融合BiFPN和YOLOv5s的密集型原木端面检测方法
2023-02-09余平平林耀海赖云锋程树英林培杰
余平平,林耀海,赖云锋,程树英,林培杰*
(1.福州大学物理与信息工程学院,福州 350108; 2.福建农林大学计算机与信息学院,福州 350002)
我国在原木贸易和原木加工上以大批量原木为主,而在单次贸易和加工过程中,原木数量常常达到上百根甚至近千根。在国家标准GB/T 4814—2013《原木材积表》中,计算成堆的原木材积需要确定原木数量、木材长度、端面直径。同一批原木的长度一般都是固定的,其端面直径可以根据树木的形状用小头直径法、中径法等确定。可见,准确检测原木数量和端面直径是其中的两个关键点。如果采取人工检尺,会消耗大量人力资源,而且由于数量庞大,使得测量结果存在主观性强且效率低等问题;若要实现自动化原木检尺,研究的难点在于实际生产中大量原木成捆堆放、卡车堆载,且堆放过程中原木的大小头交错摆放造成原木的端面径级不一,这使得原木端面图像中经常存在密集的多目标、小目标现象。密集的小目标原木是自动检尺技术存在较多漏检的一个关键难题,因此,为了准确计算成堆原木材积,十分有必要开展针对密集原木端面准确检测的相关研究。
现阶段对于原木的端面检测主要采用传统图像处理和深度学习。在传统图像处理方面:Mei等[1]通过傅里叶变换连接低频分量、反射分量和高频分量,增强了图像对比度,使原木边缘变得更加清晰,再通过变换后的图像进行原木端面检测;林耀海等[2]通过原木端面轮廓存在圆弧的特征,然后通过计算边缘重叠度对原木进行检测;陈广华等[3]采用双目视觉实现对原木端面与背景的精确分割后对原木径级进行检测;郝泉龄等[4]采用Logistic建立了回归模型,用心材缺陷面积和边材缺陷面积来确定立木的腐朽等级。传统算法依赖于提取原木端面的几何特征,当原木端面由于伐痕、污渍、发霉、原木目标较小等导致几何特征提取困难时,检测准确率大大降低。在应用深度学习方面,林耀海等[5]采用YOLOv3-Tiny结合Hough变换对端面完好、端面伐痕、端面霉变、环境复杂等情景进行检测,并取得较好的检测结果;刘嘉政等[6]利用不同树龄条件下树皮图像存在差异的特点对树种图像进行了分类。Tang等[7]通过SSD对不同尺度目标特征的提取和利用来减少光照和拍摄角度引起的遮挡,以此来提高检测精度;Lin等[8]通过改进YOLOv4-Tiny使得检测框与原木端面更加贴合,并通过软阈值化结合SE模块来提高模型识别率;余鸿晖等[9]采用Transformer和CBAM模块改进YOLOv5的特征提取网络,解决了原木被遮挡的问题,模型对整车原木场景有良好的检测效果。
然而,上述研究均未针对密集型原木端面检测深入研究,这要求所设计的网络不仅对复杂情况下的原木端面检测有良好的鲁棒性,且对密集的小目标有较强的检测能力,从而降低密集原木端面的漏检率。本研究针对成捆原木端面检测存在由于目标密集而形成的大量小目标难以精确识别的问题,提出融合BiFPN(bidirectional weighted feature pyramid network,双向加权特征金字塔网络)[10]和YOLOv5s的网络结构,在特征提取网络中加入小目标检测层,提取浅层的物理信息来加强对小目标的检测能力,同时为了解决加入小目标检测层会存在深层语义信息丢失的问题,进一步改进特征融合网络,将简化版的BiFPN融合到网络中,进一步提高网络的鲁棒性;其次,为了更好地对比密集原木端面的检测精度,该研究根据COCO数据集评价指标[11],将原木分为大、中、小目标分别对模型进行详细的性能分析。
