基于强化学习的改进三维A*算法在线航迹规划
2023-02-11任智,张栋,*,唐硕
任 智, 张 栋,*, 唐 硕
(1. 西北工业大学航天学院, 陕西 西安 710072; 2. 陕西省空天飞行器设计重点实验室, 陕西 西安 710072)
0 引 言
飞行器飞行前预先装订的规划航迹难以应对瞬息万变的战场态势,在实际飞行过程中需根据战场实时态势对航迹进行在线规划与动态调整。在线航迹规划技术是在满足飞行性能约束与战场环境约束等条件下求解规划航迹,是提高飞行器在复杂战场环境中生存能力与任务完成能力的关键技术,对规划算法的实时性与规划结果最优性有更高的要求。常见航迹规划方法包括:人工势场法[1]、遗传算法[2]、群智能算法[3-6]、A*算法[7]等。其中,A*算法原理简单且规划结果稳定可靠,已被广泛应用于工程实践中[8]。
近年来,国内外学者对A*算法的研究与改进主要从启发函数设计、拓展节点策略和数据处理方法3个角度出发。文献[9]通过调整启发函数中启发信息的权重,增加少许计算时间,以换取航迹结果的优化。文献[10]引入了跳点搜索的拓展节点方法,通过对搜索空间直线和对角线方向上冗余节点的有效剪枝,提升二维栅格空间的搜索速度。文献[11]采用动态矩形的双向搜索路径方法,进一步提升了算法的遍历速度。文献[12]通过引入对算法性能的评价标准为改进A*算法选择了合适的参数,提升了算法的鲁棒性。上述改进方法针对的是二维空间下的航迹规划场景,而三维空间规划的航迹节点数目更多,计算量更大。文献[13]针对动态环境下无人航迹规划问题,将稀疏A*算法嵌入到即时修复式架构,实现规定时间内可行航迹的生成与威胁连续机动下的在线航迹规划。文献[14]基于指数衰减的方法,调整A*算法在搜索节点过程中启发信息的权重,改进方法能够适应不同的环境。
随着人工智能技术的发展,强化学习方法在无人系统导航与控制领域得到深入应用[15]。强化学习在航迹规划问题中的应用方法主要包括:直接依据具体航迹规划问题建立强化学习模型[16-19],常结合深度神经网络等方法对强化学习方法进行优化,但效果有限且训练结果不稳定、变化大[20-23];结合强化学习方法对传统智能算法进行参数优化设计,能够有效解决传统智能算法早熟收敛、多样性不足、难以确定搜索参数等问题[24-27]。
考虑到实际战场环境下的规划任务需求,飞行器在线航迹规划问题并不追求得到问题的最优解,而是尽可能快地得到可行解。因此,区别于传统改进方法中对启发信息的加权,引入收缩因子改进A*算法代价函数。由于复杂地形环境对多约束条件下A*算法性能有着巨大影响,在不同任务场景中难以根据工程经验确定收缩因子的大小。对于遗传算法、梯度优化等传统优化算法而言,难以结合A*算法的整体规划过程对其航迹最优与求解效率构建目标优化模型,仅能够针对特定任务场景下的A*算法收缩因子进行优化,故优化结果不具备通用性。