望信号,侧重于通过自上而下的期望信号来促进个体从噪音图片中对有关面孔初级特征的检测(Li et al.,2010;Liu et al.,2014)。尽管前人分别对两种面孔视错觉的产生机制进行探究,但目前还未有能同时探究视错觉快速加工及缓慢加工的相关范式。因此后续研究也可以结合两类不同的任务,对面孔视错觉的发生机制进行探讨,进一步解释面孔视错觉的发生机制。
3.4 面孔视错觉与面孔加工的联系
面孔既包含了眼睛、鼻子这类物理属性,也有信任、吸引力这类社会属性。面孔加工的神经机制存在两种系统,分别称为核心系统(core system)和扩展系统(extended system) (Calder &Young,2005;Frässle et al.,2016;Haxby et al.,2000)。核心系统主要包括了枕叶面孔区(OFA)、梭状回面孔区(FFA)以及后颞上沟(posterior superior temporal sulcus,pSTS)。FFA 和pSTS 负责面孔的深层加工:FFA,尤其是右侧FFA,负责加工面孔的固定属性(invariant aspects of faces),如面孔身份(Li et al.,2010;Tsao &Livingstone,2008)以及面孔的社会属性,即便感知的是物体而非面孔也同样适用(Müller &Fishman,2018);pSTS 负责加工面孔的可变属性,如眼睛和嘴唇的移动。OFA 对面孔的局部属性较为敏感,用于处理面孔的低级特征,并将加工后的信息传递至FFA 和pSTS。同时有关面孔的加工是先进行初级属性加工,随后才能进行身份识别(Rotshtein et al.,2005)。除了核心系统,面孔加工的扩展系统则用于更为深层次的社会信息加工,比如杏仁核、脑岛用于处理面孔情绪,额下回用于语义分析,而眶额叶皮层则用于处理面孔吸引力和性(Calder&Young,2005;Zimmermann et al.,2019)。
个体从类面孔物体中既可能感知到有关面孔的物理属性,也可能感知到社会属性。如上文所述,一方面,面孔视错觉的产生即个体从类面孔物体中感知到类面孔的特征;另一方面,个体既会从类面孔物体中感知到面孔情绪(Alais et al.,2021;Wang et al.,2022),也会对类面孔物体进行有关人格特质的归因(Klatt et al.,2016;Miesler et al.,2011)。因此,有研究提出,个体可能从类面孔物体中感知到社会属性,从而产生注意导向(Takahashi &Watanabe,2013;Palmer &Clifford,2020)。这种注意导向同社会性线索所引起的注意引导类似,个体通过社会性线索,来判断他人的注意目标,以及行为背后的意图或精神状态(Bayliss et al.,2011;Frischen et al.,2007;Ishikawa et al.,2021;Nummenmaa &Calder,2009)。鉴于以往有关面孔视错觉的神经研究提出面孔视错觉的产生可能还涉及到社会线索的深层加工(Palmer&Clifford,2020;Pavlova et al.,2020),因此在产生面孔视错觉的过程中,除了联想面孔的物理属性,个体也可能联想面孔的社会属性来进行类比预测,进而对类面孔物体进行注意指向。使用视错觉监测范式的研究也发现,当给个体呈现类面孔物体图片时,涉及面孔社会属性加工的梭状回面孔区(Akdeniz et al.,2018)和涉及面孔初级加工的枕叶面孔区(Wardle et al.,2020)都有激活。也有研究发现,相较男性被试,女性被试在看到类面孔物体图片时更容易激活涉及社会和情感信息加工的颞上沟、扣带回以及眶额叶皮层(Proverbio &Galli,2016)。上述发现进一步验证了,在产生面孔视错觉的类比过程中,个体可能不仅将类比物的物理属性,也会将社会属性附着于所提取的局部特征上,使得类面孔物体带有面孔的社会属性。