1 材料与方法
1.1 数据采集
该研究所采用的试验数据来源包括两个部分,一部分是在福建省永安市某林场实地采集的成捆原木图像数据集,另一部分是在互联网寻找的一些接近真实原木贸易过程的图像。为了保证数据集的多样性,使得最终的模型在复杂场景能够有良好表现,并具有较强的鲁棒性,在数据集的选取过程中,除了密集型原木端面图像,还包括不同树种,尽可能多地涵盖各种复杂情况,如部分原木端面存在端裂、年轮、遮挡、霉变等。数据集共计181张图像,每一张图像中的木材数量在几根到几百根之间。
1.2 数据集制作
采用LabelImg工具对图像进行标注,标注统一采用Pascal VOC格式,使用log为样本标签。训练集和测试集的图片数量比为124∶57,其中,训练集124张图片中包含5 112个原木端面,测试集57张图片中包含4 603个原木端面。目标检测公共数据集COCO中的目标分为大、中、小3种尺寸:当目标的标注面积像素在9 216以上时认定为大目标;当目标的标注面积像素为1 024~9 216 时认定为中目标;当目标的标注面积像素在1 024以下时认定为小目标。而COCO能够采用这样的评价指标,是因为COCO官方已经将图片长边缩放到640,短边则是按照图像比例缩放。为了能够使用COCO数据集的评价指标,本研究将原木图像长边缩放到640,短边按照比例缩放。原木端面数据集数量分布如表1所示。

表1 原木端面数据集数量分布Table 1 Data distribution of log end face datasets
2 密集原木端面检测模型
2.1 YOLOv5网络原理
YOLOv5是目标检测模型YOLO系列[12-15]的最新研究成果,通过2个网络深度、宽度比例调节因子进一步地将YOLOv5分为YOLOv5-Small(YOLOv5s)、YOLOv5-Middle(YOLOv5m)、YOLOv5-Large(YOLOv5l)、YOLOv5-ExtraLarge(YOLOv5x)。考虑到网络深度过深会导致得到的模型参数量过大,不利于后续模型在嵌入式设备上的部署和推理,本研究采用YOLOv5s作为基线网络。可将网络分为特征提取网络、特征融合网络以及检测头3个部分;640×640×3代表图像的宽×高×通道数;特征融合网络标记P3、P4、P5处为特征层融合的位置。特征提取网络是在YOLOv4的CSPDarkNet53基础上[16]进行了改良,由Focus、Conv、C3、Bottleneck[17]、SPP[18]模块组成。在特征提取阶段,将整张图像作为输入,并通过特征提取网络提取目标不同特征层的特征,并将提取到的特征在特征融合网络进行融合。特征融合网络和YOLOv4一样,采用路径聚合网络(PANet)[19]。YOLOv5s的检测头和YOLOv3/v4的检测头一致,从特征提取层的第3、4、5层中分别提供大、中、小特征通道来进行多尺度检测,其中3个尺度的检测头分别对应预测小、中、大的目标。输出的通道数(cout)由分类的类别数决定:
cout=B×(5+C)
(1)
式中:B为每一个网格中预测框的数目;5代表Bbox的4个坐标信息和1个预测得分信息;C代表类别数。
2.2 改进的YOLOv5s原木端面检测模型