而深度确定性策略梯度(deep deterministic policy gradient, DDPG)方法能够综合利用神经网络与强化学习无模型学习的优势,以提升算法综合性能为训练目标设计奖励函数,无需构建具体优化模型,将A*算法整体规划作为学习训练的抽象环境,利用神经网络拟合改进A*算法代价函数的收缩因子。因此,首先建立A*算法时间性能与最优性能变化度量模型;然后,结合DDPG方法设计神经网络与A*算法搜索的复合架构,对不同任务场景收缩因子策略进行训练;最后,在线飞行时依据离线训练结果确定的收缩因子进行三维A*算法在线航迹规划。
1 问题描述与分析
1.1 航迹规划模型
在线航迹规划首先需要考虑战场环境约束条件,通过对拓展节点的筛选实现算法搜索空间的剪枝。典型战场环境约束条件包括地面地形约束、禁飞区约束、平台安全约束等[28-29]。此外,规划航迹节点的拓展与自身飞行性能约束紧密结合,确定了航迹节点在规划空间中的搜索边界。典型飞行性能约束条件包括最短航迹长度约束、最小转弯半径约束与最大转弯角约束、最大俯仰角约束以及机动能力约束。
(1)
式中:第一式表征最短航迹长度约束,lmin为由飞行器自身性能确定的最小航迹长度,h为拓展节点步长,hmin为最小步长;第二式表征最小转弯半径约束,φ为航向角,βmax为最大转弯角,PiPi+1=(xi+1-xi,yi+1-yi,zi+1-zi)表征由相邻节点确定的航迹片段;第三式表征最大俯仰角约束,αmax为最大俯仰角,z为节点高程值;第四式表征机动性能约束与飞行器飞行过程中其他约束的参数关系,v为飞行速度,nmax为最大可用过载,g为重力加速度。
1.2 三维A*算法拓展方式
结合航迹规划模型中建立的飞行性能约束,航迹节点在三维空间中以生成树的方式展开,进行拓展搜索。搜索过程具体为:以当前点为球心、搜索步长为半径的球面上对上、下、左、右、前与斜对角等9个方向进行搜索,则当前飞行器飞行至第k个航迹节点时在发射坐标系下的姿态角为
(2)
为保证拓展节点的搜索粒度,可考虑将水平方向和垂直方向上的搜索范围按角度等分。由此,根据算法步长与俯仰角和转弯角约束,将规划空间离散成可供拓展的航迹节点。各节点包括高程坐标信息、俯仰角、转弯角和评价函数值的六要素信息。设当前搜索节点Pcur(xcur,ycur,zcur,αcur,βcur,Fcur),对应父节点Ppar(xpar,ypar,zpar,αpar,βpar,Fpar),拓展节点为Pnext={Pnext,i|i=1,2,…},拓展方式如图1所示。
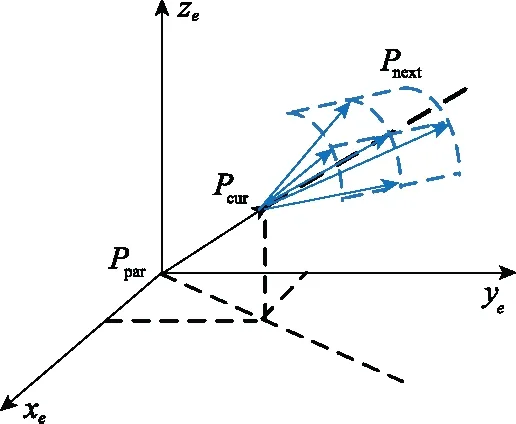
图1 拓展方式示意图Fig.1 Schematic diagram of expansion mode