大量研究通过分别使用视错觉监测范式和视错觉辨认范式来探究面孔视错觉与面孔加工之间的联系。在视错觉监测范式中,由于所用的材料均为类面孔物体,因此在整个实验过程中大多默认个体会产生面孔视错觉。但在视错觉辨认范式中,只有当个体报告称从噪音图片中看到面孔才能定义为个体此时产生了面孔视错觉。因此,有关面孔视错觉的神经影像研究更多采用的是视错觉监测范式,比较的是个体在观看面孔图片、类面孔物体图片以及普通物体图片时相应脑区所发生的激活变化(Nestor et al.,2013;Wardle et al.,2020;Zhang et al.,2008)。但也有少量研究采用视错觉辨认范式探讨期望信号下所产生的面孔视错觉和文字视错觉(Liu et al.,2014)。虽已有不少研究探究了产生面孔视错觉的两种不同加工机制,但目前还未有较多研究能整合两类范式的研究,从两种角度同时比较并解释面孔视错觉的产生。
4 面孔视错觉的研究价值
面孔视错觉的产生并非偶然,探索面孔视错觉的产生具有一定的研究价值。正如上一章节所述,面孔视错觉的发生机制基于产生方式的不同而存在差异,但基本围绕有关面孔加工的类比、联想和预测三个过程展开。鉴于类面孔物体和真实面孔存在类似的加工机制(Alais et al.,2021),面孔视错觉的研究可进一步了解个体在加工类面孔物体过程中如何提取特征,为面孔加工机制的探究提供一定的参考依据(Palmer &Clifford,2020)。再者,面孔视错觉涉及到“面孔”和“视错觉”这两个方向,部分疾病患者也具有面孔识别困难或视觉感知错误的症状(ffytche &Howard,1999;Liu et al.,2021),面孔视错觉现象可以作为部分疾病的临床表现。最后,探究类面孔物体吸引注意的机制,也可为面孔视错觉的产生机制提供理论依据,并为面孔视错觉现象应用于商业广告领域奠定一定基础(Delbaere et al.,2011;Guido et al.,2018)。
4.1 孤独症与面孔视错觉
孤独症(Autism Spectrum Disorder,ASD)是一种发育障碍性疾病,其特征之一为缺乏与他人的社会互动及交流(American Psychiatric Association,2013)。孤独症患者对社会性刺激的注意也与健康成人不同,患者会更多关注缺乏社会线索的非社会区域,而较少关注带有社会信息的区域(Chevallier et al.,2012;Nakano et al.,2010),比如孤独症患者在观看面孔时,表现出对眼神注视的回避(Frazier et al.,2017;Weigelt et al.,2012)。孤独症患者对面孔的加工异常,可能源于由杏仁核和颞上沟组成的社会性脑网络(social brain network)同健康人群存在差异。相较健康成人,在孤独症患者社会性脑网络中各个区域之间的功能连接有所减少(Sato &Uono,2019)。社会性脑网络的相关功能与孤独症患者所表现的症状也存在一定重叠,包括难以推断他人的情绪或意图、识别面部表情以及缺乏对社会性线索的注意导向(Guillon et al.,2014;Müller &Fishman,2018)。一项元分析发现,孤独症患者的左侧梭状回在面部处理任务中表现出激活减弱,同时涉及面部初级加工的枕叶区域在面孔加工过程中也存在受阻,从而可能导致了患者对面部的异常处理(Nickl-Jockschat et al.,2015)。
鉴于孤独症患者在面孔加工上同健康成人存在差异,也有研究探究该类患者是否对类面孔物体的加工上异于常人。使用视错觉监测范式的研究发现,孤独症患儿对于类面孔物体图片的面孔检测较弱,相较同龄正常儿童,孤独症患儿很难从类面孔物体图片中产生面孔视错觉(Ryan et al.,2016)。此外,有研究者给儿童依次呈现由食物组成的十幅图片,越往后呈现的图片会越像面孔,要求其判断呈现的图片中是否存在面孔,以此探究孤独症患儿和健康儿童在产生面孔视错觉时所存在的差异(Pavlova et al.,2017)。他们发现孤独症患儿将食物组成的图片识别为人脸的阈值要高于正常儿童,这说明孤独症患儿表现出较差的面孔调节能力。上述结果表明,相较正常儿童,孤独症患儿产生面孔视错觉较为困难。但也有研究在关注两个群体差异的基础上,了解孤独症患者是否可以产生面孔视错觉。如有研究在使用视错觉监测范式时,给儿童同时呈现正立和倒立的类面孔物体图片,并采集了儿童的眼动数据。他们发现相较同龄正常儿童,孤独症患儿首次注视正立类面孔物体图片的时间更晚。此外,相较倒立的类面孔物体图片,两个群体更多地关注正立的类面孔物体图片(Guillon et al.,2016)。也有研究使用视错觉监测范式以及图片形状判断任务时发现,相较一般物体,孤独症患儿与正常儿童在观看类面孔物体时,涉及面孔结构加工的N170 振幅有显著增加。同时,相较图片形状判断任务,正常儿童在进行视错觉监测范式时其N170 振幅有显著增加,而孤独症患儿在两类实验中的N170 振幅则无显著差异(Akechi et al.,2014)。上述结果表明,相较正常儿童,孤独症患儿并非不能产生面孔视错觉,只是不容易产生面孔视错觉。