原始的YOLOv5s网络从第3次下采样开始进行特征融合以及检测层的输出,因为浅层的特征图具有较多的轮廓、颜色等细节语义信息,当检测大目标时,浅层的语义信息对最后的模型权重贡献不大,但是对于小原木而言,这些浅层语义信息在原木端面检测时具有较大的作用。原木图像输入网络后,特征提取网络中第1次下采样到第5次下采样的通道特征图见图1。从图1b、c可以看出在第1次和第2次下采样时,原木的轮廓信息还较为丰富,从第3次下采样开始则是一些比较深层的语义信息,这些信息对于目标的分类贡献较大。因此,传统的目标检测网络在设计时一般不会将第1、2层特征层加入特征融合网络。

图1 特征图可视化Fig.1 Visualization of feature map
2.2.1 小目标检测层
与传统目标检测网络类似,YOLOv5s原网络也是从第3层特征层开始进行特征融合的。小目标检测层则是将第2层特征层加入特征融合网络,从而提高网络对小目标的检测能力,本研究在原始YOLOv5s算法基础上添加了一个小目标检测层以保留浅层语义信息。将特征提取网络中原本没有进行融合的160×160的特征图增加到检测层,并在特征融合网络中增加1次上采样操作和下采样操作,从而将最后输出检测层增加至4层。增加了检测层后,输出的预测框也从9个相应地增加到12个,所增加的3个预测框均为长宽比不同且针对小目标检测的。
2.2.2 BiFPN及其简化
传统的FPN结构只有自上而下的单向信息流[20],PANet网络在FPN的基础上增加了一条额外的自底向上的路径进行信息增强,有效保留更多的浅层特征。BiFPN是谷歌团队在PANet基础上改进的网络结构,BiFPN网络示意图如图2c所示。BiFPN原网络将7层特征层中的第3到第7层进行特征融合,并且认为如果一个节点只有一条输入边,其对于网络的贡献较小。因此,为了减少计算量,将第3层、第7层特征融合节点删除;同时,提出跨尺度连接的方法,增加一条额外的边,将特征提取网络中的特征直接与自底向上路径中相对于大小的特征进行融合,使网络在保留更多浅层语义信息的同时也不丢失过多相对深层的语义信息。YOLOv5s的特征融合网络为PANet,从图2b可以看出,由于网络添加了小目标检测层,将原本不参与特征融合的第2层特征层加入特征融合网络中,过多保留浅层语义信息导致网络的深层语义信息丢失严重,使得网络对于特征相对复杂,因此,更多地保留这些相对深层的语义信息显得尤为重要。基于此,本研究提出一种融合BiFPN和YOLOv5s的网络模型,BiFPN的主要思想是添加了跨尺度连接,以便在不增加太多计算成本的前提下融合更多的特征。

图2 特征融合网络设计Fig.2 Feature fusion net design
此外,从图2a可以看出,YOLOv5原网络有5层特征层,其中只有第3到第5层特征层进行特征融合,即使将第2层特征层加入也只有4层特征层可以进行特征融合,而且第2层的浅层语义信息对于小目标检测有着十分重要的作用。因此,本研究选择保留第2层和第5层的特征融合层,并且借鉴BiFPN的核心思想添加了2条跨尺度连接线。改进后的网络架构如图3所示,虽然会带来少许的计算量增加,但改进的网络架构在目标密集、特征简单的数据集上能取得良好的效果。
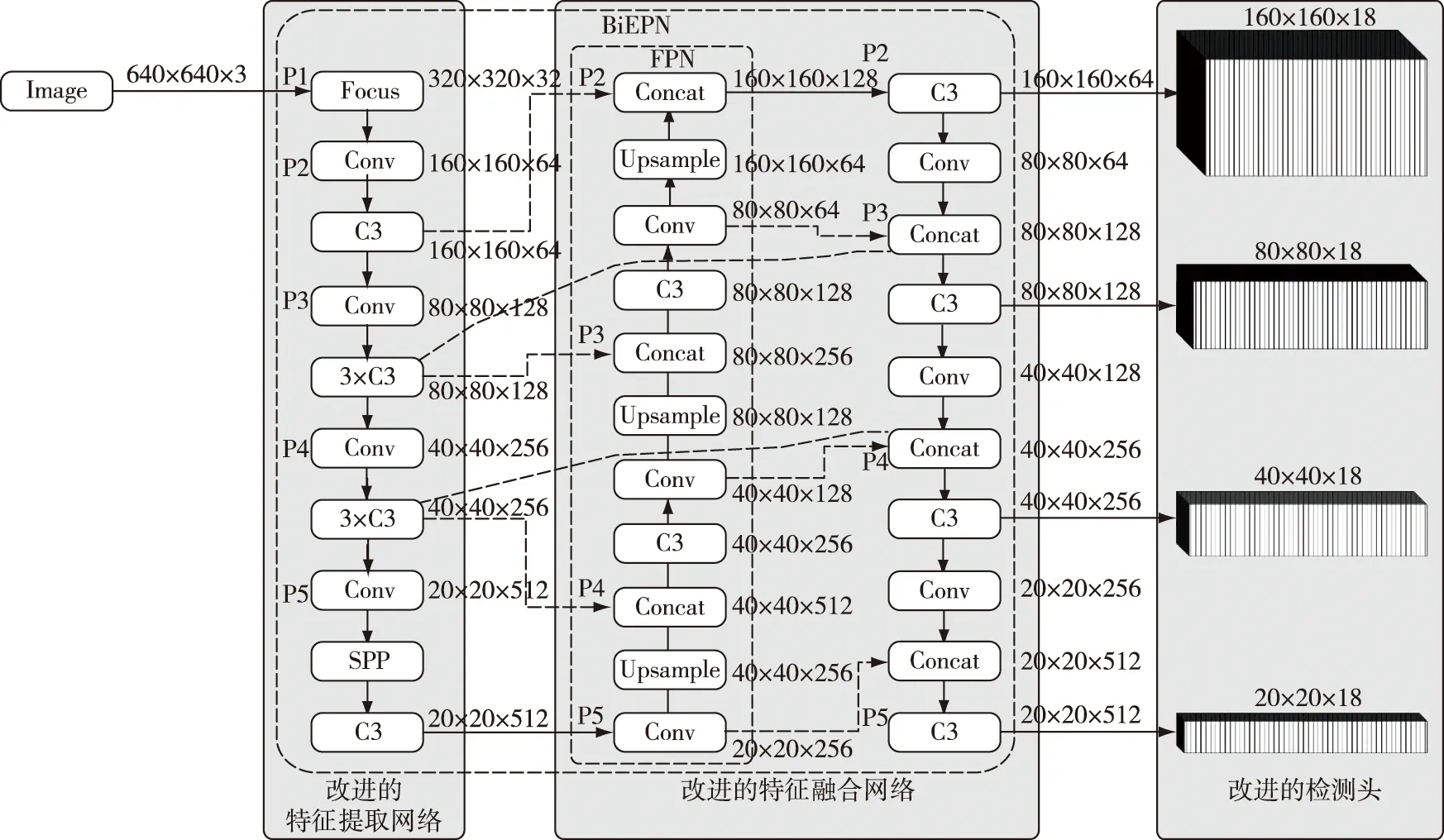
图3 改进后的YOLOV5s网络架构Fig.3 Improved YOLOV5s network architecture