1.3 三维A*算法代价函数
A*算法在Dijkstra算法的基础上,采用贪心策略,通过在搜索过程中引入启发信息,使搜索节点趋向于最优路径。代价函数包括当前节点到起始点的路程信息和当前节点到目标节点的启发信息两个部分。在传统代价函数改进中对启发信息加权,具体形式为
f=fg+ε·fh
(3)
式中:fg为采用曼哈顿方法确定的当前节点到起始点间的路程代价;fh为当前节点到目标点的启发信息;ε为启发信息在代价函数中的权重系数。当ε=1时,代价函数中的启发信息与路程信息的量级相同,此时为标准A*算法;当ε>1时,代价函数中启发信息膨胀,随着ε的增大,航迹节点的搜索拓展更倾向于目标搜索节点,最终航迹规划结果的航迹长度增加,求解时间减小。这表明:权重系数的增大能够通过牺牲规划结果最优性来提升算法时间性能。特别地,当ε=0时,标准A*算法退化为Dijkstra算法。
虽然启发信息的加权能够提升算法实时性能,但随着加权系数的增大,代价函数值在A*算法列表搜索时也随之存在数值爆炸的问题,影响搜索效率。因此,将启发信息的权重系数转换为路程代价的收缩因子,使得权重系数限定在有限区间内,避免搜索过程中列表代价函数值爆炸,代价函数变形为
(4)
式中:ω为路程信息在代价函数中的收缩因子,表征当前路程代价的权重。本文后续针对路程代价的收缩因子展开对代价函数权重系数的优化设计。
2 结合DDPG的改进A*算法
2.1 强化学习模型
强化学习的本质是当前研究的对象(智能体)与环境的交互。智能体通过对环境的感知确定当前的状态,依据既定策略在环境中选择动作,进而完成智能体的动作-状态转移。在智能体与环境的交互过程中,通过值函数对智能体选择策略进行奖惩,实现满足目标期望的迭代学习优化,使得智能体最终能够获得最多的累计奖励。本节根据研究问题与对象设计智能体、状态、动作等概念,建立强化学习模型。
2.1.1 动作-状态设计
考虑本文研究对象与内容,在A*算法求解航迹规划过程中,收缩因子的大小影响了规划结果最优性和时间性能。其中,由于A*算法中的节点拓展搜索方法采取定步长策略,规划航迹结果长度与航迹节点数目成正比,故可将航迹长度最优问题转化为航迹节点数目最优问题。因此,强化学习模型中的智能体即为概念实体A*算法,对应的状态即为A*算法的算法时间性能和规划结果最优性能在当前收缩因子影响下的优化程度,动作即为选定的收缩因子,则动作-状态空间映射可表示为
A={ω|ω∈[0,1]}→S={st,se}
(5)
式中:A为智能体动作集;S为智能体状态集;st为A*算法时间性能在当前选定收缩因子下相对于标准A*算法时间性能的变化量;se为A*算法最优性能在当前选定收缩因子下相对标准A*算法最优性能的变化量。