孤独症患者同正常人在产生面孔视错觉上的差异可能源于类比和联想过程。相较正常儿童,孤独症患儿由于缺乏对面孔的阈限感知,也缺乏对面孔的定向监测,使得个体无法较快地从类面孔物体中提取到类面孔的局部特征来进行类比。同时,患者涉及面孔加工的脑区激活较弱,可能使得他们也无法基于联想做出类比预测。虽然孤独症患者在产生面孔视错觉时较为困难,但并不意味着他们就无法产生面孔视错觉。患者较高的孤独水平可能会促进他们对社会线索更强烈的搜索欲望(Pickett et al.,2004),他们或许可以通过不断提取特征并最终产生面孔视错觉(Chevallier et al.,2012)。此外,孤独症患者对面孔的不敏感也表现在社会同步障碍上,即对社会性线索缺乏注意引导(Liu et al.,2021)。如前文所述,类面孔物体也具有注意引导的作用,可作为社会性线索对患者的行为进行干预治疗。一方面,鉴于孤独症患者对于面孔视错觉的接受程度更高(Singleton et al.,2014),今后涉及孤独症患者社会性注意的研究可采用类面孔物体和真实面孔图片混合,而非单纯面孔图片的方式,让患者逐渐适应社会性线索。另一方面,有研究发现,对孤独症患儿使用人脸面孔进行社会性注意的训练,可以改善其对表情的识别能力并推广到其他情境(Whalen &Schreibman,2003)。若类面孔物体图片替代真实面孔依旧能发现类似的干预效果,今后研究者与临床工作者可将接受程度更高的类面孔物体图片应用于改善孤独症面孔信息加工的行为治疗中。
4.2 视错觉和视幻觉
视觉感知中感知到本不存在的事物,并非视错觉特有,视幻觉症状也存在类似表现。视幻觉,是指个体看到并不存在的闪烁光点或几何图案(Allefeld et al.,2011)。许多神经疾病,如路易体痴呆、帕金森症、阿兹海默症,以及精神疾病中的精神分裂,其症状均包含了视幻觉(O'Brien et al.,2020;Owen et al.,2016)。患者除了会产生视幻觉,也存在产生视错觉的情况,并且两种症状在上述疾病中的患病率也各有不同(Cummings et al.,2018)。早期的研究就已提出,视幻觉及视错觉可作为神经疾病和精神疾病常见的临床表现(ffytche&Howard,1999)。后续也有多个研究提出,视错觉可作为视幻觉的一种亚临床表现(Akdeniz et al.,2020;Mamiya et al.,2016;Uchiyama et al.,2015)。因此探究具有视幻觉症状的病人同正常病人在观看视错觉图片时所表现出的行为差异和生理差异可更好地解释视错觉的发生机制,并为视幻觉的发生机制提供一定参考(Smailes et al.,2020)。
除了视幻觉,神经疾病患者和精神疾病患者在视错觉的产生上也同健康成人存在差异。如帕金森症患者识别面部表情的能力存在受损,还伴有视觉识别障碍(Akdeniz et al.,2020),并且患者的视幻觉症状还会进一步影响其生活质量(O'Brien et al.,2020)。有研究使用视错觉监测范式后发现,无痴呆的帕金森症患者比健康对照组更容易产生视错觉(Uchiyama et al.,2015)。通过进一步分析后发现,个体在视错觉监测范式中的面孔视错觉报告次数与双侧颞叶、顶叶和枕叶皮质的低代谢有关,视幻觉评分(The Neuropsychiatric Inventory,NPI)与左侧顶叶皮质的低代谢有关。基于此,研究者提出左顶叶后皮质的功能障碍可能是帕金森症患者产生视错觉和视幻觉的共同神经机制。也有研究使用视错觉辨认范式后发现,帕金森症患者在出现视错觉时表现出额叶激活增加(Revankar et al.,2020)。研究者认为可能是视觉加工过程中自上而下的异常调节,致使患者无法忽视无意义刺激。此外,路易体痴呆症患者也经常出现视幻觉。有研究让正常个体、存在幻觉或未存在幻觉症状的路易体痴呆症患者分别进行视错觉辨认范式,研究者发现存在幻觉症状的路易体痴呆患者在任务中可能会通过降低感知面孔标准的方式来补偿感知缺陷,从而更容易产生面孔视错觉(Bowman et al.,2017)。同帕金森症患者类似,由于对面部特征的加工受损,精神分裂症患者也表现出在面孔及面孔情绪识别上的缺陷(Bortolon et al.,2015;Norton et al.,2009)。相关研究采用视错觉监测范式后发现,相较健康组被试,精神分裂患者更容易产生面孔视错觉,从行为层面表现出较弱的面孔识别能力(Rolf et al.,2020)。