3 模型训练和测试
3.1 试验参数
本试验硬件为1台配备NVIDIA GeForce RTX 2080 Ti 12 GB(GPU)、Intel(R) Xeon(R)CPU-E5-2630 V4 2.20 GHz(CPU)的服务器,采用Pytorch1.7.1 搭建深度学习框架,并使用CUDA10.1工具包进行GPU加速。由于YOLOv5采用的特征提取网络进行了5次下采样,所以输入图像的长和宽需为32的整数倍,但为了能够采用COCO的评价标准,本试验在数据预处理时已经将图片的长边缩放到640。同时,为了最小程度地改变图像特征,在尽量不改变输入图像原始比例的原则下,短边先按照比例缩放。在模型训练以及测试时,将整张原木图片输入后,由于短边也需满足32的整数倍条件,因此将短边向上取最靠近32整数倍的值。以数据集图片为例,图像采集完后的图片大小为450×300,预处理后的图片大小为640×426,放入网络时的图片大小为640×448。训练参数为:初始学习率0.01、动量0.937、批量32、权重衰减值0.000 5。为了提高模型鲁棒性,本试验在训练过程中使用YOLOv5s自带的图像增强算法,对色调(Hue,H)、饱和度(Saturation,S)、亮度(Value,V)3个通道加入随机干扰系数,通过对色彩空间的变换以模拟光线不足的场景,并达到增强霉变、污渍等复杂情况与背景的对比,使用图像平移、图像翻转的方法来模拟原木端面存在遮挡的场景。为了防止训练出现过拟合,采用热身训练,轮次为3轮,训练迭代次数设置为800,每训练一轮保存损失最小的模型,最终得到的模型即为本研究的试验模型。
3.2 评价指标
本试验采用COCO目标检测数据集将原木分为大、中、小尺寸目标后再进行性能评价。衡量模型性能指标的是在置信度阈值分数为0.5时的查准率(P)、查全率(R)、P-R调和均值F1及平均精度(AP)。P、R、F1及AP的计算公式为:
Ρ=TP/(TP+FP)×100%
(2)
R=TP/(TP+FN)×100%
(3)
F1=2PR/(P+R)
(4)

(5)
式中:TP为正确检测出的原木数量;FP为原木出现误检的数量;FN为原木漏检的数量;F1取值为0~1;r为积分变量,是对查准率和查全率乘积的积分;AP为P-R曲线与坐标轴包围的面积。本研究中用的AP30是交并比(IOU)为0.3时不同查全率下的平均精度,mAP为不同类别的平均AP值,本试验数据集中只有一类目标,因此AP等价于mAP。采用IOU=0.3而不是COCO的IOU=0.5的原因为:在数据集中存在大量的密集原木,而这些原木横截面差异较大,这就导致了当大的目标框只要包围较为不贴合时,如果设置非极大值抑制(NMS)[21]的IOU值太大,将无法剔除多余的框。因此,通过试错法最终得到IOU=0.3为NMS的临界值时,模型误检率最低。
4 结果与分析
4.1 加入简化BiFPN的结果比较
原始的YOLOv5s算法在检测原木目标时,对于小目标的检测效果存在较高漏检率的情况。针对成捆原木端面检测存在由于目标密集而形成的大量小目标难以精确识别的问题,本研究在特征提取网络加入小目标检测层,从而增强对小目标原木的检测。由于加入小目标检测层后特征融合网络的通道长度增加导致信息丢失,因此在此基础上改进了特征融合网络,即加入简化版的BiFPN。为测试加入简化版BiFPN网络的性能,在相同测试集下采取消融试验,试验结果如表2所示。