记t为A*算法在当前选定收缩因子下进行航迹规划所需的时间;e为A*算法在当前选定收缩因子下进行航迹规划最终结果的航迹节点数目。算法性能变化的衡量以收缩因子w=1时对应的标准A*算法性能为基准,量化百分比指标为
(6)
式中:si为当前缩减因子条件下A*算法航迹规划后的性能参数提升百分比;sori为改进前标准A*算法对应的性能参数;simp为引入收缩因子后改进A*算法对应的性能参数。
2.1.2 奖励函数设计
奖励函数的设计是强化学习模型的难点,决定了强化学习方法在学习迭代后最终收敛的期望与目标。在本文的研究问题中,奖励函数是衡量收缩因子的选取对A*算法时间性能和结果最优性能影响的数学模型,反映了在解决飞行器航迹规划问题时对A*算法时间性能与航迹最优性能的需求与侧重。两者变化的归一化度量为
(7)
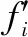
考虑飞行器航迹规划问题对算法时间性能与结果最优性能的要求,设计评价函数:
(8)
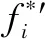
考虑奖惩关系,时间性能提升程度越大则给定奖励,最优性能降低程度越大则给定惩罚,结合式(6)设计奖励函数:
(9)

2.2 结合DDPG的改进方法
2.2.1 DDPG原理[30]
强化学习方法的基本过程是通过策略优化迭代进行动作状态转移,从而实现最大奖励总和,DDPG采用Actor-Critic方法架构结合神经网络和梯度策略(policy gradient, PG)。一方面,在策略函数μ模拟的卷积神经网络中,即Actor动作估计网络(策略网络),采用行为策略β和离线(off-policy)生成状态动作转移策略经验回放的训练数据集;另一方面,在状态价值函数Q模拟的卷积神经网络中,即Critic状态估计网络(Q网络),在策略网络训练数据集基础上进行采样,进而迭代学习得到最优策略。区别于PG方法选择动作的概率策略,DDPG方法采用确定性的行为策略β。特别地,在策略网络参数的训练过程中,动作决策采用Ornstein-Uhlenbeck随机过程引入噪声,通过时序相关的随机探索,提升算法对潜在更优策略的探索效率。
(10)
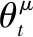
yt=E[Qμ(st,at)]=
(11)
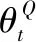
(12)
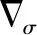
(13)
(14)
通过上述损失函数计算函数梯度并更新对应网络的权值,采用软更新方法将网络参数从当前网络更新到目标网络:
θμ-←τ·θμ+(1-τ)·θμ′
(15)
θQ-←τ·θQ+(1-τ)·θQ′
(16)
式中:τ为软策略更新因子。