基于视错觉和视幻觉的类似之处,类面孔物体图片可作为神经疾病和精神疾病临床诊断的评估工具。鉴于大量研究提出视错觉和视幻觉并不是独立的两个部分(Akdeniz et al.,2020;Mamiya et al.,2016;Uchiyama et al.,2015),因此可以考虑将视错觉任务作为预测视幻觉产生的指标。Mamiya 等人(2016)发现个体在视错觉监测范式中的误报率同其视幻觉评分存在中度相关,并提出可以将视错觉监测范式中的误报率作为视幻觉的指标,以此对路易体痴呆症患者进行施测。此外,O'Brien 等人(2020)也指出个体所产生的视错觉情况可应用于视幻觉的临床诊断,未来有望借此开发出针对路易体痴呆更加有效且可靠的评估工具。同时,也有研究提出,可以通过使用视错觉监测范式来预测睡眠障碍患者今后发展出路易体痴呆症的可能(Sasai-Sakuma et al.,2017)。
4.3 面孔视错觉的商业应用
面孔视错觉现象也广泛应用于商业领域,其主要特点为视觉上的拟人化。拟人化,即对无机生命体赋予人类特征,常常应用于画作、建筑和日用品中(DiSalvo &Gemperle,2003)。如图1a 所示,自然或人造的岩石景观也可引发视错觉,个体可以从融入视错觉元素的建筑中感知到快乐、恐惧等面孔情绪(Wang et al.,2022)。此外,如图1d 所示,西班牙画家萨尔瓦多·达利(Salvador Dali,1904~1989)的艺术作品往往是由各种蔬菜水果所组成的人物肖像。他应用大量面孔视错觉要素,旨在模糊观赏者对现实和虚拟的界限,为他们提供独特的艺术体验(Martinez-Conde et al.,2015)。个体有时候能自动且快速地从这些建筑、画作中感知到面孔的存在,有些则需要主观诱导,或者从特定角度进行感知。虽然面孔视错觉在商品中的应用表现为拟人化,但拟人化不等同于面孔视错觉。如画作中的卡通动物是作者给动物增加了人类的特征,是否也将其归为面孔视错觉还未有研究说明。
更多研究关注面孔视错觉在用户感知和体验中起到的引导注意的作用。除了在建筑、画作上,商家在产品设计上也应用了面孔视错觉元素,以此吸引观看者的注意力。早期的研究就已提出视觉上的拟人化可用于多种商业场景,比如工业制造、食品、时尚行业等领域,发挥引导消费者购买及使用的作用(Delbaere et al.,2011)。通过加入面孔视错觉要素,产品可更容易被消费者理解,更能反映产品的功能属性或利用价值,以此提升各种商业场景的视觉效果、知名度以及大众认可度(Guido et al.,2018)。基于此,广告商和设计师根据面部形态及其表情来赋予产品特定的特征,以此达到吸引个体注意力的目的(DiSalvo &Gemperle,2003;Wodehouse et al.,2018)。如图1c所示,汽车的车前框就具有拟人化的设计,使其看起来更像一张面孔。有研究提出,人类识别汽车外观的方式与识别人脸的方式类似,都会形成人格特征的归因(Klatt et al.,2016)。他们发现相较带有“友善”车前框的汽车(如车型小、轮廓柔和、车灯大而圆),被试面对带有“威胁”车前框的汽车(如车型大、轮廓刚硬)时更会提前过马路。同时也有研究发现,通过放大车前灯的汽车会引发被试更为积极的情感反应,相较普通汽车图片,被试对应用了“婴儿图式”面部特征的汽车(车型小且车灯大而圆)会评价得更为可爱(Miesler et al.,2011)。不止是汽车,其他融入了面孔视错觉元素的产品也会引起他人的更多注意,比如印着人脸图案的曲奇(Epley et al.,2007)。也有研究给被试呈现超市的商品布局,通过眼动技术发现带有卡通人物和面孔的麦片盒子比没有任何面孔的盒子更能吸引顾客的注意力(Hendrickson &Ailawadi,2014)。除此之外,视错觉在广告中的应用也起到了增加广告关注度和认可度的作用,同时也会引起消费者的注意偏好进而促进消费意图(Hart &Royne,2017)。有研究通过比较视错觉广告和非视错觉广告,来检验这两种广告在吸引消费者注意层面的差异(Guido et al.,2018)。他们发现,在观看视错觉广告的情况下,被试的注意时长与广告认可度显著高于另一种情况。