表2 不同改进结构在各个尺寸的检测结果对比Table 2 Comparison of detection results of different improved structures in each size
YOLOv5s加入小目标检测层后相比于原YOLOv5s在所有目标的查全率和平均精度上分别提高了10.82%和11.06%,其中:小目标的查全率和平均精度分别提高了17.53%和17.10%;中目标的查全率提高了0.62%,平均精度不变;大目标的查全率降低了0.30%,平均精度提高了0.03%。F1值在所有目标和小目标中分别提高了0.054和0.096,在中目标和大目标中分别降低了0.001和0.009。总体来说,加入小目标检测层后的网络在查全率、平均精度及F1值上均有明显的提高。但是从表2的结果可以看出,虽然加入小目标检测层的网络能够提高小目标的TP,但由于信息丢失增多导致网络的鲁棒性降低,使得各个尺寸的FP都有不同程度的增加,这使得加入小目标检测层的网络在所有目标和小目标的查准率分别降低了1.10% 和1.11%,在中目标和大目标的查准率分别降低了0.98%和1.45%。
改进的YOLOv5s网络在加入小目标检测层的基础上对特征融合网络进行了改进,比只加入小目标检测层的网络各方面性能指标都有所提高。对所有目标、小目标、中目标及大目标的查准率分别提高了0.21%,0.13%,0.13%及0.87%;对所有目标、小目标、中目标及大目标的查全率分别提高了2.18%,3.43%,0.13%及0.30%,对大目标的查全率依然是接近100%;对所有目标、小目标、中目标及大目标的AP30分别提高了1.97%,4.03%,0.93%及0.09%;对所有目标、小目标、中目标及大目标的F1值分别提高了0.012,0.018,0.001及0.006。总体而言,改进型YOLOv5s网络相比于原YOLOv5s网络,在所有目标和小目标的检测上,在查准率仅降低了不到1%的情况下查全率分别提高了13.00%和20.96%。试验结果表明,本研究提出的融合BiFPN和YOLOv5s的密集原木端面检测网络可以在少量降低查准率的情况下,明显地提升密集原木检测的查全率。
YOLOv5s以及加上不同网络结构对于密集原木端面的检测效果对比见图4。从图4a、b、c的绿色框可以看出,加入了小目标检测层后的算法模型,相比于原模型在密集原木端面的查全率都有较大提升。从图4a、b的黄色框及蓝色框可以看出,仅仅加入小目标检测层的算法会出现将十分靠近的2个原木识别成1个原木,而且会将图片中轮廓、颜色比较相近的物体识别成原木,从而提高了误检率。从图4b、c的黄色框以及蓝色框可以看出,在小目标检测层的基础上再加上简化的BiFPN后的算法对密集的原木端面以及轮廓、颜色相近的情况有较高的查准率和更强的鲁棒性。

注:红色框为算法对原木的检测效果,其余颜色为人工标注。图4 不同改进结构检测效果及局部放大Fig.4 Different improved structure detection effects and local magnification
4.2 不同模型效果对比