2.2.2 收缩因子训练框架
区别于确定性策略梯度(deterministic policy gradient, DPG)方法的Actor-Critic双网络,DDPG方法将各网络扩增为当前网络和目标网络。Actor当前网络负责策略网络参数的迭代更新,而Actor目标网络则负责根据经验回放池中的状态采样选择最优动作。Critic当前网络负责Q网络参数迭代更新,而Critic目标网络负责当前值函数计算,具体结构如图2所示。
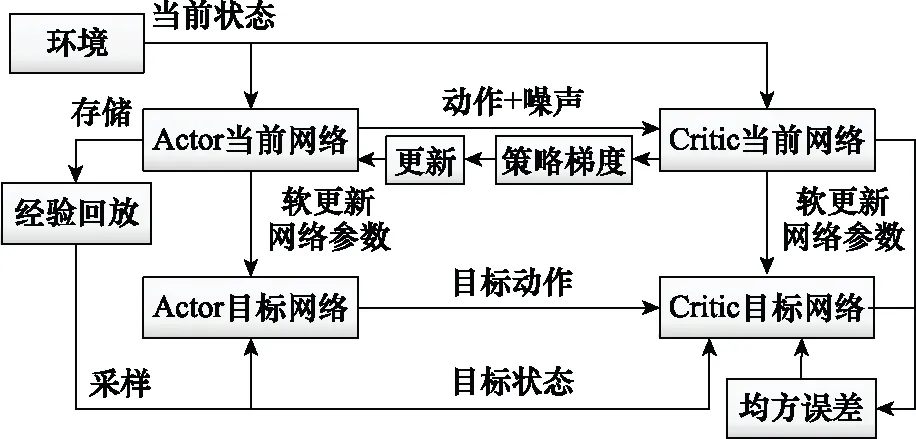
图2 Actor-Critic双网络架构示意图Fig.2 Schematic diagram of Actor-Critic network
结合A*算法代价函数中权重系数的优化设计,DDPG算法的循环结构如图3所示。

图3 算法循环结构示意图Fig.3 Schematic diagram of algorithm cycle structure
综上,基于DDPG方法的A*算法代价函数中的权重系数优化设计方法流程如图4所示。首先,对卷积神经网络参数与经验回放池进行参数初始化;然后,Actor-Critic网络从经验回放池中选取与动作对应的收缩因子;接着,由改进A*算法求解任务点间航迹规划,并得到算法求解时间与规划结果节点数目;进而,完成状态-动作转移并计算即时奖励与损失函数;重复上述训练步骤直至完成最大迭代次数后,随机更新A*算法航迹规划任务点信息,重复训练直至达到最大学习次数;最终,由此得到对应固定环境下的收缩因子策略。
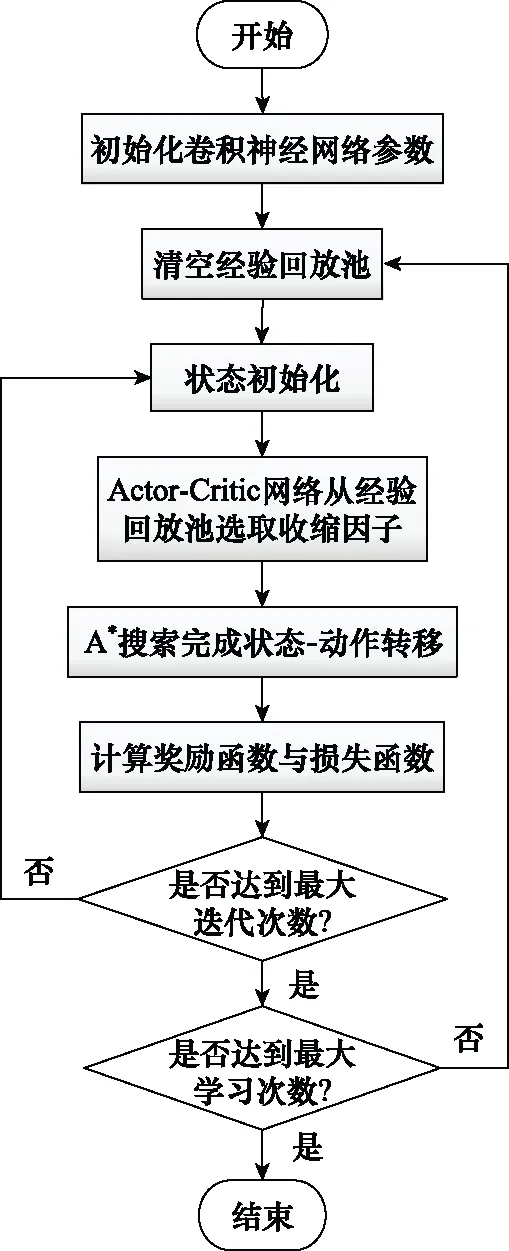
图4 结合DDPG算法流程图Fig.4 Flow chart of algorithm combined with DDPG
分析训练过程可知,在每一代训练前将任务点等信息随机初始化,在训练过程中反复调用A*算法对航迹规划问题进行求解,收缩因子策略的训练时间较长。因此,在线航迹规划采用离线训练在线应用的策略,在飞行器出发前对既定战场环境下的收缩因子确定策略进行离线训练,而在飞行器在线飞行过程中则根据由离线学习结果而确定的收缩因子,采用改进A*算法实现三维航迹在线规划。训练完成后,Actor网络中存放了可最大程度提升算法综合性能的收缩因子策略。由第2.1节可知,模型中状态为收缩因子对时间性能与最优性能的优化程度,动作对应收缩因子,环境指A*算法的整体规划过程。因此,本文提出的强化学习模型具有通用性,训练的收缩因子策略能够适用于不同作战任务场景。
3 仿真分析