综上所述,视错觉,尤其是面孔视错觉已应用于商业、艺术创作等大众领域。个体因素,如性别、人格特征等,也会影响面孔视错觉的产生(Zhou &Meng,2020),后续研究可聚焦于探究针对不同消费群体,视错觉在其商业领域的应用是否存在差异。同时基于面孔视错觉的发生机制,提高商品中类面孔特征的占比或许可以进一步促进个体产生面孔视错觉过程中的类比和联想阶段,进而起到增强引导注意的作用。此外,类面孔物体、拟人化的卡通图案和真实面孔,三者在吸引注意上是否存在联系,后续研究也可进一步探讨。
5 总结与展望
视错觉的产生并非偶然,是源于先天适应以及后天环境的共同作用,其中又往往以面孔视错觉为主。有关面孔视错觉的研究涉及了面孔加工、感觉预测模型、社会性注意以及机器学习等多个方向。本文首先介绍了研究面孔视错觉所使用的两类范式,视错觉监测范式和视错觉辨认范式。在此基础上,根据范式不同,探讨了面孔视错觉的发生过程及相应的神经机制,并罗列了面孔视错觉在临床诊断及商业上的应用。日后的研究,可从以下方面进一步探讨面孔视错觉:
5.1 视错觉范式的改进
视错觉的产生既可以是快速的,也可以是缓慢的。目前有关面孔视错觉的范式主要包括视错觉监测范式和视错觉辨认范式,前者让被试直接观看可引起视错觉的类面孔物体图片(Mamiya et al.,2016;Rolf et al.,2020;Uchiyama et al.,2015),后者则通过指导语让被试相信面孔的存在而导致其在本不存在面孔的噪音图片中声称看到面孔(Liu et al.,2014;Salge et al.,2020;Zhang et al.,2008)。有研究提出,两类范式存在差异,前者产生的是更为纯粹的面孔视错觉,而后者更多的是一种检测面孔过程中的报错行为(Rahman &van Boxtel,2022)。
正如本文中对有关两类范式其参数的罗列,范式中参数的变化,可能会影响面孔视错觉的产生。如在视错觉监测范式中类面孔物体图片的选择上,不同群体所用的材料有所不同。相较健康成年被试,当被试是儿童或老年群体,又或是精神疾病患者时,类面孔物体图片刺激的呈现则相对简单且刺激的参数变化较少(Pavlova et al.,2017;Rolf et al.,2020)。同时,有研究发现类面孔物体也存在引导注意的作用(Palmer &Clifford,2020;Takahashi &Watanabe,2013)。因此,后续研究需注意类面孔物体材料的选择,避免材料所带有的社会属性对被试产生注意导向,进而影响后续的行为反应。再者,在视错觉辨认范式中,鉴于不同研究所使用的噪音图片有所不同(Barik et al.,2019;Bowman et al.,2017;Hansen et al.,2010),日后的研究可关注不同噪音图片的选择,是否会对被试在视错觉辨认范式中产生视错觉发挥不同的作用。
5.2 拓展及深化有关商业应用中的视错觉
未来研究者可基于以下几点深化探究视错觉和拟人化在商业应用中的作用。首先,虽已有大量研究指出应用视错觉元素的商品会起到吸引消费者注意力的作用(DiSalvo &Gemperle,2003;Hart &Royne,2017;Wodehouse et al.,2018),但现有的研究很少从发生机制的角度进一步说明以产生面孔视错觉为特征的商品同一般商品之间的差异,且有关面孔视错觉的实证研究也很少能迁移至真实环境。其次,面孔视错觉也不完全等同于拟人化,两者之间存在一定的差异。如女士香水瓶的形状会做成女性的轮廓(DiSalvo &Gemperle,2003),这往往属于视错觉而非面孔视错觉范畴。有研究提出,类面孔物体和真实面孔在感知上共用了同一套表情感知机制(Alais et al.,2021)。基于此,或许类面孔物体、拟人化物体以及真实面孔也可能共用同一套面孔加工机制。此外,今后的研究可以将面孔视错觉同拟人化相结合,探讨面孔视错觉及拟人化在行为实验中如何吸引被试的注意力,以及该效应是否可迁移至真实场景以至于影响观看者做出决策。最后,虽然拟人化或视错觉的应用可吸引消费者对特定产品注意力,但无法保证这种运用可以提高产品的使用效率(DiSalvo &Gemperle,2003)。产品的视错觉或拟人化程度同商品的使用效率是否存在一定的联系,如若存在,是否可以同时提升产品视错觉程度以及使用效率。此外,针对不同消费群体,如儿童、女性,商家对产品的拟人化或视错觉应用可能也会因人而异。