为进一步测试改进的YOLOv5s模型效果,分别对改进前后的YOLOv5s模型、无锚框检测网络YOLOX[22]、二阶段网络Faster-RCNN[23]4个网络用相同的训练参数进行训练,其中,Faster-RCNN的特征提取网络分别采用ResNet50和ResNet101[17],并且均在训练收敛情况下进行列表统计对比,各个模型的试验结果对比如表3所示。

表3 各个模型试验结果对比Table 3 Comparison of experimental results of the selected models
改进的模型相比于原模型在查准率降低了不到1%的前提下将查全率和平均精度分别提高了13.00%和13.03%,相比于YOLOXs在查准率相当的前提下,查全率和平均精度分别提高了14.28%和13.89%;Faster-RCNN的查全率和平均精度均不到45%,这主要是因为根据COCO目标检测数据集的分类标准,测试集中包含小目标原木的图片占比为30.36%,但小目标原木数量占比为60.85%,这导致了当模型对小目标原木的检测效果不好时,模型的查全率和平均精度会大大降低,改进后的模型漏检数量比其他模型大大减少。
原YOLOv5s的网络为283层,浮点运算数(FLOPs)为16.4 G,平均每张图片的检测时间为10.10 ms,权重为13.7 MB。改进的YOLOv5s的网络为341层,浮点运算数为19.5 G,平均每张图片的检测时间为11.89 ms,权重为14.4 MB,改进的模型在网络深度、权重和检测时间上略有增加。Faster-RCNN-50和YOLOXs的权重分别为330.3和107.8 MB,改进后的YOLOv5s分别为它们的4.4%和13.4%;同时,改进模型的检测速度分别为Faster-RCNN-50和YOLOXs的4.04倍和1.78倍。因此,综合模型的性能、权重和检测速度,改进的YOLOv5s模型更适用于原木端面检测。
4.3 3种尺寸目标下不同模型对比
将目标按照COCO数据集标准分成大、中、小3种尺寸进行的对比试验,结果如表4所示。在大目标的检测上,Faster-RCNN的查全率为100%,在所有模型中最高,但其查准率最低;YOLOXs在所有模型中的查全率最低,只有98.21%;改进的YOLOv5s查全率不变,查准率相比于原YOLOv5s降低了0.58%,但仍高于Faster-RCNN;改进前后的F1值均优于其他模型。在中目标的检测上,改进后的YOLOv5s查全率和平均精度最高,相比于原YOLOv5s分别提高了0.75%和0.93%,改进前后的F1值相同且均优于其他模型。在小目标的检测上,由于Faster-RCNN的特征融合网络是单向信息流的FPN,导致Faster-RCNN对小目标原木检测效果较差,而原YOLOv5s和YOLOXs的特征融合网络是具有双向信息融合的路径聚合网络,因此小目标检测效果比Faster-RCNN好。Faster-RCNN-50在小目标的检测上查全率和平均精度分别只有11.75% 和11.79%,即使将网络的深度加深,Faster-RCNN-101对于小目标的查全率和平均精度也仅有12.14%和12.74%。改进后的模型由于添加了小目标检测层以及改进了特征融合网络,对于小目标原木的查全率和平均精度分别达到97.25%和96.86%,比原YOLOv5s分别提高了20.96%和21.13%;但是随着目标检测数量的提高以及小目标检测层加入后导致信息丢失,模型的误检率也随之提高,也使查准率比原YOLOv5s降低了0.98%,改进的模型F1值远远优于其他模型。试验结果表明:改进后的YOLOv5s在大、中目标的检测上,与原YOLOv5s总体上优于其他网络;在小目标的检测上,改进的模型在查准率小幅下降的前提下,查全率、F1值和平均精度有大幅提高,且改进后的平均精度在大、中、小目标的检测上基本均优于其他模型,说明模型具有更强的鲁棒性。