本节首先在三维静态环境下验证收缩因子对A*算法航迹规划时间性能与规划结果最优性能的影响;然后结合DDPG方法对收缩因子进行训练,并考虑多组不同任务点与禁飞区的仿真场景,对比文献[13]提出的指数衰减加权方法,验证本文提出的改进A*算法在静态场景下的规划性能;最后在动态场景下验证结合DDPG训练收缩因子策略的改进A*方法的在线航迹规划能力。
3.1 引入收缩因子的改进A*算法仿真实验
仿真选定北纬38°至北纬39°与西经112°至西经113°的单元经纬网格作为战场环境,战场环境地面地形如图5所示,飞行器性能参数如表1所示,敌方禁飞区经纬坐标与威胁半径参数如表2所示。
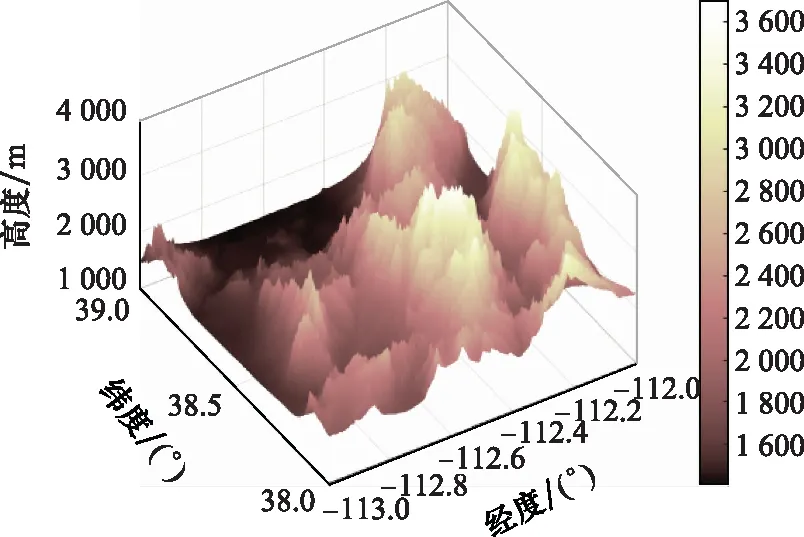
图5 战场环境地面地形图Fig.5 Topographic map of battlefield environment

表1 飞行器性能参数表
为进一步提升算法时间性能,考虑算法存储空间与排序搜索方法:① 为避免A*算法中开放列表中的拓展节点数目过多,消耗大量排序与计算时间,考虑引入存储空间约束以进一步提升算法计算效率;② 考虑采用二叉堆方法对代价函数值进行排序[31],若当前开放列表中节点数目超过预设存储空间上限,则根据排序结果将代价函数值最大的拓展节点移除,以保证拓展节点搜索效率。

表2 禁飞区参数表
选定收缩因子值区间边界验证收缩因子对算法时间性能的影响,进而确定后续DDPG方法训练收缩因子时所需的值函数。两者规划结果对比如图6与图7所示。
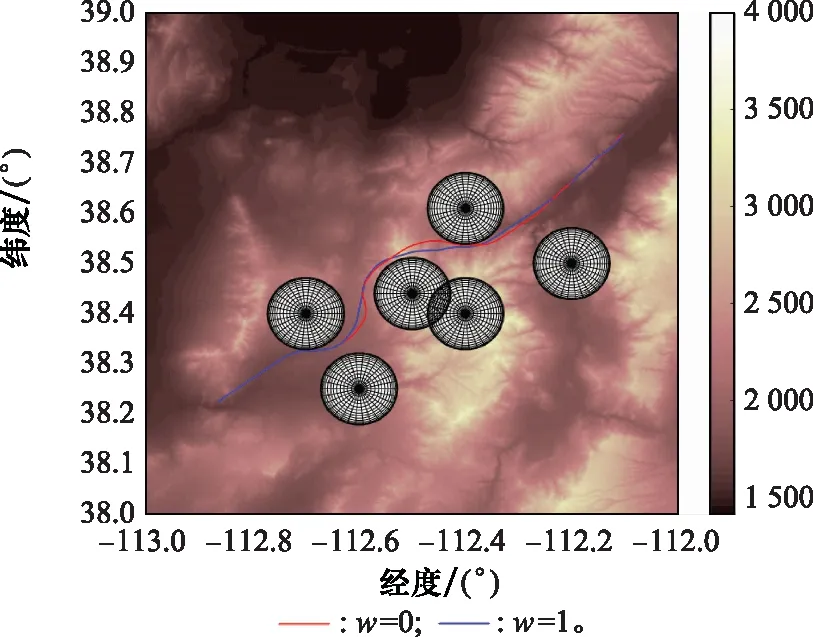
图6 标准A*算法与改进A*算法规划结果平面图Fig.6 2D comparison diagram of planning results between standard and improved A* algorithm
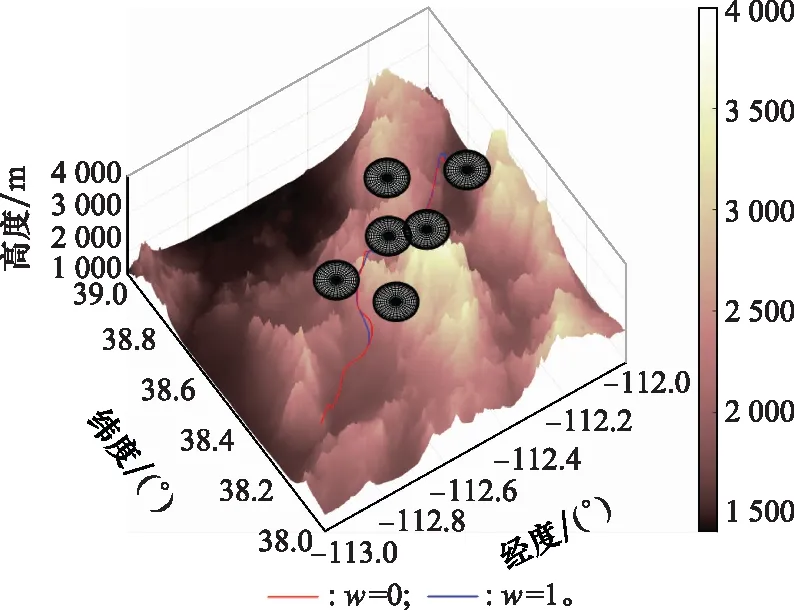
图7 标准A*算法与改进A*算法规划结果三维图Fig.7 3D comparison diagram of planning results between standard and improved A* algorithm
当w=1时,标准A*算法的仿真时间为264.13 s,规划结果节点数目为49个;当w=0时,改进A*算法运行时间为0.932 s,规划节点数目为53个。分析两者仿真时间、规划结果节点数目以及规划路径结果可以发现,引入收缩因子后,改进A*算法的规划结果满足战场环境约束与飞行器性能约束,能够在保证航迹规划结果可行的前提下提升算法时间性能。
3.2 结合DDPG方法的收缩因子训练仿真实验
结合DDPG方法对收缩因子进行迭代训练,在每一代训练前更新任务点信息,依据收缩因子值区间边界的A*算法航迹规划仿真结果。以第3.1节仿真场景为例确定奖励函数对应参数,如表3所示。

表3 奖励函数参数表