各个模型对密集原木的检测效果见图5。由图5a、b可以看出,Faster-RCNN在密集的原木端面中仅能检测出一些像素占比大、轮廓较为明显的原木;由图5d、e可以看出,YOLOXs和改进前的YOLOv5s虽然相比于Faster-RCNN在检测效果上有所提升,但是漏检率依然较高,无法满足实际生产需求;图5f是改进的YOLOv5s的检测效果,相比于其他模型,能够检测出大量原木且查准率较高,适合部署在实际应用场景。

图5 各个模型对密集原木的检测效果Fig.5 The effect of each model on the detection of dense logs
5 结 论
1)本研究提出融合BiFPN和YOLOv5s的密集型原木端面检测模型。通过对模型的特征提取网络和特征融合网络研究和改进,加入了小目标检测层,并将原模型的路径聚合网络替换为简化版的双向加权特征金字塔网络,通过对比试验,验证了改进的模型更适用于实际加工、运输过程中的密集原木端面检测。
2)为了验证简化版BiFPN的有效性,用改进前后的模型以及只加入小目标检测层的网络进行消融试验,按照COCO分类标准将原木端面测试集分成大、中、小3个尺度的目标后,以调和均值F1、平均精度、查全率及查准率为判断依据。试验结果表明,融合BiFPN和YOLOv5s的网络比只加入小目标检测层的网络各方面性能指标都有所提高。对所有目标、小目标、中目标及大目标的查准率分别提高了0.21%,0.13%,0.13%及0.87%;对所有目标、小目标、中目标及大目标的查全率分别提高了2.18%,3.43%,0.13%及0.30%,对大目标的查全率依然是接近100%;对所有目标、小目标、中目标及大目标的AP30分别提高了1.97%,4.03%,0.93% 及0.09%;对所有目标、小目标、中目标及大目标的F1值分别提高了0.012,0.018,0.001及 0.006。试验证明了改进后的网络不仅对于密集型原木端面的检测具有更强的鲁棒性,在原木端面存在伐痕、污渍、发霉等复杂情况下也有良好的检测结果。
3)用改进前后的模型以及YOLOXs和Faster-RCNN进行对比试验。试验结果表明:改进的YOLOv5s模型在所有目标的查准率、查全率、平均精度和调和均值分别为97.32%,97.68%,96.78%和0.975;相比于原模型在查准率降低了不到1%的情况下,查全率和平均精度分别提高了13.00%和13.03%,调和均值提高了0.066,且性能远优于其他对比模型。大目标和中目标检测相比于原模型性能几乎不变;小目标的查全率和平均精度相比于原模型分别提高了20.96%和21.13%,调和均值提高了0.114。改进的模型参数量为14.4 MB,虽略大于YOLOv5s网络,但相比Faster-RCNN-50的330.3 MB和YOLOXs的107.8 MB,权重也仅为4.4% 和13.4%;检测速度分别为Faster-RCNN-50和YOLOX-s的4.04倍和1.78倍。因此,综合模型的性能、权重和检测速度,改进的模型更适合应用到原木端面检测任务中。