DDPG卷积神经网络参数如表4所示。

表4 卷积神经网络参数表
DDPG方法训练A*算法收缩因子策略的仿真环境为Pycharm 2020.3.1,处理器配置为Intel(R)CoreTMi9-10885H CPU @ 2.40 GHz,累计训练迭代次数为1 000次,总训练时间为20.2 min。状态变量随训练迭代次数的变化结果如图8与图9所示,反映了改进A*算法在引入收缩因子后相对于标准A*算法的时间性能与最优性能随迭代次数的变化。在此基础上,进一步分析迭代训练下的收缩因子变化与奖励函数总回报随迭代次数的变化关系,训练结果如图10与图11所示。

图8 改进算法最优性能变化图Fig.8 Variation diagram of improved algorithm optimal performance
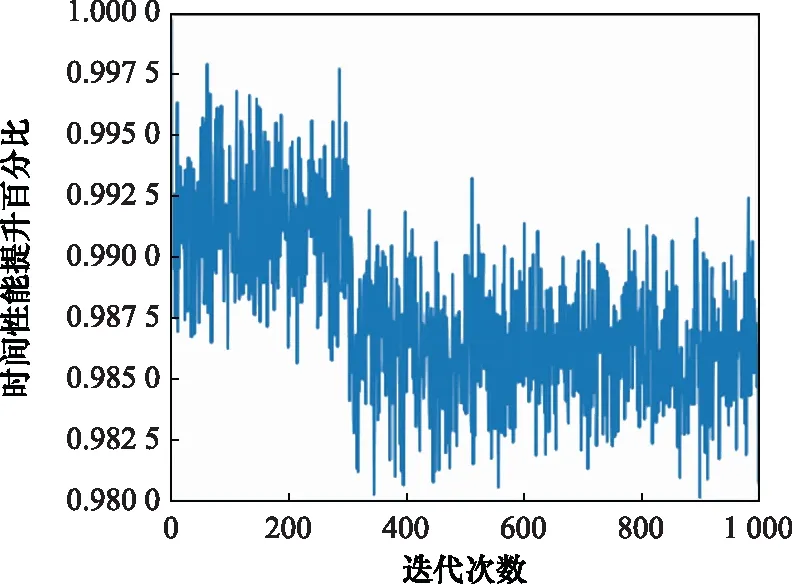
图9 改进算法时间性能变化图Fig.9 Variation diagram of improved algorithm time performance

图10 迭代收敛的收缩因子图Fig.10 Diagram of shrinkage factor of iterative convergence
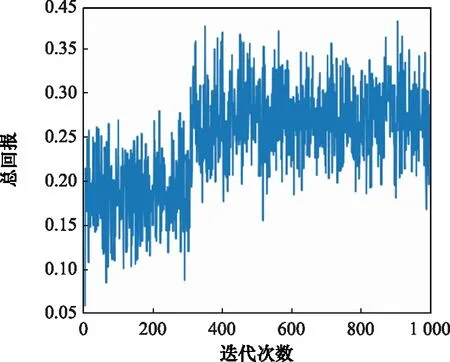
图11 迭代收敛的总回报图Fig.11 Diagram of total reward of iterative convergence
分析收缩因子迭代训练结果可知,在训练初期收缩因子在给定初值附近进行探索,收缩因子越小,算法时间性能越可以得到显著提升,规划的航迹结果轨迹长度最优性能略微下降。收缩因子策略训练在300代后逐渐收敛,奖励函数总回报稳定在[0.121.0.372],最终确定收缩因子稳定在[0.415,0.429]。
3.3 静态对比仿真实验
在第3.1节场景基础上设计不同任务点与禁飞区位置的任务场景,根据第3.2节中训练的收缩因子策略结果,对多任务场景进行航迹规划仿真,并与文献[13]提出的指数衰减加权方法进行对比。设多组不同任务点与禁飞区的经纬坐标如表5所示。其中,第1、2、3组与第4、5、6组的任务点不同且禁飞区位置相同;第1、4组与第2、5组与第3、6组的任务点相同且禁飞区位置不同。表6给出了设计的6组任务场景下,两种改进A*算法的仿真时间与规划结果节点数目的仿真结果。

表5 仿真场景参数表

表6 各场景仿真结果表
以表5中的场景1为例,指数衰减加权方法的改进A*算法运行时间为9.612 s,规划结果节点数目为69个;结合DDPG方法训练收缩因子策略的改进A*算法的运行时间为1.373 s,规划结果节点数目为52个,两种改进方法的航迹结果对比如图12与图13所示。

图12 两种改进A*算法规划结果平面图Fig.12 2D comparison diagram of planning results between two improved A* algorithms
分析表6仿真结果可知,结合DDPG方法训练的收缩因子策略相较于指数衰减加权方法,改进效果好且鲁棒性强,而指数衰减加权方法规划结果最优性差强人意,且对于不同地形环境与任务场景的改进效果不稳定。
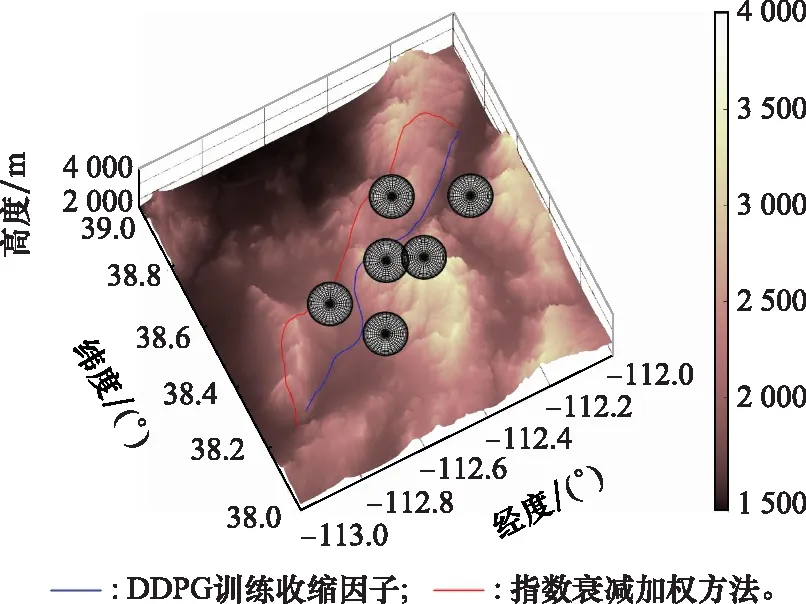
图13 两种改进A*算法规划结果三维图Fig.13 3D comparison diagram of planning results between two improved A* algorithms
3.4 三维动态仿真实验
为验证改进A*算法在线航迹规划方法的可行性与有效性,在第3.1节场景基础上设计动态威胁,飞行器飞行性能参数与表1 设置相同。设禁飞区3向南以15 m/s的速度匀速运动,禁飞区5向北以15 m/s的速度匀速运动,禁飞区6沿北偏西45°方向以15 m/s的速度匀速运动。在第3.2节收缩因子训练结果的基础上,采用改进A*算法,设拓展节点的步长为2 km,以10 s为滚动规划周期对三维动态场景进行在线航迹规划,最终全过程仿真结果如图14与图15所示。
分析仿真结果,飞行器全段飞行仿真时间为580.0 s,总航迹节点数目为58个,规划航迹结果满足地形环境与飞行器性能约束。仿真结果表明,结合DDPG方法训练收缩因子策略改进后的A*算法能够满足飞行器在线航迹规划的时间性能要求。

图14 动态场景改进算法规划结果平面图Fig.14 2D diagram of planning results for improved algorithm in dynamic scenario
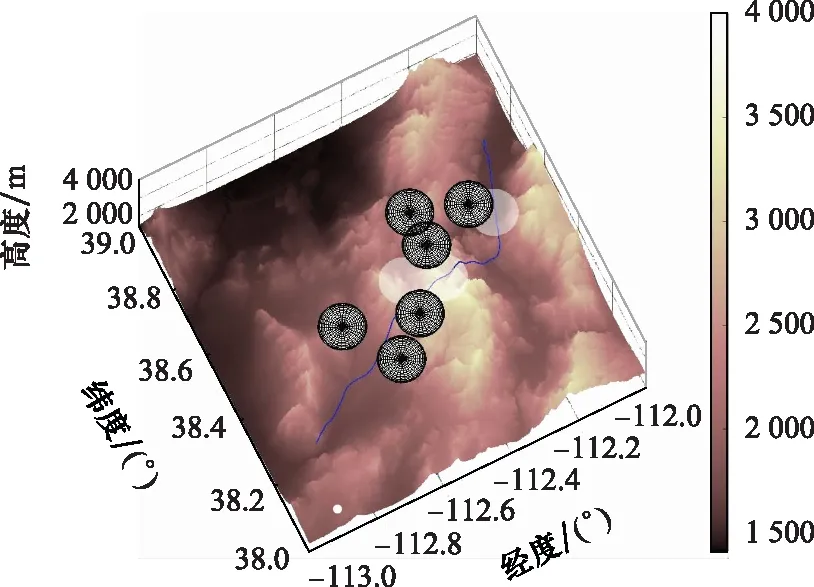
图15 动态场景改进A*算法规划结果三维图Fig.15 3D diagram of planning results for improved algorithm in dynamic scenario
4 结 论
基于强化学习方法改进三维A*算法,在保证飞行器三维航迹规划结果最优性的同时提升了算法的时间性能。引入收缩因子改进A*算法代价函数加权方法,解决了启发信息加权后在A*搜索时列表中代价函数值过大而影响搜索效率的问题,进一步提升了算法时间性能。考虑收缩因子对规划结果最优性与实时性的影响,建立综合指标模型,并结合DDPG方法对收缩因子进行训练优化。针对复杂约束条件与地形环境的不同仿真场景,改进算法的时间性能均能满足在线航迹规划的实时性要求,且算法规划结果满足飞行器自身性能条件与战场环境约束。
